软件测试 - Linux和数据库
文章目录
- 第一章 Linux操作系统
-
- 1.1 软件、硬件和操作系统
- 1.2 Linux 系统
- 1.3 Linux 系统的文件和目录
- 第二章 Linux常见命令
-
- 2.1基本Linux 命令
- 2.2 Linux命令相关的11个案例
- 第三章 数据库
-
- 3.1 数据库概念
- 3.2 图形客户端
- 第四章 SQL语句
-
- 4.1 数据类型与约束
- 4.2 表操作
- 4.3 单表查询
- 4.4 多表查询
- 第五章 数据库高级概念
-
- 5.1 E-R模型
- 5.2 外键
- 5.3 索引
- 5.4 命令行中操作 MySQL
- 5.5 存储过程
- 5.6 事务
- 5.7 视图
- 5.8 修改 MySQL 数据库密码
- 5.9 MySQL 日志的获取
第一章 Linux操作系统
Linux 命令: 软件测试第一个任务, 一般都需要进行环境搭建, 一部分环境搭建内容是在服务器上实现的,跟服务器交互(没有图形化页面),窗口打开就是一命令行,需要使用 Linux 命令
数据库: 所有的软件在使用过程中所产生的数据, 最终都要存在数据库当中, 而测试工作往往会需要去校验数据的正确与否, 因此需要学习数据库
1.1 软件、硬件和操作系统
1)硬件: 能看见也能摸得到。软件: 能看见不能摸得到。关系: 没有软件的硬件是没有任何意义的, 只有存在软件的硬件才能为人所用
2)操作系统作用:管理计算机硬件与软件资源的计算机程序,同时也是计算机系统的内核与基石。
- 是硬件设备上的第一层软件
- 有了操作系统可以方便我们调用所有的硬件设备
- 所有应用程序的安装使用前提是具备操作系统
3)操作系统的常见分类
- 桌面操作系统:Windows、macOS 和 Linux(占比很少)
- 服务端操作系统:Linux (占有比重非常高) 和 Windows Server
- 移动端操作系统:iOS、Android(基于Linux) 和 华为鸿蒙(基于Linux)
- 嵌入式操作系统:Linux (自动贩卖机/收银台/汽车中控)
1.2 Linux 系统
1)特点
-
开源(源代码可见)免费
注意: 开源不意味着一定是免费的(可能让看不让用,要看具体开源协议)
-
安全稳定
-
可移植性好(常见系统分类中都有Linux系统的存在)
-
高性能(服务端没有图形页面,只指令不需渲染)
2) Linux 系统分类
市面常见的Linux操作系统:ubuntu(乌班图)和CentOs
市面上常见的Linux系统都有一个共同的名字: Linux 发行版(在内核版【原始开源免费的Linux】基础上额外增加一些应用软件和图形化页面)
说明: 虚拟机及虚拟机系统仅在学习阶段起到在本地模拟服务器的作用, 实际工作中不需要安装及使用!
1.3 Linux 系统的文件和目录
1)特征:
- 在 Linux 系统中没有盘符概念,Linux是树形的文件结构
- Linux 系统中的所有文件都存放在根目录下(常用"/"代表),其他所有目录是他的子节点
2)常见目录:
- / : 根目录
- /home: 所有普通用户的家目录
- /root : Linux 系统超级管理员的家目录
- /usr/bin: Linux 命令大部分都存在于该目录下
3)特点
-
普通用户和超级管理员用户权限有很大区别
- 普通用户可以进入超级管理员的家目录, 但是无法对其中的文件进行任何操作
- 但是超级管理员用户可以做任何操作(实际工作中, 一般不会轻易获取 root 用户权限)
-
一般情况下, 普通用户的操作范围仅限在自己的家目录当中
- 例如: 当前用户为 admin, 操作范围仅限: /home/admin
第二章 Linux常见命令
2.1基本Linux 命令
1)基本格式
格式组成:
命令主体 -命令选项 命令参数
命令选项,可用来对命令进行控制,也可以省略;
命令参数,传给命令的参数,可以是零个、一个或者多个。
特点:命令主体必须存在, 而选项和参数都是可选的
常见命令形式:
1) 命令主体
2) 命令主体 -命令选项
3) 命令主体 参数
4) 命令主体 -命令选项 命令参数
2)Linux 命令的注意事项
- 命令的数量非常多, 不要妄图全部记忆下来
- 常用命令由于频繁使用, 不用刻意记忆基本可以搞定
- 工作中实际是用什么命令现查即可
3)查看命令帮助信息方法
此处以 ls 命令为例
按空格:向下翻页,按b:向上翻页
输入’/’+想查询单词/内容+回车,他就会把页面中所有相同内容的标黑
方法一:
命令主体 --help : 可以查看命令具备哪些选项及选项含义
eg:ls --help+回车
方法二:
man 命令主体 : 查看命令的手册信息,man是manual的缩写
eg:man ls+回车
注意: 默认情况下系统手册是英文的, 可以自行扩展修改为中文。 实际应用,推荐使用方法一。按'Q'就可以直接退出手册。
4)命令学习方法说明
此处以 ls 命令为例
pwd+回车:显示当前你在什么位置,即查看当前路径位置
ls+回车 : 展示当前路径下有哪些文件
ls -a : 显示当前路径下的所有文件(包含隐藏文件(文件名以.开头的))
ls -l : 以列表形式展示当前路径下所有文件的详细信息
ls -al : 显示当前路径下文件的详细信息(包含隐藏文件)
注意:
1. 命令选项连用形式为: 命令主体 -选项1选项2
2. 命令主体和选项之间必须包含一个空格
3. 命令选项的作用一般是用来扩展命令主体功能的
学习方法:
1. 优先搞清楚命令主体的含义
2. 根据实际需求结合帮助命令查找命令选项
3. 没用过的选项, 尝试自己搭建场景, 试验后看效果
4. 孰能生巧, 相较于死记命令, 勤加练习更合理一些!
5)Linux命令的共通知识点
(1)通配符的使用
通配符: 又叫文件名替换符号, 符号具备特殊含义, 例如: 文件名: test , 通配符可以写成:四个 ’ ? '或一个 ’ * ‘ 或者 t??? 或者 t*
* : 代表可以匹配任意长度的文件名(所有文件)
? : 代表可以匹配单个字符, 如果目标文件名有多个字符, 该符号可以使用多个
[]: 括号内的内容表示一个范围, [abc] : 代表匹配文件名是 a 或 b 或 c, 等价于 [a-c]
(2)绝对路径和相对路径
绝对路径: 路径源头固定不变, 常见有两个: ‘/’:根目录; ‘~’: 当前用户的家目录(即/home/admin)
相对路径: 以当前所在路径为源头, 常见的表示形式有两个: ’ . ’ :当前路径下; ’ . . ’ :当前目录的上一层(父层级)。eg:当前路径为/home/admin,上一级为/home,在当前目录(/home/admin)输入ls . .+回车显示home下所有文件。
路径注意事项:
- 以 ’ / ’ 开头的为绝对路径。路径信息中,只有开头的 ‘ / ’ 意为根目录,其余均只做路径拼接使用
- 绝对路径使用时, 需要确定文件在根目录下还是用户目录下, 合理选择起始符号即可
- 初学时, 建议所有路径优先使用绝对路径, 当清楚文件结构关系后, 逐步转换为相对路径
- 相对路径中, 如果是当前路径下的文件获取操作, 那么 ‘./’ 一般是可以省略的
2.2 Linux命令相关的11个案例
案例1: 文件和目录操作相关命令(ls/ pwd/ cd/ touch/ mkdir/ cp/ mv/ rm)
在桌面上打开终端窗口, 执行如下操作:
01.查看当前路径位置
02.查看当前目录下有哪些文件和文件夹
03.创建 adir,bdir,cdir 三个文件夹(创建一个文件夹/创建多个文件夹)
04.切换到 adir 目录下
05.创建文件 aa (创建一个文件)
06.切换到 admin 目录下(绝对路径/相对路径)
07.创建文件 file 并重命名为 aa
08.复制文件 aa 到 adir 目录下(要求提示是否覆盖)
09.复制文件夹 bdir 到 cdir 目录下
10.移动文件 aa 到 bdir 目录下
11.创建 bb,cc 两个文件(创建多个文件)
12.删除 bb 文件
13.删除 adir 文件夹
14.删除当前目录下所有文件和文件夹
01.pwd
02.ls
03.mkdir adir bdir cdir //mkdir是make directory的缩写,用于创建目录
04.cd adir // cd ./adir也行,cd /adir不行
05.touch aa
06.cd ~ //cd /home/admin也行
07.touch file
mv file aa
08.//cp aa adir,假如再输一遍cp aa adir这个操作是覆盖而不是复制了。-i 交互式复制,在覆盖目标文件之前将给出提示要求用户确认,回复n/y
cp -i aa adir
09.cp -r bdir cdir //假如复制的是文件夹的话,需要加上-r。假如复制文件夹也想有提示的话,可以用-ir,假如文件夹没有文件不会弹出提醒,有文件才会弹出提示
10.mv aa bdir //假如是移动文件adir到bdir目录下是mv adir bdir,不需要加上-r
11.touch bb cc
12.rm bb
13.rm -r adir //和cp一样
14.rm -r * //使用rm删除的时候,最好使用ls验证一下是否是要求删除的,防止误删
文件和目录常用命令的小结
- pwd:查看当前所在的路径位置(涉及到路径切换【cd 命令】时, 确认路径时使用)
- ls:查看当前路径下有哪些文件(对路径下文件进行了修改【创建/复制/移动/删除】时使用)
- cd:切换路径(更换操作目录时使用,常和绝对路径及相对路径配合使用)
- touch:创建普通文件(单文件:touch 文件名;多文件: touch 文件名1 文件名2 …)
- mkdir:创建目录文件(单文件夹:mkdir 文件夹名;多文件夹:mkdir 文件夹名1 文件夹名2 …)
- cp:复制文件/文件夹(文件:cp -i 源文件 目标文件夹;文件夹:cp -r 源文件夹 目标文件夹)
- mv:移动文件/文件夹夹(文件:mv 源文件 目标文件夹;文件夹: mv 源文件夹 目标文件夹)
mv:改名(mv 源文件名 新名字,当新名字是当前目录下不存在的文件名,用户可以使用mv进行的是改名操作) - rm:删除文件/文件夹(文件: rm 文件名 目录: rm -r 文件夹名)
rm:删除所有文件和文件夹(rm -r *)
扩展: cd 命令常用用法
cd 是英文单词 change directory 的简写,其功能为切换当前的工作目录,是用户最常用的命令之一。
- cd 切换到当前用户的主目录(/home/用户目录),用户登陆的时候,默认的目录就是用户的主目录。
- cd ~ 切换到当前用户的主目录(/home/用户目录)
- cd . 切换到当前目录
- cd . . 切换到上级目录
- cd - 可进入上次所在的目录
案例2: 对文件内容的相关操作命令(cat/more/grep/重定向/管道符/clear)
在桌面上打开终端窗口, 执行如下操作:
01. 将根目录下所有文件的详细信息输出到 demo 文件中(包含隐藏文件)
02. 直接查看 demo 文件的内容
03. 将 /usr/bin 目录下所有文件的详细信息追加到 demo 文件中
04. 以分屏的形式查看 demo 文件的内容
05. 查找 demo 文件内容中包含 mysql 的信息
06. 在 /usr/bin 目录下所有文件的信息中查找包含 mysql 的信息
07. 清空当前终端窗口中的内容
01.ls -al / //-a显示隐藏 -l显示详细信息 /是参数,在这里是路径。只是显示
ls -al / > demo //这才是01的答案
02.cat demo
03.ls -al /usr/bin >> demo
04.more demo
05.grep 'mysql' demo //‘’可以去掉 grep mysql demo效果一样
06.ls -al /usr/bin | grep mysql //从左侧命令的结果中查找 mysql
07.clear : 清空屏幕操作, 快捷键: Ctrl + L
文件内容操作相关命令的小结
- ’ > ‘ : 重定向符号(将左侧命令的结果输出到右侧的文件中。反复执行,文件原有内容会被替换)
- ’ >> ‘ : 追加重定向符号(将左侧命令的结果输出到右侧的文件中,反复执行,内容追加, 文件原有内容不会被替换)
- cat : 查看文件内容(格式: cat 文件名。适合用于查看文件内容较少的文件。英文全拼:concatenate,命令用于连接文件并打印到标准输出设备上)
- more : 以分屏形式查看文件内容(格式: more 文件名,适合用于查看文件内容较多的文件。快捷键空格、b和q也可以用。cat命令是整个文件的内容从上到下显示在屏幕上。 more会以一页一页的显示方便使用者逐页阅读,而且会显示使用者现在查看到文件的几%处)
- | : 管道符号(将左侧命令的结果传递给右侧命令当数据源,管道符右侧命令多用: grep 和 more)
案例3: 查看日志文件信息命令(head/tail/tail -f)
在桌面上打开终端窗口, 执行如下操作:
01. 将根目录下所有文件的详细信息输出到 demo 文件中
02. 查看 demo 文件前 5 行内容
03. 查看 demo 文件后 5 行内容
04. 将 ping www.itheima.com 的信息输出到 ping_log 文件中
05. 重新开启一个终端窗口, 动态查看 ping_log 文件中的信息
01.ls -al / > demo
02.head -5 demo
03.tail -5 demo
04.ping www.itheima.com //和windows三行结束不同,在linux中只要不手动停止,默认会一直持续运行。ping+ip地址/域名,查验该ip/域名是否能通信
ping www.itheima.com > ping_log //不停
05.//右键再开一个终端,之前的不能关!
tail -f ping_log
查看日志文件内容命令小结
- head : 可以查看文件开头内容(head 文件名:查看文件的前10行内容; head -行数 文件名:查看文件的前x行内容)
- tail : 可以查看文件结尾内容(tail 文件名:查看文件的后10行内容; tail -行数 文件名:查看文件的后x行内容)
- tail -f : 动态查看日志文件内容(格式: tail -f 日志文件名)
注意:
-系统相关日志存放位置: /var/log
-项目相关日志存放位置: 需要根据项目询问对应的开发人员
案例4: 重启/关机/查看系统信息
在桌面上打开终端窗口, 执行如下操作:
01. 查看当前系统内核版本信息
02. 查看当前系统发行版本信息
03. 重启当前系统
04. 关闭当前系统
01.cat /proc/version
02.cat /etc/redhat-release
03.reboot+回车
04.shutdown -h now
案例5: 程序和进程操作相关命令(ps/kill/top)
在桌面上打开终端窗口, 执行如下操作:
01. 查看当前系统下的进程信息
02. 手动打开火狐浏览器
03. 获取火狐浏览器的进程信息(进程 ID)
04. 通过结束火狐浏览器进程的方式关闭浏览器
05. 打开当前系统的'任务管理器'(动态查看进程信息)
01.ps -aux //确定pid和command位置
02.应用程序->选择火狐浏览器 //第一次打开会很慢
03.ps -aux | grep firefox //利用01得到的位置,找到对应的pid和command(没有标识,通过01自己判断哪个是。只要看出来的第一条就行,因为浏览器开启时,除了自己的主程序,还会开一些其他应用)
04.kill -9 3100 //3100是通过 03步骤找到的火狐浏览器对应的进程id
05.top
程序和进程操作相关命令小结
- ps -aux : 查看当前系统下所有的进程信息,显示的信息我们只用关注两项:PID(进程id,随机数字,有唯一性)和command(进程对应的程序名)
常用用法: ps -aux | grep 程序名 : 能够获取目标程序的进程 ID和command - kill -9 进程ID : 通过进程ID关闭对应程序(-9: 强制关闭)
- top : 可以调用 Linux 系统下的"任务管理器", 可以动态查看所有的进程信息。ps命令显示的是瞬时进程信息,但是进程是时刻在变化的。找某个值可以用ps,动态观察就不能用了。动态观察可以用top,出现的页面等价于Windows系统的任务管理器,按 ’ Q '或者ctrl + c结束top命令页面
案例6: 端口号信息的获取及操作命令(netstat/lsof)
在桌面上打开终端窗口, 执行如下操作:
1. 查看当前系统中开放的端口有哪些
2. 查看哪个程序正在使用 3306 端口(需要 root 用户权限)
01.netstat -anptu
02.su - //切换成root
123456 //在Linux系统下,密码输入没有任何提示,输入完成回车即可。root 用户密码: 123456
lsof -i:3306
端口号信息的获取及操作命令小结
- netstat -anptu : 可以获取当前系统的网络相关信息(可用来获取端口号信息,表中local address是地址:端口号。某些端口号具备固定用途,特定程序使用,比如:22是远程访问常用端口号;3306默认情况下是MySQL使用的端口号;80http协议的web服务;443https协议的web服务)
- lsof -i:端口号 : 查看占用某一端口的的程序名称及进程ID(需要 root 用户权限),获取到的信息里面command和PID的下面就是占用端口的程序名和进程Id。
可以通过 kill -9 进程ID 命令完成对端口占用程序的移除
案例7: 文件权限修改(chmod)
01. 在当前目录下创建文件 cm_demo
02. 查看文件当前权限状态
03. 使用字母法将文件权限修改为: 拥有者: 可读/用户组: 可写/其他用户:可执行
04. 使用数字法将文件权限修改为: 拥有者: 可读可写可执行/用户组:可读可写/其他用户:可写可执行
01.touch cm_demo
02.ls -l
03.chmod a=rwx demo 或 chmod u-r,g-w,o=x demo //原文件权限rw- rw- r--
04.chmod 763 cm_demo //rwx rw- -wx:763
02步骤结果图
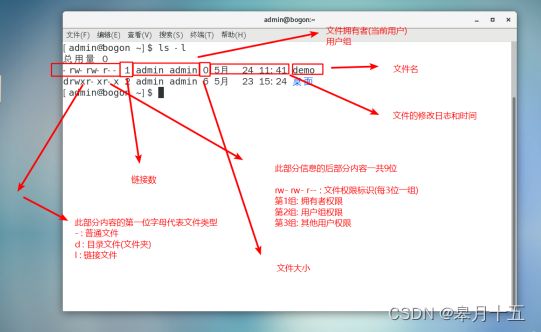
文件权限修改命令小结
- 权限:r:读取 w:写入 x:执行 -:无权限
- 权限修改: 命令格式: chmod 权限 文件名
- 字母法
-命令格式:chmod 权限 文件名
-组别代表字母: u:拥有者 g:用户组 o:其他人 a:以上所有
-赋权代表符号: +:增加 -:撤销 =:赋予
-权限代表字母 : r:读取 w:写入 x:执行
-权限修改部分不能有空格,多组权限使用逗号分隔 - 数字法
-权限对应的数字: r:4 w:2 x:1 -:0
-数字法基本格式:chmod 数字1数字2数字3 文件名。分别累加每一个组别的权限值之和, 再设置权限即可
-例如: rw- rw- r–当前文件权限用数字法显示就是664。 - 文件权限修改注意事项:
-权限修改可以反复执行, 如果未达到目的, 可以再次修改
-究竟使用字母法还是数字法完全看个人喜好
案例8: 系统操作相关命令(which/su/passwd/exit/who)
在桌面上打开终端窗口, 执行如下操作:
01. 查看 mysql 程序的存放位置
02. 从普通用户切换至 root 用户, 再从 root 用户切换回普通用户
03. 查看当前系统中所有登录用户的信息
04. 退出当前终端窗口
//桌面右键点击打开终端
01.which mysql //寻找可执行文件(.exe)
02.su -
123456
su - admin
03.who -u //user
04.exit
案例9: 查找文件(find)
在桌面上打开终端窗口, 执行如下操作:
01. 在路径下创建 adir,bdir 两个文件夹
02. 在 adir 目录下创建文件 f_demo
03. 切换路径到 bdir 目录下
04. 在当前目录下从 /home/admin 目录中查找 f_demo 文件
01.mkdir adir bdir
02.touch adir/f_demo //可以ls adir/查看是否成功创建,只要/没在最前面就写不写无所谓,系统也会自动补上。这种默认只能带一个文件名,也就是一次只能创建一个文件
03.cd bd ir
04.find /home/admin/ -name 'f_demo'
查找文件命令小结
find 路径 -name ‘目标文件名’ : 在给出的路径下查找目标文件
注意:
1.路径处可以使用绝对路径或相对路径
2.目标文件名处可以使用通配符(*/?/[])
案例10: 链接文件(ln -s)
在桌面上打开终端窗口, 执行如下操作:
01. 在当前路径下创建文件 demo
02. 给 demo 文件创建链接文件名为 ldemo
03. 修改 ldemo 链接文件的内容,查看 demo 文件的内容是否同样变化
04. 修改 demo 文件内容, 查看 ldemo 链接文件内容是否同样变化
01.touch demo
02.ln -s ~/demo ldemo
//ls -l 检查一下。应该多了文件名是蓝色,权限最前面不是-而且l的新文件
//rm demo
//ls ldemo变黑红
//ls -l ldemo变黑红,后面的路径信息不停闪烁,即源文件/文件夹被删除, 链接文件失效了
03.有变化
04.有变化
链接文件命令小结
ln -s 源文件/文件夹 链接文件名 : 给源文件/文件夹创建链接文件(也叫软链接,等价于Windows系统中的快捷方式)
注意:
- 源文件/文件夹最好给绝对路径(防止链接文件被移动位置后,相对位置找不着原文件,导致失效)
- 源文件/文件夹被删除, 链接文件会失效
- 扩展: ln 源文件/文件夹 链接文件名 : 硬链接(此处不做了解,用不上也不好理解)
案例11: 文件的压缩和解压操作(tar/gzip/bzip2/zip/unzip)
在桌面上打开终端窗口, 执行如下操作:
01. 在当前路径下创建 atdir,btdir 两个文件夹
02. 在 atdir 目录下创建 aa,bb,cc 三个文件
03. 分别用三种压缩方法对 atdir 目录进行压缩
04. 分别解压上一步产生的压缩包文件内容至 btdir 目录下
01.mkdir atdir btdir
02.cd atdir
touch aa bb cc
03.cd .. //因为我们本来在atdir里面,现在要对stdir进行压缩,所以我们先返回上一层再对atdir进行压缩
tar -zcvf atdir.tar.gz atdir/ //压缩包叫atdir.tar.gz
tar -jcvf atdir.tar.bz2 atdir/ //压缩包叫atdir.tar.bz2
zip -r atdir atdir //压缩包叫atdir.zip
04.//tar -zxvf atdir.+回车可以进行一个提示
tar -zxvf atdir.tar.gz -C btdir/
tar -jxvf atdir.tar.bz2 -C btdir/
unzip -d btdir atdir.zip
//后两次解压要把上一次的文件删除后再解压
文件的压缩和解压操作小结
- tar 和 gzip
打包和压缩: tar -zcvf 压缩包名.tar.gz 目标文件/文件夹
解包和解压: tar -zxvf 压缩包名.tar.gz
解压解包到指定解压位置: tar -zxvf 压缩包名.tar.gz 目标文件/文件夹 -C 解压位置文件夹
选项含义:
-z : gzip(压缩/解压) -j : bzip2(压缩/解压)
-c : 打包 -x : 解包 -v : 显示过程 -f : 指向文件
-C : 指定解压路径 - tar 和 bzip2
打包和压缩: tar -jcvf 压缩包名.tar.bz2 目标文件/文件夹
解包和解压: tar -jxvf 压缩包名.tar.bz2
解压解包到指定解压位置: tar -jxvf 压缩包名.tar.bz2 目标文件/文件夹 -C 解压位置文件夹 - zip 和 unzip
压缩: zip -r 压缩包名 目标文件/文件夹
解压: unzip -d 解压位置文件夹 压缩包名
案例12: vi 编辑器的使用
在桌面上打开终端窗口, 执行如下操作:
1. 使用快捷键 Ctrl + Alt + F2 切换系统至命令行模式
2. 根据提示依次输入用户名: admin 密码: ack123??
3. 在当前目录下利用 vi 命令创建文件 vi_demo 并打开
4. 修改 vi_demo 文件内容为: hello linux
5. 保存文件内容并退出 vi 模式
6. 查看 vi_demo 文件内容, 确认修改是否完成!
命令行模式 : Ctrl + Alt + F2 或 Ctrl + Alt + Fn + F2
图形化模式 : Ctrl + Alt + F1 或 Ctrl + Alt + Fn + F1
注意:
1. 如果鼠标丢失, 需要让虚拟机软件释放鼠标, 快捷键: Ctrl + Alt
2. 切换到命令行模式时, 需要先登录系统, 根据提示依次输入用户和密码即可
3. vi 文件名:如果文件存在, 则使用vi编辑器打开文件; 如果文件不存在, 则新建文件.(命令模式)
4. 按字母i键:从命令模式切换至插入模式(可以修改文件内容)
5. 正常编辑文件内容
6. 按下 Esc 键:从插入模式切换至末行模式
7. 输入 ':', 后跟 wq, 再按一个回车:保存文件内容并退出
//说明: w:写入 q:退出 !:强制操作(!q : 强制退出不保存) Ctrl+L:可以清空页面内容
注意: vi 工具只要求能够实现对文件内容就行修改并报错操作即可, 其他更多操作自行了解!
第三章 数据库
3.1 数据库概念
1)为什么学习数据库
- 软件中产生的所有数据, 最终都要存储于数据库当中
- 测试人员除了验证前端的功能逻辑以外,还要以数据库中确实存在数据做为最终结果验证。如果想要进行数据查询/数据校验, 就必须掌握对数据库的基本操作
2)数据库是什么?
- 定义: 用于存储数据的软件
- 特点: 表是数据存储的核心体现
3)数据库常见分类
- 关系型数据库(重点)
-
关系型数据库系统 RDMS:(Relational Database Management System):以数据表的形式存储数据, 便于数据查询。
-
常见的数据库代表
Oracle:在大型项目中使用,要花钱使用,例如:银行、电信等项目 MySQL:Web 项目中使用最广泛的关系型数据库,并不都要付费使用 Microsoft SQL Server:在微软的项目中使用 SQLite:轻量级数据库,主要应用在移动平台 -
关系型数据库的核心要素
数据行(一条记录) 数据列(字段) 数据表(数据行的集合) 数据库(数据表的集合,一个数据库中能够有 n 多个数据表)
-
- 非关系型数据库
- 不以数据表的形式存储数据的数据库类型
4)SQL
- SQL:Structured Query Language(结构化查询语言),通过SQL语言可以对数据库进行操作
- 特点: 所有主流的关系型数据库, 都支持使用SQL语句进行数据查询 !
- 注意: 虽然 SQL 语言分支很多, 但对于测试人员而言, 我们重点掌握查询操作即可!( 也就是掌握DQL:数据查询语言,用于对数据进行查询,例如:select)
- 在 MySQL 中,默认对 SQL 语法不区分大小写
5)MySQL 介绍
-
来源: 目前属于 Oracle 旗下产品, 目前只有社区版免费
-
特点: 开源, 支持多平台(Linux/Windows/macOS), 支持多语言(Java/C/Python…)
-
注意: 熟悉 SQL 和熟悉 MySQL 不是一回事儿(熟悉 SQL :熟悉 SQL 语言; 熟悉 MySQL: 用过 MySQL 数据库)
3.2 图形客户端
1)数据库的远程连接(重点)
注意: 实际工作中, 数据库是安装在服务器当中的, 如果要直连数据库进行数据校验, 就必须远程连接
-
连接步骤
- 获取两个信息: 服务器的 IP 地址;数据库的账号和密码(都找相关人员询问,直接用ipconfig不行)
- 在自己电脑上使用数据库连接工具(例如: Navicat), 建立连接, 远程连接数据库
- 连接过程中需要确认自己电脑和服务器是否能够正常通信(ping 命令)
-
注意事项:
- 使用的 MySQL 的账号密码虽也然是 root 和 123456, 但是和 CentOS 系统的 root 用户没有关系
- 如果第一次连接成功, 再次使用时, 提示 IP 地址问题, 则需要重新获取虚拟机系统的 IP 地址
- 使用过程中, 要更改系统设置,确保虚拟机系统不会待机或进入休眠状态。
2)Navicat 基本使用
- 连接只需要建立一次, 后续使用中, 可以通过’编辑连接’, 调整连接选项设置即可!以小桶图标表示的均为数据库,默认的四个数据库不要随意操作,可能会造成MySQL数据库错误,导致无法使用。
- 新建数据库名称不要用中文,字符集使用utf8防止中文乱码,排序选utf8_general_ci即系统默认推荐的排序规则。创建完成后不能重命名,只能更改字符集和排序规则。因此,创建时名称要慎重。
- 对哪个数据库操作就直接双击打开就ok了(变成绿色小桶),不用的一律关闭,防止误操作。
- 有时建完表,表并不显示,是因为延迟,点点其他选项,或者直接刷新就出来了。选定表,右键点击设计表,可以进行字段信息的添加和修改(注意:字段名都不建议使用中文名)
- 让表增加字段选择设计表,对表内容进行修改选择打开表。简单来说,打开表它是填入真实的数据,而设计表它是设计数据类型、取值范围、是否为空值、注释等等。
- 前面有*号,表示数据未保存。下面的+ - √ x(增加数据/删除数据/保存/不保存)如果选择清空表,只有数据会被清理,表头会被保留,也就是设计表部分不被清空。假如想全不要,直接删除表即可。
3)数据库的备份与还原(Navicat,重点)
测试过程中会产生垃圾数据, 测试结束时一般都需要还原原有数据, 因此需要在测试执行前先备份, 测试结束后执行还原
注意: 如果是测试工作中的备份与还原, 以下步骤对同一个数据库进行操作即可!
- 备份操作
- 要备份的数据库上鼠标右键 -> 转储SQL文件->假如保留字段名和数据选择结构和数据,只想保留字段名选仅字段
- 选择保存位置-> 提示成功关闭即可, 备份完成
- 还原操作
- 新建一个与备份数据库设置相同(数据库名不同,字符集和排序规则相同)的数据库
- 点击新建数据库,右键选择运行SQL文件,选择转存的SQL文件,点击开始即可
- 假如是测试结束后进行还原,不需新建,直接点击原测试数据库右键选择运行SQL文件,找到转存的SQL文件即可(上面的还原步骤更多应用在别人提供SQL文件,你进行测试的时候)
第四章 SQL语句
4.1 数据类型与约束
作用: 为了更加准确存储数据, 保证数据的有效性, 需要结合数据类型和约束来限制数据的存储
1)数据类型
- 整数:int,默认有符号,点选下方无符号即可变成无符号。有符号范围(-2147483648 ~2147483647),无符号范围(0 ~ 4294967295)
- 小数:decimal,例如:decimal(5,2) 表示共存5位数,小数占2位,整数占3位
- 字符串:varchar,范围(0~65533),例如:varchar(3) 表示最多存3个字符,一个中文或一个字母都占一个字符
- 日期时间:datetime,范围(1000-01-01 00:00:00 ~ 9999-12-31 23:59:59),例如:‘2020-01-01 12:29:59’
2)约束
- 主键(primary key):物理上存储的顺序
- 一般在设置主键时,往往会使用id作为字段名
- 主键设置一般要求:整数/无符号/自动递增/不能为空
- 当存在主键时,表中数据的物理顺序就被固定下来。当数据被清空时,新数据的顺序不会从1开始计数,而是从存入数据的顺序的下一位继续记录。能够保证数据在物理顺序是唯一的。
- 非空(not null):此字段不允许填写空值
- 惟一(unique):此字段的值不允许重复
- eg:身份证号码
- 在Navicat中设置约束唯一的步骤:点索引,点字段选择目标字段,点索引类型选UNIQUE,点保存。此时字段数据唯一,不允许在同一列中出现相同数据。
- 默认值(default):当不填写此值时会使用默认值,如果填写时以填写为准(设置默认值为字符串数据时,默认数据要加上英文符号的单引号’’,负责会报错不允许保存)
- 外键(foreign key):维护两个表之间的关联关系(现阶段先不涉及, 后边再进行扩展)
4.2 表操作
注意: SQL 语言重点是查询语句, 因此对表和数据的操作语句仅做了解, 主要是为了熟悉SQL语句的编写习惯
1)查询窗口的使用
- 查询窗口:可以编写所有的 SQL 语句
点击目标数据库,点击新建查询 - 运行方法1:直接运行
运行方法2:选中语句再运行,适用于多条语句 - 蓝色字体,多为SQL关键字(具备特定功能,有输入提示)(学习阶段应参照输入提示练习关键字的拼写)
黑色字体一般是自定义的字段(表名/字段名…) - 在MySQL中,建议每句SQL语句末尾都添加一个英文格式的分号,用于区分SQL语句,明确SQL语句结束位置。
- 点击保存,设置查询名点ok,就能在目标数据库查询下面找到刚刚保存的查询语句文件。点击文件右键选择在文件夹中显示,就会显示原文件在当前系统中的存储位置。
- 多行注释:选择目标行,使用快捷键ctrl + / 进行注释或反注释。
单行注释:在行首手动添加 ’ – '即可。
2)数据表
创表语句:
create table 表名(
字段1 类型,
字段2 类型 );
需求0: 创建商品表, 包含商品名称和价格
drop table if exists goods;
-- 优化
-- drop table : 删表 if exists : 如果存在
create table goods(
goodsName varchar(20),
price decimal(4, 2)
);
decimal(4, 2)
4是整数部分加小数部分的总长度。
2表示小数部分的位数,如果插入的值未指定小数部分或者小数部分不足则会自动补到2位小数,若插入的值小数部分超过了2位则会发生截断,截取前2位小数
创表语句如果重复执行,由于表已被创建,再次执行语句会出现报错提示。
所以加上drop table if exists goods; 进行优化。 如果表存在, 执行删除操作。能够避免表存在再反复执行时报错。
4.3 单表查询
需求1:创建商品表, 字段包括 id(主键), 商品名称, 价格, 数量, 公司,备注, 并添加商品
drop table if exists goods;
create table goods(
id int unsigned primary key auto_increment,
-- unsigned : 无符号
-- primary key : 主键(不为空)
-- auto_increment : 自动递增
-- 不用死记硬背,直接替换字段名使用即可
goodsName varchar(20),
price decimal(6,2),
num int,
company varchar(20),
remark varchar(30)
);
需求2 添加商品
添加一条数据的语法:insert into 表名 values(...)
select * from goods;
-- 查询,不用双击点开表看,直接会在下方结果处显示 (方便观察表中字段)
-- 添加1条数据
insert into goods values
(0, '战神笔记本', 6000.00, 100, '某东', '战神在手, 天下我有!');
-- 注意: 插入的数据个数与字段数必须匹配, 数据类型也需要对应
-- 主键列是自动增长,不用填值,但是插入时需要占位,通常使用0或者 default 或者 null 来占位
-- 插入多条数据
insert into goods values
(0, '小新笔记本', 5000.00, 100, '某东', '小新小新, 蜡笔小新!'),
(0, '外星人笔记本', 9999.00, 100, '某宝', '外星人上位, 战神渣渣!');
-- 注意: 插入多条数据, 每条数据使用逗点分隔即可
-- 扩展: 插入指定字段数据(了解)
insert into goods(goodsName) values('惠普游侠5');
-- insert into 表名(字段名) values(字段对应值)
--新插入一段数据,只有goodsName被赋值,其他全空
需求3:修改商品数据1条,,删除1条数据
select * from goods;
-- 先查询所有数据, 便于观察数据内容
-- 补充惠普电脑的数据
update goods set price=4500.00,num=50,company='并夕夕' where id=4;
-- 注意: 修改数据时, 为保证修改准确性, 务必要给出限定条件(where)
-- 修改数据不指定条件
update goods set price=4500.00,num=50,company='并夕夕';
-- 所有数据全部被修改
需求4: 删除一条数据
语法格式 : delete from 表名 where 条件
select * from goods;
delete from goods where id = 4;
-- 注意: 如果要删除执行数据, 务必给出限定条件, 否则会删除所有数据!
扩展1:逻辑删除
- 对于一些重要数据(例如:商品数据只是库存为零,不能删除商品数据),不能直接删除,此时使用逻辑删除。逻辑删除:通过特定字段值来标记该数据为删除状态。
- 实现步骤:
1) 增加特定字段,数据值1为未删除,0为删除。
2)对于要进行逻辑删除的数据,该字段赋值为0即可。 - 增加字段:alter table 表名 add 字段名 类型;
-- 增加标记字段
alter table goods add isdelete int;
-- 更新表内所有数据该字段的值
update goods set isdelete = 1;
-- 标记目标数据为是删除状态(修改该字段值为0)
update goods set isdelete = 0 where id = 2;
-- 查询未删除的数据
select * from goods where isdelete = 1;
扩展2:3种删除数据方法(所有数据)
- delete from 表名 : 清空表数据(只清空数据,保留结构), 但不会重置主键计数
truncate table 表名 : 清空表数据(只清空数据,保留结构), 并会重置主键计数(截断表)
drop table 表名 : 删除表, 包括表结构和数据 - 删除速度 : drop > truncate > delete
delete from goods;
truncate table goods;
drop table goods;
需求5:准备商品数据, 查询所有数据, 查询部分字段, 起字段别名, 去重
select * from goods;
-- 查询所有数据 : select * from 表名;
select goodsName,price from goods;
-- 查询部分字段
select goodsName as '商品名称',price as '价格' from goods;
-- 起别名 : 使用 as 关键字, 后跟别名即可
select goodsName '商品名称',price '价格' from goods; -- 熟练之后 as 关键字可以省略
select goodsName 商品名称,price 价格 from goods; -- 中文别名引号可以省略
select distinct(company) from goods;
-- 去重 : 根据所给字段, 将字段中数据相同数据合并保留一个
-- 需求 : 当前表当中有几家公司
需求6:查询价格等于30并且出自并夕夕的所有商品信息(比较运算符 / 逻辑运算符)
select * from goods;
select * from goods where price = 30;
-- 比较运算符:>=大于等于 <=小于等于 <>和!=不等于
select * from goods where price = 30 and company = '并夕夕';
-- 逻辑运算符 and:并列条件 or:或
-- 注意 : 在 where 关键后侧的字符串数据, 必须给引号, 否则会报错
需求7:查询全部一次性口罩的商品信息(模糊查询)
语句格式 : where 字段 like ‘%信息’
select * from goods;
select * from goods where remark like '%一次性口罩';
-- % 匹配任意的多个字符
-- 以一次性口罩结尾, 前面内容不限制
select * from goods where remark like '%一次性口罩%';
-- 优化:由于目标信息可能出现在中间部分
-- 扩展: 查询公司来源是 x宝 的商品信息内容
select * from goods where company like '_宝';
-- _ : 匹配任意单个字符
需求8:查询所有价格在30-100的商品信息 (范围查询)
条件查询-范围查询 : between 起始值 and 结束值 : 表示一个连续的范围(注意: 范围应该从小到大)
select * from goods;
select * from goods where price between 30 and 100;
-- select * from goods where price between 100 and 30; -- 查询不出数据
-- 扩展: 来自 某东 和 x宝 商品信息
select * from goods where company in ('某东', 'x宝');
-- 条件查询-范围查询 : in (条件1, 条件2, ...): 表示在某个不连续范围内
需求9:查询没有描述信息的商品信息(空判断)
判断空 : is null
select * from goods;
select * from goods where remark is null;
-- 注意 : null 与 '' 不是一码事; null : 空; '': 空字符(例如:空格/制表符(tab))
-- 扩展 : 查询以下数据中描述信息不为空的所有商品数据
select * from goods where remark is not null;
-- not : 表示对条件取反; not null : 双重否定表示肯定
需求10:查询所有商品信息, 按照价格从大到小排序, 价格相同时, 按照数量少到多排序
排序 : order by 字段名 asc(升序)/desc(降序)
select * from goods;
select * from goods order by price desc, count asc;
-- 扩展:
select * from goods order by price desc, count;
-- 默认情况下 order by 是以升序进行排列,因此 asc 可以省略
需求11:查询以下信息: 商品信息总条数; 最高商品价格; 最低商品价格; 商品平均价格; 一次性口罩的总数量(聚合函数)
聚合函数:SQL 提前准备好的一些方法,具备特定功能。
数据总数:count ( ) ; 最大值:max ( ) ;最小值:min ( ) ;平均值:avg ( ) ; 求和:sum ( ) 。
select * from goods;
select count(*) from goods;
-- goods有几列。按数据最多的那列计算,一般按是主键个数。
select count(remark) from goods;
-- 可能会漏数据,空数据不计算在内
-- 注意: 统计数据总数时, 推荐使用 *
select max(price) from goods;
select min(price) from goods;
select avg(price) from goods;
select * from goods where remark like '%一次性口罩%'; -- 先获取所有一次口罩的数据,再查询
select sum(count) from goods where remark like '%一次性口罩%';
需求12 : 查询每家公司的商品信息数量(分组)
分组 : group by 字段 : 可以根据给出的字段数据进行数据分组
select * from goods;
select company 公司名称,count(*) from goods group by company;
-- 公司名和在对应公司平台上的商品个数
-- 注意:+一般情况下, 分组会配合聚合函数一起使用, 目的是对分组后的数据进行进一步统计
-- 扩展 : 查询某东和x宝最贵商品的价格
select company 公司名称 from goods group by company;
-- 按照公司分组
select company 公司名称 from goods group by company having company != '并夕夕';
-- 把并夕夕的数据排除掉。如果想在分组后再次进行条件筛选, 可以使用 having 关键字。
select company 公司名称, max(price) from goods group by company having company != '并夕夕';
-- 获取公司商品最贵价格
扩展:
对比 where 与 having
- where 是对 from 后面指定的表进行数据筛选,属于对原始数据的筛选
- having 是对 group by 的结果进行筛选
- having 后面的条件中可以用聚合函数,where 后面不可以
需求 13:查询当前表当中第5-10行的所有数据(分页查询)
当数据量过大时,在一页中查看数据是一件非常麻烦的事情
语法:select * from 表名 limit start,count
从起始索引start开始,获取数据行数count条数据。索引从0开始。
select * from goods;
select * from goods limit 4, 6;
-- 获取当前数据中的第1行数据。
-- select * from goods limit 0, 1;
-- 扩展 : 如果获取是当前数据中的第1行数据时, 起始索引可以省略。
select * from goods limit 1;
-- 分页查询公式
-- 每页显示 m条数据,求:显示第 n页的数据
-- 公式:select * from students limit (n-1)*m,m
-- 假设:当前数据中,每页显示 3条数据,查看第 2页数据内容
select * from goods limit 3, 3;
4.4 多表查询
1)连接查询
- 内连接 : 查询的结果为两个表匹配到的数据。显示两张表中存在对应关系的数据, 无对应关系的数据不显示。
-
语法:select * from 表1 inner join 表2 on 表1.列=表2.列
需求1: 查询所有存在商品分类的商品信息
select * from goods;
select * from category;
-- 在查询中, 需要将两张表存在对应关系的数据全部显示出来时, 需要使用连接查询-内连接
select * from goods inner join category on goods.typeId = category.typeId;
-- 对连接后的表进行字段显示限制
-- 注意: 需要由对应的 表名.字段 的方式实现(防止表与表之间存在相同的字段名)
select goods.goodsName, category.cateName from goods inner join category on goods.typeId = category.typeId;
-- 表名.* : 代表显示该表的所有字段
select goods.*, category.cateName from goods inner join category on goods.typeId = category.typeId;
select go.goodsName, ca.cateName from goods go inner join category ca on go.typeId = ca.typeId;
-- 连接查询中, 往往会给表名起别名, 目的: 1) 缩短表名 2) 给表单独创建空间(了解)
-- from goods go(go就是goods的别名);inner join category ca(ca是category的别名)
- 左连接 : 以 left join 关键字为界, 关键字左侧的表的信息要全部显示出来, 而关键字右侧表的信息, 有对应的部分显示, 无对应的部分以 null 占位填充即可
-
语法 : 表1 left join 表2 on 表1.字段 = 表2.字段
需求2:查询所有商品信息,包含商品分类 及查询所有商品分类及其对应的商品的信息(左连接)
select * from goods;
select * from category;
select * from goods go left join category ca on go.typeId = ca.typeId;
-- 内连接中,只显示有对应部分的数据,所以使用内连接会出现10个数据,而使用左连接会出现12个数据。
select * from category ca left join goods go on ca.typeId = go.typeId;
- 右连接 : 以 right join 关键为界, 关键字右侧的表的信息要全部显示出来, 而关键字左侧表的信息, 有对应的部分显示, 无对应的部分以 null 占位填充即可。
- 主要解决3张及以上表进行连接查询,已经进行了多个表的连接,突然又多出来一张表,并且需要以新表为主表才需要使用右连接。
- 左右连接:主表数据是全的,假如没有对应主表的连接数据,则其他数据全为null。内连接,只要对应不上,全为null直接不显示。
-
语法 : 表1 right join 表2 on 表1.字段 = 表2.字段
需求3:查询所有商品信息,包含商品分类及查询所有商品分类及其对应的商品的信息(右连接)
select * from goods;
select * from category;
select * from category ca right join goods go on ca.typeId = go.typeId;
select * from goods go right join category ca on go.typeId = ca.typeId;
内连接和左右连接的小结

- 连接操作实质: 只是将分布于多张表的数据, 通过连接的方式进行整理, 形成数据源。
- 连接操作完成后, 之前的所有的查询语法, 都可以继续使用。
需求4:显示所有价格低于 120 的商品信息, 包含其对应商品分类
select * from goods;
select * from category;
select * from goods go
inner join category ca on go.typeId = ca.typeId
where go.price < 120;
-- 内连接 : 如果有商品没有分类对应信息, 不会被显示出来
-- 注意 : 如果使用内连接, 会造成数据缺失, 查询结果错误
select * from goods go
left join category ca on go.typeId = ca.typeId
where go.price < 120;
-- 所以使用左连接
- 自关联:只有 1 张表, 表中最少存在两列字段具备对应关系
- 原理 : 通过起别名的方式, 将 1 张表变为 2 张表, 通过对应字段的对应关系, 进行条件比对, 实现连接查询
- 通过起别名的方式, 将一表变俩表
通过 表1.字段 = 表2.字段 实现表间关联
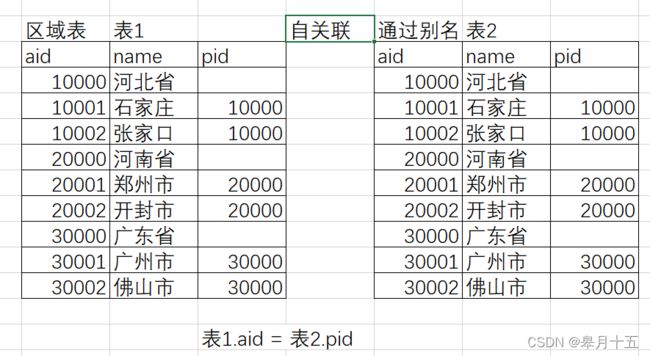
需求5:查询河南省所有的市(自关联)
select * from areas;
select * from areas a1
inner join areas a2 on a1.aid = a2.pid
where a1.atitle = '河南省';
需求6:查询河南省的所有的市和区(自关联 强化)
select * from areas;
select * from areas a1
inner join areas a2 on a1.aid = a2.pid
left join areas a3 on a2.aid = a3.pid
-- 使用inner join 会损失数据
where a1.atitle = '河南省';
2)子查询
- 定义 : 在一条查询语句当中, 利用另一条语句作为条件或数据源, 充当条件或数据源的语句称之为子查询语句。
- 注意 : 子查询语句在使用时, 务必使用括号括起来
需求7:查询价格高于平均价的商品信息(子查询-充当条件)
select * from goods;
select avg(price) from goods;
-- 查询平均价格 68.33
select * from goods where price > 68.33;
select * from goods where price > (select avg(price) from goods);
-- 在 where 关键字后边的子查询语句是充当条件的
需求8:查询所有来自并夕夕的商品信息, 包含商品分类(子查询-充当数据源)
select * from goods;
select * from category;
select * from goods where company = '并夕夕';
select * from category ca
inner join (select * from goods where company = '并夕夕') a on ca.typeId = a.typeId;
-- 在 from 和连接查询关键字后边的子查询语句是充当数据源的
扩展1 : 子查询的分类
根据子查询语句返回的结果形式体现, 子查询共分为 4 类:
子查询返回的结果是一个值(一行一列), 称之为: 标量 子查询
子查询返回的结果是一列数据(一列多行), 称之为: 列 子查询
子查询返回的结果是一行数据(一行多列), 称之为: 行 子查询
子查询返回的结果是多行多列(相当于一张表), 称之为: 表级 子查询
扩展2 : 子查询关键字(in、some/any、all)
需求 : 查询在25-100之间的商品的价格
select price from goods where price between 25 and 100;
-- 查询在25-100之间的商品的价格
select * from goods where price in (25, 30, 77, 30, 72,25);
-- in : 范围
select * from goods where price in (select price from goods where price between 25 and 100);
select * from goods where price = some(select price from goods where price between 25 and 100);
select * from goods where price = any(select price from goods where price between 25 and 100);
-- some/any : 任意一个
-- some/any和in 效果一样
select * from goods where price = all(select price from goods where price between 25 and 100);-- 无结果,price不可能即=25又=72。
select * from goods where price != all(select price from goods where price between 25 and 100);
select * from goods where price <> all(select price from goods where price between 25 and 100);
-- all : 全部(= all : 等于所有; != 或 <> all : 不等于所有)
第五章 数据库高级概念
不需要熟练操作,这部分内容作为了解,对于未来的工作是加分项。
5.1 E-R模型
- E-R模型的基本元素是:实体、联系和属性
- E 表示 entry,实体:一个数据对象,描述具有相同特征的事物
- R 表示 relationship,联系:表示一个或多个实体之间的关联关系,关系的类型包括包括一对一、一对多、多对多
- 属性:实体的某一特性称为属性
5.2 外键
- 如果一个实体的某个字段指向另一个实体的主键,就称为外键。
- 被指向的实体,称之为主实体(主表),也叫父实体(父表)。
负责指向的实体,称之为从实体(从表),也叫子实体(子表) - 作用: 对关系字段进行约束,当为从表中的关系字段填写值时,会到关联的主表中查询此值是否存在,如果存在则填写成功,如果不存在则填写失败并报错。
- 填写成功后,删除对应主表中数据会报错,因为他在从表中已经被引用了(就像删除文件夹时,假如里面某个文件正在运行,停止删除操作并弹出错误提示)。
foreign key(自己的字段名)) references 目标表名(目标表的主键)
-- 主表
drop table if exists class;
create table class(
id int unsigned primary key auto_increment,
name varchar(10)
);
-- 从表
drop table if exists stu;
create table stu(
name varchar(10),
class_id int unsigned,
foreign key(class_id) references class(id)
-- stu 表的 class_id 指向 class 表的 id, id是class表的主键,class_id 是 stu 表的外键
);
扩展1 : 对已经存在的表添加外键
alter table 从表名 add foreign key (从表字段) references 主表名(主表主键);
drop table if exists class;
create table class(
id int unsigned primary key auto_increment,
name varchar(10)
);
drop table if exists stu;
create table stu(
name varchar(10),
class_id int unsigned
);
alter table stu add foreign key (class_id) references class(id);
扩展2 : 查看和删除外键
show create table 表名,将结果复制粘贴到代码段,就可明显看出外键名称。
也可点击从表右键,点击设计表,选择外键,就能看到系统自动生成的外键名称。
alter table stu drop foreign key 外键名称;删除外键
show create table stu;
-- 显示stu表的信息,结果如下:
-- CREATE TABLE `stu` (`name` varchar(10) DEFAULT NULL,`class_id` int(10) unsigned DEFAULT NULL,KEY `class_id` (`class_id`),CONSTRAINT `stu_ibfk_1` FOREIGN KEY (`class_id`) REFERENCES `class` (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8
-- stu_ibfk_1就是外键名称
alter table stu drop foreign key stu_ibfk_1;
结论 : 由于设置外键会极大降低对数据修改效率, 因此在实际工作中遇到使用外键的几率比较低
5.3 索引
定义: 类似于图书中的目录, 能够起到快速检索数据的作用
作用: 对于大量数据进行查询效率优化时, 可以采取添加索引的策略
set profiling=1;
-- 开启时间监测
select * from test_index where num = 10000;
-- 查询示例数据 num = 10000 的值
show profiles;
-- 查看运行时间
create index num_index on test_index(num);
-- 对已存在的表添加索引:create index 索引名称 on 表名(目标字段)
select * from test_index where num = 10000;
-- 再次执行查询数据操作
show profiles;
-- 再次查看运行时间
--添加索引前查询的用时大概是添加索引后查询用时的10倍
扩展1: 查看索引名
show index from 表名
主键也能起到索引作用,所以也会显示出来。
show index from test_index;
扩展2 : 创表时添加索引
create table create_index(
id int primary key,
name varchar(10) unique, -- unique : 设置端唯一值,因为是唯一值所以name也算是索引
age int,
key(age) -- 指定添加索引方法
);
show index from create_index;-- 查看索引,显示结果是三个:id、name和age。
扩展3 : 删除索引
drop index 索引名称 on 表名;
drop index age on create_index;
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
但是,在互联网应用中,查询的语句远远大于增删改的语句,甚至可以占到80%~90%,所以也不要太在意,只是在大数据导入时,可以先删除索引,再批量插入数据,最后再添加索引
5.4 命令行中操作 MySQL
前提: 要进行操作的系统环境中, 存在 MySQL 环境
登录 MySQL
mysql -u数据库用户名 -p数据库密码
例如:
mysql -uroot -p123456
数据库操作
查看所有数据库 : show databases;
使用数据库 : use 数据库名称;
查看当前使用的数据库名称 : select database();
创建数据库 : create database 数据库名称 charset=utf8;
删除数据库 : drop database 数据库名称;
数据表操作
查看数据库中的所有数据表 : show tables;
查看表字段信息 : desc 表名;
查看创表语句 : show create table 表名;
注意:进入到数据库之后, 所有的 SQL 查询语句,均可以正常使用!如果SQL语句编写错误,可以使用exit退出。
5.5 存储过程
定义:可以叫存储程序, 通过一定的代码逻辑, 将一句或多久SQL语句进行封装, 通过调用存储过程, 快速实现其内部封装SQL语句操作
用途:可以用来向数据库中, 快速插入大量测试数据时使用
基本语法格式
delimiter //
create procedure 存储过程名称(参数列表)
begin
sql语句
end//
delimiter ;
- delimiter是mysql分隔符,在mysql客户端中分隔符默认是分号(;)如果一次输入的语句较多,并且语句中间有分号,这时需要新指定一个特殊的分隔符。
- 运行后会多出来一个名为test的函数,此时并不会运行。后面再查询窗口,直接使用call调用即可。
- delimiter,我个人认为是标明一段代码的起始和终止,分辨识别。
调用方法
在查询窗口中,call 存储过程名();
call test();
语法实现
delimiter //
-- 修改句尾标识符为'//'
drop procedure if exists test;
-- 如果存在 test 存储过程则删除
create procedure test()
-- 创建无参数的存储过程 test
begin
declare i int;
-- 声明变量 i
set i = 0;
-- 变量初始化赋值为 0
while i < 10000 do
-- 设置循环条件: 当 i 大于 10 时跳出 while 循环
insert into datatest values (null, i);
-- 往 datatest 表插入数据
set i = i + 1;
-- 循环一次, i 加一
end while;
-- 结束 while 循环
select * from datatest;
-- 查看 datatest 表数据
end//
-- 结束存储过程定义语句
delimiter ;
-- 恢复句尾标识符为';'
5.6 事务
事务广泛的运用于订单系统、银行系统等多种场景
例如:A用户和B用户是银行的储户,现在A要给B转账500元,那么需要做以下几件事:
1.检查A的账户余额>500元;
2.A 账户中扣除500元;
3.B 账户中增加500元;
正常的流程走下来,A账户扣了500,B账户加了500,皆大欢喜。那如果A账户扣了钱之后,系统出故障了呢?A白白损失了500,而B也没有收到本该属于他的500。以上的案例中,隐藏着一个前提条件:A扣钱和B加钱,要么同时成功,要么同时失败。
事务的需求就在于此定义 : 所谓事务可以称之一个操作序列, 一系列操作要么都执行, 要么就不执行. 对于数据库来讲, 对于数据的操作行为, 要么都实现, 要么都不实现, 最终需要确保写入到数据库的数据的一致性(原子性)!
事务实现案例
前提: 数据表的数据引擎类型必须是 InnoDB (可以通过查看创表语句来确认)
-- 注意 : 触发事务操作一般是由修改数据操作产生(插入数据insert/更新数据update/删除数据delete)
begin;-- 开启事务
commit;-- 提交事务
rollback;-- 回滚事务
案例实现步骤
1. 开启两个终端窗口(A窗口操作/B窗口查询)
2. A 窗口 begin 开启事务, 执行修改数据操作
3. B 窗口查询数据(此时B看不到A的修改结果)
4. A 提交事务 commit
5. B 再次查看(可以见到A的修改结果)
6. A 再次开启事务, 执行修改数据操作
7. A 执行回滚事务 rollback,修改数据操作被撤销
8. B 查看不到A的修改操作结果
5.7 视图
- 场景 : 能够封装 SQL 语句, 以类似于表的形式存在。视图本质就是对查询的封装,当成表查询使用即可。
- 视图命名一般以 v_视图名称,因为在命令行下,输入show tables;后,视图和数据表是一起显示的,以v_开头更好区分。
- 形式实现:create view 视图名称 as select 语句;
- 视图只是表,不能知道全部的原数据和具体查询语句,可以起到隐藏真实数据表内容的作用
视图基本使用
create view v_goods as select goodsName 商品名称, price 价格, num 数量, company 公司 from goods;
-- 把goods的四个属性提出来单做个视图并且起别名。
select * from v_goods;
-- 复杂 SQL 语句视图封装
select go.goodsName, ca.cateName from goods go inner join category ca on go.typeId = ca.typeId;
create view v_goods_cate as select go.*, ca.id 序号, ca.typeId 类型, ca.cateName from goods go inner join category ca on go.typeId = ca.typeId;
-- 封装连接查询语句时, 如果存在重名字段名称, 需要通过别名进行修改
select * from v_goods_cate;
-- 删除视图语句:drop view 视图名称
drop view v_goods_cate;
5.8 修改 MySQL 数据库密码
场景 : 遗忘数据库密码时使用
1) 修改数据库配置文件, 使之登录不需要密码
此操作需要具备服务器 root 账户权限
- 查找配置文件并修改
su - //切换 root 用户
locate my.cnf //定位配置文件位置,获取到配置文件地址为/etc/my.cnf
vi /etc/my.cnf //使用 vi 工具打开配置文件
skip-grant-tables //在文件内容 [mysqld] 下方回车后添加此内容, esc+:wq回车保存退出即可。
cat /etc/my.cnf //使用cat命令查看配置文件是否修改
- 重新启动 MySQL 服务
systemctl restart mysqld //重启完成可以通过查看状态命令进行验证
systemctl status mysqld //查看MySQL服务状态
mysql -uroot -p //重新输入mysql -uroot -p验证,此时发现不输入密码也可以登陆
2)登录数据库, 修改数据库账户密码
注意 : 本步骤为 SQL 语句, 需要在 mysql > 状态下执行
use mysql; -- 选择 mysql 数据库
-- 更新密码
-- update user set authentication_string=password('新密码') where user = '用户名';
update user set authentication_string=password('123') where user = 'root';
-- 注意 : authentication_string 字段名需要根据 MySQL 版本就行对应修改
flush privileges;-- 刷新权限
3)还原配置文件设置, 使之登录需要密码
还原配置文件设置与添加设置步骤基本相同
- 查找配置文件并修改
su -
locate my.cnf
vi /etc/my.cnf
# skip-grant-tables //使用 # 注释掉下方内容, 防止下次再次使用还需书写,保存后退出
- 重新启动 MySQL 服务
systemctl restart mysqld
systemctl status mysqld
- 重新使用修改后的密码登录 MySQL 即可
5.9 MySQL 日志的获取
注意 : MySQL 自带日志功能, 但是开启日志功能, 极其消耗数据库性能, 因此默认情况下是不开启的show variables like 'general%';-- 查看日志功能是否开启,获取对应日志文件位置。
set global general_log = 1;-- 开启操作
su-
cat 日志文件地址
-- 在MySQL中操作,使用root用户权限,获取日志文件
set global general_log = 0;-- 关闭操作
-- 注意: 日志功能使用完成, 需要记得马上关闭, 避免影响数据库性能!!!!!!