MySQL
目录
1. SQL语言分类:
2.单表查询:
3.多表查询:
4.事务
5.索引
二叉树
平衡二叉树
红黑树:
B树
索引分类
sql常用语句:
1.联合查询
2.从一个表复制到另一个表
3.SQL查询中选取某个字段的前几个字符
4.SQL查询多字段结合
5.SQL一次性查询一个字段不同条件下的统计结果
6.IF()函数使用
1. SQL语言分类:
DDL:数据定义语言,用于创建数据库对象,如库、表、索引等
DML:数据操纵语言,用于对表中的数据进行管理
DQL:数据查询语言,用于从数据表中查找符合条件的数据记录
DCL:数据控制语言,用于设置或者更改数据库用户或角色权限
2.单表查询:
分组查询;select from where(分组前条件) group by having(分组后条件)
where不能执行聚合函数 having可以
select from where(分组前条件)like name=“_n%”
排序查询 :select *from 表 order by 字段 asc(升序可省略),字段 desc(降序),
分页查询 select *from limit 起始(页面-1*每页记录,0开始可以省略不写),每页数值;
3.多表查询:
多表关系
一对一:任意一方加入外键 指向另一个表的主键 并设置外键唯一;
一对多:在多的一方建立外键,指向另一方的主键
多对对:建立第三张表,至少两个外键 指向两张表的主键
一对一经常做单表拆分,提升效率;
内隐式连接
select from 表1,表2where
内连接 显式内连接
select from 表a (inner) join 表b on条件;

左外连接
select from 表a left(outer) join 表b on 条件;
右外连接
select 字段 from 表a right (outer) join 表b on 条件;
左右查询可以互换 right 换 left 表a和表b换位置;
4.事务
是一组操作的集合,不可分割的工作单位,作为一个整体提交请求,要么同时成功,要不同时失败;
事务开启 start transaction /begin set @autocommit=0;
查询 ;修改;提交 commit
事务回滚 rollback;
ACID ;
原子性:事务是不可分割的最小单位
一致性:事务完成时数据保持一致的状态
隔离性:数据库的隔离机制,保证事务在独立环境下运行,不受外部并发操作影响;
持久性:事务提交或回滚,对数据库的改变是永久的;
并发事务:
脏读;select、 读取到别的事务还没有提交的事务;
不可重复读; select select 读取同一事务,两次读取的数据不同;
幻读;select insert select 解决了不可重复读的问题,insert 提交其实是失败的,
查询时没有对应的数据,提交时,数据已经存在。
事务隔离级别
read uncommited;脏读不可重复读幻读
read commited;不可重复读幻读
repeatable read ;幻读
serializable;串行化 都不会
5.索引
索引 是一种数据结构,帮助数据库高效的获取数据; 无索引全表扫描;
优缺点:索引是一种数据结构,占用空间,会提高检索效率,会降低更新表的效率
http://t.csdn.cn/xRcQo
二叉树
①根节点的值大于左子树的任意一个节点值,根节点的值小于右子树任意一个节点的值
②查找添加删除的时间复杂度都是O(n)
顺序插入时会形成一个单向链表
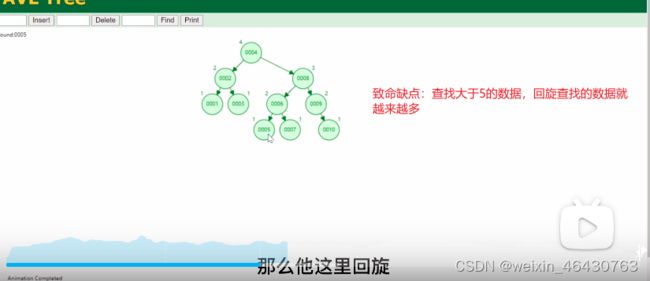
平衡二叉树
①左右子树高度相差不能超过1,查找添加删除的时间复杂度都是O(lgN)
缺点:大数据的情况下,层级较深,随着树越高,查找速度越来越慢。

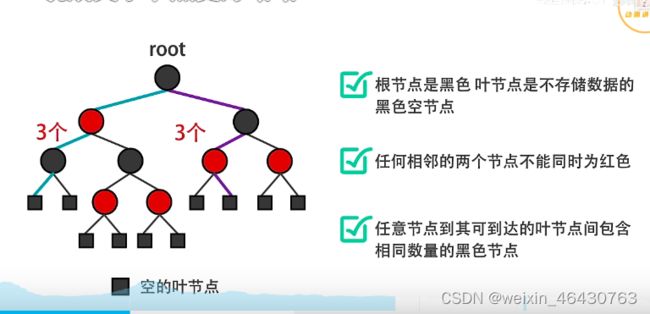
红黑树:
①根节点是黑色的。叶节点是黑色空节点,不存储数据
②任意两个节点都不是红色的
③任意节点到其叶子节点的黑色节点数量相同
B树
①非叶子节点的个数(索引值)等于子节点-1,最小是M/2 -1,最大M-1,
②所有叶子节点都在同一层

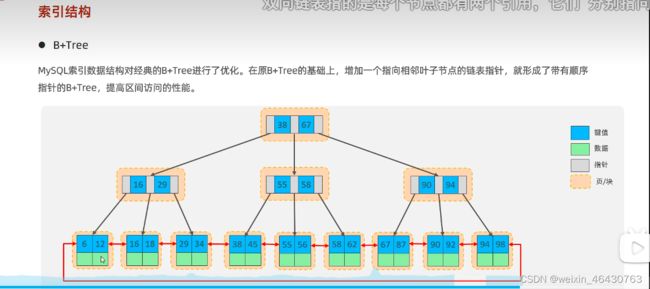
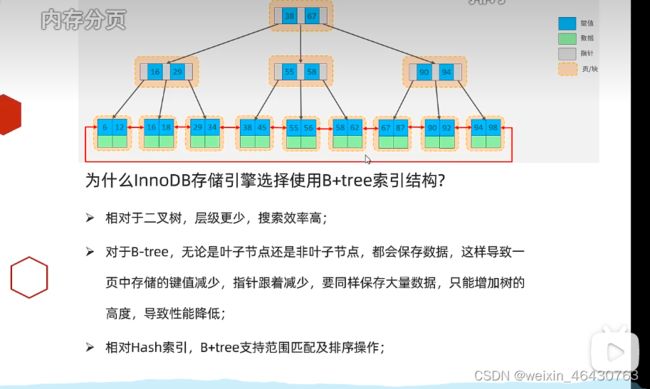
1.什么MySQL的索引要使用B+树而不是其它树形结构?比如B树?
因为B树(多路平衡查找数)不管叶子节点还是非叶子节点,都会保存数据,这样导致一页内存储的键值和指针都减少,
指针少的情况下要保存大量数据,只能增加树的高度,查询性能变低;
B+树①内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log n。
②为所有叶子结点增加了一个链指针 叶子节点形成单项链表;
Mysql对B+树进行了优化,增加了一个指向相邻叶子节点的指针,数据是以页的形式进行存储,页内数据确实是单向链表,页间(数据页和目录页)都是双向链表。
B-树允许每个节点有更多的子节点即可(多叉树)
所以一般B+树的叶节点和内节点大小不同,而B-树的每个节点大小一般是相同的,
hash索引:
哈希表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即key,即可查找到其对应的值。
当我们在mysql中用哈希索引时,主要就是通过Hash算法(常见的Hash算法有直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表的对应位置;


索引分类


主键 primary
唯一unique
创建索引:
creat unique/full text index 索引名 on 表;
表锁 行锁

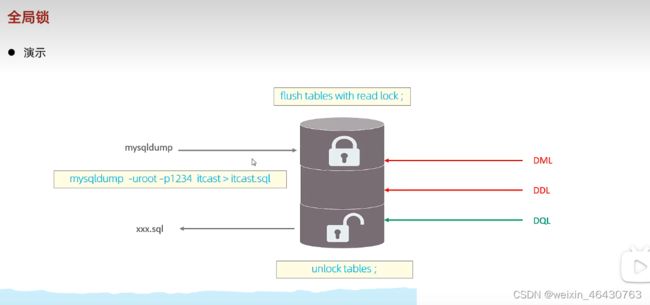

加锁:lock tables 表明 read/write
释放;unlock tables;

行锁:锁定单行记录
事务A获取了数据的共享锁s,那么事务B也可以获取数据的共享锁s
事务A获取了数据的排他锁X,那么其他事务就不可以获取事务的共享锁和排他锁。
 进行增删改默认是排他锁,查询默认没有锁;
进行增删改默认是排他锁,查询默认没有锁;
sql常用语句:
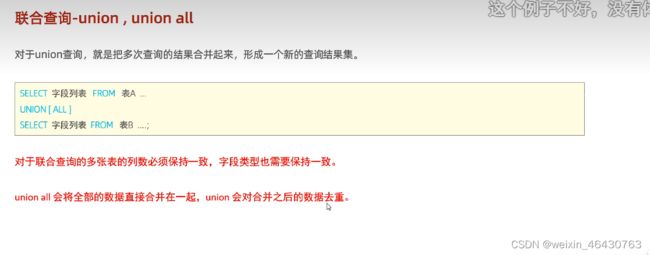
1.联合查询
对表中的数据进行限制;

2.从一个表复制到另一个表
SELECT INTO 将数据复制到一个新表(有的 DBMS 可以覆盖已经存在的表,这依赖于 所使用的具体 DBMS)
SELECT *(字段) INTO CustCopy FROM Customers;
INSERT SELECT 将数据添加到一个已经存在的表不同
3.SQL查询中选取某个字段的前几个字符
left(col_name,N),其中col_name为列名,N为左起前N个字符
subString
4.SQL查询多字段结合
A||B||'-'||C concat(A,'-',B)
5.SQL一次性查询一个字段不同条件下的统计结果
IFNULL(select a from tab where a='1',''),IFNULL(select a from tab where a='2','')
6.IF()函数使用
