WebRtc中的AEC算法2
理论
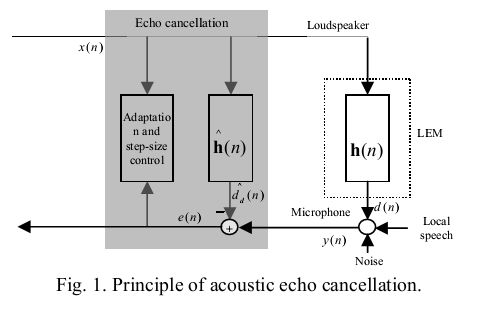
回声消除器的数学模型图
回声消除本质上就是把输出信号和它产生的回声信号之间建立一个回声数学模型,利用开始的数据训练这个模型的参数,怎么训练呢?
就是在远端有说话,但近端没有说话的时候,录音应该是静音,即回声完全消除。所以算法就朝着这个方向努力,一旦回声为0,则滤波器收敛。自适应滤波器算法多种多样,但是目前流行的还是最经典的LMS和NLMS,NLMS是LMS的优化 。
判断标准:收敛速度快,运算复杂度低,稳定性好,失调误差小
LMS算法
实际应用中,很多时候无法预先得知信号和噪声的统计特性,这时候就用得着自适应滤波器了
常用的自适应滤波技术:LMS(最小均方)自适应滤波器,递推最小二乘(RLS)滤波器,格型滤波器,无限脉冲响应(IIR)滤波器。顾名思义,LMS是使得滤波器的输出信号和期望响应之间的误差的均方值最小,也就是求一个梯度。
WebRtc中的AEC算法属于分段快频域自适应滤波算法,Partioned block frequeney domain adaptive filter(PBFDAF)。
判断远端和近端是否说话的情况,又称为双端检测,需要监测以下四种情况:
1. 仅远端说话, 此时有回声,要利用这种状态进行自适应滤波器的系数更新,尽快收敛
2. 仅近端说话, 这种时候是没有回声的,不用考虑
3. 双端都在说话(Double Talk),此时系数固化,不进行系数更新
4. 双端都没有说话,这时候可以挂电话了。。。这时候需要启用近端VAD
远端需要一个VAD;在远端有声音的时候,近端即时不说话也有回声,所以VAD没什么用,只能是使用一个DTD(double talk detection)。
跟静音检测绑定在一起的技术是舒适噪声生成,这个在VOIP,phone中用的比较广泛,但是在ASR中无需使用。 据估算,运用语音活动检测及舒适噪音生成可将一组音频信道对带宽的需求降低50%。
目前常用的DTD算法有两种:
- 基于能量的,比如Geigel算法,基本原理就是检测近端的信号强度如果足够大的话,就判断有人说话。
- 基于信号相关性的,使用一些相关性算法,比如余弦相似性。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
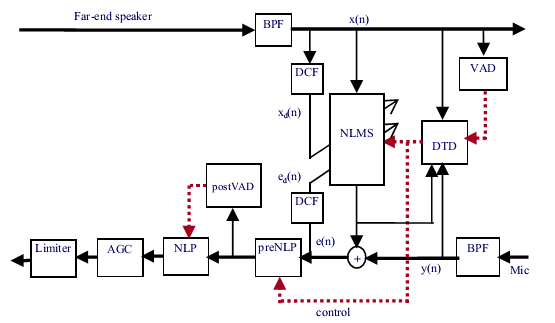
上图是功能框图,BPF是Band Pass Filter,用来滤掉远端信号中的过高和过低的频率分量(类似降噪?),DCF是correlation filter,用来使得NLMS快速收敛的。VAD是监测远端是不是有声音信号的,NLP是用来去掉残余回声的。
接口
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
nearendNoisy是带有噪音的近端信号,nearendClean是消掉噪音的近端信号,out是输出的AEC处理过的信号,nrOfSamples只能是80或者160,就是10ms的音频数据,msInSndCardBuf是输入输出的时延, 就是远端信号从被reference到被aec处理之间的时间差。
针对这个时间差:
在扬声器和麦克风离得很近的情况下,可以忽略声音传播的时间,因此这个delay就是:
// Sets the |delay| in ms between AnalyzeReverseStream() receiving a far-end
// frame and ProcessStream() receiving a near-end frame containing the
// corresponding echo. On the client-side this can be expressed as
// delay = (t_render - t_analyze) + (t_process - t_capture)
// where,
// - t_analyze is the time a frame is passed to AnalyzeReverseStream() and
// t_render is the time the first sample of the same frame is rendered by
// the audio hardware.
// - t_capture is the time the first sample of a frame is captured by the
// audio hardware and t_pull is the time the same frame is passed to
// ProcessStream().
因此AEC模块的位置越靠近硬件越好(should be placed in the signal chain as close to the audio hardware abstraction layer (HAL) as possible.)。这样:
- 避免了大量的软件处理,时延可以控制在最小;
- 因为都是在硬件里运行的,时延基本不会变化;
- 音量和从Speaker里出来的声音一致。
一次处理的长度是80 个sample,成为一个FRAME,nb对应1个FRAME, wb对应2个
WebRtcAecm_ProcessFrame是每80个采样处理一次
int WebRtcAecm_ProcessBlock(AecmCore* aecm,
const int16_t* farend,
const int16_t* nearendNoisy,
const int16_t* nearendClean,
int16_t* output) {
处理64个采样一组的bloack。
但是输出还是按照80个采样一个frame来输出
WebRtcAecm_ProcessBlock
TimeToFrequencyDomain时域到频域的转换,出来就是64个复数点,分别用实部和虚部表示
aecm->real_fft = WebRtcSpl_CreateRealFFT(PART_LEN_SHIFT);这个FFT的order是7,是 Length of (PART_LEN * 2) in base 2.
WebRtcSpl_RealForwardFFT也是通过WebRtcSpl_ComplexFFT计算的
far_q = TimeToFrequencyDomain(aecm,
aecm->xBuf, 64 * 2
dfw, 64 * 2
xfa, 64
&xfaSum);
static int TimeToFrequencyDomain(AecmCore* aecm,
const int16_t* time_signal, 64 * 2
ComplexInt16* freq_signal, 64 * 2
uint16_t* freq_signal_abs, 64
uint32_t* freq_signal_sum_abs)
int16_t fft_buf[PART_LEN4 + 16];
static void WindowAndFFT(AecmCore* aecm,
int16_t* fft, 64 * 4
const int16_t* time_signal, 64 * 2
ComplexInt16* freq_signal, 64 * 2
int time_signal_scaling)
WebRtcSpl_RealForwardFFT(aecm->real_fft,
fft, 64 * 4
(int16_t*)freq_signal 64 * 2
);
做之前要加窗?汉宁窗,防止频谱泄露。
// Approximation for magnitude of complex fft output
// magn = sqrt(real^2 + imag^2)
// magn ~= alpha * max(|imag|,|real|) + beta * min(|imag|,|real|)
//
// The parameters alpha and beta are stored in Q15
计算复数的摸的简单方法,这个是DSP的一个技巧
http://dspguru.com/dsp/tricks/magnitude-estimator
WebRtcAecm_UpdateFarHistory, 存储far end的频谱信号幅度谱到far history
The Q-domain of current frequency values 是啥?
似乎是先去一个时域信号的最大绝对值,然后。。。。。不知
if (WebRtc_AddFarSpectrumFix(aecm->delay_estimator_farend,
xfa,
PART_LEN1,
far_q) == -1)
计算fixed delay, 这个计算是根据一篇专利来的 LOW COMPLEX AND ROBUST DELAY ESTIMATION,低复杂性和稳定的延时估计算法,多么牛逼 http://patents.justia.com/patent/20130163698, 是用概率算的
估计完延时后,就是对齐far和near的波形
// Returns a pointer to the far end spectrum aligned to current near end
// spectrum. The function WebRtc_DelayEstimatorProcessFix(…) should have been
// called before AlignedFarend(…). Otherwise, you get the pointer to the
// previous frame. The memory is only valid until the next call of
// WebRtc_DelayEstimatorProcessFix(…).
//
// Inputs:
// - self : Pointer to the AECM instance.
// - delay : Current delay estimate.
//
// Output:
// - far_q : The Q-domain of the aligned far end spectrum
//
// Return value:
// - far_spectrum : Pointer to the aligned far end spectrum
// NULL - Error
//
const uint16_t* WebRtcAecm_AlignedFarend
计算近端,远端,的能量,其实是为了VAD做的
// WebRtcAecm_CalcEnergies(…)
//
// This function calculates the log of energies for nearend, farend and estimated
// echoes. There is also an update of energy decision levels, i.e. internal VAD.
//
//
// @param aecm [i/o] Handle of the AECM instance.
// @param far_spectrum [in] Pointer to farend spectrum.
// @param far_q [in] Q-domain of farend spectrum.
// @param nearEner [in] Near end energy for current block in
// Q(aecm->dfaQDomain).
// @param echoEst [out] Estimated echo in Q(xfa_q+RESOLUTION_CHANNEL16).
//
void WebRtcAecm_CalcEnergies(AecmCore* aecm,
const uint16_t* far_spectrum,
const int16_t far_q,
const uint32_t nearEner,
int32_t* echoEst) {
估计远端VAD aecm->currentVADValue = 1; 表示远端木有VAD
if (!aecm->currentVADValue)
// Far end energy level too low, no channel update
至于Step Size,这是LMS算法·中的一部分
// WebRtcAecm_CalcStepSize(…)
//
// This function calculates the step size used in channel estimation
//
//
// @param aecm [in] Handle of the AECM instance.
// @param mu [out] (Return value) Stepsize in log2(), i.e. number of shifts.
//
//
int16_t WebRtcAecm_CalcStepSize(AecmCore* const aecm) {
更新channel, NLMS的算法一部分
// WebRtcAecm_UpdateChannel(…)
//
// This function performs channel estimation. NLMS and decision on channel storage.
//
//
// @param aecm [i/o] Handle of the AECM instance.
// @param far_spectrum [in] Absolute value of the farend signal in Q(far_q)
// @param far_q [in] Q-domain of the farend signal
// @param dfa [in] Absolute value of the nearend signal (Q[aecm->dfaQDomain])
// @param mu [in] NLMS step size.
// @param echoEst [i/o] Estimated echo in Q(far_q+RESOLUTION_CHANNEL16).
//
void WebRtcAecm_UpdateChannel(AecmCore* aecm,
const uint16_t* far_spectrum,
const int16_t far_q,
const uint16_t* const dfa,
const int16_t mu,
int32_t* echoEst) {
WebRtcAecm_StoreAdaptiveChannelNeon
// This is C code of following optimized code.
// During startup we store the channel every block.
// memcpy(aecm->channelStored,
// aecm->channelAdapt16,
// sizeof(int16_t) * PART_LEN1);
// Recalculate echo estimate
// for (i = 0; i < PART_LEN; i += 4) {
// echo_est[i] = WEBRTC_SPL_MUL_16_U16(aecm->channelStored[i],
// far_spectrum[i]);
// echo_est[i + 1] = WEBRTC_SPL_MUL_16_U16(aecm->channelStored[i + 1],
// far_spectrum[i + 1]);
// echo_est[i + 2] = WEBRTC_SPL_MUL_16_U16(aecm->channelStored[i + 2],
// far_spectrum[i + 2]);
// echo_est[i + 3] = WEBRTC_SPL_MUL_16_U16(aecm->channelStored[i + 3],
// far_spectrum[i + 3]);
// }
// echo_est[i] = WEBRTC_SPL_MUL_16_U16(aecm->channelStored[i],
// far_spectrum[i]);
// We have enough data.
// Calculate MSE of “Adapt” and “Stored” versions.
// It is actually not MSE, but average absolute error.
根据谁的MSE小决定Store谁,adaptive one or old one
然后计算维纳滤波器增益
// Determine suppression gain used in the Wiener filter. The gain is based on a mix of far
// end energy and echo estimation error.
// CalcSuppressionGain(…)
//
// This function calculates the suppression gain that is used in the Wiener filter.
//
//
// @param aecm [i/n] Handle of the AECM instance.
// @param supGain [out] (Return value) Suppression gain with which to scale the noise
// level (Q14).
//
//
int16_t WebRtcAecm_CalcSuppressionGain(AecmCore* const aecm) {
在这个里面可以做DTD的判断。这个是根据估计的回声信号和实际的输入的回声信号来的判断是不是DTD。
然后是维纳滤波和汉宁窗,以及舒适噪声的产生,不懂!
缺点:
没有一个好的DTD。这就造成没有DT的时候消除回声很干净,有DT的时候,近端talk也被消掉了。
WebRtc不准备Fix it, 参见Google的邮件列表:
Andrew MacDonald
9/29/11
- show quoted texJust to set the record straight here, no, we don’t have any explicit
double-talk detection. It’s handled implicitly by limiting the
magnitude of the error used in adaptation.
Additionally, we disregard the filter output if its energy is higher
than the input, since this indicates the filter has likely diverged.[email protected], Dec 3 2013
Status: WontFix
We once states AECM offers decent double-talk feature which is not equivalent to AEC but better than nothing, giving the light complexity of AECM. But people used to have higher expectation then. So it’s more safer to say NO double-talk feature in AECM.
And from another thread, we are working on other methods to replace AECM, instead of improving it further. So I would mark this issue to WontFix too.BTW: @boykinjim, recently I found out that currently AECM is limited to 8k&16k codec only. So try not to use Opus on Android phone so far.