- x86-64汇编语言训练程序与实战
十除以十等于一
本文还有配套的精品资源,点击获取简介:汇编语言是一种低级语言,与机器代码紧密相关,特别适用于编写系统级代码及性能要求高的应用。nasm编译器是针对x86和x86-64架构的汇编语言编译器,支持多种语法风格和指令集。项目Euler提供数学和计算机科学问题,鼓励编程技巧应用,前100个问题的答案可共享。x86-64架构扩展了寄存器数量并引入新指令,提升了数据处理效率。学习汇编语言能够深入理解计算机底层
- 我不懂什么是爱,但我给你全部我拥有的
香尧
因为怕黑,所以愿意陪伴在夜中行走的人,给他一点点的安全感。因为渴望温柔与爱,所以愿意为别的孩子付出爱与温柔。因为曾遭受侮辱和伤害,所以不以同样的方式施于其他人。如果你向别人出之以利刃,对方还了你爱与包容,真的不要感激他,真的不要赞美他。每一个被人伤害过的人心里都留下了一颗仇恨的种子,他也会想要有一天以眼还眼,以牙还牙。但他未让那颗种子生根发芽,他用一把心剑又一次刺向他自己,用他血荐仇恨,开出一朵温
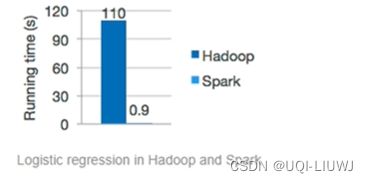
- 实时数据流计算引擎Flink和Spark剖析
程小舰
flinkspark数据库kafkahadoop
在过去几年,业界的主流流计算引擎大多采用SparkStreaming,随着近两年Flink的快速发展,Flink的使用也越来越广泛。与此同时,Spark针对SparkStreaming的不足,也继而推出了新的流计算组件。本文旨在深入分析不同的流计算引擎的内在机制和功能特点,为流处理场景的选型提供参考。(DLab数据实验室w.x.公众号出品)一.SparkStreamingSparkStreamin
- Git 与 GitHub 的对比与使用指南
一念&
其它gitgithub
Git与GitHub的对比与使用指南在软件开发中,Git和GitHub是两个密切相关但本质不同的工具。下面我将逐步解释它们的定义、区别、核心概念以及如何协同使用,确保内容真实可靠,基于广泛的技术实践。1.什么是Git?Git是一个分布式版本控制系统,由LinusTorvalds于2005年创建。它的核心功能是跟踪代码文件的变化,帮助开发者管理项目历史记录、协作和回滚错误。Git是开源的,可以在本地
- 深入解析JVM工作原理:从字节码到机器指令的全过程
一、JVM概述Java虚拟机(JVM)是Java平台的核心组件,它实现了Java"一次编写,到处运行"的理念。JVM是一个抽象的计算机器,它有自己的指令集和运行时内存管理机制。JVM的主要职责:加载:读取.class文件并验证其正确性存储:管理内存分配和垃圾回收执行:解释或编译字节码为机器指令安全:提供沙箱环境限制恶意代码二、JVM架构详解JVM由三个主要子系统组成:1.类加载子系统类加载过程分为
- ARM 和 AMD 架构的区别
m0_69576880
arm开发windows架构
ARM架构和AMD架构是两种不同的计算机处理器架构,它们有以下几个主要区别:设计出发点、兼容性、性能特点、市场定价。设计出发点:①ARM构架:ARM架构最初是为嵌入式系统设计的,旨在提供低功耗和高效能的解决方案。它主要应用于移动设备、嵌入式系统和物联网设备②AMD架构:AMD架构是基于x86架构的扩展,旨在提供与Intel架构兼容的处理器。它主要用于台式机、服务器和工作站等计算机系统。兼容性:AR
- 什么是缓存雪崩?缓存击穿?缓存穿透?分别如何解决?什么是缓存预热?
daixin8848
缓存redisjava开发语言
缓存雪崩:在一个时间段内,有大量的key过期,或者Redis服务宕机,导致大量的请求到达数据库,带来巨大压力-给key设置不同的TTL、利用Redis集群提高服务的高可用性、添加多级缓存、添加降级流策略缓存击穿:给某一个key设置了过期时间,当key过期的时间,恰好这个时间点有大量的并发请求访问这个key,可能会瞬间把数据库压垮-互斥锁:缓存失败时,只允许一个请求去加载数据并更新缓存,其他请求阻塞
- JAVA接口机结构解析
秃狼
SpringBoot八股文Javajava学习
什么是接口机在Java项目中,接口机通常指用于与外部系统进行数据交互的中间层,负责处理请求和响应的转换、协议适配、数据格式转换等任务。接口机的结构我们的接口机的结构分为两个大部分,外部接口机和内部接口机,在业务的调度上也是通过mq来实现的,只要的目的就是为了解耦合和做差异化。在接口机中主要的方法就是定时任务,消息的发送和消费,其他平台调用接口机只能提供外部接口机的方法进行调用,外部接口机可以提供消
- 最新阿里四面面试真题46道:面试技巧+核心问题+面试心得
风平浪静如码
前言做技术的有一种资历,叫做通过了阿里的面试。这些阿里Java相关问题,都是之前通过不断优秀人才的铺垫总结的,先自己弄懂了再去阿里面试,不然就是去丢脸,被虐。希望对大家帮助,祝面试成功,有个更好的职业规划。一,阿里常见技术面1、微信红包怎么实现。2、海量数据分析。3、测试职位问的线程安全和非线程安全。4、HTTP2.0、thrift。5、面试电话沟通可能先让自我介绍。6、分布式事务一致性。7、ni
- CodeFoeces-450B
ss5smi
题目原题链接:B.JzzhuandSequences题意根据公式公式计算对应fn的值。参考了其他作者的代码和思路。找循环点。负数取余需要加取余数到>0为止才可取余。代码#includeusingnamespacestd;constintmod=1e9+7;intmain(){longlongf[10],x,y,n;cin>>x>>y>>n;x=(x+mod)%mod;y=(y+mod)%mod;f
- 【项目实战】 容错机制与故障恢复:保障系统连续性的核心体系
本本本添哥
004-研效与DevOps运维工具链002-进阶开发能力分布式
在分布式系统中,硬件故障、网络波动、软件异常等问题难以避免。容错机制与故障恢复的核心目标是:通过主动检测故障、自动隔离风险、快速转移负载、重建数据一致性,最大限度减少故障对业务的影响,保障系统“持续可用”与“数据不丢失”。以下从核心机制、实现方式、典型案例等维度展开说明。一、故障检测:及时发现异常节点故障检测是容错的第一步,需通过多维度手段实时感知系统组件状态,确保故障被快速识别。1.健康检查与心
- 云集怎么赚钱?云集APP分享购物赚钱攻略
古楼
云集app怎么赚钱?云集app作为是一个全面的电商导购平台,提供诸如淘宝、京东、拼多多等各大平台的优惠券,其他同类型的导购平台相比,更加的全面,线上线下全面出击。如果你想通过云集赚钱,那你可以把这款APP推荐给淘宝(10亿用户)、拼多多(3亿用户)、京东(1亿用户)使用,那你能赚到他们购物返佣,也可以自己购物领优惠券能省不少钱,以后还有更多的商家与粉象合作,这么免费的App人人都需要,很好推广。至
- Redis + Caffeine 实现高效的两级缓存架构
周童學
Java缓存redis架构
Redis+Caffeine实现高效的两级缓存架构引言在现代高并发系统中,缓存是提升系统性能的关键组件之一。传统的单一缓存方案往往难以同时满足高性能和高可用性的需求。本文将介绍如何结合Redis和Caffeine构建一个高效的两级缓存系统,并通过三个版本的演进展示如何逐步优化代码结构。项目源代码:github地址、gitee地址两级缓存架构概述两级缓存通常由本地缓存(如Caffeine)和分布式缓
- 中原焦点团队 坚持原创分享第 1172天
金JJ
信阳案例督导:在学生出现危机时,学校启动心理应急程序,一位心理老师安抚个案的同时,其他心理老师给班级同学进行团体心理辅导,学校方面马上通知家长前来学校。学校危机干预应急流程的成熟,能有效降低个案的自杀风险。个案不愿谈及家庭及自己自杀行为等问题时,用沙盘、玩具等分散注意力,谈论他感兴趣的话题,老师温和的态度,关切的言语,个案的情绪逐渐平复。从个案自己说的,流露的非言语,家长、老师、同学、以往的记录,
- 《家庭教育促进法》解读(14)落到实处方是真
愿我们顺利平安
点击上方蓝字,关注我们吧!坚持写作第七十七天今天继续为大家解读和普及我国首部家庭类法律——《家庭教育促进法》的第四章“社会协同”。这一章是上一章“国家支持”的落脚点。第三十八条居民委员会、村民委员会可以依托城乡社区公共服务设施,设立社区家长学校等家庭教育指导服务站点,配合家庭教育指导机构组织面向居民、村民的家庭教育知识宣传,为未成年人的父母或者其他监护人提供家庭教育指导服务。个人认为这一点非常必要
- Deepseek技术深化:驱动大数据时代颠覆性变革的未来引擎
荣华富贵8
springboot搜索引擎后端缓存redis
在大数据时代,信息爆炸和数据驱动的决策逐渐重塑各行各业。作为一项前沿技术,Deepseek正在引领新一轮技术革新,颠覆传统数据处理与分析方式。本文将从理论原理、应用场景和前沿代码实践三个层面,深入剖析Deepseek技术如何为大数据时代提供颠覆性变革的解决方案。一、技术背景与核心思想1.1大数据挑战与机遇在数据量呈指数级增长的背景下,传统数据处理方法面临数据存储、计算效率和信息提取精度的诸多挑战。
- 小确幸5.23
聪聪和茵茵
图片发自App经常有好友问我,你是怎么教育孩子的?尽管我没仔细去思考这个问题,不过我还是知无不言,言无不尽的。每个孩子都是独特的,大概只有父母最为了解自己的孩子,所以其他人的做法不一定适合你的孩子,还是自己多用心去感受和体会这其中的酸甜苦辣吧。我想大概出于对孩子打出内心深处的爱,有时难免急燥粗暴地解决问题,但过后会反思,意识到自己的错误,会认真的和孩子交谈,并道歉。我是第一次当妈妈,你们是第一次当
- 大数据之路:阿里巴巴大数据实践——大数据领域建模综述
为什么需要数据建模核心痛点数据冗余:不同业务重复存储相同数据(如用户基础信息),导致存储成本激增。计算资源浪费:未经聚合的明细数据直接参与计算(如全表扫描),消耗大量CPU/内存资源。数据一致性缺失:同一指标在不同业务线的口径差异(如“活跃用户”定义不同),引发决策冲突。开发效率低下:每次分析需重新编写复杂逻辑,无法复用已有模型。数据建模核心价值性能提升:分层设计(ODS→DWD→DWS→ADS)
- 分布式链路追踪系统架构设计:从理论到企业级实践
ma451152002
java分布式系统架构
分布式链路追踪系统架构设计:从理论到企业级实践本文深入探讨分布式链路追踪系统的架构设计原理、关键技术实现和企业级应用实践,为P7架构师提供完整的技术方案参考。目录引言:分布式链路追踪的重要性核心概念与技术原理系统架构设计数据模型与协议标准核心组件架构设计性能优化与扩展性设计企业级实施策略技术选型与对比分析监控与运维体系未来发展趋势P7架构师面试要点引言:分布式链路追踪的重要性微服务架构下的挑战在现
- 父母别做“包工头”,让孩子做“小主人”
静云妈妈
文/静云妈妈很多父母,特别是爷爷奶奶外公外婆,俨然一个“包工头”,比如帮孩子穿衣、帮孩子喂饭、帮孩子洗漱、帮孩子处理与其他小朋友发生的冲突等等。这对孩子并不好,其实只是我们打着“爱孩子”的名义,剥夺了孩子自我发展的权利。像教孩子走路一样不会有哪位家长打算抱一个正常的孩子一辈子,我们总是在孩子适合的年龄想各种办法辅助孩子自己行走,最终孩子由摇摇摆摆到走得十分平顺,甚至跑步前进。面对孩子所有的事情,家
- 著作权登记申请流程
知识产权宗师猫
著作权也就是版权登记一般经过下列程序:一、作品登记应提交的材料:1、作品登记申请书(由作品登记机关提供标准格式);2、作者或其他著作权人的身份证明文件:作者身份证明(复印件,须作者签名);法人或非法人单位的工商注册登记证明或其他相关证明文件(复印件);继承人身份证明文件(复印件);委托作品的委托合同(复印件);合作作者的合作协议或合同及各合作作者的身份证明(复印件)。3、作品著作权归属证明文件:作
- 19.0-《超越感觉》-说服他人
SAM52
Becausethoughtfuljudgmentsdeservetobeshared,andthewaytheyarepresentedcanstronglyinfluencethewayothersreacttothem.因为经过深思熟虑的判断值得分享,而这些判断的呈现方式会强烈影响其他人对它们的反应。Bylearningtheprinciplesofpersuasionandapplying
- Spark SQL架构及高级用法
Aurora_NeAr
sparksql架构
SparkSQL架构概述架构核心组件API层(用户接口)输入方式:SQL查询;DataFrame/DatasetAPI。统一性:所有接口最终转换为逻辑计划树(LogicalPlan),进入优化流程。编译器层(Catalyst优化器)核心引擎:基于规则的优化器(Rule-BasedOptimizer,RBO)与成本优化器(Cost-BasedOptimizer,CBO)。处理流程:阶段输入输出关键动
- 时间是个神
王家二少2
很多时候,我们站在原地,以为总会等到那个人。可是时光荏苒,命运就像不停发车的车站,直到某一天,我们才顿然了解,所有的一切都不会再来了。我们只是因为幼稚或单纯或其他的原因,上晚了车。我们所珍惜的,不一定是别人所留念的。每一段关系都有一个保质期,有的或许如钻石般恒远,有的却只如钢铁般,看似坚牢,却终会腐蚀、生锈,最后被其他的东西所替代。——当我我回头找你,却发现早已与你背道而驰。
- 大数据技术笔记—spring入门
卿卿老祖
篇一spring介绍spring.io官网快速开始Aop面向切面编程,可以任何位置,并且可以细致到方法上连接框架与框架Spring就是IOCAOP思想有效的组织中间层对象一般都是切入service层spring组成前后端分离已学方式,前后台未分离:Spring的远程通信:明日更新创建第一个spring项目来源:科多大数据
- 瘫如葛优,动若泥鳅
小鹿姐爱吃鸡爪
有时候,需要一个戏剧性的事件才能改变人们在育儿领域的陈旧观念,才能让人们从一个全新的视角去观察孩子存在的方式,才能利用简单的互动技巧帮助孩子应对成长当中必然会有的障碍。6岁前的孩子,大约除了8-24个月之间这些即将进入学步期和处于学步期之间的宝宝,会热衷于自己站立和走路,时常拒绝大人的拥抱,其他月龄的孩子都是有感兴趣的活动时动若泥鳅,没有感兴趣的活动时马上就瘫如葛优。早上起床:妈妈我走不动玩了5小
- Python 程序设计讲义(26):字符串的用法——字符的编码
睿思达DBA_WGX
Python讲义python开发语言
Python程序设计讲义(26):字符串的用法——字符的编码目录Python程序设计讲义(26):字符串的用法——字符的编码一、字符的编码二、`ASCII`编码三、`Unicode`编码四、使用`ord()`函数查询一个字符对应的`Unicode`编码五、使用`chr()`函数查询一个`Unicode`编码对应的字符六、`Python`字符串的特征一、字符的编码计算机默认只能处理二进制数,而不能处
- 思维导图中的3A
画画的小常
图片发自App在学习思维导图3A之前,我们先来看看东方古国传统教书过程。分三步:听话,合作,变化。听话,学生摹仿老师,在这个过程中除非必需问题需要老师澄清解释,其他所有的都要求先行记忆。合作,这一阶段大多已经掌握基本知识点,允许学生提出问题,老师引导学生采用合适的方法,让学生亲自动手,解决问题。变化,经历了前面2个阶段,知识已经彻底掌握,此阶段要充分发挥洞察力和生发出新的思想以回馈老师。较之传统教
- 初探数学思维(一):数学概括
JackyFuu
数学培养规则意识;培养周密思维和创新能力“现代电子计算机之父”冯·诺依曼对微积分的评价:微积分是现代数学的第一个成就,而且怎样评价它的重要性都不为过。我认为,微积分比其他任何事物都更清楚地表明了现代数学的发端;而且,作为其逻辑发展的数学分析体系仍然构成了精密思维中最伟大的技术进展。《GEB-一条永恒的金带》,普利策奖,1979,美国,指出有一条永恒的金带把数理逻辑、绘画、音乐等不同领域之间的共同规
- 前端数据库:IndexedDB从基础到高级使用指南
文章目录前端数据库:IndexedDB从基础到高级使用指南引言一、IndexedDB概述1.1什么是IndexedDB1.2与其他存储方案的比较二、基础使用2.1打开/创建数据库2.2基本CRUD操作添加数据读取数据更新数据删除数据三、高级特性3.1复杂查询与游标3.2事务高级用法3.3性能优化技巧四、实战案例:构建离线优先的待办事项应用4.1数据库设计4.2同步策略实现五、常见问题与解决方案5.
- 对于规范和实现,你会混淆吗?
yangshangchuan
HotSpot
昨晚和朋友聊天,喝了点咖啡,由于我经常喝茶,很长时间没喝咖啡了,所以失眠了,于是起床读JVM规范,读完后在朋友圈发了一条信息:
JVM Run-Time Data Areas:The Java Virtual Machine defines various run-time data areas that are used during execution of a program. So
- android 网络
百合不是茶
网络
android的网络编程和java的一样没什么好分析的都是一些死的照着写就可以了,所以记录下来 方便查找 , 服务器使用的是TomCat
服务器代码; servlet的使用需要在xml中注册
package servlet;
import java.io.IOException;
import java.util.Arr
- [读书笔记]读法拉第传
comsci
读书笔记
1831年的时候,一年可以赚到1000英镑的人..应该很少的...
要成为一个科学家,没有足够的资金支持,很多实验都无法完成
但是当钱赚够了以后....就不能够一直在商业和市场中徘徊......
- 随机数的产生
沐刃青蛟
随机数
c++中阐述随机数的方法有两种:
一是产生假随机数(不管操作多少次,所产生的数都不会改变)
这类随机数是使用了默认的种子值产生的,所以每次都是一样的。
//默认种子
for (int i = 0; i < 5; i++)
{
cout<<
- PHP检测函数所在的文件名
IT独行者
PHP函数
很简单的功能,用到PHP中的反射机制,具体使用的是ReflectionFunction类,可以获取指定函数所在PHP脚本中的具体位置。 创建引用脚本。
代码:
[php]
view plain
copy
// Filename: functions.php
<?php&nbs
- 银行各系统功能简介
文强chu
金融
银行各系统功能简介 业务系统 核心业务系统 业务功能包括:总账管理、卡系统管理、客户信息管理、额度控管、存款、贷款、资金业务、国际结算、支付结算、对外接口等 清分清算系统 以清算日期为准,将账务类交易、非账务类交易的手续费、代理费、网络服务费等相关费用,按费用类型计算应收、应付金额,经过清算人员确认后上送核心系统完成结算的过程 国际结算系
- Python学习1(pip django 安装以及第一个project)
小桔子
pythondjangopip
最近开始学习python,要安装个pip的工具。听说这个工具很强大,安装了它,在安装第三方工具的话so easy!然后也下载了,按照别人给的教程开始安装,奶奶的怎么也安装不上!
第一步:官方下载pip-1.5.6.tar.gz, https://pypi.python.org/pypi/pip easy!
第二部:解压这个压缩文件,会看到一个setup.p
- php 数组
aichenglong
PHP排序数组循环多维数组
1 php中的创建数组
$product = array('tires','oil','spark');//array()实际上是语言结构而不 是函数
2 如果需要创建一个升序的排列的数字保存在一个数组中,可以使用range()函数来自动创建数组
$numbers=range(1,10)//1 2 3 4 5 6 7 8 9 10
$numbers=range(1,10,
- 安装python2.7
AILIKES
python
安装python2.7
1、下载可从 http://www.python.org/进行下载#wget https://www.python.org/ftp/python/2.7.10/Python-2.7.10.tgz
2、复制解压
#mkdir -p /opt/usr/python
#cp /opt/soft/Python-2
- java异常的处理探讨
百合不是茶
JAVA异常
//java异常
/*
1,了解java 中的异常处理机制,有三种操作
a,声明异常
b,抛出异常
c,捕获异常
2,学会使用try-catch-finally来处理异常
3,学会如何声明异常和抛出异常
4,学会创建自己的异常
*/
//2,学会使用try-catch-finally来处理异常
- getElementsByName实例
bijian1013
element
实例1:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/x
- 探索JUnit4扩展:Runner
bijian1013
java单元测试JUnit
参加敏捷培训时,教练提到Junit4的Runner和Rule,于是特上网查一下,发现很多都讲的太理论,或者是举的例子实在是太牵强。多搜索了几下,搜索到两篇我觉得写的非常好的文章。
文章地址:http://www.blogjava.net/jiangshachina/archive/20
- [MongoDB学习笔记二]MongoDB副本集
bit1129
mongodb
1. 副本集的特性
1)一台主服务器(Primary),多台从服务器(Secondary)
2)Primary挂了之后,从服务器自动完成从它们之中选举一台服务器作为主服务器,继续工作,这就解决了单点故障,因此,在这种情况下,MongoDB集群能够继续工作
3)挂了的主服务器恢复到集群中只能以Secondary服务器的角色加入进来
2
- 【Spark八十一】Hive in the spark assembly
bit1129
assembly
Spark SQL supports most commonly used features of HiveQL. However, different HiveQL statements are executed in different manners:
1. DDL statements (e.g. CREATE TABLE, DROP TABLE, etc.)
- Nginx问题定位之监控进程异常退出
ronin47
nginx在运行过程中是否稳定,是否有异常退出过?这里总结几项平时会用到的小技巧。
1. 在error.log中查看是否有signal项,如果有,看看signal是多少。
比如,这是一个异常退出的情况:
$grep signal error.log
2012/12/24 16:39:56 [alert] 13661#0: worker process 13666 exited on s
- No grammar constraints (DTD or XML schema).....两种解决方法
byalias
xml
方法一:常用方法 关闭XML验证
工具栏:windows => preferences => xml => xml files => validation => Indicate when no grammar is specified:选择Ignore即可。
方法二:(个人推荐)
添加 内容如下
<?xml version=
- Netty源码学习-DefaultChannelPipeline
bylijinnan
netty
package com.ljn.channel;
/**
* ChannelPipeline采用的是Intercepting Filter 模式
* 但由于用到两个双向链表和内部类,这个模式看起来不是那么明显,需要仔细查看调用过程才发现
*
* 下面对ChannelPipeline作一个模拟,只模拟关键代码:
*/
public class Pipeline {
- MYSQL数据库常用备份及恢复语句
chicony
mysql
备份MySQL数据库的命令,可以加选不同的参数选项来实现不同格式的要求。
mysqldump -h主机 -u用户名 -p密码 数据库名 > 文件
备份MySQL数据库为带删除表的格式,能够让该备份覆盖已有数据库而不需要手动删除原有数据库。
mysqldump -–add-drop-table -uusername -ppassword databasename > ba
- 小白谈谈云计算--基于Google三大论文
CrazyMizzz
Google云计算GFS
之前在没有接触到云计算之前,只是对云计算有一点点模糊的概念,觉得这是一个很高大上的东西,似乎离我们大一的还很远。后来有机会上了一节云计算的普及课程吧,并且在之前的一周里拜读了谷歌三大论文。不敢说理解,至少囫囵吞枣啃下了一大堆看不明白的理论。现在就简单聊聊我对于云计算的了解。
我先说说GFS
&n
- hadoop 平衡空间设置方法
daizj
hadoopbalancer
在hdfs-site.xml中增加设置balance的带宽,默认只有1M:
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>10485760</value>
<description&g
- Eclipse程序员要掌握的常用快捷键
dcj3sjt126com
编程
判断一个人的编程水平,就看他用键盘多,还是鼠标多。用键盘一是为了输入代码(当然了,也包括注释),再有就是熟练使用快捷键。 曾有人在豆瓣评
《卓有成效的程序员》:“人有多大懒,才有多大闲”。之前我整理了一个
程序员图书列表,目的也就是通过读书,让程序员变懒。 程序员作为特殊的群体,有的人可以这么懒,懒到事情都交给机器去做,而有的人又可以那么勤奋,每天都孜孜不倦得
- Android学习之路
dcj3sjt126com
Android学习
转自:http://blog.csdn.net/ryantang03/article/details/6901459
以前有J2EE基础,接触JAVA也有两三年的时间了,上手Android并不困难,思维上稍微转变一下就可以很快适应。以前做的都是WEB项目,现今体验移动终端项目,让我越来越觉得移动互联网应用是未来的主宰。
下面说说我学习Android的感受,我学Android首先是看MARS的视
- java 遍历Map的四种方法
eksliang
javaHashMapjava 遍历Map的四种方法
转载请出自出处:
http://eksliang.iteye.com/blog/2059996
package com.ickes;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
/**
* 遍历Map的四种方式
- 【精典】数据库相关相关
gengzg
数据库
package C3P0;
import java.sql.Connection;
import java.sql.SQLException;
import java.beans.PropertyVetoException;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class DBPool{
- 自动补全
huyana_town
自动补全
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml&quo
- jquery在线预览PDF文件,打开PDF文件
天梯梦
jquery
最主要的是使用到了一个jquery的插件jquery.media.js,使用这个插件就很容易实现了。
核心代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.
- ViewPager刷新单个页面的方法
lovelease
androidviewpagertag刷新
使用ViewPager做滑动切换图片的效果时,如果图片是从网络下载的,那么再子线程中下载完图片时我们会使用handler通知UI线程,然后UI线程就可以调用mViewPager.getAdapter().notifyDataSetChanged()进行页面的刷新,但是viewpager不同于listview,你会发现单纯的调用notifyDataSetChanged()并不能刷新页面
- 利用按位取反(~)从复合枚举值里清除枚举值
草料场
enum
以 C# 中的 System.Drawing.FontStyle 为例。
如果需要同时有多种效果,
如:“粗体”和“下划线”的效果,可以用按位或(|)
FontStyle style = FontStyle.Bold | FontStyle.Underline;
如果需要去除 style 里的某一种效果,
- Linux系统新手学习的11点建议
刘星宇
编程工作linux脚本
随着Linux应用的扩展许多朋友开始接触Linux,根据学习Windwos的经验往往有一些茫然的感觉:不知从何处开始学起。这里介绍学习Linux的一些建议。
一、从基础开始:常常有些朋友在Linux论坛问一些问题,不过,其中大多数的问题都是很基础的。例如:为什么我使用一个命令的时候,系统告诉我找不到该目录,我要如何限制使用者的权限等问题,这些问题其实都不是很难的,只要了解了 Linu
- hibernate dao层应用之HibernateDaoSupport二次封装
wangzhezichuan
DAOHibernate
/**
* <p>方法描述:sql语句查询 返回List<Class> </p>
* <p>方法备注: Class 只能是自定义类 </p>
* @param calzz
* @param sql
* @return
* <p>创建人:王川</p>
* <p>创建时间:Jul