【数据结构】时间复杂度和空间复杂度
一、数据结构前言
1.什么是数据结构:
数据结构(Data Structure)是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合
2.什么是算法?
算法(Algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为输出。简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果
通俗来说:二分查找,冒泡排序等等都为算法
3.如何学好算法和数据结构
1.多写代码(写到吐)

2.勤于思考多画图
注:学习数据结构为软件开发打下深厚功底,提升代码能力
二、算法的时间复杂度和空间复杂度
1.算法效率
1.1如何衡量一个算法的好坏
比如对于以下斐波那契数列:
long long Fib(int N)
{
if (N < 3)
return 1;
return Fib(N - 1) + Fib(N - 2);
}1.2算法的复杂度
算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。在计算机发展的期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。
2.时间复杂度
2.1 时间复杂度的概念
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例
注:算法中的基本操作的执行次数,为算法的时间复杂度。
求其时间复杂度:
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count;
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}操作次数:

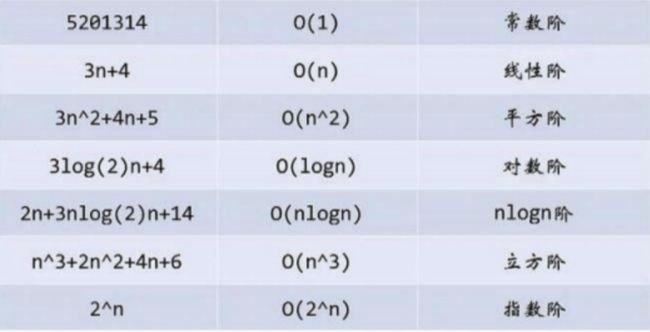
1、用常数1取代运行时间中的所有加法常数。2、在修改后的运行次数函数中,只保留最高阶项。3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大 O 阶。
N = 10 F(N) = 100N = 100 F(N) = 10000N = 1000 F(N) = 1000000
// 计算Func2的时间复杂度?
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}按照大O的渐进表示法,时间复杂度为O(N)
实例2.计算Func3的时间复杂度?
// 计算Func3的时间复杂度?
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++ k)
{
++count;
}
for (int k = 0; k < N ; ++ k)
{
++count;
}
printf("%d\n", count);
}O(M+N),如果M远大于N,时间复杂度为O(M),如果N远大于M,时间复杂度为O(N)
实例3:计算Func4的时间复杂度?
// 计算Func4的时间复杂度?
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++ k)
{
++count;
}
printf("%d\n", count);
}时间复杂度并不代表1次,而是常数次
实例4:计算strchr的时间复杂度
//计算strchr的时间复杂度
const char * strchr ( const char * str, int character );
{
while(*str)
{
if(*str == character)
{
return str;
}
}
}有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数 ( 上界 )平均情况:任意输入规模的期望运行次数最好情况:任意输入规模的最小运行次数 ( 下界 )
3.空间复杂度
4. 常见复杂度对比