arima模型_时间序列分析(R)‖ARIMA模型预测实例
背景
十九大报告,对教育方面做出了详细说明。近年来,随着研究生招生规模的逐渐扩大,报名参加硕士研究生考试的人数也逐年增加。大多数关于研究生的文章是以研究生的现状、研究生的教育、研究生的就业等方面为主题。就目前新闻热点而言,全国硕士研究生报名人数的增长问题也是一热门话题。报考人数与录取人数也存在着极大差异。
针对近年来,全国各地硕士研究生报名人数稳增不减的情况,利用R语言以及时间序列相关分析,结合近20年的全国硕士研究生报名人数数据采用ARIMA建立模型进行分析研究。根据实验寻找恰当的ARIMA模型并对未来三年全国硕士研究生报名人数进行预测。
正文
一、数据理解
1、数据来源
本问研究数据资料来源于考研帮以及中研招生信息网,使用的数据资料包括1995—2018年全国硕士研究生报名人数。
2、数据导入
> 3、数据展示
> kaoyandata 
二、模型建立与求解
(一)平稳性检验
1、时序图
根据上面的信息,运用R语言中的绘图程序,绘制全国硕士研究生随时间的趋势图。
> kaoyandata1<-kaoyandata[-1]
> kaoyandata2<-ts(kaoyandata1,start=1995)
> dev.off()
> plot(kaoyandata2)图1 1995—2018年全国硕士研究生报名人数时间序列图
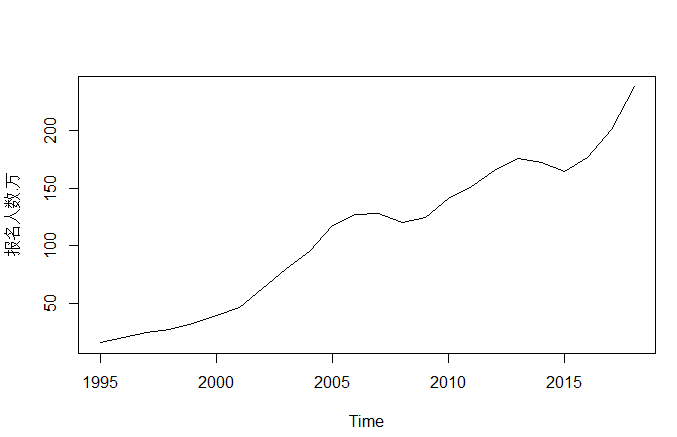
由图1可以得出,1995-2018年全国硕士研究生报名人数总体上呈上升趋势,由1995年的15.5万人上升到2018年的238万人(见上数据展示),年平均增长率为12.1%。所以它有很大可能不是平稳序列。
2、自相关图
根据上面的信息,运用R语言中的绘图程序,绘制全国硕士研究生报名人数时间序列的自相关图(滞后期为24)。
> acf(kaoyandata2,24)图2 1995—2018年全国硕士研究生报名人数自相关图

从上图可以看出,在5阶后才落入区间内,并且自相关系数长期大于0,显示出很强的自相关性。
3、ADF单位根检验
> install.packages("fUnitRoots")
> library(timeDate,timeSeries,fBasics)
> library(fUnitRoots)
> adfTest(kaoyandata2)
从返回的结果可以看出检验结果的pvalue值即P值显著大于0.05,判断该序列为非平稳序列。
4、总结
从上面三种检验中可以发现,该序列一定为非平稳序列。
(二)差分后的平稳性检验
1、差分运算
为了将非平稳时间序列转化为平稳序列,我们需要对该序列做差分运算。差分运算就是后一时间点减去当前时间如y(t)-y(t-1),用D表示,定义为Dy(t)=y(t) - yt - 1。 那么k阶差分可表示为:y(t)-y(t-k)=D(k)*y(t)=(1-L^k)*y(t)=y(t)-(L^k)*y(t),L为滞后算子,定义为L*y(t)=y(t-1),则k阶之后算子定 义为(L^k)*y(t)= y(t-k)。
进行差分遵循从小到大这一特点,故现对该时间序列进行 1阶差分运算,得出如下图所示的趋势图。
> kaoyandata2.dif<-diff(kaoyandata2)
> plot(kaoyandata2.dif)图3 全国硕士研究生报名人数1阶差分时间序列图
上图显示,1阶差分处理后的数据增减趋势较为平稳,但是依据数据最优化及准确性原则,需要对1阶差分后的时间序列再做一次差分运算。 故现对该序列进行2阶差分运算。
> kaoyandata2.dif2<-diff(kaoyandata2,1,2)
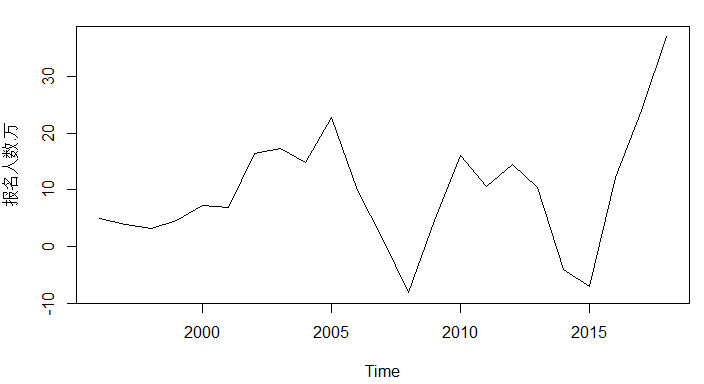
> plot(kaoyandata2.dif2)图4 全国硕士研究生报名人数2阶差分时间序列图

在理论上,足够多的差分运算可以充分提取原时间序列中的非平稳确定性信息。但进行差分运算需要注意的是,差分运算的阶数不是越多越好。差分是对信息的提取、加工的过程,每次差分都会有信息的损失,所以差分的阶数需要适当,以免过度差分。差分后的时间序列是否平稳,可以通过对差分后的时间序列进行单位根检验以此来判断差分的阶数是否最优。
> adfTest(kaoyandata2.dif)
> adfTest(kaoyandata2.dif2)
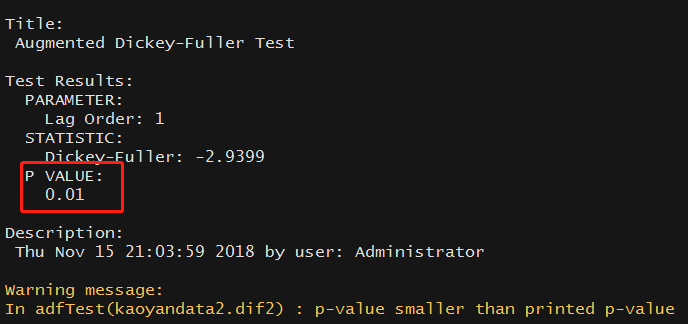
通过上面可以迅速得出,报名人数在1阶差分有常数均值下和2阶差分下ADF检验P值均小于0.05,则差分两次后的时间序列均为平稳序列,参数d的选取需要考虑1与2两个值。
2、自相关图和偏自相关图
以上是对差分阶数d的选择,而在ARIMA模型中参数p与 q也需要进行选择。时间序列的自相关系数(ACF)与偏自相关系数(PACF)可以判断参数p与q。 对平稳后的时间序列,即对1阶与2阶差分处理后的时间序列绘制自相关图与偏自相关图。
①1阶差分后的时间序列:
> par(mfrow=c(1,2))
> acf(kaoyandata2.dif,lag.max=20)
> pacf(kaoyandata2.dif,lag.max=20)图5 d=1下的自相关与偏自相关图

一阶差分后的自相关图显示滞自相关值基本没有超过边界值,虽然1阶与3阶自相关值超出边界,那么很可能属于偶然出现的,而自相关值在其他上都没有超出显著边界。偏自相关图显示除去1阶基本上也没有超过边界值。可以考虑p=2,q= 0,即ARIMA(2,1,0)模型。
②2阶差分后的时间序列:
> par(mfrow=c(1,2))
> acf(kaoyandata2.dif2,lag.max=20)
> pacf(kaoyandata2.dif2,lag.max=20)图6 d=2下的自相关与偏自相关图

二阶差分后的自相关图与偏自相关图显示没有超过边界值。
总结:由上面的检验可知,该序列可以算是平稳序列了。
(三)模型选择与参数估计
此时选择ARIMA(p,d,q)模型进行预测时,参数根据0, 1,2从低阶到高阶选择,根据AIC准则作为选择最优值模型。
> install.packages("zoo")
> install.packages("forecast")
> library(zoo)
> library(forecast)
> am120<-arima(kaoyandata2,order=c(1,2,0))
> am120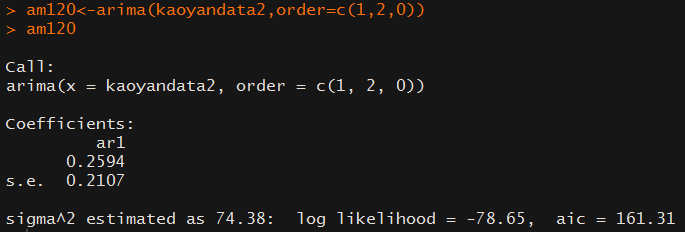
> am121<-arima(kaoyandata2,order=c(1,2,1))
> am121
> am220<-arima(kaoyandata2,order=c(2,2,0))
> am220
> am221<-arima(kaoyandata2,order=c(2,2,1))
> am221
将上面的信息整理成下表:

根据比较发现模型ARIMA(2,2,1)的AIC=160.44最小,则此模型最好。
(四)白噪声检验
> Box.test(am221$residual,type="Box-Pierce",lag=5)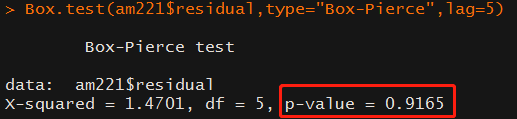
对残差序列进行白噪声检验,得出P值=0.9165> 0.05,残差序列白噪声检验说明模型显著成立。ARIMA(2,2,1) 模型对该时间序列拟合成功。
三、模型预测
运用上述得到的 ARIMA(2,2,1)模型对全国硕士研究生报名人数及置信水平分别为80%和90%双层置信区间进行预测,并给出预测表和预测图如下。
> kaoyanpredict.fore<-forecast(am221,h=3)
> kaoyanpredict.fore
> plot(kaoyanpredict.fore)

从上图中可以看出,对于2019年报名人数的预测266万相比前一年只增加了 28万人,而2018年与2017年相差37万,二者相比可能存在不足。增长的速度有所下降。
总结
通过ARIMA模型进行分析,在进行差分处理时,需要考虑多方面因素,选择较好的阶数进行判断。在全国硕士研究生报名人数上的分析可以看出,全国硕士报名已逐渐占据据大四毕业生的选择方式,且有越来越多的学生报名硕士考试。