基于mmaction2的Video-Swin-Transformer源码
网络结构图:
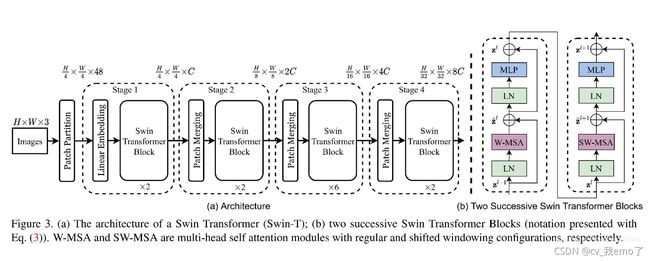
位置:Video-Swin-Transformer/mmaction/models/backbones/swin_transformer.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import numpy as np
from timm.models.layers import DropPath, trunc_normal_
from mmcv.runner import load_checkpoint
from mmaction.utils import get_root_logger
from ..builder import BACKBONES
from functools import reduce, lru_cache
from operator import mul
from einops import rearrange多层感知器:
class Mlp(nn.Module):
""" Multilayer perceptron."""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
窗口划分、逆转、尺寸:
def window_partition(x, window_size):
"""
Args:
x: (B, D, H, W, C)
window_size (tuple[int]): window size
Returns:
windows: (B*num_windows, window_size*window_size, C)
"""
B, D, H, W, C = x.shape
x = x.view(B, D // window_size[0], window_size[0], H // window_size[1], window_size[1], W // window_size[2], window_size[2], C)
windows = x.permute(0, 1, 3, 5, 2, 4, 6, 7).contiguous().view(-1, reduce(mul, window_size), C)
return windows
def window_reverse(windows, window_size, B, D, H, W):
"""
Args:
windows: (B*num_windows, window_size, window_size, C)
window_size (tuple[int]): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, D, H, W, C)
"""
x = windows.view(B, D // window_size[0], H // window_size[1], W // window_size[2], window_size[0], window_size[1], window_size[2], -1)
x = x.permute(0, 1, 4, 2, 5, 3, 6, 7).contiguous().view(B, D, H, W, -1)
return x
def get_window_size(x_size, window_size, shift_size=None):
use_window_size = list(window_size)
if shift_size is not None:
use_shift_size = list(shift_size)
for i in range(len(x_size)):
if x_size[i] <= window_size[i]:
use_window_size[i] = x_size[i]
if shift_size is not None:
use_shift_size[i] = 0
if shift_size is None:
return tuple(use_window_size)
else:
return tuple(use_window_size), tuple(use_shift_size)
W-MSA:具有相对位置偏差的基于窗口的多头自注意力模块
class WindowAttention3D(nn.Module):
""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The temporal length, height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wd, Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1) * (2 * window_size[2] - 1), num_heads)) # 2*Wd-1 * 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_d = torch.arange(self.window_size[0])
coords_h = torch.arange(self.window_size[1])
coords_w = torch.arange(self.window_size[2])
coords = torch.stack(torch.meshgrid(coords_d, coords_h, coords_w)) # 3, Wd, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 3, Wd*Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 3, Wd*Wh*Ww, Wd*Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wd*Wh*Ww, Wd*Wh*Ww, 3
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 2] += self.window_size[2] - 1
relative_coords[:, :, 0] *= (2 * self.window_size[1] - 1) * (2 * self.window_size[2] - 1)
relative_coords[:, :, 1] *= (2 * self.window_size[2] - 1)
relative_position_index = relative_coords.sum(-1) # Wd*Wh*Ww, Wd*Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
""" Forward function.
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, N, N) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # B_, nH, N, C
q = q * self.scale
attn = q @ k.transpose(-2, -1)
relative_position_bias = self.relative_position_bias_table[self.relative_position_index[:N, :N].reshape(-1)].reshape(
N, N, -1) # Wd*Wh*Ww,Wd*Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wd*Wh*Ww, Wd*Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0) # B_, nH, N, N
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return xSwin Transformer Block:
class SwinTransformerBlock3D(nn.Module):
""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (tuple[int]): Window size.
shift_size (tuple[int]): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads, window_size=(2,7,7), shift_size=(0,0,0),
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, use_checkpoint=False):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
self.use_checkpoint=use_checkpoint
assert 0 <= self.shift_size[0] < self.window_size[0], "shift_size must in 0-window_size"
assert 0 <= self.shift_size[1] < self.window_size[1], "shift_size must in 0-window_size"
assert 0 <= self.shift_size[2] < self.window_size[2], "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention3D(
dim, window_size=self.window_size, num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward_part1(self, x, mask_matrix):
B, D, H, W, C = x.shape
window_size, shift_size = get_window_size((D, H, W), self.window_size, self.shift_size)
x = self.norm1(x)
# pad feature maps to multiples of window size
pad_l = pad_t = pad_d0 = 0
pad_d1 = (window_size[0] - D % window_size[0]) % window_size[0]
pad_b = (window_size[1] - H % window_size[1]) % window_size[1]
pad_r = (window_size[2] - W % window_size[2]) % window_size[2]
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b, pad_d0, pad_d1))
_, Dp, Hp, Wp, _ = x.shape
# cyclic shift
if any(i > 0 for i in shift_size):
shifted_x = torch.roll(x, shifts=(-shift_size[0], -shift_size[1], -shift_size[2]), dims=(1, 2, 3))
attn_mask = mask_matrix
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, window_size) # B*nW, Wd*Wh*Ww, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # B*nW, Wd*Wh*Ww, C
# merge windows
attn_windows = attn_windows.view(-1, *(window_size+(C,)))
shifted_x = window_reverse(attn_windows, window_size, B, Dp, Hp, Wp) # B D' H' W' C
# reverse cyclic shift
if any(i > 0 for i in shift_size):
x = torch.roll(shifted_x, shifts=(shift_size[0], shift_size[1], shift_size[2]), dims=(1, 2, 3))
else:
x = shifted_x
if pad_d1 >0 or pad_r > 0 or pad_b > 0:
x = x[:, :D, :H, :W, :].contiguous()
return x
def forward_part2(self, x):
return self.drop_path(self.mlp(self.norm2(x)))
def forward(self, x, mask_matrix):
""" Forward function.
Args:
x: Input feature, tensor size (B, D, H, W, C).
mask_matrix: Attention mask for cyclic shift.
"""
shortcut = x
if self.use_checkpoint:
x = checkpoint.checkpoint(self.forward_part1, x, mask_matrix)
else:
x = self.forward_part1(x, mask_matrix)
x = shortcut + self.drop_path(x)
if self.use_checkpoint:
x = x + checkpoint.checkpoint(self.forward_part2, x)
else:
x = x + self.forward_part2(x)
return xPatchMerging :每个阶段,分割模块
通过步长+concat的方式,将b h w c -> b h/2w/2 4c,并通过一个全连接进行降维4d->2d,即最后,维度为 b h/2*w/2 2c。
class PatchMerging(nn.Module):
""" Patch Merging Layer
Args:
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
""" Forward function.
Args:
x: Input feature, tensor size (B, D, H, W, C).
"""
B, D, H, W, C = x.shape
# padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, :, 0::2, 0::2, :] # B D H/2 W/2 C
x1 = x[:, :, 1::2, 0::2, :] # B D H/2 W/2 C
x2 = x[:, :, 0::2, 1::2, :] # B D H/2 W/2 C
x3 = x[:, :, 1::2, 1::2, :] # B D H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B D H/2 W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
# cache each stage results
@lru_cache()计算msak:
def compute_mask(D, H, W, window_size, shift_size, device):
img_mask = torch.zeros((1, D, H, W, 1), device=device) # 1 Dp Hp Wp 1
cnt = 0
for d in slice(-window_size[0]), slice(-window_size[0], -shift_size[0]), slice(-shift_size[0],None):
for h in slice(-window_size[1]), slice(-window_size[1], -shift_size[1]), slice(-shift_size[1],None):
for w in slice(-window_size[2]), slice(-window_size[2], -shift_size[2]), slice(-shift_size[2],None):
img_mask[:, d, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, window_size) # nW, ws[0]*ws[1]*ws[2], 1
mask_windows = mask_windows.squeeze(-1) # nW, ws[0]*ws[1]*ws[2]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_maskBasicLayer:一个阶段的基本 Swin Transformer 层(一个stage)
basic_layer分为两个部分,patch_merging和swin_trans_block结构
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of feature channels
depth (int): Depths of this stage.
num_heads (int): Number of attention head.
window_size (tuple[int]): Local window size. Default: (1,7,7).
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
"""
def __init__(self,
dim,
depth,
num_heads,
window_size=(1,7,7),
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
norm_layer=nn.LayerNorm,
downsample=None,
use_checkpoint=False):
super().__init__()
self.window_size = window_size
self.shift_size = tuple(i // 2 for i in window_size)
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock3D(
dim=dim,
num_heads=num_heads,
window_size=window_size,
shift_size=(0,0,0) if (i % 2 == 0) else self.shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
use_checkpoint=use_checkpoint,
)
for i in range(depth)])
self.downsample = downsample
if self.downsample is not None:
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
def forward(self, x):
""" Forward function.
Args:
x: Input feature, tensor size (B, C, D, H, W).
"""
# calculate attention mask for SW-MSA
B, C, D, H, W = x.shape
window_size, shift_size = get_window_size((D,H,W), self.window_size, self.shift_size)
x = rearrange(x, 'b c d h w -> b d h w c')
Dp = int(np.ceil(D / window_size[0])) * window_size[0]
Hp = int(np.ceil(H / window_size[1])) * window_size[1]
Wp = int(np.ceil(W / window_size[2])) * window_size[2]
attn_mask = compute_mask(Dp, Hp, Wp, window_size, shift_size, x.device)
for blk in self.blocks:
x = blk(x, attn_mask)
x = x.view(B, D, H, W, -1)
if self.downsample is not None:
x = self.downsample(x)
x = rearrange(x, 'b d h w c -> b c d h w')
return x视频的分割嵌入:
class PatchEmbed3D(nn.Module):
""" Video to Patch Embedding.
Args:
patch_size (int): Patch token size. Default: (2,4,4).
in_chans (int): Number of input video channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, patch_size=(2,4,4), in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
self.patch_size = patch_size
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv3d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
"""Forward function."""
# padding
_, _, D, H, W = x.size()
if W % self.patch_size[2] != 0:
x = F.pad(x, (0, self.patch_size[2] - W % self.patch_size[2]))
if H % self.patch_size[1] != 0:
x = F.pad(x, (0, 0, 0, self.patch_size[1] - H % self.patch_size[1]))
if D % self.patch_size[0] != 0:
x = F.pad(x, (0, 0, 0, 0, 0, self.patch_size[0] - D % self.patch_size[0]))
x = self.proj(x) # B C D Wh Ww
if self.norm is not None:
D, Wh, Ww = x.size(2), x.size(3), x.size(4)
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
x = x.transpose(1, 2).view(-1, self.embed_dim, D, Wh, Ww)
return x
@BACKBONES.register_module()swin transformer 主代码:
整体结构中,通过PatchEmbed()分割出图像块,再经过相应层数的BasicLayer()。
class SwinTransformer3D(nn.Module):
""" Swin Transformer backbone.
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
patch_size (int | tuple(int)): Patch size. Default: (4,4,4).
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
depths (tuple[int]): Depths of each Swin Transformer stage.
num_heads (tuple[int]): Number of attention head of each stage.
window_size (int): Window size. Default: 7.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: Truee
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set.
drop_rate (float): Dropout rate.
attn_drop_rate (float): Attention dropout rate. Default: 0.
drop_path_rate (float): Stochastic depth rate. Default: 0.2.
norm_layer: Normalization layer. Default: nn.LayerNorm.
patch_norm (bool): If True, add normalization after patch embedding. Default: False.
frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
-1 means not freezing any parameters.
"""
def __init__(self,
pretrained=None,
pretrained2d=True,
patch_size=(4,4,4),
in_chans=3,
embed_dim=96,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
window_size=(2,7,7),
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.2,
norm_layer=nn.LayerNorm,
patch_norm=False,
frozen_stages=-1,
use_checkpoint=False):
super().__init__()
self.pretrained = pretrained
self.pretrained2d = pretrained2d
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
self.frozen_stages = frozen_stages
self.window_size = window_size
self.patch_size = patch_size
# split image into non-overlapping patches
self.patch_embed = PatchEmbed3D(
patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(
dim=int(embed_dim * 2**i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if i_layer= 0:
self.patch_embed.eval()
for param in self.patch_embed.parameters():
param.requires_grad = False
if self.frozen_stages >= 1:
self.pos_drop.eval()
for i in range(0, self.frozen_stages):
m = self.layers[i]
m.eval()
for param in m.parameters():
param.requires_grad = False
def inflate_weights(self, logger):
"""Inflate the swin2d parameters to swin3d.
The differences between swin3d and swin2d mainly lie in an extra
axis. To utilize the pretrained parameters in 2d model,
the weight of swin2d models should be inflated to fit in the shapes of
the 3d counterpart.
Args:
logger (logging.Logger): The logger used to print
debugging infomation.
"""
checkpoint = torch.load(self.pretrained, map_location='cpu')
state_dict = checkpoint['model']
# delete relative_position_index since we always re-init it
relative_position_index_keys = [k for k in state_dict.keys() if "relative_position_index" in k]
for k in relative_position_index_keys:
del state_dict[k]
# delete attn_mask since we always re-init it
attn_mask_keys = [k for k in state_dict.keys() if "attn_mask" in k]
for k in attn_mask_keys:
del state_dict[k]
state_dict['patch_embed.proj.weight'] = state_dict['patch_embed.proj.weight'].unsqueeze(2).repeat(1,1,self.patch_size[0],1,1) / self.patch_size[0]
# bicubic interpolate relative_position_bias_table if not match
relative_position_bias_table_keys = [k for k in state_dict.keys() if "relative_position_bias_table" in k]
for k in relative_position_bias_table_keys:
relative_position_bias_table_pretrained = state_dict[k]
relative_position_bias_table_current = self.state_dict()[k]
L1, nH1 = relative_position_bias_table_pretrained.size()
L2, nH2 = relative_position_bias_table_current.size()
L2 = (2*self.window_size[1]-1) * (2*self.window_size[2]-1)
wd = self.window_size[0]
if nH1 != nH2:
logger.warning(f"Error in loading {k}, passing")
else:
if L1 != L2:
S1 = int(L1 ** 0.5)
relative_position_bias_table_pretrained_resized = torch.nn.functional.interpolate(
relative_position_bias_table_pretrained.permute(1, 0).view(1, nH1, S1, S1), size=(2*self.window_size[1]-1, 2*self.window_size[2]-1),
mode='bicubic')
relative_position_bias_table_pretrained = relative_position_bias_table_pretrained_resized.view(nH2, L2).permute(1, 0)
state_dict[k] = relative_position_bias_table_pretrained.repeat(2*wd-1,1)
msg = self.load_state_dict(state_dict, strict=False)
logger.info(msg)
logger.info(f"=> loaded successfully '{self.pretrained}'")
del checkpoint
torch.cuda.empty_cache()
def init_weights(self, pretrained=None):
"""Initialize the weights in backbone.
Args:
pretrained (str, optional): Path to pre-trained weights.
Defaults to None.
"""
def _init_weights(m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
if pretrained:
self.pretrained = pretrained
if isinstance(self.pretrained, str):
self.apply(_init_weights)
logger = get_root_logger()
logger.info(f'load model from: {self.pretrained}')
if self.pretrained2d:
# Inflate 2D model into 3D model.
self.inflate_weights(logger)
else:
# Directly load 3D model.
load_checkpoint(self, self.pretrained, strict=False, logger=logger)
elif self.pretrained is None:
self.apply(_init_weights)
else:
raise TypeError('pretrained must be a str or None')
def forward(self, x):
"""Forward function."""
x = self.patch_embed(x)
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x.contiguous())
x = rearrange(x, 'n c d h w -> n d h w c')
x = self.norm(x)
x = rearrange(x, 'n d h w c -> n c d h w')
return x
def train(self, mode=True):
"""Convert the model into training mode while keep layers freezed."""
super(SwinTransformer3D, self).train(mode)
self._freeze_stages()