构建RNN(Recurrent Neural Network)
目前RNN网络可以在深度学习框架下通过调用函数实现(比如:tf.nn.rnn_cell),但为了掌握更多RNN的细节,我们还是需要使用numpy来逐步实现。
由于RNN网络具有“记忆力”,因此非常适合NLP和序列任务。RNN网络每次读取一个输入X(t),输入信息从当前时间步传到下一步的过程中,网络隐含层的激活函数会“记住”一些信息或上下文内容。这种机制允许单向RNN从前面的输入中获取信息以处理后续输入,同时使得双向RNN网络能够从过去和未来的获取上下文信息。
导入所需的第三方库,其中所用辅助程序可点击此处下载。
import numpy as np
from rnn_utils import *1.基本RNN的前向传播
基本RNN结构如下,其中Tx = Ty:

1.1RNN单元
RNN网络可以看做是一个单元的重复执行,首先要执行的单一时间步的计算,计算操作如图所示:
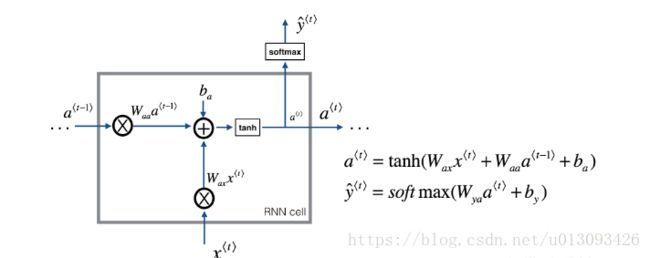
如图所示,需要计算的步骤如下:
(1)计算隐层状态a![]()
(2)计算预测值y![]()
(3)在缓存中存储cache:(a
(4)返回a
我们将m个样本向量化,因此X
def rnn_cell_forward(xt, a_prev, parameters):
Wax = parameters["Wax"]
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
a_next = np.tanh(np.dot(Waa, a_prev) + np.dot(Wax, xt) + ba)
yt_pred = softmax(np.dot(Wya, a_next) + by)
cache = (a_next, a_prev, xt, parameters)
return a_next, yt_pred, cachenp.random.seed(1)
xt = np.random.randn(3,10)
a_prev = np.random.randn(5,10)
Waa = np.random.randn(5,5)
Wax = np.random.randn(5,3)
Wya = np.random.randn(2,5)
ba = np.random.randn(5,1)
by = np.random.randn(2,1)
parameters = {"Waa": Waa, "Wax": Wax, "Wya": Wya, "ba": ba, "by": by}
a_next, yt_pred, cache = rnn_cell_forward(xt, a_prev, parameters)
print("a_next[4] = ", a_next[4])
print("a_next.shape = ", a_next.shape)
print("yt_pred[1] =", yt_pred[1])
print("yt_pred.shape = ", yt_pred.shape)a_next[4] = [ 0.59584544 0.18141802 0.61311866 0.99808218 0.85016201 0.99980978
-0.18887155 0.99815551 0.6531151 0.82872037]
a_next.shape = (5, 10)
yt_pred[1] = [0.9888161 0.01682021 0.21140899 0.36817467 0.98988387 0.88945212
0.36920224 0.9966312 0.9982559 0.17746526]
yt_pred.shape = (2, 10)1.2RNN前向传播
RNN的结构实质上就是1.1中介绍基本单元的多次组合,对于每一个单元将a

def rnn_forward(x, a0, parameters):
caches = []
n_x, m, T_x = x.shape
n_y, n_a = parameters["Wya"].shape
a = np.zeros((n_a, m, T_x))
y_pred = np.zeros((n_y, m, T_x))
a_next = a0
for t in range(T_x):
a_next, yt_pred, cache = rnn_cell_forward(x[:,:,t], a_next, parameters)
a[:,:,t] = a_next
y_pred[:,:,t] = yt_pred
caches.append(cache)
caches = (caches, x)
return a, y_pred, cachesnp.random.seed(1)
x = np.random.randn(3,10,4)
a0 = np.random.randn(5,10)
Waa = np.random.randn(5,5)
Wax = np.random.randn(5,3)
Wya = np.random.randn(2,5)
ba = np.random.randn(5,1)
by = np.random.randn(2,1)
parameters = {"Waa": Waa, "Wax": Wax, "Wya": Wya, "ba": ba, "by": by}
a, y_pred, caches = rnn_forward(x, a0, parameters)
print("a[4][1] = ", a[4][1])
print("a.shape = ", a.shape)
print("y_pred[1][3] =", y_pred[1][3])
print("y_pred.shape = ", y_pred.shape)
print("caches[1][1][3] =", caches[1][1][3])
print("len(caches) = ", len(caches))a[4][1] = [-0.99999375 0.77911235 -0.99861469 -0.99833267]
a.shape = (5, 10, 4)
y_pred[1][3] = [0.79560373 0.86224861 0.11118257 0.81515947]
y_pred.shape = (2, 10, 4)
caches[1][1][3] = [-1.1425182 -0.34934272 -0.20889423 0.58662319]
len(caches) = 2目前我们已经完成了RNN的前向传播过程,这个模型已经可以解决不少训练问题了,但是存在着梯度消失的问题。下面我们将构建LSTM来解决这个问题,以便模型可以很好的利用上下文信息。
2.长短时记忆网络(LSTM)
LSTM的主要特点是增加了遗忘门、更新门和输出门,如下图所示;
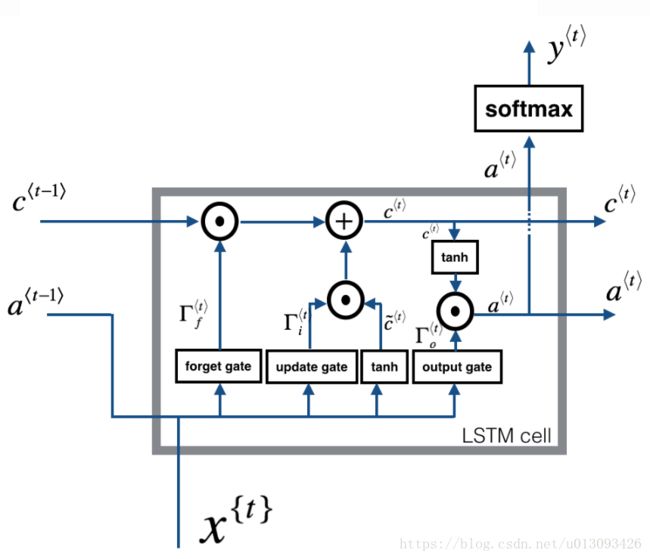
LSTM网络也是有LSTM Cell堆叠构成的。
(1)遗忘门
假设我们在阅读一段文字,主语的单复数形式决定着后文谓语的形式,因此我们需要利用LSTM的记忆功能。但是当阅读到下一段主语形式变化了,LSTM需要丢弃之前的记忆,这个功能便需要遗忘门实现,公式如下:
![]()
上式的结果是介于0-1的矢量,如果接近0,意味着LSTM应移除记忆信息;如果为1,意味着需要保持c
(2)更新门
一旦决定遗忘主语的单数形式,我们需要一个方式来更新它并反映新的主语现在是复数形式了,更新门公式如下
![]()
上式的结果是介于0-1的矢量。
(3)更新单元
在更新的主语后我们需要穿件一个新的数字矢量来增加前一单元的状态,公式如下:
![]()
最终新单元状态是
![]()
(4)输出门
为了决定我们所需的输出,需要使用如下两个公式

2.1LSTM单元的实现
def lstm_cell_forward(xt, a_prev, c_prev, parameters):
Wf = parameters["Wf"]
bf = parameters["bf"]
Wi = parameters["Wi"]
bi = parameters["bi"]
Wc = parameters["Wc"]
bc = parameters["bc"]
Wo = parameters["Wo"]
bo = parameters["bo"]
Wy = parameters["Wy"]
by = parameters["by"]
n_x, m, = xt.shape
n_y, n_a = Wy.shape
concat = np.zeros((n_x + n_a, m))
concat[: n_a,:] = a_prev
concat[n_a :,:] = xt
ft = sigmoid(np.dot(Wf, concat) + bf)
it = sigmoid(np.dot(Wi, concat) + bi)
cct = np.tanh(np.dot(Wc, concat) + bc)
c_next = ft * c_prev + it * cct
ot = sigmoid(np.dot(Wo, concat) + bo)
a_next = ot * np.tanh(c_next)
yt_pred = softmax(np.dot(Wy, a_next) + by)
cache = (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters)
return a_next, c_next, yt_pred, cachenp.random.seed(1)
xt = np.random.randn(3,10)
a_prev = np.random.randn(5,10)
c_prev = np.random.randn(5,10)
Wf = np.random.randn(5, 5+3)
bf = np.random.randn(5,1)
Wi = np.random.randn(5, 5+3)
bi = np.random.randn(5,1)
Wo = np.random.randn(5, 5+3)
bo = np.random.randn(5,1)
Wc = np.random.randn(5, 5+3)
bc = np.random.randn(5,1)
Wy = np.random.randn(2,5)
by = np.random.randn(2,1)
parameters = {"Wf": Wf, "Wi": Wi, "Wo": Wo, "Wc": Wc, "Wy": Wy, "bf": bf, "bi": bi, "bo": bo, "bc": bc, "by": by}
a_next, c_next, yt, cache = lstm_cell_forward(xt, a_prev, c_prev, parameters)
print("a_next[4] = ", a_next[4])
print("a_next.shape = ", c_next.shape)
print("c_next[2] = ", c_next[2])
print("c_next.shape = ", c_next.shape)
print("yt[1] =", yt[1])
print("yt.shape = ", yt.shape)
print("cache[1][3] =", cache[1][3])
print("len(cache) = ", len(cache))a_next[4] = [-0.66408471 0.0036921 0.02088357 0.22834167 -0.85575339 0.00138482
0.76566531 0.34631421 -0.00215674 0.43827275]
a_next.shape = (5, 10)
c_next[2] = [ 0.63267805 1.00570849 0.35504474 0.20690913 -1.64566718 0.11832942
0.76449811 -0.0981561 -0.74348425 -0.26810932]
c_next.shape = (5, 10)
yt[1] = [0.79913913 0.15986619 0.22412122 0.15606108 0.97057211 0.31146381
0.00943007 0.12666353 0.39380172 0.07828381]
yt.shape = (2, 10)
cache[1][3] = [-0.16263996 1.03729328 0.72938082 -0.54101719 0.02752074 -0.30821874
0.07651101 -1.03752894 1.41219977 -0.37647422]
len(cache) = 102.2LSTM的前向传播
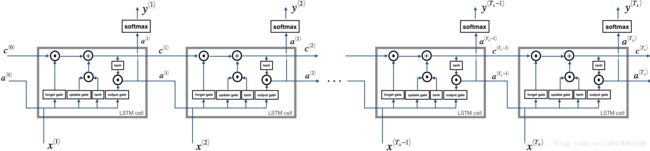
在2.1的基础上我们可以执行一个for循环来构建一个具有T_x个LSTM单元的LSTM前向传播结构,如图
def lstm_forward(x, a0, parameters):
caches = []
n_x, m, T_x = x.shape
n_y, n_a = parameters["Wy"].shape
a = np.zeros((n_a, m, T_x))
c = np.zeros((n_a, m, T_x))
y = np.zeros((n_y, m, T_x))
a_next = a0
c_next = np.zeros((n_a, m))
for t in range(T_x):
a_next, c_next, yt, cache = lstm_cell_forward(x[:,:,t], a_next, c_next, parameters)
a[:,:,t] = a_next
y[:,:,t] = yt
c[:,:,t] = c_next
caches.append(cache)
caches = (caches, x)
return a, y, c, cachesnp.random.seed(1)
x = np.random.randn(3,10,7)
a0 = np.random.randn(5,10)
Wf = np.random.randn(5, 5+3)
bf = np.random.randn(5,1)
Wi = np.random.randn(5, 5+3)
bi = np.random.randn(5,1)
Wo = np.random.randn(5, 5+3)
bo = np.random.randn(5,1)
Wc = np.random.randn(5, 5+3)
bc = np.random.randn(5,1)
Wy = np.random.randn(2,5)
by = np.random.randn(2,1)
parameters = {"Wf": Wf, "Wi": Wi, "Wo": Wo, "Wc": Wc, "Wy": Wy, "bf": bf, "bi": bi, "bo": bo, "bc": bc, "by": by}
a, y, c, caches = lstm_forward(x, a0, parameters)
print("a[4][3][6] = ", a[4][3][6])
print("a.shape = ", a.shape)
print("y[1][4][3] =", y[1][4][3])
print("y.shape = ", y.shape)
print("caches[1][1[1]] =", caches[1][1][1])
print("c[1][2][1]", c[1][2][1])
print("len(caches) = ", len(caches))a[4][3][6] = 0.17211776753291672
a.shape = (5, 10, 7)
y[1][4][3] = 0.9508734618501101
y.shape = (2, 10, 7)
caches[1][1[1]] = [ 0.82797464 0.23009474 0.76201118 -0.22232814 -0.20075807 0.18656139
0.41005165]
c[1][2][1] -0.8555449167181981
len(caches) = 2至此,我们已经一步步实现了RNN和LSTM的前向传播过程。当我们使用深度学习框架的时候反向传播的会自动进行。
3.RNN的反向传播
在现代的深度学习框架中,你只需执行前向传播的过程然后学习框架会自动完成反向传播过程,因此大部分深度学习工程师不需要考虑反向传播的过程。在RNN中我们仍然可以根据cost的导数来更新参数,RNN中反向传播的公式是相当复杂的,下面我们简要的了解一下。
3.1基本RNN的反向传播
下面我们从基本的RNN单元着手分析。
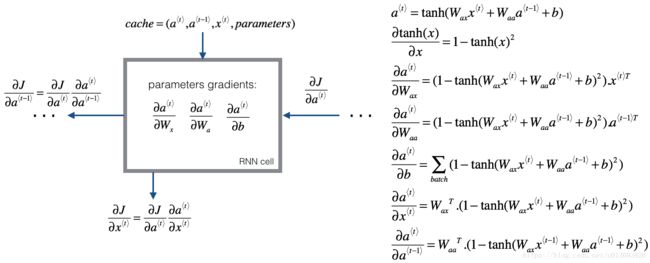
def rnn_cell_backward(da_next, cache):
(a_next, a_prev, xt, parameters) = cache
Wax = parameters['Wax']
Waa = parameters['Waa']
Wya = parameters['Wya']
ba = parameters['ba']
by = parameters['by']
dtanh = (1 - a_next**2) * da_next
dxt = np.dot(Wax.T, dtanh)
dWax = np.dot(dtanh, xt.T)
da_prev = np.dot(Waa.T, dtanh)
dWaa = np.dot(dtanh, a_prev.T)
dba = np.sum(dtanh, keepdims=True, axis=-1)
gradients = {"dxt":dxt, "da_prev":da_prev, "dWax":dWax, "dWaa":dWaa, "dba":dba}
return gradientsnp.random.seed(1)
xt = np.random.randn(3,10)
a_prev = np.random.randn(5,10)
Wax = np.random.randn(5,3)
Waa = np.random.randn(5,5)
Wya = np.random.randn(2,5)
ba = np.random.randn(5,1)
by = np.random.randn(2,1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "ba": ba, "by": by}
a_next, yt, cache = rnn_cell_forward(xt, a_prev, parameters)
da_next = np.random.randn(5,10)
gradients = rnn_cell_backward(da_next, cache)
print("gradients[\"dxt\"][1][2] =", gradients["dxt"][1][2])
print("gradients[\"dxt\"].shape =", gradients["dxt"].shape)
print("gradients[\"da_prev\"][2][3] =", gradients["da_prev"][2][3])
print("gradients[\"da_prev\"].shape =", gradients["da_prev"].shape)
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWax\"].shape =", gradients["dWax"].shape)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWaa\"].shape =", gradients["dWaa"].shape)
print("gradients[\"dba\"][4] =", gradients["dba"][4])
print("gradients[\"dba\"].shape =", gradients["dba"].shape) gradients["dxt"][1][2] = -1.3872130506020928
gradients["dxt"].shape = (3, 10)
gradients["da_prev"][2][3] = -0.15239949377395473
gradients["da_prev"].shape = (5, 10)
gradients["dWax"][3][1] = 0.41077282493545836
gradients["dWax"].shape = (5, 3)
gradients["dWaa"][1][2] = 1.1503450668497135
gradients["dWaa"].shape = (5, 5)
gradients["dba"][4] = [0.20023491]
gradients["dba"].shape = (5, 1)计算每一个时间步的激活值a
def rnn_backward(da, caches):
(cache, x) = caches
(a0, a1, x1, parameters) = cache[0]
n_a, m, T_x = da.shape
n_x, m = x1.shape
dx = np.zeros((n_x, m, T_x))
dWax = np.zeros((n_a, n_x))
dWaa = np.zeros((n_a, n_a))
dba = np.zeros((n_a, 1))
da0 = np.zeros((n_a, m))
da_prevt = np.zeros((n_a, m))
for t in reversed(range(T_x)):
gradients = rnn_cell_backward(da[:,:,t] + da_prevt, caches[0][t])
dxt, da_prevt, dWaxt, dWaat, dbat = gradients["dxt"], gradients["da_prev"],\
gradients["dWax"], gradients["dWaa"], gradients["dba"]
dx[:,:,t] = dxt
dWax += dWaxt
dWaa += dWaat
dba += dbat
da0 = da_prevt
gradients = {"dx": dx, "da0": da0, "dWax": dWax, "dWaa": dWaa,"dba": dba}
return gradientsnp.random.seed(1)
x = np.random.randn(3,10,4)
a0 = np.random.randn(5,10)
Wax = np.random.randn(5,3)
Waa = np.random.randn(5,5)
Wya = np.random.randn(2,5)
ba = np.random.randn(5,1)
by = np.random.randn(2,1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "ba": ba, "by": by}
a, y, caches = rnn_forward(x, a0, parameters)
da = np.random.randn(5, 10, 4)
gradients = rnn_backward(da, caches)
print("gradients[\"dx\"][1][2] =", gradients["dx"][1][2])
print("gradients[\"dx\"].shape =", gradients["dx"].shape)
print("gradients[\"da0\"][2][3] =", gradients["da0"][2][3])
print("gradients[\"da0\"].shape =", gradients["da0"].shape)
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWax\"].shape =", gradients["dWax"].shape)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWaa\"].shape =", gradients["dWaa"].shape)
print("gradients[\"dba\"][4] =", gradients["dba"][4])
print("gradients[\"dba\"].shape =", gradients["dba"].shape)gradients["dx"][1][2] = [-2.07101689 -0.59255627 0.02466855 0.01483317]
gradients["dx"].shape = (3, 10, 4)
gradients["da0"][2][3] = -0.31494237512664996
gradients["da0"].shape = (5, 10)
gradients["dWax"][3][1] = 11.264104496527777
gradients["dWax"].shape = (5, 3)
gradients["dWaa"][1][2] = 2.3033331265798935
gradients["dWaa"].shape = (5, 5)
gradients["dba"][4] = [-0.74747722]
gradients["dba"].shape = (5, 1)3.2LSTM反向传播
3.2.1单步反向传播
(1)门的导数计算
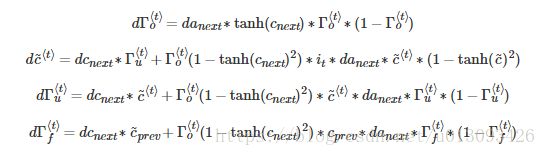
(2) 参数的导数计算
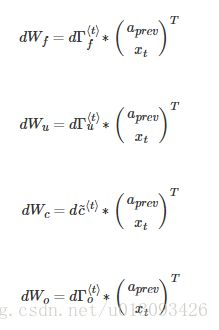
(3)da_prev, dc_prev, dxt

def lstm_cell_backward(da_next, dc_next, cache):
(a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters) = cache
n_x, m = xt.shape
n_a, m = a_next.shape
dot = da_next * np.tanh(c_next) * ot * (1-ot)
dcct = (dc_next*it+ot*(1-np.square(np.tanh(c_next)))*it*da_next)*(1-np.square(cct))
dit = (dc_next*cct+ot*(1-np.square(np.tanh(c_next)))*cct*da_next)*it*(1-it)
dft = (dc_next*c_prev+ot*(1-np.square(np.tanh(c_next)))*c_prev*da_next)*ft*(1-ft)
dWf = np.dot(dft, np.concatenate((a_prev, xt), axis=0).T)
dWi = np.dot(dit, np.concatenate((a_prev, xt), axis=0).T)
dWc = np.dot(dcct, np.concatenate((a_prev, xt), axis=0).T)
dWo = np.dot(dot, np.concatenate((a_prev, xt), axis=0).T)
dbf = np.sum(dft, axis=1, keepdims=True)
dbi = np.sum(dit, axis=1, keepdims=True)
dbc = np.sum(dcct, axis=1, keepdims=True)
dbo = np.sum(dot, axis=1, keepdims=True)
da_prev = np.dot(parameters['Wf'][:,:n_a].T, dft) + np.dot(parameters['Wi'][:,:n_a].T, dit) + np.dot(parameters['Wc'][:,:n_a].T, dcct) + np.dot(parameters['Wo'][:,:n_a].T, dot)
dc_prev = dc_next*ft + ot*(1-np.square(np.tanh(c_next)))*ft*da_next
dxt = np.dot(parameters['Wf'][:,n_a:].T,dft)+np.dot(parameters['Wi'][:,n_a:].T,dit)+np.dot(parameters['Wc'][:,n_a:].T,dcct)+np.dot(parameters['Wo'][:,n_a:].T,dot)
gradients = {"dxt": dxt, "da_prev": da_prev, "dc_prev": dc_prev, "dWf": dWf,"dbf": dbf, "dWi": dWi,"dbi": dbi,
"dWc": dWc,"dbc": dbc, "dWo": dWo,"dbo": dbo}
return gradientsnp.random.seed(1)
xt = np.random.randn(3,10)
a_prev = np.random.randn(5,10)
c_prev = np.random.randn(5,10)
Wf = np.random.randn(5, 5+3)
bf = np.random.randn(5,1)
Wi = np.random.randn(5, 5+3)
bi = np.random.randn(5,1)
Wo = np.random.randn(5, 5+3)
bo = np.random.randn(5,1)
Wc = np.random.randn(5, 5+3)
bc = np.random.randn(5,1)
Wy = np.random.randn(2,5)
by = np.random.randn(2,1)
parameters = {"Wf": Wf, "Wi": Wi, "Wo": Wo, "Wc": Wc, "Wy": Wy, "bf": bf, "bi": bi, "bo": bo, "bc": bc, "by": by}
a_next, c_next, yt, cache = lstm_cell_forward(xt, a_prev, c_prev, parameters)
da_next = np.random.randn(5,10)
dc_next = np.random.randn(5,10)
gradients = lstm_cell_backward(da_next, dc_next, cache)
print("gradients[\"dxt\"][1][2] =", gradients["dxt"][1][2])
print("gradients[\"dxt\"].shape =", gradients["dxt"].shape)
print("gradients[\"da_prev\"][2][3] =", gradients["da_prev"][2][3])
print("gradients[\"da_prev\"].shape =", gradients["da_prev"].shape)
print("gradients[\"dc_prev\"][2][3] =", gradients["dc_prev"][2][3])
print("gradients[\"dc_prev\"].shape =", gradients["dc_prev"].shape)
print("gradients[\"dWf\"][3][1] =", gradients["dWf"][3][1])
print("gradients[\"dWf\"].shape =", gradients["dWf"].shape)
print("gradients[\"dWi\"][1][2] =", gradients["dWi"][1][2])
print("gradients[\"dWi\"].shape =", gradients["dWi"].shape)
print("gradients[\"dWc\"][3][1] =", gradients["dWc"][3][1])
print("gradients[\"dWc\"].shape =", gradients["dWc"].shape)
print("gradients[\"dWo\"][1][2] =", gradients["dWo"][1][2])
print("gradients[\"dWo\"].shape =", gradients["dWo"].shape)
print("gradients[\"dbf\"][4] =", gradients["dbf"][4])
print("gradients[\"dbf\"].shape =", gradients["dbf"].shape)
print("gradients[\"dbi\"][4] =", gradients["dbi"][4])
print("gradients[\"dbi\"].shape =", gradients["dbi"].shape)
print("gradients[\"dbc\"][4] =", gradients["dbc"][4])
print("gradients[\"dbc\"].shape =", gradients["dbc"].shape)
print("gradients[\"dbo\"][4] =", gradients["dbo"][4])
print("gradients[\"dbo\"].shape =", gradients["dbo"].shape)gradients["dxt"][1][2] = 3.2305591151091875
gradients["dxt"].shape = (3, 10)
gradients["da_prev"][2][3] = -0.06396214197109236
gradients["da_prev"].shape = (5, 10)
gradients["dc_prev"][2][3] = 0.7975220387970015
gradients["dc_prev"].shape = (5, 10)
gradients["dWf"][3][1] = -0.1479548381644968
gradients["dWf"].shape = (5, 8)
gradients["dWi"][1][2] = 1.0574980552259903
gradients["dWi"].shape = (5, 8)
gradients["dWc"][3][1] = 2.3045621636876668
gradients["dWc"].shape = (5, 8)
gradients["dWo"][1][2] = 0.3313115952892109
gradients["dWo"].shape = (5, 8)
gradients["dbf"][4] = [0.18864637]
gradients["dbf"].shape = (5, 1)
gradients["dbi"][4] = [-0.40142491]
gradients["dbi"].shape = (5, 1)
gradients["dbc"][4] = [0.25587763]
gradients["dbc"].shape = (5, 1)
gradients["dbo"][4] = [0.13893342]
gradients["dbo"].shape = (5, 1)3.3LSTM RNN 的反向传播
def lstm_backward(da, caches):
(caches, x) = caches
(a1, c1, a0, c0, f1, i1, cc1, o1, x1, parameters) = caches[0]
n_a, m, T_x = da.shape
n_x, m = x1.shape
dx = np.zeros((n_x, m, T_x))
da0 = np.zeros((n_a, m))
da_prevt = np.zeros((n_a, m))
dc_prevt = np.zeros((n_a, m))
dWf = np.zeros((n_a, n_a+n_x))
dWi = np.zeros((n_a, n_a+n_x))
dWc = np.zeros((n_a, n_a+n_x))
dWo = np.zeros((n_a, n_a+n_x))
dbf = np.zeros((n_a, 1))
dbi = np.zeros((n_a, 1))
dbc = np.zeros((n_a, 1))
dbo = np.zeros((n_a, 1))
for t in reversed(range(T_x)):
gradients = lstm_cell_backward(da[:,:,t] + da_prevt, dc_prevt, caches[t])
dx[:,:,t] = gradients['dxt']
dWf = dWf + gradients['dWf']
dWi = dWi + gradients['dWi']
dWc = dWc + gradients['dWc']
dWo = dWo + gradients['dWo']
dbf = dbf + gradients['dbf']
dbi = dbi + gradients['dbi']
dbc = dbc + gradients['dbc']
dbo = dbo + gradients['dbo']
da0 = gradients['da_prev']
gradients = {"dx": dx, "da0": da0, "dWf": dWf,"dbf": dbf, "dWi": dWi,"dbi": dbi,
"dWc": dWc,"dbc": dbc, "dWo": dWo,"dbo": dbo}
return gradientsnp.random.seed(1)
x = np.random.randn(3,10,7)
a0 = np.random.randn(5,10)
Wf = np.random.randn(5, 5+3)
bf = np.random.randn(5,1)
Wi = np.random.randn(5, 5+3)
bi = np.random.randn(5,1)
Wo = np.random.randn(5, 5+3)
bo = np.random.randn(5,1)
Wc = np.random.randn(5, 5+3)
bc = np.random.randn(5,1)
Wy = np.random.randn(2,5)
by = np.random.randn(2,1)
parameters = {"Wf": Wf, "Wi": Wi, "Wo": Wo, "Wc": Wc, "Wy": Wy, "bf": bf, "bi": bi, "bo": bo, "bc": bc, "by": by}
a, y, c, caches = lstm_forward(x, a0, parameters)
da = np.random.randn(5, 10, 4)
gradients = lstm_backward(da, caches)
print("gradients[\"dx\"][1][2] =", gradients["dx"][1][2])
print("gradients[\"dx\"].shape =", gradients["dx"].shape)
print("gradients[\"da0\"][2][3] =", gradients["da0"][2][3])
print("gradients[\"da0\"].shape =", gradients["da0"].shape)
print("gradients[\"dWf\"][3][1] =", gradients["dWf"][3][1])
print("gradients[\"dWf\"].shape =", gradients["dWf"].shape)
print("gradients[\"dWi\"][1][2] =", gradients["dWi"][1][2])
print("gradients[\"dWi\"].shape =", gradients["dWi"].shape)
print("gradients[\"dWc\"][3][1] =", gradients["dWc"][3][1])
print("gradients[\"dWc\"].shape =", gradients["dWc"].shape)
print("gradients[\"dWo\"][1][2] =", gradients["dWo"][1][2])
print("gradients[\"dWo\"].shape =", gradients["dWo"].shape)
print("gradients[\"dbf\"][4] =", gradients["dbf"][4])
print("gradients[\"dbf\"].shape =", gradients["dbf"].shape)
print("gradients[\"dbi\"][4] =", gradients["dbi"][4])
print("gradients[\"dbi\"].shape =", gradients["dbi"].shape)
print("gradients[\"dbc\"][4] =", gradients["dbc"][4])
print("gradients[\"dbc\"].shape =", gradients["dbc"].shape)
print("gradients[\"dbo\"][4] =", gradients["dbo"][4])
print("gradients[\"dbo\"].shape =", gradients["dbo"].shape)gradients["dx"][1][2] = [ 0.01980463 -0.02745056 -0.31327706 0.53886581]
gradients["dx"].shape = (3, 10, 4)
gradients["da0"][2][3] = -0.00028449528974922034
gradients["da0"].shape = (5, 10)
gradients["dWf"][3][1] = -0.015389004332725791
gradients["dWf"].shape = (5, 8)
gradients["dWi"][1][2] = -0.10924217935041779
gradients["dWi"].shape = (5, 8)
gradients["dWc"][3][1] = 0.07939058449325517
gradients["dWc"].shape = (5, 8)
gradients["dWo"][1][2] = -0.08101445436214819
gradients["dWo"].shape = (5, 8)
gradients["dbf"][4] = [-0.24148921]
gradients["dbf"].shape = (5, 1)
gradients["dbi"][4] = [-0.08824333]
gradients["dbi"].shape = (5, 1)
gradients["dbc"][4] = [0.14411048]
gradients["dbc"].shape = (5, 1)
gradients["dbo"][4] = [-0.45977321]
gradients["dbo"].shape = (5, 1)以上过程就是标准的RNN网络运行的过程。