【目标检测】6、SSD:Single Shot MultiBox Detector
摘要
本文提出了一种使用单一深度神经网络来进行目标检测的方法——SSD。
将特征图上每个位置的b-box的输出离散化成了一系列不同尺度和纵横比的默认框。
预测时,网络对每个默认的框的每个目标类别进行打分,并通过调整box来更好的适应目标的形状。
此外,本网络通过结合多种分辨率的不同尺度的特征图来适应不同大小的目标。
SSD算法比需要region proposal过程的方法更简单,因为其完全消除了候选框的产生和超像素/特征重采样阶段,且将所有的计算集成到了单个网络。
这些特点使得SSD的训练较为简单,且可以直接集成到需要检测部件的系统中。
实验结果:
PASCAL,VOC,COCO,ILSVRC数据集验证了SSD方法比需要额外region proposal过程的方法效果更好更快,同时为训练和推理阶段提供了统一的框架。
1、引言
目前最优的目标检测方法主要结构如下:
假设b-box——从每个b-box中采样像素点——之后应用高质量的分类器。
自从基于Faster R-CNN 这种结构的网络发展了之后,这种检测方法成为检测的基准方法。
这类方法虽然准确,但对于嵌入式系统来说计算量过大,即使对于高端硬件,对于实时来说也很慢。
这些方法的检测方法的速度度量一般使用帧/秒(seconds per frame,SPF)来衡量,基于Faster R-CNN 的最快的高精度检测器只能达到7frames per second(FPS)。
目前已经有很多研究每个阶段的方法,来建立更快的检测器,但其往往是以显著降低的检测精度为代价。
本文提出了第一个基于深度网络的目标检测器,不需要对b-box中的像素或特征进行重采样,但效果同样准确(即避免了Faster R-CNN)的重采样。
SSD在保持高精度的同时,有效的提高了速度(59 FPS with mAP 74.3% on VOC2007 test, vs. Faster R-CNN 7 FPS with mAP 73.2% or YOLO 45 FPS with mAP 63.4%)。
速度的提升原因b-box的消除和超像素/特征的重采样阶段。
本文不是第一个这样做的,但是通过增加一系列的改进,提高了准确性。
本文的提升包括:
- 使用小的卷积核来预测目标类别和b-box偏移量
- 使用不同的预测器(filters)来检测不同的纵横比,并将这些filter用于网络后期的特征图,以便在多尺度上执行检测。
通过这些修改,尤其是在不同尺度上使用多级预测,是的我们在输入分辨率较低的情况下也能获得高准确率,同时很好的提升了检测速度。
尽管这些贡献单独看起来好像并不起眼,但是将其同时使用起来可以提高实时检测效果:使用 YOLO 在 PASCAL VOC 上 mAP=63.4%,而 SSD 的mAP=74.3%。
贡献如下:
- 本文提出了SSD,一个可以检测多个类别的单目检测器,且速度比目前最好的单目检测器 YOLO 更快更准确。且和使用候选区域和pooling的非实时方法的效果相当。
- SSD的核心是在特征图上使用小卷积核来预测类别得分和box相对默认框的偏移量。
- 为了实现较好的准确性,我们从不同尺度的特征图来产生不同尺度的预测,且通过宽高比来分别预测。
- 这些设计特征使得能够简单的进行端到端的训练和高准确性,即使输入为较低分辨率的图像,也能够较好的检测,进一步提高了速度和精度的平衡。
- 本文分别利用实验验证了不同输入大小下模型的耗时和精度。
2、SSD模型(single shot detector)
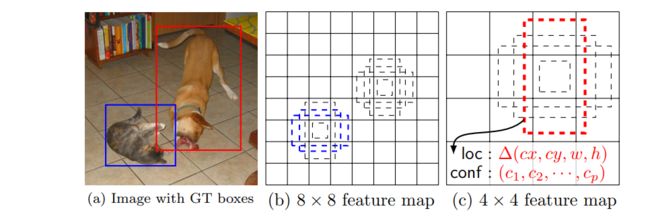
图1 SSD结构
(a) SSD的训练仅仅需要一个输入图像和所有目标的真实box。以卷积的方式,我们在几个不同尺度(如8x8和4x4)的feature map中对每个位置上不同纵横比的一小组默认框(例如4个)进行评估。
对每个默认的框,我们对所有类别同时预测形状的偏移和类别的置信度。
训练时,我们首先将真实框和默认框进行匹配,例如,我们的两个默认框匹配到了猫,一个默认框匹配到了狗,这些框被认为是正例,其余被认为是负例。
模型的损失是位置损失和置信损失的加权和。
2.1 模型
SSD方法是基于前馈卷积网络的模型,其产生一系列尺寸固定的b-box,并对框中的目标类别打分,之后使用NMS来得到最终的检测结果。
之前的神经网络层是基于高质量图像分类的标准结构(在分类层之前截断),该结构被称为基本网络(base network),我们给该网络结构中加入辅助结构,利用如下主要特征来进行检测:
-
多尺度特征图检测:
我们给截断的基础网络的末尾添加一些卷积特征层,这些层的尺寸逐渐减小,且能够在多尺度上进行检测结果的预测。在每个特征层上的用于预测检测结果的卷积模型都是不同的(Overfeat 和 YOLO 都是在单一的特征图上进行操作的)。
-
用于检测的卷积预测器:
每个添加的特征层(或基础网络中可选的一个已有的特征层)都可以使用一组卷积滤波器来产生一系列固定的预测。这些在图2中的 SSD 网络架构顶部已经指出。对于具有 p 个通道,大小为 mxn 的特征层,预测一个可能存在的检测结果的参数的基础是一个 3x3xp 的小卷积核,产生一个类别的得分活动相对于默认框的形状偏移。利用该卷积核对 mxn 特征图的每个位置都进行卷积,产生输出值。b-box的偏移的输出值是相对于特征图上每个位置的默认框的位置来衡量的(YOLO中使用的是全连接层而不是卷积核)。
-
默认框和纵横比:
我们将一系列的默认框和特征图上的每个像素值都进行联系,以用于网络顶端的多重特征图。
默认框以卷积的形式平铺整个特征图,所以每个 box 的位置和与其对应的像素点的位置是固定的。特征图中每个单元上,我们都预测该单元上默认box的形状和每个框可能的类别及其得分。
具体来说,对于在给定位置的k个框中的每个框,我们计算 c 个类别的分数和 4 个相对于默认框的偏移量,这需要在特征图上的每个位置上使用 ( c + 4 ) k (c+4)k (c+4)k 个滤波器,在 m × n m\times n m×n大小的特征图上产生 ( c + 4 ) k m n (c+4)kmn (c+4)kmn 个输出。有关默认框的说明请参见图1,默认框和 Faster R-CNN 中的 anchor box 是类似的,但是我们将其应用到了一系列不同分辨率的特征图中, 在一系列特征图中使用不同的框运行我们有效的预测到可能的输出形状。
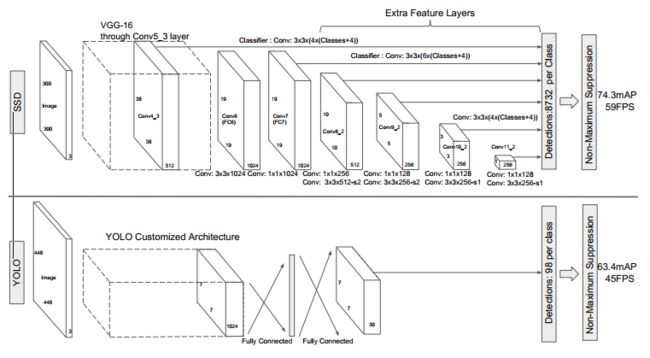
图2 单目 SSD 模型和 YOLO 模型的对比SSD 模型在base network 的最后添加了一系列特征层,能够预测不同尺度、纵横比的预测框的偏置和分类置信度得分。
使用 VOC 2007 测试集进行测试,可知SSD 输入 300x300 的情况下比 YOLO 输入448x448 情况下的效果更好,且速度更快。
2.2 训练
SSD 训练过程和传统使用 region proposal 的检测器的训练过程主要不同在于:真实标签信息需要被分配到固定的检测器输出集合中的某一特定输出上。
Faster R-CNN [2]和MultiBox [7]的regionproposal阶段、YOLO [5]的训练阶段也需要类似这样的标签。一旦确定了该分配,则端对端地应用损失函数和反向传播。训练还涉及选择默认框和检测尺度的集合,以及hard negative mining(硬负挖掘)和数据增强策略。
匹配策略:
在训练时,需要确定哪些默认框对应真实标签检测并相应地训练网络,对每个真实框,我们从默认框中进行选择,包括不同的位置、纵横比和尺度,
首先,我们对每个真实框与默认框进行jaccard 重叠计算,选择最高的结果,不同于 MultiBox,我们将默认框与真实框的 jaccard 重叠高于阈值 0.5 的任何真实标签框相匹配,这简化了学习问题,允许网络预测有重叠的默认框的的较高得分,而不是必须选择重叠最大的一个。
训练目标:
SSD 训练目标源于 MultiBox 目标,但扩展到了解决多目标的分类。
令 x i j p = 1 , 0 x_{ij}^p={1,0} xijp=1,0 作为第 p 类,第 i 个默认框和第 j 个真实框的匹配结果,从匹配策略可知,我们有 Σ i x i j p > = 1 \Sigma_ix_{ij}^p>=1 Σixijp>=1。
整体的约束损失函数是定位损失和置信损失的加权和:
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( x , l , g ) ) L(x,c,l,g)=\frac{1}{N}(L_{conf}(x,c)+\alpha L_{loc}(x,l,g)) L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g))
其中,N 是匹配到的默认框的个数,假如 N=0,我们设定 loss=0,则定位损失是 预测框 l l l 和真实值 g g g 的 smooth L1 损失。
类似于 Faster R-CNN,我们回归到默认框 d 的中心(cx,cy)和其宽(w)高(h)。

置信损失是多个类别的置信度的 softmax 损失:
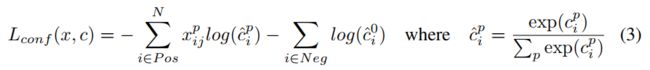
交叉验证时, α \alpha α 设置为1。
给默认框选择尺度和纵横比:
为了能够处理不同尺度的待检测目标,很多方法将图像处理成不同的大小,之后将结果进行整合。
然而,通过在单个网络中使用来自多个不同层的特征图进行预测,我们可以模拟相同的效果,同时在所有对象范围内共享参数。
以前的工作[10,11] 说明,使用底层的特征能够更好的提升语义分割的效果,因为底层特征图能够更好的捕捉输入中的目标细节信息。
[12] 中说明, 使用从特征图中 pooling 后得到的全局语义信息有助于平滑分割结果。
受这些方法的启发,我们同时使用底层特征和高层特征来进行检测。
图1展示了框架中使用的两个特征图大小,当然在实践中,我们可以使用更小的卷积核。
源于不同层的特征图具有不同的感受野大小[13],但幸运的是,SSD 框架中,默认框不需要对应每层的实际感受野。
我们可以设计默认框平铺,以便特定的特征图学习响应目标的特定尺度。假设我们要使用m个特征图做预测。每个特征图的默认框的尺度计算如下:

其中, s m i n = 0.2 s_{min}=0.2 smin=0.2, s m a x = 0.9 s_{max}=0.9 smax=0.9,意味着最底层尺度为0.2,最高层尺度为0.9,且其间的所有层具有相同的间隔。
我们对默认框使用不同的纵横比,并且定义为: a r ∈ { 1 , 2 , 3 , 1 / 2 , 1 / 3 } a_r \in \{1,2,3,1/2,1/3\} ar∈{1,2,3,1/2,1/3}
对每个默认框都计算宽度 ( w k a = s k a r w_k^a=s_k \sqrt a_r wka=skar) 和高度 ( h k a = s k a r h_k^a=s_k \sqrt a_r hka=skar) 。
当纵横比为1时,我们同样添加一个默认框,框的尺度为 s k ′ = s k s k + 1 s_k'=\sqrt {s_ks_{k+1}} sk′=sksk+1,每个特征图上的每个位置获得 6 个不同的默认框。
每个默认框的中心是 ( i + 0.5 ∣ f k ∣ , j + 0.5 ∣ f k ∣ ) (\frac{i+0.5}{|f_k|},\frac{j+0.5}{|f_k|}) (∣fk∣i+0.5,∣fk∣j+0.5),其中 ∣ f k ∣ |f_k| ∣fk∣ 是第 k 个特征图的尺寸。 i , j ∈ [ 0 , ∣ f k ∣ ) i,j \in [0,|f_k|) i,j∈[0,∣fk∣)。
实验中,我们可以通过设计默认框的分布,来最好的拟合特殊的数据集。
如何设计最优的平铺方法仍然是一个待解决的问题。
通过对所有特征图上的所有位置的不同默认框的预测结果的结合,我们获得了一系列不同的预测结果,覆盖各种输入对象的尺寸和形状,如图1中,狗被匹配到4x4特征图中的默认框,但没有匹配到8x8大小的特征图。那是因为这些框有不同的尺寸且没有匹配到狗的真实框,因此在训练期间被认为是负样本。
难例挖掘:
匹配步骤之后,大多数的默认框都被认为是负样本,尤其是当默认框的数量很大时,这就会导致训练期间正负样本不平衡(会导致发散或精度经常保持为1)。
我们没有使用所有的负样本,而是将其使用最高置信度来排序,然后挑选较高置信度的负样本,以便保持负样本和正样本的比率至多为3:1。且我们发现这样一来,可以使得优化更快且更加稳定。
数据增强:
为了使得模型对不同的输入目标的大小和形状更加鲁棒,每个训练的图像都通过以下过程随机采样:
- 使用整幅图
- 采样一块,和目标的 jaccard 重叠分别为 0.1,0.3,0.5,0.7,0.9。
- 随机采样一块
每个采样的块的大小是原图的 [0.1,1],且纵横比从 1/2 到 2。如果真实标签框中心在采样片段内,则保留重叠部分。经过上述采样处理之后,每个采样得到的块都被resize为固定大小,并以 0.5 的概率进行水平翻转。