分布式多级缓存设计方案
分布式多级缓存设计方案
-
- 设计背景
-
- 概念
- 场景
- 技术调研
-
- 一级缓存 · JVM缓存
-
- HashMap & ConcurrentHashMap & Caffeine
- 本地缓存设计
- 二级缓存 · Redis
- 设计方案
-
- 缓存架构设计
- 缓存拦截流程
- 缓存加载流程
- 缓存更新流程
设计背景
概念
先简单解释下什么是分布式多级缓存,所谓分布式简单理解就是异地跨机房服务应用部署;所谓多级缓存,这里狭义语义指定的是应用服务级别的缓存,通常泛指Redis、Memcached等;所谓多级缓存,这里是将JVM级的驻留缓存和外部依赖的缓存服务相比而言的。Redis、Memcached等都提供了性能优越的缓存服务,在高并发场景下作为提高吞吐量、优化服务性能的利器立下了汗马功劳。
场景
一般情况下,缓存我们只使用Redis作为唯一缓存就可以满足大多数业务场景。这里我们不考虑一般的业务场景,现在试图将服务场景复杂化去进行设计,进一步提高对服务性能的追求。
首先概述下业务场景, 我们的应用服务每天需要提供亿级别调用量的查询业务,在最原始阶段,外部业务提供有效入参请求服务接口返回业务数据即可,然而在之后需求迭代中,增加了对调用方权限校验(渠道校验、授权码校验、入参许可校验)和对返回业务数据的保护(涉及脱敏和非授权字段的过滤排除),业务逻辑瞬间丰富和复杂起来。
一般场景
复杂场景
- 1.入参校验
- 2.渠道校验
- 3.授权校验
- 1.脱敏处理
- 2.字段屏蔽
- 3.数据包装
以上复杂场景下,需要解决如下问题:
| 问题 | 解决方向 |
|---|---|
| 数据校验对比 | 哈希表存储避免遍历,O(1)时间复杂度 |
| 校验数据读取 | 预加载配置数据到缓存 JVM作为一级缓存,减少网络消耗 Redis作为二级缓存兜底 |
| 数据存储 | 配置数据量小,变更低频,读取高频,适合驻留JVM一级缓存 业务数据量巨大,变更不可控,读取高频,适合存储Redis二级缓存 |
技术调研
一级缓存 · JVM缓存
通常,我们会选择HashMap或线程安全的ConcurrentHashMap作为JVM缓存容器来存储数据。
HashMap & ConcurrentHashMap & Caffeine
这三者都是Key-Value形式存储,具体的实现细节不同,JDK自带的HashMap、ConcurrentHashMap操作和实现简单、Caffeine则是一套封装良好天生为本地缓存服务的框架,提供了很多缓存特性。
本地缓存设计
定义本地缓存服务的能力定义
/**
* @author: guanjian
* @date: 2020/07/06 16:11
* @description: 本地缓存接口定义
*/
public interface LocalCache {
Object get(Object key);
void put(Object key, Object value);
void putIfAbsent(Object key, Object value);
void put(Map map);
void remove(Object key);
Collection<?> getKeys();
void clear();
boolean hasKey(Object key);
void destroy();
long size();
boolean isEmpty();
String getRegion();
Map asMap();
}
由于缓存都是Key-Value形式存储,只能支持Key单维度数据存储,为了提供更为便捷和可扩展的数据存储与读取场景,引入了Region分区使得缓存支持多维度业务。其实这里每个缓存实现内部都持有一个可见性的Map
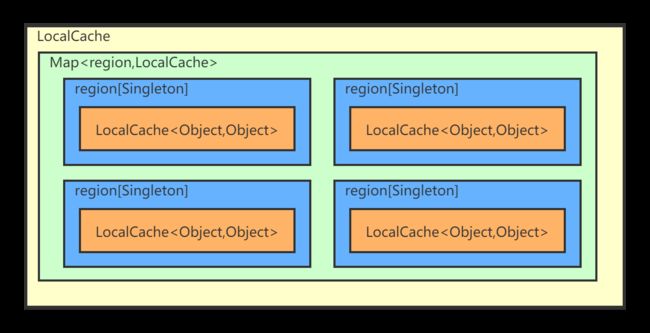
ConcurrentHashMap本地缓存的实现
/**
* @author: guanjian
* @date: 2020/07/06 16:15
* @description: 通过ConcurrentHashMap构建本地缓存
*/
public class ConcurrentHashMapCache implements LocalCache {
/**
* 多分区单例
* {@String region 缓存分区标识}
*/
private static volatile Map<String, ConcurrentHashMapCache> INSTANCES = Maps.newConcurrentMap();
/**
* 缓存分区标识
*/
private String region;
/**
* 缓存容器
* {@code Map 缓存信息}
*/
private Map<Object, Object> cache = Maps.newConcurrentMap();
@Override
public Object get(Object key) {
return cache.get(key);
}
@Override
public void put(Object key, Object value) {
cache.put(key, value);
}
@Override
public void putIfAbsent(Object key, Object value) {
cache.putIfAbsent(key, value);
}
@Override
public void put(Map map) {
cache.putAll(map);
}
@Override
public void remove(Object key) {
cache.remove(key);
}
@Override
public Collection<?> getKeys() {
return cache.keySet();
}
@Override
public void clear() {
cache.clear();
}
@Override
public boolean hasKey(Object key) {
return cache.containsKey(key);
}
@Override
public void destroy() {
INSTANCES.remove(region);
}
@Override
public long size() {
return cache.size();
}
@Override
public boolean isEmpty() {
return cache.isEmpty();
}
@Override
public String getRegion() {
return this.region;
}
@Override
public Map asMap() {
return cache;
}
public static ConcurrentHashMapCache getInstance(String region) {
if (INSTANCES.containsKey(region)) {
return INSTANCES.get(region);
}
ConcurrentHashMapCache instance = null;
if (!INSTANCES.containsKey(region)) {
synchronized (INSTANCES) {
if (!INSTANCES.containsKey(region)) {
instance = new ConcurrentHashMapCache(region);
INSTANCES.putIfAbsent(region, instance);
}
}
}
return instance;
}
private ConcurrentHashMapCache(String region) {
this.region = region;
}
}
Caffeine本地缓存的实现
/**
* @author: guanjian
* @date: 2020/07/08 9:17
* @description: 通过Caffeine构建本地缓存
*/
public class CaffeineCache implements LocalCache {
private final static Logger LOGGER = LoggerFactory.getLogger(CaffeineCache.class);
/**
* 多分区单例
* {@String region 缓存分区标识}
*/
private static volatile Map<String, CaffeineCache> INSTANCES = Maps.newConcurrentMap();
/**
* 缓存分区标识
*/
private String region;
/**
* 缓存容器
* {@code Cache 缓存信息}
*/
private Cache<Object, Object> cache = Caffeine.newBuilder()
.recordStats()
.initialCapacity(2 << 2)
.build();
private Object synLock = new Object();
@Override
public Object get(Object key) {
Object value = cache.getIfPresent(key);
LOGGER.debug("[CaffeineCache] region={}, key={},value={} getted.", region, key, JSON.toJSONString(value));
return value;
}
@Override
public void put(Object key, Object value) {
cache.put(key, value);
LOGGER.debug("[CaffeineCache] region={}, key={},value={} putted.", region, key, JSON.toJSONString(value));
}
@Override
public void putIfAbsent(Object key, Object value) {
synchronized (synLock) {
if (null != cache.getIfPresent(key)) return;
cache.put(key, value);
LOGGER.debug("[CaffeineCache] region={}, key={},value={} putted.", region, key, JSON.toJSONString(value));
}
}
@Override
public void put(Map map) {
cache.putAll(map);
LOGGER.debug("[CaffeineCache] region={}, map={} putted.", region, JSON.toJSONString(map));
}
@Override
public void remove(Object key) {
cache.cleanUp();
}
@Override
public Collection<?> getKeys() {
return cache.asMap().keySet();
}
@Override
public void clear() {
cache.invalidateAll();
}
@Override
public boolean hasKey(Object key) {
LOGGER.debug("[CaffeineCache] region={}, key={}, map={}.", region, key, JSON.toJSONString(cache.asMap()));
return null != cache.getIfPresent(key);
}
@Override
public void destroy() {
INSTANCES.remove(region);
}
@Override
public long size() {
return cache.asMap().keySet().size();
}
@Override
public boolean isEmpty() {
return 0 == cache.asMap().keySet().size();
}
@Override
public String getRegion() {
return region;
}
@Override
public Map asMap() {
return cache.asMap();
}
public static CaffeineCache getInstance(String region) {
if (INSTANCES.containsKey(region)) {
return INSTANCES.get(region);
}
CaffeineCache instance = null;
if (!INSTANCES.containsKey(region)) {
synchronized (INSTANCES) {
if (!INSTANCES.containsKey(region)) {
instance = new CaffeineCache(region);
INSTANCES.putIfAbsent(region, instance);
LOGGER.debug("[CaffeineCache] region={} is established.", region);
}
}
} else {
instance = INSTANCES.get(region);
}
return instance;
}
private CaffeineCache(String region) {
this.region = region;
}
}
二级缓存 · Redis
由于Redis提供了非常高效、便捷的数据结构,数据存储及选取的数据结构如下
| 数据名称 | 数据类型 | 存储数据结构 |
|---|---|---|
| 渠道值 | 配置数据 | Hash |
| 授权码 | 配置数据 | Hash |
| 业务授权 | 配置数据 | Hash |
| 授权字段 | 配置数据 | String(JSON序列化) |
| 脱敏字段 | 配置数据 | String(JSON序列化) |
| 业务信息 | 业务数据 | String(JSON序列化) |
设计方案
缓存架构设计

- 我们将全视图从上到下拆分为调用方→缓存层→持久层→数据库的核心数据交互主线,此外还有涉及业务数据变更的用户操作、涉及配置或运营数据变更的管理员操作,以及对缓存服务监控的定时服务等。
- 缓存层是整个缓存架构方案的核心。主要依赖JVM做配置数据的一级缓存存储,依赖Redis做业务数据存储及配置数据的兜底。
由于应用部署是分布式的,JVM的数据一致性依赖Zookeeper进行实现,通过对path进行监听,数据变更都会触发path变化从而产生event驱动JVM重新拉去数据以保证JVM缓存数据一致。虽然Zookeeper是一个CP的实现,但是JVM分布式缓存这里采用一种AP实现,由于Zookeeper是JVM缓存与DB存储数据唯一通信的信道,一旦出现网络或中间件异常,会出现无法通信无法变更数据的情况,对于这种极端情况,目前采用两种策略进行控制,一是应用启动后会有一个定时轮询的守护线程监控数据情况保证即使在脏数据下服务也部分可用,二是JVM由于监听了Zookeeper的Path变更及Session事件,对于失联情况可以选择异常报警或超时失联做服务下线保护,这里分布式通信是一个非常复杂的业务场景,仅提供一个较为可行的实现思路,具体实现可以根据业务场景做更为精细化、高可用保障的实现逻辑。 - 持久层主要做业务数据变更的缓存移除,确保缓存数据保持一致。这里通过切面环绕业务方法实现缓存移除或更新。
缓存拦截流程
- 业务请求先请求缓存是否存在业务数据,若存在直接返回
- 若缓存中为empty则说明业务数据为空,这里是为了防止缓存穿透做的空值缓存
- 若缓存值为空,避免缓存击穿会首先设置缓存为empty,而后请求DB,为了避免多个请求同一时刻穿透到DB,需要竞态获取分布式锁,获取锁成功的请求可以顺利抵达数据库进行数据获取,如果查询到数据则立刻更新缓存,无数据则不修改缓存继续保持empty并返回空数据,释放分布式锁
- 当业务方法涉及业务数据的变更时,进行切面环绕,保持第一时间清除缓存,保证缓存与DB数据一致性
缓存加载流程
- 数据加载首先判断Redis缓存中是否存在数据,若存在直接将Redis作为数据源进行数据获取加载JVM
- 若Redis数据为空则请求DB进行数据拉取,为了避免同一时刻集群JVM频繁请求和拉取DB数据,这里做了分布式锁控制,同一时刻只发起一次数据拉取操作之后更新Redis,未获取分布式锁JVM进行异步轮询Redis完成最终数据加载
缓存更新流程
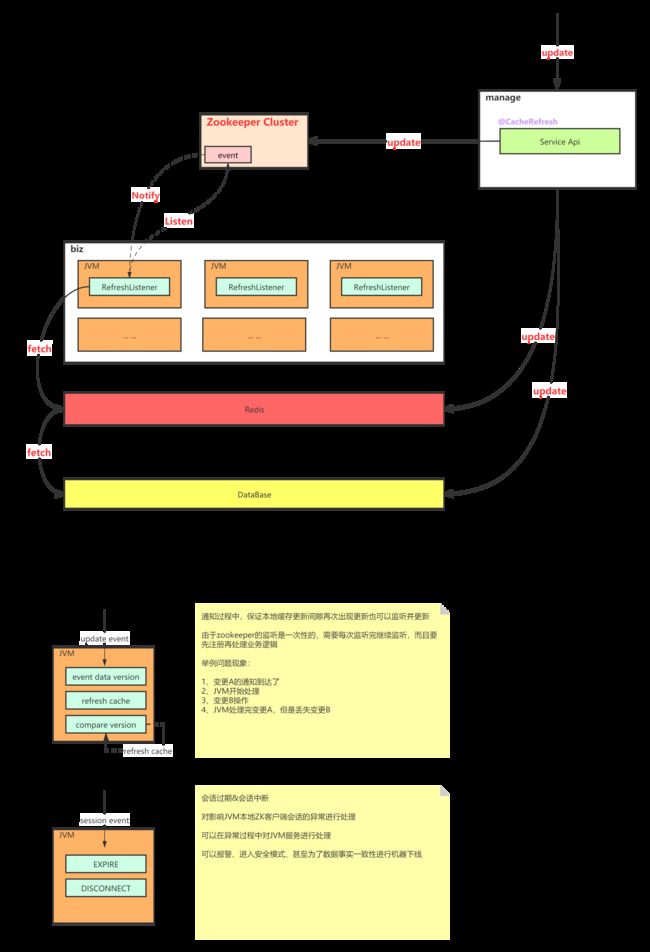
- Redis缓存更新直接通过业务方法触发进行存储、移除设置即可。
- JVM缓存的更新主要通过Zookeeper来做分布式协调,当数据库配置数据产生变化,随机触发Zookeeper迭代数据版本,JVM集群订阅Zookeeper数据变更事件触发版本对比后进行数据拉取,进入缓存加载流程保持数据更新