tf.keras.losses.SparseCategoricalCrossentropy详解
目录
tf.keras.losses.SparseCategoricalCrossentropy的作用
tf.keras.losses.SparseCategoricalCrossentropy的示例
tf.keras.losses.SparseCategoricalCrossentropy的作用
计算估计值和标签的交叉熵损失函数值。
交叉熵,描述两个分布之间的差异,比如估计的概率分布和观测到的概率分布之间的差异。最小化交叉熵等价于最大似然估计。
最大似然估计(极大似然估计),观测到某种事件发生的概率,估计系统参数为什么值的时候,最可能出现这种观测结果。
概率值,已知系统参数的前提下,某种事件发生的概率。
似然估计,观测到某种事件发生的概率,估计系统的参数。
假设有一个分类器 ,将输入分成A,B,C三类。分为A的概率
,将输入分成A,B,C三类。分为A的概率![]() 为0.3,分为B的概率
为0.3,分为B的概率![]() 为0.5,分为C的概率
为0.5,分为C的概率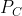 为0.2。现在有10个观测数据x,4个A,3个B, 3个C。出现这组观测结果的概率是什么?
为0.2。现在有10个观测数据x,4个A,3个B, 3个C。出现这组观测结果的概率是什么?
![]()
K是某个常数。当分类器分为每个类别概率已知时,![]() 是个确定的概率值。最大似然估计是在已知观测结果x的情况下,计算分类器的参数,使得这组观测结果出现的概率最大。
是个确定的概率值。最大似然估计是在已知观测结果x的情况下,计算分类器的参数,使得这组观测结果出现的概率最大。
![]()
那么对于单个样本,比如这次观测到A,用其估计分类器参数,则需要最小化下式
![]()
这就是tf.keras.losses.SparseCategoricalCrossentropy的计算公式,对于每个batch的样本,计算损失函数的时候,将每个样本对应真实类别的概率值负对数求和。
tf.keras.losses.SparseCategoricalCrossentropy的示例
tf.keras.losses.SparseCategoricalCrossentropy在实例化的时候,有以下可以设置的参数
from_logits=False,
ignore_class=None,
reduction=losses_utils.ReductionV2.AUTO,
name='sparse_categorical_crossentropy'from_logits为Flase表示传入的y_pred数据已经经过了softmax,变换成了概率分布。如果为True,表示传入的y_pred未经过softmax,不是一种概率分布。如果设置为True, tf.keras.losses.SparseCategoricalCrossentropy会对y_pred做softmax,转换成概率分布。
ignore_class设置要忽略的类别ID值
reduction设置对一个batch计算出的loss降至单个数值的方法,默认是AUTO,AUTO一般会将一个batch的损失值求均值,作为输出的loss
name可以指定这个实例的名字,默认是sparse_categorical_crossentropy
tf.keras.losses.SparseCategoricalCrossentropy实例化之后,可以传入(y_true, y_pred, sample_weight=None)进行调用,计算损失值。
其中,y_ture是每个类别标签值,使用0,1,2...这种单个的数字代表一个类别,形状是batch_size。
y_pred是模型估计的logit值或者概率值(对logit使用了softmax),每个类别都有一个logit或者概率值,所以其形状是(batch_size, num_classes)。
sample_weight是每个样本在损失中的权重大小。
举个栗子
y_true = [0,1,2]
y_pred = [[0.2,0.5,0.3],[0.6,0.1,0.3],[0.4,0.4,0.2]]
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False,reduction='none',name='sparse_categorical_crossentropy')
loss_val = loss_fn(y_true,y_pred).numpy()
loss_val
# array([1.609438 , 2.3025851, 1.609438 ], dtype=float32)
-np.log(0.2),-np.log(0.1),-np.log(0.2)
# (1.6094379124341003, 2.3025850929940455, 1.6094379124341003)
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False,reduction='auto',name='sparse_categorical_crossentropy')
loss_val = loss_fn(y_true,y_pred).numpy()
loss_val
# 1.840487
(-np.log(0.2)-np.log(0.1)-np.log(0.2))/3
# 1.8404869726207487当reduction设置为none时,没有做降维处理,输出的就是每个样本真实标签对应的概率值负对数结果。
reduction设置为auto(默认值)时,会对一个batch的样本损失值求平均。