2020-12-11
FJava基础
1.JDK JRE
概括:
- JRE:Java Runtime Environment,Java 运行环境的简称,为 Java 的运行提供了所需的环境。它是一个 JVM 程序,主要包括了 JVM 的标准实现和一些 Java 基本类库。
- JDK:Java Development Kit,Java 开发工具包,提供了 Java 的开发及运行环境。JDK 是 Java 开发的核心,集成了 JRE 以及一些其它的工具(编译、调试、分析工具),比如编译 Java 源码的编译器 javac 等。
2. Java异常了解吗?说说平时遇到的异常?说出6种常见的java异常。写程序遇到过哪些异常 运行时异常有哪些
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: Error 和 Exception。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
- 受检异常 :需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
- 非受检异常 :是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
常见异常:
- OutOfMemoryError:内存不足错误;
- StackOverflowError:栈溢出错误
- java.lang.NullPointerException 空指针异常;出现原因:调用了未经初始化的对象或者是不存在的对象。mnn mmmmmmmmM
- java.lang.IndexOutOfBoundsException 数组角标越界异常,常见于操作数组对象时发生。
- java.lang.ClassCastException 数据类型转换异常。
- SQLException SQL 异常,常见于操作数据库时的 SQL 语句错误。
3. 面向对象 面对对象的几大特性 多态怎么理解
面向对象三大特性:
继承:
- 继承实现了 IS-A 关系,例如 Cat 和 Animal 就是一种 IS-A 关系,因此 Cat 可以继承自 Animal,从而获得 Animal 非 private 的属性和方法。
- 继承应该遵循里氏替换原则,子类对象必须能够替换掉所有父类对象。
- Cat 可以当做 Animal 来使用,也就是说可以使用 Animal 引用 Cat 对象。父类引用指向子类对象称为 向上转型 。
封装:
利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外的接口使其与外部发生联系。用户无需关心对象内部的细节,但可以通过对象对外提供的接口来访问该对象。
多态:多态分为编译时多态和运行时多态
- 编译时多态主要指方法的重载
- 运行时多态指程序中定义的对象引用所指向的具体类型在运行期间才确定
运行时多态有三个条件:
- 继承
- 覆盖(重写)
- 向上转型
4. 修饰符:public;protect;default;private优先级
可以对类或类中的成员(字段和方法)加上访问修饰符。
- 类可见表示其它类可以用这个类创建实例对象。
- 成员可见表示其它类可以用这个类的实例对象访问到该成员;
| 同一个类 |
同一个包 |
不同包的子类 |
不同包的非子类 |
|
| Private |
√ |
|
|
|
| Default |
√ |
√ |
|
|
| Protected |
√ |
√ |
√ |
|
| Public |
√ |
√ |
√ |
√ |
5. 对string类的理解。stringbuffer 和 stringbuilder
1. 可变性
- String 不可变
- StringBuffer 和 StringBuilder 可变
2. 线程安全
- String 不可变,因此是线程安全的
- StringBuilder 不是线程安全的
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
String分析:
- String有常量池(指的是在编译期被确定,并被保存在已编译的.class文件中的一些数据)
- 存在于.class文件中的常量池,在运行期被JVM装载,可以使用String的intern()方法扩充常量池。
- 但对于new String()创建的字符串。因为不能在编译时确定所以不能加入常量池
- private final char value[];是string的值,所以string字符串声明后值属性是不可变的;
6. 反射机制介绍一下
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
类加载相当于 Class 对象的加载,类在第一次使用时才动态加载到 JVM 中。也可以使用 Class.forName("com.mysql.jdbc.Driver") 这种方式来控制类的加载,该方法会返回一个 Class 对象。
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
- Field :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
- Method :可以使用 invoke() 方法调用与 Method 对象关联的方法;
- Constructor :可以用 Constructor 的 newInstance() 创建新的对象。
反射的优点:
- 可扩展性 :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
- 类浏览器和可视化开发环境 :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
- 调试器和测试工具 : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
反射的缺点:
尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
-
性能开销 :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
-
安全限制 :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
-
内部暴露 :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
7. bio,nio,aio分别介绍一下,nio的实现方式
- BIO 就是传统的 java.io 包,它是基于流模型实现的,交互的方式是同步、阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。它的优点就是代码比较简单、直观;缺点就是 IO 的效率和扩展性很低,容易成为应用性能瓶颈。
- NIO 是 Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层高性能的数据操作方式。
- AIO 是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的 IO 操作方式,因此人们叫它 AIO(Asynchronous IO),异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
- 简单来说 BIO 就是传统 IO 包,产生的最早;NIO 是对 BIO 的改进提供了多路复用的同步非阻塞 IO,而 AIO 是 NIO 的升级,提供了异步非阻塞 IO。
NIO服务端实现:
服务端所有的Channel都需要向Selector注册,而Selector负责监视这些Socket的IO状态。通过Selector的select()方法返回该Selector上有多少个Channel具有可用的IO。通过selectedKeys()方法来返回这些Channel对应的集合。
客户端实现:
创建Socket
获取输出流
输出比特流
释放输出流
8. 问了public等变量定义修饰词的时间域
9. 问了反射机制,还有问了动态代理的好处和坏处,好处答不上来
动态代理基本格式:
实现InvocationHandler接口
并实现invoke方法:在invoke方法调用实现类方法前后可以做AOP编程
public class DynamicProxy {
public static void main(String[] args) {
Lennova lennova = new Lennova();
SaleComputer proxyInstance = (SaleComputer) Proxy.newProxyInstance(lennova.getClass().getClassLoader(), lennova.getClass().getInterfaces(), new InvocationHandler() {
@Override//不管调用被代理对象的什么方法,invoke方法都会被执行
/*proxy参数表示代理对象
method表示代理对象调用的方法,被封装为对象
* */
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//调用方法前的操作,可以以此增强方法,实现AOP编程
System.out.println("方法执行前");
System.out.println(method.getName());
return null;
}
});
System.out.println(proxyInstance.sale("4000"));
}
}好处:Java动态代理的优势是实现无侵入式的代码扩展,也就是方法的增强
坏处:使用了反射机制,效率低
10. 接口和抽象类的区别。
1. 抽象类
抽象类和抽象方法都使用 abstract 关键字进行声明。如果一个类中包含抽象方法,那么这个类必须声明为抽象类。
抽象类和普通类最大的区别是,抽象类不能被实例化,只能被继承。
2. 接口
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类,让它们都实现新增的方法。
接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。从 Java 9 开始,允许将方法定义为 private,这样就能定义某些复用的代码又不会把方法暴露出去。
接口的字段默认都是 static 和 final 的。
3. 比较
- 从设计层面上看,抽象类提供了一种 IS-A 关系,需要满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
4. 使用选择
使用接口:
- 需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Comparable 接口中的 compareTo() 方法;
- 需要使用多重继承。
使用抽象类:
- 需要在几个相关的类中共享代码。
- 需要能控制继承来的成员的访问权限,而不是都为 public。
- 需要继承非静态和非常量字段。
在很多情况下,接口优先于抽象类。因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
11. 有一个public static final的HashMap,里边对象的属性能不能修改?
先导概念:
- 对于基本类型,final 使数值不变;
- 对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
- 静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份。
- 实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
可以的,你只是修改了引用,修改属性就是在修改对象,可变的属性,比如size、modCount、threshold都不影响。final修饰的更不影响。
但如果你尝试重新初始化这个引用,就会报错,final不能初始化
12. 为什么java 平台无关性 机器码和字节码区别 JVM加载代码的一个流程
1.JavaC将Java语言编译成.class文件(字节码文件),在不同操作系统的JVM再将.class文件翻译成特定平台的执行指令
2.
字节码:Java源代码经过虚拟机编译器编译后产生的文件(即扩展为.class的文件),它不面向任何特定的处理器,只面向虚拟机。
采用字节码的好处:Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
3.Java源代码---->编译器---->jvm可执行的Java字节码(即虚拟指令)---->jvm---->jvm中解释器----->机器可执行的二进制机器码---->程序运行。
13. java数据类型以及自己的应用 自动拆箱和自动装箱以及自己的应用即什么时候用到的,列举几种情况
基本类型
- byte/8
- char/16
- short/16
- int/32
- float/32
- long/64
- double/64
- boolean/~
boolean 只有两个值:true、false,可以使用 1 bit 来存储,但是具体大小没有明确规定。JVM 会在编译时期将 boolean 类型的数据转换为 int,使用 1 来表示 true,0 表示 false。JVM 支持 boolean 数组,但是是通过读写 byte 数组来实现的。
包装类型
基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
Integer x = 2; // 装箱 调用了 Integer.valueOf(2)
int y = x; // 拆箱 调用了 X.intValue()应用场景
向集合传递泛型时、对集合添加获取元素时,有关泛型的其他操作等,因为泛型只能为引用数据类型(不能为基本数据类型)
14. 什么是值传递和引用传递,区别及应用
(1):“在Java里面参数传递都是按值传递”这句话的意思是:按值传递是传递的值的拷贝,按引用传递其实传递的是引用的地址值,所以统称按值传递。
(2):在Java里面只有基本类型和按照下面这种定义方式的String是按值传递,其它的都是按引用传递。就是直接使用双引号定义字符串方式:String str = “Java”;
15. 重载和重写
1. 重写(Override)
存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的一个方法。
为了满足里式替换原则,重写有以下三个限制:
- 子类方法的访问权限必须大于等于父类方法;
- 子类方法的返回类型必须是父类方法返回类型或为其子类型。
- 子类方法抛出的异常类型必须是父类抛出异常类型或为其子类型。
2. 重载(Overload)
存在于同一个类中,指一个方法与已经存在的方法名称上相同,但是参数类型、个数、顺序至少有一个不同。
应该注意的是,返回值不同,其它都相同不算是重载。
16. static方法是否能重写,接口和抽象类的区别
不能被重写,虽然能通过编译,但最后调用的还是父类的方法,而不会被子类覆盖
17. 你觉得java是一种什么样的语言以及java特性
Java的优点
1.平台无关性平台无关性是指Java能运行于不同的平台。Java引进虚拟机 原理,并运行于虚拟机,实现不同平台的Java接口之间。使用Java编写的程序能在世界范围内共享。Java的数据类型与 机器无关,Java虚拟机(Java Virtual Machine)是建立在硬件和操作系统之上,实现Java二进制代码的解释执行功能, 提供于不同平台的接口的。
2.安全性Java的编程类似C++,学习过C++的读者将很快掌握Java的精髓。Java舍弃了C++的指针对存储器地址的直接操作,程序运行时,内存由操作系统分配,这样可以避免病毒通过指针侵入系统。Java对程序提供了安全管理器,防止程序的非法访问。
3.面向对象Java吸取了C++面向对象的概念,将数据封装于类中,利用类的优点,实现了程序的简洁性和便于维护性。类的封装性、继承性等有关对象的特性,使程序代码只需一次编译,然后通过上述特性反复利用。
4.分布式Java建立在扩展TCP/IP网络平台上。库函数提供了用HTTP和FTP协议传送和接受信息的方法。这使得程序员使用网络上的文件和使用本机文件一样容易。
5.健壮性Java致力于检查程序在编译和运行时的错误。类型检查帮助检查出许多开发早期出现的错误。Java自己操纵内存减少了内存出错的可能性。Java还实现了真数组,避免了覆盖数据的可能,这些功能特征大大提高了开发Java应用程序的周期。并且Java还提供了Null指针检测、数组边界检测、异常出口、Byte code校验等功能。
6.解释型我们知道C,C++等语言,都是针对CPU芯片进行编译,生成机器代码,该代码的运行就和特定的CPU有关。Java不像C或C++,它不针对CPU芯片进行编译,而是把程序编译成称为自字节码的一种“中间代码”。字节码是很接近机器码的文件,可以在提供了java虚拟机(JVM)的任何系统上被解释执行。
7.动态Java语言设计成适应于变化的环境,它是一个动态的语言。例如,Java中的类是根据需要载入的,甚至有些是通过网络获取的。
Java的缺点
第一: 运行速度慢,众所周知,Java程序的运行依赖于Java虚拟机,所以相对于其他语言(汇编,C,C++)编写的程序慢,因为它不是直接,执行机器码。
第二: 因为Java考虑到了跨平台性。所以他不能像语言(例如:汇编,C) 那样更接近操作系统。也就不能和操作系统的底层打交道了。但可以通过Java的JNI(即Java本地接口。
18. lamda表达式了解吗?1.8新特性有什么?(面试宝典对接口抽象这个问题是错的,过时了)
19. 内存泄露怎么造成的,怎么排查
1.1 内存溢出
java.lang.OutOfMemoryError,是指程序在申请内存时,没有足够的内存空间供其使用,出现OutOfMemoryError。
产生原因
产生该错误的原因主要包括:
- JVM内存过小。
- 程序不严密,产生了过多的垃圾。
1.2 内存泄露
Memory Leak,是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
在Java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点:
1)首先,这些对象是可达的,即在有向图中,存在通路可以与其相连;
2)其次,这些对象是无用的,即程序以后不会再使用这些对象。
如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。
关于内存泄露的处理页就是提高程序的健壮型,因为内存泄露是纯代码层面的问题。
1.3 内存溢出和内存泄露的联系
内存泄露会最终会导致内存溢出。
相同点:都会导致应用程序运行出现问题,性能下降或挂起。
不同点:1) 内存泄露是导致内存溢出的原因之一,内存泄露积累起来将导致内存溢出。2) 内存泄露可以通过完善代码来避免,内存溢出可以通过调整配置来减少发生频率,但无法彻底避免。
20. 讲讲final修饰符。
final
1. 数据
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
- 对于基本类型,final 使数值不变;
- 对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
final int x = 1;
// x = 2; // cannot assign value to final variable 'x'
final A y = new A();
y.a = 1;2. 方法
声明方法不能被子类重写。
private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
3. 类
声明类不允许被继承。
21. 一个对象占多少内存。
Java 对象
HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
Java 对象头包括Mark Word,Class Metadata Address,ArrayList(数组对象)三部分。
Mark Word(32/64 bit)
HotSpot虚拟机的对象头(Object Header)包括两部分信息,第一部分用于存储对象自身的运行时数据, 如哈希值(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,这部分数据的长度在32位和64位的虚拟机(暂不考虑开启压缩指针的场景)中分别为32个和64个Bits,官方称它为“Mark Word”。
Class Metadata Address(32/64 bit)
存储该对象的Class 对象的地址,就是该对象属于那个Class。
ArrayList(32/64 bit)
存储数组的长度,如果是数组对象才会有此数据。非数组对象没有此数据。
32位系统:
对象头占用:32+32=64bit。 64bit/8=8byte。
数组对象头占用:32+32+32=96bit。 96bit/8=12byte。
64位系统:
对象头占用:64+64=128bit。128bit/8=16byte。
数组对象头占用:64+64+64=192bit。 192bit/8=24byte。
实例数据
实例数据就是,对象中的实例变量。
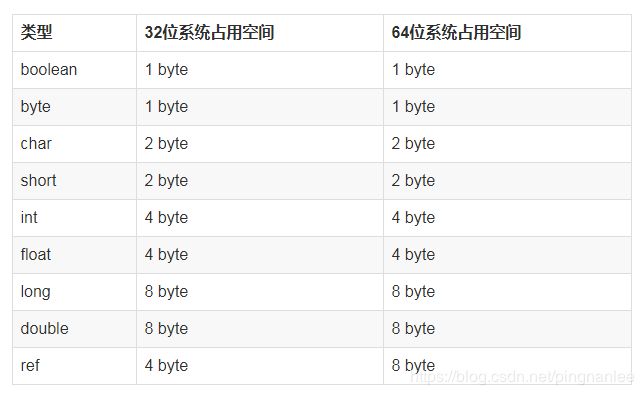
实例变量类型分为:基本类型和引用类型。在这里插入图片描述
对齐填充
对象在堆中分配的最新存储单位是8byte。如果存储的数据不够8byte的倍数,则对齐填充够8的倍数个字节。
最后需要注意一点就是从JDK 1.6 update14开始 64bit的jvm默认是开启了UseCompressedOops,而且这个参数也只是针对64bit的jvm有效。所以java对象占用内存的大小会小于等于我们正常计算出的对象大小。
22. 最短路径问题
23. java浅拷贝和深拷贝
浅拷贝:
拷贝对象与原始对象引用同一个对象(等于只拷贝了引用)
public class ShallowCloneExample implements Cloneable {
private int[] arr;
public ShallowCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
@Override
protected ShallowCloneExample clone() throws CloneNotSupportedException {
return (ShallowCloneExample) super.clone();
}
}
核心就是return (类名)super.clone();
深拷贝:
拷贝对象和原始对象的引用类型引用不同对象。
public class DeepCloneExample implements Cloneable {
private int[] arr;
public DeepCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
@Override
protected DeepCloneExample clone() throws CloneNotSupportedException {
DeepCloneExample result = (DeepCloneExample) super.clone();
result.arr = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
result.arr[i] = arr[i];
}
return result;
}
}
可以理解为:重新生成了对象,并完全复制了数据
4. clone() 的替代方案
使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
24. 内存泄露的原因和处理
25. java反射机制,优点缺点
26. 说说静态变量和非静态变量的区别,用类名调用静态变量和用实例对象调用静态变量有区别吗?非静态方法里可以有静态变量吗?
1. 静态变量
- 静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份。
- 实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
2. 静态方法
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法。
只能访问所属类的静态字段和静态方法,方法中不能有 this 和 super 关键字,因此这两个关键字与具体对象关联。
3. 静态语句块
静态语句块在类初始化时运行一次。
4. 静态内部类
非静态内部类依赖于外部类的实例,也就是说需要先创建外部类实例,才能用这个实例去创建非静态内部类。而静态内部类不需要。
5. 初始化顺序
静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
存在继承的情况下,初始化顺序为:
- 父类(静态变量、静态语句块)
- 子类(静态变量、静态语句块)
- 父类(实例变量、普通语句块)
- 父类(构造函数)
- 子类(实例变量、普通语句块)
- 子类(构造函数)
27. static能不能被重写?
- 重写方法的目的是为了多态,或者说:重写是实现多态的前提,即重写是发生在继承中且是针对非static方法的。
语法上子类允许出现和父类只有方法体不一样其他都一模一样的static方法,但是在父类引用指向子类对象时,通过父类引用调用的依然是父类的static方法,而不是子类的static方法。
即:语法上static支持重写,但是运行效果上达不到多态目的
28. 序列化,反序列化,什么时候用? 如何对一个对象序列化
序列化
序列化就是将一个对象转换成字节序列,方便存储和传输。
- 序列化:ObjectOutputStream.writeObject()
- 反序列化:ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
Serializable
序列化的类需要实现 Serializable 接口,它只是一个标准,没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
transient
transient 关键字可以使一些属性不会被序列化。
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
如何序列化:某些框架带有实现方式
Java集合类
Hashmap底层(数组+链表+红黑树)hashmap为什么线程不安全,如何保证线程安全,就扯到concurrenthashmap hashmap底层实现 多线程会出现什么情况 扩容机制是什么为什么会死锁 如何解决碰撞 Jdk 1.8的优化。为什么使用红黑树,它是如何做到效率优化的? hashmap了解不,原理是什么,位图了解不,跳跃表了解不,红黑树了解不,红黑树插入过程,B+树了解不,B+树特点和插入过程,邻接表和邻接矩阵区别,分别在什么地方用到,
插入和查询的流程。
HashMap底层:数组+链表/红黑树,将key的hashCode高16位异或低16位再取余length-1得到索引,当索引重复时将新键值对追加到桶的链表尾,当桶中的链表节点超过8就树化,因为8时查树的效率+树化的成本>=查表的效率
线程不安全是因为,在多线程操作hashMap时resize容易形成链表环(因为需要将节点取出来,其中一个线程设置节点e=e.next,另一个线程修改e=之前的某个节点)。
ConcurrentHashMap:
只是增加了Segment(分段锁),每个分段锁维护几个桶,
和 HashMap的桶 非常类似,只是核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性。
默认16个分段锁,多个线程可以同时访问不同分段锁的桶,并发量就是分段锁个数
只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
put
先定位到SegMent,尝试获取锁,如果失败就尝试自旋获取锁,如果超过最大尝试次数就改为阻塞锁,将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。之后的操作和HashMap相同,最后释放锁
1.8的改进
put
根据 key 计算出 hashcode 。
判断是否需要进行初始化。
f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
如果都不满足,则利用 synchronized 锁写入数据。
如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
红黑树
https://tech.meituan.com/2016/12/02/redblack-tree.html
红黑树定义:
1.任何一个节点都有颜色,黑色或者红色。
2.根节点是黑色的。
3.父子节点之间不能出现两个连续的红节点。
4.任何一个节点向下遍历到其子孙的叶子节点,所经过的黑节点个数必须相等。
5.空节点被认为是黑色的。
注:新插入的节点都为红色,所以只有父节点为红色时才需要修复
红黑树插入修复:
左旋:右节点上升为父节点(原父节点变为左节点)。右旋反之
case1:叔叔节点也为红色。
将父节点和叔叔节点与祖父节点的颜色互换。接着判断祖父节点的父节点是否为黑色,如果不是则继续修复
case2:叔叔节点为空,祖父节点、父节点和新节点处于一条斜线上。(可以理解为这三代的树退化成了链表)
如果他们都在左边的斜线上,将父节点右旋并且父节点和祖父节点互换颜色。
如果他们都在右边的斜线上,将父节点左旋......
case3:叔叔节点为空,祖父节点、父节点和新节点不处于一条斜线上。
(可以理解为这三代的树退化成了链表,但有没有在同一边)
我们判断父-子节点和祖父-父节点的偏移方向,比如父节点在祖父节点的右儿子位置,而子节点在父节点的左儿子位置。我们让子节点右旋,子节点就变成了父节点。且祖父-父-子节点都处于同一斜线上,这时就可以按照case2处理了
红黑树删除操作
删除前先找到中序遍历的后继节点来顶替要删除的节点
只有删除黑色节点时才需要删除修复操作(因为删除黑色结点后,不满足经过的黑色结点数相同,就需要补黑色结点,如果不能补,就得把每一级的黑色结点数减去一个)
删除黑色节点后分四种情况修复:
case1:待删除的节点的兄弟节点是红色的节点
如果兄弟结点在右,就对兄弟节点左旋,并将兄弟结点和原父结点颜色互换(注意,兄弟结点左旋后变为父节点,原来的父节点就变成了它的左子树,那它原来的左子树就要重新插入)
反之相反
case2:待删除的结点的兄弟结点是黑色的结点,且兄弟结点的子节点都是黑色的。
把兄弟节点变红(等于减去一个黑色结点),在这一级就平衡了。但父节点可能也是红色,那就需要按之前的原则调整(左右旋、交换颜色等)
把父节点看作新节点,继续向上调整()
B+树https://www.cnblogs.com/nullzx/p/8729425.html
各种资料上B+树的定义各有不同,一种定义方式是关键字个数和孩子结点个数相同。这里我们采取维基百科上所定义的方式,即关键字个数比孩子结点个数小1,这种方式是和B树基本等价的。上图就是一颗阶数为4的B+树。
除此之外B+树还有以下的要求。
1)B+树包含2种类型的结点:内部结点(也称索引结点)和叶子结点。根结点本身即可以是内部结点,也可以是叶子结点。根结点的关键字个数最少可以只有1个。
2)B+树与B树最大的不同是内部结点不保存数据,只用于索引,所有数据(或者说记录)都保存在叶子结点中。
3) m阶B+树表示了内部结点最多有m-1个关键字(或者说内部结点最多有m个子树),阶数m同时限制了叶子结点最多存储m-1个记录。
4)内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
5)每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
B+树的特点
为什么说B+树比B树更适合实际应用中作为操作系统的文件索引和数据库索引?
(1)B+树的磁盘读写代价更低
非叶子节点包含的信息更少,如果把同一节点的所有信息放在一个磁盘块中,则可以比B树放入更多的关键码。一次读入内存当中(读一个块)就能读入更多的关键码,所以降低了磁盘I/O总数。
(2)查询效率更加稳定
对任何关键字的查找都必须从根节点走到叶子节点,路径长度相同,所以对每条数据的查询效率相当。
(3)B树在提高磁盘I/O性能的同时并没有解决元素遍历效率低下的问题。而B+树因为叶子节点有链指针存在,所以遍历叶子节点即可以实现对整棵树的遍历。而在数据库中基于范围的查询是非常频繁的,B+树就能更好的支持。
与红黑树的比较
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+ Tree 作为索引结构,主要有以下两个
原因:
(一)更少的查找次数
平衡树查找操作的时间复杂度和树高 h 相关,O(h)=O(log d N),其中 d 为每个节点的出度。
红黑树的出度为 2,而 B+ Tree 的出度一般都非常大,所以红黑树的树高 h 很明显比 B+ Tree 大非常多,查找的次数
也就更多。
(二)利用磁盘预读特性
为了减少磁盘 I/O 操作,磁盘往往不是严格按需读取,而是每次都会预读。预读过程中,磁盘进行顺序读取,顺序读
取不需要进行磁盘寻道,并且只需要很短的磁盘旋转时间,速度会非常快。
操作系统一般将内存和磁盘分割成固定大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将
索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点。并且可以利用预读特性,相邻的节点
也能够被预先载入。
B+树的插入操作
1)若为空树,创建一个叶子结点,然后将记录插入其中,此时这个叶子结点也是根结点,插入操作结束。
2)针对叶子类型结点:根据key值找到叶子结点,向这个叶子结点插入记录。插入后,若当前结点key的个数小于等于m-1,则插入结束。否则将这个叶子结点分裂成左右两个叶子结点,左叶子结点包含前m/2个记录,右结点包含剩下的记录,将第m/2+1个记录的key进位到父结点中(父结点一定是索引类型结点),进位到父结点的key左孩子指针向左结点,右孩子指针向右结点。将当前结点的指针指向父结点,然后执行第3步。
3)针对索引类型结点:若当前结点key的个数小于等于m-1,则插入结束。否则,将这个索引类型结点分裂成两个索引结点,左索引结点包含前(m-1)/2个key,右结点包含m-(m-1)/2个key,将第m/2个key进位到父结点中,进位到父结点的key左孩子指向左结点, 进位到父结点的key右孩子指向右结点。将当前结点的指针指向父结点,然后重复第3步。
concurrenthashmap1.7和1.8的区别;concurrenthashmap说说,它是如何保证线程安全的?jdk1.7的hashentry和segment锁。具体说说segment锁?能讲下ConcurrentHashMap的实现原理么 JDK7或者8都行
常用集合类 实现类
List、Queue、Deque、Stack、Map、Set
list和set区别(重复/不重复)
(1)重复对象
list方法可以允许重复的对象,而set方法不允许重复对象
(2)null元素
list可以插入多个null元素,而set只允许插入一个null元素
(3)容器是否有序
list是一个有序的容器,保持了每个元素的插入顺序。即输出顺序就是输入顺序,而set方法是无序容器,无法保证每个元素的存储顺序,TreeSet通过 Comparator 或者 Comparable 维护了一个排序顺序
set,list,map(线程安全的map,map怎么实现之类的)
红黑树介绍一下,跟平衡二叉树比较一下,红黑树有哪些应用场景
你常用的数据结构有哪些?
红黑树的特点,AVL树
AVL树:自平衡二叉搜索树、最大高度差1、频繁平衡导致效率低下
一致性哈希函数以及hashmap的put方法
HashCode%length-1
结果分布在(0~length-1)的索引中
数组、二叉搜索树、B树、B+树
堆和栈。堆、栈
堆的定义:https://blog.csdn.net/SZU_Crayon/article/details/81812946?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.not_use_machine_learn_pai&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.not_use_machine_learn_pai
1.建立在完全二叉树的基础上
2.排序算法的一种,也是稳定效率最高的一种//堆排序,可以理解为从两堆牌中一张一张的拿,每次捡大的
3.可用于实现STL中的优先队列(priority_queue)
优先队列:一种特殊的队列,队列中元素出栈的顺序是按照元素的优先权大小,而不是元素入队的先后顺序
4.两类:
a.最大堆:
①根的值大于左右子树的值 ②子树也是最大堆
b.最小堆:
①根的值小于左右子树的值 ②子树也是最小堆
堆的实现:
堆一般用数组表示
1.插入(Insert):
以最大堆为栗子,插入其实就是把插入结点放在堆最后面,然后与父亲比较,如果父亲值小于它,那么它就和父亲结点交换位置,重复该过程,直到插入节点遇到一个值比它大的父亲或者它成为树根结点
2.删除(Pop):
删除就是删除最大堆中的最大值或者最小堆中的最小值,也就是树根
以删除最大堆树根为例子,删除其实就是整个堆中少了一个结点,不妨把位于最后面的一个结点当成新的树根,然后与它左右孩子比较,与值最大并且值大于它的孩子进行交换(好好读这句话),直到它的孩子都是小于它的,或者变成树叶
JVM中堆与栈的区别:https://blog.csdn.net/pt666/article/details/70876410
1.栈内存存储的是局部变量而堆内存存储的是实体;
2.栈内存的更新速度要快于堆内存,因为局部变量的生命周期很短;
3.栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。
二叉树的最大节点个数;2^n-1;
Java并发
- java创建线程的方式,runnable和callable区别(参数不同)1. java线程的状态有哪些;线程的几种状态
- wait和sleep的区别;wait和notify的使用场景;
- 介绍一下volatile以及原理;volatile介绍一下Volatile底层是如何实现的? 说了内存可见性和内存屏障,Volatile是绝对线2程安全的吗?不是,没有保证原子性。volatile关键字在线程通信的问题
- 介绍一下synchornized以及原理; lock和synchornized的区别;synchronized锁的升级过程?Synchronized,底层是如何实现的?说了monitor对象头,以及两个monitorenter和monitorexit运用于代码块。
对象头是存储了哪些信息?说说synchronized的锁优化过程?说了偏向,自旋,轻量和重量。 - 介绍一下AQS;
- 说一下公平锁和非公平锁的原理;
- cas操作是什么,以及可能出现的问题;
- 线程池,然后你再平时怎么用的,工作原理,有哪些重要参数,饱和策略有哪些;线程池了解吧,说说如何实现线程池?核心参数哪些?有哪些阻塞队列呢?如何优雅的关闭线程池 线程池(线程大小,阻塞队列)线程创建,线程池参数,说说你常用的线程池?说了new ***d 和newFixed。以及介绍各个参数
- 说说你理解的悲观锁和乐观锁?乐观锁有哪些?乐观锁有什么缺点?
- 阻塞队列 线程间通信方式 创建线程方式 创建线程池方式 线程池常用参数
- 锁有哪些
- 说说你常用的并发包JUI?
- 问了如何保证多线程通信
- 你用过Java的J.U.C并发包吧,给我讲一下AQS的原理
- CAS的原理给我讲一下,他是怎么保证内存的可见性的。CAS会产生什么问题
-
CAS(Compare And Swap)也称乐观锁。对应的Synchronized也称悲观锁
思想:
CAS使用三个基本操作数:内存地址V、旧的预期值A、要修改的新值B
在对数据修改时:先判断内存地址中的值是否和预期相同,如果相同就修改,如果就重新计算新值B,比如我要做A++的操作,A变了,我要修改的值当然也要变,如果和预期值相同就修改为B。
这里的判断和修改是原子操作,所以不需要的担心线程安全问题实现:Concurrent包下的Atomic包中的数据类型(如AtomicInteger、AtomicLong)是基于CAS实现的
自旋锁:循环判断是否有锁,没有就加锁,仅适用于锁的竞争不激烈、且占用时间短的情况
- 知道Java中的内存模型吧,它有8个指令你给我说一下
- 多线程如何保持同步?
- java可见性的关键字及其原理。
- cpu密集型多线程和io密集型多线程的比较。cpu密集型里如何管理多线程? 用什么样的线程池和阻塞队列?
- cpu线程特别多会产生什么问题?io密集型里怎么减少需要的线程数?
- io多路复用的原理和实现。怎么减少处理io(和磁盘io交互)所需要的线程?
- 线程实现方式。有什么区别。线程之间的通讯,进程之间的通讯。
JVM
JVM运行时内存区域划分?哪些线程私有?运行时数据区,私有共享都是哪些?堆区内存如何分配?
一、运行时数据区域

程序计数器
记录正在执行的虚拟机字节码指令的地址(如果正在执行的是本地方法则为空)。
Java 虚拟机栈
每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
可以通过 -Xss 这个虚拟机参数来指定每个线程的 Java 虚拟机栈内存大小,在 JDK 1.4 中默认为 256K,而在 JDK 1.5+ 默认为 1M:
java -Xss2M HackTheJava该区域可能抛出以下异常:
当线程请求的栈深度超过最大值,会抛出 StackOverflowError 异常;
栈进行动态扩展时如果无法申请到足够内存,会抛出 OutOfMemoryError 异常。
新生代(Young Generation)
老年代(Old Generation)
对象的生命周期?
创建阶段(Created)
-
在创建阶段系统通过以下几个步骤来完成对象的创建
public Dog getDog() { Dog dog = new Dog(); return dog; }一旦对象被创建,并分派给某些变量赋值,这个对象的状态就切换到了应用状态
- 为对象分配存储空间
- 开始构造对象
- 从父类到子类对static成员进行初始化
- 父类成员按顺序初始化,递归调用父类的构造方法
- 子类成员变量按顺序初始化,调用子类的构造方法
应用阶段(In Use)
对象至少被一个强引用持有称为处于应用阶段,一个对象可以有多个强引用,GC不会回收处于应用状态的对象
Dog dog = new Dog();
不可见阶段
强引用对象超出其作用域之后就变为不可见,当一个对象处于不可见阶段是,说明程序本身不再持有该对象的不论说明强引用,尽管这些引用仍然是存在的。
不可达阶段
在虚拟机所管理的对象引用根集合再也找不到直接或间接的强引用,这些对象通常是指所有线程栈中的临时变量,所有已装载的类的静态变量或者本地代码接口的引用。这些对象都是要被垃圾回收回收的预备对象,但此时该对象并不能被垃圾回收器直接回收。其实所有垃圾回收算法所面临的问题是相同的——找出由分配器分配的,但是用户程序不可到达的内存块。
收集阶段(Collected)
当垃圾回收器发现该对象已经处于“不可达阶段”而且垃圾回收器已经对该对象内存空间的又一次分配做好了准备是,则对象进入了“收集阶段”。假设该对象已经重写了finalize方法,则回去运行该方法的终端操作。
注意:不要重载finazlie()方法!
原因有两点:
会影响JVM的对象分配与回收速度
在分配该对象时,JVM要在垃圾回收器上注册该对象,以便在回收时可以运行该重载方法;在该方法的运行时要消耗CPU时间且在运行完该方法后才会又一次运行回收操作,即至少需要垃圾回收器对该对象运行两次GC
可能造成该对象的再次“复活”
在finzlize()方法中,假设有其它的强引用再次持有该对象,则会导致对象的状态由“收集阶段”又一次变为“应用阶段”。这个已经破坏了Java对象的生命周期进程,且“复活”的对象不利于代码管理。
终结阶段
当对象运行完finalize()方法后仍然处于不可达状态时,则该对象进入终结阶段。在该阶段是等待垃圾回收器对该对象空间进行回收。
对象空间的又一次分配阶段
垃圾回收器对该对象的所占内存空间进行回收或者再分配了,则该对象彻底消失了,称之为“对象空间的又一次分配阶段”。
JVM垃圾回收器,cms和g1的特点,两者的区别是什么,比g1更加先进的垃圾回收器有了解么,ZGC原理,能够管理多大的内存,CMS能管理多大的内存,G1呢
CMS(Concurrent Mark Sweep),Mark Sweep 指的是标记 - 清除算法。
分为以下四个流程:
- 初始标记:仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,需要停顿。
- 并发标记:进行 GC Roots Tracing 的过程,它在整个回收过程中耗时最长,不需要停顿。
- 重新标记:为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,需要停顿。
- 并发清除:不需要停顿。
在整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,不需要进行停顿。
具有以下缺点:
- 吞吐量低:低停顿时间是以牺牲吞吐量为代价的,导致 CPU 利用率不够高。
- 无法处理浮动垃圾,可能出现 Concurrent Mode Failure。浮动垃圾是指并发清除阶段由于用户线程继续运行而产生的垃圾,这部分垃圾只能到下一次 GC 时才能进行回收。由于浮动垃圾的存在,因此需要预留出一部分内存,意味着 CMS 收集不能像其它收集器那样等待老年代快满的时候再回收。如果预留的内存不够存放浮动垃圾,就会出现 Concurrent Mode Failure,这时虚拟机将临时启用 Serial Old 来替代 CMS。
- 标记 - 清除算法导致的空间碎片,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象,不得不提前触发一次 Full GC。
7. G1 收集器
G1(Garbage-First),它是一款面向服务端应用的 是整个新生代或者老年代,而 G1 可以直接对新生代和老年代一起回收。
G1 把堆划分成多个大小相等的独立区域(Region),新生代和老年代不再物理隔离。
通过引入 Region 的概念,从而将原来的一整块内存空间划分成多个的小空间,使得每个小空间可以单独进行垃圾回收。这种划分方法带来了很大的灵活性,使得可预测的停顿时间模型成为可能。通过记录每个 Region 垃圾回收时间以及回收所获得的空间(这两个值是通过过去回收的经验获得),并维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region。
每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region。通过使用 Remembered Set,在做可达性分析的时候就可以避免全堆扫描。
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
- 初始标记
- 并发标记
- 最终标记:为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中。这阶段需要停顿线程,但是可并行执行。
- 筛选回收:首先对各个 Region 中的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
具备如下特点:
- 空间整合:整体来看是基于“标记 - 整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
- 可预测的停顿:能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒。
JVM内存模型 类的生命周期 类加载过程 双亲委派机制了解吗 进入老年代过程 什么情况下直接进入老年代
JVM内存分布(堆栈等,程序计数器+jvm栈+本地方法栈线程不共享,堆和方法区线程共享)
类加载机制,过程,类加载机制?如何自定义实现类加载器?双亲委派模型、类加载器类别,双亲委派模型本质是解决了什么问题?安全性,有哪几种类加载器?类加载的流程。知道哪些类加载器。类加载器之间的关系?双亲委派模型。为什么使用双亲委派模型?
类是在运行期间第一次使用时动态加载的,而不是一次性加载所有类。因为如果一次性加载,那么会占用很多的内存。
- 加载(Loading)
- 验证(Verification)
- 准备(Preparation)
- 解析(Resolution)
- 初始化(Initialization)
- 使用(Using)
- 卸载(Unloading)
垃圾回收算法,常见的垃圾回收器及他们之间区别,垃圾回收发生在哪里,怎么判断对象存活、GC Roots具体有哪些、讲讲对象分配与回收,什么可以作为垃圾回收的对象,垃圾回收算法和流程。
垃圾回收算法
1. 标记 - 清除
在标记阶段,程序会检查每个对象是否为活动对象,如果是活动对象,则程序会在对象头部打上标记。
在清除阶段,会进行对象回收并取消标志位,另外,还会判断回收后的分块与前一个空闲分块是否连续,若连续,会合并这两个分块。回收对象就是把对象作为分块,连接到被称为 “空闲链表” 的单向链表,之后进行分配时只需要遍历这个空闲链表,就可以找到分块。
在分配时,程序会搜索空闲链表寻找空间大于等于新对象大小 size 的块 block。如果它找到的块等于 size,会直接返回这个分块;如果找到的块大于 size,会将块分割成大小为 size 与 (block - size) 的两部分,返回大小为 size 的分块,并把大小为 (block - size) 的块返回给空闲链表。
不足:
- 标记和清除过程效率都不高;
- 会产生大量不连续的内存碎片,导致无法给大对象分配内存。
2. 标记 - 整理
让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
优点:
- 不会产生内存碎片
不足:
- 需要移动大量对象,处理效率比较低。
3. 复制
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
主要不足是只使用了内存的一半。
对象存活判断
1. 引用计数算法
可能出现循环引用
2. 可达性分析算法
以 GC Roots 为起始点进行搜索,可达的对象都是存活的,不可达的对象可被回收
3. 方法区的回收
因为方法区主要存放永久代对象,而永久代对象的回收率比新生代低很多,所以在方法区上进行回收性价比不高。
栈什么情况下会溢出?
静态变量存放在内存哪个区域?
怎么查看java虚拟机内存占用?
linux
启动java程序,然后通过top命令
按shift+m按内存由大到小排序
在按c就可以知道命令的详情
如果是window,直接打开任务管理器,查看进程的内存消耗就行
如何减少full gc的次数?方法区是否需要gc
Minor GC 和 Full GC
-
Minor GC:回收新生代,因为新生代对象存活时间很短,因此 Minor GC 会频繁执行,执行的速度一般也会比较快。
-
Full GC:回收老年代和新生代,老年代对象其存活时间长,因此 Full GC 很少执行,执行速度会比 Minor GC 慢很多。
4个引用类型
无论是通过引用计数算法判断对象的引用数量,还是通过可达性分析算法判断对象是否可达,判定对象是否可被回收都与引用有关。
Java 提供了四种强度不同的引用类型。
1. 强引用
被强引用关联的对象不会被回收。
使用 new 一个新对象的方式来创建强引用。
Object obj = new Object();
2. 软引用
被软引用关联的对象只有在内存不够的情况下才会被回收。
使用 SoftReference 类来创建软引用。
Object obj = new Object(); SoftReference
3. 弱引用
被弱引用关联的对象一定会被回收,也就是说它只能存活到下一次垃圾回收发生之前。
使用 WeakReference 类来创建弱引用。
Object obj = new Object(); WeakReference
4. 虚引用
又称为幽灵引用或者幻影引用,一个对象是否有虚引用的存在,不会对其生存时间造成影响,也无法通过虚引用得到一个对象。
为一个对象设置虚引用的唯一目的是能在这个对象被回收时收到一个系统通知。
使用 PhantomReference 来创建虚引用。
计算机网络
输入一个url后的过程;浏览器从发送请求的全部过程
1.DNS解析
DNS解析的过程就是寻找哪台机器上有你需要资源的过程,寻找的过程遵循就近原则。
输入一个网址并按回车的时候浏览器会根据输入的URL去查找对应的IP,具体过程如下:
(1)首先是查找浏览器缓存,浏览器会保存一段时间内访问过的一些网址的DNS信息,不同浏览器保存的时常不等。
(2)如果没有找到对应的记录,这个时候浏览器会尝试调用操作系统缓存来继续查找这个网址的对应DNS信息。
(3)如果还是没找到对应的IP,那么接着会发送一个请求到路由器上,然后路由器在自己的路由器缓存上查找记录,路由器一般也存有DNS信息。
(4)如果还是没有,这个请求就会被发送到ISP(注:Internet Service Provider,互联网服务提供商,就是网络运营商,中国电信中国移动等),ISP也会有相应的ISP DNS服务器,就是本地DNS服务器,请求的域名基本上都能在这里找得到。
(5)如果还是没有的话, ISP的DNS服务器会将请求发向根域名服务器进行搜索。根域名服务器就是面向全球的顶级DNS服务器,共有13台逻辑上的服务器,从A到M命名,真正的实体服务器则有几百台,分布于全球各大洲。
(6)如果到了这里还是找不到域名的对应信息,那只能说明一个问题:这个域名本来就不存在,它没有在网上正式注册过。或者域名过期了。
这也就是为什么有时候打开一个新页面会有点慢,因为如果本地没什么缓存,查找域名的过程要这样递归地查询下去,查找完还要一层层的向上返回。例如"mp3.baidu.com",域名先是解析出这是个.com的域名,然后跑到管理.com域的服务器上进行进一步查询,然后是.baidu,最后是mp3, 所以域名结构为:三级域名.二级域名.一级域名。
所以DNS根据域名查询IP地址的过程为:浏览器缓存 --> 操作系统缓存 --> 路由器缓存-->本地(ISP)域名服务器缓存 --> 根域名服务器。
2.进行TCP连接
浏览器终于得到了IP以后,向服务器发送TCP连接,TCP连接经过三次握手。
3.浏览器发送HTTP请求
浏览器和服务器建立连接以后,浏览器接着给这个IP地址给服务器发送一个http请求,方式为get,例如访问www.baidu.com。其本质是在建立起的TCP连接中,按照HTTP协议标准发送一个索要网页的请求。
这个get请求包含了主机(Host)、用户代理(User-Agent),用户代理就是自己的浏览器,它是你的"代理人",Connection(连接属性)中的keep-alive表示浏览器告诉对方服务器在传输完现在请求的内容后不要断开连接,不断开的话下次继续连接速度就很快了。可能还会有Cookies,Cookies保存了用户的登陆信息,一般保存的是用户的JSESSIONID,在每次向服务器发送请求的时候会重复发送给服务器。
在建立连接发送请求时每个服务端需要和客户端保持通信,有很多客户端都会和服务器进行通信。服务器为了识别是哪个客户端与它通信,就必须用一个标识记录客户端的信息。客户端首次访问服务器,服务端返回响应时通过附带一个记录的客户端信息的标识来返回给客户端,这个标识就是JSESSIONID,JSESSIONID就放在了客户端的Cookies里。当客户端再次向服务器发送请求时上就使用上次记录的Cookies里面的JSESSIONID,这样服务器就知道是哪个浏览器了。这样他们之间就能保持通信了。
发送完请求接下来就是等待回应了,如下图:


4.服务器处理请求
发送完请求接下来就是等待回应了,如下图:

服务器收到浏览器的请求以后),会解析这个请求(读请求头),然后生成一个响应头和具体响应内容。接着服务器会传回来一个响应头和一个响应,响应头告诉了浏览器一些必要的信息,例如重要的Status Code,2开头如200表示一切正常,3开头表示重定向,4开头是客户端错误,如404表示请求的资源不存在,5开头表示服务器端错误。响应就是具体的要请求的页面内容。
5.浏览器解析渲染页面
(1)浏览器显示HTML
当服务器返回响应之后,浏览器读取关于这个响应的说明书(响应头),然后开始解析这个响应并在页面上显示出来。
浏览器打开一个网址的时候会慢慢加载这个页面,一部分一部分的显示,直到完全显示,知道最后的旋转进度条停止。因此在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了。
(2)浏览器向服务器发送请求获取嵌入在HTML中的对象
在浏览器显示HTML时,打开一个网页的过程中,主页(index)页面框架传送过来以后,浏览器还会因页面上的静态资源多次发起连接请求,需要获取嵌入在HTML中的其他地址的资源。这时,浏览器会发送一些请求来获取这些文件。这些内容也要一点点地请求过来,所以标签栏转啊转,内容刷啊刷,最后全部请求并加载好了就终于好了。
这时请求的内容是主页里面包含的一些资源,如图片,视频,css样式,JavaScript文件等等。
这在文件属于静态文件,首次访问会留在浏览器的缓存中,过期才会从服务器去取。缓存的内容通常不会保存很久,因为难保网站不会被改动。
静态的文件一般会从CDN中去取,CDN根据请求获取资源的时候可能还会用到负载均衡。
(3)浏览器发送异步(AJAX)请求
对于那些动态的请求,动态网页等就必须要从服务器获取了。对于静态的页面内容,浏览器通常会进行缓存,而对于动态的内容,浏览器通常不会进行缓存。对于这些动态请求,Nginx可能会专门设置一些服务器用来处理这些访问动态页面的请求。
6.关闭TCP连接
当数据完成请求到返回的过程之后,根据Connection的Keep-Alive属性可以选择是否断开TCP连接,HTTP/1.1一般支持同一个TCP多个请求,而不是1.0版本下的完成一次请求就发生断开。TCP的断开与连接不一样,断开可以分为主动关闭和被动关闭,需要经过4次握手。
当浏览器需要的全部数据都已经加载完毕,一个页面就显示完了。
OSI七层和TCP四层协议,OSI七层模型/五层模型,每一层有哪些协议,http,tcp,ip位于哪一层
1. 五层协议
应用层 :为特定应用程序提供数据传输服务,例如 HTTP、DNS 等协议。数据单位为报文。
传输层 :为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。运输层包括两种协议:传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。TCP 主要提供完整性服务,UDP 主要提供及时性服务。
网络层 :为主机提供数据传输服务。而传输层协议是为主机中的进程提供数据传输服务。网络层把传输层传递下来的报文段或者用户数据报封装成分组。
数据链路层 :网络层针对的还是主机之间的数据传输服务,而主机之间可以有很多链路,链路层协议就是为同一链路的主机提供数据传输服务。数据链路层把网络层传下来的分组封装成帧。
物理层 :考虑的是怎样在传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层的作用是尽可能屏蔽传输媒体和通信手段的差异,使数据链路层感觉不到这些差异。
2. OSI在应用层下增加了表示层和会话层
其中表示层和会话层用途如下:
表示层 :数据压缩、加密以及数据描述,这使得应用程序不必关心在各台主机中数据内部格式不同的问题。
会话层 :建立及管理会话。
五层协议没有表示层和会话层,而是将这些功能留给应用程序开发者处理。
3. TCP/IP
它只有四层,相当于五层协议中数据链路层和物理层合并为网络接口层。
TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接使用 IP 层或者网络接口层。
TCP三次握手四次分手,tcp四次挥手为什么要四次,为什么TCP是安全的,TCP,UDP的区别
TCP三次握手:

假设 A 为客户端,B 为服务器端。
1.首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。
2.A 向 B 发送连接请求报文,SYN=1,ACK=0,选择一个初始的序号 x。
3.B 收到连接请求报文,如果同意建立连接,则向 A 发送连接确认报文,SYN=1,ACK=1,确认号为 x+1,同时
也选择一个初始的序号 y。
4.A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
5.B 收到 A 的确认后,连接建立。
TCP四次挥手:

以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都
为 1。
1.A 发送连接释放报文,FIN=1。
2.B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。(注意这个时候服务器发的fin=0)
3.当 B 不再需要连接时,发送连接释放报文,FIN=1。
4.A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)后释放连接。
5.B 收到 A 的确认后释放连接。
四次挥手的原因
客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态。这个状态是为了让服
务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文。
TIME_WAIT
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器
设置的时间 2MSL。这么做有两个理由:
确保最后一个确认报文能够到达。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,
A 等待一段时间就是为了处理这种情况的发生。//简而言之:为了接受第四次挥手报文丢失后服务器新发来的释放请求
等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧
的连接请求报文。//只能说是顺便让滞留在网络中的报文失效
TCP 可靠传输
TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
TCP 滑动窗口
窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过 TCP 报文段中的窗口字段
告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
TCP 流量控制
流量控制是为了控制发送方发送速率,保证接收方来得及接收。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为
0,则发送方不能发送数据。
TCP 拥塞控制
如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当
控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接收,而拥塞控制
是为了降低整个网络的拥塞程度。
TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
UDP 和 TCP 的特点(区别)
用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文
(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多
的交互通信。
传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控
制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据
块),每一条 TCP 连接只能是点对点的(一对一)。
TCP报文结构,HTTP结构, TCP,UDP,HTTP的报文格式(我懵了)

序号 :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100
字节,那么下一个报文段的序号应为 401。
确认号 :期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据
长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
数据偏移 :指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
确认 ACK :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把
ACK 置 1。
同步 SYN :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建
立连接,则响应报文中 SYN=1,ACK=1。
终止 FIN :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
窗口 :窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空
间是有限的。
HTTP结构
请求和响应报文
HTTP请求过程:进行TCP连接后。客户端发送一个请求报文给服务器,服务器根据请求报文中的信息进行处理,并将处理结果放入响应报文中返回给客户端。
请求报文结构:
- (请求方式、URL等)第一行是包含了请求方法、URL、协议版本;
- (请求头)接下来的多行都是请求首部 Header,每个首部都有一个首部名称,以及对应的值。
- (空行)一个空行用来分隔首部和内容主体 Body
- (请求体)最后是请求的内容主体
-
GET http://www.example.com/ HTTP/1.1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 Cache-Control: max-age=0 Host: www.example.com If-Modified-Since: Thu, 17 Oct 2019 07:18:26 GMT If-None-Match: "3147526947+gzip" Proxy-Connection: keep-alive Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 xxx param1=1¶m2=2
响应报文结构:
- (响应状态码等)第一行包含协议版本、状态码以及描述,最常见的是 200 OK 表示请求成功了
- (响应头)接下来多行也是首部内容
- (空行)一个空行分隔首部和内容主体
- (响应体)最后是响应的内容主体
-
HTTP/1.1 200 OK Age: 529651 Cache-Control: max-age=604800 Connection: keep-alive Content-Encoding: gzip Content-Length: 648 Content-Type: text/html; charset=UTF-8 Date: Mon, 02 Nov 2020 17:53:39 GMT Etag: "3147526947+ident+gzip" Expires: Mon, 09 Nov 2020 17:53:39 GMT Keep-Alive: timeout=4 Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT Proxy-Connection: keep-alive Server: ECS (sjc/16DF) Vary: Accept-Encoding X-Cache: HITExample Domain // 省略...
设计一个应用层协议(没有答出来HTTP协议连接过程,HTTPS连接过程,HTTP的长连接是怎么做的HTTP2和HTTP1区别,HTTP请求过程http的几种方法,HTTP跟HTTPS的区别,https加密过程
区别
HTTP 有以下安全性问题:
- 使用明文进行通信,内容可能会被窃听;
- 不验证通信方的身份,通信方的身份有可能遭遇伪装;
- 无法证明报文的完整性,报文有可能遭篡改。
HTTPS 的缺点
- 因为需要进行加密解密等过程,因此速度会更慢;
- 需要支付证书授权的高额费用。
加密
1. 对称密钥加密
对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
优点:运算速度快;
缺点:无法安全地将密钥传输给通信方。
2.非对称密钥加密
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
优点:可以更安全地将公开密钥传输给通信发送方;
缺点:运算速度慢。
3. HTTPS 采用的加密方式
上面提到对称密钥加密方式的传输效率更高,但是无法安全地将密钥 Secret Key 传输给通信方。而非对称密钥加密方式可以保证传输的安全性,因此我们可以利用非对称密钥加密方式将 Secret Key 传输给通信方。HTTPS 采用混合的加密机制,正是利用了上面提到的方案:
使用非对称密钥加密方式,传输对称密钥加密方式所需要的 Secret Key,从而保证安全性;
获取到 Secret Key 后,再使用对称密钥加密方式进行通信,从而保证效率。(下图中的 Session Key 就是 Secret Key)
- 短连接与长连接
当浏览器访问一个包含多张图片的 HTML 页面时,除了请求访问的 HTML 页面资源,还会请求图片资源。如果每进行一次 HTTP 通信就要新建一个 TCP 连接,那么开销会很大。
长连接只需要建立一次 TCP 连接就能进行多次 HTTP 通信。
- 从 HTTP/1.1 开始默认是长连接的,如果要断开连接,需要由客户端或者服务器端提出断开,使用
Connection : close; - 在 HTTP/1.1 之前默认是短连接的,如果需要使用长连接,则使用
Connection : Keep-Alive
操作系统
程序,进程和线程的区别
进程与线程
1. 进程
进程是资源分配的基本单位。
2. 线程
线程是独立调度的基本单位。
区别
Ⅰ 拥有资源
进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问隶属进程的资源。
Ⅱ 调度
线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
Ⅲ 系统开销
由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,所付出的开销远大于创建或撤销线程时的开销。类似地,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进程 CPU 环境的设置,而线程切换时只需保存和设置少量寄存器内容,开销很小。
Ⅳ 通信方面
线程间可以通过直接读写同一进程中的数据进行通信,但是进程通信需要借助 IPC。
什么时候情况下要用多线程?
进程之间怎么通信的?
进程通信
进程同步与进程通信很容易混淆,它们的区别在于:
进程同步:控制多个进程按一定顺序执行;
进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
1. 管道
管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
#include
int pipe(int fd[2]);
它具有以下限制:
只支持半双工通信(单向交替传输);
只能在父子进程或者兄弟进程中使用。
2. FIFO
也称为命名管道,去除了管道只能在父子进程中使用的限制。
#include
int mkfifo(const char *path, mode_t mode);
int mkfifoat(int fd, const char *path, mode_t mode);
FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
3. 消息队列
相比于 FIFO,消息队列具有以下优点:
消息队列可以独立于读写进程存在,从而避免了 FIFO 中同步管道的打开和关闭时可能产生的困难;
避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法;
读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
4. 信号量
它是一个计数器,用于为多个进程提供对共享数据对象的访问。
5. 共享存储
允许多个进程共享一个给定的存储区。因为数据不需要在进程之间复制,所以这是最快的一种 IPC。
需要使用信号量用来同步对共享存储的访问。
多个进程可以将同一个文件映射到它们的地址空间从而实现共享内存。另外 XSI 共享内存不是使用文件,而是使用内存的匿名段。
6. 套接字
与其它通信机制不同的是,它可用于不同机器间的进程通信。
一个手机应用程序里面的进程和线程分别是怎么进行的?
死锁,怎么解死锁,死锁条件,怎么预防
死锁条件:
- 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
- 占有和等待:已经得到了某个资源的进程可以再请求新的资源。
- 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
- 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
处理方法
1.因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。
当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。
大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
2.不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
预防:
1. 破坏互斥条件
例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。
2. 破坏占有和等待条件
一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。
3. 破坏不可抢占条件
4. 破坏环路等待
给资源统一编号,进程只能按编号顺序来请求资源。
进程的状态:阻塞+就绪+执行
- 就绪状态(ready):等待被调度
- 运行状态(running)
- 阻塞状态(waiting):等待资源
应该注意以下内容:
- 只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
- 阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
手机内存8g,是32位的,一个进程能申请多少内存?
线程的应用,举例,线程的阻塞
处理并发请求时,并发一个创建一个线程,
主线程和子线程的区别
Linux :
- linux中如何查看CPU负载 top
- linux用过嘛(扯到了我训练过深度模型,小哥哥直接来了个场景题)
场景题:推荐算法中如何控制广告推送频率(结合强化学习说了一些 - Linux了解不,df dh区别,如何格式化磁盘,磁盘挂载过程,tcp丢包如何排查,docker是用什么实现的
- 怎么查找特定后缀名或前缀名的文件
Mysql
数据库引擎事务隔离级别,串行化如何实现,数据库的隔离级别?四个。你平常使用的是哪个隔离级别。数据库隔离级别以及分别解决了什么问题
未提交读(READ UNCOMMITTED)
事务中的修改,即使没有提交,对其它事务也是可见的。
提交读(READ COMMITTED)
一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。
可重复读(REPEATABLE READ)
保证在同一个事务中多次读取同一数据的结果是一样的。
可串行化(SERIALIZABLE)
强制事务串行执行,这样多个事务互不干扰,不会出现并发一致性问题。
该隔离级别需要加锁实现,因为要使用加锁机制保证同一时间只有一个事务执行,也就是保证事务串行执行
MySQL默认第三个

MySQL的存储引擎有哪些?它们之间的区别?你用的mysql存储引擎?为什么选择它?实现原理?
InnoDB
是 MySQL 默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎。
实现了四个标准的隔离级别,默认级别是可重复读(REPEATABLE READ)。在可重复读隔离级别下,通过多版本并发控制(MVCC)+ Next-Key Locking 防止幻影读。
主索引是聚簇索引,在索引中保存了数据,从而避免直接读取磁盘,因此对查询性能有很大的提升。
内部做了很多优化,包括从磁盘读取数据时采用的可预测性读、能够加快读操作并且自动创建的自适应哈希索引、能够加速插入操作的插入缓冲区等。
支持真正的在线热备份。其它存储引擎不支持在线热备份,要获取一致性视图需要停止对所有表的写入,而在读写混合场景中,停止写入可能也意味着停止读取。
MyISAM
设计简单,数据以紧密格式存储。对于只读数据,或者表比较小、可以容忍修复操作,则依然可以使用它。
提供了大量的特性,包括压缩表、空间数据索引等。
不支持事务。
不支持行级锁,只能对整张表加锁,读取时会对需要读到的所有表加共享锁,写入时则对表加排它锁。但在表有读取操作的同时,也可以往表中插入新的记录,这被称为并发插入(CONCURRENT INSERT)。
可以手工或者自动执行检查和修复操作,但是和事务恢复以及崩溃恢复不同,可能导致一些数据丢失,而且修复操作是非常慢的。
如果指定了 DELAY_KEY_WRITE 选项,在每次修改执行完成时,不会立即将修改的索引数据写入磁盘,而是会写到内存中的键缓冲区,只有在清理键缓冲区或者关闭表的时候才会将对应的索引块写入磁盘。这种方式可以极大的提升写入性能,但是在数据库或者主机崩溃时会造成索引损坏,需要执行修复操作。
比较
-
事务:InnoDB 是事务型的,可以使用 Commit 和 Rollback 语句。
-
并发:MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
-
外键:InnoDB 支持外键。
-
备份:InnoDB 支持在线热备份。
-
崩溃恢复:MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
-
其它特性:MyISAM 支持压缩表和空间数据索引。
怎么判断一个SQL语句有没有走索引?紧接着问explain知道哪些字段吗
索引的使用条件
-
对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
-
对于中到大型的表,索引就非常有效;
-
但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
mysql存储模型 区别 怎么看用没用索引 怎么判断sql语句好坏
数据库中索引B+树
一个手机应用要更改数据库,它的底层是怎么实现的?
sql查询过程
一 ,连接
1,客户端把语句发给服务器端执行
1.1客户端发起一条Query请求,监听客户端的‘连接管理模块’接收请求
1.2将请求转发到‘连接进/线程模块’
1.3调用‘用户模块’来进行授权检查
1.4通过检查后,‘连接进/线程模块’从‘线程连接池’中取出空闲的被缓存的连接线程和客户端请求对接,如果失败则创建一个新的连接请求
二:处理
2,语句解析
当客户端把 SQL 语句传送到服务器后,服务器进程会对该语句进行解析
2.1,查询高速缓存(library cache)。服务器进程在接到客户端传送过来的 SQL 语句时,不
会直接去数据库查询。而是会先在数据库的高速缓存中去查找,是否存在相同语句的执行计划。如果在
数据高速缓存中,则服务器进程就会直接执行这个 SQL 语句,省去后续的工作。所以,采用高速数据缓
存的话,可以提高 SQL 语句的查询效率。一方面是从内存中读取数据要比从硬盘中的数据文件中读取
数据效率要高,另一方面,也是因为这个语句解析的原因。
不过这里要注意一点,这个数据缓存跟有些客户端软件的数据缓存是两码事。有些客户端软件为了
提高查询效率,会在应用软件的客户端设置数据缓存。由于这些数据缓存的存在,可以提高客户端应用软
件的查询效率。但是,若其他人在服务器进行了相关的修改,由于应用软件数据缓存的存在,导致修改的
数据不能及时反映到客户端上。从这也可以看出,应用软件的数据缓存跟数据库服务器的高速数据缓存
不是一码事。
2.2, 语句合法性检查(data dict cache)。当在高速缓存中找不到对应的 SQL 语句时,则服
务器进程就会开始检查这条语句的合法性。这里主要是对 SQL 语句的语法进行检查,看看其是否合乎
语法规则。如果服务器进程认为这条 SQL 语句不符合语法规则的时候,就会把这个错误信息,反馈给客
户端。在这个语法检查的过程中,不会对 SQL 语句中所包含的表名、列名等等进行 SQL 他只是语法
上的检查。
2.3,语言含义检查(data dict cache)。若 SQL 语句符合语法上的定义的话,则服务器进程
接下去会对语句中的字段、表等内容进行检查。看看这些字段、表是否在数据库中。如果表名与列名不
准确的话,则数据库会就会反馈错误信息给客户端。所以,有时候我们写 select 语句的时候,若语法
与表名或者列名同时写错的话,则系统是先提示说语法错误,等到语法完全正确后,再提示说列名或表名
错误。
2.4,获得对象解析锁(control structer)。当语法、语义都正确后,系统就会对我们需要查询
的对象加锁。这主要是为了保障数据的一致性,防止我们在查询的过程中,其他用户对这个对象的结构发
生改变。
2.5,数据访问权限的核对(data dict cache)。当语法、语义通过检查之后,客户端还不一定
能够取得数据。服务器进程还会检查,你所连接的用户是否有这个数据访问的权限。若你连接上服务器
的用户不具有数据访问权限的话,则客户端就不能够取得这些数据。有时候我们查询数据的时候,辛辛苦
苦地把 SQL 语句写好、编译通过,但是,最后系统返回个 “没有权限访问数据”的错误信息,让我们气
半死。这在前端应用软件开发调试的过程中,可能会碰到。所以,要注意这个问题,数据库服务器进程先
检查语法与语义,然后才会检查访问权限。
2.6, 确定最佳执行计划 ?。当语句与语法都没有问题,权限也匹配的话,服务器进程还是不会直接对
数据库文件进行查询。服务器进程会根据一定的规则,对这条语句进行优化。不过要注意,这个优化是有
限的。一般在应用软件开发的过程中,需要对数据库的 sql 语言进行优化,这个优化的作用要大大地大
于服务器进程的自我优化。所以,一般在应用软件开发的时候,数据库的优化是少不了的。当服务器进程
的优化器确定这条查询语句的最佳执行计划后,就会将这条 SQL 语句与执行计划保存到数据高速缓存
(library cache)。如此的话,等以后还有这个查询时,就会省略以上的语法、语义与权限检查的步骤,
而直接执行 SQL 语句,提高 SQL 语句处理效率。
三 提取结果
3.结果
3.1Query请求完成后,将结果集返回给‘连接进/线程模块’
3.2返回的也可以是相应的状态标识,如成功或失败等
3.3‘连接进/线程模块’进行后续的清理工作,并继续等待请求或断开与客户端的连接
MySQL InnoDB存储引擎中的MVCC解决了什么问题,能说下MVCC的实现原理么
SQL语句经常写吧,那我给你出一道SQL题(分组求和排序)
你认为什么情况下不应该建立索引
查询非常小的表,直接全表扫描比较快
mysql有几种锁?怎么实现?
innodb事物的级别
b 树的结构?与二叉树的区别?与b树的区别?
写过最复杂的sql, 手写代码: 统计各个科目考试最高分:最复杂的包括了sum、case、left join、group by,追问左连接和内联区别,没答上来
聚簇索引跟红黑树
sql :给一个日期范围,统计每天入库的数据总量
sql语句里like和in关键字
sql语句,求平均分超过60分的学生学号
数据库sql怎么优化
什么情况不能用索引?
SELECT column_name(s)
FROM table_name
WHERE column_name
BETWEEN value1 AND value2 什么时候会发生死锁;怎么解决死锁;N个资源怎么办?
redis
- 你知道redis的什么东西
- redis中zset,说了一下跳跃表的插入,删除过程;
- 位图知道原理嘛(操作系统中的位示图还是bitmap?不太了解)
- redis数据类型,redis的应用场景,为什么redis快
- Redis的key的写入和删除的原理
- 怎么保证Redis的高可用
- redis数据结构?单线程还是多线程?
- 用什么样的队列?你是怎么实现?我回答的redis的list实现的)这种队列有什么缺点?
- 分布式锁;
mq
- 你还用过rabbitMQ呀,它能够做什么?
- rabbitMQ是怎么保证消息不丢的,从客户端—消息队列, 消息队列—服务器端的角度考虑
spring
- 开源框架有哪些了解的 为什么用spring 为什么不用new就可以自动生产 能不能自己实现一个
- spring security是干嘛的,原理是啥,jwt干啥的
- 后台用什么框架?ioc,aop,其他还有什么框架也可以做到ioc,aop(2333~不就spring?)
- Spring IOC,AOP,注解
设计模式
双重检索单例
设计模式分为哪三类,各有什么?设计模式,用过哪些设计模式,讲几个,设计模式和原则
设计模式分类https://blog.csdn.net/ttxs99989/article/details/81844135
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
单例模式https://zyfcodes.blog.csdn.net/article/details/105652399?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-3.not_use_machine_learn_pai&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-3.not_use_machine_learn_pai
(一)定义及基本要点
单例模式是指确保一个类在任何情况下都绝对只有一个实例,并提供一个全局访问点。
该模式有三个基本要点:
- 一是这个类只能有一个实例;
- 二是它必须自行创建这个实例;
- 三是它必须自行向整个系统提供这个实例。
(二)应用场景
应用场景:J2EE中的ServlertContext、SerletContextConfig等、Spring框架应用中的ApplicationContext、数据库连接池等。
-
描述:饿汉式单例模式
-
* 优点:没有任何锁,执行效率高,用户体验比懒汉式单例模式更好
-
* 缺点:类加载的时候就初始化,不管用不用都占内存空间
-
* 建议:适用于单例模式较少的场景
-
* 如果我们在程序启动后,一定会加载到类,那么用饿汉模式实现的单例简单又实用;
-
* 如果我们是写一些工具类,则优先考虑使用懒汉模式,可以避免提前被加载到内存中,占用系统资源。
描述:懒汉式单例模式---双重检查锁
* 相比单锁而言,双重检查锁性能上虽然有提升,但是依旧用到了synchronized关键字总归要上锁,对程序性能还是存在一定的性能影响
* 不算最优--存在优化空间
* 建议:如果我们在程序启动后,一定会加载到类,那么用饿汉模式实现的单例简单又实用;
* 如果我们是写一些工具类,则优先考虑使用懒汉模式,可以避免提前被加载到内存中,占用系统资源。
工厂模式
代理模式
适配器模式
https://blog.csdn.net/wwwdc1012/article/details/82780560?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160792682319724818096505%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=160792682319724818096505&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v29-1-82780560.pc_search_result_cache&utm_term=%E9%80%82%E9%85%8D%E5%99%A8%E6%A8%A1%E5%BC%8F&spm=1018.2118.3001.4449
适配器模式简述
定义将被适配的类(比如电压AC)
定义目标接口(调节电压到5伏)
定义不同的类(即适配器)实现目标接口(比如中国输入220V、日本输入110V等)
如果去中国就是
AC chinaAC=new AC220();
如果去日本就是
AC japenAC=new AC110();
装饰器模式
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装。
这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。
我们通过下面的实例来演示装饰器模式的用法。其中,我们将把一个形状装饰上不同的颜色,同时又不改变形状类。
介绍
意图:动态地给一个对象添加一些额外的职责。就增加功能来说,装饰器模式相比生成子类更为灵活。
主要解决:一般的,我们为了扩展一个类经常使用继承方式实现,由于继承为类引入静态特征,并且随着扩展功能的增多,子类会很膨胀。
何时使用:在不想增加很多子类的情况下扩展类。
如何解决:将具体功能职责划分,同时继承装饰者模式。
关键代码: 1、Component 类充当抽象角色,不应该具体实现。 2、修饰类引用和继承 Component 类,具体扩展类重写父类方法。
应用实例: 1、孙悟空有 72 变,当他变成"庙宇"后,他的根本还是一只猴子,但是他又有了庙宇的功能。 2、不论一幅画有没有画框都可以挂在墙上,但是通常都是有画框的,并且实际上是画框被挂在墙上。在挂在墙上之前,画可以被蒙上玻璃,装到框子里;这时画、玻璃和画框形成了一个物体。
优点:装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能。
缺点:多层装饰比较复杂。
使用场景: 1、扩展一个类的功能。 2、动态增加功能,动态撤销。
注意事项:可代替继承。
代理模式属于哪一类
生产者消费者模式,生产消费者的,以及多生产者同步
描述适配器,写单例
单例模式,装饰模式,
分布式
- 负载均衡的算法有哪些;
- rpc dubbo的组件有哪些
- 分布式事务,CAP定理,有没有使用过相关的产品
- zookeeper了解吗
- hbase索引的结构,kafka存储的结构,二进制文件的组织方式,kafka如何避免消息丢失,zookeeper在kafka中是干啥的,kafka在zookeeper中存储的数据,zookeeper了解不,zookeeper的共识算法,分区后如何解决。
- protobuf了解不,grpc了解不,用的什么协议,HTTP2和HTTP1区别,websocket建立连接过程
- RPC你了解过吗?
- 如何分布式存储?
算法
排序算法有哪些,简述冒泡和归并排序,冒泡算法的优化,讲讲归并排序,冒泡的优化知道吗;回答相等不交换,还有flag做已排序标志的优化;直接插入排序,写一下伪代码或者说一下思路,插入排序,时间复杂度
八大排序算法比较和特点:https://blog.csdn.net/m0_37962600/article/details/81475585

冒泡排序优化:https://blog.csdn.net/yanxiaolx/article/details/51622286?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromBaidu-1.not_use_machine_learn_pai&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromBaidu-1.not_use_machine_learn_pai
1.每次执行外循环判断flag,如果一次内循环没有发生一次交换,flag还是0,就结束(因为剩下来的都是有序的)2.每次执行内循环记录最后一次交换的位置,并设置为下次内循环的边界,这样就可以判断到最后一组无序数字,不去判断有序数字。优化结果:最坏时复杂度不变O(n^2),最好时O(n)(不做任何多余的交换)
简述归并排序:https://zhuanlan.zhihu.com/p/124356219(代码也在里面有)
归并排序是用分治思想,分治模式在每一层递归上有三个步骤:
- 分解(Divide):将n个元素分成个含n/2个元素的子序列。
- 解决(Conquer):用合并排序法对两个子序列递归的排序。
- 合并(Combine):合并两个已排序的子序列已得到排序结果。
堆排序原理
快排,快排是什么思想,快排的优化是啥,为啥这么做;
快排步骤:https://blog.csdn.net/nrsc272420199/article/details/82587933
1.设第一个元素为基准值
2.从后半部分开始,如果扫描到的值大于基准数据就让high减1,如果发现有元素比该基准数据的值小,就将high位置的值赋值给low位置
3.然后开始从前往后扫描,如果扫描到的值小于基准数据就让low加1,如果发现有元素大于基准数据的值,就再将low位置的值赋值给high位置的值
4.循环2,3过程直到最后low=high这个位置就是基准值的正确位置
5.将基准值左边的部分和右边的部分分别递归重复1,2,3,4,5过程
快排优化:https://blog.csdn.net/qq_19525389/article/details/81436838
优化1(针对逆序数组):三位取中:从数组中拿出两端、中间三次数,取第二大的为基准值
优化2:当待排序序列的长度分割到一定大小后,使用插入排序。
原因:对于很小和部分有序的数组,快排不如插排好。当待排序序列的长度分割到一定大小后,继续分割的效率比插入排序要差,此时可以使用插排而不是快排
截止范围:待排序序列长度N = 10
优化3(针对有重复数组):在一次分割结束后,可以把与Key相等的元素聚在一起,继续下次分割时,不用再对与key相等元素分割
字母排序
100个数中找出想要的数
TOPK问题的快排解法:
找出基准值,然后遍历
遍历数组一次后判断自己的位置是否>length-100,如果在就找前半部分,如果不在就找后半部分
直到找到自己的位置在length-K时输出自己位置后的所有数
一个数组分成2个相等或接近的子数组
派单的最短路径问题
很大的数据,内存放不下,如何快速找到中间值
链接:https://www.nowcoder.com/questionTerminal/359d6869d5ce4738bf9c9a42b67d9568
来源:牛客网
假设整数是32位的,根据每个整数二进制前的5位,可以划分为32个不同的桶,如果某个桶的个数在内存中放不下,则继续划分,知道内存可以放下为止;然后统计每个桶中的数的个数,就可以中位数一定出现在哪个桶中,而且知道是该桶中第几大数,因为桶的划分是根据二进制前缀来进行划分的,桶之间是排好序的(猜测是插入排序,其实也可使用红黑树)。
手撕栈
链表找环 链表找环入口,不用双指针怎么做
双向链表实现 ,写了个add()和add(index)的
求数组的全排列
中序遍历,递归非递归
求四个数绝对值的最小值
黑猫白猫,混在一起,如何把他们区分开? 黑白灰三种猫混在一起,如何按照黑白灰排好序? 还有两个小问题忘记了。
如何用一个int值,表示三种状态?
其他
- 给你10个tomcat你如何判断自己用哪个(容器?emmmm,求指点)
位图知道原理嘛(操作系统中的位示图还是bitmap?不太了解)
所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此可以大大节省存储空间。
其实就是位示图为原型,01存储的,建议面试的时候知道多少说多少,知道什么说什么~ - 序列化相关
- 最后还是问项目,项目中的难点,是如何解决的?
- c++编程搞过没,GPU编程了解不,用的什么GPU,GPU运算性能是什么决定的
- 如果某个用户同时请求创建活动接口100次,如果防止它被重复创建?创建前查看该记录是否存在、使用锁、如果是分布式的使用分布式锁—这样解决了99.99%的问题。除了使用这些方案,还能使用什么方法解决吗?
- 讲讲分布式锁的实现
- io量很大,队列很长怎么办?
- Q:觉得用过的模板解析引擎有什么不同的特征。
A:用过JSP和Thymeleaf,JSP我就说适合Java程序员做前端,本质还是Servlet,生产环境下调试方便;Thymeleaf是SpringBoot项目碰到的,本质是EL,语法特殊,但是前后端传值、传对象方便。 - 讲一下对jQUERY的使用感受
A:研一的项目做过iOS开发,用OC做的webview APP,用到了jQuery Mobile做界面和事件控制,感觉很方便。 后面的Web项目主要用来进行Ajax操作,选择器很方便。 - 硕士一个项目涉及到跨系统集成,要我在纸上画出集成逻辑架构,介绍一下开发用到的技术和业务环境。
集成用的WebService,引入Apache旗下的Axis, 涉及到文件传输和多数据源配置。。。。 - 用过eclipse、IDEA、Myeclipse,评价一下区别 代码提示、插件库、收费与免费、代码模板、资源消耗
- 用过EJB和SSH,评价一下区别
- 问了实习经历 了解分布式吗?
- 你怎么用的websocket?
- 想做安卓还是java后台?手机端安卓怎么开发的?
- activity四大组件
- 介绍一下service
- APP的启动流程
- Android事件分发机制
- view的测量方法;
- Android之间线程通信
- 介绍一个你用心做的模块,项目流程,怎么理解异步同步,什么场景用;
static能不能被重写? - MD5为啥要加盐(彩虹表·);UUID有多少位(32位)