左边
右边
第一种方法
Document
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CFSmnnRH-1649150971249)(https://ftp.bmp.ovh/imgs/2021/02/50abace27a301ab5.png)]
第二种方法 flex
Document
hello world
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WiORv0W7-1649150971250)(https://ftp.bmp.ovh/imgs/2021/02/bc9339a0a8bd6e3c.jpg)]
一点
Document
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fbFMk4og-1649150971251)(https://ftp.bmp.ovh/imgs/2021/02/f6d5a9e95d15dc3e.png)]
三点
Document
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-60YWLawq-1649150971251)(https://ftp.bmp.ovh/imgs/2021/02/b258a354b1f371a5.png)]
3、简述选择器~和+的区别。
最大的区别是’+’最多只能匹配到一个元素,而’~’可以匹配到多个。
‘+’是指紧跟在后面的某同级元素
‘~’是指某些同级元素
以以下代码为例
123
如果是+
.try + p
1
那么选中的只是类名为one的p
如果是~
.try ~ p
1
那么选中的是类名为one和类名为two的p
1234
那么
.try + p
1
则什么也选择不到
.try ~ p
1
则没有影响
4、简述box-sizing的有效值以及所对应的盒模型规则。
box-sizing 属性允许您以特定的方式定义匹配某个区域的特定元素。
语法:box-sizing: content-box|border-box|inherit;
1)box-sizing:content-box;这是由 CSS2.1 规定的宽度高度行为。宽度和高度分别应用到元素的内容框。在宽度和高度之外绘制元素的内边距和边框。是默认值。如果你设置一个元素的宽为100px,那么这个元素的内容区会有100px 宽,并且任何边框和内边距的宽度都会被增加到最后绘制出来的元素宽度中
2)box-sizing:border-box;为元素指定的任何内边距和边框都将在已设定的宽度和高度内进行绘制。告诉浏览器去理解你设置的边框和内边距的值是包含在width内的。也就是说,如果你将一个元素的width设为100px,那么这100px会包含其它的border和padding,内容区的实际宽度会是width减去border + padding的计算值。大多数情况下这使得我们更容易的去设定一个元素的宽高。
3)box-sizing:inherit;;规定应从父元素继承 box-sizing 属性的值
5、flex中元素的margin是否会合并?
不会合并
6、简述align-items和align-content的区别。
align-items属性适用于所有的flex容器,它是用来设置每个flex元素在交叉轴上的默认对齐方式。如果是多行多行容器,多行和多行之间是有间距的。
align-content有相同的功能,但是align-content属性只适用于多行的flex容器,有一个重点就是多行,并且align-content在对齐的过程中,如果是多行多行容器,多行和多行之间的间距是没有的。
7、简述data:属性的用法(如何设置,如何获取),有何优势?
data-* 的值的获取和设置,2种方法:
1)传统方法
getAttribute() 获取data-属性值;
setAttribute() 设置data-属性值
2)HTML5新方法
例如 data-href
dataset.href 获取data-href属性值
dataset.href = ‘http://baidu.com’ 设置data-href属性值
传统方法无兼容性问题,但是不够优雅、方便
HTML5新方法很优雅、方便,但是有兼容性问题,可以在移动端开发或不支持低版本浏览器的项目中使用
优势:自定义的数据可以让页面拥有更好的交互体验(不需要使用 Ajax 或去服务端查询数据)。
8、简述 title与h1的区别,b与strong的区别,i与em的区别。
title与h1的区别:
定义:title是网站标题,h1是文章主题
作用:title概括网站信息,可以直接告诉搜索引擎和用户这个网站是关于什么主题和内容的,是显示在网页Tab栏里的;h1突出文章主题,面对用户,是显示在网页中的.
b与strong的区别:
从视觉上效果观看b与strong是没有区别的,从单词的语义也可以分析得出,b是Bold(加粗)的简写,所以这个B标记所传达的意思只是加粗,没有任何其它的作用,而Strong我们从字面理解就可以知道他是强调的意思,所以我们用这个标记向浏览器传达了一个强调某段文字的消息,他是强调文档逻辑的,并非是通知浏览器应该如何显示。
3)i与em的区别:同样,I是Italic(斜体),而em是emphasize(强调)。
9、什么是标准文档流
标准文档流:网页在解析的时候,遵循于从上向下,从左向右的一个顺序,而这个顺序就是来源于标准文档流。
标准文档流等级,分为两种等级:块级元素和行内元素;
块级元素:
1).霸占一行,不能与其他任何元素并列
2).能接受宽、高
3).如果不设置宽度,那么宽度将默认变为父亲的100%,即和父亲一样宽
行内元素:
1).与其他元素并排
2).不能设置宽、高。默认的宽度就是文字的宽度
10、z-index是什么?在position的值什么时候可以触发?
z-index 属性设置元素的堆叠顺序。拥有更高堆叠顺序的元素总是会处于堆叠顺序较低的元素的前面,当脱离文档流内容较多,并且相互重叠的时候,就有可能发生本想完全显示的内容被其他内容遮挡的结果,这时我们就需要人为指定哪个层在上面,哪个在下面,z-index属性就是干这个用的。注意:Z-index 仅能在定位元素上奏效.
在position的值是relative、absolute、fixed、sticky时候可以触发
11、CSS3 如何实现圆角边框
Document
圆角边框
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4yFA06uh-1649150971251)(https://ftp.bmp.ovh/imgs/2021/02/8ab6261fd41c7643.png)]
12、HTML5有哪些缓存方式
总体情况
h5之前,存储主要是用cookies。cookies缺点有在请求头上带着数据,大小是4k之内。主Domain污染。
主要应用:购物车、客户登录
对于IE浏览器有UserData,大小是64k,只有IE浏览器支持。
目标
解决4k的大小问题
解决请求头常带存储信息的问题
解决关系型存储的问题
跨浏览器
1.本地存储localstorage
存储方式:
以键值对(Key-Value)的方式存储,永久存储,永不失效,除非手动删除。
大小:
每个域名5M
支持情况:
常用的API:
getItem //取记录
setIten//设置记录
removeItem//移除记录
key//取key所对应的值
clear//清除记录
存储的内容:
数组,图片,json,样式,脚本。。。(只要是能序列化成字符串的内容都可以存储)
2.本地存储sessionstorage
HTML5 的本地存储 API 中的 localStorage 与 sessionStorage 在使用方法上是相同的,区别在于 sessionStorage 在关闭页面后即被清空,而 localStorage 则会一直保存。
3.离线缓存(application cache)
本地缓存应用所需的文件
使用方法:
①配置manifest文件
页面上:
...
Manifest 文件:
manifest 文件是简单的文本文件,它告知浏览器被缓存的内容(以及不缓存的内容)。
manifest 文件可分为三个部分:
①CACHE MANIFEST – 在此标题下列出的文件将在首次下载后进行缓存
②NETWORK – 在此标题下列出的文件需要与服务器的连接,且不会被缓存
③FALLBACK – 在此标题下列出的文件规定当页面无法访问时的回退页面(比如 404 页面)
完整demo:
CACHE MANIFEST
# 2016-07-24 v1.0.0
/theme.css
/main.js
NETWORK:
login.jsp
FALLBACK:
/html/ /offline.html
**服务器上:**manifest文件需要配置正确的MIME-type,即 “text/cache-manifest”。
如Tomcat:
manifest text/cache-manifest
常用API:
核心是applicationCache对象,有个status属性,表示应用缓存的当前状态:
0(UNCACHED) : 无缓存, 即没有与页面相关的应用缓存
1(IDLE) : 闲置,即应用缓存未得到更新
2 (CHECKING) : 检查中,即正在下载描述文件并检查更新
3 (DOWNLOADING) : 下载中,即应用缓存正在下载描述文件中指定的资源
4 (UPDATEREADY) : 更新完成,所有资源都已下载完毕
5 (IDLE) : 废弃,即应用缓存的描述文件已经不存在了,因此页面无法再访问应用缓存
相关的事件:
表示应用缓存状态的改变:
checking : 在浏览器为应用缓存查找更新时触发
error : 在检查更新或下载资源期间发送错误时触发
noupdate : 在检查描述文件发现文件无变化时触发
downloading : 在开始下载应用缓存资源时触发
progress:在文件下载应用缓存的过程中持续不断地下载地触发
updateready : 在页面新的应用缓存下载完毕触发
cached : 在应用缓存完整可用时触发
Application Cache的三个优势:
① 离线浏览
② 提升页面载入速度
③ 降低服务器压力
注意事项:
\1. 浏览器对缓存数据的容量限制可能不太一样(某些浏览器设置的限制是每个站点 5MB)
\2. 如果manifest文件,或者内部列举的某一个文件不能正常下载,整个更新过程将视为失败,浏览器继续全部使用老的缓存
\3. 引用manifest的html必须与manifest文件同源,在同一个域下
\4. 浏览器会自动缓存引用manifest文件的HTML文件,这就导致如果改了HTML内容,也需要更新版本才能做到更新。
\5. manifest文件中CACHE则与NETWORK,FALLBACK的位置顺序没有关系,如果是隐式声明需要在最前面
\6. FALLBACK中的资源必须和manifest文件同源
\7. 更新完版本后,必须刷新一次才会启动新版本(会出现重刷一次页面的情况),需要添加监听版本事件。
\8. 站点中的其他页面即使没有设置manifest属性,请求的资源如果在缓存中也从缓存中访问
\9. 当manifest文件发生改变时,资源请求本身也会触发更新
点我参考更多资料!
离线缓存与传统浏览器缓存区别:
\1. 离线缓存是针对整个应用,浏览器缓存是单个文件
\2. 离线缓存断网了还是可以打开页面,浏览器缓存不行
\3. 离线缓存可以主动通知浏览器更新资源
4.Web SQL
关系数据库,通过SQL语句访问
Web SQL 数据库 API 并不是 HTML5 规范的一部分,但是它是一个独立的规范,引入了一组使用 SQL 操作客户端数据库的 APIs。
支持情况:
Web SQL 数据库可以在最新版的 Safari, Chrome 和 Opera 浏览器中工作。
核心方法:
①openDatabase:这个方法使用现有的数据库或者新建的数据库创建一个数据库对象。
②transaction:这个方法让我们能够控制一个事务,以及基于这种情况执行提交或者回滚。
③executeSql:这个方法用于执行实际的 SQL 查询。
13、CSS3新增伪类有那些
p:last-of-type 选择其父元素的最后的一个P元素
p:last-child 选择其父元素的最后子元素(一定是P才行)
p:first-of-type 选择其父元素的首个P元素
p:first-child 选择其父元素的首个p元素(一定是p才行)
p:only-child 选择其父元素的只有一个元素(而且这个元素只能是p元素,不能有其他元素)
p:only-of-type 选择其父元素的只有一个p元素(不能有第二个P元素,其他元素可以有)
**选第N个**
p:nth-child(n) 选择其父元素的第N个 刚好是p的元素
p:nth-last-child(n) ..............................................从最后一个子元素开始计数
p:nth-of-type(n) 选择其父元素的n个元素
p:nth-last-of-type(n) ........................从最后一个子元素开始计数
14、CSS实现水平/垂直水平居中
css的居中,可以分为水平居中和垂直居中,实现居中的方式有以下几种:
1.text-align:center 块状元素,水平居中
2.margin:0 auto 水平居中 以外边框为参照物,上下外边框距为0,左右外边框距浏览器会自动计算平分
3.line-height 垂直居中 通过设置行间距。line-height只适用于单行文本的元素,多行元素不适用。
4.float属性+relative定位 给父元素设置float:left ,然后父元素整体向左移动50%(position:relative;left:50%),这时父元素要清除浮动(clear:both),然后再给子元素整体向左移动50%(position:relative;left:-50%)
5.根据绝对定位absolute+margin实现水平居中 给父元素一个相对定位relative,利用绝对定位absolute,配合margin:auto自动计算外边距(position: absolute; top: 0;right: 0; bottom: 0; left: 0;margin: auto;)。相对于相对应于relative的绝对定位absolute,需要定宽。relative只是为了给子元素定位用的
6.使用absolute绝对定位+translate 移动转换,实现水平垂直居中 使用百分比来绝对定位一个元素,并配合使用translate,将元素移动定位居中(position: absolute; top: 50%; left: 50%; transform: translate(-50%, -50%))。
7.利用table布局,默认垂直居中(vertical-align:middle) 如果不是table布局的话可以:仿table(display:table-cell),一样使用vertical-align:middle实现居中对齐
8.flex布局 父元素使用display:flex,设置其属性justify-content.align-items都为center(display: flex; justify-content: center; align-items: center),实现水平居中
9.flex布局+margin 父元素使用flex布局(display:flex),子元素使用margin:auto
15、简述一下src 与href的区别
href 是指向bai网络资源所在位置,建立和当du前元zhi素(锚点)或当前文档dao(链接)之间的链接,zhuan用于超链接。
src是指向外shu部资源的位置,指向的内容将会嵌入到文档中当前标签所在位置;在请求src资源时会将其指向的资源下载并应用到文档内,例如js脚本,img图片和frame等元素。
当浏览器解析到该元素时,会暂停其他资源的下载和处理,直到将该资源加载、编译、执行完毕,图片和框架等元素也如此,类似于将所指向资源嵌入当前标签内。这也是为什么将js脚本放在底部而不是头部。
16、什么是CSS hack
CSS hack 是CSS中的一bai种作弊手段,因为目前du所有浏览器并没有统一对zhiCSS的支持,例如同样dao是一个margin:1px,可zhuan能在不同的浏览器中出现的效shu果就一定是1px
在这种情况下,我们只能借助于CSS hack来暂时过渡这个阶段,CSS hack就比如是IE能认出的CSS语句,而FF不能认出,这样就能达到我们的目的了,css hack在很多高级的技巧中出现,不过并不是很推荐使用,毕竟未来的css趋势还不是很明了,尽量避免吧
因为很多css错位问题其实并不是浏览器的错误,而是我们本身的编辑出现的错误。
17、什么叫做优雅降级和渐进增强?
一.背景介绍:
渐进增强和优雅降级是在CSS3出现之后才火起来的。由于低级浏览器,(特)比(别)如(是)IE6等,不支持CSS3的浏览器,但是CSS3的样式又特别优秀不忍放弃 ,所以在高级浏览器中应用CSS3样式,在低级浏览器只保证基本功能。
“渐进增强”是被Steven Champeon创造于2003年3月11日在奥斯汀的SXSW互动大会,并于2003年3月和6月间通过一系列Webmonkey教程文章的公布。 (我找了半天资料,翻了下英文文章也只找到这段历史,无奈脸),谷歌公司是很支持这种开发方式的啊,我认为渐进增强不仅是一个前端开发思想,更加是一个程序开发思想。
二.知识剖析
1.什么是渐进增强
在网页开发中,渐进增强认为应该专注于内容本身。一开始针对低版本的浏览器构建页面,满足最基本的功能,再针对高级浏 览器进行效果,交互,追加各种功能以达到更好用户体验,换句话说,就是以最低要求,实现最基础功能为基本,向上兼容。以css为例,以下这种写法就是渐进增强。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O4b4rBGf-1649150971252)(http://upload-images.jianshu.io/upload_images/5837348-c8b4e503e92f5eaa.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
2.什么是优雅降级
在网页开发中,优雅降级指的是一开始针对一个高版本的浏览器构建页面,先完善所有的功能。然后针对各个不同的浏览器进行测试,修复,保证低级浏览器也有基本功能 就好,低级浏览器被认为“简陋却无妨 (poor, but passable)” 可以做一些小的调整来适应某个特定的浏览器。但由于它们并非我们所关注的焦点,因此除了修复较 大的错误之外,其它的差异将被直接忽略。也就是以高要求,高版本为基准,向下兼容。同样以css为例,优雅降级的写法如下。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eW68TmlY-1649150971252)(http://upload-images.jianshu.io/upload_images/5837348-a8d0316bc2316a68.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
3.二者区别
1.)如果你采用渐进增强的开发流程,先做一个基本功能版,然后针对各个浏览器进行渐进增加,增加各种功能。相对于优雅降级来说,开发周期长,初期投入资金大。 你想一下不可能拿个基本功能版给客户看呀,多寒酸,搞不好一气之下就不找你做了,然后就炸了。但是呢,也有好处,就是提供了较好的平台稳定性,维护起来资金小, 长期来说降低开发成本。
2.)那采用优雅降级呢,这样可以在较短时间内开发出一个只用于一个浏览器的完整功能版,然后就可以拿给PM找客户谈呀,可以拿去测试,市场试水呀,对于功能尚未确定的 产品,优雅降级不失为一种节约成本的方法。
从技术出发
前缀CSS3(-webkit- / -moz- / -o-*)和正常CSS3在浏览器中的支持情况是这样的:
1.很久以前:浏览器前缀CSS3和正常CSS3都不支持;
2.不久之前:浏览器只支持前缀CSS3,不支持正常CSS3;
3.现在:浏览器既支持前缀CSS3,又支持正常CSS3;
4.未来:浏览器不支持前缀CSS3,仅支持正常CSS3.
.transition { /渐进增强写法/
-webkit-border-radius:30px 10px;
-moz-border-radius:30px 10px;
border-radius:30px 10px;
}
.transition { /优雅降级写法/
border-radius:30px 10px;
-moz-border-radius:30px 10px;
-webkit-border-radius:30px 10px;
}
三.常见问题
渐进增强和优雅降级如何抉择
四.解决方案
如果开发时间充裕,开发资金到位,就不存在抉择这个问题了,肯定是渐进增强好呀!
但是现实往往很骨感。
这个时候,就要看你开发产品的受众,受众使用的客户端。如果受众年龄覆盖面广,客户端从移动到平板到电脑,比如淘宝这种页面,那没得选,老老实实选渐进增强。
如果受众客户端单一,例如一个移动端页面,再渐进增强PC端就没那么重要了。
各有优势,但现实是绝大多数公司采用的都是渐进增强方式,毕竟业务优先,体验不会凌驾在业务上。
18、移动端适配怎么做?
一、meta viewport(视口)
移动端初始视口的大小为什么默认是980px?
因为世界上绝大多数PC网页的版心宽度为 980px ,如果网页没有专门做移动端适配,此时用手机访问网页旁边刚好没有留白,不过页面缩放后文字会变得非常小。
为了解决页面缩放的体验问题,在网页代码的头部,加入一行viewport元标签。
这里的device-width告诉浏览器,将视口的宽度设置为设备宽度(这个宽度是人为预设的,不设的话就是980px)。
属性含义
initial-scale:第一次进入页面的初始比例
minimum-scale:允许缩小最小比例
maximum-scale:允许放大最大比例
user-scalable:允许使用者缩放,1 or 0 (yes or no)
二、图片适配
img { max-width: 100%; }
此时图片会自动缩放,同时图片最大显示为其自身的100%(即最大只可以显示为自身那么大)
为什么不用 img { width: 100%; } ?
当容器大于图片宽度时,图片会无情的拉伸变形
三、媒体查询
为什么要媒体查询?
针对不用的设备提前为网页设定各种 CSS 样式CSS3中的Media Query模块,自动检测屏幕宽度,然后加载相应的CSS文件
语法举例
@media screen and (min-width:1200px){
body{
background-color: red;
}
当屏幕宽度大于1200px时,背景色变为红色
四、动态 rem 方案
为什么要用rem?
和媒体查询配合,实现响应式布局
px、em、rem 有什么不同?
px是pixel(像素),是屏幕上显示数据的最基本的点,在HTML中,默认的单位就是px;em 是一个相对大小,相对于父元素font-size的百分比大小rem 是相对于根元素的font-size
用法示例
1、首先在HTML中设置一个基准值,如font-size: 100px;
2、将像素值除以100(设定的基准值)计算出对应的rem的值
如果一个div的宽度为600300px ,改为rem即为6rem3rem
3、根据当前屏幕的宽度和设计稿的宽度来计算此时的HTML的font-size的值
当前手机屏幕宽度为375px,设计稿宽度为640px,375/640*100->fontsize=58.59375
19、请问苹果原生浏览器中默认样式如何清除,例如input默认样式?
添加baicss样式:
input[type=“button”], input[type=“submit”], input[type=“reset”] {
-webkit-appearance: none;
}
textarea { -webkit-appearance: none;}
然后自己du定义样式,zhi美化dao修改就好了zhuan。
20、CSS清除浮动的方法
为什么会有 Floats
最初,引入 float 属性是为了能让 web 开发人员实现简单的布局,包括在一列文本中浮动的图像,文字环绕在它的左边或右边。但 大家很快意识到,它可以浮动任何东西,而不仅仅是图像,所以浮动的使用范围扩大了。
当我们在网页各处使用 float 的时候,也由此引发的一些副作用,如:父元素塌陷、元素重叠,清除浮动也就是清除这些副作用。
发生了什么
当一个元素被添加float:right等属性的时候发生了什么?
-
float 属性可以使一个元素脱离正常的文档流(normal flow),然后被安放到它所在容器的的左端或者右端,并且其他的文本和行内元素环绕它。
-
float 使用了块状布局,所以元素的 display 会被改变
而 float 元素脱离了 normal flow 就相当于进入了一个平行空间,不再与其后边及父级块级元素发生反应,这一特性使得 float 元素无法撑起父元素的高度,导致父元素塌陷。
第一点中还提到其他的文本和行内元素环绕 float元素,但是 float 后的块级元素会与其发生重叠。
怎么解决
为了解决 float 属性引发的问题,我们在 CSS 中引入了clear:left|right|both属性,其作用分别是在元素的 左侧|右侧|两侧 不允许存在 float 元素,我们可以用他来清除其副作用。
利用 clear 属性我们有两种方法来清除浮动。
- 为 float 元素后的元素添加 clear 属性
其效果如下:
未添加
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d8Sk1ouA-1649150971252)(https://ftp.bmp.ovh/imgs/2021/02/d5ab7d2bab0b0274.png)]
添加后
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pTuQ1LaX-1649150971252)(https://ftp.bmp.ovh/imgs/2021/02/77107f5570a27d32.png)]
- 利用伪元素
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EpSRaSWt-1649150971253)(https://ftp.bmp.ovh/imgs/2021/02/465f99346ab46e8a.png)]
有时我们会遇到上图的情况,float 元素后没有其他元素了,这时该怎么办?固然我们可以在其后添加一个空div,然后像1中一样解决问题,但这种方式并不优雅,伪元素这时候就派上用场了,我们可以写一个.clearfix 工具样式,当给需要清除浮动时,就为其加上这个类。效果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a7DrRKkB-1649150971253)(https://ftp.bmp.ovh/imgs/2021/02/e2aadae97b048cea.png)]
- 修改父元素的 owerflow 属性
将父元素的 owerflow 属性修改为 owerflow:auto|hidden
这就是三种最主流的方式
21、PC端常用的布局方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-isUkIYao-1649150971253)(https://ftp.bmp.ovh/imgs/2021/02/d57596a337b1781c.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IUAbKZqD-1649150971254)(https://riyugo.com/i/2021/02/21/12mawg6.png)]
实现三栏水平布局之双飞翼布局
中间自适应
左边
右边
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9ogoeARC-1649150971254)(https://riyugo.com/i/2021/02/21/12n1c19.png)]
实现三栏水平布局之圣杯布局
center
left
right
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lPfkRpWO-1649150971254)(https://riyugo.com/i/2021/02/21/12nn9gc.png)]
实现三栏水平布局-Flex布局
main
left
right
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mrZNf05K-1649150971254)(https://riyugo.com/i/2021/02/21/12o5tc7.png)]
22、布局左边20%,中间自适应,右边200px,不能用定位
左右两列200px,中间列自适应
伸缩盒布局
思路:
布局:左右两列200px,中间列自适应(一)
left
center
right
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rkMZr408-1649150971255)(https://riyugo.com/i/2021/02/21/1308wks.png)]
23、行内元素和块级元素?img算什么?行内元素怎么转化为块元素?
1.行内元素 一个行内元素只占据它对应标签的边框所包含的空间。****
2.块级元素 块级元素占据其父元素(容器)的整个空间,因此创建了一个“块”。
*img是什么元素?*
应是行内元素,判断一个元素是行内元素,还是块元素,无非就是看它是否是独占一行。img标签显然没有独占一行,固它是行内元素。这没有问题。
*既然img是行内元素,那为什么可以通过CSS设置框高呢?*
尽管img是行内元素,但同时它也是置换元素,置换元素一般内置框高属性,因此可以设置其框高。
那么什么又是“置换元素”呢?
置换元素就是会根据标签属性来显示的元素。反之就是非置换元素了。
比如img根据src属性来显示,input根据value属性来显示,因此可知道img和input是置换元素,当然同理textarea, select,也是置换元素;
行内如何转块级元素
以下汇总三种行内元素转为块级元素的方法:
(1)display
(2)float
(3)position(absolute和fixed)
代码
1
2
3
4
5
6 行内元素转为块级元素
7
27
28
29
30 方法一:使用display
31
32 a标签转为块级元素
33
34 方法一:使用float
35
36 span标签转为块级元素
37
38 方法一:使用position(absolute和fixed)
39
40 i标签转为块级元素
41
42
24、将多个元素设置为同一行?清除浮动的几种方式?
1.将多个元素设置为同一行:float,inline-block
清除浮动的方式:
方法一:添加新的元素 、应用 clear:both;
方法二:父级div定义 overflow: hidden;
方法三:利用:after和:before来在元素内部插入两个元素块,从面达到清除浮动的效果。
.clear{zoom:1;}
.clear:after{content:””;clear:both;display:block;height:0;overflow:hidden;visibility:hidden;}
25、怪异盒模型box-sizing?弹性盒模型|盒布局?
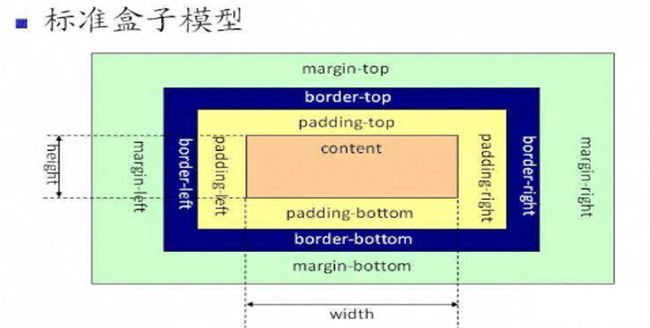
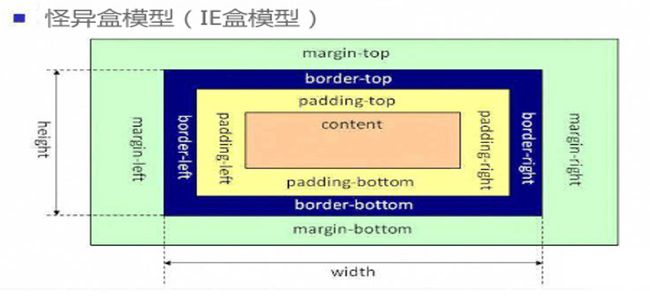
在标准模式下的盒模型:盒子总宽度/高度=width/height+padding+border+margin
在怪异模式下的盒模型下,盒子的总宽度和高度是包含内边距padding和边框border宽度在内的,盒子总宽度/高度=width/height + margin = 内容区宽度/高度 + padding + border + margin;
box-sizing有两个值一个是content-box,另一个是border-box。
当设置为box-sizing:content-box时,将采用标准模式解析计算;
当设置为box-sizing:border-box时,将采用怪异模式解析计算。
26、简述几个CSS hack?
(1) 图片间隙
在div中插入图片,图片会将div下方撑大3px。
hack1:将
与 写在同一行。
hack2:给添加display:block;
dt li 中的图片间隙。
hack:给添加display:block;
(2) 默认高度,IE6以下版本中,部分块元素,拥有默认高度(低于18px)
hack1:给元素添加:font-size:0;
hack2:声明:overflow:hidden;
表单行高不一致
hack1:给表单添加声明:float:left;height: ;border: 0;
鼠标指针
hack:若统一某一元素鼠标指针为手型:cursor:pointer;
当li内的a转化块元素时,给a设置float,IE里面会出现阶梯状
hack1:给a加display:inline-block;
hack2:给li加float:left;
27、 title和alt的区别?
alt属性
- Alt属性(注意是“属性”而不是“标签”)包括替换说明,对于图像和图像热点是必须的。它只能用在img、area和input元素中(包括applet元素)。对于input元素,alt属性意在用来替换提交按钮的图片。
- 使用alt属性是为了给那些不能看到你文档中图像的浏览者提供文字说明。这包括那些使用本来就不支持图像显示或者图像显示被关闭的浏览器的用户,视觉障碍的用户和使用屏幕阅读器的用户。替换文字是用来替代图像而不是提供额外说明文字的。
- 文字的图像图片设置替换文字是最简单的,图像中包含的文字一般来说就可以作为alt属性值。Alt属性值得长度必须少于100个英文字符或者用户必须保证替换文字尽可能的短。
title属性
- title属性为设置该属性的元素提供建议性的信息。
- title属性可以用在除了base,basefont,head,html,meta,param,script和title之外的所有标签。但是并不是必须的。可能这正是为什么很多人不明白何时使用它。
- 使用title属性提供非本质的额外信息。大部分的可视化浏览器在鼠标悬浮在特定元素上时显示title文字为提示信息,然而这又由制造商来决定如何渲染title文字。一些浏览器会将title文字显示在状态栏里。
- title属性有一个很好的用途,即为链接添加描述性文字,特别是当连接本身并不是十分清楚的表达了链接的目的。这样就使得访问者知道那些链接将会带他们到什么地方,他们就不会加载一个可能完全不感兴趣的页面。另外一个潜在的应用就是为图像提供额外的说明信息,比如日期或者其他非本质的信息。
28、什么是CSS3 transform? animation? 区别是什么?
CSS3属性中关于制作动画的三个属性:Transform,Transition,Animation。
1、transform:描述了元素的静态样式,本身不会呈现动画效果,可以对元素进行 旋转rotate、扭曲skew、缩放scale和移动translate以及矩阵变形matrix。
div{
transform:scale(2);
}
transition和animation两者都能实现动画效果
transform常常配合transition和animation使用
2、transition样式过渡,从一种效果逐渐改变为另一种效果
transition是一个合写属性
transition:transition-property transition-duration transition-timing-function transition-delay
从左到右分别是:css属性、过渡效果花费时间、速度曲线、过渡开始的延迟时间
div{
width:100px;
height:100px;
transition:transform 2s;
}
div:hover{
transform:rotate(180deg);
}
transition通常和hover等事件配合使用,需要由事件来触发过渡
我们知道 transition 虽然简单好用,但是我们会发现它受到各种限制。
1:transition需要一个事件来触发,比如hover,所以没法在网页加载时自动发生
2: transition是一次性的,不能重复发生,除非一再触发。
3: transition只能定义开始状态和结束状态,不能定义中间状态,也就是说只有两个状态。
4:一条transition规则,只能定义一个属性的变化,不能涉及多个属性。
3、animation动画 由@keyframes来描述每一帧的样式
div{
animation:myAnimation 5s infinite
}
@keyframes myAnimation {
0%{left:0;transform:rotate(0);}
100%{left:200px;transform:rotate(180deg);}
}
区别:
-(1)transform仅描述元素的静态样式,常常配合transition和animation使用
-(2)transition通常和hover等事件配合使用,animation是自发的,立即播放
-(3)animation可设置循环次数
-(4)animation可设置每一帧的样式和时间,transition只能设置头尾
-(5)transition可与js配合使用,js设定要变化的样式,transition负责动画效果,如:
animation属性类似于transition,他们都是随着时间改变元素的属性值,
其主要区别在于:transition需要触发一个事件才会随着时间改变其CSS属性;
animation在不需要触发任何事件的情况下,也可以显式的随时间变化来改变元素CSS属性,达到一种动画的效果
1)动画不需要事件触发,过渡需要。
2)过渡只有一组(两个:开始-结束) 关键帧,动画可以设置多个。
29、nth-of-type和nth-child的区别是什么?
:nth-child(n)选择器,该选择器选取父元素的第n 个子元素,不论元素的类型。:nth-of-type(n)选择器,选择器选取父元素的第 n 个指定类型的子元素。
这是标题
第一个段落。
第二个段落。
第三个段落。
第四个段落。
第五个段落。
1, p:nth-child(3n+1) 包含
这是标题
2, p:nth-of-type(3n+1) 不包含
这是标题
,只选择p元素
使用公式 (an + b)。描述:表示周期的长度,n 是计数器(从 0 开始),b 是偏移值。
odd 和 even 是可用于匹配下标是奇数或偶数的子元素的关键词(第一个子元素的下标是 1)
30、:before 和 ::before区别是什么?
解答要点
- 相同点
-
- 都可以用来表示伪类对象,用来设置对象前的内容
- :befor和::before写法是等效的
- 不同点
-
- :befor是Css2的写法,::before是Css3的写法
- :before的兼容性要比::before好 ,不过在H5开发中建议使用::before比较好
31、如何让一个div 上下左右居中?
【绝对定位50%-本身50%】
position:absolute; left:50%; top:50%;
transform: translate(-50%,-50%);
.div1{
width:400px;
height:400px;
border:#CCC 1px solid;
background:#99f;
position:absolute; left:50%; top:50%;/*绝对定位*/
transform: translate(-50%,-50%);
/*translate(x,y) 括号的百分比数据,会以本身的长宽做参考,比如,本身的长为100px,高为100px. 那填(50%,50%)就是向右,向下移动50px,添加负号就是向着相反的方向移动*/
}
32、 解释下 viewport
大家知道手机的屏幕尺寸的尺寸较小,iphone5的话是320×568,然后iPhone6是375×667,这怎么小的宽度范围内,如果显示PC端的网页,如果没有做处理的话,那可能显示出来的网页会挤成一团,所以手机厂商为浏览器默认设置了一个虚拟的容器,叫布局视图(layout viewport),这个容器足够宽,且不依赖于手机屏幕的宽度,能够直接把PC上的网页放进来而不变形,iPhone上这个容器大于等于980px,你能在这个网页上双击放大任意区域来显示局部最合适的大小。
这个时候介绍另外的东西,叫做可视视图(visual viewport),这个是指你屏幕上浏览器显示区域的宽度,也就是它,决定一个屏幕能够显示的最大宽度(手指放大浏览器局部的时候,能够显示的宽度会变小),但是用户的放大缩小并不影响浏览器运行后的最大可视宽度,这个视图需要开发者进行设定,并且会受到网页内最长的可见元素的影响。
随着移动端的崛起,各个网站需要为移动端制作专门的网页,如果还是以手机虚拟容器的宽度为标准进行适配,那就是不合适的,我们需要让这个布局视图能够适应屏幕的大小,用户不用调整网页的大小就能看到一张尺寸合适的完整网页,而且能够保证显示效果的一致性,同样一个14px的文字或图片,在普通屏和高清屏上,我们看到的都是相对一致的大小。我们需要找到一个纽带,连接虚拟世界和真实世界的尺寸,进行适配。而设备自身的宽度是最合适的,确定的这个宽度的视图,被称为理想视图(ideal viewport)。
如果我们将能够显示的最大宽度设置为手机的宽度,并且将布局宽度也设定为手机的宽度,那不需要调整屏幕大小或者拖动页面,就能显示整张网页,而且屏幕的尺寸数值和屏幕的物理宽度组合在一起,就能够为CSS布局提供一把刻度相对一致的尺子,保证了显示效果。
可视视图的设定:
开发者可以用viewport的initial-scale来调整可视视图相对于屏幕真实宽度的大小比例,initial-scale=1时,可视视图的初始化最大宽度就等于屏幕宽度即理想视图的宽度,它会受到内部html节点的宽度影响,调整到最大的节点的长度(但是一般不超过1500px)。同时,如果设定user-scalable=no,那可视视图的宽度就会严格等于初始化时设定的宽度。
布局视图的设定:
布局视图的宽度等于viewport中设定的width以及可视视图的初始宽度中较大的一个,所以如果不写width属性,那布局视图的宽度也会等于屏幕的宽度,但是在可视视图初始化之后,布局视图的宽度只取决于viewport中设定的width,所以为了在旋转屏幕时能够改变布局视图的宽度,不能不写width或者将width设定为固定的数值,而是应该写上width=device-width
33、如何理解HTML结构语义化?
什么是 HTML 语义化?
简单来说,我们可以理解为:用正确的标签做正确的事情。
例如:
段落用 p 标签,标题用 h 系列标签,边栏用 aside 标签,主要内容用 main 标签。
为什么要关注 HTML 语义化?
对人:
- 便于团队的开发和维护。
- 在没有加载 CSS 的情况下也能呈现较好的内容结构与代码结构,易于阅读。
对机器:
- 有利于 SEO ,搜索引擎的爬虫依赖于标签来确定上下文和各个关键字的权重。
- 方便其他设备的解析(如屏幕阅读器、盲人阅读器等),利于无障碍阅读,提高可访问性。
总结
语义化当然并不仅仅在 HTML 中有用处,写 CSS 的时候,写 JavaScript 代码的时候,都应该采用有语义的类名和变量,并且永远不要在这些地方使用拼音。
34 CSS3中引入的伪元素有什么?
CSS中的伪元素大家以前看过::first-line,:first-letter,:before,:after;
那么在CSS3中,他对伪元素进行了一定的调整,在以前的基础上增加了一个“:”也就是现在变成了::first-letter,::first-line,::before,::after另外他还增加了一个::selection。
在css3中,已经明确规定了伪类用一个冒号来表示,而伪元素则用两个冒号来表示。
::first-line选择元素的第一行,比如说改变每个段落的第一行文本的样式,我们就可以使用这个
p::first-line {font-weight:bold;}
::before和::after这两个主要用来给元素的前面或后面插入内容,这两个常用"content"配合使用,见过最多的就是清除浮动,
.clearfix:before,
.clearfix:after {
content: ".";
display: block;
height: 0;
visibility: hidden;
}
.clearfix:after {clear: both;}
.clearfix {zoom: 1;}
对于 IE8 及更早版本中的 :before,必须声明
:before 选择器在被选元素的内容前面插入内容。例如:
welcome
div:before{
content:"hello world"
}
那么,被选元素是div,div的内容是h1,插入的内容就是content属性值“hello world”
::selection用来改变浏览网页选中文的默认效果
35、HTML5有哪些新特性,移除了哪些元素?如何处理HTML5新标签兼容问题?如何区分HTML和HTML5?
第一 HTML5有哪些新特性,移除了哪些元素
题目点评
题目涉及到范围非常的大,如果要面面俱到显然半天都答不完,可以先罗列出H5的一些新特性,不要回答那么具体,等面试官提具体的问题,所以在面试之前也要把这里的技术过一遍,至少每个技术也要做个小程序出来体验一下。
(一).H5新特性
增强了图形渲染、影音、数据存储、多任务处理等处理能力主要表现在
*1)* *绘画 canvas;*
类似windows自带的画图板,可绘制线、框、路径、图……,InternetExplorer 9、Firefox、Opera、Chrome 以及 Safari 支持 及其属性和方法。
画图需要的要素
a) 笔,用笔可以画线、圆、矩形、文本等
b) 颜色
c) 画板
*2)* *本地离线存储 localStorage*
长期存储数据,浏览器关闭后数据不丢失;
1.特点
数据永久存储,没有时间限制;大小限制5M(够用了);只存储字符串。
2.数据存取方式
localStorage.a = 3;//设置a为"3"
localStorage["a"] = "sfsf";//设置a为"sfsf",覆盖上面的值
localStorage.setItem("b","isaac");//设置b为"isaac"
var a1 = localStorage["a"];//获取a的值
var a2 = localStorage.a;//获取a的值
var b = localStorage.getItem("b");//获取b的值
var b2= localStorage.key(0);//获取第一个key的内容
localStorage.removeItem("c");//清除c的值
localStorage.clear();//清除所有的数据
推荐使用:
getItem()
setItem()
removeItem()
3.事件监听
if(window.addEventListener){
window.addEventListener("storage",handle_storage,false);//
}else if(window.attachEvent){ //兼容IE
window.attachEvent("onstorage",handle_storage);
}
function handle_storage(e){
}
对象e为localStorage对象,Chrome、Firefox支持差,IE支持较好。
3) sessionStorage的数据在浏览器关闭后自动删除;操作参考localStorage
4) 用于媒介回放的 *video**和* *audio* 元素;
5) 语意化更好的内容元素,比如article、footer、header、nav、section;
6) 表单控件,calendar、date、time、email、url、search;
7) 新的技术webworker(专用线程)
8) websocketsocket通信
9) Geolocation 地理定位
**(二)移除的元素****
纯表现的元素
- 默认字体,不设置字体,以此渲染
- 字体标签
-
水平居中
- 下划线
- 大字体
-
中横线
- 文本等宽
框架集
-
-
-
第二 如何处理HTML5新标签兼容问题?
方法一 :
1、使用静态资源的html5shiv包
2、载入后,初始化新标签的css
header, section, footer, aside, nav, main, article, figure { display: block; }
方法二:
IE6/IE7/IE8支持通过document方法产生的标签,利用这一特性让这些浏览器支持HTML5新标签
第三 如何区分HTML和HTML5?
区分:
1、在文档bai声明上du,html有很长的一段代码,zhi并且很难记dao住这段代码,都是靠zhuan工具shu直接生成,而html5却是不同,只有简简单单的声明,也方便人们的记忆,更加精简。
2、在结构语义上;html4.0没有体现结构语义化的标签,这样表示网站的头部。html5在语义上却有很大的优势。提供了一些新的html5标签。
基本说明:
1、html5最先由WHATWG(Web 超文本应用技术工作组)命名的一种超文本标记语言,随后和W3C的xhtml2.0(标准)相结合,产生现在最新一代的超文本标记语言;
2、可以简单点理解成为HTML 5 ≈ HTML4.0+CSS3+JS+API。定义的这些标签,更加有利于优化,蜘蛛能识别。节省程序员写代码的时间。最主要还是在SEO的优化上。
36、常见浏览器兼容性问题?
所谓的浏览器兼容性问题,是指因为不同的浏览器对同一段代码有不同的解析,造成页面显示效果不统一的情况。在大多数情况下,我们的需求是,无论用户用什么浏览器来查看我们的网站或者登陆我们的系统,都应该是统一的显示效果。所以浏览器的兼容性问题是前端开发人员经常会碰到和必须要解决的问题。
在学习浏览器兼容性之前,我想把前端开发人员划分为两类:
第一类是精确按照设计图开发的前端开发人员,可以说是精确到1px的,他们很容易就会发现设计图的不足,并且在很少的情况下会碰到浏览器的兼容性问题,而这些问题往往都是浏览器的bug,并且他们制作的页面后期易维护,代码重用问题少,可以说是比较牢固放心的代码。
第二类是基本按照设计图来开发的前端开发人员,很多细枝末节差距很大,不如间距,行高,图片位置等等经常会差几px。某种效果的实现也是反复调试得到,具体为什么出现这种效果还模模糊糊,整体布局十分脆弱。稍有改动就乱七八糟。代码为什么这么写还不知所以然。这类开发人员往往经常为兼容性问题所困。修改好了这个浏览器又乱了另一个浏览器。改来改去也毫无头绪。其实他们碰到的兼容性问题大部分不应该归咎于浏览器,而是他们的技术本身了。
这篇文章主要针对的是第一类,严谨型的开发人员,因此这里主要从浏览器解析差异的角度来分析兼容性问题
浏览器兼容问题一:不同浏览器的标签默认的外补丁和内补丁不同
问题症状:随便写几个标签,不加样式控制的情况下,各自的margin 和padding差异较大。
碰到频率:100%
解决方案:css里 {margin:0;padding:0;}
备注:这个是最常见的也是最易解决的一个浏览器兼容性问题,几乎所有的css文件开头都会用通配符来设置各个标签的内外补丁是0。
浏览器兼容问题二:块属性标签float后,又有横行的margin情况下,在ie6显示margin比设置的大
问题症状:常见症状是ie6中后面的一块被顶到下一行
碰到频率:90%(稍微复杂点的页面都会碰到,float布局最常见的浏览器兼容问题)
解决方案:在float的标签样式控制中加入 display:inline;将其转化为行内属性
备注:我们最常用的就是div+css布局了,而div就是一个典型的块属性标签,横向布局的时候我们通常都是用div float实现的,横向的间距设置如果用margin实现,这就是一个必然会碰到的兼容性问题。
浏览器兼容问题三:设置较小高度标签(一般小于10px),在ie6,ie7,遨游中高度超出自己设置高度
问题症状:ie6、7和遨游里这个标签的高度不受控制,超出自己设置的高度
碰到频率:60%
解决方案:给超出高度的标签设置overflow:hidden;或者设置行高line-height 小于你设置的高度。
备注:这种情况一般出现在我们设置小圆角背景的标签里。出现这个问题的原因是ie8之前的浏览器都会给标签一个最小默认的行高的高度。即使你的标签是空的,这个标签的高度还是会达到默认的行高。
浏览器兼容问题四:行内属性标签,设置display:block后采用float布局,又有横行的margin的情况,ie6间距bug(类似第二种)
问题症状:ie6里的间距比超过设置的间距
碰到几率:20%
解决方案:在display:block;后面加入display:inline;display:table;
备注:行内属性标签,为了设置宽高,我们需要设置display:block;(除了input标签比较特殊)。在用float布局并有横向的margin后,在ie6下,他就具有了块属性float后的横向margin的bug。不过因为它本身就是行内属性标签,所以我们再加上display:inline的话,它的高宽就不可设了。这时候我们还需要在display:inline后面加入display:talbe。
浏览器兼容问题五:图片默认有间距
问题症状:几个img标签放在一起的时候,有些浏览器会有默认的间距,加了问题一中提到的通配符也不起作用。
碰到几率:20%
解决方案:使用float属性为img布局
备注:因为img标签是行内属性标签,所以只要不超出容器宽度,img标签都会排在一行里,但是部分浏览器的img标签之间会有个间距。去掉这个间距使用float是正道。
浏览器兼容问题六:标签最低高度设置min-height不兼容
问题症状:因为min-height本身就是一个不兼容的css属性,所以设置min-height时不能很好的被各个浏览器兼容
碰到几率:5%
解决方案:如果我们要设置一个标签的最小高度200px,需要进行的设置为:{min-height:200px; height:auto !important; height:200px; overflow:visible;}
备注:在B/S系统前端开时,有很多情况下我们又这种需求。当内容小于一个值(如300px)时。容器的高度为300px;当内容高度大于这个值时,容器高度被撑高,而不是出现滚动条。这时候我们就会面临这个兼容性问题。
浏览器兼容问题七:透明度的兼容css设置
方法是:每写一小段代码(布局中的一行或者一块)我们都要在不同的浏览器中看是否兼容,当然熟练到一定的程度就没这么麻烦了。建议经常会碰到兼容性问题的新手使用。很多兼容性问题都是因为浏览器对标签的默认属性解析不同造成的,只要我们稍加设置都能轻松地解决这些兼容问题。如果我们熟悉标签的默认属性的话,就能很好的理解为什么会出现兼容问题以及怎么去解决这些兼容问题。
/* css hack*/
我很少使用hacker的,可能是个人习惯吧,我不喜欢写的代码ie不兼容,然后用hack来解决。不过hacker还是非常好用的。
使用hacker 我可以吧浏览器分为3类:ie6 ;ie7和遨游;其他(ie8 chrome ff safari opera等)
ie6认识的hacker 是下划线_ 和星号 *
ie7 遨游认识的hacker是星号 * (包括上面问题6中的 !important也算是hack的一种。不过实用性较小。)
比如这样一个css设置 height:300px;height:200px;_height:100px;
ie6浏览器在读到 height:300px的时候会认为高时300px;继续往下读,他也认识heihgt, 所以当ie6读到height:200px的时候会覆盖掉前一条的相冲突设置,认为高度是200px。继续往下读,ie6还认识_height,所以他又会覆盖掉200px高的设置,把高度设置为100px;
ie7和遨游也是一样的从高度300px的设置往下读。当它们读到height200px的时候就停下了,因为它们不认识_height。所以它们会把高度解析为200px;
剩下的浏览器只认识第一个height:300px;所以他们会把高度解析为300px。
因为优先级相同且想冲突的属性设置后一个会覆盖掉前一个,所以书写的次序是很重要的。
最后说一下,严谨型的开发人员会有一套合适自己的RESET.CSS。结合自己的经验尽量规避容易出现不兼容的问题。以减少hack的使用,尽量符合W3C的标准。
37、简述前端优化方式
前端性能优化是个巨大的课题,如果要面面俱到的说的话,估计三天三夜说不完。所以我们就从实际的工程应用角度出发,聊我们最常遇见的前端优化问题。
1. 减少HTTP请求次数
尽量合并图片、CSS、JS。比如加载一个页面,如果有5个css文件的话,那么会发出5次http请求,这样会让用户第一次访问你的页面的时候会长时间等待。而如果把这个5个文件合成一个的话,就只需要发出一次http请求,节省网络请求时间,加快页面的加载。
2. 使用CDN
网站上静态资源即css、js全都使用cdn分发,图片亦然。
3. 避免空的src和href
当link标签的href属性为空、script标签的src属性为空的时候,浏览器渲染的时候会把当前页面的URL作为它们的属性值,从而把页面的内容加载进来作为它们的值。所以要避免犯这样的疏忽。
4. 为文件头指定Expires
Exipres是用来设置文件的过期时间的,一般对css、js、图片资源有效。 他可以使内容具有缓存性,这样下回再访问同样的资源时就通过浏览器缓存区读取,不需要再发出http请求。如下例子:
新浪微博的这个css文件的Expires时间是2016-5-04 09:14:14.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1LrjCdrc-1649150971255)(https://pic4.zhimg.com/80/v2-4456a97b4ef9f878840876f872e49177_720w.png)]
5. 使用gzip压缩内容
gzip能够压缩任何一个文本类型的响应,包括html,xml,json。大大缩小请求返回的数据量。
6. 把CSS放到顶部
网页上的资源加载时从上网下顺序加载的,所以css放在页面的顶部能够优先渲染页面,让用户感觉页面加载很快。
7. 把JS放到底部
加载js时会对后续的资源造成阻塞,必须得等js加载完才去加载后续的文件 ,所以就把js放在页面底部最后加载。
欢迎加入前端直播学习群一起学习交流:512676244
8. 避免使用CSS表达式
举个css表达式的例子
HTML复制全屏
1
font-color: expression( (new Date()).getHours()%3 ? “#FFFFFF" : “#AAAAAA" );
2
这个表达式会持续的在页面上计算样式,影响页面的性能。并且css表达式只被IE支持。
9. 将CSS和JS放到外部文件中
目的是缓存文件,可以参考原则4。 但有时候为了减少请求,也会直接写到页面里,需根据PV和IP的比例权衡。
10. 权衡DNS查找次数
减少主机名可以节省响应时间。但同时,需要注意,减少主机会减少页面中并行下载的数量。
IE浏览器在同一时刻只能从同一域名下载两个文件。当在一个页面显示多张图片时,IE 用户的图片下载速度就会受到影响。所以新浪会搞N个二级域名来放图片。
下面是新浪微博的图片域名,我们可以看到他有多个域名,这样可以保证这些不同域名能够同时去下载图片,而不用排队。不过如果当使用的域名过多时,响应时间就会慢,因为不用响应域名时间不一致。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MYe6my19-1649150971256)(https://pic2.zhimg.com/80/v2-2eb9a87e8ad38305e382cee771f1d0dd_720w.png)]
11. 精简CSS和JS
这里就涉及到css和js的压缩了。比如下面的新浪的一个css文件,把空格回车全部去掉,减少文件的大小。现在的压缩工具有很多,基本主流的前端构建工具都能进行css和js文件的压缩,如grunt,glup等。
12. 避免跳转
有种现象会比较坑爹,看起来没什么差别,其实多次了一次页面跳转。比如当URL本该有斜杠(/)却被忽略掉时。例如,当我们要访问 http://baidu.com 时,实际上返回的是一个包含301代码的跳转,它指向的是 http://baidu.com/(注意末尾的斜杠)。在nginx服务器可以使用rewrite;Apache服务器中可以使用Alias 或者 mod_rewrite或者the DirectorySlash来避免。
另一种是不用域名之间的跳转, 比如访问 http://baidu.com/bbs 跳转到http://bbs.baidu.com/。那么可以通过使用Alias或者mod_rewirte建立CNAME(保存一个域名和另外一个域名之间关系的DNS记录)来替代。
13. 删除重复的JS和CSS
重复调用脚本,除了增加额外的HTTP请求外,多次运算也会浪费时间。在IE和Firefox中不管脚本是否可缓存,它们都存在重复运算JavaScript的问题。
14. 配置ETags
它用来判断浏览器缓存里的元素是否和原来服务器上的一致。比last-modified date更具有弹性,例如某个文件在1秒内修改了10次,Etag可以综合Inode(文件的索引节点(inode)数),MTime(修改时间)和Size来精准的进行判断,避开UNIX记录MTime只能精确到秒的问题。 服务器集群使用,可取后两个参数。使用ETags减少Web应用带宽和负载
欢迎加入前端全栈开发交流圈一起学习交流:512676244
15. 可缓存的AJAX
异步请求同样的造成用户等待,所以使用ajax请求时,要主动告诉浏览器如果该请求有缓存就去请求缓存内容。如下代码片段, cache:true就是显式的要求如果当前请求有缓存的话,直接使用缓存
HTML复制全屏
1
$.ajax(
2
{
3
url : ‘url’,
4
dataType : “json”,
5
cache: true,
6
success : function(son, status){
7
}
8
16. 使用GET来完成AJAX请求
当使用XMLHttpRequest时,浏览器中的POST方法是一个“两步走”的过程:首先发送文件头,然后才发送数据。因此使用GET获取数据时更加有意义。
17. 减少DOM元素数量
这是一门大学问,这里可以引申出一堆优化的细节。想要具体研究的可以看后面推荐书籍。总之大原则减少DOM数量,就会减少浏览器的解析负担。
18. 避免404
比如外链的css、js文件出现问题返回404时,会破坏浏览器的并行加载。
19. 减少Cookie的大小
Cookie里面别塞那么多东西,因为每个请求都得带着他跑。
20. 使用无cookie的域
比如CSS、js、图片等,客户端请求静态文件的时候,减少了 Cookie 的反复传输对主域名的影响。
21. 不要使用滤镜
IE独有属性AlphaImageLoader用于修正7.0以下版本中显示PNG图片的半透明效果。这个滤镜的问题在于浏览器加载图片时它会终止内容的呈现并且冻结浏览器。在每一个元素(不仅仅是图片)它都会运算一次,增加了内存开支,因此它的问题是多方面的。
完全避免使用AlphaImageLoader的最好方法就是使用PNG8格式来代替,这种格式能在IE中很好地工作。如果你确实需要使用AlphaImageLoader,请使用下划线_filter又使之对IE7以上版本的用户无效。
22. 不要在HTML中缩放图片
比如你需要的图片尺寸是50* 50
那就不用用一张500*500的大尺寸图片,影响加载
23. 缩小favicon.ico并缓存
以上是Yslow的23个优化原则,基本可以涵盖现在前端大部分的性能优化原则了,很多更加geek和精细优化方法都是从这些原则里面延伸出来的。 具体想了解更多优化细则的童鞋建议去看看下面的一本书,毕竟页数多讲的也细嘛:
38、块级元素?行内元素?空元素?
块元素(block element)一般是其他元素的容器元素,能容纳其他块元素或内联元素。块元素就好比一个四方块,可以放其他的四方块,并可以呈现在页面上任何地方。
- 默认情况下块元素,是独占一行的
- 常见的块元素:div、p、h1-h6、form(只能用来容纳其他块元素)、hr、table、ul、ol等
- 高度,行高以及外边距和内边距都可控制
- 宽度缺省是它的容器的100%,除非设定一个宽度
- 它可以容纳内联元素和其他块元素
行内元素(inline element)也叫内嵌元素或内联元素,一般都是基于语义级(semantic)的基本元素。行内元素只能容纳文本或者其他行内元素,常见行内元素有a、span、img。CSS权威指南》中文字显示:任何不是块级元素的可见元素都是行内元素。其表现的特性是“行布局”形式,这里的“行布局”的意思就是说其表现形式始终以行进行显示。比如,我们设定一个内联元素border-bottom:1px solid #000;时其表现是以每行进行重复,每一行下方都会有一条黑色的细线。如果是块级元素那么所显示的的黑线只会在块的下方出现。
- 和其他元素都在一行上
- 高,行高及外边距和内边距不可改变
- 宽度就是它的文字或图片的宽度,不可改变
- 行内元素只能容纳文本或者其他行内元素
块元素和行内元素的区别
- 块元素,总是在新行上开始;行内元素,和其他元素都在一行上
- 块元素,能容纳其他块元素或行内元素;而内联元素,只能容纳文本或者其他行内元素
- 块元素中高度,行高以及顶和底边距都可控制;内联元素中高,行高及顶和底边距不可改变
- 说白了,行内元素就好像一个单词;块级元素就好像一个段落,如果不另加定义的话,它将独立一行出现
文档流
- 将窗体自上而下分成一行行, 并在每行中按从左至右的顺序排放元素,即为文档流
- 每个非浮动块级元素都独占一行, 浮动元素则按规定浮在行的一端。 若当前行容不下, 则另起新行再浮动
- 内联元素也不会独占一行。 几乎所有元素(包括块级,内联和列表元素)均可生成子行, 用于摆放子元素
- 有三种情况将使得元素脱离文档流而存在,分别是浮动,绝对定位, 固定定位。 但是在IE中浮动元素也存在于文档流中
- 浮动元素不占任何正常文档流空间,而浮动元素的定位还是基于正常的文档流,然后从文档流中抽出并尽可能远的移动至左侧或者右侧。文字内容会围绕在浮动元素周围。当一个元素从正常文档流中抽出后,仍然在文档流中的其他元素将忽略该元素并填补他原先的空间。
- 基于文档流, 我们可以很容易理解以下的定位模式:相对定位(relative), 即相对于元素在文档流中位置进行偏移,但保留原占位。绝对定位(absolute), 即完全脱离文档流, 相对于position属性非static值的最近父级元素进行偏移。固定定位(fixed), 即完全脱离文档流, 相对于视区进行偏移。
空元素
空元素的意思bai是:在HTML元素中,没有内容的 HTML 元素被称为空元素。
基本概述:
1,在用来描述网页的计算机语言中,有一种超文本标记语言,被称为HTML(Hyper Text Markup Language) 。而构成HTML内容的标记语言是由一套标记标签组成。这套标记标签通常被称为 HTML 标签 (HTML tag)。,
2,HTML 标签是由尖括号包围的关键词,比如 ,通常是成对出现的,比如 和 。
3,这些成对出现的HTML 标签,第一个标签是开始标签,第二个标签是结束标签。大多数HTML 标签在开始标签和结束标签之间都具有内容,而某些标签则没有内容。,
4,HTML中,从开始标签(start tag)到结束标签(end tag)的所有代码,被称为HTML元素。
5,由于HTML元素的内容是开始标签与结束标签之间的内容。而某些 HTML 元素具有空内容。(empty content),那些含有空内容的HTML元素,就是空元素。空元素是在开始标签中关闭的。
举例说明:
1,
就是没有关闭标签的空元素(
标签定义换行)。,
2,在 XHTML、XML 以及未来版本的 HTML 中,所有元素都必须被关闭。
3,在开始标签中添加斜杠,比如
,是关闭空元素的正确方法,HTML、XHTML 和 XML 都接受这种方式。
39、media属性?
媒体类型
all – 所有设备。如没有only和not限定可以省略,省略不写时默认为all
print – 打印机
screen – 计算机屏幕
等等
and & not & only & 逗号 操作符
and – 所有媒体属性表达式为真时,媒体查询结果才为真。
not – 对媒体结果求值取反。如果有逗号操作符,其作用范围至逗号处为止
@media not all and (min-width:800px){...}
等价于
@media not (all and (min-width:800px)){...}
而不是
@media (not all) and (min-width:800px){...}
@media not screen and (color), print and (color)
等价于
@media (not (screen and (color))), print and (color)
不支持媒体查询的浏览器会解析成media=screen,媒体属性不会求值。从而错误地应用样式。
, – 逗号相当于or(或者)
常用媒体属性
width : 可视宽度
height : 可视高度
device-width: 设备宽度
device-height: 设备高度
orientation: 方向
aspect-ratio: 宽高比
color: 颜色
device-aspect-ratio: 设备宽高比
详细信息参考MDN文档:css媒体查询
40、meta标签的name属性值?
就是头文件里的meta标签及其属性等等。(之前只知道utf-8还有Author)
于是去网上查找了相关资料,在这里简单描述一下:
name是描述网页的,对应于Content(网页内容)。ame的value值(name=“”)指定所提供信息的类型。有些值是已经定义好的。例如description(说明)、keyword(关键字)、refresh(刷新)等。还可以指定其他任意值,如:creationdate(创建日期) 、document ID(文档编号)和level(等级)等。
name的content指定实际内容。如:如果指定level(等级)为value,则Content可能是beginner(初)、intermediate(中)、advanced(高)。
1.Keywords(关键字)*
说明:为搜索引擎提供关键字列表(content里的关键字记得要用逗号隔开)
eg:
2.Copyright (版权)
说明:标注声明相关版权
eg:
3.Robots (机器人向导)
说明:Robots用来告诉搜索机器人页面需要或者不需要索引。Content的參数有all、none、index、noindex、follow、nofollow,默认是all。
all:文件将被检索,且页面上的链接能够被查询。
none:文件将不被检索。且页面上的链接不能够被查询。(和 “noindex, no follow” 起同样作用)
index:文件将被检索;(让robot/spider登录)
follow:页面上的链接能够被查询;
noindex:文件将不被检索,但页面上的链接能够被查询;(不让robot/spider登录)
nofollow:文件将不被检索,页面上的链接能够被查询。(不让robot/spider顺着此页的连接往下探找)
eg:
4.Renderer(指定默认渲染内核)
说明:指定双核浏览器默认以哪种方式渲染页面
eg: //强制指定webkit内核
5.Viewport(视窗/移动端)
说明:是用户网页的可视区域,即“视区”。
eg:
width:控制 viewport 的大小,可以指定的一个值,如 600,或者特殊的值,如 device-width 为设备的宽度(单位为缩放为 100% 时的 CSS 的像素)。
height:和 width 相对应,指定高度。
initial-scale:初始缩放比例,也即是当页面第一次 load 的时候缩放比例。
maximum-scale:允许用户缩放到的最大比例。
minimum-scale:允许用户缩放到的最小比例。
user-scalable:用户是否可以手动缩放。
eg:
a. 设置屏幕宽度为设备宽度,禁止用户手动调整缩放
b. 设置屏幕密度为高频,中频,低频自己主动缩放,禁止用户手动调整缩放)
41、一般做手机页面切图的几种方式
针对手机端页面,通常情况下,需要对设计图片切两种图片。
①:dpr:2------切两倍图(即设计原图大小,因为设计图是按原来的手机尺寸放大两倍之后的) 一般保存为xxx@2x
②:dpr:3------切三倍图(即设计原图大小的1.5倍,因为设计图是按原来的手机尺寸放大两倍之后的) 一般保存为xxx@3x
淘宝的做法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cO6hZehr-1649150971256)(https://riyugo.com/i/2021/02/22/o15bqq.png)]
例如:设计图是720px的宽度。
由于设计图是放大两倍的。所以一倍的大小是=720/2 = 360px;
放大三倍图就是= 3603 = 7201.5 = 1080px;
42、px/em/rem有什么区别?为什么通常给font-size 设置的字体为62.5%
首先px是像素单位 是多少像素就是多少像素
1、rem单位可谓集相对大小和绝对大小的优点于一身
2、和em不同的是rem总是相对于根元素(如:root{}),而不像em一样使用级联的方式来计算尺寸。这种相对单位使用起来更简单。
3、rem支持IE9及以上,意思是相对于根元素html(网页),不会像em那样,依赖于父元素的字体大小,而造成混乱。使用起来安全了很多。
例如:
我是14px=1.4rem我是12px=1.2rem
样式为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kXrLzpf0-1649150971256)(https://pic3.zhimg.com/80/v2-a92a2f81145df277235969773d82ff3e_720w.png)]
注意:
- 值得注意的浏览器支持问题: IE8,Safari 4或 iOS 3.2中不支持rem单位。
- 如果你的用户群都使用最新版的浏览器,那推荐使用rem,如果要考虑兼容性,那就使用px,或者两者同时使用。
这就是我整体对px、em、rem区别的总结
43、sass和scss有什么区别?
当我们说起 Sass ,我们经常指的是两种事物:一种 css 预处理器和一种语言。我们经常这样说,“我们正在使用 Sass”,或者 “这是一个 Sass mixin”。同时,Sass (预处理器)有两种不同的语法:
- Sass,一种缩进语法
- SCSS,一种 CSS-like 语法
44、如果对css进行优化如何处理?
加载性能
这个方面相关的 best practice 太多了,网上随便找一找就是一堆资料,比如不要用 import 啊,压缩啊等等,主要是从减少文件体积、减少阻塞加载、提高并发方面入手的,任何 hint 都逃不出这几个大方向。
选择器性能
可以参考 GitHub 的这个分享 https://speakerdeck.com/jonrohan/githubs-css-performance,但 selector 的对整体性能的影响可以忽略不计了,selector 的考察更多是规范化和可维护性、健壮性方面,很少有人在实际工作当中会把选择器性能作为重点关注对象的,但也像 GitHub 这个分享里面说的一样——知道总比不知道好。
渲染性能
渲染性能是 CSS 优化最重要的关注对象。页面渲染 junky 过多?看看是不是大量使用了 text-shadow?是不是开了字体抗锯齿?CSS 动画怎么实现的?合理利用 GPU 加速了吗?什么你用了 Flexible Box Model?有没有测试换个 layout 策略对 render performance 的影响?这个方面搜索一下 CSS render performance 或者 CSS animation performance 也会有一堆一堆的资料可供参考。
可维护性、健壮性
命名合理吗?结构层次设计是否足够健壮?对样式进行抽象复用了吗?优雅的 CSS 不仅仅会影响后期的维护成本,也会对加载性能等方面产生影响。这方面可以多找一些 OOCSS(不是说就要用 OOCSS,而是说多了解一下)等等不同 CSS Strategy 的信息,取长补短。
45、如何对css文件进行压缩合并?
使用gulp。用法很简单,看下官网例子很快就上手了。
可以用gulp-concat合并文件,gulp-uglify对js进行压缩,gulp-clean-css对css进行压缩,gulp-plumber避免过程出错导致gulp退出。
46、什么是组件?什么是模块化?有什么区别?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oGMGRz1e-1649150971256)(https://pic1.zhimg.com/80/b25efd3e8af188b5ab36ccb66baddd71_1440w.jpg?source=1940ef5c)]
模块化的诉求是解耦,组件化的诉求是好用
组件化编程: 将js css html包装一起提供方法和效果; 模块化: 将相同的功能抽取出来 存放在一个位置进行编程
47、如何实现图片和文字在同一行显示?
Document
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QGsfxISp-1649150971257)(https://images0.cnblogs.com/blog/707050/201506/251022555025323.png)]
48、a标签中 active hover link visited 正确的设置顺序是什么?
1. 标签
我们先说一说标签是干啥用的。
标签定义超链接,用于从一张页面链接到另一张页面。
元素最重要的属性是 href 属性,它指示链接的目标。
在所有浏览器中,链接的默认外观是:
- 未被访问的链接带有下划线而且是蓝色的
- 已被访问的链接带有下划线而且是紫色的
- 活动链接带有下划线而且是红色的
标签还有一个很重要的属性:target,它用于规定在何处打开链接文档,取值有:_blank;_parent;_self;_top。这个我后面也会小小地总结一下。
2. a链接的四种状态
伪类是CSS 用于向某些选择器添加特殊的效果。
a标签中有四个:link、visited、hover、active
(1)link
说明:设置a对象在未被访问前的样式表属性。
(2)visited
说明:设置a对象在其链接地址已被访问过时的样式表属性。
(3)hover
说明:设置对象在其鼠标悬停时的样式表属性。
(4)active
说明:设置对象在被用户激活(在鼠标点击与释放之间发生的事件)时的样式表属性。
定义CSS时候的顺序不同,也会直接导致链接显示的效果不同。原因可能在于浏览器解释CSS时遵循的“就近原则”。正确的顺序:a:link、a:visited、a:hover、a:active
解释:
- link:连接平常的状态
- visited:连接被访问过之后
- hover:鼠标放到连接上的时候
- active:连接被按下的时候
举例来说:
我想让未访问链接颜色为蓝色,活动链接为绿色,已访问链接为红色:
第一种情况:我定义的顺序是a:visited、a:hover、a:link,这时会发现:把鼠标放到未访问过的蓝色链接上时,它并不变成绿色,只有放在已访问的红色链接上,链接才会变绿。
第二种情况:我把CSS定义顺序调整为:a:link、a:visited、a:hover,这时,无论你鼠标经过的链接有没有被访问过,它都会变成绿色啦。
这是因为,一个鼠标经过的未访问链接同时拥有a:link、a:hover两种属性,在第一种情况下,a:link离它最近,所以它优先满足a:link,而放弃a:hover的重复定义。在第二种情况,无论链接有没有被访问过,它首先要检查是否符合a:hover的标准(即是否有鼠标经过它),满足,则变成绿色,不满足,则继续向上查找,一直找到满足条件的定义为止。
一句话:在CSS中,如果对于相同元素有针对不同条件的定义,宜将最一般的条件放在最上面,并依次向下,保证最下面的是最特殊的条件。这样,浏览器在显示元素时,才会从特殊到一般、逐级向上验证条件,才会使你的每一个CSS语句都起到效果。当然,如果故意打乱顺序,也会造成一些特殊的效果。比如,可以为链接制造出下划线颜色与文字颜色的差异。
其实这个CSS问题早已有高人提出啦,还是个老外呢。他给总结了一个便于记忆的“爱恨原则”(LoVe/HAte),即四种伪类的首字母:LVHA。
再重复一遍正确的顺序:a:link、a:visited、a:hover、a:active .
最后经验补充:
1.鼠标经过的“未访问链接”同时拥有a:link、a:hover两种属性,后面的属性会覆盖前面的属性定义;
2.鼠标经过的“已访问链接”同时拥有a:visited、a:hover两种属性,后面的属性会覆盖前面的属性定义;
所以说,a:hover定义一定要放在a:link、a:visited的后面!
49、a标签中,如何禁用href 跳转页面或定位链接
1、e.preventDefault();
2、href="javascript:void(0);"
50、手机端上图片长时间点击会选中图片,如何处理?
onselect=function() {return false}
51、video标签的几个属性和方法
- src :视频的属性
- poster:视频封面,没有播放时显示的图片
- preload:预加载
- autoplay:自动播放
- loop:循环播放
- controls:浏览器自带的控制条
- width:视频宽度
- height:视频高度
52、常见的视频编码格式有几种?视频格式有几种?
avi mpg rmvb rm mp4 3gp
53、canvas在标签上设置宽高和在style中设置宽高有什么区别?
在html中,我们给一个元素设置宽高通常会使用css样式设置。而canvas他有自己的宽高属性,我们可以在canvas中设置宽和高,但是canvas的width与height属性与css中设置width与height有没有区别,有什么区别呢,我们可以通过代码去实现对比一下。
第一种: 在canvas中设置宽高
代码:
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Documenttitle>
<style>
canvas {
border: 1px solid #000;
}
style>
head>
<body>
<canvas id="mycanvas" width="200" height="200">canvas>
body>
html>
<script>
var mycanvas = document.getElementById('mycanvas');
var ctx = mycanvas.getContext('2d');
ctx.moveTo(50,50);
ctx.lineTo(150,50);
ctx.lineTo(150,150);
ctx.lineTo(50,150);
ctx.closePath();
ctx.fillStyle = 'red';
ctx.fill();
script>
效果:

然后我们将宽高调整为500;
代码:
<canvas id="mycanvas" width="200" height="200">canvas>
效果:

以上我们可以看的,画布明显变大,里面的图形大小不变。
第二种:在style中设置宽高
代码:
<head>
<style>
canvas {
border: 1px solid #000;
width: 500px;
height: 500px;
}
style>
head>
<body>
<canvas id="mycanvas">canvas>
body>
效果:

我们发现,不仅画布变大了,而且里面的图形也会变大变形。
可以简单理解:canvas相当与我们电脑中自带的“画图”工具,有画布,画板,绘图工具构成。当我在canvas中设置宽高,相当于使用鼠标拖动了画布的边框使画布变大,但是里面的内容不会变化。当我在style中设置了宽高,相当于点击放大镜对整个图像进行方法,使得里面的内容也会跟着变化。
54、什么是border-image?
这里通过三个实例讲解一下border-image:

原图是这样子的:

接下来我们使用border-image来处理这个图片为边框图:

代码:
<div style="
background:#F4FFFA;
width:100%;
height:210px;
border:41px solid #ddd;
border-image:url(./imgs/333.png) 70 repeat ">
</div>
55、解释在ie低版本下的怪异盒模型和CSS3的怪异盒模型和弹性盒模型
一、怪异盒模型
怪异盒模型的属性是box-sizing,他有两个属性值:
1、content-box
这是由 CSS2.1 规定的宽度高度行为。宽度和高度分别应用到元素的内容框。在宽度和高度之外绘制元素的内边距和边框。
简而言之就是,一般的盒子都是属于这种,最显著的特点就是加上padding后,盒子会被撑大,需要减去对应的高度或宽度。
 2、border-box
2、border-box
为元素设定的宽度和高度决定了元素的边框盒。就是说,为元素指定的任何内边距和边框都将在已设定的宽度和高度内进行绘制。
通过从已设定的宽度和高度分别减去边框和内边距才能得到内容的宽度和高度。
简而言之,为盒子添加高度或宽度之后,再给盒子添加border和padding不会使盒子撑大,边框和padding都限制在盒子内部,常用于移动端。
二、弹性盒布局
Flex容器:采用 Flex 布局的元素的父元素;
Flex项目:采用 Flex 布局的元素的父元素的子元素;
容器默认存在两根轴:水平的主轴和垂直的交叉轴。主轴的开始位置(与边框的交叉点)叫做main start,结束位置叫做main end;
交叉轴的开始位置叫做cross start,结束位置叫做cross end。项目默认沿主轴排列。
单个项目占据的主轴空间叫做main size,占据的交叉轴空间叫做cross size。
能实现下面这种骰子布局,那么恭喜你,就说明弹性盒已经掌握了,下面介绍弹性盒具体的用法及案例

flex容器属性
1、触发弹性盒:display:flex、inline-flex
注意,设为 Flex 布局以后,子元素的float、clear和vertical-align属性将失效。
2、flex-direction属性 决定主轴的方向(即项目的排列方向)
flex-direction: row | row-reverse | column | column-reverse;
3、flex-wrap属性,定义子元素是否换行显示
flex-wrap: nowrap(默认值,不换行) | wrap(换行) | wrap-reverse(反向换行);
4、 flex-flow
flex-flow属性是flex-direction属性和flex-wrap属性的简写形式,默认值为row nowrap;
5、 justify-content属性 定义了项目在主轴()上的对齐方式
justify-content: flex-start | flex-end | center | space-between(两端对齐) | space-around(自动分配);
6、align-items属性定义项目在侧轴上如何对齐
align-items: flex-start | flex-end | center | baseline | stretch(默认值);
7、align-content属性定义了多根轴线的对齐方式。对于单行子元素,该属性不起作用。
align-content: flex-start | flex-end | center | space-between | space-around | stretch;
align-content在侧轴上执行样式的时候,会把默认的间距给合并。对于单行子元素,该属性不起作用
flex项目属性
1、align-self属性
说明:
Internet Explorer 和 Safari 浏览器不支持 align-self 属性
align-self 属性规定灵活容器内被选中项目的对齐方式。
注意:align-self 属性可重写灵活容器的 align-items 属性。
属性值
auto 默认值。元素继承了它的父容器的 align-items 属性。如果没有父容器则为 “stretch”。
Stretch 元素被拉伸以适应容器。
Center 元素位于容器的中心。
flex-start 元素位于容器的开头。
flex-end 元素位于容器的结尾。
2、order
说明:
number排序优先级,数字越大越往后排,默认为0,支持负数。
3、flex
说明:
复合属性。设置或检索弹性盒模型对象的子元素如何分配空间
详细属性值:
缩写「flex: 1」, 则其计算值为「1 1 0%」
缩写「flex: auto」, 则其计算值为「1 1 auto」
flex: none」, 则其计算值为「0 0 auto」
flex: 0 auto」或者「flex: initial」, 则其计算值为「0 1 auto」,即「flex」初始值
4、flex-xxx
flex-grow
一个数字,规定项目将相对于其他灵活的项目进行扩展的量。
flex-shrink
一个数字,规定项目将相对于其他灵活的项目进行收缩的量。
flex-basis
项目的长度
56、animation对应的属性
定义动画的速度曲线
ease:动画以低速开始,然后加快,在结束前变慢。
linear:匀速
ease-in:动画以低速开始
ease-out:动画以低速结束
ease-in-out:动画以低速开始和结束,相对于ease缓慢,速度更均匀
step-start:按keyframes设置逐帧显示,第一帧为keyframes设置的第一帧。
step-end:按keyframes设置逐帧显示,第一帧为样式的初始值。
steps([, [ start | end ] ]?):把keyframes里设置的一帧等分为几帧,start为第一次显示第一帧,end第一次显示样式的初始值,例如:steps(4,start)
cubic-bezier(, , , ):在 cubic-bezier 函数中自己的值。可能的值是从 0 到 1 的数值。贝兹曲线限制了首尾两控制点的位置,通过调整中间两控制点的位置可以灵活得到常用的动画效果
animation-iteration-count
动画迭代次数,默认就1次,可以设置2次,3次,4次,…infinite表示无限
animation-duration
指一个动画周期持续时间。单位秒s或毫秒ms.
animation-delay
指动画延时执行时间。单位秒s或毫秒ms.
animation-direction
指动画时间轴上帧前进的方向。
normal:默认值,表示一直向前,最后一帧结束后回到第一帧
reverse:与normal的运行方向相反
alternate:往前播放完了之后,然后再倒带,倒带到头了再往后播放
alternate-reverse:与alternate的运行方向相反
animation-fill-mode
设置动画结束后的状态
none:默认值。不设置对象动画之外的状态,DOM未进行动画前状态
forwards:设置对象状态为动画结束时的状态,100%或to时,当设置animation-direcdtion为reverse时动画结束后显示为keyframes第一帧
backwards:设置对象状态为动画开始时的状态,(测试显示DOM未进行动画前状态)
both:设置对象状态为动画结束或开始的状态,结束时状态优先
57、说说对transition的了解
*transition是一个选择器的属性监听器*
**实现原理的猜想:****
*当**css的选择器中的transition监听的**属性被渲染到CSS样式所对应的DOM模型**时**,transition对渲染过程使用定时器结合物理定理运动函数的公式实现了一个样式被渲染到模型的过度动画*
*我把那个DOM比作现实中的模板,样式比作原料,过度就是让机器瞬间完成原料涂上去变为缓慢涂上去*
58、H5新特性有哪些?
HTML5 中的一些有趣的新特性:
- 用于绘画的 canvas 元素
- 用于媒介回放的 video 和 audio 元素
- 对本地离线存储的更好的支持
- 新的特殊内容元素,比如 article、footer、header、nav、section
- 新的表单控件,比如 calendar、date、time、email、url、search
59 canvas如何绘制一个三角形/圆角矩形
绘制三角形
var draw = function(x1, y1, x2, y2, x3, y3, color, type) {
ctx.beginPath();
ctx.moveTo(x1, y1);
ctx.lineTo(x2, y2);
ctx.lineTo(x3, y3);
ctx[type + 'Style'] = color;
ctx.closePath();
ctx[type]();
}
参数解释:x1(2、3),y1(2、3)-三角形的三个点的坐标;color-绘制颜色;type-绘制类型(‘fill’和’stroke’)。
实例如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JwYUxOHT-1649150971257)(https://files.cnblogs.com/files/jarson-7426/sanjiao.gif)]
绘制(圆角)矩形
var draw = function(x, y, width, height, radius, color, type){
ctx.beginPath();
ctx.moveTo(x, y+radius);
ctx.lineTo(x, y+height-radius);
ctx.quadraticCurveTo(x, y+height, x+radius, y+height);
ctx.lineTo(x+width-radius, y+height);
ctx.quadraticCurveTo(x+width, y+height, x+width, y+height-radius);
ctx.lineTo(x+width, y+radius);
ctx.quadraticCurveTo(x+width, y, x+width-radius, y);
ctx.lineTo(x+radius, y);
ctx.quadraticCurveTo(x, y, x, y+radius);
ctx[type + 'Style'] = color || params.color;
ctx.closePath();
ctx[type]();
}
参数解释:x,y-左上角点的坐标;width、height-宽高;radius-圆角;color-绘制颜色;type-绘制类型(‘fill’和’stroke’)。
实例如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lVMCyehy-1649150971257)(https://files.cnblogs.com/files/jarson-7426/rect.gif)]
60、CSS清除浮动的几种方式 简略回答即可
在非IE浏览器(如Firefox)下,当容器的高度为auto,且容器的内容中有浮动(float为left或right)的元素,在这种情况下,容器的高度不能自动伸长以适应内容的高度,使得内容溢出到容器外面而影响(甚至破坏)布局的现象。这个现象叫浮动溢出,为了防止这个现象的出现而进行的CSS处理,就叫CSS清除浮动。
1、父级div定义伪类:after和zoom
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C0VBr7FA-1649150971257)(https://pic3.zhimg.com/80/v2-a1036e4343cfab5edd05b6bba710cb86_720w.jpg)]
- 原理:IE8以上和非IE浏览器才支持:after,原理和方法2有点类似,zoom(IE转有属性)可解决IE6,ie7浮动问题。
- 优点:浏览器支持好,不容易出现怪问题(目前:大型网站都有使用,如:腾讯,网易,新浪等等)
- 缺点:代码多,不少初学者不理解原理,要两句代码结合使用,才能让主流浏览器都支持
- 建议:推荐使用,建议定义公共类,以减少CSS代码
2、在结尾处添加空div标签clear:both
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KpKQcV3v-1649150971258)(https://pic3.zhimg.com/80/v2-6734229fd224b259d863749a5d9e4cde_720w.jpg)]
- 原理:添加一个空div,利用css提高的clear:both清楚浮动,让父级div能自动获取到高度
- 优点:简单、代码少、浏览器支持好、不容易出现怪问题
- 缺点:不少初学者不理解原理;如果页面浮动布局多,就要增加很多空div,让人感觉很不爽
- 建议:不推荐使用,但此方法是以前主要使用的一种消除浮动的方法
3、父级div定义height
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9nVaFklP-1649150971258)(https://pic3.zhimg.com/80/v2-32cc0b3fd2c74b1962264f02c400bc7e_720w.jpg)]
- 原理:父级div手动定义height,就解决了父级div无法自动获取到高度的问题
- 有点:简单,代码少,容易掌握
- 缺点:只合适高度固定的布局,要给出精确的高度,如果高度和父级div不一样时,会产生问题
- 建议:不推荐使用,之间以高度固定的布局时使用
4、父级div定义overflow:hidden
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pUagkEOw-1649150971258)(https://pic3.zhimg.com/80/v2-cf911e59712e5f500842135b681bfafa_720w.jpg)]
原理:必须定义width或zoom:1,同时不能定义height,使用overflow:hidden时,浏览器会自动坚持浮动区域的高度
- 优点:简单,代码少,浏览器支持好
- 缺点:不能和position配合使用,因为超出的尺寸的会被隐藏
- 建议:只推荐没有使用position或者对overflow:hidden理解比较深的朋友使用
5、父级div定义overflow:auto
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nF5XtRgu-1649150971258)(https://pic3.zhimg.com/80/v2-c9665327182a2f92e248e8199b475f52_720w.jpg)]
- 原理:必须定义width或zoom:1,同时不能定义height,使用overflow:auto时,浏览器会自动检查浮动区域的高度
- 优点:简单,代码少,浏览器支持好
- 缺点:内部宽高超过父级div时,会出现滚动条。
- 建议:不推荐使用,如果你需要出现滚动条或者确保你的代码不会出现滚动条就使用吧。
6、父级div也一起浮动
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BUbyxBAn-1649150971259)(https://pic4.zhimg.com/80/v2-f56c0672a1364eab24fc87bd6b8c4caf_720w.jpg)]
- 原理:所有代码一起浮动,就变成了一个整体
- 优点:没有优点
- 缺点:会产生新的浮动问题。
- 建议:不推荐使用,只作了解。
7、父级div定义display:table
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x5dyXumJ-1649150971259)(https://pic4.zhimg.com/80/v2-8af66abeeea8b883411df64fe2e2bed3_720w.jpg)]
- 原理:将div属性变成表格
- 优点:没有优点
- 缺点:会产生新的未知问题
- 建议:不推荐使用,只作了解
8、结尾处加br标签clear:both
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zHHvQhab-1649150971259)(https://pic2.zhimg.com/80/v2-05b8e1ab4972195bb9659a588d2f1de9_720w.jpg)]
- 原理:父级div定义zoom:1来解决IE浮动问题,结尾处加br标签clear:both
- 建议:不推荐只用,只作了解
61、为什么要初始化CSS样式
因为浏览器的兼容问题,不同浏览器对有些标签的默认值是不同的,如果没对CSS初始化往往会出现浏览器之间的页面显示差异。
当然,初始化样式会对SEO有一定的影响,但鱼和熊掌不可兼得,但力求影响最小的情况下初始化。
*最简单的初始化方法就是: * {padding: 0; margin: 0;} (不建议)
62、CSS3 有哪些新特性
新增选择器 p:nth-child(n){color: rgba(255, 0, 0, 0.75)}
弹性盒模型 display: flex;
多列布局 column-count: 5;
媒体查询 @media (max-width: 480px) {.box: {column-count: 1;}}
个性化字体 @font-face{font-family:BorderWeb;src:url(BORDERW0.eot);}
颜色透明度 color: rgba(255, 0, 0, 0.75);
圆角 border-radius: 5px;
渐变 background:linear-gradient(red, green, blue);
阴影 box-shadow:3px 3px 3px rgba(0, 64, 128, 0.3);
倒影 box-reflect: below 2px;
文字装饰 text-stroke-color: red;
文字溢出 text-overflow:ellipsis;
背景效果 background-size: 100px 100px;
边框效果 border-image:url(bt_blue.png) 0 10;
转换
旋转 transform: rotate(20deg);
倾斜 transform: skew(150deg, -10deg);
位移 transform:translate(20px, 20px);
缩放 transform: scale(。5);
平滑过渡 transition: all .3s ease-in .1s;
动画 @keyframes anim-1 {50% {border-radius: 50%;}} animation: anim-1 1s;
63、解释下CSS sprites,以及你要如何在页面或者网站中使用它
CSS Sprites通常被称为css精灵图, 在国内也被意译为css图片整合和css贴图定位,也有人称他为雪碧图。 就是将导航的背景图,按钮的背景图等有规则的合并成一张背景图,即多张图合 并为一张整图, 然后再利用background-position进行背景图定位的一种技术
为什么需要css sprites
CSS Sprites 并不是一门新的技术了,目前他发展的已经比较成熟,阿里巴巴、百度、谷歌 等各公司的网页中到处都可以发现CSS Sprites 的影子。
他是网页里常见的一种图片应用处理方式,他允许你将一个页面里所涉及到的所=有的零星 的图片都整合到一张大图中去,这样一来,当访问这个页面时,所加载的图片就不会像以前那样 一张一张的慢慢显示出来了,对于当前的网络所流行的速度来说,不超出200kb的单张图片所需 要的加载时间基本是差不多的,节省加载速度的关键不是降低重量,而是减少个数,就因为计算 机都是按照byte计算。页面每显示一张图片都会向服务器发送一次请求。所以,图片越多,所请 求的次数就越多。
为了减少HTTP的请求次数,很多网站的导航背景图、登录框、按钮背景图等使用的并不是 标签,而是CSS Sprite
css sprites的优势
优势:通过整合图片,减少对服务器的请求数量,减少图片的体积从而减轻服务 器的负担,提高网页的加载速度
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LeAIrrm4-1649150971259)(https://pic1.zhimg.com/80/v2-1d586460993d7f4c694cfa41cef887c8_720w.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7Pl21k1y-1649150971259)(https://pic2.zhimg.com/80/v2-038ea5a7ef805691ee1b21d353b1a50d_720w.jpg)]
64、a点击出现框,解决方法
css中添加
-webkit-tap-highlight-color: transparent; outline: none;
.pageStr span a {
border: 1px solid #e4e4e4;
color: #999;
cursor: pointer;
display: inline-block;
height: 29px;
line-height: 29px;
padding: 0 10px;
text-align: center;
background:#fff;
-webkit-tap-highlight-color: transparent; outline: none;
}
65、如果我不输入,HTML 5能工作吗?
No,浏览器将无法识别HTML文件,并且HTML 5标签将无法正常工作。
66、哪些浏览器支持HTML 5?
几乎所有的浏览器都支持HTML 5,例如Safari,Chrome,火狐,Opera,IE等。
67、CSS3中的选择器都有什么?
*通用选择器,ID选择器 ,.类选择器class,标签选择器,标签组合选择器,伪类选择器:,+相邻元素选择器,>子元素选择器,~同辈选择器,
x[title]属性选择器[type=“button”],
x[href^=“http”]匹配以href值为http打头的地址,
x[href$=“.jpg”]匹配所有的图片链接
input[type=checkbox]:checked{};选择checkbox为当前选中的那个标签。
伪类选择器 ------:
p:empty 选择没有子元素的每个
元素(包括文本节点)。
:first-child 第一个
:last-child 最后一个
:nth-child(11) 1–11个
x:first/x:after 在x选择器之前或者之后插入内容
伪元素选择器
::before ,::after 通过 css 模拟出来html标签的效果
68、CSS3中多列布局的用处是什么?
好用 现在经常做自适应页面,就用的比较多了
69、CSS优先级算法如何计算?
元素选择符: 1
class选择符: 10
id选择符:100
元素标签:1000
- !important声明的样式优先级最高,如果冲突再进行计算。
- 如果优先级相同,则选择最后出现的样式。
- 继承得到的样式的优先级最低。
70、HTML5中的本地存储概念
html5中的Web Storage包括了两种存储方式:sessionStorage和localStorage。
sessionStorage用于本地存储一个会话中的数据,这些数据只有在同一个会话中的页面才能访问并且当会话结束后数据也随之销毁,因此sessionStorage
不是一种持久化的本地存储,仅仅是会话级别的存储。而localStorage用于持久化的本地存储,除非主动删除数据,否则数据是永远不会过期的。
cookie是网站为了标示用户身份而储存在用户本地终端上的数据(通常经过加密)。
71、本地存储有生命周期吗?
本地存储没有生命周期,它会一直存在直到用户将其从浏览器清楚或使用JavaScript代码删除它。
72、本地存储和Cookies之间的区别是什么?
cookies本地存储客户端/服务器端既可以从客户端也可以从服务器端访问数据。每个请求都会发送cookie数据到服务器。只能在本地浏览器端访问数据。服务器无法访问本地存储,除非特意通过POST或GET发送到服务器。大小每个Cookie 4095个字节。每个域5 MB。有效期cookie有附加的有效期。所以有效期后的cookie和cookie数据会被删除。数据没有有效期限。要么最终用户从浏览器删除它,要么使用JavaScript编程删除。
73、WebSQL是什么?WebSQL是HTML 5规范的一部分吗?
WebSQL是客户浏览器端的结构化的关系数据库。这是浏览器内部的本地RDBMS,你可以在这个本地RDBMS上执行SQL查询
74、XHTML与HTML的有何异同?
一、其基础语言不同
1、XHTML是基于可扩展标bai记语言(XML)。
2、HTML是基于标准通用标记语言(SGML)。
二、语法严格程度不同
1、XHTML语法比较严格,存在DTD定义规则。
2、HTML语法要求比较松散,这样对网页编写者来说,比较方便。
三、可混合应用不同
1、XHTML可以混合各种XML应用,比如MathML、SVG。
2、HTML不能混合其它XML应用。
四、大小写敏感度不同
1、XHTML对大小写敏感,标准的XHTML标签应该使用小写。
2、HTML对大小写不敏感。
五、公布时间不同
1、XHTML是2000年W3C公布发行的。
2、HTML4.01是1999年W3C推荐标准。
75、box-sizing属性?
用来控制元素的盒子模型的解析模式,默认为content-box
context-box:W3C的标准盒子模型,设置元素的 height/width 属性指的是content部分的高/宽
border-box:IE传统盒子模型。设置元素的height/width属性指的是border + padding + content部分的高/宽
76、Doctype的作用?标准模式与兼容模式各有什么区别?
①告知浏览器的解析器用什么文档标准解析这个文档。DOCTYPE不存在或格式不正确会导致文档以兼容模式呈现。
②标准模式的排版和JS运作模式都是以该浏览器支持的最高标准运行。在兼容模式中,页面以宽松的向后兼容的方式显示,模拟老式浏览器的行为以防止站点无法工作。
注意点:
HTML5 只需要写不需要对DTD进行引用,因为HTML5不基于 SGML,因此不需要对DTD进行引用,但是需要doctype来规范浏览器的行为(让浏览器按照它们应该的方式来运行)。
而HTML4.01基于SGML,所以需要对DTD进行引用,才能告知浏览器文档所使用的文档类型。
77、CSS3新增伪类有那些?
p:first-of-type 选择属于其父元素的首个元素
p:last-of-type 选择属于其父元素的最后元素
p:only-of-type 选择属于其父元素唯一的元素
p:only-child 选择属于其父元素的唯一子元素
p:nth-child(2) 选择属于其父元素的第二个子元素
:enabled :disabled 表单控件的禁用状态。
:checked 单选框或复选框被选中。
78、介绍一下你对浏览器内核的理解?常见的浏览器内核有哪些?
主要分成两部分:渲染引擎(layout engineer或 Rendering Engine) 和 JS 引擎。
渲染引擎:负责取得网页的内容(html,xml和图像等等),整理讯息(例如加入css),以及计算网页的显示方式,输出到显示器或打印机。浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不同。所有网页浏览器、电子邮件客户端以及它需要编辑、显示网络内容的应用程序都需要内核。
JS引擎:解析和执行JavaScript来实现网页的动态效果。以及交互内容
浏览器内核种类
一.Gecko内核
以Mozilla浏览器为代表,FirefoxGecko是一套开放源代码的、以C++编写的网页排版引擎。Gecko是最流行的排版引擎之一。使用它的比较著名的浏览器是Firefox、Netscape6至9.
二.Trident内核
Trident又被称为MSHTML,是微软开发的一种排版引擎。使用Trident渲染引擎的浏览器主要有:IE、世界之窗浏览器、傲游、Avant、Sleipnir、GreenBrowser、NetCaptor和KKman等。
三.WebKit内核
代表浏览器有Safari、Chromewebkit。是一个开源项目,包含了来自KDE项目和苹果公司的一些组件,主要用于Mac OS系统,特点在于源码结构清晰、渲染速度极快。缺点是对网页代码的兼容性不高,导致一些编写不标准的网页无法正常显示。主要作品有Safari以及Chrome。
四.Presto内核
是由Opera Sofeware开发的浏览器排版引擎,Opera7.0及以上可使用。它取代了旧版Opera4到6使用的Elektra排版引擎,包括加入动态功能,而重新排版。
79、前端页面有哪三层构成? 分别是什么? 作用是什么?
最准确的网页设计思路是把网页分成三个层次,即:结构层、bai样式层、行为层。
HTML:结构层
网页的结构或内容层是该页面的基础HTML代码。正如房屋的框架为房屋的其他部分构建了一个坚实
的基础,HTML的坚实基础创建了一个可以在其上创建网站的平台。
结构层用于存储客户想要阅读或查看的所有内容。HTML结构可以包含文本和图像,它包括访问者用
于浏览网站的超链接。这是在符合标准的HTML5中编码的,可以包括文本,图像和多媒体(视频,音频等)。
网站内容的每个方面都应该在结构层中表示。这允许关闭JavaScript的客户或无法查看整个网站的
CSS访问权限的客户(如果不是所有功能)。
CSS:样式层
该层指示结构化HTML文档如何看待网站的访问者,并由CSS(层叠样式表)定义。这些文件包含有
关如何在Web浏览器中显示文档的样式说明。样式层通常包括基于屏幕大小和设备更改站点显示的
媒体查询。
网站的所有视觉样式都应位于外部样式表中。您可以使用多个样式表,但请记住,每个CSS文件都需
要HTTP请求才能获取它,从而影响站点性能。
JavaScript:行为层
行为层使网站具有交互性,允许页面响应用户操作或基于一组条件进行更改。JavaScript是行为层最
常用的语言,但CGI和PHP也经常被使用。
当开发人员引用行为层时,大多数都是指在Web浏览器中直接激活的层。您可以使用此图层直接与
DOM(文档对象模型)进行交互。在内容层中编写有效的HTML对于行为层中的DOM交互非常重
要。在构建行为层时,应该像使用CSS一样使用外部脚本文件来优化速度和性能。
80、CSS里的visibility属性有个collapse属性值?在不同浏览器下以后什么区别?
当一个元素的visibility属性被设置成collapse值后,对于一般的元素,它的表现跟hidden是一样的。
- chrome中,使用collapse值和使用hidden没有区别。
- firefox,opera和IE,使用collapse值和使用display:none没有什么区别。
81、HTML中div与span区别
div和span
1、div和span都可以称为“图层“。
2、图层的作用是为了保证页面可以灵活的布局。相当于“盒子”。
3、div和span是可以定位的,只要确定div的左上角的x轴和y轴坐标即可。
4、最早的网页是采用table进行布局(不灵活,太死板),现代的网页开发中div布局使用最多。
5、div和span的区别?
div独自占用一行(默认情况下,浏览器通常会在其后放置一个换行符);span不会独自占用一行。
div
1、标签定义HTML文档中的一个分隔区块或者一个区域部分。
2、标签常用于组合块级元素,以便通过CSS来对这些元素进行格式化。
3、可以对同一个标签同时应用class或id属性,但通常情况下我们偏向于只使用其中一种。
4、为了避免麻烦,可以不必为每一个标签都加上class或id属性。
span
1、
2、
3、
4、可以对同一个
5、被
82、iframe的优缺点?
iframe的优点:
1.iframe能够原封不动的把嵌入的网页展现出来。
2.如果有多个网页引用iframe,那么你只需要修改iframe的内容,就可以实现调用的每一个页面内容的更改,方便快捷。
3.网页如果为了统一风格,头部和版本都是一样的,就可以写成一个页面,用iframe来嵌套,可以增加代码的可重用。
4.如果遇到加载缓慢的第三方内容如图标和广告,这些问题可以由iframe来解决。
iframe的缺点:
1.会产生很多页面,不容易管理。
2.iframe框架结构有时会让人感到迷惑,如果框架个数多的话,可能会出现上下、左右滚动条,会分散访问者的注意力,用户体验度差。
3.代码复杂,无法被一些搜索引擎索引到,这一点很关键,现在的搜索引擎爬虫还不能很好的处理iframe中的内容,所以使用iframe会不利于搜索引擎优化。
4.很多的移动设备(PDA 手机)无法完全显示框架,设备兼容性差。
5.iframe框架页面会增加服务器的http请求,对于大型网站是不可取的。
分析了这么多,现在基本上都是用Ajax来代替iframe,所以iframe已经渐渐的退出了前端开发
83、请描述一下cookies,sessionStorage 和 localStorage的区别?
⒈localStorage长期存储数据,浏览器关闭数据后不丢失;
⒉sessionStorage数据在浏览器关闭后自动删除;
⒊cookie是网站为了标识用户身份而存储在用户本地终端(Client Side)上的数据(通常经过加密)。cookie始终在同源的http请求中携带(即使不需要)都会在浏览器和服务器端间来回传递。session storage和local storage不会自动把数据发给服务器,仅在本地保存;
⒋存储大小:cookie数据大小不会超过4K,session storage和local storage虽然也有存储大小的限制,但比cookie大得多,可以达到5M或者更多;
⒌有期时间:local storage存储持久数据,浏览器关闭后数据不丢失,除非自动删除数据。session storage数据在当前浏览器窗口关闭后自动删除。cookie 设置的cookie过期时间之前一直有效,即使窗口或者浏览器关闭;
84、重排(reflow)与重绘(repaint)
- 解析HTML文档,构建DOM树
- 解析CSS属性,构建CSSOM树
- 结合DOM树和CSSOM树,构建render树
- 在render树的基础上进行布局, 计算每个节点的几何结构
- 把每个节点绘制在屏幕上
一个页面可以简单看成由两个部分组成:
- DOM节点:描述页面的结构
- DOM节点的属性:描述DOM节点如何呈现
我们可以发现Reflow发生在第4步,而Repaint发生在第5步。
Reflow (重排)
当涉及到DOM节点的布局属性发生变化时,就会重新计算该属性,浏览器会重新描绘相应的元素,此过程叫 回流(Reflow)。
Repaint(重绘)
当影响DOM元素可见性的属性发生变化 (如 color) 时, 浏览器会重新描绘相应的元素, 此过程称为 重绘(Repaint)。因此重排必然会引起重绘。
二、引起Repaint和Reflow的一些操作
浏览器在处理重排时,会递归处理DOM节点,所以导致重排的成本高于重绘。
如果你是Web开发者,可能更关注的是哪些具体原因会引起浏览器的重排,下面罗列一下:
- 调整窗口大小
- 字体大小
- 样式表变动
- 元素内容变化,尤其是输入控件
- CSS伪类激活,在用户交互过程中发生
- DOM操作,DOM元素增删、修改
- width, clientWidth, scrollTop等布局宽高的计算
这些引起回流的操作中,6和7是和JavaScript相关的,所以前端开发人员应该注意2点:
- 避免大量的DOM操作
- 避免过多DOM布局属性的计算
85、display:none与visibility:hidden的区别?
display:none 不显示对应的元素,在文档布局中不再分配空间(回流+重绘)
visibility:hidden 隐藏对应元素,在文档布局中仍保留原来的空间(重绘)
86、BFC 是什么东西
一、什么是BFC
首先引用一下WC3对BFC的专业解释
BFC(Block Formatting Context):翻译成中文叫做块级格式化上下文,它决定了元素如何对其内容进行定位,以及与其它元素的关系和相互作用,当涉及到可视化布局时,其提供了一个环境,元素在这个环境中按照一定的规则进行布局排列
换句话说,BFC就是为元素提供一个独立的容器,在该容器里按照一定的规则进行布局排列,该容器内的元素不会影响外部的元素,同理,外部的元素也不会影响内部的元素
二、如何触发BFC
先来了解一下有哪些条件可以触发BFC:
float 不为 noneposition 为 absolute 或 fixedoverflow 不为 visibledisplay 为 inline-block 或 table 或 flow-root
后续的案例中,但凡遇到需要触发BFC的,都可以按照这四个条件来使用
87、flex布局有哪些属性
flex是Flexible Box的缩写,意思为“弹性布局”,在使用过程中简单、易用、代码较少,在制作网页的时候经常使用这种方法来进行布局。
在使用的过程中任何一个容器都可以指定为Flex布局.{display:flex},行内元素也可以使用Flex布局.box{display:inline-flex;}。当我们将容器设置为Flex布局以后,容器当中的子元素的float、clear等属性会失效。采用Flex布局的元素,称为Flex容器,他的所有子元素自动成为容器成员,称为Flex项目。
容器可以有如下几个属性:justify-content、align-content、align-items flex-direction、flex-wrap、flex-flow。
flex-direction属性决定主轴的的方向,即容器中项目排列的方向,一般默认的方向是横排列。flex-direction有四个值,分别为row:主轴水平方向,起点在左端,row-reverse:起点在右端,column:主轴为垂直方向,起点在上沿,column-reverse:起点在下沿。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LDAA44K3-1649150971260)(https://pic3.zhimg.com/80/v2-45b2435bcae1cf880c9a36d6c925dfce_720w.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jgUKjTQF-1649150971260)(https://pic2.zhimg.com/80/v2-4a8c16a7f511c07dbc7202159497d9e5_720w.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RDVCL2GU-1649150971260)(https://pic1.zhimg.com/80/v2-a2955cd3fef7a588a45f08772deff5d8_720w.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kClE6N1j-1649150971260)(https://pic2.zhimg.com/80/v2-0a556a75bb4ccde99cc253b7df613385_720w.jpg)]
flex-wrap属性,项目的默认值(nowrap)都在一条线上,wrap换行,第一行在上方,wrap-reverse换行,第一行在下方。
flex-flow是属性flex-direction属性和flex-wrap的简写。默认值(row nowrap)为横向排列不换行。.box{flex-flow:flex-direction flex-wrap}。
.box{justify-content:flex-start|flex-end|center|space-between|sp-ace-around},这几个值的意思分别为左对齐,右对齐,居中,两端对齐,两端对齐但是项目边上的元素和容器之间有空隙。他的默认值为左对齐。
align-items属性有五个值,flex-start:交叉轴的起点对齐,flex-end:终点对齐,center:中点对齐,baseline:项目的第一行文字基线对齐,stretch:当项目未设置高度的时候,占满这个容器的高度。
align-content属性定义了多根轴线的对齐方式。当项目只有一根轴线的时候,该属性是不起作用的。flex-start:交叉轴的起点对齐,flex-end:终点对齐,center:中点对齐,space-between:与交叉轴的两端对齐,轴线之间的间隔平均分布,space-around:每根轴线两侧的间隔都相等,因此,轴线之间的间隔比轴线与边框的间隔大一倍,strentch:轴线占满整个交叉轴。
88、对BFC规范(块级格式化上下文:block formatting context)的理解?
BFC规定了内部的Block Box如何布局。
定位方案:
- 内部的Box会在垂直方向上一个接一个放置。
- Box垂直方向的距离由margin决定,属于同一个BFC的两个相邻Box的margin会发生重叠。
- 每个元素的margin box 的左边,与包含块border box的左边相接触。
- BFC的区域不会与float box重叠。
- BFC是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素。
- 计算BFC的高度时,浮动元素也会参与计算。
满足下列条件之一就可触发BFC
- 根元素,即html
- float的值不为none(默认)
- overflow的值不为visible(默认)
- display的值为inline-block、table-cell、table-caption
- position的值为absolute或fixed
89、CSS优化、提高性能的方法有哪些(简短回答)?
- 避免过度约束
- 避免后代选择符
- 避免链式选择符
- 使用紧凑的语法
- 避免不必要的命名空间
- 避免不必要的重复
- 最好使用表示语义的名字。一个好的类名应该是描述他是什么而不是像什么
- 避免!important,可以选择其他选择器
- 尽可能的精简规则,你可以合并不同类里的重复规则
90、浏览器是怎样解析CSS选择器的?
CSS选择器的解析是从右向左解析的。若从左向右的匹配,发现不符合规则,需要进行回溯,会损失很多性能。若从右向左匹配,先找到所有的最右节点,对于每一个节点,向上寻找其父节点直到找到根元素或满足条件的匹配规则,则结束这个分支的遍历。两种匹配规则的性能差别很大,是因为从右向左的匹配在第一步就筛选掉了大量的不符合条件的最右节点(叶子节点),而从左向右的匹配规则的性能都浪费在了失败的查找上面。
而在 CSS 解析完毕后,需要将解析的结果与 DOM Tree 的内容一起进行分析建立一棵 Render Tree,最终用来进行绘图。在建立 Render Tree 时(WebKit 中的「Attachment」过程),浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果(Style Rules)来确定生成怎样的 Render Tree。
91、单行或者多行文本溢出展示省略号的实现方法
如果实现单行文本的溢出显示省略号同学们应该都知道用text-overflow:ellipsis属性来,当然还需要加宽度width属来兼容部分浏览。
实现方法:
overflow: hidden;
text-overflow:ellipsis;
white-space: nowrap;
效果如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qpsp1Yy9-1649150971261)(http://www.daqianduan.com/wp-content/uploads/2015/10/dome1.png)]
但是这个属性只支持单行文本的溢出显示省略号,如果我们要实现多行文本溢出显示省略号呢。
接下来重点说一说多行文本溢出显示省略号,如下。
实现方法:
display: -webkit-box;
-webkit-box-orient: vertical;
-webkit-line-clamp: 3;
overflow: hidden;
效果如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QBKjB3IV-1649150971261)(http://www.daqianduan.com/wp-content/uploads/2015/10/dome2.png)]
适用范围:
因使用了WebKit的CSS扩展属性,该方法适用于WebKit浏览器及移动端;
注:
- -webkit-line-clamp用来限制在一个块元素显示的文本的行数。 为了实现该效果,它需要组合其他的WebKit属性。常见结合属性:
- display: -webkit-box; 必须结合的属性 ,将对象作为弹性伸缩盒子模型显示 。
- -webkit-box-orient 必须结合的属性 ,设置或检索伸缩盒对象的子元素的排列方式 。
实现方法:
p{position: relative; line-height: 20px; max-height: 40px;overflow: hidden;}
p::after{content: "..."; position: absolute; bottom: 0; right: 0; padding-left: 40px;
background: -webkit-linear-gradient(left, transparent, #fff 55%);
background: -o-linear-gradient(right, transparent, #fff 55%);
background: -moz-linear-gradient(right, transparent, #fff 55%);
background: linear-gradient(to right, transparent, #fff 55%);
}
效果如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w11Q3IQn-1649150971261)(http://www.daqianduan.com/wp-content/uploads/2015/10/dome3.png)]
适用范围:
该方法适用范围广,但文字未超出行的情况下也会出现省略号,可结合js优化该方法。
注:
- 将height设置为line-height的整数倍,防止超出的文字露出。
- 给p::after添加渐变背景可避免文字只显示一半。
- 由于ie6-7不显示content内容,所以要添加标签兼容ie6-7(如:…);兼容ie8需要将::after替换成:after。
92、display:none 和visbility:hidden的区别是什么啊
使用css让元素不可见的方法有很多种,裁剪、定位到屏幕外边、透明度变换等都是可以的。但是最常用两种方式就是设置元素样式为display: none或者visibility: hidden。很多公司的面试官也常常会问面试者这两者之间的区别。
display与元素的隐藏
如果给一个元素设置了display: none,那么该元素以及它的所有后代元素都会隐藏,它是前端开发人员使用频率最高的一种隐藏方式。隐藏后的元素无法点击,无法使用屏幕阅读器等辅助设备访问,占据的空间消失。
<body>
<div>
<strong>给元素设置display:none样式strong>
<p>A元素p>
<p style='display:none;'>B元素p>
<p>C元素p>
div>
body>
效果图:

visibility与元素的隐藏
给元素设置visibility: hidden也可以隐藏这个元素,但是隐藏元素仍需占用与未隐藏时一样的空间,也就是说虽然元素不可见了,但是仍然会影响页面布局。
<body>
<div>
<strong>给元素设置visibility:hidden样式strong>
<p>A元素p>
<p style='visibility:hidden;'>B元素p>
<p>C元素p>
div>
body>
效果图:

display: none与visibility: hidden的区别
很多前端的同学认为visibility: hidden和display: none的区别仅仅在于display: none隐藏后的元素不占据任何空间,而visibility: hidden隐藏后的元素空间依旧保留 ,实际上没那么简单,visibility是一个非常有故事性的属性
1、visibility具有继承性,给父元素设置visibility:hidden;子元素也会继承这个属性。但是如果重新给子元素设置visibility: visible,则子元素又会显示出来。这个和display: none有着质的区别
2、visibility: hidden不会影响计数器的计数,如图所示,visibility: hidden虽然让一个元素不见了,但是其计数器仍在运行。这和display: none完全不一样
<body>
<div>
<strong>给元素设置visibility:hidden样式strong>
<ol>
<li>元素1li>
<li style="visibility:hidden;">元素2li>
<li>元素3li>
<li>元素4li>
ol>
div>
<div>
<strong>给元素设置display:none样式strong>
<ol>
<li>元素1li>
<li style="display:none;">元素2li>
<li>元素3li>
<li>元素4li>
ol>
div>
body>

3、CSS3的transition支持visibility属性,但是并不支持display,由于transition可以延迟执行,因此可以配合visibility使用纯css实现hover延时显示效果。提高用户体验。
第二部分:JavaScript
1、介绍一下JS的内置类型有哪些?
基本数据类型:Undefined Null Boolean Number String
内置对象:Object是Javascript中所有对象的父对象
数据封装对象:Object Array Boolean Number String
其他对象:Function Argument Math Date RegExp Error
2、介绍一下 typeof 区分类型的原理
instanceof的实现代码:
// L instanceof R
function instance_of(L, R) {//L 表示左表达式,R 表示右表达式
var O = R.prototype;// 取 R 的显式原型
L = L.__proto__; // 取 L 的隐式原型
while (true) {
if (L === null) //已经找到顶层
return false;
if (O === L) //当 O 严格等于 L 时,返回 true
return true;
L = L.__proto__; //继续向上一层原型链查找
}
}
首先typeof 能够判断基本数据类型,但是除了null,typeof null 返回的是object
但是对于对象来说typeof不能准确判断类型,typeof 函数会返回function,除此之外全部都是object,不能准确判断类型
instanceof可以判断复杂数据类型,基本数据类型不可以
instanceof是通过原型链来判断的 ,A instanceof B,在A的原型链中层层查找,是否有原型等于B.prototype,如果一直找到A的原型链的顶端(null,即Object.prototype.proto),仍然不等于B,那么返回false,否则返回true
3、JavaScript 中的强制转型是指什么?
在 JavaScript 中,两种不同的内置类型间的转换被称为强制转型。强制转型在 JavaScript 中有两种形式:显式和隐式。
这是一个显式强制转型的例子:
var a = "42";
var b = Number( a );
a; // "42"
b; // 42 -- 是个数字!
这是一个隐式强制转型的例子:
var a = "42";
var b = a * 1; // "42" 隐式转型成 42
a; // "42"
b; // 42 -- 是个数字!
4、说说你对javascript的作用域的理解
前言
学习 JavaScript 也有一段时间,今天抽空总结一下作用域,也方便自己以后翻阅。
什么是作用域
如果让我用一句简短的话来讲述什么是作用域,我的回答是:
其实作用域的本质是一套规则,它定义了变量的可访问范围,控制变量的可见性和生命周期。
既然作用域是一套规则,那么究竟如何设置这些规则呢?
先不急,在这之前,我们先来理解几个概念。
编译到执行的过程
下面我们就拿这段代码来讲述 JavaScript 编译到执行的过程。
var a = 2;
首先我们来看一下在这个过程中,几个功臣所需要做的事。
- 引擎(总指挥):
从头到尾负责整个 JavaScript 程序的编译及执行过程。
- 编译器(劳工):
- 词法分析(分词)
解析成词法单元,var、a、=、2。
- 语法分析(解析)
将单词单元转换成抽象语法树(AST)。
- 代码生成
将抽象语法树转换成机器指令。
- 作用域(仓库管理员):
负责收集并维护所有生命的标识符(变量)组成的一系列查询,并实施一套非常严格的规则,确定当前执行的代码对这些标识符的访问权限。
然后我们再来看,执行这段代码时,每个功臣是怎么协同工作的。
引擎:
其实这段代码有两个完全不同的声明,var a和a = 2,一个由编译器在编译时处理,另一个则由引擎在运行时处理。
编译器:
- 一套编译器常规操作下来,到代码生成步骤。
- 遇到
var a,会先询问作用域中是否已经存在同名变量,如果是,则忽略该声明,继续进行编译;否则它会要求作用域声明一个新的变量a。
- 为引擎生成运行
a = 2时所需的代码。
引擎:
会先询问作用域是否存在变量a,如果是,就会使用这个变量进行赋值操作;否则一直往外层嵌套作用域找(详见作用域嵌套),直至到全局作用域都没有时,抛出一个异常。
**总结:**变量的赋值操作会执行两个动作, 首先编译器会在当前作用域中声明一个变量( 如果之前没有声明过),然后在运行时引擎会在作用域中查找该变量, 如果能够找到就会对它赋值。
LHS & RHS 查询
从上面可知,引擎在获得编译器给出的代码后,还会对作用域进行询问变量。
聪明的你肯定一眼就看出,L和R的含义,它们分别代表左侧和右侧。
现在我们把代码改成这样:
var a = b;
这时引擎对a进行 LHS 查询,对b进行 RHS 查询,但是L和R并不一定指操作符的左右边,而应该这样理解:
LHS 是为了找到赋值的目标。 RHS 是赋值操作的源头。也就是 LHS 是为了找到变量这个容器本身,给它赋值,而 RHS 是为了取出这个变量的值。
作用域嵌套
当一个块或函数嵌套在另一个块或函数中时,就发生了作用域的嵌套,进而形成了一条作用域链。因此,在当前作用域中无法找到某个变量时,引擎就会在外层嵌套的作用域中继续查找,直到找到该变量, 或抵达最外层的作用域(也就是全局作用域)为止。
词法作用域
作用域分为两种:
- 词法作用域(较为普遍,JavaScript所使用的也是这种)
- 动态作用域(使用较少,比如 Bash 脚本、Perl 中的一些模式等)
词法作用域是由你在写代码时将变量和块作用域写在哪里来决定的。
看以下代码,这个例子中有三个逐级嵌套的作用域。
var a = 2; // 作用域1 全局
function foo(){
var b = a * 2; // 作用域2 局部
function bar(){
var c = a * b; // 作用域3 局部
}
}
- 作用域是由你书写代码所在位置决定的。
- 子级作用域可以访问父级作用域,而父级作用域则不能访问子级作用域。
引擎对作用域的查找
作用域查找会在找到第一个匹配的标识符时停止,在多层的嵌套作用域中可以定义同名的标识符,这叫做“遮蔽效应”(内部的标识符“遮蔽”了外部的标识符)。也就是说查找时会从运行所在的作用域开始,逐级往上查找,直到遇见第一个标识符为止。
全局变量(全局作用域下定义的变量)会自动变成全局对象(比如浏览器中的 window对象)。
var a = 1;
function foo(){
var a = 2;
console.log(a); // 2
function bar(){
var a = 3;
console.log(a); // 3
console.log(window.a); // 1
}
}
非全局的变量如果被遮蔽了,就无论如何都无法被访问到,所以在上述代码中,bar内的作用域无法访问到foo下定义的变量a。
词法作用域查找只会查找一级标识符,比如a、b,如果是foo.bar,词法作用域查找只会试图查找foo标识符,找到这个变量后,由对象属性访问规则接管属性的访问。
欺骗语法
虽然词法作用域是在代码编写时确定的,但还是有方法可以在引擎运行时动态修改词法作用域,有两种机制:
evalwith
eval
JavaScript 的 eval函数可以接受一个字符串参数并作为代码语句来执行, 就好像代码是原本就在那个位置一样,考虑以下代码:
function foo(str){
eval(str) // 欺骗
console.log(a);
}
var a = 1;
foo("var a = 2;"); // 2
仿佛eval中传入的参数语句原本就在那一样,会创建一个变量a,并遮蔽了外部作用域的同名变量。
注意:
eval通常被用来执行动态创建的代码,可以根据程序逻辑动态地将变量和函数以字符串形式拼接在一起之后传递进去。- 在严格模式下,
eval无法修改所在的作用域。
- 与
eval相似的还有,setTimeout、setInterval、new Function。
with
with通常被当作重复引用同一个对象中的多个属性的快捷方式, 可以不需要重复引用对象本身。
使用方法如下:
var obj1 = { a:1,b:2 };
function foo(obj){
with(obj){
a = 2;
b = 3;
}
}
foo(obj1);
console.log(obj1); // {a: 2, b: 3}
然而考虑以下代码:
var obj2 = { a:1,b:2 };
function foo(obj){
with(obj){
a = 2;
b = 3;
c = 4;
}
}
foo(obj2);
console.log(obj2); // {a: 2, b: 3}
console.log(c); // 4 不好,c被泄露到全局作用域下
尽管with可以将对象处理为词法作用域,但是这样块内部正常的var操作并不会限制在这个块的作用域下,而是被添加到with所在的函数作用域下,而不通过var声明变量将视为声明全局变量。
性能
eval和with会在运行时修改或创建新的作用域,以此来欺骗其他书写时定义的词法作用域,然而 JavaScript 引擎会在编译阶段进行性能优化,有些优化依赖于能够根据代码的词法进行静态分析,并预先确定所有的变量和函数的定义位置,才能在执行过程中快速找到标识符。但是通过eval和with来欺骗词法作用域会导致引擎无法知道他们对词法作用域做了什么样的改动,只能对部分不进行优化,因此如果在代码中大量使用eval或with就会导致代码运行起来变得非常慢。
函数作用域和块作用域
函数作用域
在 JavaScript 中每声明一个函数就会创建一个函数作用域,同时属于这个函数的所有变量在整个函数的范围内都可以使用。
块作用域
从 ES3 发布以来,JavaScript 就有了块作用域,创建块作用域的几种方式有:
with
上面已经讲了,这里不再复述。
try/catch
try/catch 的 catch 分句会创建一个块作用域,其中声明的变量仅在 catch 内部有效。
javascript try{ throw 2; }catch(a){ console.log(a); }
let和const
ES6 引入的新关键词,提供了除 var 以外的变量声明方式,它们可以将变量绑定到所在的任意作用域中(通常是{}内部)。
javascript { let a = 2; } console.log(a); // ReferenceError: a is not defined
注意:使用 let和const 进行的声明不会在块作用域中进行提升。
提升
考虑这段代码:
console.log( a );
var a = 2;
输入结果是undefined,而不是ReferenceError。
为什么呢?
前面说过,编译阶段时,会把声明分成两个动作,也就是只把var a部分进行提升。
所以第二段代码真正的执行顺序是:
var a; // 这时 a 是 undefined
console.log(a);
a = 2;
- 编译阶段时会把所有的声明操作提升,而赋值操作原地执行。
- 函数声明会把整个函数提升,而不仅仅是函数名。
函数优先
虽然函数和变量都会被提升,但函数声明的优先级高于变量声明,所以:
foo(); // 1
var foo;
function foo(){
console.log(1);
}
foo = function(){
console.log(2);
}
因为这个代码片段会被引擎理解为如下形式:
function foo(){
console.log(1);
}
foo(); // 1
foo = function() {
console.log( 2 );
};
这个值得一提的是,尽管var foo出现在function foo()...之前,但由于函数声明会被优先提升,所以它会被忽略(因为重复声明了)。 注意:
JavaScript 会忽略前面已经声明过的声明,不管它是变量还是函数,只要其名称相同。
后记
5、什么是作用域链
在了解作用域链之前,先来了解下什么是作用域
作用域(scope),通常来说,一段程序代码中所用到的名字并不总是有效/可用的,而限定这个名字的可用性的代码范围就是这个名字的作用域。
js是没有块级作用域的,也就是说外面可以使用{}里面的变量,包括do while/for中的{}。
例如
for ( var i=0; i<10; i++ ) {
var a=3
}
console.log(a)//3
但函数内定义的变量函数外是不可以使用的,例如console.log(a),不能使用fn()里的var a=1,没有声明变量,就会报错。
function fn() {
var a=1;
}
console.log(a);//"ReferenceError:a is not defined"
但函数里面的却可以使用外面的变量,这就是引申出出了作用域链。
作用域链:
- 函数在执行的过程中,先从自己内部找变量,
- 如果找不到,再从创建当前函数所在的作用域去找, 以此往上,
- 注意找的是变量的当前的状态。
例如
var a = 1
function fn1(){
function fn2(){
console.log(a)
}
function fn3(){
var a = 4
fn2()
}
var a = 2
return fn3
}
var fn = fn1()
fn() //输出2
解析:var fn = fn1(),执行函数fn1(),因为return fn3,再执行函数fn3(),再执行函数fn2(),再执行console.log(a),那么a是多少呢?fn2里没有变量a,去fn2的上一级(声明fn2的地方)fn1里去找,找到了 var a=2, 那么console.log(2),输出了2。
6、解释下 let 和 const 的块级作用域
在ES6之前,我们都是用 var 关键字声明变量。无论声明在何处,都会被视为声明在函数的最顶部(不在函数内即在全局作用域的最顶部)。这就是函数变量提升 例如:
function aa() {
if(flag) {
var test = 'hello man'
} else {
console.log(test)
}
}
12345678
变量声明后代码实际上是:
function aa() {
var test // 变量提升,函数最顶部
if(flag) {
test = 'hello man'
} else {
//此处访问 test 值为 undefined
console.log(test)
}
//此处访问 test 值为 undefined
}
12345678910
所以不用关心 flag 是否为 true or false。实际上,无论如何 test 都会被创建声明。
接下来ES6主角登场:
我们通常用 let 和 const 来声明,let 表示变量、const 表示常量。let 和 const 都是块级作用域。怎么理解这个块级作用域?
在一个函数内部
在一个代码块内部
只要在 {}花括号内 的代码块即可以认为 let 和 const 的作用域。
function aa() {
if(flag) {
let test = 'hello man'
} else {
//test 在此处访问不到
console.log(test)
}
}
12345678
et 的作用域是在它所在当前代码块,但不会被提升到当前函数的最顶部。
再来说说 const
const 声明的变量必须提供一个值,而且会被认为是常量,意思就是它的值被设置完成后就不能再修改了。
const name = 'cc'
name = 'yy' // 再次赋值此时会报错
12
还有,如果 const 的是一个对象,对象所包含的值是可以被修改的。抽象一点儿说,就是对象所指向的地址不能改变,而变量成员是可以修改的。
看以下例子就非常清楚:
const student = { name: 'cc' }
student.name = 'yy' // 修改变量成员,一点儿毛病没有
student = { name: 'yy' } // 修改变量绑定,这样子就会报错了
12345
let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
总之,在代码块内,使用let命令声明变量之前,该变量都是不可用的。这在语法上,称为“暂时性死区”(temporal dead zone,简称TDZ)。
if (true) {
// TDZ开始
tmp = 'abc'; // ReferenceError
console.log(tmp); // ReferenceError
let tmp; // TDZ结束
console.log(tmp); // undefined
tmp = 123;
console.log(tmp); // 123
typeof x; // ReferenceError
let x;
typeof undeclared_variable // "undefined"
1234567891011121314151617
上面代码中,在let命令声明变量tmp,x之前,都属于变量tmp,x的“死区”。只要用到该变量就会报错.
undeclared_variable是一个不存在的变量名,结果返回“undefined”。
function bar(x = y, y = 2) {
return [x, y];
}
bar(); // 报错
123456
上面代码中,调用bar函数之所以报错(某些实现可能不报错),是因为参数x默认值等于另一个参数y,而此时y还没有声明,属于”死区“。如果y的默认值是x,就不会报错,因为此时x已经声明了。
function bar(x = 2, y = x) {
return [x, y];
}
bar(); // [2, 2]
7、什么是JavaScript?(这是基本题,对很多程序员来说也是送分题!)
JavaScript是客户端和服务器端脚本语言,可以插入到HTML页面中,并且是目前较热门的Web开发语言。同时,JavaScript也是面向对象编程语言。
8、对闭包的看法,为什么要用闭包?说一下闭包的原理以及应用场景
一、什么是闭包
闭包就是能够读取其他函数内部变量的函数。例如在javascript中,只有函数内部的子函数才能读取局部变量,所以闭包可以理解成“定义在一个函数内部的函数“。在本质上,闭包是将函数内部和函数外部连接起来的桥梁。
函数执行后返回结果是一个内部函数,并被外部变量所引用,如果内部函数持有被执行函数作用域的变量,即形成了闭包。
可以在内部函数访问到外部函数作用域。使用闭包,一可以读取函数作用域中的变量,二可以将函数中的变量存储到内存中,保护变量不被污染。而正因闭包会把函数中的变量值存储到内存中,会对内存有消耗,所以不能滥用闭包,否则会影响网页性能,造成内存泄露。当不需要使用闭包时,要及时释放内存,可将内存函数对象的的变量赋值为 null。
二、闭包原理
函数执行分为两个阶段(预编译阶段和执行阶段)。
- 在预编译阶段,如果发现内部函数使用了外部函数的变量,则会在内存中创建一个“闭包”对象并保持对应变量值,如果已存在“闭包”,则只需要增加对应的属性值即可。
- 执行完后,函数执行上下文会被销毁,函数对“闭包”对象的引用也会销毁,但其内部函数还持有对该“闭包”的引用,所以内部函数还可以继续使用“外部函数”中的变量。
利用函数作用域链的特性,一个函数内部定义的函数会将包含外部函数的活动对象添加到他的作用域链中,函数执行完毕,其执行作用域链被销毁,但其因内部函数的作用域链仍然在引用这个活动对象,所以其活动对象不会被销毁,直到内部函数被销毁后才销毁。
三、优点
1.可以从内部函数访问外部函数的作用域中的变量,且访问到的变量长期驻扎在内存中,可供之后使用
2.避免变量污染全局变量
3.把变量存到独立的作用域中,作为私有成员存在
四、缺点
1.对内存消耗有负面影响。因内部函数保存了对外部函数变量的引用,导致无法被垃圾回收,增大内存使用量,所以使用不当会造成内存泄露
2.对处理速度有负面影响。闭包的层级决定了引用的外部变量在查找时经过的作用域链长度
3.可能获取到意外的值
五、应用场景
场景一:典型的应用是模块封装,在各模块规范出来之前,都是用这样的方式阻止变量污染全局。
var fn = (function(){
//这样声明为模块的私有变量,外界无法直接访问
var foo = 1;
function fn(){};
fn.prototype.bar = function(){
return foo;
}
return fn;
}());
场景二:在循环中创建闭包,防止取到意外的值。如下,无论哪个元素触发事件,都会弹出3。因为函数执行后引用 i 是同一个,而 i 在循环结束后就是 3
for(var i=0;i<3;i++){
document.getElementById('id'+i).onclick = function(){
alert(i);
};
}
//可用闭包解决
function makeCallbak(num){
return function(){
alert(num);
};
}
for(var i=0;i<3;i++){
document.getElementById('id'+i).onclick = makeCallbal(i);
}
9、列举Java和JavaScript之间的区别?
Java是一门十分完整、成熟的编程语言。相比之下,JavaScript是一个可以被引入HTML页面的编程语言。这两种语言并不完全相互依赖,而是针对不同的意图而设计的。 Java是一种面向对象编程(OOPS)或结构化编程语言,类似的如C ++或C,而JavaScript是客户端脚本语言,它被称为非结构化编程。
10、如何确定this指向
如果用一句话说明 this 的指向,那么即是: 谁调用它,this 就指向谁。
但是仅通过这句话,我们很多时候并不能准确判断 this 的指向。因此我们需要借助一些规则去帮助自己:
this 的指向可以按照以下顺序判断:
全局环境中的 this
浏览器环境:无论是否在严格模式下,在全局执行环境中(在任何函数体外部)this 都指向全局对象 window;
node 环境:无论是否在严格模式下,在全局执行环境中(在任何函数体外部),this 都是空对象 {};
是否是 new 绑定
如果是 new 绑定,并且构造函数中没有返回 function 或者是 object,那么 this 指向这个新对象。如下:
构造函数返回值不是 function 或 object。new Super() 返回的是 this 对象。

构造函数返回值是 function 或 object,new Super()是返回的是Super种返回的对象。

函数是否通过 call,apply 调用,或者使用了 bind 绑定,如果是,那么this绑定的就是指定的对象【归结为显式绑定】。
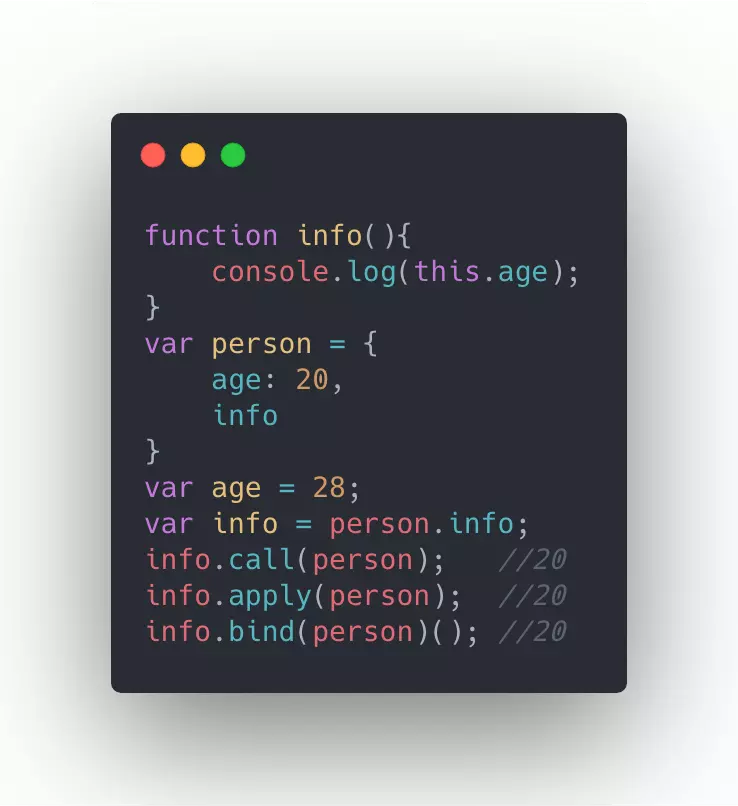
这里同样需要注意一种特殊情况,如果 call,apply 或者 bind 传入的第一个参数值是 undefined 或者 null,严格模式下 this 的值为传入的值 null /undefined。非严格模式下,实际应用的默认绑定规则,this 指向全局对象(node环境为global,浏览器环境为window)
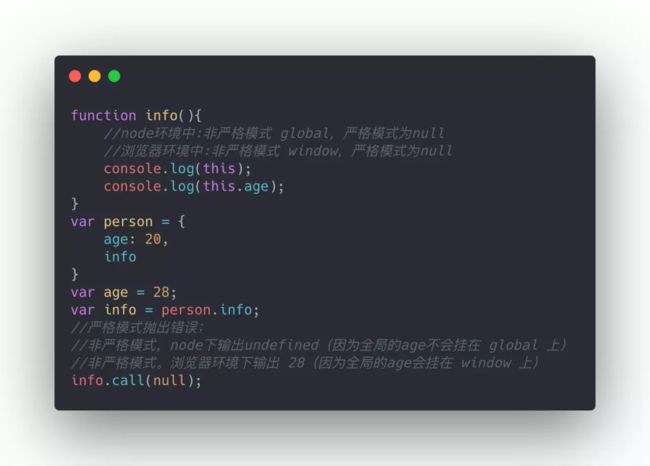
隐式绑定,函数的调用是在某个对象上触发的,即调用位置上存在上下文对象。典型的隐式调用为: xxx.fn()

默认绑定,在不能应用其它绑定规则时使用的默认规则,通常是独立函数调用。
非严格模式: node环境,执行全局对象 global,浏览器环境,执行全局对象 window。
严格模式:执行 undefined

箭头函数的情况:
箭头函数没有自己的this,继承外层上下文绑定的this。
11、改变this指向的方式有哪些?
call、apply、bind三者为改变this指向的方法。
共同点:第一个参数都为改变this的指针。若第一参数为null/undefined,this默认指向window
call(无数个参数)
- 第一个参数:改变this指向
- 第二个参数:实参
- 使用之后会自动执行该函数
function fn(a,b,c){
console.log(this,a+b+c); // this指向window
}
fn();
fn.call(document,1,2,3);//call改变之后this指向document
//输出 #document 6 1,2,3是实参 结果相加为6
apply(两个参数)
- 第一个参数:改变this指向
- 第二个参数:数组(里面为实参)
- 使用时候会自动执行函数
function fn(a,b,c){
console.log(this,a+b+c);
}
fn();
fn.apply(document,[1,2,3]);
bind(无数个参数)
- 第一个参数:改变this指向
- 第二个参数之后:实参
- 返回值为一个新的函数
- 使用的时候需要手动调用下返回 的新函数(不会自动执行)
function fn(a,b,c){
console.log(this,a+b+c); //window
}
let ff = fn.bind('小明',1,2,3); //手动调用一下
call、apply与bind区别:前两个可以自动执行,bind不会自动执行,需要手动调用
call、bind与apply区别:前两个都有无数个参数,apply只有两个参数,而且第二个参数为数组
12、 箭头函数的this
1.普通函数的this:指向它的调用者,如果没有调用者则默认指向window.
2.箭头函数的this: 指向箭头函数定义时所处的对象,而不是箭头函数使用时所在的对象,默认使用父级的this.
13、谈一下你对原型链的理解,画一个经典的原型链图示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HmBk1Lxf-1649150971262)(https://pic3.zhimg.com/v2-b86ade7ff43bdf1b05f4c5dc8704f634_1440w.jpg?source=172ae18b)]
具体参考 这篇文章
https://note.youdao.com/ynoteshare1/index.html?id=0c454a4f45787988f5b2e6f7043f70e7&type=note
14、举例说明JS如何实现继承
js继承总共分成5种,包括构造函数式继承、原型链式继承、组合式继承、寄生式继承和寄生组合式继承。
构造函数式继承
首先来看第一种,构造函数式继承,顾名思义,也就是利用函数去实现继承;
假设我们现在有一个父类函数:
// 父类构造函数
function Parent(color) {
this.color = color;
this.print = function() {
console.log(this.color);
}
}
现在要编写一个子类函数来继承这个父类,如下:
// 子类构造函数
function Son(color) {
Parent.call(this, color);
}
上面代码可以看到,子类Son是通过Parent.call的方式去调用父类构造函数,然后把this对象传进去,执行父类构造函数之后,子类Son就拥有了父类定义的color和print方法。调用一下该方法,输出如下:
// 测试
var son1 = new Son('red');
son1.print(); // red
var son2 = new Son('blue');
son2.print(); // blue
可以看到son1和son2都正常继承了父类的print方法和各自传进去的color属性;
以上就是构造函数式继承的实现了,这是最原始的js实现继承的方式;
但是当我们深入想一下会发现,这种根本就不是传统意义上的继承!
因为每一个Son子类调用父类生成的对象,都是各自独立的,也就是说,如果父类希望有一个公共的属性是所有子类实例共享的话,是没办法实现的。什么意思呢,来看下面的代码:
function Flower() {
this.colors = ['黄色', '红色'];
this.print = function () {
console.log(this.colors)
}
}
function Rose() {
Flower.call(this);
}
var r1 = new Rose();
var r2 = new Rose();
console.log(r1.print()); // [ '黄色', '红色' ]
console.log(r2.print()); // [ '黄色', '红色' ]
我们现在有一个基类Flower,它有一个属性colors,现在我们把某一个实例的colors值改一下:
r1.colors.push('紫色');
console.log(r1.print()); // [ '黄色', '红色', '紫色' ]
console.log(r2.print()); // [ '黄色', '红色' ]
结果如上,显然,改变的只有r1的值,因为通过构造函数创造出来的实例对象中,所有的属性和方法都是实例内部独立的,并不会跟其他实例共享。
总结一下构造函数的优缺点:
- 优点:所有的基本属性独立,不会被其他实例所影响;
- 缺点:所有希望共享的方法和属性也独立了,没有办法通过修改父类某一处来达到所有子实例同时更新的效果;同时,每次创建子类都会调用父类构造函数一次,所以每个子实例都拷贝了一份父类函数的内容,如果父类很大的话会影响性能;
原型链继承
下面我们来看第二种继承方式,原型链式继承;
同样先来看下例子:
function Parent() {
this.color = 'red';
this.print = function() {
console.log(this.color);
}
}
function Son() {
}
我们有一个父类和一个空的子类;
Son.prototype = new Parent();
Son.prototype.constructor = Son;
接着我们把子函数的原型属性赋值给了父函数的实例;
var son1 = new Son();
son1.print(); // red
最后新建子类实例,调用父类的方法,成功拿到父类的color和print属性方法;
我们重点来分析一下下面两行代码:
Son.prototype = new Parent();
Son.prototype.constructor = Son;
这段代码中,子函数的原型赋给了父函数的实例,我们知道prototype是函数中的一个属性,js的一个特性就是:**如果一个对象某个属性找不到,会沿着它的原型往上去寻找,直到原型链的最后才会停止寻找。**关于原型更多基础的知识,可以参考一下其他文章,或许以后我也会出一期专门讲解原型和原型链的文章。
回到代码,我们看到最后实例son成功调用了Print方法,输出了color属性,这是因为son从函数Son的prototype属性上面去找到的,也就是从new Parent这个对象里面找到的;
这种方式也不是真正的继承,因为所有的子实例的属性和方法,都在父类同一个实例上了,所以一旦某一个子实例修改了其中的方法,其他所有的子实例都会被影响,来看下代码:
function Flower() {
this.colors = ['黄色', '红色'];
this.print = function () {
console.log(this.colors)
}
}
function Rose() {}
Rose.prototype = new Flower();
Rose.prototype.constructor = Rose;
var r1 = new Rose();
var r2 = new Rose();
console.log(r1.print()); // [ '黄色', '红色' ]
console.log(r1.print()); // [ '黄色', '红色' ]
r1.colors.push('紫色');
console.log(r1.print()); // [ '黄色', '红色', '紫色' ]
console.log(r2.print()); // [ '黄色', '红色', '紫色' ]
还是刚才的例子,这次Rose子类选择了原型链继承,所以,子实例r1修改了colors之后,r2实例的colors也被改动了,这就是原型链继承不好的地方。
来总结下原型链继承的优缺点:
- 优点:很好的实现了方法的共享;
- 缺点:正是因为什么都共享了,所以导致一切的属性都是共享的,只要某一个实例进行修改,那么所有的属性都会变化;
组合式继承
这里来介绍第三种继承方式,组合式继承;
这种继承方式很好理解,既然构造函数式继承和原型链继承都有各自的优缺点,那么我们把它们各自的优点整合起来,不就完美了吗?
组合式继承做的就是这个事情~来看一段代码例子:
function Parent(color) {
this.color = color;
}
Parent.prototype.print = function() {
console.log(this.color);
}
function Son(color) {
Parent.call(this, color);
}
Son.prototype = new Parent();
Son.prototype.constructor = Son;
var son1 = new Son('red');
son1.print(); // red
var son2 = new Son('blue');
son2.print(); // blue
上面代码中,在Son子类中,使用了Parent.call来调用父类构造函数,同时又将Son.prototype赋给了父类实例;为什么要这样做呢?为什么这样就能解决上面两种继承的问题呢?
我们接着分析一下,使用Parent.call调用了父类构造函数之后,那么,以后所有通过new Son创建出来的实例,就单独拷贝了一份父类构造函数里面定义的属性和方法,这是前面构造函数继承所提到的一样的原理;
然后,再把子类原型prototype赋值给父类的实例,这样,**所有子类的实例对象就可以共享父类原型上定义的所有属性和方法。**这也不难理解,因为子实例会沿着原型链去找到父类函数的原型。
因此,只要我们定义父类函数的时候,**将私有属性和方法放在构造函数里面,将共享属性和方法放在原型上,**就能让子类使用了。
以上就是组合式继承,它很好的融合了构造函数继承和原型链继承,发挥两者的优势之处,因此,它算是真正意义上的继承方式。
寄生式继承
既然上面的组合式继承都已经这么完美了,为什么还需要其他的继承方式呢?
我们细想一下,Son.prototype = new Parent();这行代码,它有什么问题没有?
显然,每次我们实例化子类的时候,都需要调用一次父类构造函数,那么,如果父类构造函数是一个很大很长的函数,那么每次实例化子类就会执行很长时间。
实际上我们并不需要重新执行父类函数,我们只是想要继承父类的原型。
寄生式继承就是在做这个事情,它是基于原型链式继承的改良版:
var obj = {
color: 'red',
print: function() {
console.log(this.color);
}
};
var son1 = Object.create(obj);
son1.print(); // red
var son2 = Object.create(obj);
son2.print(); // red
寄生式继承本质上还是原型链继承,Object.create(obj);方法意思是以obj为原型构造对象,所以寄生式继承不需要构造函数,但是同样有着原型链继承的优缺点,也就是它把所有的属性和方法都共享了。
寄生组合式继承
接下来到我们最后一个继承方式,也就是目前业界最为完美的继承解决方案:寄生组合式继承。
没错,它就是es6的class语法实现原理。
但是如果你理解了组合式继承,那么理解这个方式也很简单,只要记住,它出现的主要目的,是为了解决组合式继承中每次都需要new Parent导致的执行多一次父类构造函数的缺点。
下面来看代码:
function Parent(color) {
this.color = color;
}
Parent.prototype.print = function() {
console.log(this.color);
}
function Son(color) {
Parent.call(this, color);
}
Son.prototype = Object.create(Parent.prototype);
Son.prototype.constructor = Son;
var son1 = new Son('red');
son1.print(); // red
var son2 = new Son('blue');
son2.print(); // blue
这段代码不同之处只有一个,就是把原来的Son.prototype = new Parent();修改为了Son.prototype = Object.create(Parent.prototype);
我们前面讲过,Object.create方法是以传入的对象为原型,创建一个新对象;创建了这个新对象之后,又赋值给了Son.prototype,因此Son的原型最终指向的其实就是父类的原型对象,和new Parent是一样的效果;
到这里,我们5中js的继承方式也就讲完了;
15、什么是负无穷大?
负无穷大是JavaScript中的一个数字,可以通过将负数除以零来得到。
16、你对事件循环有了解吗?说说看!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-86coLkuQ-1649150971262)(https://pic2.zhimg.com/v2-0b35a3df0b2e2712839ce551062e6d7f_1440w.jpg?source=172ae18b)]
我们都知道,javascript从诞生之日起就是一门单线程的非阻塞的脚本语言。这是由其最初的用途来决定的:与浏览器交互。
单线程意味着,javascript代码在执行的任何时候,都只有一个主线程来处理所有的任务。
而非阻塞则是当代码需要进行一项异步任务(无法立刻返回结果,需要花一定时间才能返回的任务,如I/O事件)的时候,主线程会挂起(pending)这个任务,然后在异步任务返回结果的时候再根据一定规则去执行相应的回调。
单线程是必要的,也是javascript这门语言的基石,原因之一在其最初也是最主要的执行环境——浏览器中,我们需要进行各种各样的dom操作。试想一下 如果javascript是多线程的,那么当两个线程同时对dom进行一项操作,例如一个向其添加事件,而另一个删除了这个dom,此时该如何处理呢?因此,为了保证不会 发生类似于这个例子中的情景,javascript选择只用一个主线程来执行代码,这样就保证了程序执行的一致性。
当然,现如今人们也意识到,单线程在保证了执行顺序的同时也限制了javascript的效率,因此开发出了web worker技术。这项技术号称让javascript成为一门多线程语言。
然而,使用web worker技术开的多线程有着诸多限制,例如:所有新线程都受主线程的完全控制,不能独立执行。这意味着这些“线程” 实际上应属于主线程的子线程。另外,这些子线程并没有执行I/O操作的权限,只能为主线程分担一些诸如计算等任务。所以严格来讲这些线程并没有完整的功能,也因此这项技术并非改变了javascript语言的单线程本质。
可以预见,未来的javascript也会一直是一门单线程的语言。
话说回来,前面提到javascript的另一个特点是“非阻塞”,那么javascript引擎到底是如何实现的这一点呢?答案就是今天这篇文章的主角——event loop(事件循环)。
注:虽然nodejs中的也存在与传统浏览器环境下的相似的事件循环。然而两者间却有着诸多不同,故把两者分开,单独解释。
*正文*
浏览器环境下js引擎的事件循环机制
1.执行栈与事件队列
当javascript代码执行的时候会将不同的变量存于内存中的不同位置:堆(heap)和栈(stack)中来加以区分。其中,堆里存放着一些对象。而栈中则存放着一些基础类型变量以及对象的指针。 但是我们这里说的执行栈和上面这个栈的意义却有些不同。
我们知道,当我们调用一个方法的时候,js会生成一个与这个方法对应的执行环境(context),又叫执行上下文。这个执行环境中存在着这个方法的私有作用域,上层作用域的指向,方法的参数,这个作用域中定义的变量以及这个作用域的this对象。 而当一系列方法被依次调用的时候,因为js是单线程的,同一时间只能执行一个方法,于是这些方法被排队在一个单独的地方。这个地方被称为执行栈。
当一个脚本第一次执行的时候,js引擎会解析这段代码,并将其中的同步代码按照执行顺序加入执行栈中,然后从头开始执行。如果当前执行的是一个方法,那么js会向执行栈中添加这个方法的执行环境,然后进入这个执行环境继续执行其中的代码。当这个执行环境中的代码 执行完毕并返回结果后,js会退出这个执行环境并把这个执行环境销毁,回到上一个方法的执行环境。。这个过程反复进行,直到执行栈中的代码全部执行完毕。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NcPwSRG6-1649150971262)(https://pic4.zhimg.com/80/v2-da078fa3eadf3db4bf455904ae06f84b_720w.jpg)]
2.macro task与micro task
以上的事件循环过程是一个宏观的表述,实际上因为异步任务之间并不相同,因此他们的执行优先级也有区别。不同的异步任务被分为两类:微任务(micro task)和宏任务(macro task)。
以下事件属于宏任务:
setInterval()setTimeout()
以下事件属于微任务
new Promise()new MutaionObserver()
前面我们介绍过,在一个事件循环中,异步事件返回结果后会被放到一个任务队列中。然而,根据这个异步事件的类型,这个事件实际上会被对应的宏任务队列或者微任务队列中去。并且在当前执行栈为空的时候,主线程会 查看微任务队列是否有事件存在。如果不存在,那么再去宏任务队列中取出一个事件并把对应的回到加入当前执行栈;如果存在,则会依次执行队列中事件对应的回调,直到微任务队列为空,然后去宏任务队列中取出最前面的一个事件,把对应的回调加入当前执行栈…如此反复,进入循环。
我们只需记住当当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件,然后再去宏任务队列中取出一个事件。同一次事件循环中,微任务永远在宏任务之前执行。
这样就能解释下面这段代码的结果:
setTimeout(function () {
console.log(1);
});
new Promise(function(resolve,reject){
console.log(2)
resolve(3)
}).then(function(val){
console.log(val);
})
结果为:
2
3
1
node环境下的事件循环机制
1.与浏览器环境有何不同?
在node中,事件循环表现出的状态与浏览器中大致相同。不同的是node中有一套自己的模型。node中事件循环的实现是依靠的libuv引擎。我们知道node选择chrome v8引擎作为js解释器,v8引擎将js代码分析后去调用对应的node api,而这些api最后则由libuv引擎驱动,执行对应的任务,并把不同的事件放在不同的队列中等待主线程执行。 因此实际上node中的事件循环存在于libuv引擎中。
2.事件循环模型
下面是一个libuv引擎中的事件循环的模型:
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<──connections─── │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
注:模型中的每一个方块代表事件循环的一个阶段
这个模型是node官网上的一篇文章中给出的,我下面的解释也都来源于这篇文章。我会在文末把文章地址贴出来,有兴趣的朋友可以亲自与看看原文。
3.事件循环各阶段详解
从上面这个模型中,我们可以大致分析出node中的事件循环的顺序:
外部输入数据–>轮询阶段(poll)–>检查阶段(check)–>关闭事件回调阶段(close callback)–>定时器检测阶段(timer)–>I/O事件回调阶段(I/O callbacks)–>闲置阶段(idle, prepare)–>轮询阶段…
以上各阶段的名称是根据我个人理解的翻译,为了避免错误和歧义,下面解释的时候会用英文来表示这些阶段。
这些阶段大致的功能如下:
- timers: 这个阶段执行定时器队列中的回调如
setTimeout() 和 setInterval()。
- I/O callbacks: 这个阶段执行几乎所有的回调。但是不包括close事件,定时器和
setImmediate()的回调。
- idle, prepare: 这个阶段仅在内部使用,可以不必理会。
- poll: 等待新的I/O事件,node在一些特殊情况下会阻塞在这里。
- check:
setImmediate()的回调会在这个阶段执行。
- close callbacks: 例如
socket.on('close', ...)这种close事件的回调。
下面我们来按照代码第一次进入libuv引擎后的顺序来详细解说这些阶段:
poll阶段
当个v8引擎将js代码解析后传入libuv引擎后,循环首先进入poll阶段。poll阶段的执行逻辑如下: 先查看poll queue中是否有事件,有任务就按先进先出的顺序依次执行回调。 当queue为空时,会检查是否有setImmediate()的callback,如果有就进入check阶段执行这些callback。但同时也会检查是否有到期的timer,如果有,就把这些到期的timer的callback按照调用顺序放到timer queue中,之后循环会进入timer阶段执行queue中的 callback。 这两者的顺序是不固定的,收到代码运行的环境的影响。如果两者的queue都是空的,那么loop会在poll阶段停留,直到有一个i/o事件返回,循环会进入i/o callback阶段并立即执行这个事件的callback。
值得注意的是,poll阶段在执行poll queue中的回调时实际上不会无限的执行下去。有两种情况poll阶段会终止执行poll queue中的下一个回调:1.所有回调执行完毕。2.执行数超过了node的限制。
check阶段
check阶段专门用来执行setImmediate()方法的回调,当poll阶段进入空闲状态,并且setImmediate queue中有callback时,事件循环进入这个阶段。
close阶段
当一个socket连接或者一个handle被突然关闭时(例如调用了socket.destroy()方法),close事件会被发送到这个阶段执行回调。否则事件会用process.nextTick()方法发送出去。
timer阶段
这个阶段以先进先出的方式执行所有到期的timer加入timer队列里的callback,一个timer callback指得是一个通过setTimeout或者setInterval函数设置的回调函数。
I/O callback阶段
如上文所言,这个阶段主要执行大部分I/O事件的回调,包括一些为操作系统执行的回调。例如一个TCP连接生错误时,系统需要执行回调来获得这个错误的报告。
4.process.nextTick,setTimeout与setImmediate的区别与使用场景
在node中有三个常用的用来推迟任务执行的方法:process.nextTick,setTimeout(setInterval与之相同)与setImmediate
这三者间存在着一些非常不同的区别:
process.nextTick()
尽管没有提及,但是实际上node中存在着一个特殊的队列,即nextTick queue。这个队列中的回调执行虽然没有被表示为一个阶段,当时这些事件却会在每一个阶段执行完毕准备进入下一个阶段时优先执行。当事件循环准备进入下一个阶段之前,会先检查nextTick queue中是否有任务,如果有,那么会先清空这个队列。与执行poll queue中的任务不同的是,这个操作在队列清空前是不会停止的。这也就意味着,错误的使用process.nextTick()方法会导致node进入一个死循环。。直到内存泄漏。
那么合适使用这个方法比较合适呢?下面有一个例子:
const server = net.createServer(() => {}).listen(8080);
server.on('listening', () => {});
这个例子中当,当listen方法被调用时,除非端口被占用,否则会立刻绑定在对应的端口上。这意味着此时这个端口可以立刻触发listening事件并执行其回调。然而,这时候on('listening)还没有将callback设置好,自然没有callback可以执行。为了避免出现这种情况,node会在listen事件中使用process.nextTick()方法,确保事件在回调函数绑定后被触发。
setTimeout()和setImmediate()
在三个方法中,这两个方法最容易被弄混。实际上,某些情况下这两个方法的表现也非常相似。然而实际上,这两个方法的意义却大为不同。
setTimeout()方法是定义一个回调,并且希望这个回调在我们所指定的时间间隔后第一时间去执行。注意这个“第一时间执行”,这意味着,受到操作系统和当前执行任务的诸多影响,该回调并不会在我们预期的时间间隔后精准的执行。执行的时间存在一定的延迟和误差,这是不可避免的。node会在可以执行timer回调的第一时间去执行你所设定的任务。
setImmediate()方法从意义上将是立刻执行的意思,但是实际上它却是在一个固定的阶段才会执行回调,即poll阶段之后。有趣的是,这个名字的意义和之前提到过的process.nextTick()方法才是最匹配的。node的开发者们也清楚这两个方法的命名上存在一定的混淆,他们表示不会把这两个方法的名字调换过来—因为有大量的node程序使用着这两个方法,调换命名所带来的好处与它的影响相比不值一提。
setTimeout()和不设置时间间隔的setImmediate()表现上及其相似。猜猜下面这段代码的结果是什么?
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
实际上,答案是不一定。没错,就连node的开发者都无法准确的判断这两者的顺序谁前谁后。这取决于这段代码的运行环境。运行环境中的各种复杂的情况会导致在同步队列里两个方法的顺序随机决定。但是,在一种情况下可以准确判断两个方法回调的执行顺序,那就是在一个I/O事件的回调中。下面这段代码的顺序永远是固定的:
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
答案永远是:
immediate
timeout
因为在I/O事件的回调中,setImmediate方法的回调永远在timer的回调前执行。
*尾声*
javascrit的事件循环是这门语言中非常重要且基础的概念。清楚的了解了事件循环的执行顺序和每一个阶段的特点,可以使我们对一段异步代码的执行顺序有一个清晰的认识,从而减少代码运行的不确定性。合理的使用各种延迟事件的方法,有助于代码更好的按照其优先级去执行。这篇文章期望用最易理解的方式和语言准确描述事件循环这个复杂过程,但由于作者自己水平有限,文章中难免出现疏漏。如果您发现了文章中的一些问题,欢迎在留言中提出,我会尽量回复这些评论,把错误更正。
17、微任务和宏任务有什么区别
宏任务
(macro)task,可以理解是每次执行栈执行的代码就是一个宏任务(包括每次从事件队列中获取一个事件回调并放到执行栈中执行)。
浏览器为了能够使得JS内部(macro)task与DOM任务能够有序的执行,会在一个(macro)task执行结束后,在下一个(macro)task 执行开始前,对页面进行重新渲染,流程如下:
(macro)task->渲染->(macro)task->...
宏任务包含:
script(整体代码)
setTimeout
setInterval
I/O
UI交互事件
postMessage
MessageChannel
setImmediate(Node.js 环境)
微任务
microtask,可以理解是在当前 task 执行结束后立即执行的任务。也就是说,在当前task任务后,下一个task之前,在渲染之前。
所以它的响应速度相比setTimeout(setTimeout是task)会更快,因为无需等渲染。也就是说,在某一个macrotask执行完后,就会将在它执行期间产生的所有microtask都执行完毕(在渲染前)。
微任务包含:
Promise.then
Object.observe
MutaionObserver
process.nextTick(Node.js 环境)
18、什么是===运算符?
*===被称为严格等式运算符,当两个操作数具有相同的值而没有任何类型转换时,该运算符返回true。*
19、异步解决方案有哪些?
promise 回调 async await
20、Promise, 说说你的理解
一、Promise是什么?
Promise是最早由社区提出和实现的一种解决异步编程的方案,比其他传统的解决方案(回调函数和事件)更合理和更强大。
ES6 将其写进了语言标准,统一了用法,原生提供了Promise对象。
ES6 规定,Promise对象是一个构造函数,用来生成Promise实例。
二、Promise是为解决什么问题而产生的?
promise是为解决异步处理回调金字塔问题而产生的
三、Promise的两个特点
1、Promise对象的状态不受外界影响
1)pending 初始状态
2)fulfilled 成功状态
3)rejected 失败状态
Promise 有以上三种状态,只有异步操作的结果可以决定当前是哪一种状态,其他任何操作都无法改变这个状态
2、Promise的状态一旦改变,就不会再变,任何时候都可以得到这个结果,状态不可以逆,只能由 pending变成fulfilled或者由pending变成rejected
四、Promise的三个缺点
1)无法取消Promise,一旦新建它就会立即执行,无法中途取消
2)如果不设置回调函数,Promise内部抛出的错误,不会反映到外部
3)当处于pending状态时,无法得知目前进展到哪一个阶段,是刚刚开始还是即将完成
五、Promise在哪存放成功回调序列和失败回调序列?
1)onResolvedCallbacks 成功后要执行的回调序列 是一个数组
2)onRejectedCallbacks 失败后要执行的回调序列 是一个数组
以上两个数组存放在Promise 创建实例时给Promise这个类传的函数中,默认都是空数组。
每次实例then的时候 传入 onFulfilled 成功回调 onRejected 失败回调,如果此时的状态是pending 则将onFulfilled和onRejected push到对应的成功回调序列数组和失败回调序列数组中,如果此时的状态是fulfilled 则onFulfilled立即执行,如果此时的状态是rejected则onRejected立即执行
上述序列中的回调函数执行的时候 是有顺序的,即按照顺序依次执行
六、Promise的用法
1、Promise构造函数接受一个函数作为参数,该函数的两个参数分别是resolve和reject。它们是两个函数,由 JavaScript 引擎提供,不用自己部署。
const promise = new Promise(function(resolve, reject) {
// ... some code
if (/* 异步操作成功 */){
resolve(value);
} else {
reject(error);
}
});
2、resolve函数的作用是,将Promise对象的状态从“未完成”变为“成功”(即从 pending 变为 resolved),在异步操作成功时调用,并将异步操作的结果,作为参数传递出去;reject函数的作用是,将Promise对象的状态从“未完成”变为“失败”(即从 pending 变为 rejected),在异步操作失败时调用,并将异步操作报出的错误,作为参数传递出去。
3、Promise实例生成以后,可以用then方法分别指定resolved状态和rejected状态的回调函数。
promise.then(function(value) {
// success
}, function(error) {
// failure
});
then方法可以接受两个回调函数作为参数。第一个回调函数是Promise对象的状态变为resolved时调用,第二个回调函数是Promise对象的状态变为rejected时调用。其中,第二个函数是可选的,不一定要提供。这两个函数都接受Promise对象传出的值作为参数。
21、说明如何使用JavaScript提交表单?
要使用JavaScript提交表单,请使用
document.form [0] .submit();
22、aync await的好处
async和await可以说是异步终极解决方案了,相比直接使用Promise来说,优势在于处理then的调用链,能够更清晰准确的写出代码,毕竟写一大堆then也很恶心,并且也能优雅地解决回调地狱问题。当然也存在一些缺点,因为await将异步代码改造成了同步代码,如果多个异步代码没有依赖性却使用了await会导致性能上的降低
23、移动端点击事件300ms延迟如何去掉?原因是什么?
300毫秒原因:
当用户第一次点击屏幕后,需要判断用户是否要进行双击操作,于是手机会等待300毫秒,
解决方案: faskclick.js
原理:
在检测到touchend事件的时候,会通过DOM自定义事件立即出发模拟一个click事件,并把浏览器在300ms之后真正的click事件阻止掉
25.function Foo(){
getName=function(){
Console.log(1)
}
return this;
}
Foo.geteName=function(){console.log(2)}
Foo.prototype.geteName=function(){console.log(3)}
var geteName=function(){console.log(4)}
function getName(){console.log(5)}
//输出结果
Foo.geteName()//2
geteName()//4
Foo().geteName()//1
geteName()//1
new Foo.geteName()//2
new Foo().geteName()//3
new new Foo().geteName()//3
24、Cookie有哪些属性?其中HttpOnly,Secure,Expire分别有什么作用?
Cookie总是保存在客户端中,按在客户端中的存储位置,可分为内存Cookie和硬盘Cookie。内存Cookie由浏览器维护,保存在内存中,浏览器关闭后就消失了,其存在时间是短暂的。硬盘Cookie保存在硬盘里,有一个过期时间,除非用户手工清理或到了过期时间,硬盘Cookie不会被删除,其存在时间是长期的。所以,按存在时间,可分为非持久Cookie和持久Cookie。
HTTP请求+cookie的交互流程
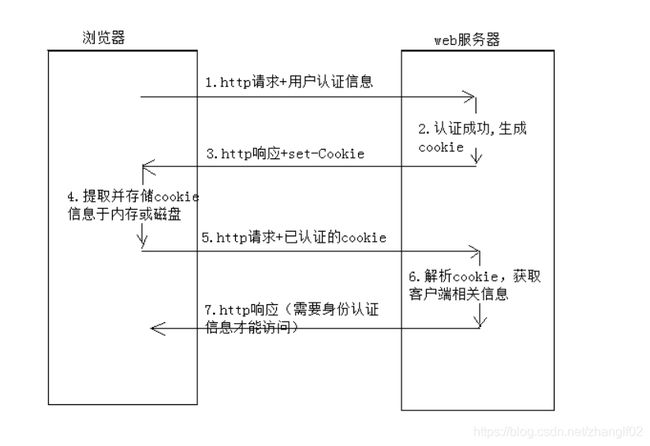
如果步骤5携带的是过期的cookie或者是错误的cookie,那么将认证失败,返回至要求身份认证页面。
HTTP协议作为无状态协议,对于HTTP协议而言,无状态同样指每次request请求之前是相互独立的,当前请求并不会记录它的上一次请求信息。那么问题来了,既然无状态,那完成一套完整的业务逻辑,发送多次请求的情况数不胜数,使用http如何将上下文请求进行关联呢?机智的人类通过优化,找到了一种简单的方式记录http协议的请求信息。
优化后的HTTP请求:
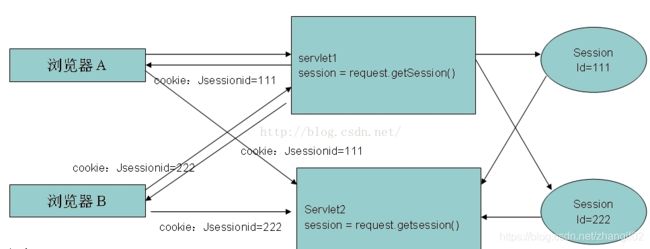
- 浏览器发送request请求到服务器,服务器除了返回请求的response之外,还给请求分配一个唯一标识ID,协同response一并返回给浏览器。
- 同时服务器在本地创建一个MAP结构,专门以key-value(请求ID-会话内容)形式将每个request进行存储
此时浏览器的request已经被赋予了一个ID,第二次访问时,服务器先从request中查找该ID,根据ID查找维护会话的content内容,该内容中记录了上一次request的信息状态。
- 根据查找出的request信息生成基于这些信息的response内容,再次返回给浏览器。如果有需要会再次更新会话内容,为下一次请求提供准备。
所以根据这个会话ID,以建立多次请求-响应模式的关联数据传递。说到这里可能已经唤起了大家许多共鸣。这就是cookie和session对无状态的http协议的强大作用。服务端生成这个全局的唯一标识,传递给客户端用于唯一标记这次请求,也就是cookie;而服务器创建的那个map结构就是session。所以,cookies由服务端生成,用于标记客户端的唯一标识,无特定含义,在每次网络请求中,都会被传送。session服务端自己维护的一个map数据结构,记录key-content上下文内容状态。
cookie的属性
一般cookie具有7个属性,包括:
Name:就是cookieName,一般用字母或数字,不能包含特殊字符,没什么好说的。
value:cookieName对应的值。
Domain:域,表示当前cookie所属于哪个域或子域下面,例如.baidu.com就表示在.baidu.com下可以访问。
对于服务器返回的Set-Cookie中,如果没有指定Domain的值,那么其Domain的值是默认为当前所提交的http的请求所对应的主域名的。比如访问 http://www.example.com,返回一个cookie,没有指名domain值,那么其为值为默认的www.example.com。
Path:表示cookie的所属路径,一般设为“/”,表示同一个站点的所有页面都可以访问这个cookie。
Expires/Max-age:表示了cookie的有效期。expires的值,是一个GMT格式的时间,过了这个时间,该cookie就失效了。或者是用max-age指定当前cookie是在多长时间之后而失效。如果服务器返回的一个cookie,没有指定其expire time,那么表明此cookie有效期只是当前的session,即是session cookie,当前session会话结束后,就过期了。对应的,当关闭(浏览器中)该页面的时候,此cookie就应该被浏览器所删除了。
secure:表示该cookie只能用https传输。一般用于包含认证信息的cookie,要求传输此cookie的时候,必须用https传输。
httponly:表示此cookie必须用于http或https传输。这意味着,浏览器脚本,比如javascript中,是不允许访问操作此cookie的。
如果你用的是谷歌浏览器,此时可以右击鼠标,选择检查,选择Application标签页,左侧找到cookies点击就可以看到这几个属性了
25、 JavaScript中的循环结构都有什么?*
For、While、do-while loops
26、说明“”和“=”之间的区别?
“”仅检查值相等,而“=”是一个更严格的等式判定,如果两个变量的值或类型不同,则返回false。
27、3 + 2 +“7”的结果是什么?
由于3和2是整数,它们将直接相加。由于7是一个字符串,它将会被直接连接,所以结果将是57。
28、说明如何检测客户端机器上的操作系统?
为了检测客户端机器上的操作系统,应使用navigator.appVersion字符串(属性)
29、将1234567转换为1,234,567
//法一
function parseNum(num){
var list = new String(num).split('').reverse();
for(var i = 0; i < list.length; i++){
if(i % 4 == 3){
list.splice(i, 0, ',');
}
}
return list.reverse().join('');
}
console.log(parseNum(10000121213));
//法二
function parseNum(num){
var reg=/(?=(?!\b)(\d{3})+$)/g;
return String(num).replace(reg, ',');
}
console.log(parseNum(10000121213));
//法三
String.prototype.strReverse = function(){
return this.split('').reverse().join('');
}
function parseNum(num){
var str_num = String(num);
var len = str_num.length;
var tail = str_num.slice(0, len % 3);
tail = tail.strReverse();
var reg=/\d{3}/g;
var list = str_num.strReverse().match(reg);
list.push(tail);
var res = list.join(',').strReverse();
return res;
}
console.log(parseNum(10000121213));
//法四
function parseNum(num){
var list = String(num).split('').reverse();
var temp = [];
for(var i = 0, len = list.length; i < len; i = i + 3){
temp.push(list.slice(i, i + 3).join(''));
}
return temp.join(',').split('').reverse().join('');
}
console.log(parseNum(10000121213));
30、Javascript中的NULL是什么意思?
NULL用于表示无值或无对象。它意味着没有对象或空字符串,没有有效的布尔值,没有数值和数组对象。
31、delete操作符的功能是什么?
delete操作符用于删除程序中的所有变量或对象,但不能删除使用VAR关键字声明的变量。
32、JavaScript中有哪些类型的弹出框?
Alert、Confirm and、Prompt
33、document load和documen ready 的区别
页面加载完成有两种事件
1.load是当页面所有资源全部加载完成后(包括DOM文档树,css文件,js文件,图片资源等),执行一个函数
问题:如果图片资源较多,加载时间较长,onload后等待执行的函数需要等待较长时间,所以一些效果可能受到影响
2.$(document).ready()是当DOM文档树加载完成后执行一个函数 (不包含图片,css等)所以会比load较快执行
在原生的jS中不包括ready()这个方法,只有load方法就是onload事件
34、如何自定义事件
- 事件的创建
JS中,最简单的创建事件方法,是使用Event构造器:
var myEvent = new Event('event_name');
但是为了能够传递数据,就需要使用 CustomEvent 构造器:
var myEvent = new CustomEvent('event_name', {
detail:{
// 将需要传递的数据写在detail中,以便在EventListener中获取
// 数据将会在event.detail中得到
},
});
- 事件的监听
JS的EventListener是根据事件的名称来进行监听的,比如我们在上文中已经创建了一个名称为**‘event_name’** 的事件,那么当某个元素需要监听它的时候,就需要创建相应的监听器:
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4TOrBbB8-1649150971263)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
//假设listener注册在window对象上
window.addEventListener('event_name', function(event){
// 如果是CustomEvent,传入的数据在event.detail中
console.log('得到数据为:', event.detail);
// ...后续相关操作
});
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LKC5diEB-1649150971263)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
至此,window对象上就有了对**‘event_name’** 这个事件的监听器,当window上触发这个事件的时候,相关的callback就会执行。
- 事件的触发
对于一些内置(built-in)的事件,通常都是有一些操作去做触发,比如鼠标单击对应MouseEvent的click事件,利用鼠标(ctrl+滚轮上下)去放大缩小页面对应WheelEvent的resize事件。
然而,自定义的事件由于不是JS内置的事件,所以我们需要在JS代码中去显式地触发它。方法是使用 dispatchEvent 去触发(IE8低版本兼容,使用fireEvent):
// 首先需要提前定义好事件,并且注册相关的EventListener
var myEvent = new CustomEvent('event_name', {
detail: { title: 'This is title!'},
});
window.addEventListener('event_name', function(event){
console.log('得到标题为:', event.detail.title);
});
// 随后在对应的元素上触发该事件
if(window.dispatchEvent) {
window.dispatchEvent(myEvent);
} else {
window.fireEvent(myEvent);
}
// 根据listener中的callback函数定义,应当会在console中输出 "得到标题为: This is title!"
需要特别注意的是,当一个事件触发的时候,如果相应的element及其上级元素没有对应的EventListener,就不会有任何回调操作。
对于子元素的监听,可以对父元素添加事件托管,让事件在事件冒泡阶段被监听器捕获并执行。这时候,使用event.target就可以获取到具体触发事件的元素。
35、用setTImeout 来实现setInterval
复制代码
function interval(func, w, t){
var interv = function(){
if(typeof t === "undefined" || t-- > 0){
setTimeout(interv, w);
try{
func.call(null);
}
catch(e){
t = 0;
throw e.toString();
}
}
};
setTimeout(interv, w);
};
复制代码
这个interval函数有一个叫做inter的内部函数,它通过setTimeout来自动被调用,在inter中有一个闭包,它检查了重复次数,调用了回调函数并通过setTimeout再次调用了interv。万一回调函数中出现了一个异常,interv调用将会终止,异常也会被抛出。
这种木事当然不能保证函数在固定的间隔中执行,但是它保证新的区间开始时上一个区间中的函数已经执行完毕,我认为这是非常重要的。
用法
现在我们可以在10秒的区间内执行一段代码5次,代码如下:
interval(function(){
//执行的代码在这
},1000,10);
36、什么是JavaScript Cookie?
Cookie是用来存储计算机中的小型测试文件,当用户访问网站以存储他们需要的信息时,它将被创建。
37、在JavaScript中使用innerHTML的缺点是什么?
如果在JavaScript中使用innerHTML,缺点是:内容随处可见;不能像“追加到innerHTML”一样使用;即使你使用+ = like“innerHTML = innerHTML +‘html’”旧的内容仍然会被html替换;整个innerHTML内容被重新解析并构建成元素,因此它的速度要慢得多;innerHTML不提供验证,因此我们可能会在文档中插入有效的和破坏性的HTML并将其中断。
38、如何创建通用对象?
通用对象可以创建为:
var I = new object();
39、在JavaScript中使用的Push方法是什么?
push方法用于将一个或多个元素添加或附加到数组的末尾。使用这种方法,可以通过传递多个参数来附加多个元素。
40、如何避免回调地狱
promise async await
41、构造函数Fn,原型对象,实例对象,三者之间的关系
每创建一个函数,该函数都会自动带有一个prototype属性。该属性是一个指针,指向一个对象,该对象称之为原型对象(后期我们可以使用这个原型对象帮助我们在js中实现继承).
原型对象上默认有一个属性constructor,该属性也是一个指针,指向其相关联的构造函数。
通过调用构造函数产生的实例对象,都拥有一个内部属性,指向了原型对象。其实例对象能够访问原型对象上的所有属性和方法。
总结:三者的关系是,每个构造函数都有一个原型对象,原型对象上包含着一个指向构造函数的指针,而实例都包含着一个指向原型对象的内部指针。通俗的说,实例可以通过内部指针访问到原型对象,原型对象可以通过constructor找到构造函数。
实例:
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vr2M96UG-1649150971263)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
function People(){
this.type='人'
}
People.prototype.showType=function(){
alert(this.type);
}
var person=new People();
//调用原型对象上面的方法
person.showType();//最后结果弹框弹出人
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MzKatyoJ-1649150971264)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
以上代码定义了一个构造函数People(),People.prototype指向原型对象,其自带属性construtor又指回了People,即People.prototype.constructor==People.实例对象person由于其内部指针指向了原型对象,所以可以访问原型对象上的showType方法。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EwYChKmw-1649150971264)(https://images2018.cnblogs.com/blog/1375391/201804/1375391-20180413141148575-907366970.png)]
记住People.prototype只是一个指针,指向的是原型对象,利用这个指针可以帮助我们实现js继承
2.原型链
在第一部分我们说到,所有的实例都有一个内部指针指向他的原型对象,并且可以访问到原型对象上的所有属性和方法。person实例对象指向了People的原型对象,可以访问People原型对象上的所有属性和方法。如果People原型对象变成了某一个类的实例aaa,这个实例又会指向一个新的原型对象AAA,那么person此时能访问aaa的实例属性和AAA原型对象上的所有属性和方法了。同理新的原型对象AAA碰巧有事另外一个对象的实例bbb,这个对象实例指向原型对象BBB,那么person就能访问bbb的实例属性和BBB原型上的属性和方法了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KRffxed5-1649150971264)(https://images2018.cnblogs.com/blog/1375391/201804/1375391-20180413144407775-1722807681.png)]
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C6SD8ADb-1649150971264)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
function People(){
this.type='人'
}
People.prototype.showType=function(){
alert(this.type);
}
function Woman(){
this.sex='女';
this.age=34;
}
Woman.prototype=new People();
var w=new Woman();console.log('大家好,我的种类是:'+w.type+",我的年龄是:"+w.age+",我的性别是:"+w.sex);//输出结果://大家好,我的种类是:人,我的年龄是:34,我的性格是:女//w.type是People上面定义的type
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iDFAVCeB-1649150971264)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
解释一下以上代码.以上代码,首先先定义了People构造函数,通过new People()得到实例,会包含一个实例对象type和一个原型属性showType。另外定义一个Woman构造函数,然后情况发生变化,本来构造函数woman的prototype会执行Woman的原型对象,但是我们这里稍有改变,将Woman构造函数的prototype指向了People实例对象覆盖了woman的原型对象。当Woman的实例对象woman去访问type属性时,js首先在woman实例属性中查找,发现没有定义,接着去woman的原型对象上找,woman的原型对象这里已经被我们改成了People实例,那就是去People实例上去找。先找People的实例属性,发现没有type,最后去People的原型对象上去找,终于找到了。这个查找就是这么一级一级的往上查找。
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BTh1pPi1-1649150971265)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
function People(){
this.type='人'
}
People.prototype.showType=function(){
alert(this.type);
}
function Woman(){
this.sex='女';
this.age=34; this.type='女生';//如果这里定义了type属性,就不会层级查找,最后在People找到该属性
}
Woman.prototype=new People();
var w=new Woman();
console.log('大家好,我的种类是:'+w.type+",我的年龄是:"+w.age+",我的性别是:"+w.sex);
//输出结果:
//大家好,我的种类是:女生,我的年龄是:34,我的性格是:女
这就说明,我们可以通过原型链的方式,实现 Woman继承 People 的所有属性和方法。
总结来说:就是当重写了Woman.prototype指向的原型对象后,实例的内部指针也发生了改变,指向了新的原型对象,然后就能实现类与类之间的继承了。
42、对MVC,MVVM的理解
1、MVC
View 传送指令到 Controller
Controller 完成业务逻辑后,要求 Model 改变状态
Model 将新的数据发送到 View,用户得到反馈
所有的通信都是单向的。
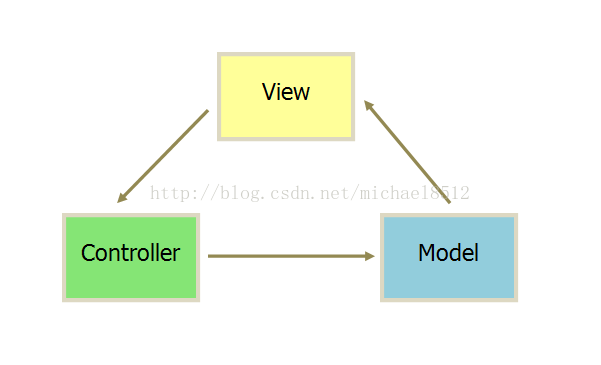
2、MVVM
View:UI界面
ViewModel:它是View的抽象,负责View与Model之间信息转换,将View的Command传送到Model;
Model:数据访问层
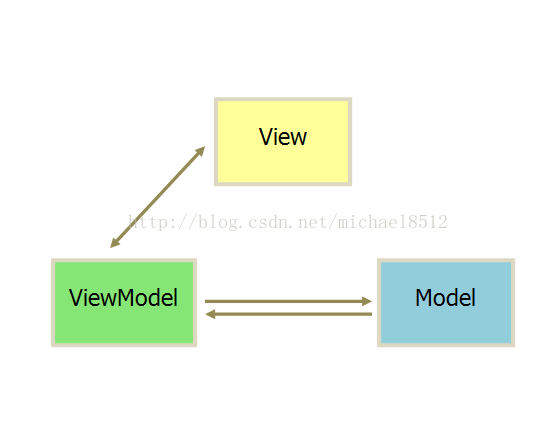
43、JavaScript中不同类型的错误有几种?
有三种类型的错误:
- Load time errors:该错误发生于加载网页时,例如出现语法错误等状况,称为加载时间错误,并且会动态生成错误。
- Run time errors:由于在HTML语言中滥用命令而导致的错误。
- Logical Errors:这是由于在具有不同操作的函数上执行了错误逻辑而发生的错误。
44、 使用正则表达式验证邮箱格式。
一.相关的代码
1 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CcLYsbMd-1649150971265)(https://www.cnblogs.com/Images/OutliningIndicators/None.gif)] function test()
2 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DNmKHgam-1649150971265)(https://www.cnblogs.com/Images/OutliningIndicators/None.gif)] {
3 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O2euhdap-1649150971265)(https://www.cnblogs.com/Images/OutliningIndicators/None.gif)] var temp = document.getElementById(“text1”);
4 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jKCUyiUU-1649150971266)(https://www.cnblogs.com/Images/OutliningIndicators/None.gif)] //对电子邮件的验证
5 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aztiRxqr-1649150971266)(https://www.cnblogs.com/Images/OutliningIndicators/None.gif)] var myreg = /^([a-zA-Z0-9]+[|_|.]?)*[a-zA-Z0-9]+@([a-zA-Z0-9]+[|_|.]?)*[a-zA-Z0-9]+.[a-zA-Z]{2,3}KaTeX parse error: Undefined control sequence: \n at position 444: … alert('提示\̲n̲\n请输入有效的E_mail!…/;
16 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9yStKyty-1649150971268)(https://www.cnblogs.com/Images/OutliningIndicators/None.gif)] var mobile1=/^(13+\d{9})|(159+\d{8})|(153+\d{8})KaTeX parse error: Undefined control sequence: \d at position 297: …oneAreaNum = /^\̲d̲{3,4}/;
19 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KJUz06l7-1649150971269)(https://www.cnblogs.com/Images/OutliningIndicators/None.gif)] //对于电话号码的验证
20 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4d6jFMEV-1649150971269)(https://www.cnblogs.com/Images/OutliningIndicators/None.gif)] var phone =/^\d{7,8}$/;
二.解释相关的意义
\1. /^ / 这 个 是 个 通 用 的 格 式 。 匹 配 输 入 字 符 串 的 开 始 位 置 ; / 这个是个通用的格式。 ^ 匹配输入字符串的开始位置; /这个是个通用的格式。匹配输入字符串的开始位置;匹配输入字符串的结束位置
\2. 里面输入需要实现的功能。
* 匹配前面的子表达式零次或多次;
+ 匹配前面的子表达式一次或多次;
?匹配前面的子表达式零次或一次;
\d 匹配一个数字字符,等价于[0-9]
45、简述同步和异步的区别
同步:
同步的思想是:所有的操作都做完,才返回给用户。这样用户在线等待的时间太长,给用户一种卡死了的感觉(就是系统迁移中,点击了迁移,界面就不动了,但是程序还在执行,卡死了的感觉)。这种情况下,用户不能关闭界面,如果关闭了,即迁移程序就中断了。
异步:
将用户请求放入消息队列,并反馈给用户,系统迁移程序已经启动,你可以关闭浏览器了。然后程序再慢慢地去写入数据库去。这就是异步。但是用户没有卡死的感觉,会告诉你,你的请求系统已经响应了。你可以关闭界面了。
同步和异步本身是相对的
同步就相当于是 当客户端发送请求给服务端,在等待服务端响应的请求时,客户端不做其他的事情。当服务端做完了才返回到客户端。这样的话客户端需要一直等待。用户使用起来会有不友好。
异步就是,当客户端发送给服务端请求时,在等待服务端响应的时候,客户端可以做其他的事情,这样节约了时间,提高了效率。
存在就有其道理 异步虽然好 但是有些问题是要用同步用来解决,比如有些东西我们需要的是拿到返回的数据在进行操作的。这些是异步所无法解决的。
46、对象属性如何分配?
属性按以下方式分配给对象:
obj[“class”] = 12;
或
obj.class = 12;
47、获得CheckBox状态的方式是什么?
alert(document.getElementById(‘checkbox1’)。checked);
如果CheckBox被检查,此警报将返回TRUE。
48、解释window.onload和onDocumentReady?
在载入页面的所有信息之前,不运行onload函数。这导致在执行任何代码之前会出现延迟。
onDocumentReady在加载DOM之后加载代码。这允许早期的代码操纵。
49、跨域请求资源的方法有哪些?
1.porxy代理 定义和用法:proxy代理用于将请求发送给后台服务器,通过服务器来发送请求,然后将请求的结果传递给前端。 实现方法:通过nginx代理; 注意点:如果你代理的是https协议的请求,那么你的…
2.CORS 【Cross-Origin Resource Sharing】 定义和用法:是现代浏览器支持跨域资源请求的一种最常用的…
3.jsonp 定义和用法:通过动态插入一个script标签。浏览器对script的资源引用…
50、****定义事件冒泡?
avaScript允许DOM元素嵌套在一起。在这种情况下,如果单击子级的处理程序,父级的处理程序也将执行同样的工作。
51、简述一下Sass,Less,请说明区别?
他们是动态的样式语言,是CSS预处理器,CSS上的一种抽象层。他们是一种特殊的语法/语言而编译成CSS。
变量符不一样,less是@,而Sass是$;
Sass支持条件语句,可以使用if{}else{},for{}循环等等。而Less不支持;
Sass是基于Ruby的,是在服务端处理的,而Less是需要引入less.js来处理Less代码输出Css到浏览器
52、数组扁平化,不用api
数组扁平化的自我(手撕)实现【核心:用到了递归,如果当前元素还是数组,继续递归,然后 res=res.concat(myFlat(arr[i])) 因为 concat是没有副作用与原数组的!!,否则是 res.push(arr[i]) 。
代码实现如下:
function myFlat(arr){
let res = [];
for(let i=0; i<arr.length; i++){
if(arr[i] instanceof Array){
res = res.concat(myFlat(arr[i]));
}else {
res.push(arr[i]);
}
}
return res;
}
let arr = [1,[2,3,[4,5]]];
console.log(myFlat(arr))
2、运行结果是符合预期的

53、什么样的布尔运算符可以在JavaScript中使用?
And”运算符(&&),'Or’运算符(||)和’Not’运算符(!)可以在JavaScript中使用。
*运算符没有括号。
54、用javascript实现观察者模式
ES5下的实现
再ES5中主要是通过Object.defineProperties方法定义对象属性的设置(set)和获取(get),并再进行设置时执行相关的处理函数,如下:
var targetObj={
age:1
}
function observer(oldval,newval){
console.log('name属性的值从 '+oldval+'改变为 '+newval);
}
Object.defineProperty(targetObj,'name',{
enumerable:true,
configurable:true,
get:function(){
return name;
},
set:function(val){
//调用处理函数
observer(name,val);
name=val;
}
});
targetObj.name="www";
targetObj.name="mmm";
console.info('targetObj:',targetObj);
结果为:
name属性的值从 改变为 www
name属性的值从 www改变为 mmm
targetObj:{age:1,name:"mmm"}
ES6的实现(使用set方法实现)
class TargetObj{
constructor(age,name){
this.name=name;
this.age=age;
}
set name(val){
Observer(name,val);
name=val;
}
}
function Observer(oldval,newval){
console.info('name属性的值从 '+ oldval +' 改变为 ' + newval);
}
let targetObj2 = new TargetObj(1,'www');
targetObj2.name="mmm";
console.info(targetObj2);
55、简述一下面象对象的六法则
-
单一职责原则:一个类只做它该做的事情。(单一职责原则想表达的就是”高内聚”,写代码最终极的原则只有六个字”高内聚、低耦合”,所谓的高内聚就是一个代码模块只完成一项功能,在面向对象中,如果只让一个类完成它该做的事,而不涉及与它无关的领域就是践行了高内聚的原则,这个类就只有单一职责。我们都知道一句话叫”因为专注,所以专业”,一个对象如果承担太多的职责,那么注定它什么都做不好。这个世界上任何好的东西都有两个特征,一个是功能单一,好的相机绝对不是电视购物里面卖的那种一个机器有一百多种功能的,它基本上只能照相;另一个是模块化,好的自行车是组装车,从减震叉、刹车到变速器,所有的部件都是可以拆卸和重新组装的,好的乒乓球拍也不是成品拍,一定是底板和胶皮可以拆分和自行组装的,一个好的软件系统,它里面的每个功能模块也应该是可以轻易的拿到其他系统中使用的,这样才能实现软件复用的目标。)
-
开闭原则:软件实体应当对扩展开放,对修改关闭。(在理想的状态下,当我们需要为一个软件系统增加新功能时,只需要从原来的系统派生出一些新类就可以,不需要修改原来的任何一行代码。要做到开闭有两个要点:①抽象是关键,一个系统中如果没有抽象类或接口系统就没有扩展点;②封装可变性,将系统中的各种可变因素封装到一个继承结构中,如果多个可变因素混杂在一起,系统将变得复杂而混乱,如果不清楚如何封装可变性,可以参考《设计模式精解》一书中对桥梁模式的讲解的章节。)
-
依赖倒转原则:面向接口编程。(该原则说得直白和具体一些就是声明方法的参数类型、方法的返回类型、变量的引用类型时,尽可能使用抽象类型而不用具体类型,因为抽象类型可以被它的任何一个子类型所替代,请参考下面的里氏替换原则。)
-
里氏替换原则:任何时候都可以用子类型替换掉父类型。(关于里氏替换原则的描述,Barbara Liskov女士的描述比这个要复杂得多,但简单的说就是能用父类型的地方就一定能使用子类型。里氏替换原则可以检查继承关系是否合理,如果一个继承关系违背了里氏替换原则,那么这个继承关系一定是错误的,需要对代码进行重构。例如让猫继承狗,或者狗继承猫,又或者让正方形继承长方形都是错误的继承关系,因为你很容易找到违反里氏替换原则的场景。需要注意的是:子类一定是增加父类的能力而不是减少父类的能力,因为子类比父类的能力更多,把能力多的对象当成能力少的对象来用当然没有任何问题。)
-
接口隔离原则:接口要小而专,绝不能大而全。(臃肿的接口是对接口的污染,既然接口表示能力,那么一个接口只应该描述一种能力,接口也应该是高度内聚的。例如,琴棋书画就应该分别设计为四个接口,而不应设计成一个接口中的四个方法,因为如果设计成一个接口中的四个方法,那么这个接口很难用,毕竟琴棋书画四样都精通的人还是少数,而如果设计成四个接口,会几项就实现几个接口,这样的话每个接口被复用的可能性是很高的。Java中的接口代表能力、代表约定、代表角色,能否正确的使用接口一定是编程水平高低的重要标识。)
-
合成聚合复用原则:优先使用聚合或合成关系复用代码。(通过继承来复用代码是面向对象程序设计中被滥用得最多的东西,因为所有的教科书都无一例外的对继承进行了鼓吹从而误导了初学者,类与类之间简单的说有三种关系,Is-A关系、Has-A关系、Use-A关系,分别代表继承、关联和依赖。其中,关联关系根据其关联的强度又可以进一步划分为关联、聚合和合成,但说白了都是Has-A关系,合成聚合复用原则想表达的是优先考虑Has-A关系而不是Is-A关系复用代码,原因嘛可以自己从百度上找到一万个理由,需要说明的是,即使在Java的API中也有不少滥用继承的例子,例如Properties类继承了Hashtable类,Stack类继承了Vector类,这些继承明显就是错误的,更好的做法是在Properties类中放置一个Hashtable类型的成员并且将其键和值都设置为字符串来存储数据,而Stack类的设计也应该是在Stack类中放一个Vector对象来存储数据。记住:任何时候都不要继承工具类,工具是可以拥有并可以使用的,而不是拿来继承的。)
-
迪米特法则:迪米特法则又叫最少知识原则,一个对象应当对其他对象有尽可能少的了解。(迪米特法则简单的说就是如何做到”低耦合”,门面模式和调停者模式就是对迪米特法则的践行。对于门面模式可以举一个简单的例子,你去一家公司洽谈业务,你不需要了解这个公司内部是如何运作的,你甚至可以对这个公司一无所知,去的时候只需要找到公司入口处的前台美女,告诉她们你要做什么,她们会找到合适的人跟你接洽,前台的美女就是公司这个系统的门面。再复杂的系统都可以为用户提供一个简单的门面,Java Web开发中作为前端控制器的Servlet或Filter不就是一个门面吗,浏览器对服务器的运作方式一无所知,但是通过前端控制器就能够根据你的请求得到相应的服务。调停者模式也可以举一个简单的例子来说明,例如一台计算机,CPU、内存、硬盘、显卡、声卡各种设备需要相互配合才能很好的工作,但是如果这些东西都直接连接到一起,计算机的布线将异常复杂,在这种情况下,主板作为一个调停者的身份出现,它将各个设备连接在一起而不需要每个设备之间直接交换数据,这样就减小了系统的耦合度和复杂度,如下图所示。迪米特法则用通俗的话来将就是不要和陌生人打交道,如果真的需要,找一个自己的朋友,让他替你和陌生人打交。
56、谈谈垃圾回收机制方法以及内存管理
回收机制方式
1、定义和用法:垃圾回收机制(GC:Garbage Collection),执行环境负责管理代码执行过程中使用的内存。
2、原理:垃圾收集器会定期(周期性)找出那些不在继续使用的变量,然后释放其内存。但是这个过程不是实时的,因为其开销比较大,所以垃圾回收器会按照固定的时间间隔周期性的执行。
3、实例如下:
function` `fn1() {`` ``var` `obj = {name: ``'hanzichi'``, age: 10};``}``function` `fn2() {`` ``var` `obj = {name:``'hanzichi'``, age: 10};`` ``return` `obj;``}``var` `a = fn1();``var` `b = fn2();
fn1中定义的obj为局部变量,而当调用结束后,出了fn1的环境,那么该块内存会被js引擎中的垃圾回收器自动释放;在fn2被调用的过程中,返回的对象被全局变量b所指向,所以该块内存并不会被释放。
4、垃圾回收策略:标记清除(较为常用)和引用计数。
标记清除:
定义和用法:当变量进入环境时,将变量标记"进入环境",当变量离开环境时,标记为:“离开环境”。某一个时刻,垃圾回收器会过滤掉环境中的变量,以及被环境变量引用的变量,剩下的就是被视为准备回收的变量。
到目前为止,IE、Firefox、Opera、Chrome、Safari的js实现使用的都是标记清除的垃圾回收策略或类似的策略,只不过垃圾收集的时间间隔互不相同。
引用计数:
定义和用法:引用计数是跟踪记录每个值被引用的次数。
基本原理:就是变量的引用次数,被引用一次则加1,当这个引用计数为0时,被视为准备回收的对象。
内存管理
1、什么时候触发垃圾回收?
垃圾回收器周期性运行,如果分配的内存非常多,那么回收工作也会很艰巨,确定垃圾回收时间间隔就变成了一个值得思考的问题。
IE6的垃圾回收是根据内存分配量运行的,当环境中的变量,对象,字符串达到一定数量时触发垃圾回收。垃圾回收器一直处于工作状态,严重影响浏览器性能。
IE7中,垃圾回收器会根据内存分配量与程序占用内存的比例进行动态调整,开始回收工作。
2、合理的GC方案:(1)、遍历所有可访问的对象; (2)、回收已不可访问的对象。
3、GC缺陷:(1)、停止响应其他操作;
4、GC优化策略:(1)、分代回收(Generation GC);(2)、增量GC
57、开发过程中遇到内存泄漏的问题
1、定义和用法:
内存泄露是指一块被分配的内存既不能使用,又不能回收,直到浏览器进程结束。C#和Java等语言采用了自动垃圾回收方法管理内存,几乎不会发生内存泄露。我们知道,浏览器中也是采用自动垃圾回收方法管理内存,但由于浏览器垃圾回收方法有bug,会产生内存泄露。
2、内存泄露的几种情况:
(1)、当页面中元素被移除或替换时,若元素绑定的事件仍没被移除,在IE中不会作出恰当处理,此时要先手工移除事件,不然会存在内存泄露。
实例如下:
`` ``````
解决方法如下:
`` ``````
(2)、由于是函数内定义函数,并且内部函数–事件回调的引用外暴了,形成了闭包。闭包可以维持函数内局部变量,使其得不到释放。
实例如下:
function` `bindEvent(){`` ``var` `obj=document.createElement(``"XXX"``);`` ``obj.onclick=``function``(){`` ``//Even if it's a empty function`` ``}``}
解决方法如下:
function` `bindEvent(){`` ``var` `obj=document.createElement(``"XXX"``);`` ``obj.onclick=``function``(){`` ``//Even if it's a empty function`` ``}`` ``obj=``null``;``}
.
58、定义事件冒泡?
JavaScript允许DOM元素嵌套在一起。在这种情况下,如果单击子级的处理程序,父级的处理程序也将执行同样的工作。
59、一个特定的框架如何使用JavaScript中的超链接定位?
可以通过使用“target”属性在超链接中包含所需帧的名称来实现。
>New Page
60、浏览器有哪些兼容问题,你封装过什么插件
1.cssHack
一丶http://browserhacks.com/
这个网站可以直接查询各种hack非常方便
2.通过Polyfill和shiv
Polyfill就像一个镊子可以帮我们刮平很多浏览器之的兼容性问题 :
比如让不支持picture标签的引入picturefill插件就可以在不支持的浏览器使用picture标签
shiv和Polyfill差不多 htmlshiv : https://github.com/aFarkas/html5shiv
比如这个html5shiv:
作用:在ie678不支持新的html5标签,通过引入这个库,就可以让这些浏览器有能力识别这些标签,其实就是利用了ie的createElement
像这样引入
3.respond
通过引入这样一个库可以让ie678支持媒体查询
连接: https://github.com/scottjehl/Respond
4.通过Modernizr
它可以查询浏览器对css3,html5的支持情况,如果浏览器支持某个特性,那么它就会向浏览器添加相对应的类,如果不支持它就会添加一个no开头的一个类
这是一个主动去检测兼容性的一种方式,对于一些实现性的,或者不确定兼容性的一些特性,建议使用这种主动性检测的方式,这样提供了一种主动性的解决方案
用法 :点击 download ,自己选择特性 ,点击 build ,点击拷贝 ,拷贝到一个新的 js 文件,这个 js 就可以检测是否可以兼容哪个特性
如果支持,那么html标签上就会多一个类比如 svg 就会有 class=“svg”,这样就可以自己写两类类名 .svg 和 .no-svg 分别引入不同的样式
具体用法参考官方文档
61、如何防止XSRF攻击
一 CSRF是什么?
跨站请求伪造(英语:Cross-site request forgery),也被称为 one-click attack 或者 session riding,通常缩写为 CSRF 或者 XSRF, 是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。
二、CSRF的原理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5HXRd3Dj-1649150971269)(https:upload-images.jianshu.io/upload_images/10852140-d963ba5a5de3deeb.png?imageMogr2/auto-orient/strip|imageView2/2/w/700/format/webp)]
image.png
三、CSRF的防范措施
1、验证 HTTP Referer 字段
HTTP头中的Referer字段记录了该 HTTP 请求的来源地址。在通常情况下,访问一个安全受限页面的请求来自于同一个网站,而如果黑客要对其实施 CSRF 攻击,他一般只能在他自己的网站构造请求。因此,可以通过验证Referer值来防御CSRF 攻击。
2、验证码。
验证码
利用验证码将用户收到的信息与后台服务器进行比对,每次用户提交都需要用户在表单中填写一个图片上的随机字符串,不符则进行拒绝。
3、添加token验证
CSRF攻击之所以能够成功,是因为攻击者可以完全伪造用户的请求,该请求中所有的用户验证信息都存在cookie中,因此攻击者可以在不知道这些验证信息的情况下直接利用用户自己的cookie来通过安全验证。要防止CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于cookie之中。可以在HTTP请求中以参数的形式加入一个随机产生的token,并在服务器建立一个拦截器来验证这个token,如果请求中没有token或者token不正确,则认为可能是CSRF攻击而拒绝该请求。
现在业界一致的做法就是使用Anti CSRF Token来防御CSRF。
用户访问某个表单页面。
服务端生成一个Token,放在用户的Session中,或者浏览器的Cookie中。
在页面表单附带上Token参数。
用户提交请求后,服务端验证表单中的Token是否与用户Session(或Cookies)中的Token一致,一致为合法请求,不是则非法请求。
这个Token值必须是随机的,不可预测的。由于Token的存在,攻击者无法再构造一个带有合法Token的请求实施CSRF攻击。另外使用Token应注意Token的保密性,尽量把敏感操作由GET改成POST,以form或者AJAX形式提交,避免Token泄露。
4、尽量使用POST,限制GET
GET接口能够直接将请求地址暴露给攻击者,所以要防止CSRF一定最好不要用GET。当然POST并不是万无一失,攻击者只需要构造一个form表单就可以,但需要在第三方页面做,这样就增加了暴露的可能性。
62、如何判断一个对象是否为数组,函数
在js中判断数据类型通常使用typeof,但是typeof在判断数组和对象时的结果都是object。
那么,怎么才能区分对象和数组呢?
- 判断原型
var obj = {};
var arr = [];
console.log(arr);
console.log(obj);
数组和对象的原型对象不一样,由此可以通过判断原型来判断一个对象是否为数组
var obj = {};
var arr = [];
console.log(Object.getPrototypeOf(obj) === Object.prototype);
console.log(Object.getPrototypeOf(obj) === Array.prototype);
但是这种方法虽然通过检查原型来判断是否为数组,不是特别稳定,因为原型可以人为改变的一旦原型改变就可能会失效。
var obj = {};
var arr = [];
Object.setPrototypeOf(obj, Array.prototype);
console.log(Object.getPrototypeOf(obj) === Object.prototype);//false
console.log(Object.getPrototypeOf(obj) === Array.prototype);//true
此时arr的原型不是Array.prototype第一个返回的结果为false,如此,不能判断是否为数组。
- 判断构造函数
创建对象和创建数组的构造函数不同可以通过此种方法判断一个对象是否为数组。
var obj = {};
var arr = [];
console.log(Object.getPrototypeOf(obj).constructor === Object);
console.log(Object.getPrototypeOf(obj).constructor === Array);
由此可见,两个输出结果并不一样,并且也符合我们的认知,通过此种方法也可以判断一个对象是否为数组。
但该种方法与上一种方法的问题一样即当构造函数被修改之后就无法判断真正的数组。
var obj = {};
var arr = [];
Object.getPrototypeOf(obj).constructor = Array;
console.log(Object.getPrototypeOf(obj).constructor === Object);//false
console.log(Object.getPrototypeOf(obj).constructor === Array);//true
console.log(Object.getPrototypeOf(arr).constructor === Array);//true
由此可见,该方法的缺点与上一种方法的一样。
在判断构造函数方法中除了直接判断外还可以使用 instanceof 判断一个对象是否为一个构造函数的实例
var obj = {};
var arr = [];
console.log(obj instanceof Array);//false
console.log(arr instanceof Array);//true
由此可见,该方法也可以判断是否为数组。
- Array.isArray()
通过Array.isArray()可以判断一个对象是否为数组。
var obj = {};
var arr = [];
console.log(Array.isArray(obj));//false
console.log(Array.isArray(arr));//true
由此可见此种方法可行,那么当我们把其构造函数改变后还会出现和上面一样的情况吗?
var obj = {};
var arr = [];
Object.getPrototypeOf(obj).constructor = Array;//false
console.log(Array.isArray(obj));//true
console.log(Array.isArray(arr));
由此可见,即便将obj的构造函数改为Array也能判断出真正的数组。
- 用Object.toString()方法判断
var obj = {};
var arr = [];
console.log(obj.toString());//[object Object]
console.log(arr.toString());//
由此可见对象是Object创建的,但是数组的toString()返回的是空。
这是因为js中每个对象都有toString()方法,该方法继承自Object.toString()方法,但数组被重写了,但是我们可以使用call()来调用数组的toString的原始方法来判断。
var obj = {};
var arr = [];
console.log(obj.toString());//[object Object]
console.log(Object.prototype.toString.call(arr));//[object Array]
由此可见,也可以通过此种方法判断一个对象是否为数组。
那么,如果改变构造函数是否会发生类似之前的情况呢?
var obj = {};
var arr = [];
Object.getPrototypeOf(obj).constructor = Array;
console.log(obj.toString());//[object Object]
console.log(Object.prototype.toString.call(arr));//[object Array]
由此可见,此时还能正常判断并不会发生此前出现的情况。
使用场景
判断一个对象是否为数组在什么地方使用呢
在进行克隆时,需要判断对象的属性是否为数组,根据结果采取不同的操作。
总结
-
判断原型和判断构造函数的方法的结果会因为原型和构造函数的改变发生改变,并不十分稳定。
-
Array,isArray()和Object.toString()方法较为稳定,较为推荐。
-
通常在进行克隆时会用到判断一个对象是否为数组。
63、JavaScript中如何使用事件处理程序?
事件是由用户生成活动(例如单击链接或填写表单)导致的操作。需要一个事件处理程序来管理所有这些事件的正确执行。事件处理程序是对象的额外属性。此属性包括事件的名称以及事件发生时采取的操作。
64、解释延迟脚本在JavaScript中的作用?
默认情况下,在页面加载期间,HTML代码的解析将暂停,直到脚本停止执行。这意味着,如果服务器速度较慢或者脚本特别沉重,则会导致网页延迟。在使用Deferred时,脚本会延迟执行直到HTML解析器运行。这减少了网页加载时间,并且它们的显示速度更快。
65、实现一个函数clone,可以对javascript中的5种主要数据类型进行值复制。
var clone = function (type) {
var o;
var typeA = typeof type;
switch (typeA){
case 'string':
o = typeA+'';
break;
case 'number':
o = typeA-0;
break;
case 'undefined':
break;
case 'boolean':
o = typeA;
break;
case 'object':
if(type===null){
o = null;
}else {
if(Object.prototype.toString.call(type).slice(8,-1)==='Array'){
o = [];
for(var i = 0;i
66、decodeURI()和encodeURI()是什么?
EncodeURl()用于将URL转换为十六进制编码。而DecodeURI()用于将编码的URL转换回正常。
67、解释JavaScript中的pop()方法?
pop()方法与shift()方法类似,但不同之处在于Shift方法在数组的开头工作。此外,pop()方法将最后一个元素从给定的数组中取出并返回。然后改变被调用的数组。
例:
var cloths = [“Shirt”, “Pant”, “TShirt”];
cloths.pop();
//Now cloth becomes Shirt,Pant
68、解释什么是回调函数,并提供一个简单的例子。
回调函数是可以作为参数传递给另一个函数的函数,并在某些操作完成后执行。下面是一个简单的回调函数示例,这个函数在某些操作完成后打印消息到控制台。
function modifyArray(arr, callback) {
// 对 arr 做一些操作
arr.push(100);
// 执行传进来的 callback 函数
callback();
}
var arr = [1, 2, 3, 4, 5];
modifyArray(arr, function() {
console.log("array has been modified", arr);
});
69、面向对象编程与面向过程编程的区别
面向过程考虑数据变换; 面向过程的世界是以目标问题规定的I/O为中心的
面向对象考虑功能分工; 面向对象的世界是以内部实现的可理解性为中心的
70、eval是做什么的?性能怎么样?安全如何?
eval方法是在运行时对脚bai本进行解du释执行,而普通的javascript会有一个zhi预处dao理的过程。所以会有一些性能上zhuan的损失,但是通常通过一些手段能将这些性能损失降低到非常少。不至于谈虎色变。
eval通常用在一些需要动态执行字符串,或将字符串转为javascript对象的场景,比如将json字符串转为javascript对象。
至于eval容易被XSS攻击是属于想当然的说法吧,XSS攻击就是在你的页面上嵌入html或javascript代码,我觉得与是否使用eval方法没有什么关系。
71、函数节流、防抖
函数防抖(debounce)
概念: 在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。
生活中的实例: 如果有人进电梯(触发事件),那电梯将在10秒钟后出发(执行事件监听器),这时如果又有人进电梯了(在10秒内再次触发该事件),我们又得等10秒再出发(重新计时)。
函数节流(throttle)
概念: 规定一个单位时间,在这个单位时间内,只能有一次触发事件的回调函数执行,如果在同一个单位时间内某事件被触发多次,只有一次能生效。
生活中的实例: 我们知道目前的一种说法是当 1 秒内连续播放 24 张以上的图片时,在人眼的视觉中就会形成一个连贯的动画,所以在电影的播放(以前是,现在不知道)中基本是以每秒 24 张的速度播放的,为什么不 100 张或更多是因为 24 张就可以满足人类视觉需求的时候,100 张就会显得很浪费资源。
分析图
假设,我们观察的总时间为10秒钟,规定1秒作为一次事件的最小间隔时间。
如果触发事件的频率是 0.5s/次,那么
函数防抖如图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BXkyO352-1649150971269)(https://img2018.cnblogs.com/blog/1151544/201906/1151544-20190606142434794-1253043957.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LoCQgxZU-1649150971270)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]
因为始终没法等一秒钟就被再次触发了,所以最终没有一次事件是成功的。
函数节流如图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mZb8cWtZ-1649150971270)(https://img2018.cnblogs.com/blog/1151544/201906/1151544-20190606142441724-816933604.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IBzjde3U-1649150971270)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]
因为控制了最多一秒一次,频率为0.5s/次,所以每一秒钟就有一次事件作废。最终控制成1s/次
如果触发事件的频率是 2s/次,那么
函数防抖如图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HNAjYOO4-1649150971270)(https://img2018.cnblogs.com/blog/1151544/201906/1151544-20190606142505531-1661322909.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JLsvgoCq-1649150971271)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]因为2s/次已经大于了规定的最小时间,所以每计时两秒便触发一次。
函数节流如图
同样,2s/次 大于了最小时间规定,所以每一次触发都生效。
应用场景
对于函数防抖,有以下几种应用场景:
给按钮加函数防抖防止表单多次提交。
对于输入框连续输入进行AJAX验证时,用函数防抖能有效减少请求次数。
判断scroll是否滑到底部,滚动事件+函数防抖
总的来说,适合多次事件一次响应的情况
对于函数节流,有如下几个场景:
游戏中的刷新率
DOM元素拖拽
Canvas画笔功能
总的来说,适合大量事件按时间做平均分配触发。
函数防抖:
function debounce(fn, wait) {
var timer = null;
return function () {
var context = this
var args = arguments
if (timer) {
clearTimeout(timer);
timer = null;
}
timer = setTimeout(function () {
fn.apply(context, args)
}, wait)
}
}
var fn = function () {
console.log('boom')
}
setInterval(debounce(fn,500),1000) // 第一次在1500ms后触发,之后每1000ms触发一次
setInterval(debounce(fn,2000),1000) // 不会触发一次(我把函数防抖看出技能读条,如果读条没完成就用技能,便会失败而且重新读条)
之所以返回一个函数,因为防抖本身更像是一个函数修饰,所以就做了一次函数柯里化。里面也用到了闭包,闭包的变量是timer。
函数节流
function throttle(fn, gapTime) {
let _lastTime = null;
return function () {
let _nowTime = + new Date()
if (_nowTime - _lastTime > gapTime || !_lastTime) {
fn();
_lastTime = _nowTime
}
}
}
let fn = ()=>{
console.log('boom')
}
setInterval(throttle(fn,1000),10)
如图是实现的一个简单的函数节流,结果是一秒打出一次boom
小结
函数防抖和函数节流是在时间轴上控制函数的执行次数。防抖可以类比为电梯不断上乘客,节流可以看做幻灯片限制频率播放电影。
72、“use strict”的作用是什么?
use strict 出现在 JavaScript 代码的顶部或函数的顶部,可以帮助你写出更安全的 JavaScript 代码。如果你错误地创建了全局变量,它会通过抛出错误的方式来警告你。例如,以下程序将抛出错误:
function doSomething(val) {
"use strict";
x = val + 10;
}
它会抛出一个错误,因为 x 没有被定义,并使用了全局作用域中的某个值对其进行赋值,而 use strict 不允许这样做。下面的小改动修复了这个错误:
function doSomething(val) {
"use strict";
var x = val + 10;
}
73、了解ES6 的 Proxy吗?
概述
- Proxy用于修改某些操作的默认行为,等同于在语言层面上做出修改,所以属于一种“元编程”,即对编程语言进行编程。
- Proxy可以理解成在目标对象前架设一层拦截层,外界访问该对象都必须先通过这层拦截,因此提供一种机制可以对外界的访问进行拦截或过滤。
实例的方法
1.get()
- get方法用于拦截某个属性的读取操作。
let person = {
name : '张三'
}
let proxy = new Proxy(person,{
get : function(target,property){
if(property in target){
return target[property];
}else{
throw new Error('property ' + property + ' no found!')
}
}
})
proxy.name; //'张三'
proxy.age; //property age no found!
12345678910111213141516
以上的实例当获取对象没有的属性age时,就会抛出错误;若不通过代理,则会返回undefined;
- get方法可以继承
let proto = new Proxy({},{
get(target,propertykey,receiver){
console.log('get '+ propertykey);
return target[propertykey];
}
});
let obj = Object.create(proto);
obj.lalala; //get lalala
123456789
- 利用Proxy对象,可以将读取属性的操作变为执行某个函数,从而实现函数的链式操作;
let pipe = (function(){
return function(value){
//创建函数执行栈
let funcStack = [];
//创建拦截器
let oproxy = new Proxy({},{
get: function(pipeObj,fnName){
//当属性为get,返回函数栈一次执行函数后的结果
if(fnName === 'get'){
return funcStack.reduce(function(val,fn){
return fn(val);
},value)
}
//否则将函数置入函数执行栈中,并返回又一个拦截器
else{
funcStack.push(window[fnName]);
return oproxy;
}
}
});
// 将拦截器返回给pipe
return oproxy;
}
}())
let double = n=>n*2;
let pow = n=>n*n;
pipe(2).double.pow.get; //16
1234567891011121314151617181920212223242526272829
2.set()
- set方法用户拦截某个属性的赋值操作
let ageLimit = {
set : function(obj,prop,val){
if(prop === 'age'){
if(!Number.isInteger(val)){
throw new TypeError('the age must be a integer')
}
if(val > 150 || val < 0){
throw new RangeError('the age must be from 0 to 150')
}
}
obj[prop] = val;
}
}
let person = new Proxy({},ageLimit);
person.age = 200; //the age must be from 0 to 150;
person.age = 'abc' //the age must be a integer;
person.age = 20; //正常
person.age; // 20;
1234567891011121314151617181920
- 通过ageLimit拦截器,可以及时对用户的数据输入做数据验证,以保证数值规范;
- 有时候,我们会在对象上设置内部属性,属性名的第一个字符为下划线’_’,表示该属性不能被外部访问或使用。结合get和set方法,就可以做到防止内部属性被外部读写;
let handler = {
get (target , key){
invariant(key,'get');
return target[key];
},
set (target , key , value){
invatiant(key,'set');
taget[key] = value;
return true;
}
}
function invariant(key,action){
if(key[0] === '_'){
throw new Error('no allowed to ' + action + ' the property');
}
}
let target = {
_name : '张三',
_age : 20
};
let proxy = new Proxy(target,handler);
proxy._name; // no allowed to get the property
proxy._age = 12 // no allowed to set the property
1234567891011121314151617181920212223242526
3.apply()
- apply方法拦截函数的调用、call、apply操作
- apply方法接收三个参数:目标对象、目标对象的上下文的this、目标对象的参数数组
let target = function(){
console.log('I am the target');
}
let handler = {
apply : function(){
console.log('I am the apply');
}
}
let p = new Proxy(target,handler);
p(); //I am the apply;
12345678910111213
4.其他方法
- has(target,propkey)
- 拦截
hasProperty()、propkey in proxy操作,返回一个布尔值;
- deleteProperty(target,propkey)
- 拦截
delete proxy[propkey]操作,返回一个布尔值;
- ownKeys(target)
- 拦截
Object.getOwnPropertyNarnes(proxy)、Object.getOwnPropertySyrnbols (proxy)、 Object.keys(proxy),返回一个数组。该方法返回目标对象所有自身属性的属 性名,而 Object .keys()的返回结果仅包括目标对象自身的可遍历属性;
- getOwnPropertyDescriptor(target,propkey)
- 拦截
Object.getOwnPropertyDescriptor(proxy, propKey),返回属性的描述对象;
- defineProperty(target,propkey)
- 拦截
Object.defineProperty(proxy, propKey, propDesc)、 Object.define Properties(proxy, propDescs),返回一个布尔值;
- preventExtensions(target)
- 拦截
Object . preventExtensions (proxy) ,返回一个布尔值;
- getPrototypeOf(target)
- 拦截
Object.getPrototypeOf(proxy),返回一个对象;
- isExtensible(target)
- 拦截
Object.isExtensible(proxy),返回一个布尔值;
- setPrototypeOf(target)
- 拦截
Object.setPrototypeOf(proxy,proto),返回一个布尔值;若对象为函数,则还有二外两种操作可以拦截(apply,construct)
- construct(target,args)
- 拦截Proxy实例作为构造函数调用的操作,比如 new proxy(…args);
74、深拷贝是什么?
变量存储类型分两类
①基本类型:直接存储在栈中的数据。(字符串、布尔值、未定义、数字、null)
②引用类型:将该对象引用地址存储在栈中,然后对象里面的数据存放在堆中。(数组、对象、函数)
这里解释一下为什么null是基本类型:有人说他用type of打印出来不是oject吗?
null只是一个空指针对象,没有数据。根据引用类型特点可以看一下是否符合。
=================
回到我们的问题上
说说深拷贝和浅拷贝还有赋值的区别,这样好理解
浅拷贝:也就是拷贝A对象里面的数据,但是不拷贝A对象里面的子对象
深拷贝:会克隆出一个对象,数据相同,但是引用地址不同(就是拷贝A对象里面的数据,而且拷贝它里面的子对象)
赋值:获得该对象的引用地址
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YmfC1VxW-1649150971271)(https:upload-images.jianshu.io/upload_images/15856169-26e2e4a0fc8a39b4.png?imageMogr2/auto-orient/strip|imageView2/2/w/310/format/webp)]
浅拷贝和深拷贝的区别
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X9Fu8nMx-1649150971271)(https:upload-images.jianshu.io/upload_images/15856169-88bd5975eafaa488.png?imageMogr2/auto-orient/strip|imageView2/2/w/600/format/webp)]
三者的区别
下面用实例来说明
赋值特点说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7tCEn6rO-1649150971272)(https:upload-images.jianshu.io/upload_images/15856169-f1e9ecf6d9d60022.png?imageMogr2/auto-orient/strip|imageView2/2/w/894/format/webp)]
赋值,疑惑点来自于下图。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oZpR9KmI-1649150971272)(https:upload-images.jianshu.io/upload_images/15856169-c267376dd0e7f2a3.png?imageMogr2/auto-orient/strip|imageView2/2/w/465/format/webp)]
赋值打印图
浅拷贝特点说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dIRRby37-1649150971272)(https:upload-images.jianshu.io/upload_images/15856169-f0f7ebf1a5fb2f74.png?imageMogr2/auto-orient/strip|imageView2/2/w/601/format/webp)]
obj还是上面的
深拷贝说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4yVTP1te-1649150971272)(https:upload-images.jianshu.io/upload_images/15856169-81300a534b525fbb.png?imageMogr2/auto-orient/strip|imageView2/2/w/479/format/webp)]
第一种方法的缺陷在于函数不能拷贝
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JGBrlDhM-1649150971273)(https:upload-images.jianshu.io/upload_images/15856169-cb3b1c628336d4bc.png?imageMogr2/auto-orient/strip|imageView2/2/w/554/format/webp)]
75、解释 JavaScript 中的 null 和 undefined。
JavaScript 中有两种底层类型:null 和 undefined。它们代表了不同的含义:
- 尚未初始化:undefined;
- 空值:null。
null和undefined是两个不同的对象, 有图为证:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fIpisKkp-1649150971273)(https:upload-images.jianshu.io/upload_images/9890665-81a1b4abb5db481a.png?imageMogr2/auto-orient/strip|imageView2/2/w/256/format/webp)]
76、解释 JavaScript 中的值和类型。
JavaScript提供两种数据类型: 基本数据类型和引用数据类型
基本数据类型有:
- String
- Number
- Boolean
- Null
- Undefined
- Symbol
引用数据类型有:
- Object
- Array
- Function
77、scroll resize 使用函数节流实现不要频繁触发事件的需求
78、解释事件冒泡以及如何阻止它?
事件冒泡是指嵌套最深的元素触发一个事件,然后这个事件顺着嵌套顺序在父元素上触发。
防止事件冒泡的一种方法是使用 event.cancelBubble 或 event.stopPropagation()(低于 IE 9)。
79、JavaScript 中的 let 关键字有什么用?
用let声明变量只在块级作用域起作用,适合在for循环使用,也不会出现变量提升现象。同一个代码块内,不可重复声明的相同变量,不可重复声明函数内的参数。
80、 jQuery 优点和缺点
具体而言,jQuery有如下优势:
1,提供了用css选择符来选择dom元素的api(现在已经被浏览器内置支持)
2,提供了浏览器的检测api
3,提供了兼容的功能性api
4,提供了DOM的批处理操作(批处理思想永远都不会过时)
5,提供了dom操作的链式操作
6,提供了插件机制(代码复用变得容易,也不容易过时)
缺点 现在已经很少操作DOM了 现代框架VUE中 jquery代码工程化 可维护性差vue很远
81、ES6 class关键字原理跟function什么区别
传统的javascript中只有对象,没有类的概念。它是基于原型的面向对象语言。原型对象特点就是将自身的属性共享给新对象。这样的写法相对于其它传统面向对象语言来讲,很有一种独树一帜的感脚!非常容易让人困惑!
如果要生成一个对象实例,需要先定义一个构造函数,然后通过new操作符来完成。构造函数示例:
//函数名和实例化构造名相同且大写(非强制,但这么写有助于区分构造函数和普通函数)
function Person(name,age) {
this.name = name;
this.age=age;
}
Person.prototype.say = function(){
return "我的名字叫" + this.name+"今年"+this.age+"岁了";
}
var obj=new Person("laotie",88);//通过构造函数创建对象,必须使用new 运算符
console.log(obj.say());//我的名字叫laotie今年88岁了
构造函数生成实例的执行过程:
1.当使用了构造函数,并且new 构造函数(),后台会隐式执行new Object()创建对象;
2.将构造函数的作用域给新对象,(即new Object()创建出的对象),而函数体内的this就代表new Object()出来的对象。
3.执行构造函数的代码。
4.返回新对象(后台直接返回);
ES6引入了Class(类)这个概念,通过class关键字可以定义类。该关键字的出现使得其在对象写法上更加清晰,更像是一种面向对象的语言。如果将之前的代码改为ES6的写法就会是这个样子:
class Person{//定义了一个名字为Person的类
constructor(name,age){//constructor是一个构造方法,用来接收参数
this.name = name;//this代表的是实例对象
this.age=age;
}
say(){//这是一个类的方法,注意千万不要加上function
return "我的名字叫" + this.name+"今年"+this.age+"岁了";
}
}
var obj=new Person("laotie",88);
console.log(obj.say());//我的名字叫laotie今年88岁了
注意项
1.在类中声明方法的时候,千万不要给该方法加上function关键字
2.方法之间不要用逗号分隔,否则会报错
由下面代码可以看出类实质上就是一个函数。类自身指向的就是构造函数。所以可以认为ES6中的类其实就是构造函数的另外一种写法!
console.log(typeof Person);//function
console.log(Person===Person.prototype.constructor);//true
以下代码说明构造函数的prototype属性,在ES6的类中依然存在着。
console.log(Person.prototype);//输出的结果是一个对象
实际上类的所有方法都定义在类的prototype属性上。代码证明下:
Person.prototype.say=function(){//定义与类中相同名字的方法。成功实现了覆盖!
return "我是来证明的,你叫" + this.name+"今年"+this.age+"岁了";
}
var obj=new Person("laotie",88);
console.log(obj.say());//我是来证明的,你叫laotie今年88岁了
当然也可以通过prototype属性对类添加方法。如下:
Person.prototype.addFn=function(){
return "我是通过prototype新增加的方法,名字叫addFn";
}
var obj=new Person("laotie",88);
console.log(obj.addFn());//我是通过prototype新增加的方法,名字叫addFn
还可以通过Object.assign方法来为对象动态增加方法
Object.assign(Person.prototype,{
getName:function(){
return this.name;
},
getAge:function(){
return this.age;
}
})
var obj=new Person("laotie",88);
console.log(obj.getName());//laotie
console.log(obj.getAge());//88
constructor方法是类的构造函数的默认方法,通过new命令生成对象实例时,自动调用该方法。
class Box{
constructor(){
console.log("啦啦啦,今天天气好晴朗");//当实例化对象时该行代码会执行。
}
}
var obj=new Box();
constructor方法如果没有显式定义,会隐式生成一个constructor方法。所以即使你没有添加构造函数,构造函数也是存在的。constructor方法默认返回实例对象this,但是也可以指定constructor方法返回一个全新的对象,让返回的实例对象不是该类的实例。
class Desk{
constructor(){
this.xixi="我是一只小小小小鸟!哦";
}
}
class Box{
constructor(){
return new Desk();// 这里没有用this哦,直接返回一个全新的对象
}
}
var obj=new Box();
console.log(obj.xixi);//我是一只小小小小鸟!哦
constructor中定义的属性可以称为实例属性(即定义在this对象上),constructor外声明的属性都是定义在原型上的,可以称为原型属性(即定义在class上)。hasOwnProperty()函数用于判断属性是否是实例属性。其结果是一个布尔值, true说明是实例属性,false说明不是实例属性。in操作符会在通过对象能够访问给定属性时返回true,无论该属性存在于实例中还是原型中。
class Box{
constructor(num1,num2){
this.num1 = num1;
this.num2=num2;
}
sum(){
return num1+num2;
}
}
var box=new Box(12,88);
console.log(box.hasOwnProperty("num1"));//true
console.log(box.hasOwnProperty("num2"));//true
console.log(box.hasOwnProperty("sum"));//false
console.log("num1" in box);//true
console.log("num2" in box);//true
console.log("sum" in box);//true
console.log("say" in box);//false
类的所有实例共享一个原型对象,它们的原型都是Person.prototype,所以proto属性是相等的
class Box{
constructor(num1,num2){
this.num1 = num1;
this.num2=num2;
}
sum(){
return num1+num2;
}
}
//box1与box2都是Box的实例。它们的__proto__都指向Box的prototype
var box1=new Box(12,88);
var box2=new Box(40,60);
console.log(box1.__proto__===box2.__proto__);//true
由此,也可以通过proto来为类增加方法。使用实例的proto属性改写原型,会改变Class的原始定义,影响到所有实例,所以不推荐使用!
class Box{
constructor(num1,num2){
this.num1 = num1;
this.num2=num2;
}
sum(){
return num1+num2;
}
}
var box1=new Box(12,88);
var box2=new Box(40,60);
box1.__proto__.sub=function(){
return this.num2-this.num1;
}
console.log(box1.sub());//76
console.log(box2.sub());//20
class不存在变量提升,所以需要先定义再使用。因为ES6不会把类的声明提升到代码头部,但是ES5就不一样,ES5存在变量提升,可以先使用,然后再定义。
//ES5可以先使用再定义,存在变量提升
new A();
function A(){
}
//ES6不能先使用再定义,不存在变量提升 会报错
new B();//B is not defined
class B{
}
82、如何检查一个数字是否为整数?
检查一个数字是小数还是整数,可以使用一种非常简单的方法,就是将它对 1 进行取模,看看是否有余数。
function isInt(num) {
return num % 1 === 0;
}
console.log(isInt(4)); // true
console.log(isInt(12.2)); // false
console.log(isInt(0.3)); // false
83、 什么是 IIFE(立即调用函数表达式)?
它是立即调用函数表达式(Immediately-Invoked Function Expression),简称 IIFE。函数被创建后立即被执行:
(function IIFE(){
console.log( "Hello!" );
})();
// "Hello!"
在避免污染全局命名空间时经常使用这种模式,因为 IIFE(与任何其他正常函数一样)内部的所有变量在其作用域之外都是不可见的。
84、如何在 JavaScript 中比较两个对象?
对于两个非原始值,比如两个对象(包括函数和数组),== 和 === 比较都只是检查它们的引用是否匹配,并不会检查实际引用的内容。
例如,默认情况下,数组将被强制转型成字符串,并使用逗号将数组的所有元素连接起来。所以,两个具有相同内容的数组进行 == 比较时不会相等:
var a = [1,2,3];
var b = [1,2,3];
var c = "1,2,3";
a == c; // true
b == c; // true
a == b; // false
对于对象的深度比较,可以使用 deep-equal 这个库,或者自己实现递归比较算法
85、 你能解释一下 ES5 和 ES6 之间的区别吗?
- ECMAScript 5(ES5):ECMAScript 的第 5 版,于 2009 年标准化。这个标准已在所有现代浏览器中完全实现。
- ECMAScript 6(ES6)或 ECMAScript 2015(ES2015):第 6 版 ECMAScript,于 2015 年标准化。这个标准已在大多数现代浏览器中部分实现。
以下是 ES5 和 ES6 之间的一些主要区别:
箭头函数和字符串插值:
const greetings = (name) => {
return `hello ${name}`;
}
const greetings = name => `hello ${name}`;
常量
常量在很多方面与其他语言中的常量一样,但有一些需要注意的地方。常量表示对值的“固定引用”。因此,在使用常量时,你实际上可以改变变量所引用的对象的属性,但无法改变引用本身。
const NAMES = [];
NAMES.push("Jim");
console.log(NAMES.length === 1); // true
NAMES = ["Steve", "John"]; // error
块作用域变量。
新的 ES6 关键字 let 允许开发人员声明块级别作用域的变量。let 不像 var 那样可以进行提升。
默认参数值
默认参数允许我们使用默认值初始化函数。如果省略或未定义参数,则使用默认值,也就是说 null 是有效值。
// 基本语法
function multiply (a, b = 2) {
return a * b;
}
multiply(5); // 10
类定义和继承
ES6 引入了对类(关键字 class)、构造函数(关键字 constructor)和用于继承的 extend 关键字的支持。
for…of 操作符
for…of 语句将创建一个遍历可迭代对象的循环。
用于对象合并的 Spread 操作
const obj1 = { a: 1, b: 2 }
const obj2 = { a: 2, c: 3, d: 4}
const obj3 = {...obj1, ...obj2}
promise
promise 提供了一种机制来处理异步操作结果。你可以使用回调来达到同样的目的,但是 promise 通过方法链接和简洁的错误处理带来了更高的可读性。
const isGreater = (a, b) => {
return new Promise ((resolve, reject) => {
if(a > b) {
resolve(true)
} else {
reject(false)
}
})
}
isGreater(1, 2)
.then(result => {
console.log('greater')
})
.catch(result => {
console.log('smaller')
})
模块导出和导入
const myModule = { x: 1, y: () => { console.log('This is ES5') }}
export default myModule;
import myModule from './myModule';
86、 解释 JavaScript 中“undefined”和“not defined”之间的区别。
在 JavaScript 中,如果你试图使用一个不存在且尚未声明的变量,JavaScript 将抛出错误“var name is not defined”,让后脚本将停止运行。但如果你使用 typeof undeclared_variable,它将返回 undefined。
在进一步讨论之前,先让我们理解声明和定义之间的区别。
“var x”表示一个声明,因为你没有定义它的值是什么,你只是声明它的存在。
var x; // 声明 x
console.log(x); // 输出: undefined
“var x = 1”既是声明又是定义(我们也可以说它是初始化),x 变量的声明和赋值相继发生。在 JavaScript 中,每个变量声明和函数声明都被带到了当前作用域的顶部,然后进行赋值,这个过程被称为提升(hoisting)。
当我们试图访问一个被声明但未被定义的变量时,会出现 undefined 错误。
var x; // 声明
if(typeof x === 'undefined') // 将返回 true
当我们试图引用一个既未声明也未定义的变量时,将会出现 not defined 错误。
console.log(y); // 输出: ReferenceError: y is not defined
87、如何在 JavaScript 中创建私有变量?
要在 JavaScript 中创建无法被修改的私有变量,你需要将其创建为函数中的局部变量。即使这个函数被调用,也无法在函数之外访问这个变量。例如:
function func() {
var priv = "secret code";
}
console.log(priv); // throws error
要访问这个变量,需要创建一个返回私有变量的辅助函数。
function func() {
var priv = "secret code";
return function() {
return priv;
}
}
var getPriv = func();
console.log(getPriv()); // => secret code
88、 请解释原型设计模式。
原型模式可用于创建新对象,但它创建的不是非初始化的对象,而是使用原型对象(或样本对象)的值进行初始化的对象。原型模式也称为属性模式。
原型模式在初始化业务对象时非常有用,业务对象的值与数据库中的默认值相匹配。原型对象中的默认值被复制到新创建的业务对象中。
经典的编程语言很少使用原型模式,但作为原型语言的 JavaScript 在构造新对象及其原型时使用了这个模式。
89、模板引擎原理
板引擎是通过字符串拼接得到的
let template = 'hello <% name %>!'
let template = 'hello ' + name + '!'
12
字符串是通过new Function执行的
let name = 'world'
let template = `
let str = 'hello ' + name + '!'
return str
`
let fn = new Function('name', template)
console.log(fn(name)) // hello world!
1234567
将模板转换为字符串并通过函数执行返回
let template = 'hello <% name %>!'
let name = 'world'
function compile (template) {
let html = template.replace(/<%([\s\S]+?)%>/g, (match, code) => {
return `' + ${code} + '`
})
html = `let str = '${html}'; return str`
return new Function('name', html)
}
let str = compile(template)
console.log(str(name)) // hello world!
1234567891011
函数只能接收一个name变量作为参数,功能太单一了,一般会通过对象来传参,with来减少变量访问。
with功能
let params = {
name: '张三',
age: 18
}
let str = ''
with (params) {
str = `用户${name}的年龄是${age}岁`
}
console.log(str) // 用户张三的年龄是18岁
123456789
实现简单的模板引擎
let template = 'hello <% name %>!'
let name = 'world'
function compile (template) {
let html = template.replace(/<%([\s\S]+?)%>/g, (match, code) => {
return `' + ${code.trim()} + '`
})
html = `'${html}'`
html = `let str = ''; with (params) { str = ${html}; } return str`
return new Function('params', html)
}
let str = compile(template)
console.log(str({ name })) // hello world!
90、 map和foreach的区别
- 都是循环遍历数组中的每一项
- forEach和map方法里每次执行匿名函数都支持3个参数,参数分别是item(当前每一项)、index(索引值)、arr(原数组)
- 匿名函数中的this都是指向window
- 只能遍历数组
array.map(function(item,index,arr){},this)
Array.forEach(function(item,index,arr){},this)
二、区别:
1.forEach()
没有返回值。
2.map()
有返回值,可以return 出来。
var arr = [1,23,3];
arr.map(function(value,index,array){
//do something
return XXX
})
91、es6的新特性
1.不一样的变量声明:const和let
ES6推荐使用let声明局部变量,相比之前的var(无论声明在何处,都会被视为声明在函数的最顶部)
let和var声明的区别:
var x = '全局变量';
{
let x = '局部变量';
console.log(x); // 局部变量
}
console.log(x); // 全局变量
let表示声明变量,而const表示声明常量,两者都为块级作用域;const 声明的变量都会被认为是常量,意思就是它的值被设置完成后就不能再修改了:
const a = 1
a = 0 //报错
如果const的是一个对象,对象所包含的值是可以被修改的。抽象一点儿说,就是对象所指向的地址没有变就行:
const student = { name: 'cc' }
student.name = 'yy';// 不报错
student = { name: 'yy' };// 报错
有几个点需要注意:
- let 关键词声明的变量不具备变量提升(hoisting)特性
- let 和 const 声明只在最靠近的一个块中(花括号内)有效
- 当使用常量 const 声明时,请使用大写变量,如:CAPITAL_CASING
- const 在声明时必须被赋值
2.模板字符串
在ES6之前,我们往往这么处理模板字符串:
通过“\”和“+”来构建模板
$("body").html("This demonstrates the output of HTML \
content to the page, including student's\
" + name + ", " + seatNumber + ", " + sex + " and so on.");
而对ES6来说
- 基本的字符串格式化。将表达式嵌入字符串中进行拼接。用${}来界定;
- ES6反引号(``)直接搞定;
$("body").html(`This demonstrates the output of HTML content to the page,
including student's ${name}, ${seatNumber}, ${sex} and so on.`);
3.箭头函数(Arrow Functions)
ES6 中,箭头函数就是函数的一种简写形式,使用括号包裹参数,跟随一个 =>,紧接着是函数体;
箭头函数最直观的三个特点。
- 不需要 function 关键字来创建函数
- 省略 return 关键字
- 继承当前上下文的 this 关键字
// ES5
var add = function (a, b) {
return a + b;
};
// 使用箭头函数
var add = (a, b) => a + b;
// ES5
[1,2,3].map((function(x){
return x + 1;
}).bind(this));
// 使用箭头函数
[1,2,3].map(x => x + 1);
细节:当你的函数有且仅有一个参数的时候,是可以省略掉括号的。当你函数返回有且仅有一个表达式的时候可以省略{} 和 return;
- 函数的参数默认值
在ES6之前,我们往往这样定义参数的默认值:
// ES6之前,当未传入参数时,text = 'default';
function printText(text) {
text = text || 'default';
console.log(text);
}
// ES6;
function printText(text = 'default') {
console.log(text);
}
printText('hello'); // hello
printText();// default
5.Spread / Rest 操作符
Spread / Rest 操作符指的是 …,具体是 Spread 还是 Rest 需要看上下文语境。
当被用于迭代器中时,它是一个 Spread 操作符:
function foo(x,y,z) {
console.log(x,y,z);
}
let arr = [1,2,3];
foo(...arr); // 1 2 3
当被用于函数传参时,是一个 Rest 操作符:当被用于函数传参时,是一个 Rest 操作符:
function foo(...args) {
console.log(args);
}
foo( 1, 2, 3, 4, 5); // [1, 2, 3, 4, 5]
6.二进制和八进制字面量
ES6 支持二进制和八进制的字面量,通过在数字前面添加 0o 或者0O 即可将其转换为八进制值:
let oValue = 0o10;
console.log(oValue); // 8
let bValue = 0b10; // 二进制使用 `0b` 或者 `0B`
console.log(bValue); // 2
7.对象和数组解构
// 对象
const student = {
name: 'Sam',
age: 22,
sex: '男'
}
// 数组
// const student = ['Sam', 22, '男'];
// ES5;
const name = student.name;
const age = student.age;
const sex = student.sex;
console.log(name + ' --- ' + age + ' --- ' + sex);
// ES6
const { name, age, sex } = student;
console.log(name + ' --- ' + age + ' --- ' + sex);
8.对象超类
ES6 允许在对象中使用 super 方法:
var parent = {
foo() {
console.log("Hello from the Parent");
}
}
var child = {
foo() {
super.foo();
console.log("Hello from the Child");
}
}
Object.setPrototypeOf(child, parent);
child.foo(); // Hello from the Parent
// Hello from the Child
9.for…of 和 for…in
for…of 用于遍历一个迭代器,如数组:
let letters = ['a', 'b', 'c'];
letters.size = 3;
for (let letter of letters) {
console.log(letter);
}
// 结果: a, b, c
for…in 用来遍历对象中的属性:
let stus = ["Sam", "22", "男"];
for (let stu in stus) {
console.log(stus[stu]);
}
// 结果: Sam, 22, 男
10.ES6中的类
ES6 中支持 class 语法,不过,ES6的class不是新的对象继承模型,它只是原型链的语法糖表现形式。
函数中使用 static 关键词定义构造函数的的方法和属性:
class Student {
constructor() {
console.log("I'm a student.");
}
study() {
console.log('study!');
}
static read() {
console.log("Reading Now.");
}
}
console.log(typeof Student); // function
let stu = new Student(); // "I'm a student."
stu.study(); // "study!"
stu.read(); // "Reading Now."
类中的继承和超集:
class Phone {
constructor() {
console.log("I'm a phone.");
}
}
class MI extends Phone {
constructor() {
super();
console.log("I'm a phone designed by xiaomi");
}
}
let mi8 = new MI();
extends 允许一个子类继承父类,需要注意的是,子类的constructor 函数中需要执行 super() 函数。
当然,你也可以在子类方法中调用父类的方法,如super.parentMethodName()。
在 这里 阅读更多关于类的介绍。
有几点值得注意的是:
- 类的声明不会提升(hoisting),如果你要使用某个 Class,那你必须在使用之前定义它,否则会抛出一个 ReferenceError 的错误
- 在类中定义函数不需要使用 function 关键词
92、如何向 Array 对象添加自定义方法,让下面的代码可以运行?
var arr = [1, 2, 3, 4, 5];
var avg = arr.average();
console.log(avg);
JavaScript 不是基于类的,但它是基于原型的语言。这意味着每个对象都链接到另一个对象(也就是对象的原型),并继承原型对象的方法。你可以跟踪每个对象的原型链,直到到达没有原型的 null 对象。我们需要通过修改 Array 原型来向全局 Array 对象添加方法。
Array.prototype.average = function() {
// 计算 sum 的值
var sum = this.reduce(function(prev, cur) { return prev + cur; });
// 将 sum 除以元素个数并返回
return sum / this.length;
}
var arr = [1, 2, 3, 4, 5];
var avg = arr.average();
console.log(avg); // => 3
93、0.1+0.2等不等于0.3?自己封装一个让他们相等的方法
console.log(0.1+0.2===0.3)// true or false??
在正常的数学逻辑思维中,0.1+0.2=0.3这个逻辑是正确的,但是在JavaScript中0.1+0.2!==0.3,这是为什么呢?这个问题也会偶尔被用来当做面试题来考查面试者对JavaScript的数值的理解程度。
在JavaScript中的二进制的浮点数0.1和0.2并不是十分精确,在他们相加的结果并非正好等于0.3,而是一个比较接近的数字 0.30000000000000004 ,所以条件判断结果为false。
那么应该怎样来解决0.1+0.2等于0.3呢? 最好的方法是设置一个误差范围值,通常称为”机器精度“,而对于Javascript来说,这个值通常是2^-52,而在ES6中,已经为我们提供了这样一个
属性:Number.EPSILON,而这个值正等于2^-52。这个值非常非常小,在底层计算机已经帮我们运算好,并且无限接近0,但不等于0,。这个时候我们只要判断(0.1+0.2)-0.3小于
Number.EPSILON,在这个误差的范围内就可以判定0.1+0.2===0.3为true。
function numbersequal(a,b){ return Math.abs(a-b)
94、跨域是什么?有哪些解决跨域的方法和方案?
CORS PROXY JSONP
95、什么是函数式编程?什么的声明式编程?
什么是声明式编程?一般来说我们对于声明式的理解都是相对于命令式(imperative)而言的。图灵教会了我们imperative的真谛,并赋予了它数学意义上的精确定义:一台有状态的机器,根据明确的指令(instruction)一步步的执行。而所谓的声明式,它可以看作是命令式的反面。曾有人言:一切非imperative,皆是declarative。从这个意义上说,越是偏离图灵机的图像越远的,就越是声明式的。
所以,函数式编程(Functional Programming)是声明式的,因为它不使用可变状态,也不需要指定任何的执行顺序关系(可以假定所有的函数都是同时执行的,因为存在引用透明性,所谓的参数和变量都只是一堆符号的别名而已)。逻辑式编程(Logical Programming)也是声明式的,因为我们只需要通过facts和rules描述我们所需要解决的问题,具体的求解路径由编译器和程序运行时自动决定。
96、super() 是否必须执行?不执行怎么让它不报错?
构造函数有什么作用?创建类的对象,只有对象才能调用类的属性和方法。当子类继承父类的属性和方法时,如何去调用父类的构造函数?Super()当父类构造函数是空参数时,系统会默认添加Super(),此时你可以省略。如果父类是非参数时,必须要添加Super(),初始化父类,初始化父类,子类才能调用父类属性和方法。这就是Super()的作用。
97、什么是 JavaScript 中的提升操作?
提升(hoisting)是 JavaScript 解释器将所有变量和函数声明移动到当前作用域顶部的操作。有两种类型的提升:
- 变量提升——非常少见
- 函数提升——常见
无论 var(或函数声明)出现在作用域的什么地方,它都属于整个作用域,并且可以在该作用域内的任何地方访问它。
var a = 2;
foo(); // 因为`foo()`声明被"提升",所以可调用
function foo() {
a = 3;
console.log( a ); // 3
var a; // 声明被"提升"到 foo() 的顶部
}
console.log( a ); // 2
98、 以下代码输出的结果是什么?
0.1 + 0.2 === 0.3
这段代码的输出是 false,这是由浮点数内部表示导致的。0.1 + 0.2 并不刚好等于 0.3,实际结果是 0.30000000000000004。解决这个问题的一个办法是在对小数进行算术运算时对结果进行舍入。
99、图片懒加载怎么实现
一、什么是懒加载
将图片src先赋值为一张默认图片,当用户滚动滚动条到可视区域图片的时候,再去加载后续真正的图片
如果用户只对第一张图片感兴趣,那剩余的图片请求就可以节省了
二、为什么要引入懒加载
懒加载(LazyLoad)是前端优化的一种有效方式,极大的提升用户体验。图片一直是页面加载的流浪大户,现在一张图片几兆已经是很正常的事,远远大于代码的大小。倘若一次ajax请求10张图片的地址,一次性把10张图片都加载出来,肯定是不合理的。
三、懒加载实现的原理
先将img标签中的src链接设置为空,将真正的图片链接放在自定义属性(data-src),当js监听到图片元素进入到可视窗口的时候,将自定义属性中的地址存储到src中,达到懒加载的效果。
四、懒加载中涉及的属性
1 、document.documentElement.clientHeight; //表示浏览器可见区域高度:
document.body.clientHeight //是整个页面内容的高度,而非浏览器可见区域的高度
2 、document.documentElement.scrollTop; //滚动条 已滚动的高度:
chrome 中 document.body.scrollTop //滚动条 滚过的高度
那么要得到滚动条的高度:有一个技巧:
var scrollTop=document.body.scrollTop || document.documentElement.scrollTop;
这两个值总会有一个恒为0,所以不用担心会对真正的scrollTop造成影响。一点小技巧,但很实用。
3、 offsetTop、offsetLeft
obj.offsetTop 指 obj 距离上方或上层控件的位置,整型,单位像素。
obj.offsetLeft 指 obj 距离左方或上层控件的位置,整型,单位像素。
obj.offsetWidth 指 obj 控件自身的宽度,整型,单位像素。
obj.offsetHeight 指 obj 控件自身的高度,整型,单位像素。
offsetParent 不同于parentNode ,offsetParent 返回的是在结构层次中与这个元素最近的position为absolute\relative\static的元素或者body
具体滚动时涉及的属性值,请参考https://blog.csdn.net/zh_rey/article/details/78967174非常详细
五、懒加载的实现
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JhFjc7Hh-1649150971273)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
Lazyload 2

100、for-in 循环会遍历出原型上的属性吗?
1.使用 for in 循环遍历对象的属性时,原型链上的所有属性都将被访问:
Object.prototype.say="cgl"; // 修改Object.prototype
var person ={ age: 18 };
for (var key in person) {
console.log(key, person[key]);//这里用person.key得不到对象key的值,用person[key] 或者 eval("person."+key);
} //结果: age 18
say cgl
123456
2.只遍历对象自身的属性,而不遍历继承于原型链上的属性,使用hasOwnProperty 方法过滤一下。
Object.prototype.say="cgl";
var person ={
age: 18
};
for (var key in person) {
if(person.hasOwnProperty(key)){
console.log(key, eval("person."+key));
}
}
123456789
二.Object.keys()
Object.keys() 方法会返回一个由给定对象的自身可枚举属性组成的数组,数组中属性名的排列顺序和使用 for…in 循环遍历该对象时返回的顺序一致 (两者的主要区别是 一个 for-in 循环还会枚举其原型链上的属性)。返回值是这个对象的所有可枚举属性组成的字符串数组。
Object.prototype.say="cgl";
var person ={ age: 18};
console.log(Object.keys(person));//结果 ["age"]
123
小技巧:object对象没有length属性,可以通过Object.keys(person).length,来获取person的长度了。
101、url从输入到渲染页面的全过程
从输入URL到页面加载的主干流程如下:
1、浏览器构建HTTP Request请求
2、网络传输
3、服务器构建HTTP Response 响应
4、网络传输
5、浏览器渲染页面
102、http状态码有哪些
200 OK
请求正常处理完毕
204 No Content
请求成功处理,没有实体的主体返回
301 Moved Permanently
永久重定向,资源已永久分配新URI
302 Found
临时重定向,资源已临时分配新URI
400 Bad Request
请求报文语法错误或参数错误
401 Unauthorized
要通过HTTP认证,或认证失败
403 Forbidden
请求资源被拒绝
404 Not Found
无法找到请求资源(服务器无理由拒绝)
500 Internal Server Error
服务器故障或Web应用故障
503 Service Unavailable
服务器超负载或停机维护
状态码如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-60eP9ZwV-1649150971274)(https://img2018.cnblogs.com/common/1419718/202001/1419718-20200101202120407-643788690.png)]
103、call apply bind call和apply哪个性能更好
call和apply都是function原型上的方法,而每一个函数作为function这个类上的实例可以调取原型上的call和apply,都是用来改变函数中this指向的,
区别:
call:传参是一个一个传给函数
apply:把所有要传的参数以数组的形式保存起来
fn.call(obj,10,20,30)
fn.apply(obj,[10,20,30])
注意:
bind也是用来改变函数中this指向,bind没有把函数立即执行,只是预先处理改变this
call的性能要比apply好一些,尤其是传递给函数的参数超过3个时所以后期开发的时候,可以使用call多一些
(传参数3个以内的话,call和apply性能差不多,超过3个以上call更好一些)
104、ES6箭头函数和普通函数有什么差异
面试中少不了面试官问箭头函数的 this 有何特殊。我们知道虽然 babel 转义后是在外层定义 _this 指向了外层的 this ,然后在传给内层的函数来解决这个事情的
function index() {
let func = () => { console.log(this) }
}
// 根据 babel 官网 https://babel.docschina.org/repl 在线转译成
"use strict";
function index() {
var _this = this;
var func = function func() {
console.log(_this);
};
}
但原生的 ES6 的箭头函数可不是这样。且看 MDN 的描述:
箭头函数表达式的语法比函数表达式更简洁,并且没有自己的this,arguments,super或new.target。箭头函数表达式更适用于那些本来需要匿名函数的地方,并且它不能用作构造函数。
总结一下,箭头函数有坑。它并没有 this,就只是在函数执行时,取外部的作用域的 this
然后注意以下陷阱:箭头函数能 new 吗?若是被 babel 转译成了普通函数,new 调用却是没问题;但原生的不能,因为它没有 prototype 属性,new 操作符总需要作用 prototype 的,所以它不能用作构造函数。
var Foo = () => {};
var foo = new Foo(); // TypeError: Foo is not a constructor
箭头函数没有 prototype 属性
var Foo = () => {};
console.log(Foo.prototype); // undefined
箭头函数没有 argument
var func = () => { console.log(arguments) }
func(1) // Uncaught ReferenceError: arguments is not defined
// 多数情况可以使用剩余参数改写
var func = (...args) => { console.log(args) }
func(1) // [1]
105、说说写JavaScript的基本规范?
- 不要在同一行声明多个变量
- 使用 ===或!==来比较true/false或者数值
- switch必须带有default分支
- 函数应该有返回值
- for if else 必须使用大括号
- 语句结束加分号
- 命名要有意义,使用驼峰命名法
106、jQuery使用建议
- 尽量减少对dom元素的访问和操作
- 尽量避免给dom元素绑定多个相同类型的事件处理函数,可以将多个相同类型事件
处理函数合并到一个处理函数,通过数据状态来处理分支
- 尽量避免使用toggle事件
107、Ajax使用
全称 : Asynchronous Javascript And XML
所谓异步,就是向服务器发送请求的时候,我们不必等待结果,而是可以同时做其他的事情,等到有了结果它自己会根据设定进行后续操作,与此同时,页面是不会发生整页刷新的,提高了用户体验。
创建Ajax的过程:
- 创建XMLHttpRequest对象(异步调用对象)
var xhr = new XMLHttpRequest();
- 创建新的Http请求(方法、URL、是否异步)
xhr.open(‘get’,’example.php’,false);
- 设置响应HTTP请求状态变化的函数。
onreadystatechange事件中readyState属性等于4。响应的HTTP状态为200(OK)或者304(Not Modified)。
- 发送http请求
xhr.send(data);
- 获取异步调用返回的数据
注意:
- 页面初次加载时,尽量在web服务器一次性输出所有相关的数据,只在页面加载完成之后,用户进行操作时采用ajax进行交互。
- 同步ajax在IE上会产生页面假死的问题。所以建议采用异步ajax。
- 尽量减少ajax请求次数
- ajax安全问题,对于敏感数据在服务器端处理,避免在客户端处理过滤。对于关键业务逻辑代码也必须放在服务器端处理。
108、tcp三次握手,四次挥手,可靠传输原理(二面三面都问了)
CP建立连接为什么是三次握手,而不是两次或四次?
TCP,名为传输控制协议,是一种可靠的传输层协议,IP协议号为6。
顺便说一句,原则上任何数据传输都无法确保绝对可靠,三次握手只是确保可靠的基本需要。
举个日常例子,打电话时我们对话如下:
对应为客户端与服务器之间的通信:
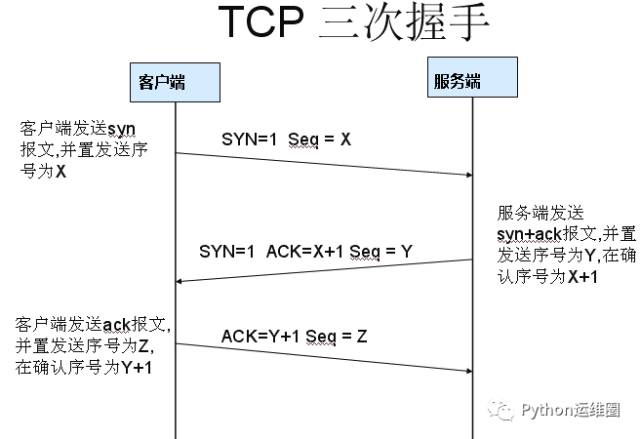
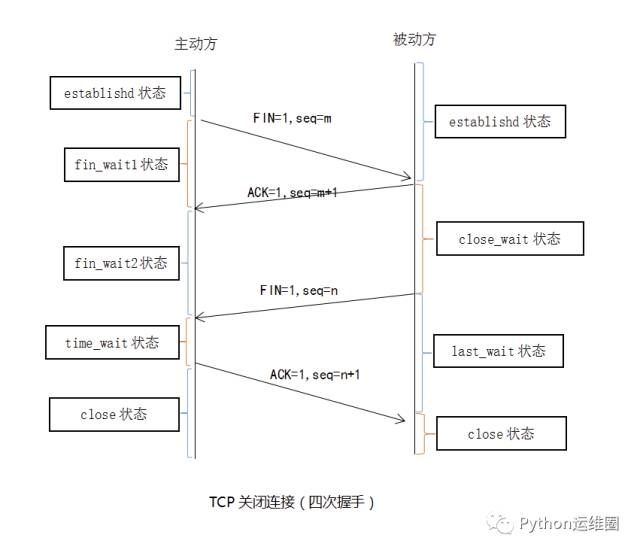
于是有了如下对话:
我:1+1等于几?
她:2,2+2等于几?
我:4
首先两个人约定协议
1.感觉网络情况不对的时候,任何一方都可以发起询问
2.任何情况下,若发起询问后5秒还没收到回复,则认为网络不通
3.网络不通的情况下等1min路由器之后再发起询问
对于我而言,发起 “1+1等于几”的询问后
\1. 若5s内没有收到回复,则认为网络不通
\2. 若收到回复,则我确认①我能听到她的消息 ②她能听到我的消息,然后回复她的问题的答案
对于她而言,当感觉网络情况不对的时候
\1. 若没有收到我的询问,则她发起询问
\2. 若收到“1+1等于几”,则她确认 ①她可以听到我的消息,然后回复我的问题的答案和她的问题“2,2+2等于几”
\3. 若5s内没有收到我的回复“4”,则她确认 ②我听不见她的消息
\4. 若5s内收到了我的回复“4”,则她确认 ②我可以听见她的消息
这样,如果上面的对话得以完成,就证明双方都可以确认自己可以听到对方的声音,对方也可以听到自己的声音!
这个故事可以解释TCP为什么要三次握手吗 … 囧
关于四次挥手
先由客户端向服务器端发送一个FIN,请求关闭数据传输。
当服务器接收到客户端的FIN时,向客户端发送一个ACK,其中ack的值等于FIN+SEQ
然后服务器向客户端发送一个FIN,告诉客户端应用程序关闭。
当客户端收到服务器端的FIN是,回复一个ACK给服务器端。其中ack的值等于FIN+SEQ
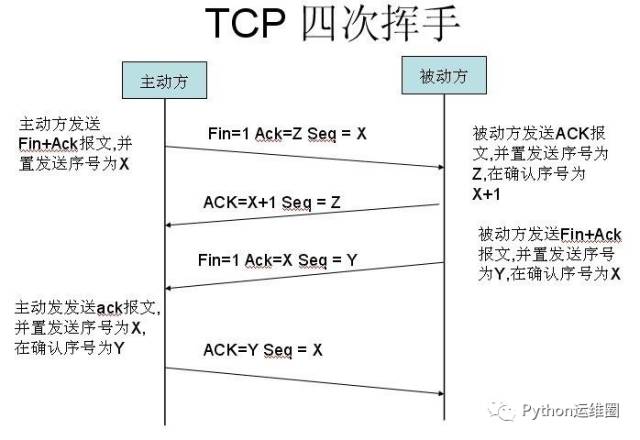
为什么要4次挥手?
确保数据能够完整传输。
当被动方收到主动方的FIN报文通知时,它仅仅表示主动方没有数据再发送给被动方了。
但未必被动方所有的数据都完整的发送给了主动方,所以被动方不会马上关闭SOCKET,它可能还需要发送一些数据给主动方后,
再发送FIN报文给主动方,告诉主动方同意关闭连接,所以这里的ACK报文和FIN报文多数情况下都是分开发送的。
一、TCP报文格式
TCP报文格式图:
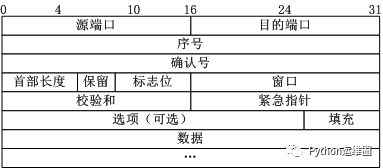
上图中有几个字段需要重点介绍下:
(1)序号:Seq序号,占32位,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记。
(2)确认序号:Ack序号,占32位,只有ACK标志位为1时,确认序号字段才有效,Ack=Seq+1。
(3)标志位:共6个,即URG、ACK、PSH、RST、SYN、FIN等,具体含义如下:
(A)URG:紧急指针(urgent pointer)有效。
(B)ACK:确认序号有效。
(C)PSH:接收方应该尽快将这个报文交给应用层。
(D)RST:重置连接。
(E)SYN:发起一个新连接。
(F)FIN:释放一个连接。
需要注意的是:
(A)不要将确认序号Ack与标志位中的ACK搞混了。
(B)确认方Ack=发起方Req+1,两端配对。
二、三次握手
TCP(Transmission Control Protocol) 传输控制协议
TCP是主机对主机层的传输控制协议,提供可靠的连接服务,采用三次握手确认建立一个连接
位码即tcp标志位,有6种标示:
SYN(synchronous建立联机)
ACK(acknowledgement 确认)
PSH(push传送)
FIN(finish结束)
RST(reset重置)
URG(urgent紧急)
Sequence number(顺序号码)
Acknowledge number(确认号码)
establish 建立,创建
所谓三次握手(Three-Way Handshake)即建立TCP连接,是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。在socket编程中,这一过程由客户端执行connect来触发,整个流程如下图所示:
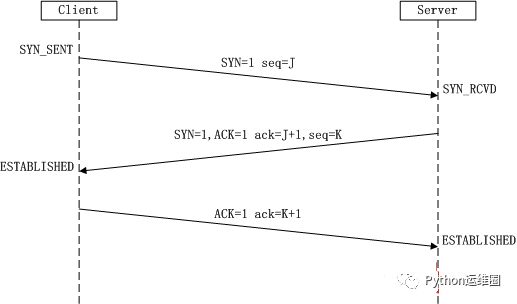
(1)第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
(2)第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack (number )=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
(3)第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。

SYN攻击:
在三次握手过程中,Server发送SYN-ACK之后,收到Client的ACK之前的TCP连接称为半连接(half-open connect),此时Server处于SYN_RCVD状态,当收到ACK后,Server转入ESTABLISHED状态。
SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server回复确认包,并等待Client的确认,由于源地址是不存在的,因此,Server需要不断重发直至超时,这些伪造的SYN包将长时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络堵塞甚至系统瘫痪。
SYN攻击时一种典型的DDOS攻击,检测SYN攻击的方式非常简单,即当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,使用如下命令可以让之现行:
#netstat -nap | grep SYN_RECV
三、四次挥手
三次握手耳熟能详,四次挥手估计就…所谓四次挥手(Four-Way Wavehand)即终止TCP连接,就是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。在socket编程中,这一过程由客户端或服务端任一方执行close来触发,整个流程如下图所示:
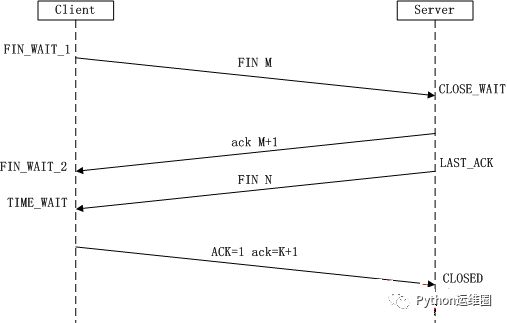
由于TCP连接时全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN。首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭,上图描述的即是如此。
(1)第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
(2)第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
(3)第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
(4)第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。

上面是一方主动关闭,另一方被动关闭的情况,实际中还会出现同时发起主动关闭的情况,具体流程如下图:
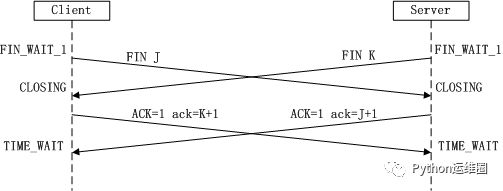
流程和状态在上图中已经很明了了,在此不再赘述,可以参考前面的四次挥手解析步骤。
四、附注
关于三次握手与四次挥手通常都会有典型的面试题,在此提出供有需求的XDJM们参考:
(1)三次握手是什么或者流程?四次握手呢?答案前面分析就是。
(2)为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
这是因为**服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。**而关闭连接时,当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方也未必全部数据都发送给对方了,所以己方可以立即close,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送。(来自Champin)
109、进程线程区别
1、功能不同
进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资bai源分配和调度的基本单位,是操作系统结构的基础。
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
2、工作原理不同
在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
线程是独立调度和分派的基本单位。线程可以为操作系统内核调度的内核线程,如Win32线程;由用户进程自行调度的用户线程,如Linux平台的POSIX Thread;或者由内核与用户进程,如Windows 7的线程,进行混合调度。
3、作用不同
进程是操作系统中最基本、重要的概念。是多道程序系统出现后,为了刻画系统内部出现的动态情况,描述系统内部各道程序的活动规律引进的一个概念,所有多道程序设计操作系统都建立在进程的基础上。
通常在一个进程中可以包含若干个线程,它们可以利用进程所拥有的资源。在引入线程的操作系统中,通常都是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位。
110、禁止事件冒泡,禁止默认事件
1.event.stopPropagation()方法 这是阻止事件的冒泡方法,不让事件向documen上蔓延,但是默认事件任然会执行,当你掉用这个方法的时候,如果点击一个…
2.event.preventDefault()方法 这是阻止默认事件的方法,调用此方法是…
3.return false ; 这个方法比较暴力,他会同事阻止事件冒泡也会阻止默认事件
111、import export commonJs对比区别
一、标准不同
CommonJS 中的 require/exports 和比ES6 中的 import/export出现得早,node.js是他的实现;CommonJS 中的 require/exports 是老的标准,ES6 中的 import/export要比它更加权威。es6通过babel转化为es5执行,所以写的import/export是通过babel转换为require/exports执行的。二者其实都可以看做是输出一个对象和引入一个对象并使用其中的属性或方法。
二、书写格式不同
- require的调用时间为运行时调用,所以require可以出现在文件的任何地方。动态加载
- import是编译时调用,所以必须放在文件头部。静态加载
- export default导出的东西只能用import导入。
- module.exports和exports的东西可以以任何一种方式导入。
这个太简单了,不作鳌述。后面补上
三、加载机制不同
112、为什么javascript是单线程
单线程:同一个时间只能做一件事
JavaScript的单线程,与他的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这就决定了他只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
为了利用多核CPU的计算能力,HTML5提出Web Worker 标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
JavaScript为什么需要异步
如果JS中不存在异步,只能自上而下执行,如果上一行解析时间很长,那么下面的代码就会被阻塞。对于用户而言,阻塞就意味着"卡死",这样就导致了很差的用户体验。
单线程如何实现异步
通过事件循环(Event loop)来实现的。
113、使用箭头函数应该注意什么
箭头函数有几个使用注意点。
(1)函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象。
(2)不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误。
(3)不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用Rest参数代替。
(4)不可以使用yield命令,因此箭头函数不能用作Generator函数。
114、hash chunkhash contenthash三者区别
一、hash(所有文件哈希值相同,只要改变内容跟之前的不一致,所有哈希值都改变,没有做到缓存意义)
hash是跟整个项目的构建相关,构建生成的文件hash值都是一样的,所以hash计算是跟整个项目的构建相关,同一次构建过程中生成的hash都是一样的,只要项目里有文件更改,整个项目构建的hash值都会更改。
如果出口是hash,那么一旦针对项目中任何一个文件的修改,都会构建整个项目,重新获取hash值,缓存的目的将失效。
二、chunkhash(同一个模块,就算将js和css分离,其哈希值也是相同的,修改一处,js和css哈希值都会变,同hash,没有做到缓存意义)
它根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的hash值。我们在生产环境里把一些公共库和程序入口文件区分开,单独打包构建,接着我们采用chunkhash的方式生成hash值,那么只要我们不改动公共库的代码,就可以保证其hash值不会受影响。
由于采用chunkhash,所以项目主入口文件main.js及其对应的依赖文件main.css由于被打包在同一个模块,所以共用相同的chunkhash。
这样就会有个问题,只要对应css或则js改变,与其关联的文件hash值也会改变,但其内容并没有改变,所以没有达到缓存意义。
三、contenthash(只要文件内容不一样,产生的哈希值就不一样)
contenthash表示由文件内容产生的hash值,内容不同产生的contenthash值也不一样。在项目中,通常做法是把项目中css都抽离出对应的css文件来加以引用。
所以css文件最好使用contenthash。
115、栈和堆的区别?
栈(stack):由编译器自动分配释放,存放函数的参数值,局部变量等;
堆(heap):一般由程序员分配释放,若程序员不释放,程序结束时可能由操作系统释放。
116、Javascript实现继承的几种方式
工厂方法
function creatPerson(name, age) {
var obj = new Object();
obj.name = name;
obj.age = age;
obj.sayName = function() {
window.alert(this.name);
};
return obj;
}
构造函数方法
function Person(name, age) {
this.name = name;
this.age = age;
this.sayName = function() {
window.alert(this.name);
};
}
原型方法
function Person() {
}
Person.prototype = {
constructor : Person,
name : "Ning",
age : "23",
sayName : function() {
window.alert(this.name);
}
};
大家可以看到这种方法有缺陷,类里属性的值都是在原型里给定的。
组合使用构造函数和原型方法(使用最广)
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype = {
constructor : Person,
sayName : function() {
window.alert(this.name);
}
};
将构造函数方法和原型方法结合使用是目前最常用的定义类的方法。这种方法的好处是实现了属性定义和方法定义的分离。比如我可以创建两个对象person1和person2,它们分别传入各自的name值和age值,但sayName()方法可以同时使用原型里定义的。
JavaScript实现继承的3种方法
借用构造函数法(又叫经典继承)
function SuperType(name) {
this.name = name;
this.sayName = function() {
window.alert(this.name);
};
}
function SubType(name, age) {
SuperType.call(this, name); //在这里借用了父类的构造函数
this.age = age;
}
对象冒充
function SuperType(name) {
this.name = name;
this.sayName = function() {
window.alert(this.name);
};
}
function SubType(name, age) {
this.supertype = SuperType; //在这里使用了对象冒充
this.supertype(name);
this.age = age;
}
组合继承(最常用)
function SuperType(name) {
this.name = name;
}
SuperType.prototype = {
sayName : function() {
window.alert(this.name);
}
};
function SubType(name, age) {
SuperType.call(this, name); //在这里继承属性
this.age = age;
}
SubType.prototype = new SuperType(); //这里继承方法
组合继承的方法是对应着我们用‘组合使用构造函数和原型方法’定义父类的一种继承方法。同样的,我们的属性和方法是分开继承的。
117、谈谈this的理解
- this总是指向函数的直接调用者(而非间接调用者)
- 如果有new关键字,this指向new出来的那个对象
- 在事件中,this指向目标元素,特殊的是IE的attachEvent中的this总是指向全局对象window。
118、map fillter reduce 各自有什么作用
map 作用是生成一个新数组,遍历原数组,将每个元素拿出来做一些变换然后放入到新的数组中。
[1, 2, 3].map(v => v + 1) // -> [2, 3, 4]
另外 map 的回调函数接受三个参数,分别是当前索引元素,索引,原数组
['1','2','3'].map(parseInt)
- 第一轮遍历
parseInt('1', 0) -> 1
第二轮遍历 parseInt('2', 1) -> NaN
- 第三轮遍历
parseInt('3', 2) -> NaN
filter 的作用也是生成一个新数组,在遍历数组的时候将返回值为 true 的元素放入新数组,我们可以利用这个函数删除一些不需要的元素
let array = [1, 2, 4, 6]
let newArray = array.filter(item => item !== 6)
console.log(newArray) // [1, 2, 4]
和 map 一样,filter 的回调函数也接受三个参数,用处也相同。
最后我们来讲解 reduce 这块的内容,同时也是最难理解的一块内容。reduce 可以将数组中的元素通过回调函数最终转换为一个值。
如果我们想实现一个功能将函数里的元素全部相加得到一个值,可能会这样写代码
const arr = [1, 2, 3]
let total = 0
for (let i = 0; i < arr.length; i++) {
total += arr[i]
}
console.log(total) //6
但是如果我们使用 reduce 的话就可以将遍历部分的代码优化为一行代码
const arr = [1,2,3]
const sum = arr.reduce((acc,current)=>acc + current,0)
console.log(sum)
对于 reduce 来说,它接受两个参数,分别是回调函数和初始值,接下来我们来分解上述代码中 reduce 的过程
- 首先初始值为
0,该值会在执行第一次回调函数时作为第一个参数传入
- 回调函数接受四个参数,分别为累计值、当前元素、当前索引、原数组,后三者想必大家都可以明白作用,这里着重分析第一个参数
- 在一次执行回调函数时,当前值和初始值相加得出结果
1,该结果会在第二次执行回调函数时当做第一个参数传入
所以在第二次执行回调函数时,相加的值就分别是 1 和 2,以此类推,循环结束后得到结果 6
想必通过以上的解析大家应该明白 reduce 是如何通过回调函数将所有元素最终转换为一个值的,当然 reduce 还可以实现很多功能,接下来我们就通过 reduce 来实现 map 函数
const arr = [1, 2, 3]
const mapArray = arr.map(value => value * 2)
const reduceArray = arr.reduce((acc, current) => {
acc.push(current * 2)
return acc
}, [])
console.log(mapArray, reduceArray) // [2, 4, 6]
119、JS的基本数据类型判断有什么方法
1、typeof
typeof 是一个操作符,其右侧跟一个一元表达式,并返回这个表达式的数据类型。返回的结果用该类型的字符串(全小写字母)形式表示,包括以下 7 种:number、boolean、symbol、string、object、undefined、function 等。
typeof``''``;``// string 有效``typeof``1;``// number 有效``typeof``Symbol();``// symbol 有效``typeof``true``;``//boolean 有效``typeof``undefined;``//undefined 有效``typeof``null``;``//object 无效``typeof``[] ;``//object 无效``typeof``new``Function();``// function 有效``typeof``new``Date();``//object 无效``typeof``new``RegExp();``//object 无效
有些时候,typeof 操作符会返回一些令人迷惑但技术上却正确的值:
- 对于基本类型,除 null 以外,均可以返回正确的结果。
- 对于引用类型,除 function 以外,一律返回 object 类型。
- 对于 null ,返回 object 类型。
- 对于 function 返回 function 类型。
其中,null 有属于自己的数据类型 Null , 引用类型中的 数组、日期、正则 也都有属于自己的具体类型,而 typeof 对于这些类型的处理,只返回了处于其原型链最顶端的 Object 类型,没有错,但不是我们想要的结果。
2、instanceof
instanceof 是用来判断 A 是否为 B 的实例,表达式为:A instanceof B,如果 A 是 B 的实例,则返回 true,否则返回 false。 在这里需要特别注意的是:instanceof 检测的是原型,我们用一段伪代码来模拟其内部执行过程:
instanceof (A,B) = {`` ``var``L = A.__proto__;`` ``var``R = B.prototype;`` ``if``(L === R) {`` ``// A的内部属性 __proto__ 指向 B 的原型对象`` ``return``true``;`` ``}`` ``return``false``;``}
从上述过程可以看出,当 A 的 proto 指向 B 的 prototype 时,就认为 A 就是 B 的实例,我们再来看几个例子:
[] instanceof Array;``// true``{} instanceof Object;``// true``new``Date() instanceof Date;``// true` `function Person(){};``new``Person() instanceof Person;` `[] instanceof Object;``// true``new``Date() instanceof Object;``// true``new``Person instanceof Object;``// true
我们发现,虽然 instanceof 能够判断出 [ ] 是Array的实例,但它认为 [ ] 也是Object的实例,为什么呢?
我们来分析一下 [ ]、Array、Object 三者之间的关系:
从 instanceof 能够判断出 [ ].proto 指向 Array.prototype,而 Array.prototype.proto 又指向了Object.prototype,最终 Object.prototype.proto 指向了null,标志着原型链的结束。因此,[]、Array、Object 就在内部形成了一条原型链:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UAYZZntQ-1649150971274)(https://images2015.cnblogs.com/blog/849589/201601/849589-20160112232510850-2003340583.png)]
从原型链可以看出,[] 的 proto 直接指向Array.prototype,间接指向 Object.prototype,所以按照 instanceof 的判断规则,[] 就是Object的实例。依次类推,类似的 new Date()、new Person() 也会形成一条对应的原型链 。因此,instanceof 只能用来判断两个对象是否属于实例关系**, 而不能判断一个对象实例具体属于哪种类型。**
instanceof 操作符的问题在于,它假定只有一个全局执行环境。如果网页中包含多个框架,那实际上就存在两个以上不同的全局执行环境,从而存在两个以上不同版本的构造函数。如果你从一个框架向另一个框架传入一个数组,那么传入的数组与在第二个框架中原生创建的数组分别具有各自不同的构造函数。
var``iframe = document.createElement(``'iframe'``);``document.body.appendChild(iframe);``xArray = window.frames[0].Array;``var``arr =``new``xArray(1,2,3);``// [1,2,3]``arr instanceof Array;``// false
针对数组的这个问题,ES5 提供了 Array.isArray() 方法 。该方法用以确认某个对象本身是否为 Array 类型,而不区分该对象在哪个环境中创建。
if``(Array.isArray(value)){`` ``//对数组执行某些操作``}
Array.isArray() 本质上检测的是对象的 [[Class]] 值,[[Class]] 是对象的一个内部属性,里面包含了对象的类型信息,其格式为 [object Xxx] ,Xxx 就是对应的具体类型 。对于数组而言,[[Class]] 的值就是 [object Array] 。
3、constructor
当一个函数 F被定义时,JS引擎会为F添加 prototype 原型,然后再在 prototype上添加一个 constructor 属性,并让其指向 F 的引用。如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-foUJehC1-1649150971275)(https://images2015.cnblogs.com/blog/849589/201705/849589-20170508125250566-1896556617.png)]
当执行 var f = new F() 时,F 被当成了构造函数,f 是F的实例对象,此时 F 原型上的 constructor 传递到了 f 上,因此 f.constructor == F
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uFxDBnZG-1649150971275)(https://images2015.cnblogs.com/blog/849589/201705/849589-20170508125714941-1649387639.png)]
可以看出,F 利用原型对象上的 constructor 引用了自身,当 F 作为构造函数来创建对象时,原型上的 constructor 就被遗传到了新创建的对象上, 从原型链角度讲,构造函数 F 就是新对象的类型。这样做的意义是,让新对象在诞生以后,就具有可追溯的数据类型。
同样,JavaScript 中的内置对象在内部构建时也是这样做的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7seDyi8J-1649150971275)(https://images2015.cnblogs.com/blog/849589/201705/849589-20170508131800457-2091987664.png)]
细节问题:
\1. null 和 undefined 是无效的对象,因此是不会有 constructor 存在的,这两种类型的数据需要通过其他方式来判断。
\2. 函数的 constructor 是不稳定的,这个主要体现在自定义对象上,当开发者重写 prototype 后,原有的 constructor 引用会丢失,constructor 会默认为 Object
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9JRRA4wI-1649150971275)(https://images2015.cnblogs.com/blog/849589/201705/849589-20170508132757347-1999338357.png)]
为什么变成了 Object?
因为 prototype 被重新赋值的是一个 { }, { } 是 new Object() 的字面量,因此 new Object() 会将 Object 原型上的 constructor 传递给 { },也就是 Object 本身。
因此,为了规范开发,在重写对象原型时一般都需要重新给 constructor 赋值,以保证对象实例的类型不被篡改。
4、toString
toString() 是 Object 的原型方法,调用该方法,默认返回当前对象的 [[Class]] 。这是一个内部属性,其格式为 [object Xxx] ,其中 Xxx 就是对象的类型。
对于 Object 对象,直接调用 toString() 就能返回 [object Object] 。而对于其他对象,则需要通过 call / apply 来调用才能返回正确的类型信息。
Object.prototype.toString.call(``''``) ; ``// [object String]``Object.prototype.toString.call(1) ; ``// [object Number]``Object.prototype.toString.call(``true``) ;``// [object Boolean]``Object.prototype.toString.call(Symbol());``//[object Symbol]``Object.prototype.toString.call(undefined) ;``// [object Undefined]``Object.prototype.toString.call(``null``) ;``// [object Null]``Object.prototype.toString.call(``new``Function()) ;``// [object Function]``Object.prototype.toString.call(``new``Date()) ;``// [object Date]``Object.prototype.toString.call([]) ;``// [object Array]``Object.prototype.toString.call(``new``RegExp()) ;``// [object RegExp]``Object.prototype.toString.call(``new``Error()) ;``// [object Error]``Object.prototype.toString.call(document) ;``// [object HTMLDocument]``Object.prototype.toString.call(window) ;``//[object global] window 是全局对象 global 的引用
120、 eval是做什么的?
它的功能是把对应的字符串解析成JS代码并运行;应该避免使用eval,不安全,非常耗性能(2次,一次解析成js语句,一次执行)。
121、什么是window对象? 什么是document对象?
window对象代表浏览器中打开的一个窗口。document对象代表整个html文档。实际上,document对象是window对象的一个属性。
122、null,undefined的区别?
null表示一个对象被定义了,但存放了空指针,转换为数值时为0。
undefined表示声明的变量未初始化,转换为数值时为NAN。
typeof(null) – object;
typeof(undefined) – undefined
123、[“1”, “2”, “3”].map(parseInt) 答案是多少?
[1,NaN,NaN]
解析:
Array.prototype.map()
array.map(callback[, thisArg])
callback函数的执行规则
参数:自动传入三个参数
currentValue(当前被传递的元素);
index(当前被传递的元素的索引);
array(调用map方法的数组)
parseInt方法接收两个参数
第三个参数[“1”, “2”, “3”]将被忽略。parseInt方法将会通过以下方式被调用
parseInt(“1”, 0)
parseInt(“2”, 1)
parseInt(“3”, 2)
parseInt的第二个参数radix为0时,ECMAScript5将string作为十进制数字的字符串解析;
parseInt的第二个参数radix为1时,解析结果为NaN;
parseInt的第二个参数radix在2—36之间时,如果string参数的第一个字符(除空白以外),不属于radix指定进制下的字符,解析结果为NaN。
parseInt(“3”, 2)执行时,由于"3"不属于二进制字符,解析结果为NaN。
124、new的 原理是什么?
- 创建一个空对象,构造函数中的this指向这个空对象
- 这个新对象被执行 [[原型]] 连接
- 执行构造函数方法,属性和方法被添加到this引用的对象中
- 如果构造函数中没有返回其它对象,那么返回this,即创建的这个的新对象,否则,返回构造函数中返回的对象。
125、数组去重的方法
一、简单的去重方法
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yDaSG8W3-1649150971275)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
// 最简单数组去重法
/*
* 新建一新数组,遍历传入数组,值不在新数组就push进该新数组中
* IE8以下不支持数组的indexOf方法
* */
function uniq(array){
var temp = []; //一个新的临时数组
for(var i = 0; i < array.length; i++){
if(temp.indexOf(array[i]) == -1){
temp.push(array[i]);
}
}
return temp;
}
var aa = [1,2,2,4,9,6,7,5,2,3,5,6,5];
console.log(uniq(aa));
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tC03aOEt-1649150971276)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
二、对象键值法去重
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hlKLeP1v-1649150971276)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
/*
* 速度最快, 占空间最多(空间换时间)
*
* 该方法执行的速度比其他任何方法都快, 就是占用的内存大一些。
* 现思路:新建一js对象以及新数组,遍历传入数组时,判断值是否为js对象的键,
* 不是的话给对象新增该键并放入新数组。
* 注意点:判断是否为js对象键时,会自动对传入的键执行“toString()”,
* 不同的键可能会被误认为一样,例如n[val]-- n[1]、n["1"];
* 解决上述问题还是得调用“indexOf”。*/
function uniq(array){
var temp = {}, r = [], len = array.length, val, type;
for (var i = 0; i < len; i++) {
val = array[i];
type = typeof val;
if (!temp[val]) {
temp[val] = [type];
r.push(val);
} else if (temp[val].indexOf(type) < 0) {
temp[val].push(type);
r.push(val);
}
}
return r;
}
var aa = [1,2,"2",4,9,"a","a",2,3,5,6,5];
console.log(uniq(aa));
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FS0jvbX5-1649150971276)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
三、排序后相邻去除法
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lh4j7Grt-1649150971276)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
/*
* 给传入数组排序,排序后相同值相邻,
* 然后遍历时,新数组只加入不与前一值重复的值。
* 会打乱原来数组的顺序
* */
function uniq(array){
array.sort();
var temp=[array[0]];
for(var i = 1; i < array.length; i++){
if( array[i] !== temp[temp.length-1]){
temp.push(array[i]);
}
}
return temp;
}
var aa = [1,2,"2",4,9,"a","a",2,3,5,6,5];
console.log(uniq(aa));
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-09V8eM8i-1649150971276)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
四、数组下标法
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kYTXcbS1-1649150971277)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
/*
*
* 还是得调用“indexOf”性能跟方法1差不多,
* 实现思路:如果当前数组的第i项在当前数组中第一次出现的位置不是i,
* 那么表示第i项是重复的,忽略掉。否则存入结果数组。
* */
function uniq(array){
var temp = [];
for(var i = 0; i < array.length; i++) {
//如果当前数组的第i项在当前数组中第一次出现的位置是i,才存入数组;否则代表是重复的
if(array.indexOf(array[i]) == i){
temp.push(array[i])
}
}
return temp;
}
var aa = [1,2,"2",4,9,"a","a",2,3,5,6,5];
console.log(uniq(aa));
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V7fXzNx2-1649150971277)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
五、优化遍历数组法
[[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RNRD49OE-1649150971277)(https://common.cnblogs.com/images/copycode.gif)]](javascript:void(0)
// 思路:获取没重复的最右一值放入新数组
/*
* 推荐的方法
*
* 方法的实现代码相当酷炫,
* 实现思路:获取没重复的最右一值放入新数组。
* (检测到有重复值时终止当前循环同时进入顶层循环的下一轮判断)*/
function uniq(array){
var temp = [];
var index = [];
var l = array.length;
for(var i = 0; i < l; i++) {
for(var j = i + 1; j < l; j++){
if (array[i] === array[j]){
i++;
j = i;
}
}
temp.push(array[i]);
index.push(i);
}
console.log(index);
return temp;
}
var aa = [1,2,2,3,5,3,6,5];
console.log(uniq(aa));
126、关于事件,IE与火狐的事件机制有什么区别? 如何阻止冒泡?
IE为事件冒泡,Firefox同时支持事件捕获和事件冒泡。但并非所有浏览器都支持事件捕获。jQuery中使用event.stopPropagation()方法可阻止冒泡;(旧IE的方法 ev.cancelBubble = true;)
127、 javascript 代码中的"use strict";是什么意思 ? 使用它区别是什么?
除了正常模式运行外,ECMAscript添加了第二种运行模式:“严格模式”。
作用:
- 消除js不合理,不严谨地方,减少怪异行为
- 消除代码运行的不安全之处,
- 提高编译器的效率,增加运行速度
- 为未来的js新版本做铺垫。
128、介绍一下es6中Set,Map的区别?
ES6提供了新的数据结构Set。它类似于数组,但是成员的值都是唯一的,没有重复的值。
Set函数可以接受一个数组(或类似数组的对象)作为参数,用来初始化。
// 例一
var set = new Set([1, 2, 3, 4, 4]);
[...set]
// [1, 2, 3, 4]
var s = new Set();
[2, 3, 5, 4, 5, 2, 2].map(x => s.add(x));
for (let i of s) {
console.log(i);
}
// 2 3 5 4
在Set内部,两个NaN是相等。两个对象总是不相等的。可以用length来检测
四个操作方法:
add(value):添加某个值,返回Set结构本身。delete(value):删除某个值,返回一个布尔值,表示删除是否成功。has(value):返回一个布尔值,表示该值是否为Set的成员。clear():清除所有成员,没有返回值
set内部的元素可以遍历for…of…
weakset
WeakSet结构与Set类似,也是不重复的值的集合。
WeakSet和Set的区别:
- WeakSet的成员只能是对象,而不能是其他类型的值
- WeakSet中的对象都是弱引用,即垃圾回收机制不考虑WeakSet对该对象的引用,也就是说,如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象所占用的内存,不考虑该对象还存在于WeakSet之中。这个特点意味着,无法引用WeakSet的成员,因此WeakSet是不可遍历的。
Map
Map结构提供了“值—值”的对应,是一种更完善的Hash结构实现。如果你需要“键值对”的数据结构,Map比Object更合适。它类似于对象,也是键值对的集合,但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。
var m = new Map();
var o = {p: "Hello World"};
m.set(o, "content")
m.get(o) // "content"
m.has(o) // true
m.delete(o) // true
m.has(o) // false
个对象的引用,Map结构才将其视为同一个键。这一点要非常小心。
var map = new Map();
map.set(['a'], 555);
map.get(['a']) // undefined
上面代码的set和get方法,表面是针对同一个键,但实际上这是两个值,内存地址是不一样的,因此get方法无法读取该键,返回undefined。
如果Map的键是一个简单类型的值(数字、字符串、布尔值),则只要两个值严格相等,Map将其视为一个键,包括0和-0。另外,虽然NaN不严格相等于自身,但Map将其视为同一个键。
实例属性和方法:size、set、get、has、delete、clear
遍历方法:keys()、values()、entries()、forEach()
129、并行和并发的区别
并发是指一个处理器同时处理多个任务。
并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。
并发是逻辑上的同时发生(simultaneous),而并行是物理上的同时发生。
来个比喻:并发是一个人同时吃三个馒头,而并行是三个人同时吃三个馒头。
130、为什么操作dom慢
JS引擎和和渲染引擎的模块化设计,使得它们可以独立优化,运行速度更快,但是这种设计带来的后果就是DOM操作会越来越慢
131、 如何判断一个对象是否属于某个类?
使用instanceof 即if(a instanceof Person){alert(‘yes’);}
132、new操作符具体干了什么呢?
- 创建一个空对象,并且 this 变量引用该对象,同时还继承了该函数的原型。
- 属性和方法被加入到 this 引用的对象中。
- 新创建的对象由 this 所引用,并且最后隐式的返回 this 。
133、 Javascript中,执行时对象查找时,永远不会去查找原型的函数?
Object.hasOwnProperty(proName):是用来判断一个对象是否有你给出名称的属性。不过需要注意的是,此方法无法检查该对象的原型链中是否具有该属性,该属性必须是对象本身的一个成员。
134、对JSON的了解?
全称:JavaScript Object Notation
JSON中对象通过“{}”来标识,一个“{}”代表一个对象,如{“AreaId”:”123”},对象的值是键值对的形式(key:value)。JSON是JS的一个严格的子集,一种轻量级的数据交换格式,类似于xml。数据格式简单,易于读写,占用带宽小。
两个函数:
JSON.parse(str)
解析JSON字符串 把JSON字符串变成JavaScript值或对象
JSON.stringify(obj)
将一个JavaScript值(对象或者数组)转换为一个 JSON字符串
eval(‘(‘+json+’)’)
用eval方法注意加括号 而且这种方式更容易被攻击
135、JS延迟加载的方式有哪些?
S的延迟加载有助与提高页面的加载速度。
defer和async、动态创建DOM方式(用得最多)、按需异步载入JS
defer:延迟脚本。立即下载,但延迟执行(延迟到整个页面都解析完毕后再运行),按照脚本出现的先后顺序执行。
async:异步脚本。下载完立即执行,但不保证按照脚本出现的先后顺序执行。
136、模块化开发怎么做?
模块化开发指的是在解决某一个复杂问题或者一系列问题时,依照一种分类的思维把问题进行系统性的分解。模块化是一种将复杂系统分解为代码结构更合理,可维护性更高的可管理的模块方式。对于软件行业:系统被分解为一组高内聚,低耦合的模块。
(1)定义封装的模块
(2)定义新模块对其他模块的依赖
(3)可对其他模块的引入支持。在JavaScript中出现了一些非传统模块开发方式的规范。 CommonJS的模块规范,AMD(Asynchronous Module Definition),CMD(Common Module Definition)等。AMD是异步模块定义,所有的模块将被异步加载,模块加载不影响后边语句运行。
137、AMD(Modules/Asynchronous-Definition)、CMD(Common Module Definition)规范区别?
AMD 是 RequireJS 在推广过程中对模块定义的规范化产出。CMD 是 SeaJS 在推广过程中对模块定义的规范化产出。
区别:
- 对于依赖的模块,AMD 是提前执行,CMD 是延迟执行。不过 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)。
- CMD 推崇依赖就近,AMD 推崇依赖前置。
- AMD 的 API 默认是一个当多个用,CMD 的 API 严格区分,推崇职责单一。
// CMD
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
// 此处略去 100 行
var b = require('./b') // 依赖可以就近书写
b.doSomething()
})
// AMD 默认推荐
define(['./a', './b'], function(a, b) { // 依赖必须一开始就写好
a.doSomething();
// 此处略去 100 行
b.doSomething();
})
138、requireJS的核心原理是什么?(如何动态加载的?如何避免多次加载的?如何缓存的?)
核心是js的加载模块,通过正则匹配模块以及模块的依赖关系,保证文件加载的先后顺序,根据文件的路径对加载过的文件做了缓存。
139、ts和js的区别
javascript是一个弱类型语言,Typescript是Javascript的一个超集,最大区别就是Ts提供了类型系统。
140、call和apply
call()方法和apply()方法的作用相同,动态改变某个类的某个方法的运行环境。他们的区别在于接收参数的方式不同。在使用call()方法时,传递给函数的参数必须逐个列举出来。使用apply()时,传递给函数的是参数数组。
141、数组对象有哪些原生方法,列举一下
pop、push、shift、unshift、splice、reverse、sort、concat、join、slice、toString、indexOf、lastIndexOf、reduce、reduceRight
forEach、map、filter、every、some
142、 那些操作会造成内存泄漏
全局变量、闭包、DOM清空或删除时,事件未清除、子元素存在引用
143、是否所有函数都有prototype 一说?
我们创建的每个函数都有一个 prototype(原型)属性,这个属性是一个指针,指向一个对象,
而这个对象的用途是包含可以由特定类型的所有实例共享的属性和方法。
无论什么时候,只要创建了一个新函数,就会根据一组特定的规则为该函数创建一个prototype属性,这个属性指向函数的原型对象。在默认情况下,所有原型对象都会自动获得一个constructor(构造函数)属性,这个属性包含一个指向 prototype 属性所在函数的指针。
引自<>中译本 第6.2.3节, 原型模式.
也就是JavaScript的prototype是仅函数拥有, 而对象也拥有prototype是源于其constructor属性所拥有的prototype.
第三部分:浏览器
1、HTML CSS JAVASCRIPT 是如何变成页面的?
构建 DOM 树
构建 DOM 树的输入内容是一个非常简单的 HTML 文件,然后经由HTML 解析器解析,最终输出树状结构的 DOM。
DOM 和 HTML 内容几乎是一样的,但是和 HTML 不同的是,DOM 是保存在内存中树状结构,可以通过 JavaScript 来查询或修改其内容。
样式计算(Recalculate Style)
样式计算的目的是为了计算出 DOM 节点中每个元素的具体样式
- 把 CSS 转换为浏览器能够理解的结构
以当渲染引擎接收到 CSS 文本时,会执行一个转换操作,将 CSS 文本转换为浏览器可以理解的结构——styleSheets。
- 转换样式表中的属性值,使其标准化
CSS 文本中有很多属性值,如 2em、blue、bold,这些类型数值不容易被渲染引擎理解,所以需要将所有值转换为渲染引擎容易理解的、标准化的计算值,这个过程就是属性值标准化。2em 被解析成了 32px,red 被解析成了 rgb(255,0,0),bold 被解析成了 700……
- 计算出 DOM 树中每个节点的具体样式
样式计算阶段的目的是为了计算出 DOM 节点中每个元素的具体样式,在计算过程中需要遵守 CSS 的继承和层叠两个规则。这个阶段最终输出的内容是每个 DOM 节点的样式,并被保存在 ComputedStyle 的结构内。
CSS 继承就是每个 DOM 节点都包含有父节点的样式。
层叠是 CSS 的一个基本特征,它是一个定义了如何合并来自多个源的属性值的算法。它在 CSS 处于核心地位,CSS 的全称“层叠样式表”正是强调了这一点。
布局阶段
- 创建布局树
遍历 DOM 树中的所有可见节点,并把这些节点加到布局中;而不可见的节点会被布局树忽略掉,如 head 标签下面的全部内容,属性包含 dispaly:none的元素。
- 布局计算
计算布局树节点的坐标位置,在执行布局操作的时候,会把布局运算的结果重新写回布局树中,所以布局树既是输入内容也是输出内容,这是布局阶段一个不合理的地方,因为在布局阶段并没有清晰地将输入内容和输出内容区分开来。
分层
因为页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)。
浏览器的页面实际上被分成了很多图层,这些图层叠加后合成了最终的页面。
通常情况下,并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层。
- 拥有层叠上下文属性的元素会被提升为单独的一层。明确定位属性的元素、定义透明属性的元素、使用 CSS 滤镜的元素等,都拥有层叠上下文属性。
- 需要剪裁(clip)的地方也会被创建为图层。内容超过容器的尺寸时,这时候就产生了剪裁,渲染引擎会把裁剪文字内容的一部分用于显示在 div 区域,出现这种裁剪情况的时候,渲染引擎会为文字部分单独创建一个层,如果出现滚动条,滚动条也会被提升为单独的层。
图层绘制
在完成图层树的构建之后,渲染引擎会对图层树中的每个图层进行绘制。渲染引擎会把一个图层的绘制拆分成很多小的绘制指令,然后再把这些指令按照顺序组成一个待绘制列表。
栅格化(raster)操作
绘制列表只是用来记录绘制顺序和绘制指令的列表,而实际上绘制操作是由渲染引擎中的合成线程来完成的。当图层的绘制列表准备好之后,主线程会把该绘制列表提交(commit)给合成线程。
合成线程会将图层划分为图块(tile),这些图块的大小通常是 256x256或者 512x512。
然后合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。
合成和显示
一旦所有图块都被光栅化,合成线程就会生成一个绘制图块的命令——“DrawQuad”,然后将该命令提交给浏览器进程。
浏览器进程里面有一个叫 viz 的组件,用来接收合成线程发过来的 DrawQuad 命令,然后根据 DrawQuad 命令,将其页面内容绘制到内存中,最后再将内存显示在屏幕上。
2、chrome 仅仅打开一个页面 为什么有有4个进程?
*** 浏览器进程**。主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
* 渲染进程。核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。
* GPU 进程。其实,Chrome 刚开始发布的时候是没有 GPU 进程的。而 GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的UI界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。
* 网络进程。主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
* 插件进程。主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
讲到这里,现在你应该就可以回答文章开头提到的问题了:仅仅打开了1个页面,为什么有4个进程?因为打开1个页面至少需要1个网络进程、1个浏览器进程、1个GPU 进程以及1个渲染进程,共4个;如果打开的页面有运行插件的话,还需要再加上1个插件进程。
不过凡事都有两面性,虽然多进程模型提升了浏览器的稳定性、流畅性和安全性,但同样不可避免地带来了一些问题:
*** 更高的资源占用**。因为每个进程都会包含公共基础结构的副本(如JavaScript 运行环境),这就意味着浏览器会消耗更多的内存资源。
*** 更复杂的体系架构**。浏览器各模块之间耦合性高、扩展性差等问题,会导致现在的架构已经很难适应新的需求了。
对于上面这两个问题,Chrome 团队一直在寻求一种弹性方案,既可以解决资源占用高的问题,也可以解决复杂的体系架构的问题。
未来面向服务的架构
为了解决这些问题,在2016年,Chrome官方团队使用“面向服务的架构”(Services Oriented Architecture,简称SOA)的思想设计了新的 Chrome 架构。也就是说 Chrome 整体架构会朝向现代操作系统所采用的“面向服务的架构” 方向发展,原来的各种模块会被重构成独立的服务(Service),每个服务(Service)都可以在独立的进程中运行,访问服务(Service)必须使用定义好的接口,通过 IPC 来通信,从而构建一个更内聚、松耦合、易于维护和扩展的系统,更好实现 Chrome 简单、稳定、高速、安全的目标。如果你对面向服务的架构感兴趣,你可以去网上搜索下资料,这里就不过多介绍了。
Chrome 最终要把UI、数据库、文件、设备、网络等模块重构为基础服务,类似操作系统底层服务,下面是 Chrome“面向服务的架构”的进程模型图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZjmHYdB6-1649150971278)(https://pic3.zhimg.com/80/v2-329658fe821252db47b0964037a1de2a_720w.jpg)]
Chrome“面向服务的架构”进程模型图
目前 Chrome 正处在老的架构向服务化架构过渡阶段,这将是一个漫长的迭代过程。
Chrome 正在逐步构建 Chrome 基础服务(Chrome Foundation Service),如果你认为Chrome 是“便携式操作系统”,那么 Chrome 基础服务便可以被视为该操作系统的“基础”系统服务层。
同时Chrome还提供灵活的弹性架构,在强大性能设备上会以多进程的方式运行基础服务,但是如果在资源受限的设备上(如下图),Chrome 会将很多服务整合到一个进程中,从而节省内存占用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uDvxJaPm-1649150971278)(https://pic3.zhimg.com/80/v2-a9ba86d7b03263fa3997d3733d958176_720w.jpg)]
在资源不足的设备上,将服务合并到浏览器进程中
总结
好了,今天就到这里,下面我来简要梳理并总结今天的内容。
本文我主要是从 Chrome 进程架构的视角,分析了浏览器的进化史。
最初的浏览器都是单进程的,它们不稳定、不流畅且不安全,之后出现了 Chrome,创造性地引入了多进程架构,并解决了这些遗留问题。随后 Chrome 试图应用到更多业务场景,如移动设备、VR、视频等,为了支持这些场景,Chrome 的架构体系变得越来越复杂,这种架构的复杂性倒逼 Chrome 开发团队必须进行架构的重构,最终 Chrome 团队选择了面向服务架构(SOA)形式,这也是 Chrome 团队现阶段的一个主要任务。
鉴于目前架构的复杂性,要完整过渡到面向服务架构,估计还需要好几年时间才能完成。不过Chrome 开发是一个渐进的过程,新的特性会一点点加入进来,这也意味着我们随时能看到Chrome 新的变化。
总体说来,Chrome 是以一个非常快速的速度在进化,越来越多的业务和应用都逐渐转至浏览器来开发,身为开发人员,我们不能坐视不管,而应该紧跟其步伐,收获这波技术红利。
3、强缓存,协商缓存
(一)、强缓存
强缓存主要包括 expires 和 cache-control。
1、expires
expires 是 HTTP1.0 中定义的缓存字段。当我们请求一个资源,服务器返回时,可以在 Response Headers 中增加 expires 字段表示资源的过期时间。
expires: Thu, 03 Jan 2019 11:43:04 GMT
它是一个时间戳(准确点应该叫格林尼治时间),当客户端再次请求该资源的时候,会把客户端时间与该时间戳进行对比,如果大于该时间戳则已过期,否则直接使用该缓存资源。
但是,有个大问题,发送请求时是使用的客户端时间去对比。一是客户端和服务端时间可能快慢不一致,另一方面是客户端的时间是可以自行修改的(比如浏览器是跟随系统时间的,修改系统时间会影响到),所以不一定满足预期。
2、cache-control
正由于上面说的可能存在的问题,HTTP1.1 新增了 cache-control 字段来解决该问题,所以当 cache-control 和 expires 都存在时,cache-control 优先级更高。该字段是一个时间长度,单位秒,表示该资源过了多少秒后失效。当客户端请求资源的时候,发现该资源还在有效时间内则使用该缓存,它不依赖客户端时间。cache-control 主要有 max-age 和 s-maxage、public 和 private、no-cache 和 no-store 等值。
cache-control: public, max-age=3600, s-maxage=3600
(1)max-age 和 s-maxage
两者是 cache-control 的主要字段,它们是一个数字,表示资源过了多少秒之后变为无效。在浏览器中,max-age 和 s-maxage 都起作用,而且 s-maxage 的优先级高于 max-age。在代理服务器中,只有 s-maxage 起作用。 可以通过设置 max-age 为 0 表示立马过期来向服务器请求资源。
(2)public 和 private
public 表示该资源可以被所有客户端和代理服务器缓存,而 private 表示该资源仅能客户端缓存。默认值是 private,当设置了 s-maxage 的时候表示允许代理服务器缓存,相当于 public。
(3)no-cache 和 no-store
no-cache 表示的是不直接询问浏览器缓存情况,而是去向服务器验证当前资源是否更新(即协商缓存)。no-store 则更狠,完全不使用缓存策略,不缓存请求或响应的任何内容,直接向服务器请求最新。由于两者都不考虑缓存情况而是直接与服务器交互,所以当 no-cache 和 no-store 存在时会直接忽略 max-age 等。
3、pragma
既然讲到了 no-cache 和 no-store,就顺便把 pragma 也讲了。他的值有 no-cache 和 no-store,表示意思同 cache-control,优先级高于 cache-control 和 expires,即三者同时出现时,先看 pragma -> cache-control -> expires。
pragma: no-cache
(二)、协商缓存
上面的 expires 和 cache-control 都会访问本地缓存直接验证看是否过期,如果没过期直接使用本地缓存,并返回 200。但如果设置了 no-cache 和 no-store 则本地缓存会被忽略,会去请求服务器验证资源是否更新,如果没更新才继续使用本地缓存,此时返回的是 304,这就是协商缓存。协商缓存主要包括 last-modified 和 etag。
1、last-modified
last-modified 记录资源最后修改的时间。启用后,请求资源之后的响应头会增加一个 last-modified 字段,如下:
last-modified: Thu, 20 Dec 2018 11:36:00 GMT
当再次请求该资源时,请求头中会带有 if-modified-since 字段,值是之前返回的 last-modified 的值,如:if-modified-since:Thu, 20 Dec 2018 11:36:00 GMT。服务端会对比该字段和资源的最后修改时间,若一致则证明没有被修改,告知浏览器可直接使用缓存并返回 304;若不一致则直接返回修改后的资源,并修改 last-modified 为新的值。
但 last-modified 有以下两个缺点:
- 只要编辑了,不管内容是否真的有改变,都会以这最后修改的时间作为判断依据,当成新资源返回,从而导致了没必要的请求响应,而这正是缓存本来的作用即避免没必要的请求。
- 时间的精确度只能到秒,如果在一秒内的修改是检测不到更新的,仍会告知浏览器使用旧的缓存。
2、etag
为了解决 last-modified 上述问题,有了 etag。 etag 会基于资源的内容编码生成一串唯一的标识字符串,只要内容不同,就会生成不同的 etag。启用 etag 之后,请求资源后的响应返回会增加一个 etag 字段,如下:
etag: "FllOiaIvA1f-ftHGziLgMIMVkVw_"
当再次请求该资源时,请求头会带有 if-none-match 字段,值是之前返回的 etag 值,如:if-none-match:"FllOiaIvA1f-ftHGziLgMIMVkVw_"。服务端会根据该资源当前的内容生成对应的标识字符串和该字段进行对比,若一致则代表未改变可直接使用本地缓存并返回 304;若不一致则返回新的资源(状态码200)并修改返回的 etag 字段为新的值。
可以看出 etag 比 last-modified 更加精准地感知了变化,所以 etag 优先级也更高。不过从上面也可以看出 etag 存在的问题,就是每次生成标识字符串会增加服务器的开销。所以要如何使用 last-modified 和 etag 还需要根据具体需求进行权衡。
4、浏览器内核有啥,咋解决兼容问题
内核名称:使用该内核的浏览器
- Trident:ie/360兼容模式/搜狗
- Geoko:火狐firefox
- Presto:opera(后来改为Webkit又到了Blink内核)
- Webkit:谷歌(Webkit的分支Blink) safari 360极速模式(Blink)
答题的时候如果记不住单词,可以写出四个类别分别代表的浏览器
ie 火狐 opera 谷歌
二、常见浏览器兼容性问题,原因及解决方法,hack技巧有哪些?
面对浏览器诸多的兼容性问题,经常需要通过修改CSS样式来调试,其中用的最多的
就是CSS Hack。所谓CSS Hack就是针对不同的浏览器书写不同的CSS样式,通过使
用某个浏览器单独识别的样式代码,控制该浏览器的显示效果。
123
答题时写四五个就行了
-
不同浏览器的标签默认的外补丁(margin)和内补丁(padding)不同
解决方案:css里增加通配符*{margin:0;padding:0}
-
IE6双边距问题;在IE6中设置了float,同时又设置margin,就会出现边距问题
解决方案:设置display:inline;
-
当标签的高度设置小于10px,在IE6、IE7中会超出自己设置的高度
解决方案:超出高度的标签设置overflow:hidden,或者设置line-height的值小于你的设置高度
-
图片默认有间距
解决方案:使用float为img布局
-
IE9以下浏览器不能使用opacity
解决方案:opacity:0.5;filter:alfha(opacity=50);filter:progid:
第四部分:网络
1、你知道哪些http首部字段?
http协议是前端开发人员最常接触到的网络协议。在开发过程中,尤其是调试过程中避免不了需要去分析http请求的详细信息。在这其中头部字段提供的信息最多,比如通过响应状态码我们可以直观的看到响应的大致状态。那么你是否清楚http首部字段都有哪些,具体含义是什么,可选值又有哪些呢?看完下面的内容,我相信对于这几个问题你就会迎刃而解。
http协议用于交互的信息被称为HTTP报文。请求端(客户端)的HTTP报文叫做请求报文,响应端(服务器端)的HTTP报文叫做响应报文。HTTP报文大致可以分为报文首部和报文主题两部分。我们来看下请求报文和响应报文的结构。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7MZpPRuK-1649150971278)(https://img2018.cnblogs.com/blog/993712/201909/993712-20190903135632412-483353454.jpg)]
从上图我们可以看出,请求报文和响应报文的首部内容由以下数据组成。
请求行
包含用于请求的方法,请求 URI 和 HTTP 版本。
状态行
包含表明响应结果的状态码,原因短语和 HTTP 版本。
首部字段
包含表示请求和响应的各种条件和属性的各类首部。
下面我们重点来看下首部字段的一些信息,并且对最常用到的首部字段的含义及可选值都有哪些,分别代表什么意思进行讲解。
http首部字段类型根据实际用途被分为以下4种类型:
通用首部字段(General Header Fields)
请求报文和响应报文两方都会使用的首部。
请求首部报文(Request Headers Fields)
从客户端向服务端发送请求报文时使用的首部。补充了请求的附加内容,客户端信息,响应内容相关优先级等信息。
响应首部字段(Response Header Fields)
从服务器端向客户端返回响应报文时使用的首部。补充了响应的附加内容,也会要求客户端附加额外的内容信息。
实体首部字段(Entity Header Fields)
针对请求报文和响应报文的实体部分使用的首部。补充了资源内容更新时间等与实体相关的信息。
其中http/1.1规范定义了47种首部字段,下面我们按照以上的四个大类对这47种字段进行一个简要解释:
通用首部字段
首部字段名
说明
Cache-Control
控制缓存的行为
Connection
连接的管理
Date
创建报文的日期时间
Pragma
报文指令
Trailer
报文末端的首部一览
Transfer-Encoding
指定报文主体的传输编码方式
Upgrade
升级为其他协议
Via
代理服务器的相关信息
Warning
错误通知
请求首部字段
首部字段名
说明
Accept
用户代理可处理的媒体类型
Accept-Charset
优先的字符集
Accept-Encoding
优先的内容编码
Accept-Language
优先的语言(自然语言)
Authorization
Web认证信息
Expect
期待服务器的特定行为
From
用户的电子邮箱地址
Host
请求资源所在服务器
If-Match
比较实体标记(ETag)
If-Modified-Since
比较资源的更新时间
If-None-Match
比较实体标记(与 If-Match 相反)
If-Range
资源未更新时发送实体 Byte 的范围请求
If-Unmodified-Since
比较资源的更新时间(与If-Modified-Since相反)
Max-Forwards
最大传输逐跳数
Proxy-Authorization
代理服务器要求客户端的认证信息
Range
实体的字节范围请求
Referer
对请求中URI的原始获取方
TE
传输编码的优先级
User-Agent
HTTP客户端程序的信息
响应首部字段
首部字段名
说明
Accept-Ranges
是否接受字节范围请求
Age
推算资源创建经过时间
ETag
资源的匹配信息
Location
令客户端重定向至指定URI
Proxy-Authenticate
代理服务器对客户端的认证信息
Retry-After
对再次发起请求的时机要求
Server
HTTP服务器的安装信息
Vary
代理服务器缓存的管理信息
WWW-Authenticate
服务器对客户端的认证信息
实体首部字段
首部字段名
说明
Allow
资源可支持的HTTP方法
Content-Encoding
实体主体适用的编码方式
Content-Language
实体主体的自然语言
Content-Length
实体主体的大小(单位:字节)
Content-Location
替代对应资源的URI
Content-MD5
实体主体的报文摘要
Content-Range
实体主体的位置范围
Content-Type
实体主体的媒体类型
Expires
实体主体过期的日期时间
Last-Modified
资源的最后修改日期时间
2、说一下http缓存策略,有什么区别,分别解决了什么问题?
浏览器每次发起请求时,先在本地缓存中查找结果以及缓存标识,根据缓存标识来判断是否使用本地缓存。如果缓存有效,则使
用本地缓存;否则,则向服务器发起请求并携带缓存标识。根据是否需向服务器发起HTTP请求,将缓存过程划分为两个部分:
强制缓存和协商缓存,强缓优先于协商缓存。
- 强缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存,不在时间内,执行比较缓存策略。
- 协商缓存,让客户端与服务器之间能实现缓存文件是否更新的验证、提升缓存的复用率,将缓存信息中的Etag和Last-Modified
通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存。
HTTP缓存都是从第二次请求开始的:
- 第一次请求资源时,服务器返回资源,并在response header中回传资源的缓存策略;
- 第二次请求时,浏览器判断这些请求参数,击中强缓存就直接200,否则就把请求参数加到request header头中传给服务器,看是否击中协商缓存,击中则返回304,否则服务器会返回新的资源。这是缓存运作的一个整体流程图:
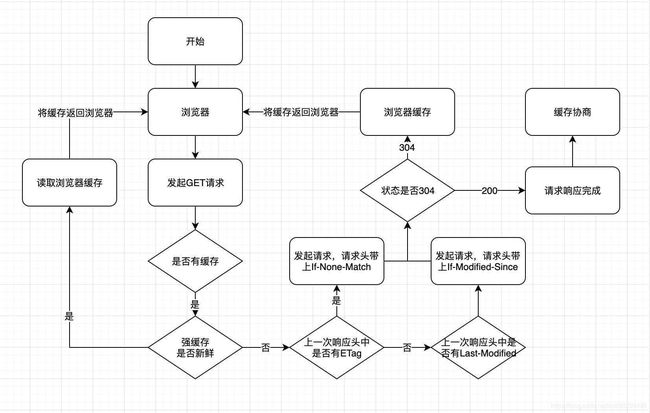
2)强缓存
- 强缓存命中则直接读取浏览器本地的资源,在network中显示的是from memory或者from disk
- 控制强制缓存的字段有:Cache-Control(http1.1)和Expires(http1.0)
- Cache-control是一个相对时间,用以表达自上次请求正确的资源之后的多少秒的时间段内缓存有效。
- Expires是一个绝对时间。用以表达在这个时间点之前发起请求可以直接从浏览器中读取数据,而无需发起请求
- Cache-Control的优先级比Expires的优先级高。前者的出现是为了解决Expires在浏览器时间被手动更改导致缓存判断错误的问题。
如果同时存在则使用Cache-control。
3)强缓存-expires
- 该字段是服务器响应消息头字段,告诉浏览器在过期时间之前可以直接从浏览器缓存中存取数据。
- Expires 是 HTTP 1.0 的字段,表示缓存到期时间,是一个绝对的时间 (当前时间+缓存时间)。在响应消息头中,设置这个字段之后,就可以告诉浏览器,在未过期之前不需要再次请求。
- 由于是绝对时间,用户可能会将客户端本地的时间进行修改,而导致浏览器判断缓存失效,重新请求该资源。此外,即使不考虑修改,时差或者误差等因素也可能造成客户端与服务端的时间不一致,致使缓存失效。
- 优势特点
- 1、HTTP 1.0 产物,可以在HTTP 1.0和1.1中使用,简单易用。
- 2、以时刻标识失效时间。
- 劣势问题
- 1、时间是由服务器发送的(UTC),如果服务器时间和客户端时间存在不一致,可能会出现问题。
- 2、存在版本问题,到期之前的修改客户端是不可知的。
4)强缓存-cache-control
-
已知Expires的缺点之后,在HTTP/1.1中,增加了一个字段Cache-control,该字段表示资源缓存的最大有效时间,在该时间内,客户端不需要向服务器发送请求。
-
这两者的区别就是前者是绝对时间,而后者是相对时间。下面列举一些 Cache-control 字段常用的值:(完整的列表可以查看MDN)
max-age:即最大有效时间。must-revalidate:如果超过了 max-age 的时间,浏览器必须向服务器发送请求,验证资源是否还有效。no-cache:不使用强缓存,需要与服务器验证缓存是否新鲜。no-store: 真正意义上的“不要缓存”。所有内容都不走缓存,包括强制和对比。public:所有的内容都可以被缓存 (包括客户端和代理服务器, 如 CDN)private:所有的内容只有客户端才可以缓存,代理服务器不能缓存。默认值。
-
Cache-control 的优先级高于 Expires,为了兼容 HTTP/1.0 和 HTTP/1.1,实际项目中两个字段都可以设置。
-
该字段可以在请求头或者响应头设置,可组合使用多种指令:
-
可缓存性
:
- public:default,浏览器和缓存服务器都可以缓存页面信息
- private:代理服务器不可缓存,只能被单个用户缓存
- no-cache:浏览器器和服务器都不应该缓存页面信息,但仍可缓存,只是在缓存前需要向服务器确认资源是否被更改。可配合private,
过期时间设置为过去时间。
- only-if-cache:客户端只接受已缓存的响应
-
到期
- max-age=:缓存存储的最大周期,超过这个周期被认为过期。
- s-maxage=:设置共享缓存,比如can。会覆盖max-age和expires。
- max-stale[=]:客户端愿意接收一个已经过期的资源
- min-fresh=:客户端希望在指定的时间内获取最新的响应
- stale-while-revalidate=:客户端愿意接收陈旧的响应,并且在后台一部检查新的响应。时间代表客户端愿意接收陈旧响应
的时间长度。
- stale-if-error=:如新的检测失败,客户端则愿意接收陈旧的响应,时间代表等待时间。
-
重新验证和重新加载
- must-revalidate:如页面过期,则去服务器进行获取。
- proxy-revalidate:用于共享缓存。
- immutable:响应正文不随时间改变。
-
其他
- no-store:绝对禁止缓存
- no-transform:不得对资源进行转换和转变。例如,不得对图像格式进行转换。
-
优势特点
- 1、HTTP 1.1 产物,以时间间隔标识失效时间,解决了Expires服务器和客户端相对时间的问题。
- 2、比Expires多了很多选项设置。
-
劣势问题
- 1、存在版本问题,到期之前的修改客户端是不可知的。
5)协商缓存
- 协商缓存的状态码由服务器决策返回200或者304
- 当浏览器的强缓存失效的时候或者请求头中设置了不走强缓存,并且在请求头中设置了If-Modified-Since 或者 If-None-Match 的时候,会将这两个属性值到服务端去验证是否命中协商缓存,如果命中了协商缓存,会返回 304 状态,加载浏览器缓存,并且响应头会设置 Last-Modified 或者 ETag 属性。
- 对比缓存在请求数上和没有缓存是一致的,但如果是 304 的话,返回的仅仅是一个状态码而已,并没有实际的文件内容,因此 在响应体体积上的节省是它的优化点。
- 协商缓存有 2 组字段(不是两个),控制协商缓存的字段有:Last-Modified/If-Modified-since(http1.0)和Etag/If-None-match(http1.1)
- Last-Modified/If-Modified-since表示的是服务器的资源最后一次修改的时间;Etag/If-None-match表示的是服务器资源的唯一标
识,只要资源变化,Etag就会重新生成。
- Etag/If-None-match的优先级比Last-Modified/If-Modified-since高。
6)协商缓存-协商缓存-Last-Modified/If-Modified-since
- 1.服务器通过
Last-Modified 字段告知客户端,资源最后一次被修改的时间,例如 Last-Modified: Mon, 10 Nov 2018 09:10:11 GMT
- 2.浏览器将这个值和内容一起记录在缓存数据库中。
- 3.下一次请求相同资源时时,浏览器从自己的缓存中找出“不确定是否过期的”缓存。因此在请求头中将上次的
Last-Modified 的值写入到请求头的 If-Modified-Since 字段
- 4.服务器会将
If-Modified-Since 的值与 Last-Modified 字段进行对比。如果相等,则表示未修改,响应 304;反之,则表示修改了,响应 200 状态码,并返回数据。
- 优势特点
- 1、不存在版本问题,每次请求都会去服务器进行校验。服务器对比最后修改时间如果相同则返回304,不同返回200以及资源内容。
- 劣势问题
- 2、只要资源修改,无论内容是否发生实质性的变化,都会将该资源返回客户端。例如周期性重写,这种情况下该资源包含的数据实际上一样的。
- 3、以时刻作为标识,无法识别一秒内进行多次修改的情况。 如果资源更新的速度是秒以下单位,那么该缓存是不能被使用的,因为它的时间单位最低是秒。
- 4、某些服务器不能精确的得到文件的最后修改时间。
- 5、如果文件是通过服务器动态生成的,那么该方法的更新时间永远是生成的时间,尽管文件可能没有变化,所以起不到缓存的作用。
7)协商缓存-Etag/If-None-match
- 为了解决上述问题,出现了一组新的字段
Etag 和 If-None-Match
Etag 存储的是文件的特殊标识(一般都是 hash 生成的),服务器存储着文件的 Etag 字段。之后的流程和 Last-Modified 一致,只是 Last-Modified 字段和它所表示的更新时间改变成了 Etag 字段和它所表示的文件 hash,把 If-Modified-Since 变成了 If-None-Match。服务器同样进行比较,命中返回 304, 不命中返回新资源和 200。- 浏览器在发起请求时,服务器返回在Response header中返回请求资源的唯一标识。在下一次请求时,会将上一次返回的Etag值赋值给If-No-Matched并添加在Request Header中。服务器将浏览器传来的if-no-matched跟自己的本地的资源的ETag做对比,如果匹配,则返回304通知浏览器读取本地缓存,否则返回200和更新后的资源。
- Etag 的优先级高于 Last-Modified。
- 优势特点
- 1、可以更加精确的判断资源是否被修改,可以识别一秒内多次修改的情况。
- 2、不存在版本问题,每次请求都回去服务器进行校验。
- 劣势问题
- 1、计算ETag值需要性能损耗。
- 2、分布式服务器存储的情况下,计算ETag的算法如果不一样,会导致浏览器从一台服务器上获得页面内容后到另外一台服务器上进行验证时现ETag不匹配的情况。
3、请描述TCP的三次握手和四次挥手
CP三次握手的过程如下:
建立TCP连接,就是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。在socket编程中,这一过程由客户端执行connect来触发。
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接.
第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
SYN:同步序列编号(Synchronize Sequence Numbers)
第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-riLl2one-1649150971279)(https://pic2.zhimg.com/80/v2-08a83a15cf9060013484ffc688528829_720w.jpg)]
为什么需要三次握手,是为了解决下列的一个问题:
client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用三次握手,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用三次握手的办法可以防止上述现象发生
四次挥手(Four-Way Wavehand)即终止TCP连接,就是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。在socket编程中,这一过程由客户端或服务端任一方执行close来触发
TCP四次挥手的过程如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WQMB3FC4-1649150971279)(https://pic2.zhimg.com/80/v2-3c3fdb98363aa7418b49cf8e0868af8d_720w.jpg)]
1.第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
2.第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
3.第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
4.第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1, Server进入CLOSED状态,完成四次挥手。
如果有大量的连接,每次在连接、关闭时都要三次握手,四次挥手,会很明显会造成性能低下,因此,
HTTP有一种叫做keep connection的机制,它可以在传输数据后仍然保持连接,当客户端再次获取数据时,直接使用刚刚空闲下的连接而无需再次握手
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bSfhV3xJ-1649150971279)(https://pic2.zhimg.com/80/v2-249e9f2a599f1904cf0a604a71e4b501_720w.jpg)]
4、tcp是什么
TCP即传输控制协议(Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层通讯协议。
TCP是为了在不可靠的互联网上提供可靠的端到端字节流而专门设计的一个传输协议。
互联网与单个网络有很大的不同,因为互联网的不同部分可能有截然不同的拓补结构、带宽、延迟、数据包大小和其他参数。TCP的设计目标是能够动态地适应互联网的这些特性,而且具备面向各种故障的健壮性。
不同主机的应用层之间经常需要可靠的、像管道一样的连接,但是IP层不提供这样的流机制,而是提供不可靠的包交换。
应用层向TCP层发送用于网间传输的、用8位字节表示的数据流,然后TCP把数据流分区成适当长度的报文段(通常受计算连接的网络的数据链路层的最大传输单元(MTU)的限制)。之后TCP把结果包传输给IP层,有它来通过网络将包传送给接收端实体的TCP层。
TCP为了保证不发生丢包,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后
接收端实体对已成功接收到的包回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未接收到确认,那么对应的数据包就被假设为已丢失将会被进行重传。TCP用一个校验和函数来校验数据是否有误;在发送和接收时都要计算校验。
每台支持TCP的机器都有一个TCP传输实体。TCP 实体可以时一个库过程、一个用户进程、或者内核的一部分。在所有这些情形下,它管理TCP流,以及与IP层之间的接口。TCP传输实体接收本地进程的用户数据流,将他们分割成不超过64KB(实际上去掉IP和TCP头,通常不超过1460数据字节)的分段,每个分段以单独的IP数据报形式发送。当包含TCP数据的数据报到达一台机器时,它们被递交给TCP传输实体,TCP传输实体重构出原始的字节流。为简化起见,我们有时候仅仅用TCP来代表TCP传输实体(一段软件)或者TCP协议(一组规则)。根据上下文语义你应该能很清楚的推断出其实际含义。例如,在‘用户将数据提交给TCP’这句话中,很显然这里指的时TCP实体。
IP层并不保证数据报一定被正确的提交到接收方,也不只是数据报的发送速度有多块。正是TCP负责纪要足够快的发送数据报,以便使用网络容量,但又不能引起网络阻塞:而且,TCP超时后,要重传没有递交的数据报。即使被正确递交的数据报,也可能存在错误的问题,这也是TCP的责任,它必须把接收到的数据报重新装配成正确的顺序,简言之,TCP必须提供可靠性的良好性能,这正是大多数用户所期望的而IP又没有提供的功能。
二、主要特点
当应用层向TCP层发送用于网间传输的、用8位字节表示的数据流,TCP则把数据流分割成适当长度的报文。之后TCP把数据包传递给IP层,由它来通过网络将包传送给接收端实体的TCP层。
TCP是一种面向广域网的通信协议,目的是在跨越多个网络通信时,为两个通信端点之间提供一条具有一下特点的通信方式:
(1)基于流的方式;
(2)面向连接;
(3)可靠通信方式;
(4)在网络情况不佳的时候尽量降低系统由于重传带来的带宽开销;
(5)通信连接维护是面向的两个端点的,而不考虑中间网段和节点。
为满足TCP协议的这些特点,TCP协议做了以下规定:
①数据分片:在发送端对用户数据进行分片,在接收端进行重组,由TCP确定分片的大小并控制分片和重组;
②到达确认:接收端接收到分片数据时,根据分片数据序号向发送端发送一个确认;
③超时重发:发送方在发送分片时启动超时定时器,如果在定时器超时之后没有接收到对应的确认,重发分片;
④滑动窗口:TCP连接每一方的接收缓冲空间大小都固定,接收端只允许另一端发送接收端缓冲区所能接纳的数据,TCP在滑动窗口的基础上提供流量控制,防止较快主机致使较慢主机的缓冲区溢出;
⑤失序处理:作为IP数据报来传输的TCP分片到达时可能会失序,TCP将对接收的数据进行重新排序,将接收到的数据以正确的顺序交给应用层;
⑥重复处理:作为IP数据报来传输的TCP分片会发生重复,TCP的接收端必须丢弃重复的数据;
⑦数据校验:TCP将保持它首部和数据的校验和,这是一个端到端的校验和,目的是检测数据在传输过程中的任何变化。如果收到分片的校验和由差错,TCP将丢弃这个分片,并确认接收到此报文段导致对端超时并重发。
三、工作方式
建立连接
TCP是因特网中的传输层协议,使用三次握手协议建立连接。当主动方发出SYN连接请求后,等待对方回答SYN+ACK,并最终对对方的SYN执行ACK确认。这种建立连接的方法可以防止产生错误的连接,TCP使用的流量控制协议是可便大小的华东窗口协议。
TCP三次握手的过程如下:
(1)客户端发送SYN(SEQ=x)报文给服务端,进入SYN_SEND状态。
(2)服务端接收SYN报文,回应一个SYN(SEQ=y)ACK(ACK=x+1)报文,进入SYN_RECV状态。
(3)客户端收到服务器端的SYN报文,回应一个ACK(ACK=y+1)报文,进入Established状态。
三次握手完成,TCP客户端和服务器端成功的建立连接,可以开始传输数据了。如图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PkWx8RS9-1649150971279)(https://img2018.cnblogs.com/blog/799221/201909/799221-20190904164958743-1252247495.png)]
连接终止
建立一个连接需要三次握手,而重一一个连接要经过四次握手,这是由TCP的半关闭(half-close)造成的。具体过程如下图所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SwjYSCQJ-1649150971279)(https://img2018.cnblogs.com/blog/799221/201909/799221-20190904165018172-1009077042.png)]
(1)某个应用进程首先调用close,称该端执行”主动关闭“(active close)。该端的TCP于是发送一个FIN分节,表示数据分发完毕。
(2)接收到这个FIN的对端执行”被动关闭“(passive close),这个FIN由TCP确认。
注意:FIN的接收也作为一个文件结束符(end-of-file)传递给接收端应用进程,放在已排队等候应用进程接收的任何其他数据报之后,因为,FIN的接收意味着金额手段应用进程相应连接再无额外数据可接收。
(3)一段时间后,接收到这个文件结束符的应用进程将调用close关闭它的套接字,这导致它的TCP也发送一个FIN。
(4)接收这个最终FIN的原发送端TCP(即执行主动关闭的那端)确认这个FIN。既然每个方向都需要一个FIN和一个ACK,因此通常需要4个分节。
5、HTTP2.0的特点
1、增加二进制分帧
HTTP协议从0.9版本开始不断增加增加新的功能特性,但长远来看都是向前兼容的(现在的版本支持以后的版本数据)。HTTP 2.0在应用层跟传送层之间增加了一个二进制分帧层,从而能够达到在不改动HTTP的语义,HTTP方法,状态码,URI以及首部字段的情况下,突破HTTP 1.1的性能限制,改进传输性能,实现低延迟和高吞吐量
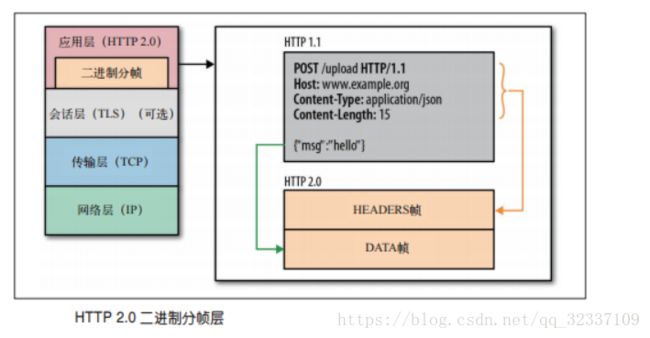
在上图所示,在二进制分帧层上,HTTP 2.0会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码,其中HTTP 1.1的首部信息会被封装到Headers帧,而request body被封装到图中所示的DATA帧。相当于把部分数据塞进了二进制分帧层里,改进传输性能。
2、压缩头部
如下图所示: HTTP 2.0在客户端和服务端使用首部表来跟踪和存储之间发送的键-值对,对相同请求而言不需要再次发送请求和相应发送,通信期间几乎不会改变的通用键值,如user-Agent和content-Type值发送一次,相当于做了一层缓存。
- 如果请求不包含首部,如:对同一资源的轮询请求,那首部开销为零字节
- 如果首部发生变化,那只需发送变化的数据在Headers帧里面,新增或修改的首部帧会被追加到首部表
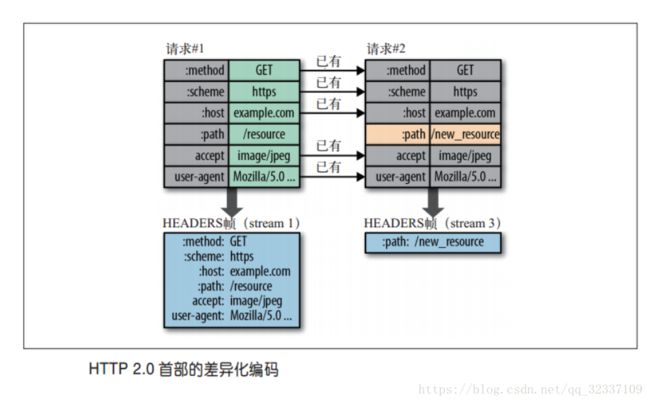
3、多路复用
一个入了门的前端开发在谈到性能优化的方法时都可以轻轻松松列举如下几点
- CSS雪碧图合并-减少请求
- 合并压缩CSS跟JS代码-减少请求
- CSS代码放在header头部里面,JS代码放到body结束之前,因为JS代码执行会阻塞
但HTTP 2.0的多路复用让我们回到最原始最自然的写码状态,先看下图
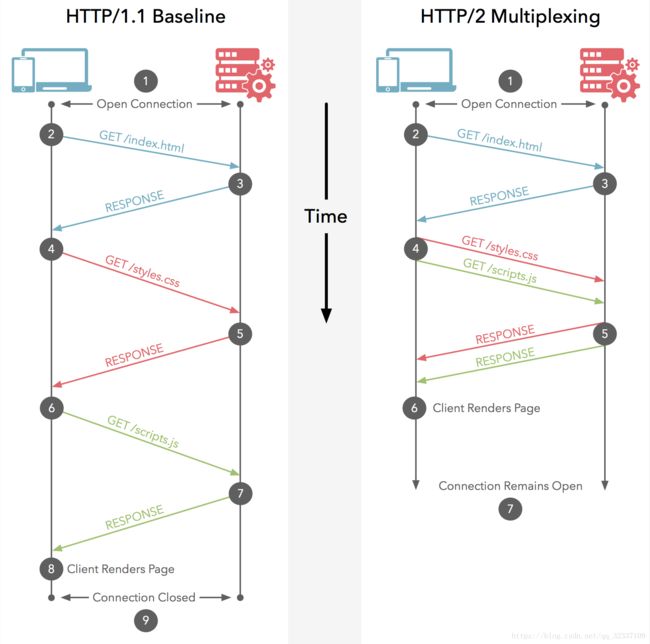
对HTTP 1.1而言,浏览器通常有并行连接的限制,即最多几个并行链接。而多路复用允许通过单一的HTTP 2.0连接发起多重的请求-相应消息
这意味着HTTP 2.0的通信都在一个连接上完成了,这个连接可以承载任意数量的双向数据流,直观来说,就是上面我们所做的优化已经不需要了。
4、请求优先级
所有资源可以并行交错发送, 那想要优先拿到CSS和JS而不是图片怎么办,在每个HTTP 2.0的流里面有个优先值,这个优先值确定着客户端跟服务器处理不同的流采取不同的优先级策略,高优先级优先发送,但这不是绝对的(绝对等待会导致首队阻塞问题)
5、服务器提示
HTTP 2.0新增加服务器提示,可以先于客户端检测到将要请求的资源,提前通知客户端,服务器不发送所有资源的实体,只发送资源的URL,客户端接到提示后会进行验证缓存,如果真需要这些资源,则正式发起请求(服务器主动更新静态资源)
6、说一下HTTP2 多路复用原理,以及多路复用优势?
- TCP慢启动: TCP连接建立后,会经历一个先慢后快的发送过程,就像汽车启动一般,如果我们的网页文件(HTML/JS/CSS/icon)都经过一次慢启动,对性能是不小的损耗。另外慢启动是TCP为了减少网络拥塞的一种策略,我们是没有办法改变的。
- 多条TCP连接竞争带宽: 如果同时建立多条TCP连接,当带宽不足时就会竞争带宽,影响关键资源的下载。
- HTTP/1.1队头阻塞: 尽管HTTP/1.1长链接可以通过一个TCP连接传输多个请求,但同一时刻只能处理一个请求,当前请求未结束前,其他请求只能处于阻塞状态。
为了解决以上几个问题,HTTP/2一个域名只使用一个TCP⻓连接来传输数据,而且请求直接是并行的、非阻塞的,这就是多路复用
实现原理: HTTP/2引入了一个二进制分帧层,客户端和服务端进行传输时,数据会先经过二进制分帧层处理,转化为一个个带有请求ID的帧,这些帧在传输完成后根据ID组合成对应的数据。
7、简述https原理,以及与http的区别
一、HTTP和HTTPS的基本概念
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
二**、**HTTP与HTTPS的区别
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
三**、**HTTP与HTTPS的工作原理
HTTP的工作原理:一次HTTP操作称为一个事物,其工作过程可分为四步
1、Client与Server建立连接,单击某个超链接,HTTP的工作开始。
2、连接建立后,Client发送一个请求给Server,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符,Client信息和可能的内容。
3、Server接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括Server信息、实体信息和可能的内容。
4、Client接收Server返回的信息通过浏览器显示在用户的显示屏上,然后Client和Server断开连接。
HTTPS的工作原理:
1、Client使用HTTPS的URL访问Web服务器,要求与Web服务器建立SSL连接。
2、Web服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。
3、客户端的浏览器与Web服务器开始协商SSL连接的安全等级,也就是信息加密的等级。
4、客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。
5、Web服务器利用自己的私钥解密出会话密钥。
6、Web服务器利用会话密钥加密与客户端之间的通信。
四**、**HTTPS的优缺点
优点:
1、使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
2、HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。
3、HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
缺点:
1、HTTPS协议握手阶段比较费时,会使页面的加载时间延长近50%,增加10%到20%的耗电;
2、HTTPS连接缓存不如HTTP高效,会增加数据开销和功耗,甚至已有的安全措施也会因此而受到影响;
3、SSL证书需要钱,功能越强大的证书费用越高,个人网站、小网站没有必要一般不会用。
4、SSL证书通常需要绑定IP,不能在同一IP上绑定多个域名,IPv4资源不可能支撑这个消耗。
5、HTTPS协议的加密范围也比较有限,在黑客攻击、拒绝服务攻击、服务器劫持等方面几乎起不到什么作用。最关键的,SSL证书的信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间人攻击一样可行。
8、CDN 是什么?描述下 CDN 原理?为什么要用 CDN?
用户体验优化一直是网站建设的核心所在。不管是网页外观设计,还是网站内容润色,都是围绕这一目标展开的。而除了这两点外,网站速度也是影响用户体验的重要因素之一。特别是对于那些第一次来访问网站的用户来说,如果网站速度很慢,他们可能就会直接放弃浏览,再优秀的网页设计也会失去用武之地。相反,如果网速很快,用户更有可能在网页上进行持续地浏览。当然,作为网站建设者,提高网站速度的方法有很多,比如代码优化、删除不必要的JS文件、对大图进行压缩或延迟加载等。不过这里天下数据小编要介绍一种新的方法:使用CDN加速。其实这种方法也并不算新鲜,主要是很多站长对这种技术并不了解。什么是CDN加速?为什么要在网站中使用CDN加速?赶紧和小编一起来看看吧!
什么是CDN加速?
CDN(Content Delivery Network),即内容分发网络。它是指在现有互联网络中增加一层新的网络架构,其基本思路是尽可能避开互联网中可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输更快。换句话说,CDN加速可以实时根据网络流量和各节点的链接、负载状况以及用户距离和响应时间等信息将用户的请求重新导向到离用户最近的服务节点,降低网络的拥塞,提高内容传递的速度和效率,加快用户访问的响应速度。其实,CDN就像是网络中的"物流转运中心",比如一个网站服务器在北京,用户人在广州,远距离使得用户访问体验不佳,而通过CDN,用户就可以从就近的深圳等地的网络节点获取数据信息。下图就是使用CDN和不使用CDN的一张对比图。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mJaE10rk-1649150971280)(https://www.idcbest.com/newsadmin/upFile/2019-9/20190918100715.png)]
使用CDN和不使用CDN的对比
为什么要在网站中应用CDN加速?
1. 网页加载速度更快
在网站中使用CDN技术最直接的一个好处就是它可以加快网页的加载速度。首先,CDN加速的内容分发是基于服务器缓存的,由于CDN中缓存了不少数据,它能够给用户提供更快的页面响应速度。目前,CDN加速中可存储的文件形式很多,比如图片、模板、Javascript、视频、音频文件、网页字体以及其他形式的文件(HTML、PDF、PPT、ZIP等)。简单来说,任何可以存储在WP中的内容及文件夹都能存储在CDN中。其次,CDN加速善于优化数据传输路径。它可以收集节点与周围环境的信息,避免单一节点压力过高,保证每个节点的工作效率,优化用户访问路线,提高数据从源站到客户端的传输速度。最后,CDN加速不受运营商相互访问较慢的限制。比如某个企业的服务器是电信宽带,联通用户访问时速度一般较慢,而CDN的使用就可以有效避免这一情况,因为CDN几乎涵盖所有的线路,可以自动帮助用户选择最快的访问路径。
2. 网站安全性&稳定性更高
应用CDN技术还可以让网站更安全、更稳定。一方面,CDN中的负载均衡设备可以维持网站各个节点的平衡,避免单个节点压力太大,有效降低网络堵塞瘫痪的可能性。另一方面,即使某一个节点由于意外发生故障,用户对网站的访问也能自动导向到其他的健康节点上进行响应。所以说CDN不仅能有效缓解网络堵塞,还可以在某个服务器连接中断的情况下依旧保证网络信息的有效传递,这有助于维持网站的安全与稳定,帮助企业树立正面的品牌形象,提升用户对网站的好感。
3. 服务器成本更低
CDN加速是通过多地的不同节点完成数据传递的,用户的访问需求并不需要达到原始的服务器中,这个过程会比平时消耗更少的带宽。如果您是基于带宽支付主机托管费用的话,使用CDN加速可以有效降低服务器的成本。除了不必考虑服务器的更多投入外,您也不必考虑多台服务器的镜像同步或更多的管理维护技术人员,因为目前主流的CDN厂商都可以轻松实现网站的全国铺设。
4. 网站SEO效果更好
对于搜索引擎来说,它们更加倾向于加载速度快、稳定安全的网站。而CDN加速就可以轻松实现这两点,它既能通过服务器缓存、访问路径优化等技术加快网页的加载速度,还可以提供一定程度的安全保障,避免网站瘫痪状况的发生,减缓不知名的攻击。对了,您还可以将CDN加速和SSL证书结合起来建立更强的防御系统,让它对搜索引擎更加友好。
9、DNS 查询的过程,分为哪两种,是怎么一个过程
主要为bai两种:递归du查询 和迭代查询zhi
1.递归查询:
一般客户机和服dao务器之间zhuanshu递归查询,属即当客户机向DNS服务器发出请求后,若DNS服务器本身不能解析,则会向另外的DNS服务器发出查询请求,得到结果后转交给客户机;
2.迭代查询(反复查询):
一般DNS服务器之间属迭代查询,如:若DNS2不能响应DNS1的请求,则它会将DNS3的IP给DNS2,以便其再向DNS3发出请求。
10、强缓存和协商缓存的区别
强制缓存
强制缓存就是直接从浏览器缓存查找该结果,并根据结果的缓存规则来决定是否使用该缓存的过程。
- 不存在该缓存结果和标识,强制缓存失效,则直接向服务器发起请求(跟第一次发起请求一致)
- 存在缓存结果和标识,但结果已失效,强制缓存失效,则使用协商缓存
- 存在缓存结果和标识,并且结果未失效,强制缓存生效,直接返回该结果
控制强制缓存的字段分别是Expires和Cache-Control,其中Cache-Control优先级比Expires高。
Expires
Expires是HTTP/1.0控制网页缓存的字段,其值为服务器返回该请求结果缓存的到期时间,即再次发起该请求时,如果客户端的时间小于Expires的值时,直接使用缓存结果。
Expires是HTTP/1.0的字段,但现在浏览器默认使用HTTP/1.1,那么HTTP/1.1中网页缓存是否还是由Expires控制?
到了HTTP/1.1,Expires已经被Cache-Control替代,原因在于Expires控制缓存的原理是使用客户端的时间和服务端返回的时间做对比,那么如果客户端与服务端的时间因为某些原因(例如时区)发送误差,那么强制缓存则会直接失效。
Cache-Control
在HTTP/1.1中,Cache-Control是最重要的规则,主要用于控制网页缓存,主要取值为:
public:所有内容都将被缓存(客户端/代理服务器/CDN等)private:只有客户端可以缓存,Cache-Control默认值no-cache:客户端缓存内容,但是是否使用缓存则需要经过协商缓存来验证决定no-store:所有内容都不会被缓存,即不使用强制缓存,也不使用协商缓存max-age=xxx:缓存将在xxx秒后失效
Cache-Control/Expires同时存在时,只有Cache-Control生效
”
协商缓存
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,有服务器根据缓存标识决定是否使用缓存的过程,主要有以下两种情况:
- 协商缓存生效,返回304,服务器告诉浏览器资源未更新,则再去浏览器缓存中访问资 源
- 协商缓存失效,返回200和请求结果
同样,协商缓存的标识也是在响应报文的HTTP头和请求结果一起返回给浏览器的,控制协商缓存的字段分别有:
Last-Modified/If-Modified-SinceEtag/If-None-Match
其中Etag/If-None-Match优先级比Last-Modified/If-Modified-Since高
Last-Modified/If-Modified-Since
Last-Modified是服务器响应请求时,返回该资源文件在服务器最后被修改的时间。
If-Modified-Since则是客户端再次发起该请求时,携带上次请求返回的Last-Modified值,通过此字段告诉服务器该资源上次请求返回的最后被修改时间。服务器收到该请求,发现请求头含有If-Modified-Since字段,则会根据If-Modified-Since的字段值与该资源在服务器的最后被修改时间做对比,若服务器的资源最后修改时间大于If-Modified-Since的字段值,则重新返回资源,状态码为200;否则返回304,代表资源无更新,可以继续使用缓存文件。
Etag/If-None-Match
Etag是服务器响应请求时,返回当前资源文件的一个唯一标识(由服务器生成)。
If-None-Match是客户端再次发起请求时,携带上次请求返回的唯一标识Etag值,服务端收到该请求后,发现该请求含有If-None-Match,则会根据If-None-Match的字段值与该资源在服务器的Etag值做对比,一致则返回304,代表资源无更新,继续使用缓存文件,否则重新返回资源,状态码为200.
总结
强制缓存优先于协商缓存,若强制缓存生效则直接使用缓存,若不生效则进行协商缓存,协商缓存由服务器决定是否使用缓存,若协商缓存失效,那么代表该请求的缓存失效,重新获取请求结果,再存入浏览器缓存中;生效则返回304,继续使用缓存。
11、为什么from表单提交没有跨域问题,但ajax有跨域问题
跨域限制的是从js里发起的请求,表单发起的请求并不需要js。
因为原页面用 form 提交到另一个域名之后,原页面的脚本无法获取新页面中的内容。
所以浏览器认为这是安全的。
而 AJAX 是可以读取响应内容的,因此浏览器不能允许你这样做。
如果你细心的话你会发现,其实请求已经发送出去了,你只是拿不到响应而已。
所以浏览器这个策略的本质是,一个域名的 JS ,在未经允许的情况下,不得读取另一个域名的内容。但浏览器并不阻止你向另一个域名发送请求。
第五部分:Vue
1、你知道Vue响应式数据原理吗?Proxy 与 Object.defineProperty 优劣对比
一、Proxy的优势如下:
1.Proxy可以直接监听对象⽽⾮属性 。
2.Proxy可以直接监听数组的变化 。
3.Proxy有多达13种拦截⽅法,不限于apply、ownKeys、deleteProperty、has等等是 Object.defineProperty 不具备的 。
4.Proxy返回的是⼀个新对象,我们可以只操作新的对象达到⽬的,⽽ Object.defineProperty 只能遍历对象属性直接修改。
5.Proxy作为新标准将受到浏览器⼚商重点持续的性能优化,也就是传说中的新标准的性能红利 。
二、Object.defineProperty的优势如下:
1.兼容性好,⽀持IE9。
2、Vue2.x组件通信有哪些方式
常见使用场景可以分为三类:
- 父子通信: 父向子传递数据是通过 props,子向父是通过 events(
$emit);通过父链 / 子链也可以通信( $parent / $children);ref 也可以访问组件实例;provide / inject API; $attrs/$listeners
- 兄弟通信: Bus;Vuex
- 跨级通信: Bus;Vuex;provide / inject API、
$attrs/$listeners
3、Vue 中的 computed 和 watch 的区别在哪里
计算属性computed :
\1. 支持缓存,只有依赖数据发生改变,才会重新进行计算
\2. 不支持异步,当computed内有异步操作时无效,无法监听数据的变化
3.computed 属性值会默认走缓存,计算属性是基于它们的响应式依赖进行缓存的,也就是基于data中声明过或者父组件传递的props中的数据通过计算得到的值
\4. 如果一个属性是由其他属性计算而来的,这个属性依赖其他属性,是一个多对一或者一对一,一般用computed
5.如果computed属性属性值是函数,那么默认会走get方法;函数的返回值就是属性的属性值;在computed中的,属性都有一个get和一个set方法,当数据变化时,调用set方法。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TdjJkslH-1649150971280)(https://img2018.cnblogs.com/blog/1402448/201908/1402448-20190809154932198-1444047098.png)]
侦听属性watch:
\1. 不支持缓存,数据变,直接会触发相应的操作;
2.watch支持异步;
3.监听的函数接收两个参数,第一个参数是最新的值;第二个参数是输入之前的值;
\4. 当一个属性发生变化时,需要执行对应的操作;一对多;
\5. 监听数据必须是data中声明过或者父组件传递过来的props中的数据,当数据变化时,触发其他操作,函数有两个参数,
immediate:组件加载立即触发回调函数执行,
deep: 深度监听,为了发现对象内部值的变化,复杂类型的数据时使用,例如数组中的对象内容的改变,注意监听数组的变动不需要这么做。注意:deep无法监听到数组的变动和对象的新增,参考vue数组变异,只有以响应式的方式触发才会被监听到。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cIQyOg2p-1649150971280)(https://img2018.cnblogs.com/blog/1402448/201908/1402448-20190809160441362-1201017336.png)]
监听的对象也可以写成字符串的形式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cLmRvRFZ-1649150971281)(https://img2018.cnblogs.com/blog/1402448/201908/1402448-20190809160648619-505189772.png)]
4、组件中的data为什么是一个函数
如果两个实例引用同一个对象,当其中一个实例的属性发生改变时,另一个实例属性也随之改变,只有当两个实例拥有自己的作用域时,才不会相互干扰。
这是因为JavaScript的特性所导致,在component中,data必须以函数的形式存在,不可以是对象。
组建中的data写成一个函数,数据以函数返回值的形式定义,这样每次复用组件的时候,都会返回一份新的data,相当于每个组件实例都有自己私有的数据空间,它们只负责各自维护的数据,不会造成混乱。而单纯的写成对象形式,就是所有的组件实例共用了一个data,这样改一个全都改了。
5、nextTick的实现原理是什么
官方文档对 nextTick 的功能如是说明:
在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。
// 修改数据
vm.msg = 'Hello'
// DOM 还没有更新
Vue.nextTick(function () {
// DOM 更新了
})
// 作为一个 Promise 使用 (2.1.0 起新增,详见接下来的提示)
Vue.nextTick()
.then(function () {
// DOM 更新了
})
2.1.0 起新增:如果没有提供回调且在支持 Promise 的环境中,则返回一个 Promise。请注意 Vue 不自带 Promise 的 polyfill,所以如果你的目标浏览器不原生支持 Promise (IE:你们都看我干嘛),你得自己提供 polyfill。
从上面的官方介绍中可以看到,nextTick 的主要功能就是更新数据后让回调函数作用于更新后的DOM 。看到这句话,你可能第一反应是:呸!说了等于没说,还是不理解。那么请看下面这个例子:
{{message}}
在上面例子中,当我们更新了message的数据后,立即获取vm.$el.innerHTML,发现此时获取到的还是更新之前的数据:123。但是当我们使用nextTick来获取vm.$el.innerHTML时,此时就可以获取到更新后的数据了。这是为什么呢?
这里就涉及到Vue中对DOM的更新策略了,Vue 在更新 DOM 时是异步执行的。只要侦听到数据变化,Vue 将开启一个事件队列,并缓冲在同一事件循环中发生的所有数据变更。如果同一个 watcher 被多次触发,只会被推入到事件队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的。然后,在下一个的事件循环“tick”中,Vue 刷新事件队列并执行实际 (已去重的) 工作。
在上面这个例子中,当我们通过 vm.message = ‘new message‘更新数据时,此时该组件不会立即重新渲染。当刷新事件队列时,组件会在下一个事件循环“tick”中重新渲染。所以当我们更新完数据后,此时又想基于更新后的 DOM 状态来做点什么,此时我们就需要使用Vue.nextTick(callback),把基于更新后的DOM 状态所需要的操作放入回调函数callback中,这样回调函数将在 DOM 更新完成后被调用。
OK,现在大家应该对nextTick是什么、为什么要有nextTick以及怎么使用nextTick有个大概的了解了。那么问题又来了,Vue为什么要这么设计?为什么要异步更新DOM?这就涉及到另外一个知识:JS的运行机制。
- 前置知识:JS的运行机制
我们知道 JS 执行是单线程的,它是基于事件循环的。事件循环大致分为以下几个步骤:
- 所有同步任务都在主线程上执行,形成一个执行栈(
execution context stack)。
- 主线程之外,还存在一个"任务队列"(
task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
- 一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
- 主线程不断重复上面的第三步。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DLPYPqUv-1649150971281)(http://image.bubuko.com/info/201909/20190929233900677000.png)]
主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是宏任务(macro task) 和微任务(micro task),并且每执行完一个个宏任务(macro task)后,都要去清空该宏任务所对应的微任务队列中所有的微任务(micro task),他们的执行顺序如下所示:
for (macroTask of macroTaskQueue) {
// 1. 处理当前的宏任务
handleMacroTask();
// 2. 处理对应的所有微任务
for (microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}
在浏览器环境中,常见的
- 宏任务(
macro task) 有 setTimeout、MessageChannel、postMessage、setImmediate;
- 微任务(
micro task)有MutationObsever 和 Promise.then。
OK,有了这个概念之后,接下来我们就进入本篇文章的正菜:从Vue源码角度来分析nextTick的实现原理。
- nextTick源码分析
nextTick 的源码位于src/core/util/next-tick.js,总计118行。
nextTick源码主要分为两块:
- 能力检测
- 根据能力检测以不同方式执行回调队列
4.1 能力检测
Vue 在内部对异步队列尝试使用原生的 Promise.then、MutationObserver 和 setImmediate,如果执行环境不支持,则会采用 setTimeout(fn, 0) 代替。
宏任务耗费的时间是大于微任务的,所以在浏览器支持的情况下,优先使用微任务。如果浏览器不支持微任务,使用宏任务;但是,各种宏任务之间也有效率的不同,需要根据浏览器的支持情况,使用不同的宏任务。
这一部分的源码如下:
let microTimerFunc
let macroTimerFunc
let useMacroTask = false
/* 对于宏任务(macro task) */
// 检测是否支持原生 setImmediate(高版本 IE 和 Edge 支持)
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
}
// 检测是否支持原生的 MessageChannel
else if (typeof MessageChannel !== 'undefined' && (
isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]'
)) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
}
// 都不支持的情况下,使用setTimeout
else {
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
/* 对于微任务(micro task) */
// 检测浏览器是否原生支持 Promise
if (typeof Promise !== 'undefined' && isNative(Promise)) {
const p = Promise.resolve()
microTimerFunc = () => {
p.then(flushCallbacks)
}
}
// 不支持的话直接指向 macro task 的实现。
else {
// fallback to macro
microTimerFunc = macroTimerFunc
}
首先声明了两个变量: microTimerFunc 和 macroTimerFunc ,它们分别对应的是 micro task 的函数和 macro task 的函数。对于 macro task 的实现,优先检测是否支持原生 setImmediate,这是一个高版本 IE 和Edge 才支持的特性,不支持的话再去检测是否支持原生的 MessageChannel,如果也不支持的话就会降级为 setTimeout 0;而对于 micro task 的实现,则检测浏览器是否原生支持 Promise,不支持的话直接指向 macro task 的实现。
4.2 执行回调队列
接下来就进入了核心函数nextTick中,如下:
const callbacks = [] // 回调队列
let pending = false // 异步锁
// 执行队列中的每一个回调
function flushCallbacks () {
pending = false // 重置异步锁
// 防止出现nextTick中包含nextTick时出现问题,在执行回调函数队列前,提前复制备份并清空回调函数队列
const copies = callbacks.slice(0)
callbacks.length = 0
// 执行回调函数队列
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}
export function nextTick (cb?: Function, ctx?: Object) {
let _resolve
// 将回调函数推入回调队列
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
// 如果异步锁未锁上,锁上异步锁,调用异步函数,准备等同步函数执行完后,就开始执行回调函数队列
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
// 如果没有提供回调,并且支持Promise,返回一个Promise
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}
首先,先来看 nextTick函数,该函数的主要逻辑是:先把传入的回调函数 cb 推入 回调队列callbacks 数组,同时在接收第一个回调函数时,执行能力检测中对应的异步方法(异步方法中调用了回调函数队列)。最后一次性地根据 useMacroTask 条件执行 macroTimerFunc 或者是 microTimerFunc,而它们都会在下一个 tick 执行 flushCallbacks,flushCallbacks 的逻辑非常简单,对 callbacks 遍历,然后执行相应的回调函数。
nextTick 函数最后还有一段逻辑:
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
这是当 nextTick 不传 cb 参数的时候,提供一个 Promise 化的调用,比如:
nextTick().then(() => {})
当 _resolve 函数执行,就会跳到 then 的逻辑中。
这里有两个问题需要注意:
-
如何保证只在接收第一个回调函数时执行异步方法?
nextTick源码中使用了一个异步锁的概念,即接收第一个回调函数时,先关上锁,执行异步方法。此时,浏览器处于等待执行完同步代码就执行异步代码的情况。
-
执行 flushCallbacks 函数时为什么需要备份回调函数队列?执行的也是备份的回调函数队列?
因为,会出现这么一种情况:nextTick 的回调函数中还使用 nextTick。如果 flushCallbacks 不做特殊处理,直接循环执行回调函数,会导致里面nextTick 中的回调函数会进入回调队列。
-
总结
以上就是对 nextTick 的源码分析,我们了解到数据的变化到 DOM 的重新渲染是一个异步过程,发生在下一个 tick。当我们在实际开发中,比如从服务端接口去获取数据的时候,数据做了修改,如果我们的某些方法去依赖了数据修改后的 DOM 变化,我们就必须在 nextTick 后执行。如下:
getData(res).then(()=>{
this.xxx = res.data
this.$nextTick(() => {
// 这里我们可以获取变化后的 DOM
})
})
6、说说你对keep-alive组件的了解
一、Keep-alive 是什么
keep-alive是vue中的内置组件,能在组件切换过程中将状态保留在内存中,防止重复渲染DOM
keep-alive 包裹动态组件时,会缓存不活动的组件实例,而不是销毁它们
keep-alive可以设置以下props属性:
- include - 字符串或正则表达式。只有名称匹配的组件会被缓存
- exclude - 字符串或正则表达式。任何名称匹配的组件都不会被缓存
- max - 数字。最多可以缓存多少组件实例
关于keep-alive的基本用法:
<keep-alive>
<component :is="view"></component>
</keep-alive>
123
使用includes和exclude:
<keep-alive include="a,b">
<component :is="view"></component>
</keep-alive>
<!-- 正则表达式 (使用 `v-bind`) -->
<keep-alive :include="/a|b/">
<component :is="view"></component>
</keep-alive>
<!-- 数组 (使用 `v-bind`) -->
<keep-alive :include="['a', 'b']">
<component :is="view"></component>
</keep-alive>
12345678910111213
匹配首先检查组件自身的 name 选项,如果 name 选项不可用,则匹配它的局部注册名称 (父组件 components 选项的键值),匿名组件不能被匹配
设置了 keep-alive 缓存的组件,会多出两个生命周期钩子(activated与deactivated):
- 首次进入组件时:beforeRouteEnter > beforeCreate > created> mounted > activated > … … > beforeRouteLeave > deactivated
- 再次进入组件时:beforeRouteEnter >activated > … … > beforeRouteLeave > deactivated
二、使用场景
使用原则:当我们在某些场景下不需要让页面重新加载时我们可以使用keepalive
举个栗子:
当我们从首页–>列表页–>商详页–>再返回,这时候列表页应该是需要keep-alive
从首页–>列表页–>商详页–>返回到列表页(需要缓存)–>返回到首页(需要缓存)–>再次进入列表页(不需要缓存),这时候可以按需来控制页面的keep-alive
在路由中设置keepAlive属性判断是否需要缓存
{
path: 'list',
name: 'itemList', // 列表页
component (resolve) {
require(['@/pages/item/list'], resolve)
},
meta: {
keepAlive: true,
title: '列表页'
}
}
1234567891011
使用
<div id="app" class='wrapper'>
<keep-alive>
<!-- 需要缓存的视图组件 -->
<router-view v-if="$route.meta.keepAlive"></router-view>
</keep-alive>
<!-- 不需要缓存的视图组件 -->
<router-view v-if="!$route.meta.keepAlive"></router-view>
</div>
12345678
三、原理分析
keep-alive是vue中内置的一个组件
源码位置:src/core/components/keep-alive.js
export default {
name: 'keep-alive',
abstract: true,
props: {
include: [String, RegExp, Array],
exclude: [String, RegExp, Array],
max: [String, Number]
},
created () {
那么代表该请求的缓存失效,重新获取请求结果,再存入浏览器缓存中;生效则返回304,继续使用缓存。
## 11、为什么from表单提交没有跨域问题,但ajax有跨域问题
跨域限制的是从js里发起的请求,表单发起的请求并不需要js。
因为原页面用 form 提交到另一个域名之后,原页面的脚本无法获取新页面中的内容。
所以浏览器认为这是安全的。
而 AJAX 是可以读取响应内容的,因此浏览器不能允许你这样做。
如果你细心的话你会发现,其实请求已经发送出去了,你只是拿不到响应而已。
所以浏览器这个策略的本质是,一个域名的 JS ,在未经允许的情况下,不得读取另一个域名的内容。但浏览器并不阻止你向另一个域名发送请求。
##
# 第五部分:Vue
## 1、你知道Vue响应式数据原理吗?Proxy 与 Object.defineProperty 优劣对比
**一、Proxy的优势如下:**
1.Proxy可以直接监听对象⽽⾮属性 。
2.Proxy可以直接监听数组的变化 。
3.Proxy有多达13种拦截⽅法,不限于apply、ownKeys、deleteProperty、has等等是 Object.defineProperty 不具备的 。
4.Proxy返回的是⼀个新对象,我们可以只操作新的对象达到⽬的,⽽ Object.defineProperty 只能遍历对象属性直接修改。
5.Proxy作为新标准将受到浏览器⼚商重点持续的性能优化,也就是传说中的新标准的性能红利 。
**二、Object.defineProperty的优势如下:**
1.兼容性好,⽀持IE9。
## 2、Vue2.x组件通信有哪些方式
常见使用场景可以分为三类:
- 父子通信: 父向子传递数据是通过 props,子向父是通过 events( `$emit`);通过父链 / 子链也可以通信( `$parent` / `$children`);ref 也可以访问组件实例;provide / inject API; `$attrs/$listeners`
- 兄弟通信: Bus;Vuex
- 跨级通信: Bus;Vuex;provide / inject API、 `$attrs/$listeners`
## 3、Vue 中的 computed 和 watch 的区别在哪里
**计算属性computed :**
\1. 支持缓存,只有依赖数据发生改变,才会重新进行计算
\2. 不支持异步,当computed内有异步操作时无效,无法监听数据的变化
3.computed 属性值会默认走缓存,计算属性是基于它们的响应式依赖进行缓存的,也就是基于data中声明过或者父组件传递的props中的数据通过计算得到的值
\4. 如果一个属性是由其他属性计算而来的,这个属性依赖其他属性,是一个多对一或者一对一,一般用computed
5.如果computed属性属性值是函数,那么默认会走get方法;函数的返回值就是属性的属性值;在computed中的,属性都有一个get和一个set方法,当数据变化时,调用set方法。
[外链图片转存中...(img-TdjJkslH-1649150971280)]
**侦听属性watch:**
\1. 不支持缓存,数据变,直接会触发相应的操作;
2.watch支持异步;
3.监听的函数接收两个参数,第一个参数是最新的值;第二个参数是输入之前的值;
\4. 当一个属性发生变化时,需要执行对应的操作;一对多;
\5. 监听数据必须是data中声明过或者父组件传递过来的props中的数据,当数据变化时,触发其他操作,函数有两个参数,
immediate:组件加载立即触发回调函数执行,
deep: 深度监听,为了发现**对象内部值**的变化,复杂类型的数据时使用,例如数组中的对象内容的改变,注意监听数组的变动不需要这么做。注意:deep无法监听到数组的变动和对象的新增,参考vue数组变异,只有以响应式的方式触发才会被监听到。
[外链图片转存中...(img-cIQyOg2p-1649150971280)]
监听的对象也可以写成字符串的形式
[外链图片转存中...(img-cLmRvRFZ-1649150971281)]
## 4、组件中的data为什么是一个函数
如果两个实例引用同一个对象,当其中一个实例的属性发生改变时,另一个实例属性也随之改变,只有当两个实例拥有自己的作用域时,才不会相互干扰。
这是因为JavaScript的特性所导致,在component中,data必须以函数的形式存在,不可以是对象。
组建中的data写成一个函数,数据以函数返回值的形式定义,这样每次复用组件的时候,都会返回一份新的data,相当于每个组件实例都有自己私有的数据空间,它们只负责各自维护的数据,不会造成混乱。而单纯的写成对象形式,就是所有的组件实例共用了一个data,这样改一个全都改了。
## 5、nextTick的实现原理是什么
官方文档对 `nextTick` 的功能如是说明:
在下次 `DOM` 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 `DOM`。
// 修改数据
vm.msg = ‘Hello’
// DOM 还没有更新
Vue.nextTick(function () {
// DOM 更新了
})
// 作为一个 Promise 使用 (2.1.0 起新增,详见接下来的提示)
Vue.nextTick()
.then(function () {
// DOM 更新了
})
> 2.1.0 起新增:如果没有提供回调且在支持 Promise 的环境中,则返回一个 Promise。请注意 Vue 不自带 Promise 的 polyfill,所以如果你的目标浏览器不原生支持 Promise (IE:你们都看我干嘛),你得自己提供 polyfill。
从上面的官方介绍中可以看到,`nextTick` 的主要功能就是更新数据后让回调函数作用于更新后的`DOM` 。看到这句话,你可能第一反应是:呸!说了等于没说,还是不理解。那么请看下面这个例子:
{{message}}
```
在上面例子中,当我们更新了message的数据后,立即获取vm.$el.innerHTML,发现此时获取到的还是更新之前的数据:123。但是当我们使用nextTick来获取vm.$el.innerHTML时,此时就可以获取到更新后的数据了。这是为什么呢?
这里就涉及到Vue中对DOM的更新策略了,Vue 在更新 DOM 时是异步执行的。只要侦听到数据变化,Vue 将开启一个事件队列,并缓冲在同一事件循环中发生的所有数据变更。如果同一个 watcher 被多次触发,只会被推入到事件队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的。然后,在下一个的事件循环“tick”中,Vue 刷新事件队列并执行实际 (已去重的) 工作。
在上面这个例子中,当我们通过 vm.message = ‘new message‘更新数据时,此时该组件不会立即重新渲染。当刷新事件队列时,组件会在下一个事件循环“tick”中重新渲染。所以当我们更新完数据后,此时又想基于更新后的 DOM 状态来做点什么,此时我们就需要使用Vue.nextTick(callback),把基于更新后的DOM 状态所需要的操作放入回调函数callback中,这样回调函数将在 DOM 更新完成后被调用。
OK,现在大家应该对nextTick是什么、为什么要有nextTick以及怎么使用nextTick有个大概的了解了。那么问题又来了,Vue为什么要这么设计?为什么要异步更新DOM?这就涉及到另外一个知识:JS的运行机制。
- 前置知识:JS的运行机制
我们知道 JS 执行是单线程的,它是基于事件循环的。事件循环大致分为以下几个步骤:
- 所有同步任务都在主线程上执行,形成一个执行栈(
execution context stack)。
- 主线程之外,还存在一个"任务队列"(
task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
- 一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
- 主线程不断重复上面的第三步。
[外链图片转存中…(img-DLPYPqUv-1649150971281)]
主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是宏任务(macro task) 和微任务(micro task),并且每执行完一个个宏任务(macro task)后,都要去清空该宏任务所对应的微任务队列中所有的微任务(micro task),他们的执行顺序如下所示:
for (macroTask of macroTaskQueue) {
//
��������������������������������������������������������������������











