mysql为什么要使用B+树作为索引
目录
1 概述
2 各种数据结构区别
2.1 hash表
2.2 二叉树
2.3 B树(B-树)
2.4 B+树
3 相关问题
1 概述
大家可能在面试的时候都会被问到这样一个问题:mysql的索引结构是什么?这个时候了解的都知道是B+树,那么为什么会采用B+树作为它的索引结构呢?
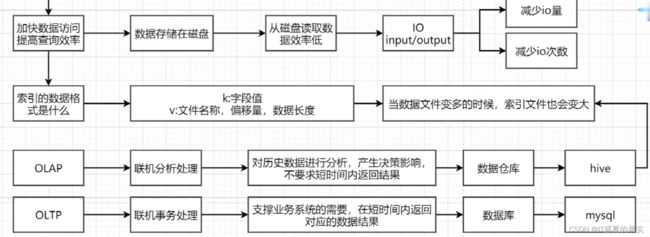
由图可以知道:索引的存在时为了加快数据访问提高查询效率的,而数据存储在磁盘中,但从磁盘读取数据会产生大量的IO操作,读取效率是非常低的。所以在读取的时候要减少io量和减少io次数来提高读取效率。那么存储k-v格式数据的时候需要使用什么数据格式呢?
哈希表?二叉树?红黑树?B树?还是B+树呢?结果肯定是B+树了,那么为什么会放弃其他的数据结构而单单选择B+树呢?
2 各种数据结构区别
2.1 hash表
hash表结构:

1)使用hash表的目的是为了尽可能的散列,因此在使用hash表的时候要选择hash算法,避免hash碰撞和hash冲突
2)hash表存储的数据是无序的,当需要进行范围查询的时候,只能挨个进行遍历对比,效率极低
3)mysql中的memory存储引擎支持hash索引,innodb存储引擎支持自适应hash
2.2 二叉树
二叉树,BST树(二叉搜索树)、AVL树、红黑树的特点:

二叉树结构(三层为例):
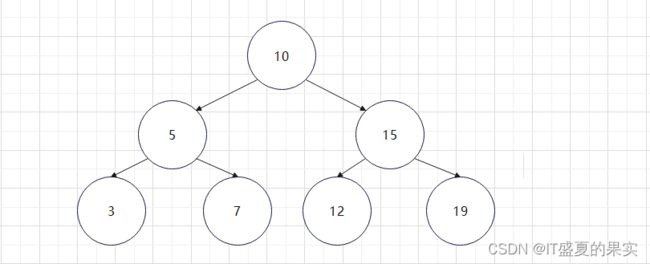
当二叉树为三层结构时,在存满的情况下,至多只能存储7条结果,如果想要存储更多的数据,只能将树的高度提高,变成4层或者5层甚至更多层,那么层数变多了相应的io次数也就变多了,那也就表示磁盘预读的操作也变多了。由于磁盘预读在数据读取的时候一般操作的都是页的整数倍,那么当我们存储的数据n层存储空间不够,还有一丁点数据也要在n+1层进行存储,那么我们的datapage就会变的非常大(因为它是页的整数倍),这样就极大的浪费了内存空间。所以二叉树并不适合作为索引的结构
磁盘预读:内存跟磁盘进行数据交互时候,有一个最基本的逻辑单位,称之为页或者叫做datapage,页的大小是跟操作系统相关的,一般是4k或者8k,我们在进行数据读取的时候一般操作的都是页的整数倍
2.3 B树(B-树)
当b树作为索引时的结构:

那磁盘块1举例:16,34表示具体的key值,data表示行数据,p1,p2,p3表示实际的指针。
如果需要读取28为key的这条数据时,读取顺序:
1 ,读取磁盘块1,拿16和34进行比较,发现在其中间,发现p2指针指向了磁盘块3
2,读取磁盘块3,拿25和31进行对比,发现在其中间,又发现p2指针执行了磁盘块8
3,读取磁盘块8,找到28对应数据,返回
注意:在mysql为Innodb的存储引擎里面,默认读取的大小是16kb的数据。而且三层的树桩结构可以发现里面占用太多内存的是data数据,这严重影响了我们存储数据的性能。所以B树也并不符合存储索引结构的特点
2.4 B+树
B+树是在B树的基础上做的一种优化:
1)B+树每个节点可以包含更多的节点,这样做的原因有两个,一是可以降低树的高度,二是将数据范围变为多个区间,区间越多,数据检索越快。
2)非叶子结点存储key,叶子结点存储key和数据
3)叶子结点两两指针相互连接(符合磁盘预读特性),顺序查询性能更高
B+树作为索引时结构:

注意:在B+树上有两个头指针,一个指向根节点,另一个指向关键字更小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此对B+树可以进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从跟节点开始,进行随机查找。
总结:
1)B+树的叶子结点是没有数据的,所以同样大小的磁盘可以容纳更多的节点元素。这就意味着(B+树会更加矮胖,查询的IO次数会更少)
2)B树的查找性能是不稳定的(如果查找的数据分别在根节点和叶子结点上,他们的性能就会不同)。但B树的每一次查询都是稳定的,因为所有的数据都存在叶子节点上
3)B+树上所有的叶子结点形成有序链表,便于范围查询
根节点:树的最顶端的节点
子节点:除根节点外,并且本身下面还连接有节点的节点
叶子节点:自己下面不在连接有节点的节点(即末端),称为叶子结点(又称为终端节点)。度为0
所以B+树结构能存储更多的数据,各适合作为存储mysql的索引结构。
3 相关问题
1)mysql中B+树的索引一般是几层
3层,还是4层,其实一般情况下:3~4层的B+树足以支撑千万级别的数据量存储
2)在存储过程中,谁的大小决定了能存储多大的数据
key的大小,key越小,存储的数据越多