自然语言处理中的预训练模型
这里写目录标题
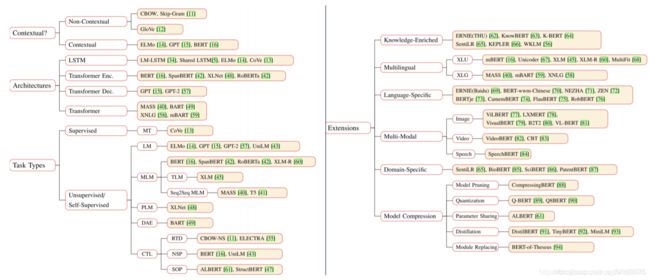
- 预训练模型分类体系
- 典型模型
-
- Bert
- SpanBert
- StructBert
- XLNet
- T5
- GPT-3
- 预训练模型的扩展
-
- Knowledge-Enriched PTMs
- Multilingual and Language-Specific PTMs
-
- Cross-Lingual Language Understanding(XLU)
- Cross-Lingual Language Generation(XLG)
- Language-Specific PTMs
- VL-Bert
- VideoBert
- 模型压缩
- 迁移到下游任务
-
- 选择适当的预训练任务,模型架构和语料库
- 选择合适的预训练模型的神经网络层
- 预训练模型的参数是否微调
- 句子分类变为句子对分类
- 集成Bert
- Self-Ensembel and Self-Distillation
- 未来展望
-
- 预训练模型的上界
- 预训练模型的架构
- 任务定向的预训练和模型压缩
- 除了微调之外的知识迁移
- 预训练模型的可解释性和可靠性
- fsatNLP
预训练模型分类体系
典型模型
Bert

Bert有两个训练任务,第一个任务是预测被mask的单词,第二个任务是句子级任务——句对预测。
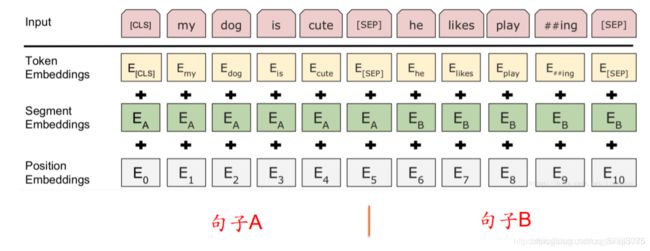
上述图片中有两个特殊的地方,在句子输入中添加了[CLS]和[SEP],[SEP]的作用是区分两句话,[CLS]用于捕捉全局信息;
当使用Bert进行分类任务时,直接在Bert上拼接一个分类器就能执行分类任务;
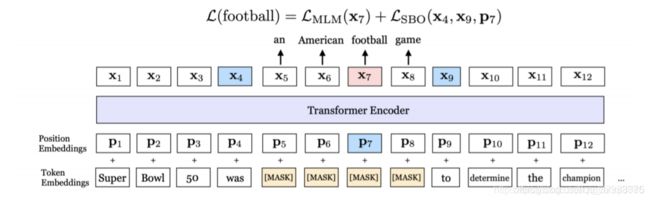
SpanBert
预测一个范围内的所有词;
去除NSP预训练任务;
StructBert

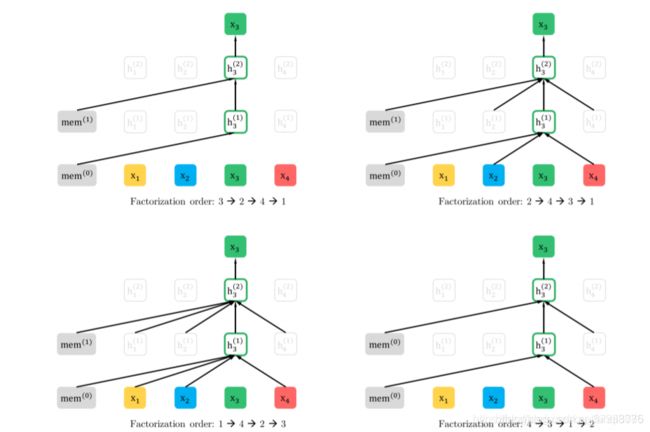
XLNet
T5
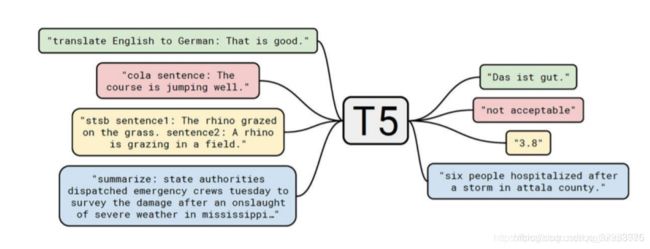
GPT-3

预训练模型的扩展
Knowledge-Enriched PTMs
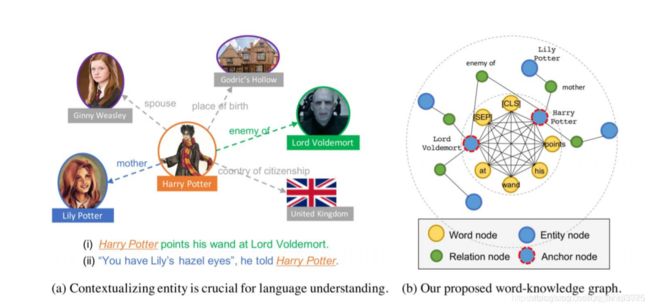
把知识图谱引进预训练模型中,如上图中,右图中的黄色内圈表示文本的全连接的图结构,在完全的图结构中把知识图谱的结构化信息引进来,这样就丰富了预训练模型的信息,除了可以获得文本的上下文信息,也可以获得知识图谱中的信息。
用类似于Bert的训练方式进行训练,如下所示:

Multilingual and Language-Specific PTMs
Cross-Lingual Language Understanding(XLU)
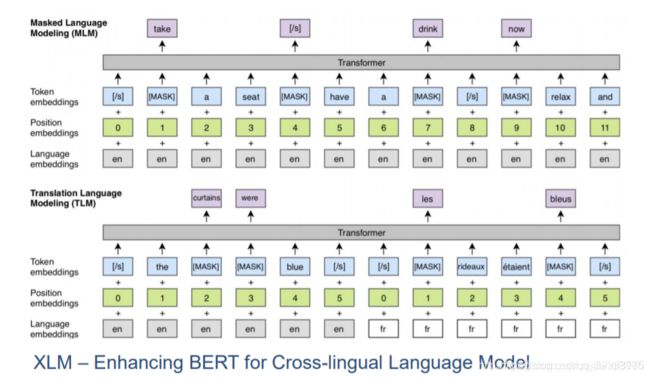
跨语言模型训练,例如XLM中句子对的前半句为英语句子,句子对中的后半句为法语句子,只需要在输入的时候给不同的句子加上不同的语言标记,如en或者fr;双语句子对中信息是冗余的,可以充分利用双语语料中的信息预测mask的词;
Cross-Lingual Language Generation(XLG)
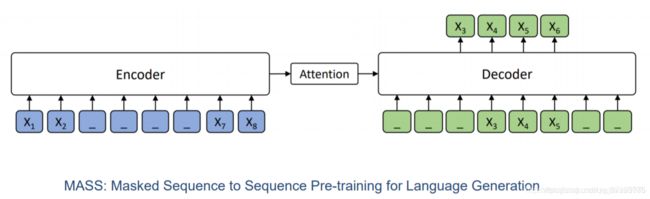
用类似于序列到序列的方法建模预训练模型,把训练句子中的一部分进行mask,放进Encoder中进行编码,然后在Decoder中将其预测出来;这个模型不同于Bert,Bert只使用Transformer中的Encoder部分,而MASS使用了整个Transformer结构;
可以看到,在MASS模型中,如果仅仅mask一个词,该模型可以近似看做Bert模型;如果把MASS中的所有词进行mask,这时候可以把MASS模型看做一个标准语言模型;

Language-Specific PTMs

原始Bert在进行中文预训练任务时是mask一个一个字,这样丢失了字与字之间的关联信息,ERNIE通过预测一个词捕捉句子中词的依赖关系,其得到的中文预训练模型效果更好;
VL-Bert
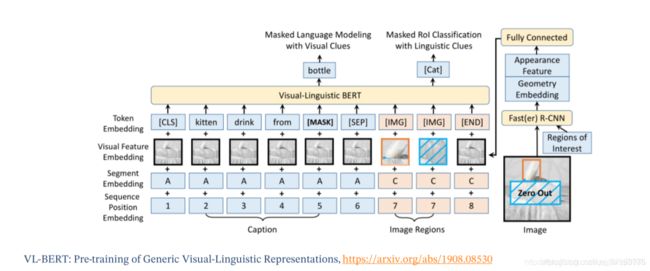
VideoBert
将文本和视频对作为BERT的输入,同时Mask词以及图像块

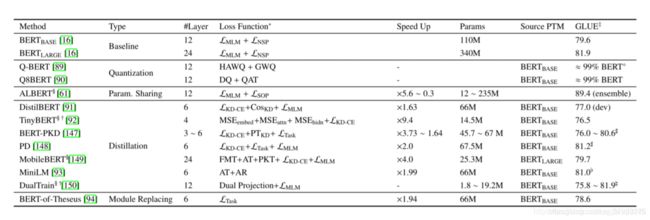
模型压缩
模型剪枝 —— 去掉一些不重要的参数;
权重矢量化 —— 使用简单的二值数表示参数;
参数共享;
知识蒸馏;
模块替换;
迁移到下游任务
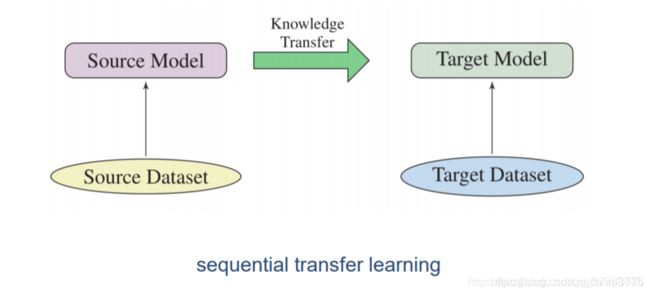
在预训练数据集上训练得到一个模型,将得到的模型迁移到下游任务中,这种是sequential transfer learning;
选择适当的预训练任务,模型架构和语料库
不同的预训练任务有自己的侧重方向,并且对不同的任务产生不同的影响;
预训练模型的结构同样对下游任务很重要;举个例子,bert模型对自然语言理解非常友好,但是对生成语言模型不大友好;
下游任务的数据分布需要和预训练模型的数据分布大体一致;
选择合适的预训练模型的神经网络层

预训练模型的参数是否微调
是否微调依赖于具体的任务,在ELMO中不进行微调效果更好,在Bert中进行微调效果更好;
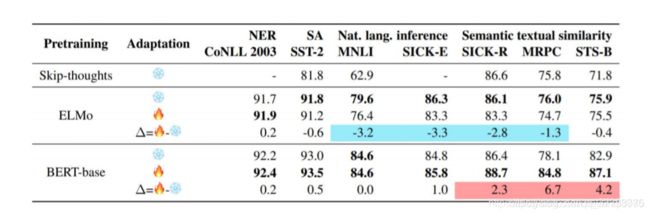
微调策略
-
多步迁移
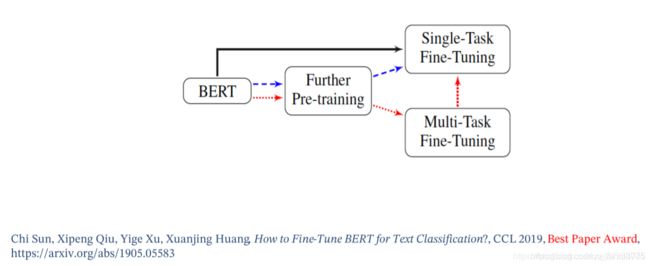
有两种方法,如上图,第一种是蓝色线方法,先预训练,接着在单一目标任务上进行微调;第二种方法是红色线方法,先预训练,然后在多任务数据集上进行微调,接着在单一目标任务上进行微调; -
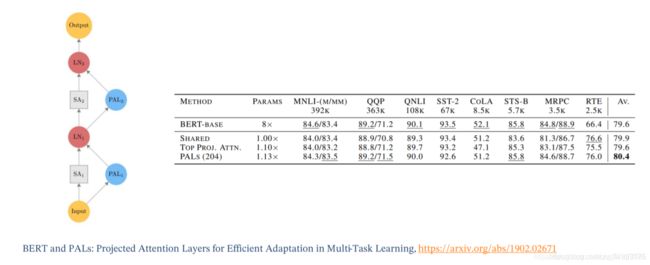
用额外的自适应模块进行微调
句子分类变为句子对分类
当标签含有语义信息时,将单句(single sentence)分类问题转换为句对(sentence-pair)分类。
集成Bert
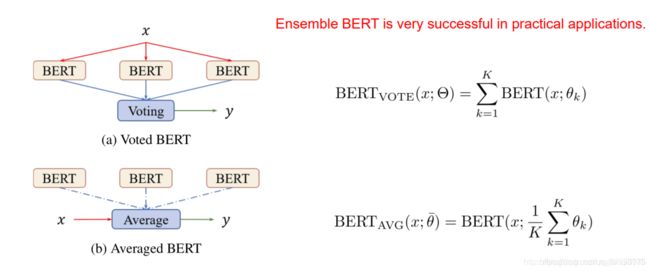
图(a)是将预测结果进行平均;图(b)是将多个Bert的参数进行平均,然后对输入x进行预测;
Self-Ensembel and Self-Distillation

未来展望
预训练模型的上界
预训练模型的架构
transformer已经被证明是一种有效的预训练模型结构,但是计算效率比较复杂,目前大部分预训练模型都不能处理序列长度大于512的文本;
为预训练模型寻找更有效的模型架构对于捕获更广泛的上下文信息很重要;
任务定向的预训练和模型压缩
预训练模型与下游任务之间的差异通常在于两个方面:
模型架构
数据分布
较大的差异可能会导致预训练模型的收益微不足道;
任务导向型预训练模型;
模型压缩
除了微调之外的知识迁移
当前,微调是将预训练模型的知识转移到下游任务的主要方法;
参数无效 ;
从预训练模型挖掘知识可以更加灵活,例如:
特征提取;
知识蒸馏;
数据增强;
将预训练模型作为额外知识;
预训练模型的可解释性和可靠性
fsatNLP
https://github.com/fastnlp/fastNLP
预训练模型综述论文:《Pre-trained Models for Natural Language Processing: A Survey》