面试完了,等offer。
推荐几个需要特别熟悉源码原理的框架,因为二面一般会问:Volley(比较老了)、Okhttp、Retrofit、DiskLruCache、Glide、热修复的框架、路由框架比如ARouter。这些一定要有两个特别特别熟悉。
分割线
持续更新答案,上一篇的36问等过两天工作定下来再写,下面的题目大家有兴趣去研究一下
先推荐一本android书,看完了Android基础技术面试都没问题
《Android开发艺术探索》任玉刚 著
1:简历上的每个点都仔细看一下实现原理和数据结构,为什么要用它实现,具体实现了什么,可以用别的吗?
Android里面的SparseArray,两个数组存放key和object
-
2:Activity各种交互的生命周期,能从源码解释一下吗,AMS等。
点击launcher上的app之后activity启动流程

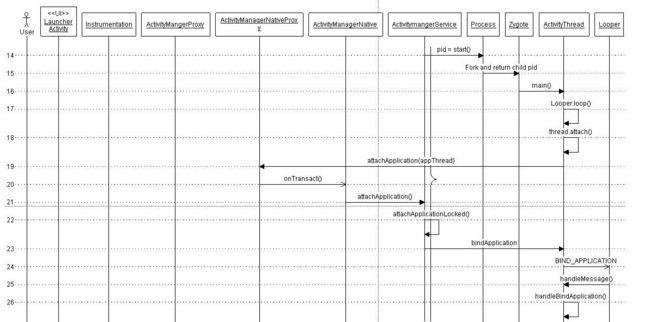
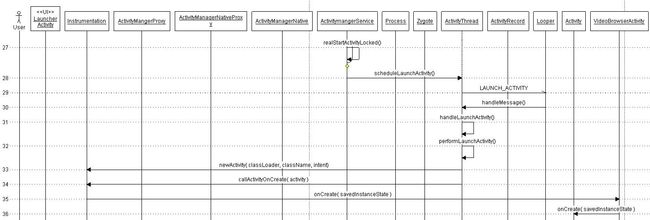
3:Android的插件化、热修补、Android的ClassLoader的相关原理,反射的原理,动态代理的两种方式是底层库的区别,都是运行时操作字节码。
-
4:setVisible与setGone区别,都会引起重绘吗,还是只是重新布局,layout之后一定会draw吗?requestLayout与invalidate与postInvalidate;
建议重新看一下View中的measure layout invalidate draw源码,各个标志为,setFrame是连接layout和draw的关键点,也是判断是否change的关键,如果change则measure layout draw都会执行,否则只是force_layout的话只会measure和layout
这一篇讲的这个方法的衔接讲的不错
invalidate方法,当子View调用了invalidate方法后,会为该View添加一个标记位,这个标记位是只是draw的标记位,因此measure、layout流程不会执行。同时不断向父容器请求刷新,父容器通过计算得出自身需要重绘的区域,直到传递到ViewRootImpl中,最终触发performTraversals方法,进行开始View树重绘流程(只绘制需要重绘的视图)。
requestLayout方法,会标记当前View及父容器,同时逐层向上提交,直到ViewRootImpl处理该事件,从measure开始,对于每一个含有标记位的view及其子View都会进行测量、布局,会不会执行draw方法,要看重绘过程中具体的判断。
一个执行draw,一个只执行measure和layout,draw不确定
view的方法:
public void requestLayout() {
if (mMeasureCache != null) mMeasureCache.clear();
if (mAttachInfo != null && mAttachInfo.mViewRequestingLayout == null) {
// Only trigger request-during-layout logic if this is the view requesting it,
// not the views in its parent hierarchy
ViewRootImpl viewRoot = getViewRootImpl();
if (viewRoot != null && viewRoot.isInLayout()) {
if (!viewRoot.requestLayoutDuringLayout(this)) {
return;
}
}
mAttachInfo.mViewRequestingLayout = this;
}
mPrivateFlags |= PFLAG_FORCE_LAYOUT;//强制layout的方法,设置父view的重新layout的标记。
mPrivateFlags |= PFLAG_INVALIDATED; //强制重绘的方法
if (mParent != null && !mParent.isLayoutRequested()) {
mParent.requestLayout();
}
if (mAttachInfo != null && mAttachInfo.mViewRequestingLayout == this) {
mAttachInfo.mViewRequestingLayout = null;
}
}
5:进程如何守护:广播,双进程,全家桶,如何跨进程通信,Binder跨进程的通信原理
6:AIDL的实现原理,创建方式,文件结构
7:动态代理
-
8:Volley与OkHttp区别,OkHttp3的特性,Http2.0是什么,有什么特性,Volley支持Https吗?HttpClient与HttpUrlConnection区别。SPDY协议具体做了什么?(SPDY之前有bug,连接复用的问题,如果一个连接阻塞,其他的连接也会等待,这块再查一查)
OKHTTP连接池!!
SPDY相关笔记:SPDY还是在应用层的优化
1:直到2008年,大部分浏览器才最终从每个域名2个连接发展到每个域名6个连接。
2:额外的初始客户请求;在HTTP协议中,只有客户端能初始化一个请求。尽管服务器知道客户端需要资源,但是它没有机制来通知客户端,而且必须等待客户端发来资源请求。(类似后面http2的请求html还给了js和css的例子),支持两种服务器推送和服务器暗示。
3:冗余和未压缩的头部。有一些头部在同一个信道的请求中多次发送,并且比较大未压缩
4:为了考虑未来的网络安全性,底层采用SSL作为传输层协议
5:为了克服网络带宽造成阻塞,客户端可以设置请求的优先级,在TCP的并行请求中,优先级高的先执行。
volley也支持Https,需要自己构造SSLSocketFactory;
Http各个版本:
HTTP/0.9
只接受GET一种请求方法,没有在通讯中指定版本号,且不支持请求头。由于该版本不支持POST方法,因此客户端无法向服务器传递太多信息。HTTP/1.0
这是第一个在通讯中指定版本号的HTTP协议版本,至今仍被广泛采用,特别是在代理服务器中HTTP/1.1
当前版本。持久连接被默认采用,并能很好地配合代理服务器工作。还支持以管道方式在同时发送多个请求,以便降低线路负载,提高传输速度。
其中1.1支持持久链接,而1.0默认开启新链接;
1.1版本增加Host域www.jianshu.com,1.0不支持,只能再建立Tcp连接时指定ip地址;
1.1版本增加的range(android的断点续传)能够get部分内容,状态码206防止缓存认为是完整对象。
1.1压缩传输数据,采用逐段编码:RFC 2616中14.41章节中定义的Transfer-Encoding: chunked的头信息,chunked编码定义在3.6.1中,所有HTTP1.1 应用都支持此使用trunked编码动态的提供body内容的长度的方式。进行Chunked编码传输的HTTP数据要在消息头部设置:Transfer-Encoding: chunked表示Content Body将用chunked编码传输内容。
1.1增加更多的状态码Http2.0
多路复用 (Multiplexing):允许通过同一Http2的连接发起多重请求/相应,而1.1有最大请求次数的限制;http2更容易实现多流并行,并且把通信基本单位定义为帧,可以并行在TCP上交换消息。
二进制分帧:在传输成和应用层之间加了帧层,把http的header和body都封装成frame流,用于双向数据流通信,过去的http主要优化TCP的慢启动特性,降低延迟,而不是提高带宽,所以复用连接的这种方式,正好利用了tcp启动中间阶段的较快窗口期。同时慢启动时间的减少,使拥塞和丢包恢复速度更快
头部压缩:HTTP/1.1并不支持 HTTP 首部压缩,为此 SPDY 和 HTTP/2 应运而生, SPDY 使用的是通用的DEFLATE(这个自己查查吧)算法,HTTP2使用了专门为压缩头部设计的HPACK算法;(额,为了看下DEFLATE算法,我复习了半小时的哈夫曼编码,为了面试,面试举例基本套路:网络请求->okhttp3->http2,spdy->区别->压缩算法->分别什么算法->哈夫曼演变而来,哈夫曼编码了解吗->哈夫曼树构造->前缀编码。。。。)
服务器端Push:客户端请求一次,服务器可以返回多个相应,比如请求html,服务器可以把相关的js和css都返回,并且这些可以缓存并共用。
-
9:websocket长连接实现原理,为什么要发心跳,局域网也需要心跳吗
为了解决http的频繁建立连接,无法服务器端push而生。
http1.1中的keep-alive是指多个http连接中可以实现多个request请求,但是一个request对应一个response
websocket也是基于http的,使用http协议来完成部分握手,握手请求头包含:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
Origin: http://example.com
服务器返回:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: HSmrc0sMlYUkAGmm5OPpG2HaGWk=
Sec-WebSocket-Protocol: chat
javax里可以实现websocket
@ServerEndpoint("/websocket") //这个注解可以标志为websocket服务
public class WebSocketTest
//再使用注解实现一系列方法 onOpen onClose onMessage等
@OnOpen
public void onOpen(Session session){
this.session = session;
webSocketSet.add(this); //加入set中
addOnlineCount(); //在线数加1
System.out.println("有新连接加入!当前在线人数为" + getOnlineCount());
}
-
10:RenrrentLock是怎么用的Condition怎么用的,与Synchronize区别。重新看一下之前写的例子
顺便提一下volatile,volatile只保证可见性,禁止并发重排序,1000个线程执行volatile类型的i++,结果不一定是1000.
synchronize主要保持两种特性,原子性(atomicity)和 可见性(visibility)。
1:synchronize代码块 使用的java代码在使用javap进行反编译class文件后能看出来

monitor是对于每个对象来说,每个对象都有一个自己的监视器锁,默认monitor计数为0,当执行monitorenter后,某个线程获取锁,对象的monitor加1,当该线程再次进入已获取锁的对象代码块,则再次加1,其他线程想使用该对象,只能等对象的monitor为0才能使用并再加1.只有获取monitor的线程才能操作monitor的相关方法,比如休眠,唤醒等等。
2:synchronize修饰方法,可以看到增加了ACC_SYNCHRONIZED标识符,JVM检测到该标识符,执行线程会获取monitor,本质是一样的,只是外表不一样。(reentrantLock底层也是操作对象的monitor,在lock1.lock后的线程A操作lock2的condition2.signal方法就会抛出ava.lang.IllegalMonitorStateException)

ReentrantLock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。RLock可以设置公平非公平。对象的监视器锁也是非公平锁。
lockInterruptibly可以实现可中断锁,lock.lockInterruptibly 而 lock.lock不可被中断。
Reentrant底层的AQS实现有一个state代表锁获取计数器,如果拥有锁的某个线程再次得到锁(是可重入的概念),那么获取计数器就加1,然后锁需要被释放两次才能获得真正释放,这里仿照了Synchronize的做法。lock必须在finally中释放,不然不会被释放。可实现 时间锁等候、 可中断锁等候、 无块结构锁、 多个条件变量 锁投票
condition可以用来通知具体的哪个线程开始执行,而synchronize中使用对象的notify方法只能告诉大家,这个对象可以被大家使用了,具体谁用这个决定不了,得看线程调度。condition则区分消费者的condition还是生产者的condition,分别调度。
-
11:LinearLayout与RelativeLayout区别,哪个方法的区别,onLayout还是onMeasure,relativeLayout为什么要重绘两次?
View的measure方法,优化了只有当forceLayout和needsLayout时才会走onMeasure,具体计算看源码,执行onMeasure一定会执行onLayout
view 的measure的方法
···
···
···
if (forceLayout || needsLayout) {
// first clears the measured dimension flag
mPrivateFlags &= ~PFLAG_MEASURED_DIMENSION_SET;
resolveRtlPropertiesIfNeeded();
int cacheIndex = forceLayout ? -1 : mMeasureCache.indexOfKey(key);
if (cacheIndex < 0 || sIgnoreMeasureCache) {
// 执行onMeasure方法。
onMeasure(widthMeasureSpec, heightMeasureSpec);
mPrivateFlags3 &= ~PFLAG3_MEASURE_NEEDED_BEFORE_LAYOUT;
} else {
long value = mMeasureCache.valueAt(cacheIndex);
// Casting a long to int drops the high 32 bits, no mask needed
setMeasuredDimensionRaw((int) (value >> 32), (int) value);
mPrivateFlags3 |= PFLAG3_MEASURE_NEEDED_BEFORE_LAYOUT;
}
// flag not set, setMeasuredDimension() was not invoked, we raise
// an exception to warn the developer
if ((mPrivateFlags & PFLAG_MEASURED_DIMENSION_SET) != PFLAG_MEASURED_DIMENSION_SET) {
throw new IllegalStateException("View with id " + getId() + ": "
+ getClass().getName() + "#onMeasure() did not set the"
+ " measured dimension by calling"
+ " setMeasuredDimension()");
}
mPrivateFlags |= PFLAG_LAYOUT_REQUIRED;//如果需要force layout就会设置 layout的标记位
}
LinearLayout的测量:
(1)如果我们在LinearLayout中不使用weight属性,将只进行一次measure的过程。
(2)如果使用了weight属性,LinearLayout在第一次测量时避开设置过weight属性的子View,之后再对它们做第二次measure。由此可见,weight属性对性能是有影响的。
RelativeLayout由于子view可以横向依赖也可以纵向依赖,所以会排序后绘制两次:
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
if (mDirtyHierarchy) {
mDirtyHierarchy = false;
sortChildren();
}
···
···
···
//横向排序的子view
View[] views = mSortedHorizontalChildren;
int count = views.length;
for (int i = 0; i < count; i++) {
View child = views[i];
if (child.getVisibility() != GONE) {
LayoutParams params = (LayoutParams) child.getLayoutParams();
int[] rules = params.getRules(layoutDirection);
applyHorizontalSizeRules(params, myWidth, rules);
measureChildHorizontal(child, params, myWidth, myHeight);
if (positionChildHorizontal(child, params, myWidth, isWrapContentWidth)) {
offsetHorizontalAxis = true;
}
}
}
//纵向排序的子view
views = mSortedVerticalChildren;
count = views.length;
final int targetSdkVersion = getContext().getApplicationInfo().targetSdkVersion;
for (int i = 0; i < count; i++) {
final View child = views[i];
if (child.getVisibility() != GONE) {
final LayoutParams params = (LayoutParams) child.getLayoutParams();
applyVerticalSizeRules(params, myHeight, child.getBaseline());
measureChild(child, params, myWidth, myHeight);
if (positionChildVertical(child, params, myHeight, isWrapContentHeight)) {
offsetVerticalAxis = true;
}
if (isWrapContentWidth) {
if (isLayoutRtl()) {
if (targetSdkVersion < Build.VERSION_CODES.KITKAT) {
width = Math.max(width, myWidth - params.mLeft);
} else {
width = Math.max(width, myWidth - params.mLeft - params.leftMargin);
}
} else {
if (targetSdkVersion < Build.VERSION_CODES.KITKAT) {
width = Math.max(width, params.mRight);
} else {
width = Math.max(width, params.mRight + params.rightMargin);
}
}
}
if (isWrapContentHeight) {
if (targetSdkVersion < Build.VERSION_CODES.KITKAT) {
height = Math.max(height, params.mBottom);
} else {
height = Math.max(height, params.mBottom + params.bottomMargin);
}
}
if (child != ignore || verticalGravity) {
left = Math.min(left, params.mLeft - params.leftMargin);
top = Math.min(top, params.mTop - params.topMargin);
}
if (child != ignore || horizontalGravity) {
right = Math.max(right, params.mRight + params.rightMargin);
bottom = Math.max(bottom, params.mBottom + params.bottomMargin);
}
}
}
···
···
···
-
12:JVM回收时,GCRoot的时候怎么查找根节点,可以选取那些区域作为参照点(这个问题有点懵逼…)其实就是普通gc不会回收的即可,比如直接内存,栈、方法区这些。
Jvm新建对象时的内存分配:new的时候,首先检查常量池中有类的符号引用,并且检查这个符号引用代表的类是否已经被加载、解析、初始化。然后在堆上分配内存:
- (1)假设java堆上的内存绝对规整,采用指针碰撞即对象指针在内存上挪动与对象大小一样的距离。
- (2)java堆不是规整的,虚拟机需要维护一个列表,并实时更新块内存可用,哪块不可用,称为“空闲列表”;jvm采用哪种取决于垃圾收集器是否带有压缩整理的功能。
分配内存时还需考虑多线程问题,采用两种方案:(1)采用CAS分配内存 (2)使用线程中的本地线程分配缓冲(TLAB),先分配到TLAB上,当需要新的TLAB时才会加锁。
可作为GC root的点:
- (1)虚拟机栈(栈帧中的本地变量表)中引用的对象
- (2)方法区中的静态属性引用对象。
- (3)方法区中的常量引用对象。(被final修饰的变量会变成常量,存在常量区)
- (4)本地方法栈中的JNI中的引用对象。
13:动态规划基本问题。
-
14:RecyclerView与ListView区别,除了更灵活,从源码层解释,回收机制有什么区别。
回收机制差别
区别:
- 1:recyclerView方便的实现横向、纵向及瀑布流,大大降低耦合性,功能上更强大
- 2:Recycler具有局部刷新功能
- 3:两者的回收机制不同,listview两级缓存,mActiveViews缓存(屏幕内的itemview直接重用),mScrapViews缓存,该缓存中取出后不再执行createview,但必须执行getView();
RecyclerView4级缓存,mAttachedViews(屏幕内的itemview直接重用);mCachedView(缓存屏幕外的两个itemview,也可以拿出直接用,默认上限2);mCacheExtensionViews默认不实现,需要用户自己重写;mRecyclerPool缓存池,取出缓存后直接执行bindView(),缓存池默认上限是5,技术上可以实现多个recyclerview共用一个recyclerpool。
ListView和RecyclerView最大的区别在于数据源改变时的缓存的处理逻辑,ListView是"一锅端",将所有的mActiveViews都移入了二级缓存mScrapViews,而RecyclerView则是更加灵活地对每个View修改标志位,区分是否重新bindView。
15:JNI中的ENV指针是线程安全还是进程安全
-
16:对比Glide与Picasso
推荐不错的讲解文章
Glide支持GIF,Picasso不支持
Glide会为同一图片缓存多种imageView尺寸,Picasso只会缓存一种原图
Glide ARGB565 Picasso ARGB8888
-
17:为什么ScrollView嵌套RecyclerView会有问题,从源码绘制的角度解释ScrollView如何绘制子布局。
ScrollView测量不一样的地方,这就是为什么嵌套ListView或者RecyclerView会出问题,绘制不全
@Override
protected void measureChildWithMargins(View child, int parentWidthMeasureSpec, int widthUsed,
int parentHeightMeasureSpec, int heightUsed) {
final MarginLayoutParams lp = (MarginLayoutParams) child.getLayoutParams();
final int childWidthMeasureSpec = getChildMeasureSpec(parentWidthMeasureSpec,
mPaddingLeft + mPaddingRight + lp.leftMargin + lp.rightMargin
+ widthUsed, lp.width);
final int usedTotal = mPaddingTop + mPaddingBottom + lp.topMargin + lp.bottomMargin +
heightUsed;
final int childHeightMeasureSpec = MeasureSpec.makeSafeMeasureSpec(
Math.max(0, MeasureSpec.getSize(parentHeightMeasureSpec) - usedTotal),
MeasureSpec.UNSPECIFIED);//这里出现了不常见的MeasureSpec.UNSPECIFIED,也是重写了ViewGroup里的MeasureChildWithMargins
child.measure(childWidthMeasureSpec, childHeightMeasureSpec);
}
-
18:Http各种Code解释:
201-206都表示服务器成功处理了请求的状态代码,说明网页可以正常访问。 200(成功) 服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。 201(已创建) 请求成功且服务器已创建了新的资源。 202(已接受) 服务器已接受了请求,但尚未对其进行处理。 203(非授权信息) 服务器已成功处理了请求,但返回了可能来自另一来源的信息。 204(无内容) 服务器成功处理了请求,但未返回任何内容。 205(重置内容) 服务器成功处理了请求,但未返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如清除表单内容以输入新内容)。 206(部分内容) 服务器成功处理了部分 GET 请求。 300-3007表示的意思是:要完成请求,您需要进一步进行操作。通常,这些状态代码是永远重定向的。 300(多种选择) 服务器根据请求可执行多种操作。服务器可根据请求者 来选择一项操作,或提供操作列表供其选择。 301(永久移动) 请求的网页已被永久移动到新位置。服务器返回此响应时,会自动将请求者转到新位置。您应使用此代码通知搜索引擎蜘蛛网页或网站已被永久移动到新位置。 302(临时移动) 服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。会自动将请求者转到不同的位置。但由于搜索引擎会继续抓取原有位置并将其编入索引,因此您不应使用此代码来告诉搜索引擎页面或网站已被移动。 303(查看其他位置) 当请求者应对不同的位置进行单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。 304(未修改) 自从上次请求后,请求的网页未被修改过。服务器返回此响应时,不会返回网页内容。 如果网页自请求者上次请求后再也没有更改过,您应当将服务器配置为返回此响应。由于服务器可以告诉 搜索引擎自从上次抓取后网页没有更改过,因此可节省带宽和开销。 305(使用代理) 请求者只能使用代理访问请求的网页。如果服务器返回此响应,那么,服务器还会指明请求者应当使用的代理。 307(临时重定向) 服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。会自动将请求者转到不同的位置。但由于搜索引擎会继续抓取原有位置并将其编入索引,因此您不应使用此代码来告诉搜索引擎某个页面或网站已被移动。 4XXHTTP状态码表示请求可能出错,会妨碍服务器的处理。 400(错误请求) 服务器不理解请求的语法。 401(身份验证错误) 此页要求授权。您可能不希望将此网页纳入索引。 403(禁止) 服务器拒绝请求。 404(未找到) 服务器找不到请求的网页。例如,对于服务器上不存在的网页经常会返回此代码。 例如:http://www.0631abc.com/20100aaaa,就会进入404错误页面 405(方法禁用) 禁用请求中指定的方法。 406(不接受) 无法使用请求的内容特性响应请求的网页。 407(需要代理授权) 此状态码与 401 类似,但指定请求者必须授权使用代理。如果服务器返回此响应,还表示请求者应当使用代理。 408(请求超时) 服务器等候请求时发生超时。 409(冲突) 服务器在完成请求时发生冲突。服务器必须在响应中包含有关冲突的信息。服务器在响应与前一个请求相冲突的 PUT 请求时可能会返回此代码,以及两个请求的差异列表。 410(已删除) 请求的资源永久删除后,服务器返回此响应。该代码与 404(未找到)代码相似,但在资源以前存在而现在不存在的情况下,有时会用来替代 404 代码。如果资源已永久删除,您应当使用 301 指定资源的新位置。 411(需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。 412(未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。 413(请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。 414(请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。 415(不支持的媒体类型) 请求的格式不受请求页面的支持。 416(请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态码。 417(未满足期望值) 服务器未满足"期望"请求标头字段的要求。 500至505表示的意思是:服务器在尝试处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错。 500(服务器内部错误) 服务器遇到错误,无法完成请求。 501(尚未实施) 服务器不具备完成请求的功能。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。 502(错误网关) 服务器作为网关或代理,从上游服务器收到了无效的响应。 503(服务不可用) 目前无法使用服务器(由于超载或进行停机维护)。通常,这只是一种暂时的状态。 504(网关超时) 服务器作为网关或代理,未及时从上游服务器接收请求。 505(HTTP 版本不受支持) 服务器不支持请求中所使用的 HTTP 协议版本。