微信公众号Python开发(Wechatpy+新浪云SAE应用)
微信公众号Python开发(Wechatpy)
前言:微信公众号后台只提供指定条件的指定回复,如果想有聊天、翻译、查询、后台数据库等则需要使用公众号提供的接口开发脚本。开发工具语言选择诸多,Python+Web框架是较为快捷的,这也是我第一个web框架练手项目。
准备工作
注册两个平台:微信公众号和新浪云(ps:微信订阅号和小程序是不同账号,并且长期不等录会冻结),这里选择新浪云的云应用也可用其他平台的云应用,细节差别看其文档。
关于云平台分类 IaaS(Infrastructure-as-a- Service):基础设施即服务 消费者通过Internet可以从完善的计算机基础设施获得服务。
换成我们通常理解的内容来讲就是我们不用购置硬件(服务器、存储等),不用去考虑如何把服务器连上网,只需要我们购买IaaS服务就可以使用这些硬件的服务。国外的代表服务商Amazon EC2
PaaS(Platform-as-a- Service):平台即服务。PaaS实际上是指将软件研发的平台作为一种服务,以SaaS的模式提交给用户。
这里的平台换成我们理解的就是应用程序运行所需要的环境,如果我们部署PHP开发程序就需要有Apache等引擎支持。用Java的需要Tomcat等支持。国外的代表服务商Google GAE
SaaS(Software-as-a- Service):软件即服务。它是一种通过Internet提供软件的模式,用户无需购买软件,而是向提供商租用基于Web的软件,来管理企业经营活动。
这里的软件即服务,举例子说我们用的QQ 邮箱 其实就是一种SaaS服务。企业市场常用的在线CRM系统也是。国外的代表服务商Salesforce。
IaaS:阿里云 亚马逊云 腾讯云
PaaS:新浪云 百度云百度开放云平台
IaaS和PaaS的区别: IaaS其实提供的就是服务器,用户可以自行在服务器安装配置各种软件环境。可以很灵活的实现各种功能。
PaaS目前主要是WEB环境的应用,通常支持PHP、Java、Python和GO语言。必须在云计算服务商的框架内开发。 IaaS需要自己搭建程序运行环境,优势是灵活,缺点就是需要自己配置。 PaaS不需要自己做环境配置,缺点是必须使用指定的开发语言,遵循平台的开发规范。
如果开发的应用不是用PHP、Java、Python语言。建议使用阿里云的服务。如果是上述语言的WEB服务,可以考虑使用新浪云、百度云等。
价格:PaaS比IaaS便宜,SAE和BAE都有免费配额。
{% asset_img 创建sae.png 图片加载失败的描述 %}
第一个SAE应用HelloWorld
-
创建新浪云新SAE应用:作为测试项目选择个收费最少的,其他都是按时间计费至少10+/月,应用名(项目名)就是那个二级域名填的,下面那个名称没啥用。
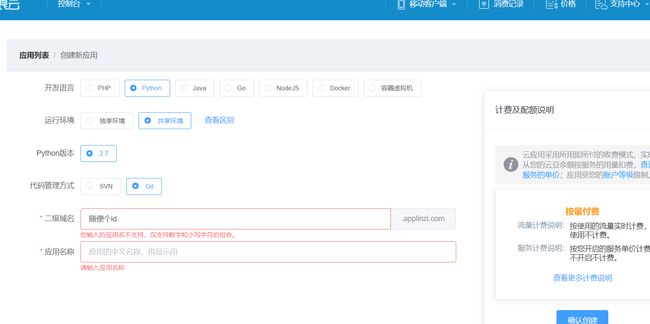
- 理解前后端交互**(选):此时你相当于有了一个服务器但它只提供两个端口80/443给你运行python的web框架,这样就相当于Apache+php(能处理前后端)的作用(其他语言开发目的也是如此),当然数据库也可以供他们调用。
而微信公众号会给你发Get请求验证不是其他来源的信息,而用户消息会转换为Post请求,python后端需要处理这类请求,这就是开发过程。
- 理解前后端交互**(选):此时你相当于有了一个服务器但它只提供两个端口80/443给你运行python的web框架,这样就相当于Apache+php(能处理前后端)的作用(其他语言开发目的也是如此),当然数据库也可以供他们调用。
-
创建项目文件夹:先在 运行环境下->代码管理 中创建新版本(数字就是个代号)
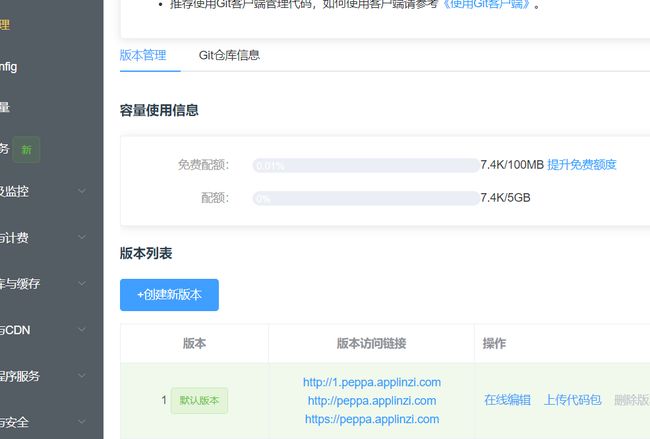
再把初始的项目文件夹克隆(下载)到本地:(需要安装Git)
在bash(命令行)中
git clone https://git.sinacloud.com/你的应用名这里我的是peppa,此时会得到一个在当前目录下产生一个和应用名同名文件夹。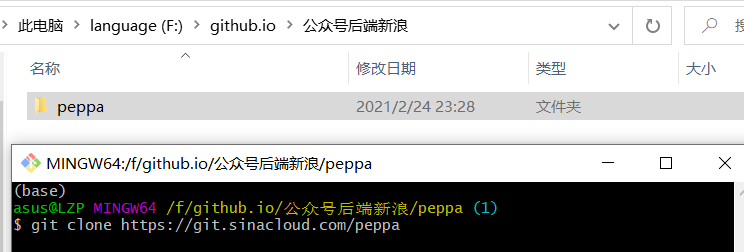
加深理解:可以把每个SAE应用视为GitHub一个仓库,和GitHub一样可以先创建版本再clone到本地(过程中可能需要密码,输错在windows设置中删除凭据),也可以先本地init再添加remote进行push。默认版本就是主分支。如果不会Git可以本地写好程序上传代码包(在线编辑非常辣鸡),这样就将程序上传到SAE,并且不需要你自己运行(运行方式在下面)。
-
Coding:此文件夹中需要新建
index.wsgi,新浪云上的 Python 应用的入口为index.wsgi:application,也就是这个文件中名为 application 的 callable object。# -*- coding: utf-8 -*- #记得加上这个编码,在平时本地写也许没问题但在这个环境下第一二行的作用体现出来了 import sae def app(environ, start_response): status = '200 OK' response_headers = [('Content-type', 'text/plain')] start_response(status, response_headers) return ['Welcom to SAE!'] application = sae.create_wsgi_app(app)此时文件还在本地,可以在控制台直接上传代码包也可以通过Git上传(推荐):
jaime@westeros:~/peppa$ git add . jaime@westeros:~/peppa$ git commit -m 'create app' jaime@westeros:~/peppa$ git push当需要使用python的包或者指定提交的版本时,需要在同级目录下创建应用配置文件 config.yaml ,内容如下:这里libraries下包含需要的包
name: peppa version: 1 libraries: - name: 'lxml' version: '1.4' -
浏览器访问应用80/443端口如
https://peppa.applinzi.com/是你设置的二级域名
使用Web框架开发
- Python的Web框架非常多,官方文档也很丰富,我们选择一个易入门的web.py进行示例开发
-
Web框架完成处理类,先新建一个Wxinterface.py文件,内容如下:
import hashlib import web import lxml import time import os import urllib2,json from lxml import etree # import wechatpy class WeixinInterface: def __init__(self): self.app_root = os.path.dirname(__file__) self.templates_root = os.path.join(self.app_root, 'templates') self.render = web.template.render(self.templates_root) def GET(self): #专门写给公众号验证的 try: #获取输入参数 data = web.input() signature=data.signature timestamp=data.timestamp nonce=data.nonce echostr=data.echostr #自己的token token="xgD3R7" #随便一个字符串但和在微信公众平台里输入的token一致 #字典序排序 lists=[token,timestamp,nonce] lists.sort() sha1=hashlib.sha1() map(sha1.update,lists) hashcode=sha1.hexdigest() #sha1加密算法 #如果是来自微信的请求,则回复echostr if hashcode == signature: return echostr else: return "" except Exception,Argument: return Argument def POST(self): str_xml = web.data() #获得post来的数据 xml = etree.fromstring(str_xml)#进行XML解析 content=xml.find("Content").text#获得用户所输入的内容 msgType=xml.find("MsgType").text fromUser=xml.find("FromUserName").text toUser=xml.find("ToUserName").text return self.render.reply_text(fromUser,toUser,int(time.time()),u"我现在还在开发中,还没有什么功能,您刚才说的是:"+content)其中的Get用来微信验证(这是官网文档定义的算法),Post是接受Post请求的处理,再更改文件index.wsgi:
import os import sae import web from Wxinterface import WeixinInterface urls = ( '/','WeixinInterface' ) app_root = os.path.dirname(__file__) templates_root = os.path.join(app_root, 'templates') render = web.template.render(templates_root) app = web.application(urls, globals()).wsgifunc() application = sae.create_wsgi_app(app)因为更改了两个文件,此时需要更新云端代码,使用之前示例的Git三连进行提交。访问二级域名如
https://peppa.applinzi.com返回signature说明正常,报import错误就改config.yaml。 -
微信公众号配置:之前注册了微信公众号订阅号,现在进入微信管理后台,选择 开发-》基本配置
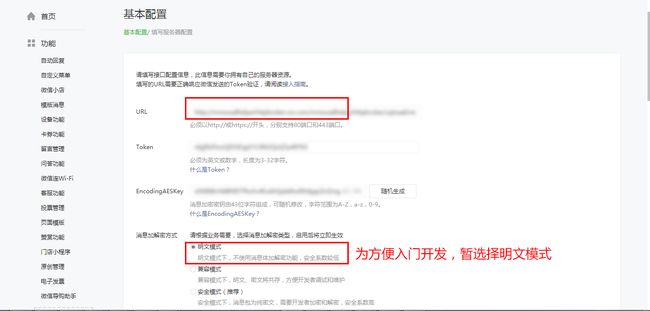
这个token就是上面Get方法中的那个,而URL是上面你填写的二级域名形如
https://peppa.applinzi.com。在代码更新后点击提交就可配置成功测试。
安装Wechatpy并完成两个功能
介绍并安装
-
之前的wechat停止开发了换成这个,让你可以专注于业务逻辑本身,而不是浪费精力在与微信服务器复杂的交互中(含处理交互的抽象函数)。文档
-
现在还有一个问题,预置的库可以通过config文件使用,但使用requests等第三方库就需要自己下载到项目一起提交。先在项目根目录下新建文件夹如vendor,用pip下载到其中
import sae sae.add_vendor_dir('放库的目录这里是vendor') #!以上代码需要放在index.wsgi最开头PS:安装wechatpy只需想上图一样,把requests换成wechatpy。
-
不出意外此时你访问二级域名会看到报错
No module enum也就是没有这个包,这是因为上面使用的Python是2.7,在pypi官方源搜索发现这个包在python3已经变成标准库,而Wechatpy这个库又需要,我们只能想办法搞到vendor里,最简单的想法是直接pip下载enum,这样又会报错'enum' has no attribute 'IntFlag'。这是因为我们本地下载使用的pip是3.x的。- 想到可以下载源码解压复制过去,也可以专门安装Python2或者pip2来下载enum,但问题出现了,这样下载的都是Python2的库,里面没有wechatpy需要的代码。
-
还是得用python3的enum,刚好Pipy里有个enum34可以兼容,可以直接用pip3安装到vendor:
pip install -t vendor enum34可以解决报错,此时访问二级域名无此报错即可
复读机
-
在
import wechatpy后还有个版本bug,就是cryptography模块的导入问题会引发捕获,这是因为模块还是得找个python2能用的(最好可以用pip3安装),去官网找历史版本果然有,下载Linux的whl文件(SAE系统是Red Hat),下载到项目后pip install -t vendor ***.whl即可,另外我们是明文传输不用加密也可以把import报错语句删除不管这个库。 -
在使用wechatpy之后,Get方法中的验证就很简单了,验证算法不用计算了。
from wechatpy.utils import check_signature def GET(self): #专门写给公众号验证的 try: #获取输入参数 data = web.input() signature=data.signature timestamp=data.timestamp nonce=data.nonce echostr=data.echostr token="123456" #这里改写你在微信公众平台里输入的token check_signature(token,signature,timestamp,nonce) return echostr except Exception,Argument: return Argument -
复读功能很简单直接写出来:
from wechatpy import parse_message from wechatpy.replies import TextReply,create_reply def POST(self): str_xml = web.data() #这是请求的数据(来自用户发给公众号) msg = parse_message(str_xml) if msg.type == "text": reply = create_reply(msg.content,msg) #返回xml return reply.render()
How-old 基于微软年龄识别的API
-
通过抓包可以看到这个API是个简单的Post请求,我们在收到客户发送图片后,拿图片url查询后解析字符串返回。我们专门写个函数来测试API,传入url返回解析。
# -*- coding: utf-8 -*- import requests import re def imgtest(picurl): s = requests.session() url = 'https://www.how-old.net/Home/Analyze?isTest=False&source&version=www.how-old.net' header = { 'Accept-Encoding':'gzip, deflate', 'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0", # 'Host': "how-old.net",这个host改了还用这个会301 'Referer': "http://how-old.net/", 'X-Requested-With': "XMLHttpRequest" } # data = {'file':s.get(picurl).content} #data = {'file': open(sid+'.jpg', 'rb')} #此处打开指定的jpg文件 # r = s.post(url,data=data, headers=header,allow_redirects=False) r = s.post(url+'&faceUrl='+picurl, headers=header,allow_redirects=False) h = r.content.decode() # i = h.replace('\\n','').replace('\\r','') i = h.replace('\\','') # print(i)没有办法json化 # import json # datajson = json.loads(i) # print(datajson) #j = eval(i) gender = re.search(r'"gender": "(.*?)"rn', i) age = re.search(r'"age": (.*?),rn', i) if gender.group(1) == 'Male': ender1 = '男' else: gender1 = '女' #print gender1 #print age.group(1) datas = [gender1, age.group(1)] return datas data = imgtest('一个含人脸的图片url') print(data) #返回年龄性别现在直接在POST函数中,判断是图片类型就返回:
def POST(self): str_xml = web.data() msg = parse_message(str_xml) if msg.type == "text": if msg.content == "gg": reply = TextReply("回复内容,好难调试bug以后换flask",msg) else: reply = create_reply(msg.content,message=msg) elif msg.type=="image": picurl = msg.image replay = create_reply((picurl),msg) else: replay = create_reply("sorry, can not handle this type for now",msg) #怎么在web框架下用 return reply.render()
总结
这个项目调试比较麻烦,如果是GET函数和大的语法错误还好,可以通过访问二级域名看到,但POST函数有bug就难以发现,编译错误看不到。后面换成Flask框架效果会更好,另外还有个WeRobot库可以用,总之微信公众号开发文档比较丰富可以自己解决问题。