深度学习-自然语言处理(NLP):Q&A
一、神经网络
1、简述几种自然语言处理开源工具包
LingPipe、FudanNLP、OpenNLP、CRF++、Standord CoreNLP、IKAnalyzer
2、比较Boosting和Bagging的异同
二者都是集成学习算法,都是将多个弱学习器组合成强学习器的方法。
Bagging:从原始数据集中每一轮有放回地抽取训练集,训练得到k个弱学习器,将这k个弱学习器以投票的方式得到最终的分类结果。
Boosting:每一轮根据上一轮的分类结果动态调整每个样本在分类器中的权重,训练得到k个弱分类器,他们都有各自的权重,通过加权组合的方式得到最终的分类结果。
3、卷积神经网络CNN中池化层有什么作用?
减小图像尺寸即数据降维,缓解过拟合,保持一定程度的旋转和平移不变性。
4、卷积神经网络CNN中池化层有什么作用?
减小图像尺寸即数据降维,缓解过拟合,保持一定程度的旋转和平移不变性。
5、神经网络中Dropout的作用?具体是怎么实现的?
防止过拟合。每次训练,都对每个神经网络单元,按一定概率临时丢弃。
6、解释下卷积神经网络中感受野的概念?
在卷积神经网络中,感受野 (receptive field)的定义是 卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
7、梯度爆炸的解决方法?
针对梯度爆炸问题,解决方案是引入Gradient Clipping(梯度裁剪)。通过Gradient Clipping,将梯度约束在一个范围内,这样不会使得梯度过大。
8、深度学习模型参数初始化都有哪些方法?
(1)Gaussian 满足mean=0,std=1的高斯分布x∼N(mean, [公式] )
(2)Xavier 满足x∼U(−a,+a)x∼U(−a,+a)的均匀分布, 其中 a = sqrt(3/n)
(3)MSRA 满足x∼N(0, [公式] )x∼N(0,[公式])的高斯分布,其中σ = sqrt(2/n)
(4)Uniform 满足min=0,max=1的均匀分布。x∼U(min,max)x∼U(min,max)
9、注意力机制在深度学习中的作用是什么?有哪些场景会使用?
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标是从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息。目前在神经机器翻译(Neural Machine Translation)、图像理解(Image caption)等场景都有广泛应用
10、卷积神经网络为什么会具有平移不变性?
MaxPooling能保证卷积神经网络在一定范围内平移特征能得到同样的激励,具有平移不变形。
11、神经网络参数共享(parameter sharing)是指什么?
所谓的权值共享就是说,用一个卷积核去卷积一张图,这张图每个位置是被同样数值的卷积核操作的,权重是一样的,也就是参数共享。
12、什么是神经网络的梯度消失问题,为什么会有梯度消失问题?有什么办法能缓解梯度消失问题?
在反向传播算法计算每一层的误差项的时候,需要乘以本层激活函数的导数值,如果导数值接近于0,则多次乘积之后误差项会趋向于0,而参数的梯度值通过误差项计算,这会导致参数的梯度值接近于0,无法用梯度下降法来有效的更新参数的值。
改进激活函数,选用更不容易饱和的函数,如ReLU函数。
13、神经网络中使用的损失函数
欧氏距离,交叉熵,对比损失,合页损失
14、对于多分类问题,为什么神经网络一般使用交叉熵而不用欧氏距离损失?
交叉熵在一般情况下更容易收敛到一个更好的解。
15、解释SVM核函数的原理
核函数将数据映射到更高维的空间后处理,但不用做这种显式映射,而是先对两个样本向量做内积,然后用核函数映射。这等价于先进行映射,然后再做内积。
16、解释维数灾难的概念
当特征向量数理很少时,增加特征,可以提高算法的精度,但当特征向量的维数增加到一定数量之后,再增加特征,算法的精度反而会下降
17、Logistic回归为什么用交叉熵而不用欧氏距离做损失函数?
如果用欧氏距离,不是凸函数,而用交叉熵则是凸函数
18、解释GBDT的核心思想
用加法模拟,更准确的说,是多棵决策树树来拟合一个目标函数。每一棵决策树拟合的是之前迭代得到的模型的残差。求解的时候,对目标函数使用了一阶泰勒展开,用梯度下降法来训练决策树
19、解释XGBoost的核心思想
在GBDT的基础上,目标函数增加了正则化项,并且在求解时做了二阶泰勒展开
20、介绍seq2seq的原理
整个系统由两个RNN组成,一个充当编码器,一个充当解码器;编码器依次接收输入的序列数据,当最后一个数据点输入之后,将循环层的状态向量作为语义向量,与解码器网络的输入向量一起,送入解码器中进行预测
21、HMM和CRF的区别?
HMM描述的是 P(X,Y)=P(X|Y)*P(Y), 是 generative model; CRF描述的是 P(Y|X), 是 discriminative model. 前者你要加入对状态概率分布的先验知识,而后者完全是 data driven.
22、什么是共线性, 跟过拟合有啥关联?
共线性:多变量线性回归中,变量之间由于存在高度相关关系而使回归估计不准确。
共线性会造成冗余,导致过拟合。
解决方法:排除变量的相关性/加入权重正则
23、Bias和Variance的区别?
Bias量了学习算法的期望预测与真实结果的偏离程度,即刻画了算法本身的拟合能力。
Variance度量了同样大小的训练集的变动所导致的学习性能变化,即刻画了数据扰动所造成的影响。
24、特征选择方法有哪些
相关系数法 使用相关系数法,先要计算各个特征对目标值的相关系
构建单个特征的模型,通过模型的准确性为特征排序,借此来选择特征
通过L1正则项来选择特征:L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性
(分别使用L1和L2拟合,如果两个特征在L2中系数相接近,在L1中一个系数为0一个不为0,那么其实这两个特征都应该保留,原因是L1对于强相关特征只会保留一个)
训练能够对特征打分的预选模型:RandomForest和LogisticRegression/GBDT等都能对模型的特征打分,通过打分获得相关性后再训练最终模型;
通过特征组合后再来选择特征:如对用户id和用户特征最组合来获得较大的特征集再来选择特征,这种做法在推荐系统和广告系统中比较常见
通过深度学习来进行特征选择
传统用前进或者后退法的逐步回归来筛选特征或者对特征重要性排序,对于特征数量不多的情况还是适用的。
方差选择法计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征
卡方检验 经典的卡方检验是检验定性自变量对定性因变量的相关性
互信息法 互信息法经典的互信息也是评价定性自变量对定性因变量的相关性的
线性判别分析法(LDA)
主成分分析法(PCA)
25、GBDT和XGBoost的区别是什么?
XGBoost类似于GBDT的优化版,不论是精度还是效率上都有了提升。与GBDT相比,具体的优点有:
- 损失函数是用泰勒展式二项逼近,而不是像GBDT里的就是一阶导数;
- 对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能性;
- 节点分裂的方式不同,GBDT是用的基尼系数,XGBoost是经过优化推导后的。
26、overfitting怎么解决?
dropout、regularization、batch normalizatin
27、为什么XGBoost要用泰勒展开,优势在哪里?
XGBoost使用了一阶和二阶偏导, 二阶导数有利于梯度下降的更快更准. 使用泰勒展开取得二阶倒数形式, 可以在不选定损失函数具体形式的情况下用于算法优化分析.本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 这种去耦合增加了XGBoost的适用性。
28、XGBoost如何寻找最优特征?是又放回还是无放回的呢?
XGBoost在训练的过程中给出各个特征的评分,从而表明每个特征对模型训练的重要性.。XGBoost利用梯度优化模型算法, 样本是不放回的(想象一个样本连续重复抽出,梯度来回踏步会不会高兴)。但XGBoost支持子采样, 也就是每轮计算可以不使用全部样本。
29、L1和L2的区别
L1范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.
简单总结一下就是:
L1范数: 为x向量各个元素绝对值之和。
L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或Frobenius范数
Lp范数: 为x向量各个元素绝对值p次方和的1/p次方.
在支持向量机学习过程中,L1范数实际是一种对于成本函数求解最优的过程,因此,L1范数正则化通过向成本函数中添加L1范数,使得学习得到的结果满足稀疏化,从而方便人类提取特征。
L1范数可以使权值稀疏,方便特征提取。
L2范数可以防止过拟合,提升模型的泛化能力。
30、RNN原理
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward+Neural+Networks)。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出。所以叫循环神经网络
31、RNN、LSTM、GRU区别
RNN引入了循环的概念,但是在实际过程中却出现了初始信息随时间消失的问题,即长期依赖(Long-Term Dependencies)问题,所以引入了LSTM。
LSTM:因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。推导forget gate,input gate,cell state, hidden information等因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸的变化是关键,下图非常明确适合记忆:
GRU是LSTM的变体,将忘记门和输入们合成了一个单一的更新门。
32、LSTM防止梯度弥散和爆炸
LSTM用加和的方式取代了乘积,使得很难出现梯度弥散。但是相应的更大的几率会出现梯度爆炸,但是可以通过给梯度加门限解决这一问题。
33、word2vec
这个也就是Word Embedding,是一种高效的从原始语料中学习字词空间向量的预测模型。分为CBOW(Continous Bag of Words)和Skip-Gram两种形式。其中CBOW是从原始语句推测目标词汇,而Skip-Gram相反。CBOW可以用于小语料库,Skip-Gram用于大语料库。
34、LR和SVM对比
首先,LR和SVM最大的区别在于损失函数的选择,LR的损失函数为Log损失(或者说是逻辑损失都可以)、而SVM的损失函数为hinge loss。
35、EM算法、HMM、CRF
这三个放在一起不是很恰当,但是有互相有关联,所以就放在这里一起说了。注意重点关注算法的思想。
(1)EM算法
EM算法是用于含有隐变量模型的极大似然估计或者极大后验估计,有两步组成:E步,求期望(expectation);M步,求极大(maxmization)。本质上EM算法还是一个迭代算法,通过不断用上一代参数对隐变量的估计来对当前变量进行计算,直到收敛。
注意:EM算法是对初值敏感的,而且EM是不断求解下界的极大化逼近求解对数似然函数的极大化的算法,也就是说EM算法不能保证找到全局最优值。对于EM的导出方法也应该掌握。
(2)HMM算法
隐马尔可夫模型是用于标注问题的生成模型。有几个参数(ππ,A,B):初始状态概率向量ππ,状态转移矩阵A,观测概率矩阵B。称为马尔科夫模型的三要素。
马尔科夫三个基本问题:
概率计算问题:给定模型和观测序列,计算模型下观测序列输出的概率。–》前向后向算法
学习问题:已知观测序列,估计模型参数,即用极大似然估计来估计参数。–》Baum-Welch(也就是EM算法)和极大似然估计。
预测问题:已知模型和观测序列,求解对应的状态序列。–》近似算法(贪心算法)和维比特算法(动态规划求最优路径)
(3)条件随机场CRF
给定一组输入随机变量的条件下另一组输出随机变量的条件概率分布密度。条件随机场假设输出变量构成马尔科夫随机场,而我们平时看到的大多是线性链条随机场,也就是由输入对输出进行预测的判别模型。求解方法为极大似然估计或正则化的极大似然估计。
之所以总把HMM和CRF进行比较,主要是因为CRF和HMM都利用了图的知识,但是CRF利用的是马尔科夫随机场(无向图),而HMM的基础是贝叶斯网络(有向图)。而且CRF也有:概率计算问题、学习问题和预测问题。大致计算方法和HMM类似,只不过不需要EM算法进行学习问题。
(4)HMM和CRF对比
其根本还是在于基本的理念不同,一个是生成模型,一个是判别模型,这也就导致了求解方式的不同。
36、防止过拟合的方法
过拟合的原因是算法的学习能力过强;一些假设条件(如样本独立同分布)可能是不成立的;训练样本过少不能对整个空间进行分布估计。
处理方法:
- 早停止:如在训练中多次迭代后发现模型性能没有显著提高就停止训练
- 数据集扩增:原有数据增加、原有数据加随机噪声、重采样
- 正则化
- 交叉验证
- 特征选择/特征降维
37、数据不平衡问题
这主要是由于数据分布不平衡造成的。解决方法如下:
采样,对小样本加噪声采样,对大样本进行下采样
进行特殊的加权,如在Adaboost中或者SVM中
采用对不平衡数据集不敏感的算法
改变评价标准:用AUC/ROC来进行评价
采用Bagging/Boosting/ensemble等方法
考虑数据的先验分布
二、词向量
1、什么是 Word2Vec?如何训练?
word2vec也叫做词嵌入表示,它能用密集矩阵表示一个词,相对于独热编码用稀疏矩阵表示词而言,他能大大的减少内存的使用量和运算的复杂度。
那么word2vec是如何做到减少矩阵维度的呢?
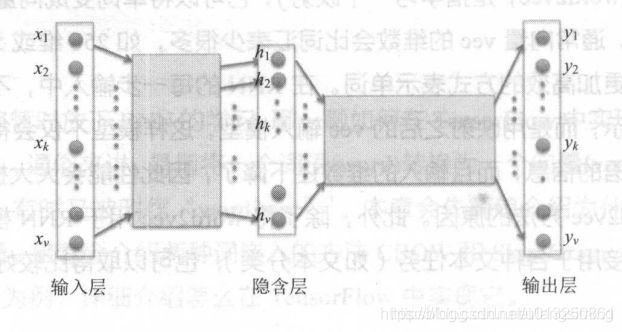
如上图所示,这种场景是利用一个单词来预测一个单词的情况,它是利用了神经网络结构中隐层的性质,隐层可以不受输入层和输出层的影响自由控制大小。这里的隐层就是word2vec最终的矩阵表示。
而利用多个单词来预测一个单词的情况如下图所示,他其实是将所有隐层的参数相加得到的。
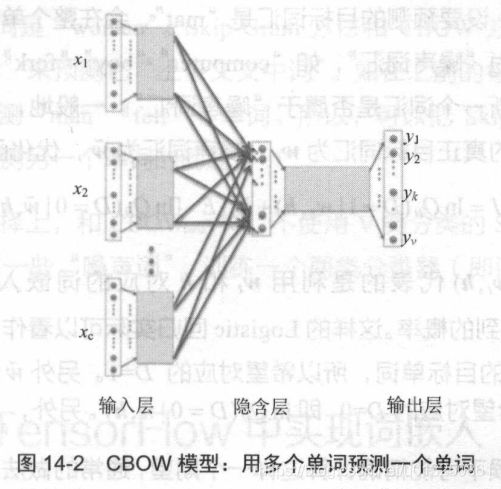
word2vec这里还有一个知识点就是,它使用的损失函数是nec函数。在训练词嵌入矩阵的时候,它使用2分类问题去代替n分类问题。nec损失函数会随机从词库选取一些单词作为负例,其他的单词作为正例。我认为之所以这样做可行是因为,我们现在要做的事情是想用一个矩阵去表示单词而已,并不是真正做预测。所以这个简单的二分类可以满足我们的要求。
2、Word2vec,CBOW和Skip-gram的区别是什么?
word2vec也叫做词嵌入表示,它能用密集矩阵表示一个词,相对于独热编码用稀疏矩阵表示词而言,他能大大的减少内存的使用量和运算的复杂度。
CBOW ,连续词袋法,它是word2vec方法中的一种。它的核心思想是利用它周边的词来预测该词。
skip-gram,的核心思想正好相反,它是利用一个词去预测它周边的词。
3、文本相似度计算方式?
| 文本表示模型 |
相似度度量方法 |
|
| 文本切分粒度 |
特征构建方法 |
|
| 原始字符串 ngram 词语 句法分析结果 主题模型
|
TF TF-IDF 句向量 词向量 Simhash
|
最小编辑距离 欧氏距离 余弦距离 杰卡德相似度 |
| 海明距离 |
||
| 分类器 |
||
一、闵可夫斯基距离(Minkowski Distance)
二、曼哈顿距离(Manhattan Distance)
三、欧氏距离(Euclidean Distance)
四、切比雪夫距离(Chebyshev Distance)
五、"加权(weighted)"闵可夫斯基距离
六、余弦相似度(Cosine Similarity)
七、皮尔逊相关系数(Pearson Correlation)
八、马氏距离(Mahalanobis Distance)
九、汉明距离(Hamming Distance)
十、杰卡德相似系数(Jaccard Similarity)
十一、KL散度(Kullback-Leibler Divergence)
十二、Hellinger距离(Hellinger Distance)
4、词向量前世今生
word2vector:核心思想是通过词的上下文得到词的向量化表示,有两种方法:CBOW(通过附近词预测中心词)、Skip-gram(通过中心词预测附近的词)。
glove:word2vec只考虑到了词的局部信息,glove利用共现矩阵设计损失函数,同时考虑了局部信息和整体的信息。
语言模型(elmo、bert、gpt…):词在不同的语境下其实有不同的含义,对应的词向量也不同。
5、wordpiece的作用
wordpiece其核心思想是将单词打散为字符,然后根据片段的组合频率,最后单词切分成片段处理。和原有的分词相比,能够极大的降低OOV的情况,例如cosplayer, 使用分词的话如果出现频率较低则是UNK,但bpe可以把它切分吃cos play er, 模型可以词根以及前缀等信息,学习到这个词的大致信息,而不是一个OOV。
wordpiece与BPE(Byte Pair Encoding)算法类似,也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
6、实现输入纠错的方法
-
误拼词字典法。
-
N-gram法。基于n元文法,通过对大规模英文文本的统计得到单词与单词问的转移概率矩阵。当检测到某英文单词不在词典中时。查转移概率矩阵,取转移概率大于某给定阈值的单词为纠错建议。
-
最小编辑距离法。通过计算误拼字符串与词典中某个词间的最小编辑距离来确定纠错候选词。所谓最小编辑距离是指将一个词串转换为另一个词串所需的最少的编辑操作次数。在编辑操作中,可以将单次的编辑动作归纳为三种:插入字符、删除字符和替换字符;
7、 有哪些文本表示模型,它们各有什么优缺点?
文本表示模型是研究如何表示文本数据的模型,输入是语料库(文档)。
7.1 词袋模型与N-gram
最基本的文本表示模型是词袋模型(Bag of Words)。基本思想是把每篇文章看成一袋子词,并忽略每个词出现的顺序。具体来看:将整段文本表示成一个长向量,每一维代表一个单词。该维对应的权重代表这个词在原文章中的重要程度。
常用TF-IDF计算权重。公式为: T F − I D F ( t , d ) = T F ( t , d ) ∗ I D F ( t ) TF−IDF(t,d)=TF(t,d)∗IDF(t) TF−IDF(t,d)=TF(t,d)∗IDF(t)
其中TF(t,d)为单词t在文档中出现的频率,IDF(t)是逆文档频率,用来衡量单词t对表达语义所起的重要性。表示为 l o g 总 文 档 数 量 该 词 出 现 的 文 档 数 量 + 1 log\frac{总文档数量}{该词出现的文档数量+1} log该词出现的文档数量+1总文档数量
直观的解释是如果一个单词在非常多的文章里面都出现,那么它可能是一个比较通用的词汇,对于区分某篇文章特殊语义的贡献较小,因此对权重做一定惩罚。
- 缺点:单词程度的划分有时候并不是一个好的做法。比如Natural Language Processing一词,单个单词拆分的语义与三个词连续出现的语义并不相同。
- 改进:通常可将连续出现的N个单词构成的词组作为一个特征放到向量表示中去。构成N-gram模型
7.2 主题模型
主题模型用于从文本库中发现有代表性的主题(得到每个主题上的词的分布特性),并且能够计算出每篇文章的主题分布。
7.3 词嵌入与深度学习模型
词嵌入是一类将词向量化的模型的统称,核心思想是将每个单词都映射成地位空间上的一个稠密向量。低维空间上的每一个单词也可以看做是一个隐含的主题,只不过不像主题模型中那么明显。
对有N个单词的文档,词嵌入用K维向量映射单词,可以得到一个N*K的矩阵来表示这篇文档。但是还需要抽象出更高层的特征,通常使用深度学习来得到更高维的特征。
8、 Word2vec是如何工作的
谷歌2013年提出的word2vec是目前最常用的词嵌入模型之一。word2vec实际上是一种浅层的神经网络模型,它有两种网络结构,分别是CBOW和skip-gram。
CBOW目标是根据上下文出现的单词预测当前词的生成概率。而Skip-gram根据当前词预测上下文各词的生成概率。
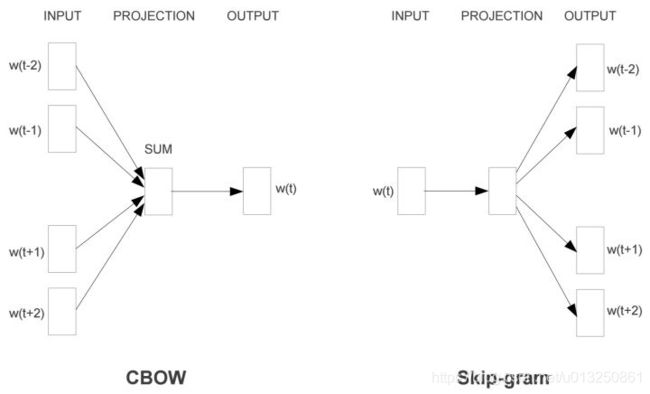
其中 w ( t ) w(t) w(t) 是当前所关注的词, w ( t − 2 ) , w ( t − 1 ) , w ( t + 1 ) , w ( t + 2 ) w(t−2),w(t−1),w(t+1),w(t+2) w(t−2),w(t−1),w(t+1),w(t+2) 是上下文单词,这里前后滑动窗口大小均设为2。
CBOW和skip-gram都可以表示为有输入层、映射层、输出层组成的浅层神经网络。
输入层中每个单词是由独热编码表示。所有词均表示一个N维向量,N为词汇表中单词的总数。在向量中,每个单词对应的维度为1,其余维度为0。
在映射层中,K个隐含单元的值可以由N维输入向量以及连接输入和隐含单元的NK维权重矩阵计算得到。
输出层向量的值可以由隐含层向量(K维),以及连接隐含层和输出层之间的KN维权重矩阵计算得到。输出层也是一个N维向量,每一维与词汇表中的一个单词对应。最后对输出层向量应用Softmax函数,可以得到每个单词的生成概率。
接下来需要训练神经网络权重,使得所有单词的整体生成概率最大化。共有两大参数:从输入层到隐含层的一个维度为NK的权重矩阵,从隐含层到输出层的一个维度为KN的权重矩阵。学习权重可以使用BP算法实现。
训练得到维度为N * K和K * N的两个权重矩阵之后,可以选择其中一个作为N个词的K维向量表示。
但是由于Softmax激活函数存在归一化项的缘故,推导出来的迭代公式需要对词汇表中的所有单词进行遍历,使得迭代过程非常缓慢。由此产生了Hierarchical Softmax和Negative Sampling两种方法。
9、word2vec与LDA区别
首先,LDA是按照文档中单词的共现关系来对单词按照主题聚类,也可以理解为对“文档-单词”矩阵进行分解,得到“文档-主题”和“主题-单词”两个概率分布。而word2vec实际上是对“上下文-单词”矩阵进行学习,其中上下文由周围几个单词组成,由此学到的词向量更多融入了上下文特征。
主题模型和词嵌入两类方法最大的不同在于模型本身。
- 主题模型(LDA)是一种基于概率图模型的生成式模型。其似然函数可以写为若干条件概率连乘的形式,其中包含需要推测的隐含变量(即主题)
- 词嵌入模型(word2vec)一般表示为神经网络的形式,似然函数定义在网络的输出之上。需要学习网络的权重来得到单词的稠密向量表示。
三、RNN&LSTM
1、为什么RNN会有梯度消失的情况,而LSTM可以避免这种情况的发生
RNN的求解可以采用BPTT(Back Propagation Through Time)算法实现。实际上是BP的简单变种。RNN设计的初衷在于捕捉长距离输入之间的依赖关系,然而使用BPTT的算法并不能成功捕捉远距离依赖关系,这一现象源于深度神经网络中的梯度消失问题。

由于预测误差沿神经网络每一层反向传播,当雅克比矩阵最大特征值大于1时,随着离输出越来越远,每层的梯度大小会呈指数增长,导致梯度爆炸。反之若最大特征值小于1,梯度大小会指数减小,产生梯度消失。梯度消失意味着无法通过加深网络层数来提升预测效果,只有靠近输出的几层才真正起到学习的作用,这样RNN很难学习到输入序列中的长距离依赖关系。
梯度爆炸可以通过梯度裁剪来缓解,即当梯度的范式大于某个给定值的时候,对梯度进行等比缩放。而梯度消失问题需要对模型本身进行改进。深度残差网络是对前馈神经网络的改进。通过残差学习的方式缓解了梯度消失的现象,从而可以学习到更深层的网络表示。对于RNN来说,长短时记忆模型及其变种门控循环单元等模型通过加入门控机制,很大程度上缓解了梯度消失带来的损失。
2、在RNN中可以采用ReLU作为激活函数吗?
在CNN中采用ReLU激活函数可以有效改进梯度消失,取得更好收敛速度和收敛结果,那么在RNN中可以采用ReLU作为激活函数吗?
答案是肯定的。但是需要对矩阵的初值做一定限制,否则容易引发数值问题。首先回顾一下RNN前向传播公式:

综上所述,采用ReLU作为RNN中隐含层的激活函数时,只有当W的取值在单位矩阵附近时才能取得较好结果。因此需要将W初始化为单位矩阵。实践证明,初始化W为单位矩阵并使用ReLU激活函数在一些应用中取得了与LSTM相似的结果,并且学习速度更快。
2、为什么说 LSTM 具有长期记忆功能?
LSTM实现长期记忆不仅仅是依靠门控,还有cell状态。
在前向传播中,如果将输入的一串序列当做一部戏剧,那么LSTM的cell就是记录下的主线,而遗忘门,输入门都用于给主线增加一些元素(比如新的角色,关键性的转机)。通过训练,遗忘门能够针对性地对主线进行修改,选择“保留”或是“遗忘”过去主线中出现的内容,输入门用于判断是否要输入新的内容,并且输入内容。输出门则用于整合cell状态,判断需要把什么内容提取出来传递给下一层神经元。而RNN只是每一层接受上一幕的情景以及对以前情景越来越模糊的记忆,进行下一步传递,虽然运算很快,写法简单,但是无法处理长时间依赖的数据。
LSTM和RNN一样都会有梯度爆炸(千万记住),都需要进行梯度裁剪,防止Inf和NaN的出现。
之所以LSTM能比RNN更好地应对梯度消失,原因要从反向传播的过程中去找。
一般情况下我们用RNN的时候,使用的激励函数是tanh,tanh的导数范围在[0,1]之间,且在自变量为0的时候导数为1,这就直接导致了在不断往反向传播的过程中,反复乘以小于1的数,不需要经过几个time step,梯度就会变得非常非常小,出现梯度消失。
而LSTM的神经元中与输入数据有关的有三个sigmoid和一个tanh。sigmoid的导数范围在[0,0.25]之间,且在自变量为0的时候导数取最大值0.25。那么在不考虑权重等等影响条件下,三个sigmoid和一个tanh控制的门在反向传播中都要接受上一层的梯度,并且在这一层进行整合,在最好的情况下,几乎等同于乘以3*0.25+1,显然是大于1的(所以如果参数设置不太好的话,每次都乘大于1的数,会梯度爆炸),不过介于每一个time step不一定都是这种情况,所以要乘以的数值的分布基本上很均匀,有小于1和大于1的,一定程度上可以缓解梯度消失。
3、LSTM是如何实现长短期记忆功能的?
https://blog.csdn.net/qq_17677907/article/details/86448214
RNN有梯度消失和梯度爆炸问题,学习能力有限。LSTM可以对有价值的信息进行长期记忆,有广泛应用
首先结合LSTM结构图和更新的计算公式探讨这种网络如何实现功能。

4、处理文本数据时,RNN比CNN有什么特点?
传统文本处理任务的方法一般将TF-IDF向量作为特征输入,这样实际上丢失了输入的文本系列中每个单词的顺序。
CNN一般会接收一个定长的向量作为输入,然后通过滑动窗口加池化的方法将原来的输入转换为一个固定长度的向量表示。这样做可以捕捉到文本中的一些局部特征,但是两个单词之间的长距离依赖关系难以学习。
RNN能够很好处理文本数据变长并且有序的输入序列。将前面阅读到的有用信息编码到状态变量中去,从而拥有了一定的记忆能力。
一个长度为T的序列用RNN建模,展开后可看做是一个T层前馈神经网络。其中第t层的隐含状态 h t h_t ht 编码了序列中前t个输入的信息。可以通过当前的输入 x t x_t xt 和上一层神经网络的状态 h t − 1 h_{t-1} ht−1 计算得到。最后一层的状态 h T h_T hT 编码了整个序列的信息,因此可以作为整篇文档的压缩表示。在 h T h_T hT 后面加一个Softmax层,输出文本所属类别的预测概率y,就可以实现文本分类。 h t h_t ht 和y的计算公式如下:

其中f和g为激活函数,U为输入层到隐含层的权重矩阵,W为隐含层中从上一时刻到下一时刻转移的权重矩阵。在文本分类任务中,f可以选取Tanh或ReLU函数,g可以采用Softmax函数。
通过不断最小化损失误差(即输出的y与真实类别之间的距离),可以不断训练网络,使得得到的循环神经网络可以准确预测文本类别。相比于CNN,RNN由于具备对序列信息的刻画能力,往往能得到更加准确的结果。
5、LSTM中各模块分别使用什么激活函数,可以使用别的激活函数吗?
https://blog.csdn.net/qq_17677907/article/details/86485461

6、什么是Seq2Seq模型?Seq2Seq有哪些优点?
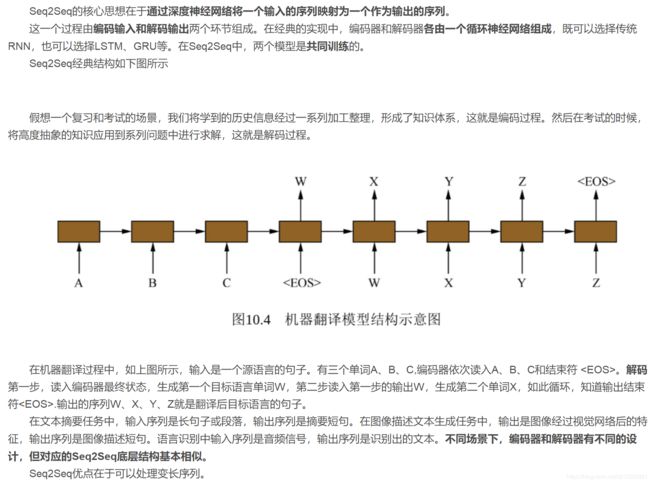
Seq2Seq,全称Sequence to Sequence模型。称为序列到序列模型。大致意思是将一个序列信息,通过编码和解码生成一个新的序列模型。通常用于机器翻译、语音识别、自动对话等任务。
在Seq2Seq模型之前,深度神经网络所擅长的问题中,输入和输出都可以表示为固定长度的向量,如果长度稍有变化,会使用补零等操作。然而对于前面的任务,其序列长度实现并不知道。如何突破这个局限,Seq2Seq应运而生。
7、Seq2Seq模型在解码时,有哪些常用的方法?
Seq2Seq模型最核心的部分在于解码部分,大量的改进也是基于解码环节。Seq2Seq模型最基础的解码方法是贪心法:即选取一种度量标准后,每次都在当前状态下选择最佳的一个结果,直到结束。贪心法计算代价低,适合作为基准结果与其他方法比较。显然贪心法获得的是一个局部最优解,往往并不能取得最好的效果。
集束搜索是常见改进算法,它是一种启发式算法。该方法会保存beam size个当前的较佳选择。解码的时候每一步根据当前的选择进行下一步扩展和排序,接着选择前beam size个进行保存,循环迭代,直到结束时选择一个最佳的作为编码的结果。
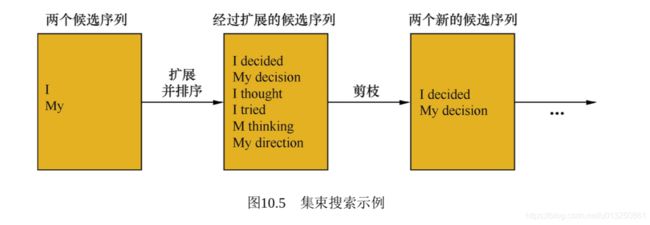
上图中beam size为2。当前有解码得到的两个候选:I和My。然后输入解码器,得到一系列候选序列。显然,如果beam size取1,退化为贪心算法。b越大,搜索空间越大,效果会有所提升,但计算量也相应增大。实际上beam size需要取一个折中范围:8~12.
常见的改进方法还有:
- 解码时使用堆叠RNN
- 增加Dropout机制
- 与编码器建立残差连接
- 加入注意力机制(解码时每一步有针对的关注当前有关编码结果)
- 加入记忆网络(从外部获取知识)
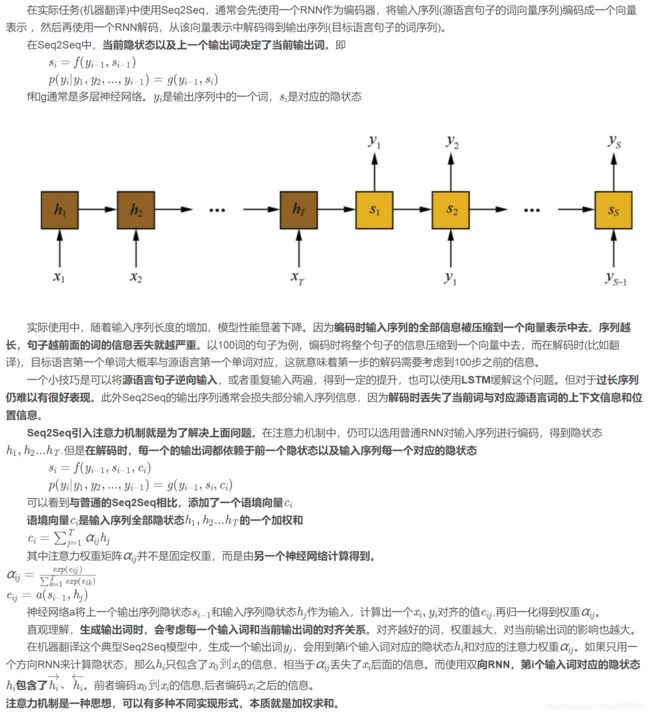
8、Seq2Seq模型加入注意力机制是为了解决什么问题?为什么选用了双向循环神经网络?
人脑在工作时具有一定注意力,当欣赏艺术品时,既可以看到全貌,也可以关注 细节,眼睛聚焦在局部,忽略其他位置信息。说明人脑在处理信息的时候有一定权重划分。而注意力机制的提出正是模仿了人脑的这种核心特性。
9、知道哪些命名实体识别算法?具体的优缺点?(Bi-LSTM-CRF)

四、优化方法
1、Dropout的原理是什么
除了输入和输出层外,使其它层的神经元的个数暂时性的减少,以达到防止过拟合的一种方法。
2、深度学习优化算法有哪些,随便介绍一个(说的Adagrad,优缺点明显,进退自如)
SGD(Stochastic Gradient Descent,随机梯度下降)算法
SGDM (SGD with Momentum,带动量的随机梯度下降)算法
AdaGrad(自适应梯度下降)算法
RMSProp(Root Mean Square Prop Gradient Descent )算法
Adam算法:RMSProp+SGDM
AdaGrad算法分析
-
从AdaGrad算法中可以看出,随着算法不断迭代,r会越来越大,整体的学习率会越来越小。所以,一般来说AdaGrad算法一开始是激励收敛,到了后面就慢慢变成惩罚收敛,速度越来越慢。
-
在SGD中,随着梯度的增大,我们的学习步长应该是增大的。但是在AdaGrad中,随着梯度g的增大,我们的r也在逐渐的增大,且在梯度更新时r在分母上,也就是整个学习率是减少的,这是为什么呢?
这是因为随着更新次数的增大,我们希望学习率越来越慢。因为我们认为在学习率的最初阶段,我们距离损失函数最优解还很远,随着更新次数的增加,越来越接近最优解,所以学习率也随之变慢。 -
经验上已经发现,对于训练深度神经网络模型而言,从训练开始时积累梯度平方会导致有效学习率过早和过量的减小。AdaGrade在某些深度学习模型上效果不错,但不是全部。
3、为什么batch normalization
https://cloud.tencent.com/developer/article/1376683
在机器学习中,我们需要对输入的数据做预处理,可以用 normalization 归一化 ,或者 standardization 标准化,用来将数据的不同 feature 转换到同一范围内。
- normalization 归一化 :将数据转换到 [0, 1] 之间,
- standardization 标准化:转换后的数据符合标准正态分布

为什么需要做归一化 标准化等 feature scaling?
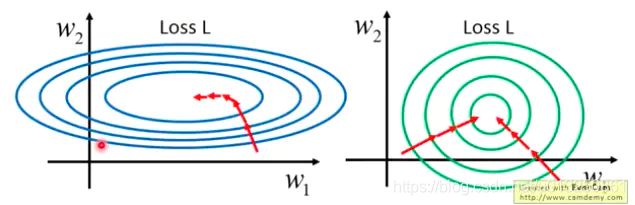
因为如果不做这样的处理,不同的特征具有不同数量级的数据,它们对线性组合后的结果的影响所占比重就很不相同,数量级大的特征显然影响更大。
进一步体现在损失函数上,影响也更大,可以看一下,feature scaling 之前,损失函数的切面图是椭圆的,之后就变成圆,无论优化算法在何处开始,都更容易收敛到最优解,避免了很多弯路。
在神经网络中,不仅仅在输入层要做 feature scaling,在隐藏层也需要做。
尤其是在神经网络中,特征经过线性组合后,还要经过激活函数,如果某个特征数量级过大,在经过激活函数时,就会提前进入它的饱和区间,即不管如何增大这个数值,它的激活函数值都在 1 附近,不会有太大变化,这样激活函数就对这个特征不敏感。
在神经网络用 SGD 等算法进行优化时,不同量纲的数据会使网络失衡,很不稳定。
在神经网络中,这个问题不仅发生在输入层,也发生在隐藏层,因为前一层的输出值,对后面一层来说,就是它的输入,而且也要经过激活函数,
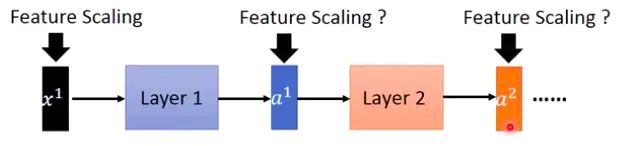
所以就需要做 batch normalization
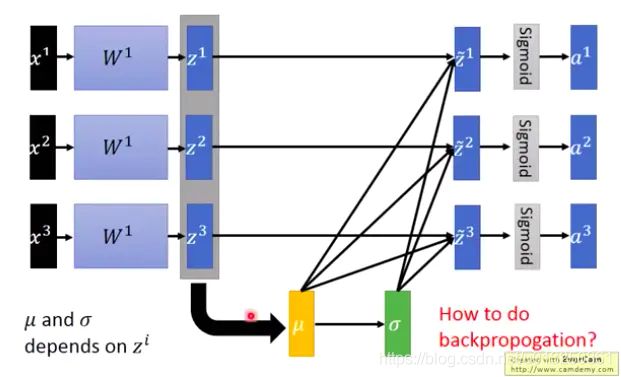
就是在前一层的线性输出 z 上做 normalization:需要求出这一 batch 数据的平均值和标准差,然后再经过激活函数,进入到下一层。

在 Keras 可以这样应用:
# import BatchNormalization
from keras.layers.normalization import BatchNormalization
# instantiate model
model = Sequential()
# we can think of this chunk as the input layer
model.add(Dense(64, input_dim=14, init='uniform'))
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Dropout(0.5))
# we can think of this chunk as the hidden layer
model.add(Dense(64, init='uniform'))
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Dropout(0.5))
# we can think of this chunk as the output layer
model.add(Dense(2, init='uniform'))
model.add(BatchNormalization())
model.add(Activation('softmax'))
# setting up the optimization of our weights
sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd)
# running the fitting
model.fit(X_train, y_train, nb_epoch=20, batch_size=16, show_accuracy=True, validation_split=0.2, verbose = 2)
其他normalization手段:Instance Normalization、Layer Normalization
4、神经网络中 warmup 策略为什么有效
https://www.zhihu.com/question/338066667/answer/771252708
- 在训练的开始阶段,模型权重迅速改变
- mini-batch size较小,样本方差较大
第一种情况很好理解,可以认为,刚开始模型对数据的“分布”理解为零,或者是说“均匀分布”(当然这取决于你的初始化);在第一轮训练的时候,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。当训练了一段时间(比如两轮、三轮)后,模型已经对每个数据点看过几遍了,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型学偏,所以可以适当调大学习率。这个过程就可以看做是warmup。那么为什么之后还要decay呢?当模型训到一定阶段后(比如十个epoch),模型的分布就已经比较固定了,或者说能学到的新东西就比较少了。如果还沿用较大的学习率,就会破坏这种稳定性,用我们通常的话说,就是已经接近loss的local optimal了,为了靠近这个point,我们就要慢慢来。
第二种情况其实和第一种情况是紧密联系的。在训练的过程中,如果有mini-batch内的数据分布方差特别大,这就会导致模型学习剧烈波动,使其学得的权重很不稳定,这在训练初期最为明显,最后期较为缓解(所以我们要对数据进行scale也是这个道理)。
三、BERT
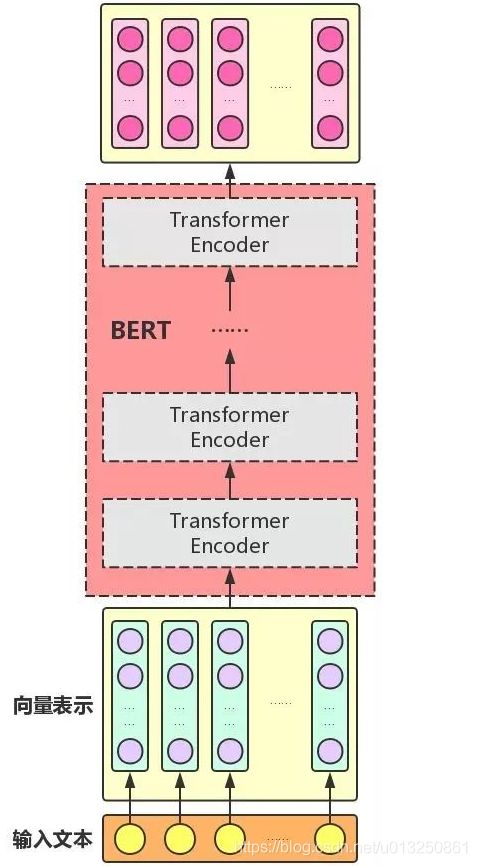
1、BERT的基本原理是什么?
BERT来自Google的论文 Pre-training of Deep Bidirectional Transformers for Language Understanding,BERT是” Bidirectional Encoder Representations from Transformers ”的首字母缩写,整体是一个自编码语言模型(Autoencoder LM),并且其设计了两个任务来预训练该模型。第一个任务是采用MaskLM的方式来训练语言模型,通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号[MASK]来代替它们,之后让模型根据所给的标签去学习这些地方该填的词。第二个任务在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入BERT的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。最后的实验表明BERT模型的有效性,并在11项NLP任务中夺得SOTA结果。
BERT相较于原来的RNN、LSTM可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。相较于word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。同时缺点也是显而易见的,模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
2、bert的具体网络结构,以及训练过程,bert为什么火,它在什么的基础上改进了些什么?
bert是用了transformer的encoder侧的网络,作为一个文本编码器,使用大规模数据进行预训练,预训练使用两个loss,一个是mask LM,遮蔽掉源端的一些字(可能会被问到mask的具体做法,15%概率mask词,这其中80%用[mask]替换,10%随机替换一个其他字,10%不替换,至于为什么这么做,那就得问问BERT的作者了{捂脸}),然后根据上下文去预测这些字,一个是next sentence,判断两个句子是否在文章中互为上下句,然后使用了大规模的语料去预训练。在它之前是GPT,GPT是一个单向语言模型的预训练过程(它和gpt的区别就是bert为啥叫双向 bi-directional),更适用于文本生成,通过前文去预测当前的字。下图为transformer的结构,bert的网络结构则用了左边的encoder。
3、讲讲multi-head attention的具体结构
BERT由12层transformer layer(encoder端)构成,首先word emb , pos emb(可能会被问到有哪几种position embedding的方式,bert是使用的哪种), sent emb做加和作为网络输入,每层由一个multi-head attention, 一个feed forward 以及两层layerNorm构成,一般会被问到multi-head attention的结构,具体可以描述为,
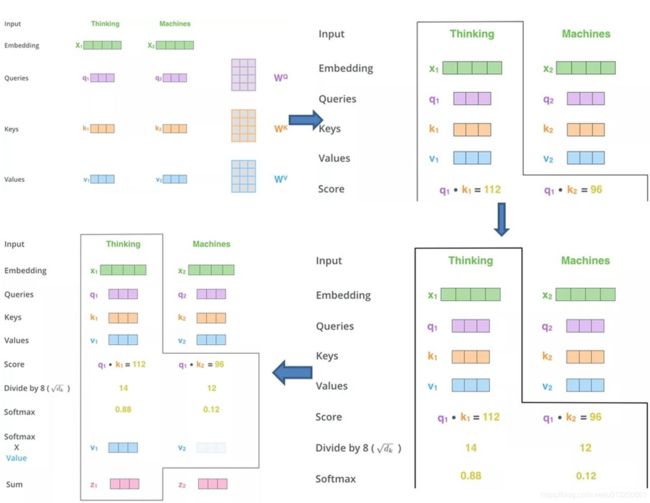
step1
一个768的hidden向量,被映射成query, key, value。 然后三个向量分别切分成12个小的64维的向量,每一组小向量之间做attention。不妨假设batch_size为32,seqlen为512,隐层维度为768,12个head
hidden(32 x 512 x 768) -> query(32 x 512 x 768) -> 32 x 12 x 512 x 64
hidden(32 x 512 x 768) -> key(32 x 512 x 768) -> 32 x 12 x 512 x 64
hidden(32 x 512 x 768) -> val(32 x 512 x 768) -> 32 x 12 x 512 x 64
step2
然后query和key之间做attention,得到一个32 x 12 x 512 x 512的权重矩阵,然后根据这个权重矩阵加权value中切分好的向量,得到一个32 x 12 x 512 x 64 的向量,拉平输出为768向量。
32 x 12 x 512 x 64(query_hidden) * 32 x 12 x 64 x 512(key_hidden) -> 32 x 12 x 512 x 512
32 x 12 x 64 x 512(value_hidden) * 32 x 12 x 512 x 512 (权重矩阵) -> 32 x 12 x 512 x 64
然后再还原成 -> 32 x 512 x 768
简言之是12个头,每个头都是一个64维度分别去与其他的所有位置的hidden embedding做attention然后再合并还原。
4、Bert 采用哪种Normalization结构,LayerNorm和BatchNorm区别,LayerNorm结构有参数吗,参数的作用?
采用LayerNorm结构,和BatchNorm的区别主要是做规范化的维度不同,BatchNorm针对一个batch里面的数据进行规范化,针对单个神经元进行,比如batch里面有64个样本,那么规范化输入的这64个样本各自经过这个神经元后的值(64维),LayerNorm则是针对单个样本,不依赖于其他数据,常被用于小mini-batch场景、动态网络场景和 RNN,特别是自然语言处理领域,就bert来说就是对每层输出的隐层向量(768维)做规范化,图像领域用BN比较多的原因是因为每一个卷积核的参数在不同位置的神经元当中是共享的,因此也应该被一起规范化。
class BertLayerNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-5):
super(BertLayerNorm, self).__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.bias = nn.Parameter(torch.zeros(hidden_size))
self.variance_epsilon = eps
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.variance_epsilon)
return self.weight * x + self.bias
帖一个LayerNorm的实现,可以看到module中有weight和bias参数,以Sigmoid激活函数为例,批量归一化之后数据整体处于函数的非饱和区域, 只包含线性变换,破坏了之前学习到的特征分布。为了恢复原始数据分布,具体实现中引入了变换重构以及可学习参数w和b ,也就是上面的weight和bias,简而言之,规范化后的隐层表示将输入数据限制到了一个全局统一的确定范围,为了保证模型的表达能力不因为规范化而下降,引入了b是再平移参数,w是再缩放参数。(过激活函数前规范化,之后还原)
5、BERT是怎么用Transformer的?
BERT只使用了Transformer的Encoder模块,原论文中,作者分别用12层和24层Transformer Encoder组装了两套BERT模型,分别是:
B E R T b a s e : L = 12 , H = 768 , A = 12 , T o t a l P a r a m e t e r s = 110 M B E R T l a r g e : L = 24 , H = 1024 , A = 16 , T o t a l P a r a m e t e r s = 340 M BERT_{base}: L=12, H=768, A=12, Total Parameters=110M\\ BERT_{large}: L=24, H=1024, A=16, Total Parameters=340M BERTbase:L=12,H=768,A=12,TotalParameters=110MBERTlarge:L=24,H=1024,A=16,TotalParameters=340M
其中层的数量(即,Transformer Encoder块的数量)为 L L L ,隐藏层的维度为 H H H ,自注意头的个数为 A A A 。在所有例子中,我们将前馈/过滤器(Transformer Encoder端的feed-forward层)的维度设置为 4 H 4H 4H,即当 768 768 768 时是 3072 3072 3072 ;当 H = 1024 H = 1024 H=1024 是 4096 4096 4096 。
图示如下:
需要注意的是,与Transformer本身的Encoder端相比,BERT的Transformer Encoder端输入的向量表示,多了Segment Embeddings。
6、BERT的训练过程是怎么样的?
在论文原文中,作者提出了两个预训练任务:Masked LM和Next Sentence Prediction。
6.1 Masked LM
Masked LM的任务描述为:给定一句话,随机抹去这句话中的一个或几个词,要求根据剩余词汇预测被抹去的几个词分别是什么,如下图所示。
BERT 模型的这个预训练过程其实就是在模仿我们学语言的过程,思想来源于完形填空的任务。具体来说,文章作者在一句话中随机选择 15% 的词汇用于预测。对于在原句中被抹去的词汇, 80% 情况下采用一个特殊符号 [MASK] 替换, 10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。这么做的主要原因是:在后续微调任务中语句中并不会出现 [MASK] 标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。上述提到了这样做的一个缺点,其实这样做还有另外一个缺点,就是每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛。
6.2 Next Sentence Prediction
Next Sentence Prediction的任务描述为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示。
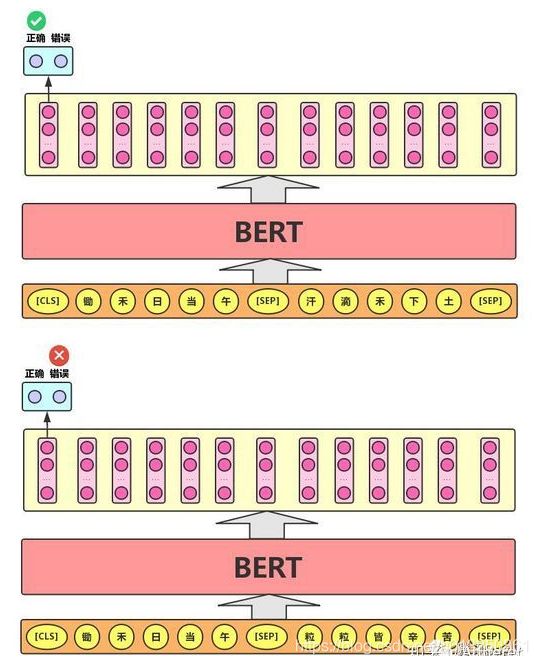
这个类似于段落重排序的任务,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。Next Sentence Prediction 任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
BERT 模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字/词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
7、为什么BERT比ELMo效果好?ELMo和BERT的区别是什么?
7.1 为什么BERT比ELMo效果好?
从网络结构以及最后的实验效果来看,BERT比ELMo效果好主要集中在以下几点原因:
-
LSTM抽取特征的能力远弱于Transformer
-
拼接方式双向融合的特征融合能力偏弱(没有具体实验验证,只是推测)
-
其实还有一点,BERT的训练数据以及模型参数均多余ELMo,这也是比较重要的一点
7.2 ELMo和BERT的区别是什么?
ELMo模型是通过语言模型任务得到句子中单词的embedding表示,以此作为补充的新特征给下游任务使用。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。而BERT模型是“基于Fine-tuning的模式”,这种做法和图像领域基于Fine-tuning的方式基本一致,下游任务需要将模型改造成BERT模型,才可利用BERT模型预训练好的参数。
8、BERT有什么局限性?
从XLNet论文中,提到了BERT的两个缺点,分别如下:
BERT在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的,比如”New York is a city”,假设我们Mask住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。
但是需要注意的是,这个问题并不是什么大问题,甚至可以说对最后的结果并没有多大的影响,因为本身BERT预训练的语料就是海量的(动辄几十个G),所以如果训练数据足够大,其实不靠当前这个例子,靠其它例子,也能弥补被Mask单词直接的相互关系问题,因为总有其它例子能够学会这些单词的相互依赖关系。
BERT的在预训练时会出现特殊的[MASK],但是它在下游的fine-tune中不会出现,这就出现了预训练阶段和fine-tune阶段不一致的问题。其实这个问题对最后结果产生多大的影响也是不够明确的,因为后续有许多BERT相关的预训练模型仍然保持了[MASK]标记,也取得了很大的结果,而且很多数据集上的结果也比BERT要好。但是确确实实引入[MASK]标记,也是为了构造自编码语言模型而采用的一种折中方式。
另外还有一个缺点,是BERT在分词后做[MASK]会产生的一个问题,为了解决OOV的问题,我们通常会把一个词切分成更细粒度的WordPiece。BERT在Pretraining的时候是随机Mask这些WordPiece的,这就可能出现只Mask一个词的一部分的情况,例如:

probability这个词被切分成”pro”、”#babi”和”#lity”3个WordPiece。有可能出现的一种随机Mask是把”#babi” Mask住,但是”pro”和”#lity”没有被Mask。这样的预测任务就变得容易了,因为在”pro”和”#lity”之间基本上只能是”#babi”了。这样它只需要记住一些词(WordPiece的序列)就可以完成这个任务,而不是根据上下文的语义关系来预测出来的。类似的中文的词”模型”也可能被Mask部分(其实用”琵琶”的例子可能更好,因为这两个字只能一起出现而不能单独出现),这也会让预测变得容易。
为了解决这个问题,很自然的想法就是词作为一个整体要么都Mask要么都不Mask,这就是所谓的Whole Word Masking。这是一个很简单的想法,对于BERT的代码修改也非常少,只是修改一些Mask的那段代码。
9、BERT的输入和输出分别是什么?
BERT模型的主要输入是文本中各个字/词(或者称为token)的原始词向量,该向量既可以随机初始化,也可以利用Word2Vector等算法进行预训练以作为初始值;输出是文本中各个字/词融合了全文语义信息后的向量表示,如下图所示(为方便描述且与BERT模型的当前中文版本保持一致,统一以字向量作为输入):
从上图中可以看出,BERT模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。此外,模型输入除了字向量(英文中对应的是Token Embeddings),还包含另外两个部分:
- 文本向量(英文中对应的是Segment Embeddings):该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
- 位置向量(英文中对应的是Position Embeddings):由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分
最后,BERT模型将字向量、文本向量和位置向量的加和作为模型输入。特别地,在目前的BERT模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将playing分割为play和##ing;此外,对于中文,目前作者未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
需要注意的是,上图中只是简单介绍了单个句子输入BERT模型中的表示,实际上,在做Next Sentence Prediction任务时,在第一个句子的首部会加上一个[CLS] token,在两个句子中间以及最后一个句子的尾部会加上一个[SEP] token。
10、针对句子语义相似度/多标签分类/机器翻译翻译/文本生成的任务,利用BERT结构怎么做fine-tuning?
10.1 针对句子语义相似度的任务

实际操作时,上述最后一句话之后还会加一个[SEP] token,语义相似度任务将两个句子按照上述方式输入即可,之后与论文中的分类任务一样,将[CLS] token位置对应的输出,接上softmax做分类即可(实际上GLUE任务中就有很多语义相似度的数据集)。
10.2 针对多标签分类的任务
多标签分类任务,即MultiLabel,指的是一个样本可能同时属于多个类,即有多个标签。以商品为例,一件L尺寸的棉服,则该样本就有至少两个标签——型号:L,类型:冬装。
对于多标签分类任务,显而易见的朴素做法就是不管样本属于几个类,就给它训练几个分类模型即可,然后再一一判断在该类别中,其属于那个子类别,但是这样做未免太暴力了,而多标签分类任务,其实是可以只用一个模型来解决的。
利用BERT模型解决多标签分类问题时,其输入与普通单标签分类问题一致,得到其embedding表示之后(也就是BERT输出层的embedding),有几个label就连接到几个全连接层(也可以称为projection layer),然后再分别接上softmax分类层,这样的话会得到 [公式] ,最后再将所有的loss相加起来即可。这种做法就相当于将n个分类模型的特征提取层参数共享,得到一个共享的表示(其维度可以视任务而定,由于是多标签分类任务,因此其维度可以适当增大一些),最后再做多标签分类任务。
10.3 针对翻译的任务
针对翻译的任务,我自己想到一种做法,因为BERT本身会产生embedding这样的“副产品”,因此可以直接利用BERT输出层得到的embedding,然后在做机器翻译任务时,将其作为输入/输出的embedding表示,这样做的话,可能会遇到UNK的问题,为了解决UNK的问题,可以将得到的词向量embedding拼接字向量的embedding得到输入/输出的表示(对应到英文就是token embedding拼接经过charcnn的embedding的表示)。
UNK是Unknown Words的简称,在用seq2seq解决问题上经常出现,比如机器翻译任务,比如文本摘要任务。在decoder中生成某个单词的时候就会出现UNK问题。decoder本质上是一个语言模型,而语言模型本质上是一个多分类器,通过计算词汇表中的每个单词在当前条件下出现的概率,来生成该条件下的单词。为了提高计算效率,往往只选择出现频次最高的Top N个单词作为词汇表,其他的单词都用UNK来替换,这样导致decoder的时候会出现UNK。其中,很多UNK可能都是一些不常出现的但有意义的词,比如机构名、地名。
11、BERT应用于有空格丢失或者单词拼写错误等数据是否还是有效?有什么改进的方法?
11.1 BERT应用于有空格丢失的数据是否还是有效?
按照常理推断可能会无效了,因为空格都没有的话,那么便成为了一长段文本,但是具体还是有待验证。而对于有空格丢失的数据要如何处理呢?一种方式是利用Bi-LSTM + CRF做分词处理,待其处理成正常文本之后,再将其输入BERT做下游任务。
11.2 BERT应用于单词拼写错误的数据是否还是有效?
如果有少量的单词拼写错误,那么造成的影响应该不会太大,因为BERT预训练的语料非常丰富,而且很多语料也不够干净,其中肯定也还是会含有不少单词拼写错误这样的情况。但是如果单词拼写错误的比例比较大,比如达到了30%、50%这种比例,那么需要通过人工特征工程的方式,以中文中的同义词替换为例,将不同的错字/别字都替换成同样的词语,这样减少错别字带来的影响。例如花被、花珼、花呗、花呗、花钡均替换成花呗。
12、BERT的embedding向量如何的来的?
以中文为例,BERT模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入(还有position embedding和segment embedding);模型输出则是输入各字对应的融合全文语义信息后的向量表示。
而对于输入的token embedding、segment embedding、position embedding都是随机生成的,需要注意的是在Transformer论文中的position embedding由sin/cos函数生成的固定的值,而在这里代码实现中是跟普通word embedding一样随机生成的,可以训练的。作者这里这样选择的原因可能是BERT训练的数据比Transformer那篇大很多,完全可以让模型自己去学习。
13、BERT模型为什么要用mask?它是如何做mask的?其mask相对于CBOW有什么异同点?
13.1 BERT模型为什么要用mask?
BERT通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词。其实这个就是典型的Denosing Autoencoder的思路,那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似BERT这种预训练模式,被称为DAE LM。因此总结来说BERT模型 [Mask] 标记就是引入噪音的手段。
关于DAE LM预训练模式,优点是它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,然而缺点也很明显,主要在输入侧引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题。
13.2 它是如何做mask的?
给定一个句子,会随机Mask 15%的词,然后让BERT来预测这些Mask的词,如同上述10.1所述,在输入侧引入[Mask]标记,会导致预训练阶段和Fine-tuning阶段不一致的问题,因此在论文中为了缓解这一问题,采取了如下措施:
如果某个Token在被选中的15%个Token里,则按照下面的方式随机的执行:
- 80%的概率替换成[MASK],比如my dog is hairy → my dog is [MASK]
- 10%的概率替换成随机的一个词,比如my dog is hairy → my dog is apple
- 10%的概率替换成它本身,比如my dog is hairy → my dog is hairy
这样做的好处是,BERT并不知道[MASK]替换的是这15%个Token中的哪一个词(注意:这里意思是输入的时候不知道[MASK]替换的是哪一个词,但是输出还是知道要预测哪个词的),而且任何一个词都有可能是被替换掉的,比如它看到的apple可能是被替换的词。这样强迫模型在编码当前时刻的时候不能太依赖于当前的词,而要考虑它的上下文,甚至对其上下文进行”纠错”。比如上面的例子模型在编码apple是根据上下文my dog is应该把apple(部分)编码成hairy的语义而不是apple的语义。
13.3 其mask相对于CBOW有什么异同点?
相同点:CBOW的核心思想是:给定上下文,根据它的上文 Context-Before 和下文 Context-after 去预测input word。而BERT本质上也是这么做的,但是BERT的做法是给定一个句子,会随机Mask 15%的词,然后让BERT来预测这些Mask的词。
不同点:首先,在CBOW中,每个单词都会成为input word,而BERT不是这么做的,原因是这样做的话,训练数据就太大了,而且训练时间也会非常长。
其次,对于输入数据部分,CBOW中的输入数据只有待预测单词的上下文,而BERT的输入是带有[MASK] token的“完整”句子,也就是说BERT在输入端将待预测的input word用[MASK] token代替了。
另外,通过CBOW模型训练后,每个单词的word embedding是唯一的,因此并不能很好的处理一词多义的问题,而BERT模型得到的word embedding(token embedding)融合了上下文的信息,就算是同一个单词,在不同的上下文环境下,得到的word embedding是不一样的。
其实自己在整理这个问题时,萌生了新的问题,具体描述如下:为什么BERT中输入数据的[mask]标记为什么不能直接留空或者直接输入原始数据,在self-attention的Q K V计算中,不与待预测的单词做Q K V交互计算?
这个问题还要补充一点细节,就是数据可以像CBOW那样,每一条数据只留一个“空”,这样的话,之后在预测的时候,就可以将待预测单词之外的所有单词的表示融合起来(均值融合或者最大值融合等方式),然后再接上softmax做分类。
乍一看,感觉这个idea确实有可能可行,而且也没有看到什么不合理之处,但是需要注意的是,这样做的话,需要每预测一个单词,就要计算一套Q、K、V。就算不每次都计算,那么保存每次得到的Q、K、V也需要耗费大量的空间。总而言之,这种做法确实可能也是可行,但是实际操作难度却很大,从计算量来说,就是预训练BERT模型的好几倍(至少),而且要保存中间状态也并非易事。其实还有挺重要的一点,如果像CBOW那样做,那么文章的“创新”在哪呢~
14、BERT的两个预训练任务对应的损失函数是什么(用公式形式展示)?
BERT的损失函数由两部分组成,第一部分是来自 Mask-LM 的单词级别分类任务,另一部分是句子级别的分类任务。通过这两个任务的联合学习,可以使得 BERT 学习到的表征既有 token 级别信息,同时也包含了句子级别的语义信息。具体损失函数如下:
L ( θ , θ 1 , θ 2 ) = L 1 ( θ , θ 1 ) + L 2 ( θ , θ 2 ) L\left(\theta, \theta_{1}, \theta_{2}\right)=L_{1}\left(\theta, \theta_{1}\right)+L_{2}\left(\theta, \theta_{2}\right) L(θ,θ1,θ2)=L1(θ,θ1)+L2(θ,θ2)
其中 θ \theta θ 是 BERT 中 Encoder 部分的参数, θ 1 \theta_1 θ1 是 Mask-LM 任务中在 Encoder 上所接的输出层中的参数, θ 2 \theta_2 θ2 则是句子预测任务中在 Encoder 接上的分类器参数。因此,在第一部分的损失函数中,如果被 mask 的词集合为 M,因为它是一个词典大小 |V| 上的多分类问题,那么具体说来有:
L 1 ( θ , θ 1 ) = − ∑ i = 1 M log p ( m = m i ∣ θ , θ 1 ) , m i ∈ [ 1 , 2 , … , ∣ V ∣ ] L_{1}\left(\theta, \theta_{1}\right)=-\sum_{i=1}^{M} \log p\left(m=m_{i} | \theta, \theta_{1}\right), m_{i} \in[1,2, \ldots,|V|] L1(θ,θ1)=−i=1∑Mlogp(m=mi∣θ,θ1),mi∈[1,2,…,∣V∣]
在句子预测任务中,也是一个分类问题的损失函数:
L 2 ( θ , θ 2 ) = − ∑ j = 1 N log p ( n = n i ∣ θ , θ 2 ) , n i ∈ [ IsNext , NotNext ] L_{2}\left(\theta, \theta_{2}\right)=-\sum_{j=1}^{N} \log p\left(n=n_{i} | \theta, \theta_{2}\right), n_{i} \in[\text {IsNext}, \text {NotNext}] L2(θ,θ2)=−j=1∑Nlogp(n=ni∣θ,θ2),ni∈[IsNext,NotNext]
因此,两个任务联合学习的损失函数是:
L ( θ , θ 1 , θ 2 ) = − ∑ i = 1 M log p ( m = m i ∣ θ , θ 1 ) − ∑ j = 1 N log p ( n = n i ∣ θ , θ 2 ) L\left(\theta, \theta_{1}, \theta_{2}\right)=-\sum_{i=1}^{M} \log p\left(m=m_{i} | \theta, \theta_{1}\right)-\sum_{j=1}^{N} \log p\left(n=n_{i} | \theta, \theta_{2}\right) L(θ,θ1,θ2)=−i=1∑Mlogp(m=mi∣θ,θ1)−j=1∑Nlogp(n=ni∣θ,θ2)
具体的预训练工程实现细节方面,BERT 还利用了一系列策略,使得模型更易于训练,比如对于学习率的 warm-up 策略,使用的激活函数不再是普通的 ReLu,而是 GeLu,也使用了 dropout 等常见的训练技巧。
15、词袋模型到word2vec改进了什么?word2vec到BERT又改进了什么?
15.1 词袋模型到word2vec改进了什么?
词袋模型(Bag-of-words model)是将一段文本(比如一个句子或是一个文档)用一个“装着这些词的袋子”来表示,这种表示方式不考虑文法以及词的顺序。而在用词袋模型时,文档的向量表示直接将各词的词频向量表示加和。通过上述描述,可以得出词袋模型的两个缺点:
- 词向量化后,词与词之间是有权重大小关系的,不一定词出现的越多,权重越大。
- 词与词之间是没有顺序关系的。
而word2vec是考虑词语位置关系的一种模型。通过大量语料的训练,将每一个词语映射成一个低维稠密向量,通过求余弦的方式,可以判断两个词语之间的关系,word2vec其底层主要采用基于CBOW和Skip-Gram算法的神经网络模型。
因此,综上所述,词袋模型到word2vec的改进主要集中于以下两点:
- 考虑了词与词之间的顺序,引入了上下文的信息
- 得到了词更加准确的表示,其表达的信息更为丰富
15.2 word2vec到BERT又改进了什么?
word2vec到BERT的改进之处其实没有很明确的答案,如同上面的问题所述,BERT的思想其实很大程度上来源于CBOW模型,如果从准确率上说改进的话,BERT利用更深的模型,以及海量的语料,得到的embedding表示,来做下游任务时的准确率是要比word2vec高不少的。
实际上,这也离不开模型的“加码”以及数据的“巨大加码”。再从方法的意义角度来说,BERT的重要意义在于给大量的NLP任务提供了一个泛化能力很强的预训练模型,而仅仅使用word2vec产生的词向量表示,不仅能够完成的任务比BERT少了很多,而且很多时候直接利用word2vec产生的词向量表示给下游任务提供信息,下游任务的表现不一定会很好,甚至会比较差。
16、为什么BERT选择mask掉15%这个比例的词,可以是其他的比例吗?
BERT采用的Masked LM,会选取语料中所有词的15%进行随机mask,论文中表示是受到完形填空任务的启发,但其实与CBOW也有异曲同工之妙。
从CBOW的角度,这里 p = 15 % p=15\% p=15% 有一个比较好的解释是:在一个大小为 1 / p = 100 / 15 ≈ 7 1/p=100/15\approx7 1/p=100/15≈7 的窗口中随机选一个词,类似CBOW中滑动窗口的中心词,区别是这里的滑动窗口是非重叠的。
那从CBOW的滑动窗口角度,10%~20%都是还ok的比例。
上述非官方解释,是来自我的一位朋友提供的一个理解切入的角度,供参考。
来自@Serendipity:
15%的概率是通过实验得到的最好的概率,xlnet也是在这个概率附近,说明在这个概率下,既能有充分的mask样本可以学习,又不至于让segment的信息损失太多,以至于影响mask样本上下文信息的表达。然而因为在下游任务中不会出现token“”,所以预训练和fine-tune出现了不一致,为了减弱不一致性给模型带来的影响,被mask的token有80%的概率用“”表示,有10%的概率随机替换成某一个token,有10%的概率保留原来的token,这3个百分比也是多次实验得到的最佳组合,在这3个百分比的情况下,下游任务的fine-tune可以达到最佳的实验结果。
17、使用BERT预训练模型为什么最多只能输入512个词,最多只能两个句子合成?
个人推断是考虑了计算与运行效率综合做出的限制。
BERT输入的最大长度限制为512, 其中还需要包括[CLS]和[SEP]. 那么实际可用的长度仅为510.但是别忘了,每个单词tokenizer之后也有可能被分成好几部分. 所以实际可输入的句子长度远不足510.
BERT由于position-embedding的限制只能处理最长512个词的句子。如果文本长度超过512,有以下几种方式进行处理:
- 直接截断:从长文本中截取一部分,具体截取哪些片段需要观察数据,如新闻数据一般第一段比较重要就可以截取前边部分;
- 抽取重要片段:抽取长文本的关键句子作为摘要,然后进入BERT;
- 分段:把长文本分成几段,每段经过BERT之后再进行拼接或求平均或者接入其他网络如lstm。
另外transformer-xl 、LongFormer:用稀疏自注意力拓展模型文本容纳量等优秀设计也可以解决长文本。
这是Google BERT预训练模型初始设置的原因,前者对应Position Embeddings,后者对应Segment Embeddings

在BERT中,Token,Position,Segment Embeddings 都是通过学习来得到的,pytorch代码中它们是这样的
self.word_embeddings = Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = Embedding(config.type_vocab_size, config.hidden_size)
上述BERT pytorch代码来自:https://github.com/xieyufei1993/Bert-Pytorch-Chinese-TextClassification,结构层次非常清晰。
而在BERT config中
"max_position_embeddings": 512
"type_vocab_size": 2
因此,在直接使用Google 的BERT预训练模型时,输入最多512个词(还要除掉[CLS]和[SEP]),最多两个句子合成一句。这之外的词和句子会没有对应的embedding。
当然,如果有足够的硬件资源自己重新训练BERT,可以更改 BERT config,设置更大max_position_embeddings 和 type_vocab_size值去满足自己的需求。
https://zhuanlan.zhihu.com/p/132554155
18、为什么BERT在第一句前会加一个[CLS]标志?
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。如果是句子对的任务,那么两个句子间使用特定的token“[seq]”来分割。
为什么选它呢,因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层,每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。
而[CLS]位本身没有语义,经过12层,得到的是attention后所有词的加权平均,相比其他正常词,可以更好的表征句子语义。
当然,也可以通过对最后一层所有词的embedding做pooling去表征句子语义。
这里补充一下bert的输出,有两种,在BERT TF源码中对应:
- 一种是get_pooled_out(),就是上述[CLS]的表示,输出shape是[batch size,hidden size]。
- 一种是get_sequence_out(),获取的是整个句子每一个token的向量表示,输出shape是[batch_size, seq_length, hidden_size],这里也包括[CLS],因此在做token级别的任务时要注意它。
https://zhuanlan.zhihu.com/p/132554155
19、BERT非线性的来源在哪里?
前馈层的gelu激活函数和self-attention,self-attention是非线性的
https://zhuanlan.zhihu.com/p/132554155
20、为什么 Bert 的三个 Embedding 可以进行相加.
(Token Embedding、Segment Embedding、Position Embedding三个向量为什么可以相加呢?相加后向量的大小和方向就变了,语义不就变了吗?) 深度神经网络里变得非常复杂,本质上神经网络中每个神经元收到的信号也是“权重”相加得来。这三个向量为什么可以相加呢?因为三个embedding相加等价于三个原始one-hot的拼接再经过一个全连接网络。 相加后向量的大小和方向就变了,语义不就变了吗?这里不是语义变了,而是在训练的时候就是这几个向量相加进行训练的,训练完之后,将lookup后的向量进行相加,就能得到比较好的表示了。 从梯度的角度解释:
![]()
21、为什么bert需要额外的segment embedding?
因为bert预训练的其中一个任务是判断segment A和segment B之间的关系,这就需要embedding中能包含当前token属于哪个segment的信息,然而无论是token embedding,还是position embedding都无法表示出这种信息,因此额外创建一个segment embedding matrix用来表示当前token属于哪个segment的信息,segment vocab size就是2,其中index=0表示token属于segment A,index=1表示token属于segment B。
22、如何优化BERT效果
1 感觉最有效的方式还是数据。
2 把现有的大模型ERNIE_2.0_large, Roberta,roberta_wwm_ext_large、roberta-pair-large等进行ensemble,然后蒸馏原始的bert模型,这是能有效提高的,只是操作代价比较大。
3 BERT上面加一些网络结构,比如attention,rcnn等,个人得到的结果感觉和直接在上面加一层transformer layer的效果差不多,模型更加复杂,效果略好,计算时间略增加。
4 改进预训练,在特定的大规模数据上预训练,相比于开源的用百科,知道等数据训练的更适合你的任务(经过多方验证是一种比较有效的提升方案)。以及在预训练的时候去mask低频词或者实体词(听说过有人这么做有收益,但没具体验证)。
5 文本对抗
23、 如何优化BERT性能
1 压缩层数,然后蒸馏,直接复用12层bert的前4层或者前6层,效果能和12层基本持平,如果不蒸馏会差一些。
2 双塔模型(短文本匹配任务),将bert作为一个encoder,输入query编码成向量,输入title编码成向量,最后加一个DNN网络计算打分即可。离线缓存编码后的向量,在线计算只需要计算DNN网络。
3 int8预估,在保证模型精度的前提下,将Float32的模型转换成Int8的模型。
4 提前结束,大致思想是简单的case前面几层就可以输出分类结果,比较难区分的case走完12层
5 ALBERT 做了一些改进优化,主要是不同层之间共享参数,以及用矩阵分解降低embedding的参数
24、bert相比lstm优点是什么?
bert通过使用self-attention + position embedding对序列进行编码,lstm的计算过程是从左到右从上到下(如果是多层lstm的话),后一个时间节点的emb需要等前面的算完,而bert这种方式相当于并行计算,虽然模型复杂了很多,速度其实差不多。
25、BERT的一些改进模型
- ERNIE_1.0(baidu) : 模型结构不变,预训练的时候第一阶段基于切词mask,第二阶段基于实体mask,让模型在预训练的过程中根据上下文去学到一些词级别,实体级别,短语级别的信息。
- ERNIE_2.0:模型结构加入task embedding(作者将预训练任务分为:Word-aware, Structure-aware,Semantic-aware),不同类型的任务选取不同的task embedding,然后加了很多预训练任务,很多数据。
- ALBERT
- Factorized Embedding Parameterization,矩阵分解降低embedding参数量。
- Cross-layer Parameter Sharing,不同层之间共享参数。
- Sentence Order Prediction(SOP),next sentence任务的负样本增强。
二、Attention
1、为什么要引入Attention机制?
根据通用近似定理,前馈网络和循环网络都有很强的能力。但为什么还要引入注意力机制呢?
- 计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
- 优化算法的限制:虽然局部连接、权重共享以及pooling等优化操作可以让神经网络变得简单一些,有效缓解模型复杂度和表达能力之间的矛盾;但是,如循环神经网络中的长距离以来问题,信息“记忆”能力并不高。
可以借助人脑处理信息过载的方式,例如Attention机制可以提高神经网络处理信息的能力。
2、Attention机制有哪些?(怎么分类?)
当用神经网络来处理大量的输入信息时,也可以借鉴人脑的注意力机制,只 选择一些关键的信息输入进行处理,来提高神经网络的效率。按照认知神经学中的注意力,可以总体上分为两类:
- 聚焦式(focus)注意力:自上而下的有意识的注意力,主动注意——是指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力;
- 显著性(saliency-based)注意力:自下而上的有意识的注意力,被动注意——基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关;可以将max-pooling和门控(gating)机制来近似地看作是自下而上的基于显著性的注意力机制。
在人工神经网络中,注意力机制一般就特指聚焦式注意力。
3、Attention机制的计算流程是怎样的?

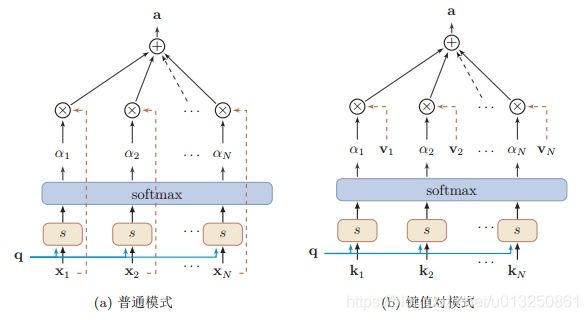
Attention机制的实质其实就是一个寻址(addressing)的过程,如上图所示:给定一个和任务相关的查询Query向量 q,通过计算与Key的注意力分布并附加在Value上,从而计算Attention Value,这个过程实际上是Attention机制缓解神经网络模型复杂度的体现:不需要将所有的N个输入信息都输入到神经网络进行计算,只需要从X中选择一些和任务相关的信息输入给神经网络。
注意力机制可以分为三步:一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均。
- step1-信息输入:用 X = [ x 1 , ⋅ ⋅ ⋅ , x N ] X = [x_1, · · · , x_N ] X=[x1,⋅⋅⋅,xN]表示N 个输入信息;
- step2-注意力分布计算:令Key=Value=X,则可以给出注意力分布
α i = s o f t m a x ( s ( k e y i , q ) ) = s o f t m a x ( s ( X i , q ) ) \alpha_i=softmax(s(key_i,q))=softmax(s(X_i,q)) αi=softmax(s(keyi,q))=softmax(s(Xi,q))
我们将 α i \alpha_i αi 称之为注意力分布(概率分布), s ( X i , q ) s(X_i,q) s(Xi,q) 为注意力打分机制,有几种打分机制:
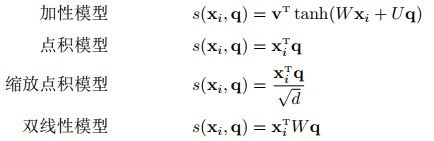
- step3-信息加权平均:注意力分布 α i \alpha_i αi 可以解释为在上下文查询q时,第i个信息受关注的程度,采用一种“软性”的信息选择机制对输入信息X进行编码为:
a t t ( q , X ) = ∑ i = 1 N α i X i att(q,X)=\sum_{i=1}^{N}{\alpha_iX_i} att(q,X)=i=1∑NαiXi
这种编码方式为软性注意力机制(soft Attention),软性注意力机制有两种:普通模式(Key=Value=X)和键值对模式(Key!=Value)。
4、Attention机制的变种有哪些?
与普通的Attention机制(图左)相比,Attention机制有哪些变种呢?
- 变种1-硬性注意力
之前提到的注意力是软性注意力,其选择的信息是所有输入信息在注意力 分布下的期望。还有一种注意力是只关注到某一个位置上的信息,叫做硬性注意力(hard attention)。硬性注意力有两种实现方式:(1)一种是选取最高概率的输入信息;(2)另一种硬性注意力可以通过在注意力分布式上随机采样的方式实现。硬性注意力模型的缺点:硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息。因此最终的损失函数与注意力分布之间的函数关系不可导,因此无法使用在反向传播算法进行训练。为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。硬性注意力需要通过强化学习来进行训练。——《神经网络与深度学习》 - 变种2-键值对注意力
即上图右边的键值对模式,此时Key!=Value,注意力函数变为:
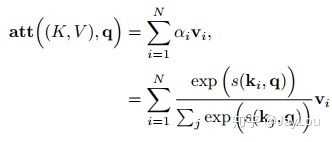
- 变种3-多头注意力
多头注意力(multi-head attention)是利用多个查询Q = [q1, · · · , qM],来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分,然后再进行拼接:
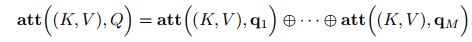
5、为什么自注意力模型(self-Attention model)在长距离序列中如此强大?
5.1 卷积或循环神经网络难道不能处理长距离序列吗?
当使用神经网络来处理一个变长的向量序列时,我们通常可以使用卷积网络或循环网络进行编码来得到一个相同长度的输出向量序列,如图所示:
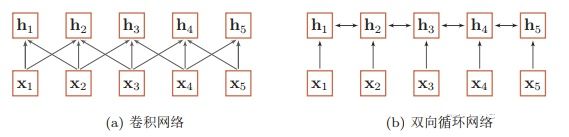
从上图可以看出,无论卷积还是循环神经网络其实都是对变长序列的一种“局部编码”:卷积神经网络显然是基于N-gram的局部编码;而对于循环神经网络,由于梯度消失等问题也只能建立短距离依赖。
5.2 要解决这种短距离依赖的“局部编码”问题,从而对输入序列建立长距离依赖关系,有哪些办法呢?
如果要建立输入序列之间的长距离依赖关系,可以使用以下两种方法:一 种方法是增加网络的层数,通过一个深层网络来获取远距离的信息交互,另一种方法是使用全连接网络。 ——《神经网络与深度学习》
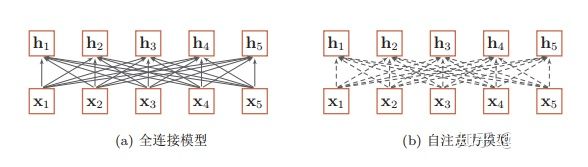
由上图可以看出,全连接网络虽然是一种非常直接的建模远距离依赖的模型, 但是无法处理变长的输入序列。不同的输入长度,其连接权重的大小也是不同的。
这时我们就可以利用注意力机制来“动态”地生成不同连接的权重,这就是自注意力模型(self-attention model)。由于自注意力模型的权重是动态生成的,因此可以处理变长的信息序列。
总体来说,为什么自注意力模型(self-Attention model)如此强大:利用注意力机制来“动态”地生成不同连接的权重,从而处理变长的信息序列。
5.3 自注意力模型(self-Attention model)具体的计算流程是怎样的呢?
同样,给出信息输入:用X = [x1, · · · , xN ]表示N 个输入信息;通过线性变换得到为查询向量序列,键向量序列和值向量序列:
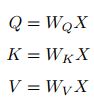
上面的公式可以看出,self-Attention中的Q是对自身(self)输入的变换,而在传统的Attention中,Q来自于外部。
注意力计算公式为:
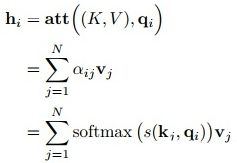
自注意力模型(self-Attention model)中,通常使用缩放点积来作为注意力打分函数,输出向量序列可以写为:
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q ⋅ K d k ) ⋅ V Attention(Q,K,V)=Softmax(\cfrac{Q·K}{\sqrt{d_k}})·V Attention(Q,K,V)=Softmax(dkQ⋅K)⋅V
6、Self-Attention 的核心是什么?
Self-Attention的核心是用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。
7、不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会有什么问题?
Self-Attention的核心是用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。
对于 Attention 机制,都可以用统一的 query/key/value 模式去解释,而对于 self-attention,一般会说它的 q=k=v,这里的相等实际上是指它们来自同一个基础向量,而在实际计算时,它们是不一样的,因为这三者都是乘了QKV参数矩阵的。那如果不乘,每个词对应的q,k,v就是完全一样的。
在self-attention中,sequence中的每个词都会和sequence中的每个词做点积去计算相似度,也包括这个词本身。
在相同量级的情况下, q i q_i qi 与 k i k_i ki 点积的值会是最大的(可以从“两数和相同的情况下,两数相等对应的积最大”类比过来)。那么在softmax后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示。而乘以QKV参数矩阵,会使得每个词的q,k,v都不一样,能很大程度上减轻上述的影响。
当然,QKV参数矩阵也使得多头,类似于CNN中的多核,去捕捉更丰富的特征/信息成为可能。
8、为什么Q和K使用不同的权重矩阵生成,为什么不能使用同一个值进行自身的点乘?
既然K和Q差不多(唯一区别是W_k和W_Q权值不同),直接拿K自己点乘就行了,何必再创建一个Q?创建了还要花内存去保存,浪费资源,还得更新参数。
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q ⋅ K d k ) ⋅ V Attention(Q,K,V)=Softmax(\cfrac{Q·K}{\sqrt{d_k}})·V Attention(Q,K,V)=Softmax(dkQ⋅K)⋅V
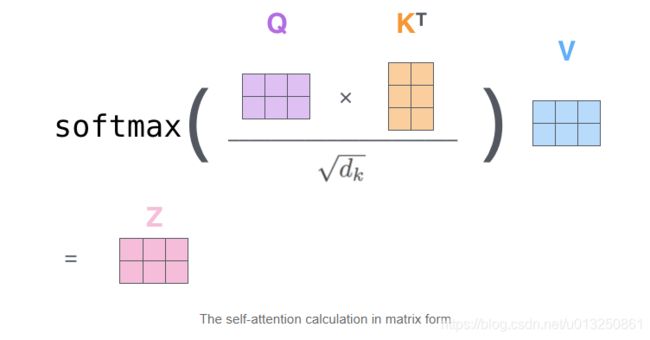
我们知道K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。这里解释下我理解的泛化能力,因为K和Q使用了不同的W_k, W_Q来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。
9、self-attention中为什么在进行softmax之前需要对注意进行scaled(为什么除以dk的平方根)
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q ⋅ K d k ) ⋅ V Attention(Q,K,V)=Softmax(\cfrac{Q·K}{\sqrt{d_k}})·V Attention(Q,K,V)=Softmax(dkQ⋅K)⋅V
(论文中解释是:向量的点积结果会很大,将softmax函数push到梯度很小的区域,scaled会缓解这种现象。怎么理解将sotfmax函数push到梯度很小区域?还有为什么scaled是维度的根号,不是其他的数?)
至于attention后的权重为啥要除以 d k \sqrt{d_k} dk,作者在论文中的解释是点积后的结果大小是跟维度成正比的,所以经过softmax以后,梯度就会变很小,除以 d k \sqrt{d_k} dk 后可以让attention的权重分布方差为1,而不是 d k d_k dk。
具体细节(简而言之就是softmax如果某个输入太大的话就会使得权重太接近于1,梯度很小)
10、Self-Attention 的时间复杂度是怎么计算的?
Self-Attention时间复杂度: O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d) ,这里,n是序列的长度,d是embedding的维度。
Self-Attention包括三个步骤:相似度计算,softmax和加权平均
它们的时间复杂度分别是:
- 相似度计算可以看作大小为(n,d)和(d,n)的两个矩阵相乘: ( n , d ) ∗ ( d , n ) = O ( n 2 ⋅ d ) (n,d)*(d,n)=O(n^2 \cdot d) (n,d)∗(d,n)=O(n2⋅d),得到一个(n,n)的矩阵
- softmax就是直接计算了,时间复杂度为 O ( n 2 ) O(n^2) O(n2)
- 加权平均可以看作大小为(n,n)和(n,d)的两个矩阵相乘: ( n , n ) ∗ ( n , d ) = O ( n 2 ⋅ d ) (n,n)*(n,d)=O(n^2 \cdot d) (n,n)∗(n,d)=O(n2⋅d),得到一个(n,d)的矩阵
因此,Self-Attention的时间复杂度是 O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d)。
这里再分析一下Multi-Head Attention,它的作用类似于CNN中的多核。
多头的实现不是循环的计算每个头,而是通过 transposes and reshapes,用矩阵乘法来完成的。In practice, the multi-headed attention are done with transposes and reshapes rather than actual separate tensors. —— 来自 google BERT 源码
Transformer/BERT中把 d ,也就是hidden_size/embedding_size这个维度做了reshape拆分,可以去看Google的TF源码或者上面的pytorch源码:hidden_size (d) = num_attention_heads (m) * attention_head_size (a),也即 d=m*a
并将 num_attention_heads 维度transpose到前面,使得Q和K的维度都是(m,n,a),这里不考虑batch维度。
这样点积可以看作大小为(m,n,a)和(m,a,n)的两个张量相乘,得到一个(m,n,n)的矩阵,其实就相当于(n,a)和(a,n)的两个矩阵相乘,做了m次,时间复杂度(感谢评论区指出)是 O ( n 2 ⋅ m ⋅ a ) = O ( n 2 ⋅ d ) O(n^2 \cdot m \cdot a)=O(n^2 \cdot d) O(n2⋅m⋅a)=O(n2⋅d)
张量乘法时间复杂度分析参见:矩阵、张量乘法的时间复杂度分析
因此Multi-Head Attention时间复杂度也是 O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d) ,复杂度相较单头并没有变化,主要还是transposes and reshapes 的操作,相当于把一个大矩阵相乘变成了多个小矩阵的相乘。
https://zhuanlan.zhihu.com/p/132554155
11、在常规 attention 中,一般有 k=v,那 self-attention 可以嘛?
self-attention 实际只是 attention 中的一种特殊情况,因此 k=v 是没有问题的,也即K,V参数矩阵相同。
扩展到 Multi-Head Attention 中,乘以 Q、K 参数矩阵之后,其实就已经保证了多头之间的差异性了,在 q和k 点积+softmax 得到相似度之后,从常规 attention 的角度,觉得再去乘以和 k 相等的 v 会更合理一些。
在 Transformer/BERT 中,完全独立的QKV参数矩阵,可以扩大模型的容量和表达能力。
但采用Q,K=V 这样的参数模式,我认为也是没有问题的,也能减少模型的参数,又不影响多头的实现。
三、Transformer
1、Transformer在哪里做了权重共享,为什么可以做权重共享?
Transformer在两个地方进行了权重共享:
(1)Encoder和Decoder间的Embedding层权重共享;
(2)Decoder中Embedding层和FC层权重共享。
对于(1),《Attention is all you need》中Transformer被应用在机器翻译任务中,源语言和目标语言是不一样的,但它们可以共用一张大词表,对于两种语言中共同出现的词(比如:数字,标点等等)可以得到更好的表示,而且对于Encoder和Decoder,嵌入时都只有对应语言的embedding会被激活,因此是可以共用一张词表做权重共享的。
论文中,Transformer词表用了bpe来处理,所以最小的单元是subword。英语和德语同属日耳曼语族,有很多相同的subword,可以共享类似的语义。而像中英这样相差较大的语系,语义共享作用可能不会很大。
但是,共用词表会使得词表数量增大,增加softmax的计算时间,因此实际使用中是否共享可能要根据情况权衡。
该点参考:https://www.zhihu.com/question/333419099/answer/743341017
对于(2),Embedding层可以说是通过onehot去取到对应的embedding向量,FC层可以说是相反的,通过向量(定义为 x)去得到它可能是某个词的softmax概率,取概率最大(贪婪情况下)的作为预测值。
那哪一个会是概率最大的呢?在FC层的每一行量级相同的前提下,理论上和 x 相同的那一行对应的点积和softmax概率会是最大的(可类比本文问题1)。
因此,Embedding层和FC层权重共享,Embedding层中和向量 x 最接近的那一行对应的词,会获得更大的预测概率。实际上,Decoder中的Embedding层和FC层有点像互为逆过程。
通过这样的权重共享可以减少参数的数量,加快收敛。
但开始我有一个困惑是:Embedding层参数维度是:(v,d),FC层参数维度是:(d,v),可以直接共享嘛,还是要转置?其中v是词表大小,d是embedding维度。
查看 pytorch 源码发现真的可以直接共享:
fc = nn.Linear(d, v, bias=False) # Decoder FC层定义
weight = Parameter(torch.Tensor(out_features, in_features)) # Linear层权重定义
Linear 层的权重定义中,是按照 (out_features, in_features) 顺序来的,实际计算会先将 weight 转置在乘以输入矩阵。所以 FC层 对应的 Linear 权重维度也是 (v,d),可以直接共享。
https://zhuanlan.zhihu.com/p/132554155
2、为什么Transformer 需要进行 Multi-head Attention
Attention is all you need论文中讲模型分为多个头,形成多个子空间,每个头关注不同方面的信息。
如果Multi-Head作用是关注句子的不同方面,那么不同的head就应该关注不同的Token;当然也有可能是关注的pattern相同,但是关注的内容不同,即V不同。
但是大量的paper表明,transformer或Bert的特定层有独特的功能,底层更偏向于关注语法;顶层更偏向于关注语义。
所以对Multi-head而言,同一层Transformer_block关注的方面应该整体是一致的。不同的head关注点也是一样。但是可视化同一层的head后,发现总有那么一两个头独一无二的,和其他头的关注不一样。
众多研究表明Multi-Head其实不是必须的,去掉一些头效果依然有不错的效果(而且效果下降可能是因为参数量下降),这是因为在头足够的情况下,这些头已经能够有关注位置信息、关注语法信息、关注罕见词的能力了,再多一些头,无非是一种enhance或noise而已。
3、为什么在进行多头关注的时候需要对每个head进行切割?
Transformer的多头注意力看上去是借鉴了CNN中同一卷积层内使用多个卷积核的思想,原文中使用了 8 个“scaled dot-product attention”,在同一“multi-head attention”层中,输入均为“KQV”,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息,在此之前的 A Structured Self-attentive Sentence Embedding 也有着类似的思想。
简而言之,就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。
其核心思想在于,抽取到更加丰富的特征信息。
回到题主的问题上来,如果只使用 one head 并且维度为 d m o d e l d_{model} dmodel ,相较于 8 head 并且维度为 d m o d e l / 8 d_{model} / 8 dmodel/8。首先存在计算量极大的问题,并且高维空间下的学习难度也会相应提升,这就难免文中实验出现的参数量大且效果不佳的情况,于是将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息,降低了计算量,而且取得了更好的效果,十分巧妙。
4、在计算注意力分数的时候如何对padding做mask操作?
mask是将一些不要用的值掩盖掉,使其不产生作用。有两种mask,第一种是padding mask,在所有scaled dot-product attention都用到;第二种是sequence mask,在decoder的self-attention里面用到。
padding mask:因为一个批量输入中,所有序列的长度使不同的。为了符合模型的输入方式,会用padding的方式来填充(比如填0),使所有序列的长度一致。但填充部分是没有意义的,所以在计算注意力的时候,不需要也不应该有注意力分配到这些填充的值上面。所以解决方式就是在填充的位置赋予一个很小的负值/负无穷(-np.inf)的值,经过softmax后的得分为0,即没有注意力分配到这个上面。
def padding_mask(seq_k, seq_q):
# shape(seq_k)=(B,L_k), shape(seq_q)=(B,L_q)
# 因为要计算seq_k和seq_q的相似程度,来表示注意力的得分
# padding mask要作用在QK^T上,所以padding mask是跟seq_k和seq_q序列长度相关的矩阵
# shape(padding mask)=(B, L_q, L_k)
len_q = seq_q.size(1)
# `PAD` is 0,这里要计算seq_k序列中,padding为0的地方,并将相应位置变为True,方便后面处理
pad_mask = seq_k.eq(0)
# 将每个seq_k序列扩展len_q次,shape=[B, L_q, L_k]
pad_mask = pad_mask.unsqueeze(1).expand(-1, len_q, -1)
return pad_mask
以上方法为大部分padding mask的计算形式,但实际上,这里做了seq_q全部有效的假设(没有padding),并不够精确 。自己的看法:上述代码expand操作,只是将seq_k中padding的部分重复了L_q次,并没有注意到,seq_q也有padding的部分。即在一个(L_q,L_k)矩阵中,只有最后几列需要掩码,实际矩阵的最后几行也需要掩码。(以后上图更形象)
sequence mask:在decoder部分,因为不能见到下文信息(防止泄漏),所以用mask的方式掩盖掉当前时刻t及之后的下文信息。具体,可产生一个对角线为0的上三角矩阵,将其作用到每个decoder的输入列上。代码如下:
def sequence_mask(seq):
batch_size, seq_len = seq.size()
mask = torch.triu(torch.ones((seq_len, seq_len), dtype=torch.uint8),
diagonal=1)
mask = mask.unsqueeze(0).expand(batch_size, -1, -1) # [B, L, L]
# 三角矩阵中,为1的部分是需要被掩码掉的
return mask
decoder-block有两个multi-head attention,下面的multi-head attention是目标输入的self-attention,需要用到1.padding mask:去除padding位置的影响;2.sequence mask:去掉下文穿越的影响。上面的multi-head attention只需要padding mask,因为下面的多头注意力已经磨平了下文信息。当encoder和decoder的输入序列长度一样时,可以通过padding mask+sequence mask作为scaled dot-product attention的attn_mask来实现。
其他情况的attn_mask(代码中的表达)等于padding mask
5、为什么inputs embedding要加入positional encoding?
因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。
因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。positional encoding的公式如下:
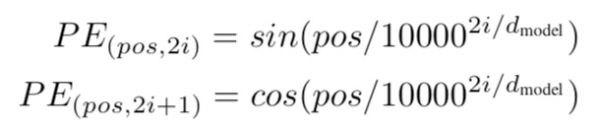
6、Transformer如何并行化的?解码器端可以做并行化吗?
Transformer的并行化主要体现在self-attention模块,在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出,在self-attention模块,对于某个序列 x 1 , x 2 , … , x n x_{1}, x_{2}, \dots, x_{n} x1,x2,…,xn,self-attention模块可以直接计算 x i , x j x_{i}, x_{j} xi,xj 的点乘结果,而RNN系列的模型就必须按照顺序从 x 1 x_{1} x1 计算到 x n x_{n} xn。
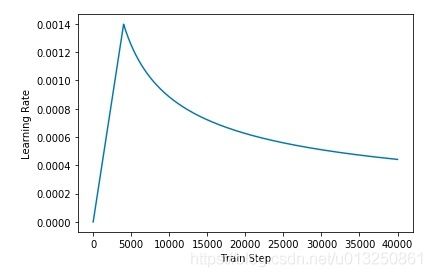
7、Transformer训练的时候学习率是如何设定的?
Transformer 使用 Adam 优化器,其 β 1 \beta_1 β1 为 0.9, β 2 \beta_2 β2 为0.98, ϵ \epsilon ϵ 为 1 0 − 9 10^{-9} 10−9。其学习率随着训练的进程变化:
![]()
其中,这个 warmup_step 设定为 4000。如此设计,学习率随着训练(Train Step)的变化就如下图所示
8、Transformer中multi-head机制是如何实现每个head提取的信息空间互斥的?
Transformer的多头注意力看上去是借鉴了CNN中同一卷积层内使用多个卷积核的思想,原文中使用了 8 个“scaled dot-product attention”,在同一“multi-head attention”层中,输入均为“KQV”,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息。简而言之,就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息。
9、Bert和Transformer在loss上的差异
transformer的loss是在decoder阶段计算的。bert预训练的loss由2部分构成,一部分是NSP的loss,就是token“[cls]”经过1层Dense,然后接一个二分类的loss,其中0表示segment B是segment A的下一句,1表示segment A和segment B来自2篇不同的文本;另一部分是MLM的loss,segment中每个token都有15%的概率被mask,而被mask的token有80%的概率用“”表示,有10%的概率随机替换成某一个token,有10%的概率保留原来的token,被mask的token经过encoder后乘以embedding matrix的转置会生成在vocab上的分布,然后计算分布和真实的token的one-hot形式的cross entropy,最后sum起来当作loss。这两部分loss相加起来当作total loss,利用adam进行训练。bert fine-tune的loss会根据任务性质来设计,例如分类任务中就是token“[cls]”经过1层Dense,然后接了一个二分类的loss;例如问题回答任务中会在paragraph上的token中预测一个起始位置,一个终止位置,然后以起始位置和终止位置的预测分布和真实分布为基础设计loss;例如序列标注,预测每一个token的词性,然后以每一个token在词性的预测分布和真实分布为基础设计loss。
bert在encoder之后,在计算NSP和MLM的loss之前,分别对NSP和MLM的输入加了一个Dense操作,这部分参数只对预训练有用,对fine-tune没用。而transformer在decoder之后就直接计算loss了,中间没有Dense操作。
10、为什么transformer的embedding后面接了一个dropout,而bert是先接了一个layer normalization,再接dropout?
LN是为了解决梯度消失的问题,dropout是为了解决过拟合的问题。在embedding后面加LN有利于embedding matrix的收敛。
在BERT应用中,如何解决长文本问题?
https://www.zhihu.com/question/327450789

论文
Transformer:Attention Is All You Need
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
源码
Transformer Pytorch源码
BERT Pytorch源码
HuggingFace Transformers
attention-is-all-you-need-pytorch
参考资料:
史上最细节的自然语言处理NLP/Transformer/BERT/Attention面试问题与答案
关于BERT的若干问题整理记录
超细节的BERT/Transformer知识点
目前主流的attention方法都有哪些?
Transformer和Bert相关知识解答
BERT相关面试题(不定期更新)
nlp面试题大全