前言
阅读本文前请先理解前面的两篇内容《iOS - 内存管理(一)之MRR》和 《iOS - 内存管理(二)之Copy》 ,因为本文会结合MRR的内存管理规则来解释ARC。
简述
ARC(Automatic Reference Counting)是在 Xcode 4.2的时候推出的编译器的一个功能,编译器简单的说就是把你写的代码翻译成机器能识别的代码,通常还会在这个过程中给你的代码添砖加瓦,ARC就是这样的一个功能,编译器在编译过程中自动地在合适的位置加入内存管理的代码,编译器给你加代码的原则还是遵守着MRR的那一套规则。
相信现在的iOS程序员都是基于ARC来敲代码了,ARC的出现目的就是让程序员在构建上层应用的时候可以更加地关注业务逻辑的代码,而不用再特别的操心下层的内存释放的问题(除有些特殊情况),但是作为一个合格的程序员还是应该了解下层的相关实现,这也是为什么还要去看MRR的原因。
PS:ARC只是针对Objective-C的对象的内存管理功能,我们常用的基于Foundation框架的对象都可以适用。但是某些时候为了一些特殊的功能实现可能会用到更下层的接口,比如Core Foundation,而Core Foundation是一套基于C语言的接口。虽然Core Foundation和Foundation的对象有桥接转换的方法,但是ARC并不适用于非Objective-C的对象。苹果也有一篇专门讲对于Core Foundation框架使用应该如何内存管理的文章,以后我有空也可以讲一下。
ARC的口诀
基于ARC管理内存,就一条口诀:只要还有强引用(strong reference)引用着一个对象,这个对象就不会被销毁,反之则对象会被销毁,内存会被释放。
变量的修饰符
要解释上面的口诀就要先说一下如何去定义强引用和其他类型的引用。
修饰符可以对变量进行修饰,也就是告诉编译器这个变量是用一种什么方式引用着它指向的对象,编译器就知道怎么去对待和维持这个对象的生命周期。
有4个变量修饰符__strong,__weak,__unsafe_unretained,__autoreleasing
我们说过ARC的本质就是底层遵守MRR的规则,然后编译器帮我们加上了调用retain,release或者autorelease的代码。我们就通过结合MRR的思想来让大家更容易理解这4个变量修饰符还有编译器在其中的作用。
以下讲解中代码示例涉及到的TestObj类就是很简单这样的:
//TestObj.h
@interface TestObj : NSObject
+ (TestObj *)obj;
@end
//TestObj.m
@implementation TestObj
+ (TestObj *)obj
{
TestObj * obj = [[TestObj alloc] init];
return obj;
}
@end
(1)来者不拒的__strong
__strong也是我们所说的强引用。
MMR中我们说过通过alloc/new/copy/mutableCopy方法返回的对象是直接持有的,需要管理它的释放。而非这些方法返回的对象,或者直接通过等号(=)赋值一个对象都只是有它的使用权。
在ARC模式下,只要一个变量有__strong标识了,就标识拥有了赋值的对象,不管赋值的对象是怎么来的。也可理解为只要见到__strong标识,编译器就会给那些不是你持有的对象自动加上retain,并且在变量超出作用域后自动调用了一次release。
结合代码来说明:
//ARC模式下
//结合MRR的思想和假设的编译器的行为来分析对象的内存释放
@autoreleasepool {
//通过类方法obj获取一个对象,注意不是使用alloc/new/copy/mutablCopy获取的对象
//所以这个+obj内部返回对象之前其实已经给对象调用了autorelease。
TestObj * __strong obj1 = [TestObj obj];
//本来这个obj1只有TestObj对象的使用权,并不持有,但是因为有__strong,编译器自动的加上了一句retain
//编辑器加的:[obj1 retain];
//将obj1的对象赋值给obj2,本来在MRR模式下,这种赋值并不会引起引用计数的变化
TestObj * __strong obj2 = obj1;
//因为看大obj2也有__strong
//编译器加的:[obj2 retain];
//通过alloc方法创建一个obj3
TestObj * __strong obj3 = [[TestObj alloc] init];
//因为这个是通过alloc创建的对象,表示这个对象返回回来就直接持有了,所以编译器不加上[obj3 retain]
.
.
.
//在即将超出作用域的时候,编译器会给所有__strong标识的变量调用一次release
//编译器加的:[obj1 release];
//编译器加的:[obj2 release];
//编译器加的:[obj3 release];
}
只要在作用域内,用__strong标记的变量就可以放心使用,不会被意外释放。也可以理解到为什么只要对象有被强引用就不会被销毁。
用MRR的思维来解释就是,用___strong修饰的变量,被赋值一个对象的时候,默认地把对象持有,在变量超出其作用域的时候会对引用的对象自动的调用一次release。
从上面的代码可以看到虽然注释的内容和代码好像很多,其实在ARC模式下我们需要敲的代码很少,在这个例子中实际就敲了3行,之后就能随心所欲地使用对象,也不用过分关心内存的问题,都交给编译器了,只要我们正确的标识了变量。
__strong是默认的标识符,即上面的代码例子中__strong都可以省去。
TestObj *obj1 = [TestObj obj];
等同于
TestObj * __strong obj1 = [TestObj obj];
(2)只白嫖不负责的__weak
__weak也称为弱引用,弱引用表示并不持有对象,当所引用的对象销毁了,这个变量就自动设为nil。
即使是使用alloc/new/copy/mutableCopy创建的对象,也不持有,结果就是这个对象没人要,所以一出来就销毁了,这里需要注意的是通过非这4个方法创建的对象,并不会因为__weak标识已创建就销毁,而是要等到超出autoreleasepool的时候才会销毁。
//ARC模式下
TestObj *__weak wObj;
@autoreleasepool {
//通过alloc方法创建一个obj1
TestObj * __weak obj1 = [[TestObj alloc] init];
//因为这个是通过alloc创建的对象,表示你要持有这个对象,但是__weak又表示我不要持有
//结果就是这个对象变成无人认领孤儿,创建完马上就被销毁了,XCode编译器马上就会给你警告。
//创建一个强引用的obj2
TestObj * obj2 = [[TestObj alloc] init];
//将obj2的对象传给当前作用域外的弱引用变量,因为wObj是弱引用个,所以不会对这个对象的生命周期产生影响
wObj = obj2;
.
.
.
}
//超出obj2的作用域后,强引用失效,对象被销毁
//大括号外的wObj此时被设置为nil,到此wObj == nil的
通常__weak只有在避免循环引用的时候才会使用,至于循环引用就是两个对象互相持有,或者或互相强引用对方,所以两者永远不能被销毁。必须将其中一方的引用改成__weak的才能打破这种死循环,最常见的就是delegate模式和block情况下使用。
(3)比__weak还不负责的__unsafe_unretained
__unsafe_unretained和__weak很像,唯一区别就是,__unsafe_unretained变量引用的对象再被销毁以后,不会被自动设置为nil,仍然指向对象销毁前的内存地址。所以它的名字叫做unsafe,此时你再尝试通过变量访问这个对象的属性或方法就会crash。
(4)思维长远的__autoreleasing
__autoreleasing可以说跟__strong有点类似,你可以放心地在autoreleasing块结束此前都可以正常地使用这个对象,而不用担心它被销毁。
这个对象也会被注册到autoreleasepool里,将autoreleasepool结束时候才会被销毁,而在变量的作用域结束后不会像__strong那样马上被release。
//ARC模式下
//结合MRR的思想和假设的编译器的行为来分析对象的内存释放
@autoreleasepool {
TestObj *__autoreleasing atObj;
TestObj *__weak wObj;
{
//创建一个强引用的obj1变量,这个TestObj对象的retainCount = 1
TestObj * obj1 = [[TestObj alloc] init];
//obj1赋值给atObj
atObj = obj1;
/*
由于atObj是__autoreleasing修饰的,相当于编译器会在此加上
[atObj retain];
[atObj autorelease];
由于只是autorelease,不是马上release,此时obj1引用的TestObj对象的retainCount = 2,
*/
//创建一个强引用的obj2变量,这个TestObj对象的retainCount = 1
TestObj * obj2 = [[TestObj alloc] init];
//obj2赋值给wObj
wObj = obj2;
/*
由于wObj是__weak修饰的,编译器不会在此加上retain和autorelease
此时obj2引用的TestObj对象的retainCount = 1,
*/
/*
编译器会对超出作用的变量所持有的对象调用release
obj1和obj2即将超出其作用域,所以再这里会自动调用release
[obj1 release];
[obj2 release];
执行完后,obj1引用的对象retainCount = 1,所以还未销毁
obj2引用的对象retainCount = 0,所以被销毁了
*/
}
//此时,超出了内部大括号的作用域,obj2引用的对象已经被销毁了,wObj也重新指向了nil
//obj1引用的对象还存活着,虽然obj1这个变量已经没有了
}
//执行到这个位置,超出了autoreleasepool,atObj1引用的对象的autorelease才被触发,才真正地调用了release,才被销毁。
(5)__autoreleasing的应用场景
但是但是,__autoreleasing在我们实际真实的iOS应用开发的时候,基本上是用不到的,我说的用不到只是针对业务程序员来说。实际上编译器是会用到它的,另外在一些方法声明的时候,你也会看到自动地给你加上的__autoreleasing,即时你没有显式地手敲出来。
(5.1)隐式使用的情况
隐式使用__autoreleasing的情况就是你的代码上看不到它,但是它编译后确实会存在,比如返回值:
//这个是我们的TestObj的创建对象的一个自定义类方法
+ (TestObj *)obj
{
/*
本来这个对象创建出来默认是__strong的,
但是因为编译器发现这个对象是要被当做返回值返回出去的,
所以不能在这个方法结束时候就release这个对象,
而应该放长远的眼光,使用autorelease,这个其实也是在MRR里我们说过
*/
TestObj * obj = [[TestObj alloc] init];
return obj;
}
我们再结合在讲__weak时候说的例子来说说隐式的__autoreleasing,还记得我们创建对象同时赋值给一个weak的变量,这个对象马上被销毁了么?
TestObj *__weak obj = [[TestObj alloc] init];
//这句TestObj对象已创建就被销毁了,因为它没有被强引用
假如用__weak修饰非new/alloc/copy/mutableCopy方法获得的对象会怎样?
@autoreleasepool {
//通过类方法obj获取一个对象,注意不是使用alloc/new/copy/mutablCopy获取的对象
//所以这个+obj内部返回对象之前其实已经给对象调用了autorelease。
TestObj * __weak obj1 = [TestObj obj];
//TestObj不会马上销毁,XCode编译器也不会提醒你警告。
.
.
.
//在即将超出autoreleasepool作用域的时候,obj1指向那个对象才会因为注册到了autoreleasepool而调用release方法进行释放
}
可以看到区别,虽然obj1是弱引用,但是通过类方法obj创建获得的对象不会马上被销毁,而是要等到超过autoreleasepool的作用域才会真实执行release。这就是因为obj方法里的编译器帮你返回了一个autoreleasing的对象的效果。
(5.2)显式使用的情况
显式使用是你在代码上能看到它,虽然可能不是你手动敲出来的,但是你如果手动去修改它是会影响到对象的销毁的。
最常见的显示使用的情况就是发生在指向对象的指针的指针时候。
什么叫做指向对象的指针的指针,有点拗口,我们知道对象内存是在heap里面,我们声明一个引用对象变量,实际上这个变量就是一个指针,它里面存放的就是这个对象再内存中的地址。
//学过C语言都知道*就是一个指针
//所以obj这个光秃秃的变量里面实际上就是一串数字,这串数字就是一个TestObj在内存中的地址
TestObj *obj = [[TestObj alloc] init];
那么TestObj **obj这个就是指针对象地址的指针,这个指针里存放的数字不是真实对象的内存地址,而是另一个指针的内存地址,这个另一个指针里存放的数字才是那个对象的内存地址。
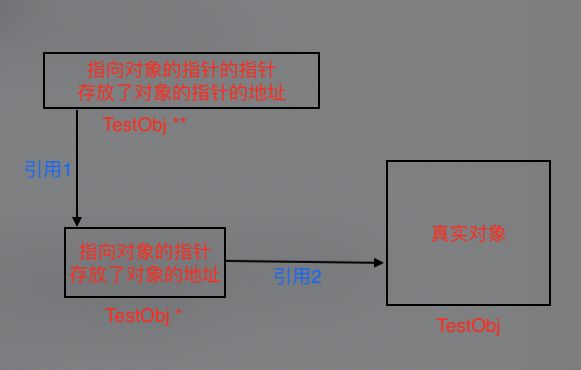
做过iOS开发的肯定熟悉用一种异常处理方式,不同于很多语言习惯用的try-catch,iOS开发时候经常会传递一个指向NSError的指针的指针给一个方法,这个方法执行有误的时候会在内部创建一个error对象赋值给传进来的对象指针。
*-(BOOL)doSomethingWithError:(NSError **)error;*
看到这个假方法是不是很眼熟?如果执行成功返回YES,失败返回NO,但是失败的时候还能通过读取error来知道具体错误原因,也就是说将是否创建error对象的权利交给这个方法。
接下来来说明它跟__autoreleasing之间的关系之前,先给我们的测试对象加上一些方法,变成以下的样子
//TestObj.m
@interface TestObj : NSObject
+ (TestObj *)obj;
//增加一个doSomethingWithError方法
- (BOOL)doSomethingWithError:(NSError **)error;
@end
//TestObj.h
@implementation TestObj
+ (TestObj *)obj
{
return [[TestObj alloc] init];
}
//重写dealloc方法,未了稍后测试时打印对象的销毁
- (void)dealloc
{
NSLog(@"dealloc:%@", [self className]);
}
/*
注意注意,当我们先在.h头文件里写了方法的定义后,再来.m里来敲这个方法的时候,XCode会自动地补全这个方法
可以看到error的类型多了修饰符变成NSError *__autoreleasing _Nullable *
_Nullable不重要,只是说明此方法这个参数不能传空
__autoreleasing才是我们要关注的重点
*/
- (BOOL)doSomethingWithError:(NSError *__autoreleasing _Nullable *)error
{
//做某事
NSLog(@"do something - start");
//做某事出错,设置错误
*error = [[NSError alloc] initWithDomain:@"test error" code:1234 userInfo:@{}];
/*
由于*error类型是NSError *__autoreleasing,所以编译器自动在这里加上了
[*error autoreleasing];
*/
//返回失败
return NO;
}
@end
为什么我们在.h头文件里写的NSError **到.m文件里会自动变成NSError __autoreleasing 类型?
那是因为编译器看到NSError这种指向指针的指针作为参数的时候就默认给它加上__autoreleasing的标识,为了延迟销毁在指针方法里创建的对象。
而在调用方,并没有显示地声明一个__autoreleasing修饰的对象,这样传递的话就会类型不匹配(修饰符也属于类型定义),那为什么没有报错呢?
因为编译器会改写我们的改码:
NSError * __strong error;
NSError *__autoreleasing tmp = error;
[obj doSomethingWithError:&tmp];
error = tmp;
它会创建一个_autoreleasing的临时变量,传给方法的实际上是这个临时变量,所以不会出现类型不匹配的警告。
鉴于以上编译器的行为,有的文章问告诉你,这个可以进行一定的优化:当你想要传递指针的指针的时候,就自己显式地申明一个__autoreleasing,比如NSError * __autoreleasing error。这样编译器就不用再隐式地帮你创建一个临时变量来做类型转换,可以提高一定的效率。
但是我个人的意见是你可以选择这么做,但是不是必要的,因为针对传递error这个情况不会持续频繁的动作,对app的实际影响很小。而ARC的出现的目的就是为了让程序员在写业务代码的时候更加专注入业务本身,所以就将手动内存管理简化为强引用和弱引用两个概念,并且编译器做了很多工作为了让程序员不要手写__autoreleasing。
为了等会测试可以看到error销毁的情况,我们给NSError也添加一个分类,实现dealloc方法。
@implementation NSError (dealloc)
- (void)dealloc
{
NSLog(@"dealloc:%@", [self className]);
}
@end
测试代码:
int main(int argc, const char * argv[]) {
@autoreleasepool {
TestObj *obj = [[TestObj alloc] init];
NSError *error = nil;
BOOL result = [obj doSomethingWithError:&error];
}
NSLog(@"out of release pool");
return 0;
}
执行打印结果:

可以看到在超出autoreleasepool时,obj和error都被销毁了,obj是由于超出作用域被release,而error是由于autorelease触发了真实的release。
如果我们将测试代码改成如下:
int main(int argc, const char * argv[]) {
{
TestObj *obj = [[TestObj alloc] init];
NSError *error = nil;
BOOL result = [obj doSomethingWithError:&error];
}
NSLog(@"out of release pool");
return 0;
}
去掉了autoreleaspool,只是设置了一个作用域,打印结果如下
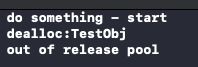
可以发现error并没有打印销毁,说明这个对象是被autoreleasing修饰了,由于没有设置releasepool它就没有触发release。
接下来我们继续做点测试,我们把.h和.m里的doSomethingWithError方法的参数强制声明为NSError __strong,如下
//TestObj.h
- (BOOL)doSomethingWithError:(NSError *__strong*)error;
//TestObj.m
- (BOOL)doSomethingWithError:(NSError *__strong*)error
{
...
}
这个时候我们来执行一下看看如何

可以看到虽然吧__autoreleasing强制改成了__strong后,执行结果并没有什么特别的影响。但是实际上本质是有区别的,前一种情况下,error的释放是由于它被注册到了autoreleasepool里,最后真是释放它的原因是超出autoreleasepool。而改成__strong后,在doSomethingWithError方法内部创建的error并不会调用autorelease,他最后的销毁是因为调用方的error变量超出了大括号作用域后失效了,从而对它引用的对象release一次。
我们可以将上面的autoreleasepool去掉之后再测试一次:
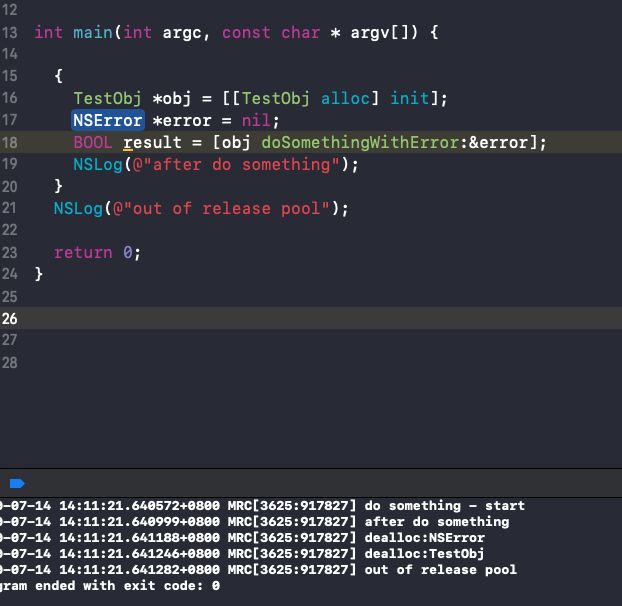
可以看到error对象依然被成功销毁了,足以证明改成__strong后error的释放不是由autoreleasepool来管理的了。
那么既然上述情况下对于使用方来说strong和autoreleasing没有区别,为什么编译器还要默认给指针的指针设置为__autoreleasing???
因为要遵守规则!什么是规则?MRR就是规则。谁创建的谁有责任释放。在这个例子中,调用方并不知道方法的执行是否会出错,所以调用方没有责任先创建一个error对象。
而方法的实现方是知道在什么时候需要创建error对象,实际上error的创建也是在实现方法里完成的,所以它就有责任释放这个对象,error创建后不能方法执行完就release,所以要延迟释放,因而会使用autorelease,最终结果就是它被标识为__autoreleasing。
所以说MRR就是ARC内存管理的下层规则,即时你使用的ARC来管理内存,实际上还是会处处透着MRR的风格。
总结
虽然我们在真实开发中,在ARC模式下,几乎不用主动地去顾忌内存管理的问题,最常见的只有在避免循环引用的时候才能使用一下__weak修饰符,把精力都放在业务的功能实现上。但是了解下层的原理也是很重要的,也能了解到早期的iOS开发程序员是如何写代码的,这对于今后业务层的代码实现也有帮助,可以对代码分层和模式设计有更多方面的认识。之后关于iOS内存管理这一块有空再去写针对CoreFoundation框架的规则。