如何进行聚类可视化_从爬虫到机器学习-高级Python数据处理与可视化

很多同学都听说过数据集 (dataset)。实际上,熟练使用爬虫技术获取和整理数据集是机器学习的第一步。而下载下来的数据如何处理则是一门功课,几乎就是机器学习这门课的核心要义之一。今天我们来讨论一下,从网上获取数据后,如何对这些数据进行高级数据分析,可视化,最终你将学会如何建立你的第一个机器学习数据集。但在这之前,需要对数据进行预处理,作为入门计算机视觉的第二步,话不多说,我们开始吧。
通过本文的学习,你将学会如何使用Python的Matplotlib、Pandas、DataFrame工具来进行高级数据处理以及数据可视化。
你将在支持PaddlePaddle和TensorFlow的项目中无缝地使用他们。

本文使用Python 3实现,笔者于Python 3.6,Python 3.7平台调试可运行。
建议使用Anaconda 3+Python 3.5-3.7使用。更高的版本目前支持还不完善。如果你做机器学习,3.6再适合你不过了。如果你好奇其中的奥义,可以参考我之前的文章:
本文约 3520 字,全文阅读约需 10 分钟,对照练习仅需 20 分钟。
阅读之前,可以先看看我之前的帖子。作为铺垫。如果你是来找轮子的,请直接继续看。
realkris:从爬虫到机器学习-Python网络数据分析zhuanlan.zhihu.com

一 聚类分析
今天是小张进入Department of Computer Science的第一天,午饭过后,他兴奋地在系楼里转来转去。前几天是数学建模与数据分析竞赛的决赛。优胜团队的作品在系楼里排列展示。小张从没了解过数据分析,虽然像看天书一样,但还是津津乐道其中。他注意到“聚类”这个词出现的频率很高。什么是聚类呢?
聚类分析,用人话说,就是以相似性为基础把相似的对象通过分类的方法分成不同的组别和子集。

比如,从中学起,你注意到班里的女孩子们总是一群一群的凑在一起。具有相同爱好和兴趣的女孩子会凑在一起。每一个团体独立于操场的某一隅。你拿出相机,把整个操场拍下来。用指头圈出每一组女孩子的位置。你就完成了聚类。

对于一张散点图,它可能由任何数据产生,而聚类通常有这样的特性:
- 基于相似性。
- 有多个聚类中心。
这里就要提一下大名鼎鼎的K-MEANS算法。也称K-均值算法。
看起来名字很高大上,其实K-均值算法只不过表示以空间中k个点为中心进行聚类,对最靠近他们的对象归类。(fig. 1)

这里有一个例子,以更快的了解K-MEANS,寻找学霸:

import numpy as np
from scipy.cluster.vq import vq, kmeans, whiten
list1 = [88.0, 74.0, 96.0, 85.0]
list2 = [92.0, 99.0, 95.0, 94.0]
list3 = [91.0, 87.0, 99.0, 95.0]
list4 = [78.0, 99.0, 97.0, 81.0]
list5 = [88.0, 78.0, 98.0, 84.0]
list6 = [100.0, 95.0, 100.0, 92.0]
data = np.array([list1,list2,list3,list4,list5,list6])
whiten = whiten(data)
centroids,_ = kmeans(whiten, 2)
result,_= vq(whiten, centroids)
print(result)
这里有个很关键的函数whiten():使用whiten来美化数据(缩放数据集的每个特征维度),每个特征除以所有观测值的标准偏差以给出其单位异差。
- kmeans(): 传入美化后的测试数据以及K值,返回K个均值以及聚类中心。
- vq(): 传入测试数据和中心值。计算上面的概念步骤3,获得最终的分簇。
你会得到这样的结果:
[1 0 0 1 1 0]所以大明,小明,大萌是学霸。

这样你就完成了一个基本的聚类过程。
二 Matplotlib可视化与图像属性控制
数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息。数据可视化与信息图形、信息可视化、科学可视化以及统计图形密切相关。当前,在研究、教学和开发领域,数据可视化乃是一个极为活跃而又关键的方面。“数据可视化”这条术语实现了成熟的科学可视化领域与较年轻的信息可视化领域的统一。
这里,我们介绍Matplotlib,最著名的Python 2D绘图库。他具备的优点是:
- 全部基于Plot Api;
- 集成pylab模块,包含Numpy中的常用函数。
光说不做假把式,你可以用这个例程自己尝试画一个心形图送给你的男/女朋友:

如果没有的话,送给自己也行。
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import math
t = np.linspace(0, math.pi, 1000)
x = np.sin(t)
y = np.cos(t) + np.power(x, 2.0 / 3)
# 按照点连线
plt.plot(x, y, color='red', linewidth=2)
plt.plot(-x, y, color='red', linewidth=2)
# 设置定义域,可以用来控制图像拉伸
plt.ylim(-1.5, 2)
plt.xlim(-1.5, 1.5)
# 将连线区域内填充少女粉
plt.fill_between(x,y,facecolor='pink')
plt.fill_between(-x,y,facecolor='pink')
#显示图像
plt.show()
你会得到:

怎么样,是不是心动了呢?别人过节送花多俗啊,我们过节可以送给女朋友一串代码。
哦,其实我并没有女朋友。
如果你想送 五颜六色 的心,你可以参考下面的色彩与样式表找到最适合自己的色彩。

比如我,猛男粉。
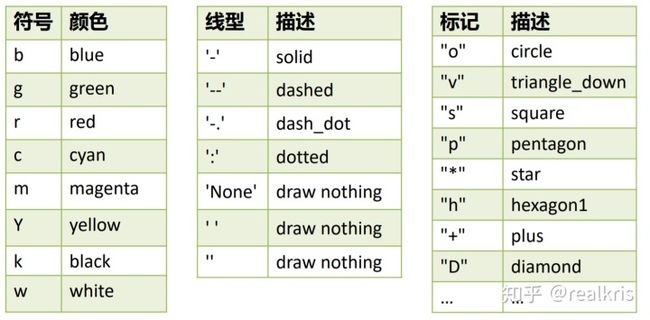
其他常用的函数:
axes(): 子图的容器。类似于小时候看电视画中画的效果。

加标题、横纵轴标志:
plt.title('Any title you want')
plt.xlabel('This is axis-x')
plt.ylabel('This is axis-y')
实战:
如果你想把一个列表,或者一个可以被可视化的数据结构,譬如你分析好的一个可能形成曲线的数组画成图。这里有一个精巧的例子。
为了举例,我们先创造一些数据:
t=np.arange(0.,4.,0.1)你可以直接使用pl.plot将这些数据可视化:
pl.plot(t,t,t,t+2,t,t**2)你将会得到

你,学会了么

三 Pandas绘图
pandas 是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas可以用来绘制三维图。这是一个官网的实例,我觉得很不错。你们感受一下效果:
导入包
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from pylab import *
创建fig
fig=figure()
ax=Axes3D(fig) # 3D图产生数据,可以是你想生成的任何数据
x=np.arange(-4,4,0.1)
y=np.arange(-4,4,0.1)
x,y=np.meshgrid(x,y)做目标计算
R=np.sqrt(x**2+y**2)
z=np.sin(R)打印图
ax.plot_surface(x,y,z,rstride=1,cstride=1,cmap='hot')
show()你会得到:

Pandas不仅可以将运行中变量数据可视化,其内建了强大的Turtle库。
如果上一章你送心心,女神没有理你,你可以尝试再送她一朵玫瑰。
Turtle库的使用很简单,核心思路是控制一只小乌龟,你给他 坐标 ,他就顺着坐标爬来爬去。你可以改变轨迹的颜色。这样玫瑰就产生了。这段代码几乎不需要理解,人人都可以大胆尝试!

如果你和我一样,小学微机课就接触了一款叫PCLogo的软件。那这个库你肯定心领神会。这个软件在我国覆盖量还是很大的。如果你没接触过,八成是微机课被你们班头占上主课去了。
import turtle
# 设置初始位置
turtle.penup()
turtle.left(90)
turtle.fd(200)
turtle.pendown()
turtle.right(90)
# 花蕊
turtle.fillcolor("red")
turtle.begin_fill()
turtle.circle(10,180)
turtle.circle(25,110)
turtle.left(50)
turtle.circle(60,45)
turtle.circle(20,170)
turtle.right(24)
turtle.fd(30)
turtle.left(10)
turtle.circle(30,110)
turtle.fd(20)
turtle.left(40)
turtle.circle(90,70)
turtle.circle(30,150)
turtle.right(30)
turtle.fd(15)
turtle.circle(80,90)
turtle.left(15)
turtle.fd(45)
turtle.right(165)
turtle.fd(20)
turtle.left(155)
turtle.circle(150,80)
turtle.left(50)
turtle.circle(150,90)
turtle.end_fill()
# 花瓣1
turtle.left(150)
turtle.circle(-90,70)
turtle.left(20)
turtle.circle(75,105)
turtle.setheading(60)
turtle.circle(80,98)
turtle.circle(-90,40)
# 花瓣2
turtle.left(180)
turtle.circle(90,40)
turtle.circle(-80,98)
turtle.setheading(-83)
# 叶子1
turtle.fd(30)
turtle.left(90)
turtle.fd(25)
turtle.left(45)
turtle.fillcolor("green")
turtle.begin_fill()
turtle.circle(-80,90)
turtle.right(90)
turtle.circle(-80,90)
turtle.end_fill()
turtle.right(135)
turtle.fd(60)
turtle.left(180)
turtle.fd(85)
turtle.left(90)
turtle.fd(80)
# 叶子2
turtle.right(90)
turtle.right(45)
turtle.fillcolor("green")
turtle.begin_fill()
turtle.circle(80,90)
turtle.left(90)
turtle.circle(80,90)
turtle.end_fill()
turtle.left(135)
turtle.fd(60)
turtle.left(180)
turtle.fd(60)
turtle.right(90)
turtle.circle(200,60)你会得到:

不,不香

四 数据访问
csv
对于初学者,在生活中,或者在机器学习、深度学习和数据挖掘等课程中,你会经常接触到一种叫"csv"的文件格式。
细心的小伙伴发现了,他和你手机通讯录的保存格式是一样的。

通讯录具有什么特点呢?

csv(逗号分隔值文件格式)由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号。简单来说,是一种很方便的通过逗号分隔类别,通过换行标记数据的数据类型。
它很简单,你一定要熟练掌握它的使用,不然在机器学习的学习中你将寸步难行!
真实的个人经历。

例如,这是一个很常见的机器学习数据集可能的样子:

这里介绍CSV的产生-存储,读取函数。
如果你记不住,建议收藏这篇文章,这几个函数你会用到成千上百次。
产生-存储:
csv可以由DataFrame格式无缝转换,确保你采用DataFrame作为优先数据格式。至于什么是DataFrame,我的主页有一篇常见机器学习数据结构的分享。这里不再赘述。
使用DataFrame() 转换数据(转换至DataFrame)
import pandas as pd
…
output = pd.DataFrame(source) //Source 表示转换前数据
output.to_csv('OUTPUT.csv')
//将DataFrame转换至CSV读取:
读取csv时需要注意绝对路径和相对路径。一般如果你的csv在py文件一个目录下,直接写文件名.csv就好,若非之,建议使用绝对路径。
但是,相对路径可以在工程化目录里提高兼容性和便携性。如果你正在写一个工程,优先使用相对路径。
读取csv:
pd.read_csv('output.csv')举个例子,读取一个股票涨停数据集的csv文件(发布于我的GitHub):
>>> result = pd.read_csv('stockAXP.csv')
>>> result
Unnamed: 0 close date high low open
0 0 76.800003 1495200600 77.349998 76.300003 76.550003
1 1 76.379997 1495114200 76.849998 75.970001 76.269997
2 2 76.370003 1495027800 78.129997 76.239998 78.129997
3 3 78.129997 1494941400 78.639999 77.839996 78.599998
…
csv看起来难,其实很简单。你已经学会了如何整理csv文件的本地访问。
Excel
大多数人都用过Excel。现在仍有好多商业上的数据使用excel保存,毕竟有查看方便的优势。

存取EXCEL的".xlsx"文件的本地访问和CSV类似。
保存数据为EXCEL .xlsx格式
# Filename: to_excel.py
…
output = pd.DataFrame(Source)
output.to_excel('output.xlsx', sheet_name='Sheet1')读取EXCEL .xlsx格式的DataSet文件
# Filename: read_excel.py
…
source = pd.read_excel('output.xlsx')之后和之前的读取都可以用DataFrame操作实现。
对照操作。这样,你就学会了数据分析之本地数据访问。

五 你的第一个Python本地数据分析案例
从简单到复杂的例程供大家参考。
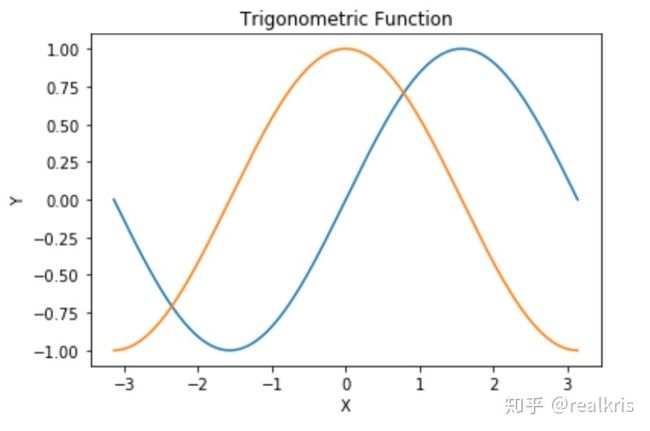
简单的三角函数计算
# Filename: mathA.py
import numpy as np
import pylab as pl
x = np.linspace(-np.pi, np.pi, 256)
s = np.sin(x)
c = np.cos(x)
pl.title('Trigonometric Function')
pl.xlabel('X')
pl.ylabel('Y')
pl.plot(x,s)
pl.plot(x,c)
你会得到
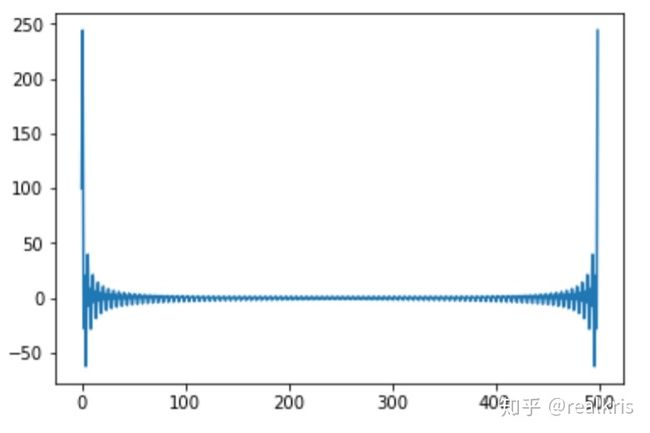
一组数据的快速傅里叶变换
# Filename: mathB.py
import scipy as sp
import pylab as pl
listA = sp.ones(500)
listA[100:300] = -1
f = sp.fft(listA)
pl.plot(f)
常见的图像处理
如果有兴趣,可以了解常用的Python图像处理库。在接下来的专栏也会提到。
- – Pillow(PIL)
- – OpenCV
PIL:
PIL(Python Image Library)是python的第三方图像处理库,但是由于其强大的功能与众多的使用人数,几乎已经被认为是python官方图像处理库了。其官方主页为:
Python Imaging Library (PIL)pythonware.comOpenCV:
名气最大!OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上,跨平台性做得非常好。它由一系列 C 函数和少量 C++ 类构成,所以效率很高的同时占用也很少,同时提供Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
OpenCVopencv.org另外还有一个Skimage,也是Python中常用的图像处理库。
skimagepypi.org
这是一个简单图像处理实例:
# Filename: pasteimg.py
from PIL import Image
im1 = Image.open('1.jpg')
print(im1.size, im1.format, im1.mode)
Image.open('1.jpg').save('2.png')
im2 = Image.open('2.png')
size = (288, 180)
im2.thumbnail(size)
out = im2.rotate(45)
im1.paste(out, (50,50))你会得到

到这里,你成功掌握了高级本地数据分析必备的工具。在从爬虫到机器学习的征途中,你已经掌握了一定的本地数据分析和数据可视化的能力。

下一篇文章将会介绍爬虫-高级Python数据处理与可视化的下一步:常见本地数据结构。以及如何在不掉坑的情况下正确打开的方法。
如果你觉得这篇文章不错,点赞,转发。
如果你觉得我挺有点东西,请关注我。你们的支持是我创作的动力!
我的GitHub:realkris
我的其他博客:
Python DataAnalizeblog.csdn.net
realkris Zhang,男,山东烟台人。研究方向:计算机视觉,神经网络与人工智能。大三在读cs,本科期间著有四篇科研论文,包括两篇EI,一篇核心,和一篇IEEE在投。获奖若干。专业划水二十年。目前在准备去美国读研。我想把我对于计算机视觉的passion point、理解与大家分享,少走弯路,一起造更多的轮子。