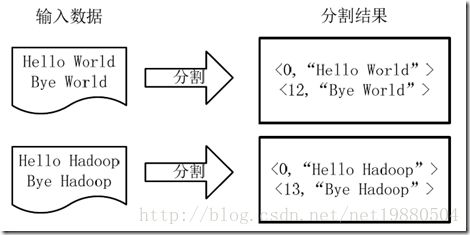
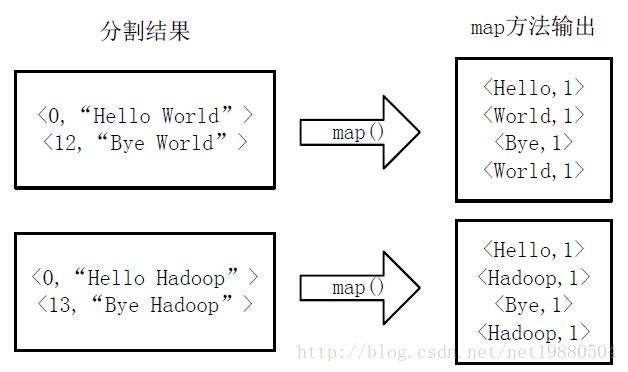
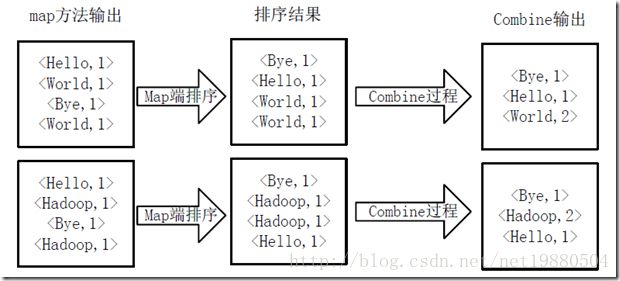
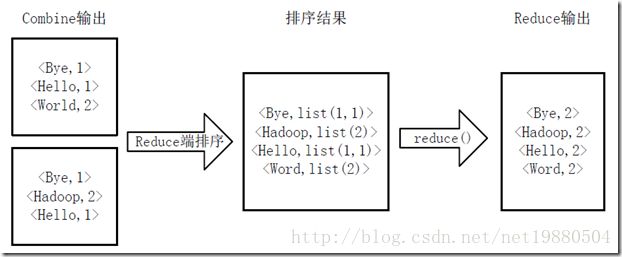
- Hive详解
一:Hive的历史价值1,Hive是Hadoop上的KillerApplication,Hive是Hadoop上的数据仓库,Hive同时兼具有数据仓库中的存储引擎和查询引擎的作用;而SparkSQL是一个更加出色和高级的查询引擎,所以在现在企业级应用中SparkSQL+Hive成为了业界使用大数据最为高效和流行的趋势。2,Hive是Facebook的推出,主要是为了让不动Java代码编程的人员也能
- zookeeper和hadoop
zookeeper操作连接zkCli.sh-server服务名称查看客户端指令helpZooKeeper-serverhost:portcmdargs statpath[watch] setpathdata[version] lspath[watch] delquota[-n|-b]path ls2path[watch] setAclpathacl setquot
- Hadoop 之 ZooKeeper (一)
devalone
HadoopHadoopZooKeeperHbaseChubbyznode
Hadoop之ZooKeeper本文介绍使用Hadoop的分布式协调服务构建通用的分布式应用——ZooKeeper。ZooKeeper是Hadoop分布式协调服务。写分布式应用是比较难的,主要是因为部分失败(partialfailure).当一条消息通过网络在两个节点间发送时,如果发生网络错误,发送者无法知道接受者是否接收到了这条消息。接收者可能在发生网络错误之前已经收到了这条消息,也可能没有收到
- ZooKeeper在Hadoop中的协同应用:从NameNode选主到分布式锁实现
码字的字节
hadoop布道师分布式zookeeperhadoop分布式锁
Hadoop与ZooKeeper概述Hadoop与ZooKeeper在大数据生态系统中的核心位置和交互关系Hadoop的架构与核心组件作为大数据处理的基石,Hadoop生态系统由多个关键组件构成。其核心架构主要包含HDFS(HadoopDistributedFileSystem)和YARN(YetAnotherResourceNegotiator)两大模块。HDFS采用主从架构设计,由NameNo
- 大数据开发系列(六)----Hive3.0.0安装配置以及Mysql5.7安装配置
Xiaoyeforever
hivemysqlhivehadoop数据库
一、Hive3.0.0安装配置:(Hive3.1.2有BUG)hadoop3.1.2Hive各个版本下载地址:http://archive.apache.org/dist/hive/,这里我们下载hive3.0.01、解压:tar-xzvfapache-hive-3.0.0-bin.tar.gz-C/usr/lib/JDK_2021cd/usr/lib/JDK_20212.改名称.将解压以后的文件
- 大数据编程基础
芝麻开门-新的起点
大数据大数据
3.1Java基础(重点)内容讲解Java是大数据领域最重要的编程语言之一。Hadoop、HBase、Elasticsearch等众多核心框架都是用Java开发的。因此,扎实的Java基础对于深入理解这些框架的底层原理和进行二次开发至关重要。为什么Java在大数据领域如此重要?生态系统:Hadoop生态系统原生就是Java构建的,使用Java进行开发可以无缝集成。跨平台性:Java的“一次编译,到
- 深入解析HBase如何保证强一致性:WAL日志与MVCC机制
码字的字节
hadoop布道师hadoopHBaseWALMVCC
HBase强一致性的重要性在分布式数据库系统中,强一致性是确保数据可靠性和系统可信度的核心支柱。作为Hadoop生态系统中关键的列式存储数据库,HBase需要处理金融交易、实时风控等高敏感场景下的海量数据操作,这使得强一致性成为其设计架构中不可妥协的基础特性。分布式环境下的数据一致性挑战在典型的HBase部署环境中,数据被分散存储在多个RegionServer节点上,同时面临以下核心挑战:1.跨节
- Hadoop中MapReduce和Yarn相关内容详解
接上一章写的HDFS说,Hadoop是一个适合海量数据的分布式存储和分布式计算的一个平台,上一章介绍了分布式存储,这一章介绍一下分布式计算——MapReduce。一、MapReduce设计理念map——>映射Reduce——>归纳mapreduce是一种必须构建在hadoop之上的大数据离线计算框架。因为mapreduce是给予磁盘IO来计算存储文件的,所以它具有一定的延时性,因此一般用来处理离线
- 阿里云MaxCompute SQL与Apache Hive区别面面观
大模型大数据攻城狮
阿里云odpssql物化maxcomputeudf开发sql语法
目录1.引爆开场:MaxCompute和Hive,谁才是大数据SQL的王者?2.架构大比拼:从Hadoop到Serverless的进化之路Hive的架构:老派但经典MaxCompute的架构:云原生新贵3.SQL语法的微妙差异:90%相似,10%决定胜负建表语句分区与分桶函数与UDF4.执行引擎的较量:MapReducevs飞天引擎Hive的MapReduce执行流程MaxCompute的飞天引擎
- 一文说清楚Hive
Hive作为ApacheHadoop生态的核心数据仓库工具,其设计初衷是为熟悉SQL的用户提供大规模数据离线处理能力。以下从底层计算框架、优点、场景、注意事项及实践案例五个维度展开说明。一、Hive底层分布式计算框架对比Hive本身不直接执行计算,而是将HQL转换为底层计算引擎的任务。目前支持的主流引擎及其特点如下:计算引擎核心原理优点缺点适用场景MapReduce基于“Map→Shuffle→R
- HBase 简介
HBase简介什么是HBaseApacheHBase是Hadoop数据库,一个分布式的、可伸缩的大数据存储。当您需要对大数据进行随机的、实时的读/写访问时,请使用ApacheHBase。这个项目的目标是在商品硬件的集群上托管非常大的表——数十亿行百万列的列。ApacheHBase是一个开源的、分布式的、版本化的、非关系的数据库,它模仿了Google的Bigtable:一个结构化数据的分布式存储系统
- sqoop的几个注意参数
yayooo
vimsqoop_export.shsqoop导出脚本:#!/bin/bashdb_name=gmallexport_data(){/opt/module/sqoop/bin/sqoopexport\--connect"jdbc:mysql://hadoop102:3306/${db_name}?useUnicode=true&characterEncoding=utf-8"\--username
- 大数据领域Hadoop集群搭建的详细步骤
AI天才研究院
ChatGPT实战ChatGPTAI大模型应用入门实战与进阶大数据hadoop分布式ai
大数据领域Hadoop集群搭建的详细步骤关键词:Hadoop集群、HDFS、YARN、大数据平台、分布式系统、集群配置、故障排查摘要:Hadoop作为大数据领域的基石框架,其集群搭建是数据工程师和运维人员的核心技能。本文从Hadoop核心架构出发,结合生产环境实践,详细讲解从环境准备、配置文件调优到集群启动验证的全流程,并涵盖常见问题排查与最佳实践。无论你是初学者还是需要优化现有集群的工程师,本文
- Zookeeper简单入门
灬哆啦A梦不吃鱼
zookeeper简介ZooKeeper(动物园管理员),顾名思义,是用来管理Hadoop(大象)、Hive(蜜蜂)、Pig(小猪)的管理员,同时ApacheHBase、ApacheSolr、LinkedInSensei等众多项目中都采用了ZooKeeper。ZooKeeper曾是Hadoop的正式子项目,后发展成为Apache顶级项目,与Hadoop密切相关但却没有任何依赖。它是一个针对大型应用
- 解锁Hive:高效数据查找的秘密武器
YangRyeon
hivehadoop数据仓库
Hive是什么?Hive是基于Hadoop的一个数据仓库工具,它能够进行数据提取、转化和加载操作,为存储、查询和分析Hadoop中的大规模数据提供了有效的机制。Hive能将结构化的数据文件映射为一张数据库表,让用户可以通过熟悉的SQL查询功能来处理数据。其内部机制是将SQL语句巧妙地转变成MapReduce任务来执行,大大降低了开发的难度和复杂性。例如,在面对海量的用户行为日志数据时,Hive就能
- Hive/Spark小文件解决方案(企业级实战)–参数和SQL优化
陆水A
大数据hivehadoopsparkpython
重点是后面的参数优化一、小文件的定义在Hadoop的上下文中,小文件的定义是相对于Hadoop分布式文件系统(HDFS)的块(Block)大小而言的。HDFS是Hadoop生态系统中的核心组件之一,它设计用于存储和处理大规模数据集。在HDFS中,数据被分割成多个块,每个块的大小是固定的,这个大小在Hadoop的不同版本和配置中可能有所不同,但常见的默认块大小包括128MB、256MB等。基于这个背
- 深入解析Hadoop资源隔离机制:Cgroups、容器限制与OOM Killer防御策略
码字的字节
hadoop布道师Hadoop资源隔离机制Cgroups容器限制OOMKiller
Hadoop资源隔离机制概述在分布式计算环境中,资源隔离是保障多任务并行执行稳定性的关键技术。Hadoop作为主流的大数据处理框架,其资源管理能力直接影响集群的吞吐量和任务成功率。随着YARN架构的引入,Hadoop实现了计算资源与存储资源的解耦,而资源隔离机制则成为YARN节点管理器(NodeManager)最核心的功能模块之一。资源隔离的必要性在共享集群环境中,典型问题表现为"资源侵占"现象:
- CC00096.kafka——|Hadoop&kafka.V03|——|kafka.v03|Kafka源码剖析|Topic创建流程|
yanqi_vip
kafkajava大数据pythonspark
一、Kafka源码剖析之Topic创建流程###---Topic创建~~~有两种创建方式:自动创建、手动创建。~~~在server.properties中配置auto.create.topics.enable=true时,~~~kafka在发现该topic不存在的时候会按照默认配置自动创建topic,~~~触发自动创建topic有以下两种情况:~~~Producer向某个不存在的Topic写入消息
- 大数据集群 多命令脚本
小P聊技术
1简介在大数据集群部署过程中,需要查询各个集群节点运行的服务状态,可使用批量命令脚本。2配置集群hostname2.1配置hostname文件1服务器hadoop01[root@localhost~]#echohostname1>/etc/hostnamehostnamehadoop012服务器hadoop02[root@localhost~]#echohadoop02>/etc/hostname
- R 和 Hadoop 大数据分析(一)
原文:annas-archive.org/md5/b7f3a14803c1b4d929732471e0b28932译者:飞龙协议:CCBY-NC-SA4.0前言企业每天获取的数据量呈指数增长。现在可以将这些海量信息存储在像Hadoop这样的低成本平台上。这些组织目前面临的难题是如何处理这些数据,以及如何从中提取关键见解。因此,R就成为了关键工具。R是一个非常强大的工具,它使得在数据上运行高级统计模
- Zookeeper 在 Kafka 中的作用详解:分布式协调服务的核心价值
lxb_不卑不亢
消息队列MQ进阶实战分布式zookeeperkafkarocketmq
摘要ApacheKafka是一个高吞吐、分布式的流处理平台,广泛应用于大数据和实时系统中。而ApacheZookeeper,则是Kafka背后不可或缺的“隐形英雄”。本文将深入剖析Zookeeper在Kafka架构中的核心作用,帮助开发者全面理解其在分布式协调、元数据管理、故障恢复等方面的关键地位。一、Zookeeper简介Zookeeper是一个开源的分布式协调服务,最初由Hadoop生态发展而
- 深入解析Hadoop中的推测执行:原理、算法与策略
码字的字节
hadoop布道师hadoop算法推测执行
Hadoop推测执行概述在分布式计算环境中,任务执行速度的不均衡是一个普遍存在的挑战。Hadoop作为主流的大数据处理框架,通过引入推测执行(SpeculativeExecution)机制有效缓解了这一问题。该技术本质上是一种乐观的容错策略,当系统检测到某些任务执行明显落后于预期进度时,会自动在其它计算节点上启动相同任务的冗余副本,最终选择最先完成的任务结果作为输出。核心设计动机推测执行的诞生源于
- spark on yarn
不辉放弃
pyspark大数据开发
SparkonYARN是指将Spark应用程序运行在HadoopYARN集群上,借助YARN的资源管理和调度能力来管理Spark的计算资源。这种模式能充分利用现有Hadoop集群资源,简化集群管理,是企业中常用的Spark部署方式。核心角色•Spark应用:包含Driver进程和Executor进程。Driver负责任务调度、逻辑处理;Executor负责执行具体任务并存储数据。•YARN组件:◦
- 深入解析Hadoop中的Region分裂与合并机制
码字的字节
hadoop布道师hadoop大数据分布式Region分裂合并
Hadoop与Region的基本概念Hadoop的分布式架构基础作为大数据处理的核心框架,Hadoop通过分布式存储和计算解决了海量数据的处理难题。其架构核心由HDFS(HadoopDistributedFileSystem)和MapReduce组成,前者负责数据的分布式存储,后者实现分布式计算。在HDFS中,数据被分割成固定大小的块(默认128MB)分散存储在集群节点上,而MapReduce则通
- 深入解析Hadoop RPC:技术细节与推广应用
码字的字节
hadoop布道师HadoopRPC
HadoopRPC框架概述在分布式系统的核心架构中,远程过程调用(RPC)机制如同神经网络般连接着各个计算节点。Hadoop作为大数据处理的基石,其自主研发的RPC框架不仅支撑着内部组件的协同运作,更以独特的工程哲学诠释了分布式通信的本质。透明性:隐形的通信桥梁HadoopRPC最显著的特征是其对通信细节的完美封装。当NameNode接收DataNode的心跳检测,或ResourceManager
- 深入解析Hadoop:大数据处理的基石
学习的锅
hadoop大数据分布式
随着信息技术的快速发展和互联网的普及,数据的产生速度极具增加。面对如此海量的数据,传统的数据处理工具显得力不从心。在这种背景下,诞生了一系列用于处理大数据的框架与工具,而ApacheHadoop便是其中最为知名和应用最广泛的一个。本文将深入解析Hadoop的基本原理、架构及其在大数据处理中的重要性。1.Hadoop的起源与发展Hadoop起源于Google公司的三篇奠基性论文:GoogleFile
- 大数据技术关键技术组件
大数据技术是一组用于处理、分析和管理大规模数据集的复杂方法和技术。这些数据集的特点是容量大、增长速度快,且结构多样化,包括结构化、半结构化和非结构化数据。传统数据库管理和分析工具在处理此类数据时效率低下或无法胜任,因此需要专门的大数据技术栈来支持高效的数据处理和智能决策。大数据技术的关键组件通常包括:分布式存储系统:HadoopDistributedFileSystem(HDFS):一个高度可扩展
- 大数据领域HDFS的集群资源管理优化
大数据洞察
大数据与AI人工智能大数据AI应用大数据hdfshadoopai
大数据领域HDFS的集群资源管理优化关键词:HDFS;集群资源管理;存储优化;性能调优;副本策略;负载均衡;NameNode优化摘要:HDFS(Hadoop分布式文件系统)作为大数据领域的基石,承载着海量数据的存储与管理重任。随着数据规模爆炸式增长和业务复杂度提升,HDFS集群的资源管理面临着"存不下、跑不快、管不好"的三重挑战:存储资源浪费与不足并存、计算与存储资源匹配失衡、集群运维效率低下。本
- 深入探索Hadoop技术:全面学习指南
引言在大数据时代,高效地存储、处理和分析海量数据已成为企业决策与创新的关键驱动力。Hadoop,作为开源的大数据处理框架,以其强大的分布式存储和并行计算能力,以及丰富的生态系统,为企业提供了应对大规模数据挑战的有效解决方案。本文旨在为初学者和进阶者提供一份详尽的Hadoop技术学习指南,涵盖HDFS、MapReduce、YARN等核心组件,以及Hive、Pig、HBase等生态系统工具,助您踏上H
- HDFS文件系统
HDFS文件系统是hadoop生态系统的核心,主要用于分布式文件存储,它具备高可用,流式读取,文件结构简单,跨平台的特点,它的集群采用的是主从结构,分为命名节点和数据节点,命名节点主要用于元数据管理(例如对目录,文件的创建,数据块与数据节点的关系维护管理)及数据节点管理(例如数据节点之间数据的复制,节点状态的维护,节点间数据的均衡),该文件系统最基本的存储单位是block即数据块,默认大小是64M
- jquery实现的jsonp掉java后台
知了ing
javajsonpjquery
什么是JSONP?
先说说JSONP是怎么产生的:
其实网上关于JSONP的讲解有很多,但却千篇一律,而且云里雾里,对于很多刚接触的人来讲理解起来有些困难,小可不才,试着用自己的方式来阐释一下这个问题,看看是否有帮助。
1、一个众所周知的问题,Ajax直接请求普通文件存在跨域无权限访问的问题,甭管你是静态页面、动态网页、web服务、WCF,只要是跨域请求,一律不准;
2、
- Struts2学习笔记
caoyong
struts2
SSH : Spring + Struts2 + Hibernate
三层架构(表示层,业务逻辑层,数据访问层) MVC模式 (Model View Controller)
分层原则:单向依赖,接口耦合
1、Struts2 = Struts + Webwork
2、搭建struts2开发环境
a>、到www.apac
- SpringMVC学习之后台往前台传值方法
满城风雨近重阳
springMVC
springMVC控制器往前台传值的方法有以下几种:
1.ModelAndView
通过往ModelAndView中存放viewName:目标地址和attribute参数来实现传参:
ModelAndView mv=new ModelAndView();
mv.setViewName="success
- WebService存在的必要性?
一炮送你回车库
webservice
做Java的经常在选择Webservice框架上徘徊很久,Axis Xfire Axis2 CXF ,他们只有一个功能,发布HTTP服务然后用XML做数据传输。
是的,他们就做了两个功能,发布一个http服务让客户端或者浏览器连接,接收xml参数并发送xml结果。
当在不同的平台间传输数据时,就需要一个都能解析的数据格式。
但是为什么要使用xml呢?不能使json或者其他通用数据
- js年份下拉框
3213213333332132
java web ee
<div id="divValue">test...</div>测试
//年份
<select id="year"></select>
<script type="text/javascript">
window.onload =
- 简单链式调用的实现技术
归来朝歌
方法调用链式反应编程思想
在编程中,我们可以经常遇到这样一种场景:一个实例不断调用它自身的方法,像一条链条一样进行调用
这样的调用你可能在Ajax中,在页面中添加标签:
$("<p>").append($("<span>").text(list[i].name)).appendTo("#result");
也可能在HQ
- JAVA调用.net 发布的webservice 接口
darkranger
webservice
/**
* @Title: callInvoke
* @Description: TODO(调用接口公共方法)
* @param @param url 地址
* @param @param method 方法
* @param @param pama 参数
* @param @return
* @param @throws BusinessException
- Javascript模糊查找 | 第一章 循环不能不重视。
aijuans
Way
最近受我的朋友委托用js+HTML做一个像手册一样的程序,里面要有可展开的大纲,模糊查找等功能。我这个人说实在的懒,本来是不愿意的,但想起了父亲以前教我要给朋友搞好关系,再加上这也可以巩固自己的js技术,于是就开始开发这个程序,没想到却出了点小问题,我做的查找只能绝对查找。具体的js代码如下:
function search(){
var arr=new Array("my
- 狼和羊,该怎么抉择
atongyeye
工作
狼和羊,该怎么抉择
在做一个链家的小项目,只有我和另外一个同事两个人负责,各负责一部分接口,我的接口写完,并全部测联调试通过。所以工作就剩下一下细枝末节的,工作就轻松很多。每天会帮另一个同事测试一些功能点,协助他完成一些业务型不强的工作。
今天早上到公司没多久,领导就在QQ上给我发信息,让我多协助同事测试,让我积极主动些,有点责任心等等,我听了这话,心里面立马凉半截,首先一个领导轻易说
- 读取android系统的联系人拨号
百合不是茶
androidsqlite数据库内容提供者系统服务的使用
联系人的姓名和号码是保存在不同的表中,不要一下子把号码查询来,我开始就是把姓名和电话同时查询出来的,导致系统非常的慢
关键代码:
1, 使用javabean操作存储读取到的数据
package com.example.bean;
/**
*
* @author Admini
- ORACLE自定义异常
bijian1013
数据库自定义异常
实例:
CREATE OR REPLACE PROCEDURE test_Exception
(
ParameterA IN varchar2,
ParameterB IN varchar2,
ErrorCode OUT varchar2 --返回值,错误编码
)
AS
/*以下是一些变量的定义*/
V1 NUMBER;
V2 nvarc
- 查看端号使用情况
征客丶
windows
一、查看端口
在windows命令行窗口下执行:
>netstat -aon|findstr "8080"
显示结果:
TCP 127.0.0.1:80 0.0.0.0:0 &
- 【Spark二十】运行Spark Streaming的NetworkWordCount实例
bit1129
wordcount
Spark Streaming简介
NetworkWordCount代码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
- Struts2 与 SpringMVC的比较
BlueSkator
struts2spring mvc
1. 机制:spring mvc的入口是servlet,而struts2是filter,这样就导致了二者的机制不同。 2. 性能:spring会稍微比struts快。spring mvc是基于方法的设计,而sturts是基于类,每次发一次请求都会实例一个action,每个action都会被注入属性,而spring基于方法,粒度更细,但要小心把握像在servlet控制数据一样。spring
- Hibernate在更新时,是可以不用session的update方法的(转帖)
BreakingBad
Hibernateupdate
地址:http://blog.csdn.net/plpblue/article/details/9304459
public void synDevNameWithItil()
{Session session = null;Transaction tr = null;try{session = HibernateUtil.getSession();tr = session.beginTran
- 读《研磨设计模式》-代码笔记-观察者模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.List;
import java.util.Observable;
import java.util.Observer;
/**
* “观
- 重置MySQL密码
chenhbc
mysql重置密码忘记密码
如果你也像我这么健忘,把MySQL的密码搞忘记了,经过下面几个步骤就可以重置了(以Windows为例,Linux/Unix类似):
1、关闭MySQL服务
2、打开CMD,进入MySQL安装目录的bin目录下,以跳过权限检查的方式启动MySQL
mysqld --skip-grant-tables
3、新开一个CMD窗口,进入MySQL
mysql -uroot
- 再谈系统论,控制论和信息论
comsci
设计模式生物能源企业应用领域模型
再谈系统论,控制论和信息论
偶然看
- oracle moving window size与 AWR retention period关系
daizj
oracle
转自: http://tomszrp.itpub.net/post/11835/494147
晚上在做11gR1的一个awrrpt报告时,顺便想调整一下AWR snapshot的保留时间,结果遇到了ORA-13541这样的错误.下面是这个问题的发生和解决过程.
SQL> select * from v$version;
BANNER
-------------------
- Python版B树
dieslrae
python
话说以前的树都用java写的,最近发现python有点生疏了,于是用python写了个B树实现,B树在索引领域用得还是蛮多了,如果没记错mysql的默认索引好像就是B树...
首先是数据实体对象,很简单,只存放key,value
class Entity(object):
'''数据实体'''
def __init__(self,key,value)
- C语言冒泡排序
dcj3sjt126com
算法
代码示例:
# include <stdio.h>
//冒泡排序
void sort(int * a, int len)
{
int i, j, t;
for (i=0; i<len-1; i++)
{
for (j=0; j<len-1-i; j++)
{
if (a[j] > a[j+1]) // >表示升序
- 自定义导航栏样式
dcj3sjt126com
自定义
-(void)setupAppAppearance
{
[[UILabel appearance] setFont:[UIFont fontWithName:@"FZLTHK—GBK1-0" size:20]];
[UIButton appearance].titleLabel.font =[UIFont fontWithName:@"FZLTH
- 11.性能优化-优化-JVM参数总结
frank1234
jvm参数性能优化
1.堆
-Xms --初始堆大小
-Xmx --最大堆大小
-Xmn --新生代大小
-Xss --线程栈大小
-XX:PermSize --永久代初始大小
-XX:MaxPermSize --永久代最大值
-XX:SurvivorRatio --新生代和suvivor比例,默认为8
-XX:TargetSurvivorRatio --survivor可使用
- nginx日志分割 for linux
HarborChung
nginxlinux脚本
nginx日志分割 for linux 默认情况下,nginx是不分割访问日志的,久而久之,网站的日志文件将会越来越大,占用空间不说,如果有问题要查看网站的日志的话,庞大的文件也将很难打开,于是便有了下面的脚本 使用方法,先将以下脚本保存为 cutlog.sh,放在/root 目录下,然后给予此脚本执行的权限
复制代码代码如下:
chmo
- Spring4新特性——泛型限定式依赖注入
jinnianshilongnian
springspring4泛型式依赖注入
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- centOS安装GCC和G++
liuxihope
centosgcc
Centos支持yum安装,安装软件一般格式为yum install .......,注意安装时要先成为root用户。
按照这个思路,我想安装过程如下:
安装gcc:yum install gcc
安装g++: yum install g++
实际操作过程发现,只能有gcc安装成功,而g++安装失败,提示g++ command not found。上网查了一下,正确安装应该
- 第13章 Ajax进阶(上)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- How to determine BusinessObjects service pack and fix pack
blueoxygen
BO
http://bukhantsov.org/2011/08/how-to-determine-businessobjects-service-pack-and-fix-pack/
The table below is helpful. Reference
BOE XI 3.x
12.0.0.
y BOE XI 3.0 12.0.
x.
y BO
- Oracle里的自增字段设置
tomcat_oracle
oracle
大家都知道吧,这很坑,尤其是用惯了mysql里的自增字段设置,结果oracle里面没有的。oh,no 我用的是12c版本的,它有一个新特性,可以这样设置自增序列,在创建表是,把id设置为自增序列
create table t
(
id number generated by default as identity (start with 1 increment b
- Spring Security(01)——初体验
yang_winnie
springSecurity
Spring Security(01)——初体验
博客分类: spring Security
Spring Security入门安全认证
首先我们为Spring Security专门建立一个Spring的配置文件,该文件就专门用来作为Spring Security的配置