项目笔记4-xml文件的生成和python解析xml文件
项目笔记4-xml文件的生成和python解析xml文件
- 目录
- 一.xml文件的生成
- 1.步骤:
- 2.生成多个xml文件
- 二.遍历本目录下所有的文件
- 1.不包括目录的目录里的文件
- 2.包括目录的目录里的文件
- 3.解析同一目录下的所有xml文件
- 二. java实现主成分分析
- 1.主成分分析PCA
- 2.矩阵运算包Ejml
- 3.java实现主成分分析PCA
- 四.python实现主成分分析PCA
- 五.python解析xml文件
- 1.SAX (simple API for XML )
- 2.DOM(Document Object Model)
- 3.ElementTree
- 六.过程中的知识点总结
- 1.循环-while
- 2.随机数
- 3.随机字符串
- 4.几个字符串内随机选取
- 5.整型与字符型相互转换
- 6.python解析xml文件中遇到的错误及解决办法
目录
一.xml文件的生成
1.步骤:
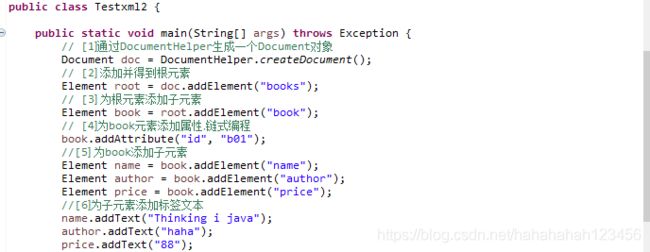
(1)通过DocumentHelper生成一个Document对象
(2)添加并得到根元素–addElement(“根元素”)
(3)为根元素添加子元素----addElement(“子元素”)
(4)为子元素添加属性,链式编程–addAttribute(“属性名”,“属性值”)或(2)(3)(4)整合嵌套:addElement(“根元素”).addElement(“子元素”).addAttribute(“属性名”,“属性值”)
(5)为子元素添加子元素
(6)为子元素添加文本标签
(7)将对象输出xml文件中–对象.write(writer)
(8)关闭资源–writer.close()
简单文件输出:
情况一:简单的格式输出

![]()
情况二:良好的格式输出

2.生成多个xml文件
package com.bjsxt.xml;
import java.io.File;
import java.io.FileWriter;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class Testxml2 {
public static void main(String[] args) throws Exception {
// [1]通过DocumentHelper生成一个Document对象
Document doc = DocumentHelper.createDocument();
// [2] 添加并得到根元素
Element root = doc.addElement("books");
int a=10;
while (a<25) {
// [3] 为根元素添加子元素
Element book = root.addElement("book");
// [4]为book元素添加属性,链式编程
String id = "b"+a;
book.addAttribute("id", id);
//[5] 为book添加子元素
Element name = book.addElement("name");
Element author = book.addElement("author");
Element price = book.addElement("price");
//[6]为子元素添加标签文本
int i=(int)(Math.round(Math.random()*100+1));
System.out.println("随机生成的数字为:"+i);
String[] str1 = { "数学", "语文", "英语", "物理", "化学" };
int random1 = (int) ( Math.random () * 5 );
System.out.println ("名字:"+str1[random1]);
name.addText(str1[random1]);
String[] str2 = { "张三", "李四", "王五", "孙六", "陈七" };
int random2 = (int) ( Math.random () * 5 );
System.out.println ("作者:"+str2[random2]);
author.addText(str2[random2]);
String j = String.valueOf(i);
price.addText(j);
//[7]格式良好的输出
OutputFormat format = OutputFormat.createPrettyPrint();
String file = "conf2/book"+a+".xml";
XMLWriter writer = new XMLWriter(new FileWriter(new File(file)), format);
writer.write(doc);
//[8]关闭资源
writer.close();
a++;};
}
}
结果:
book11.xml
book15.xml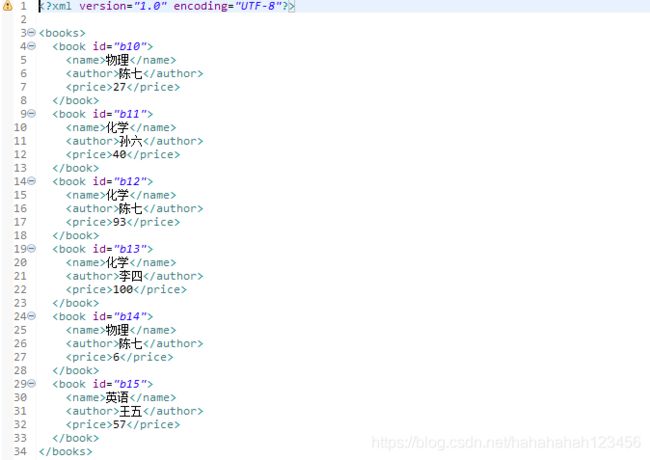
二.遍历本目录下所有的文件
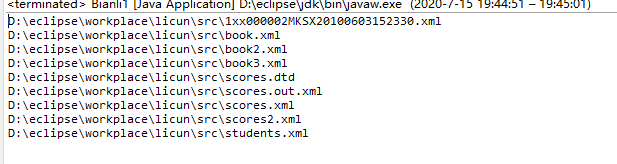
1.不包括目录的目录里的文件
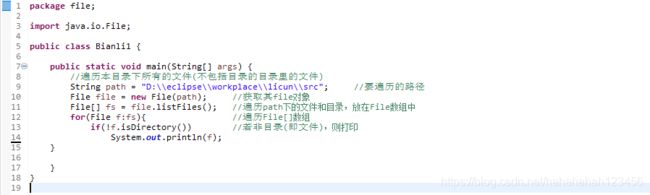
结果:
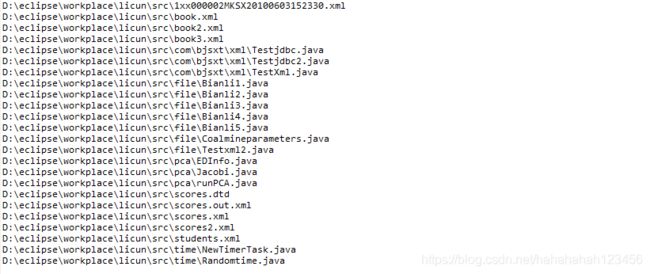
2.包括目录的目录里的文件
结果:
参考:
https://blog.csdn.net/u014453898/article/details/79655338
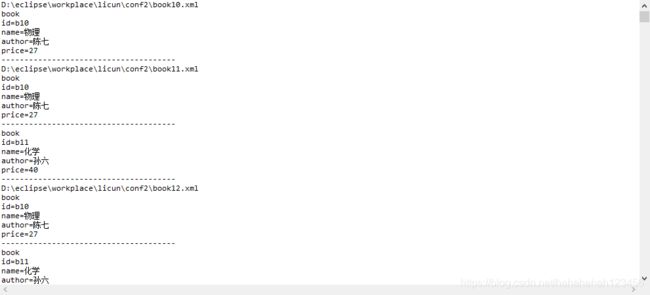
3.解析同一目录下的所有xml文件
(用上面生成的conf2文件加下的xml文件)
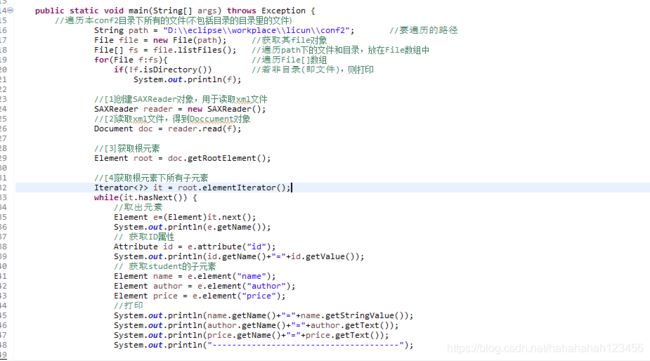
结果:
二. java实现主成分分析
1.主成分分析PCA
(1)定义:高维数据转化为低维数据的过程,可能会舍弃原有数据创造新的变量,数据维数的压缩尽可能多的反应原变量的数据信息。(用几个较少的综合指标来代替原来较多的指标,而这些较少的综合指标既能尽多地反映原来较多指标的有用信息,且相互之间又是无关的。
(2)步骤
对原始d维数据集做标准化处理
构造样本的协方差矩阵
计算协方差矩阵的特征值和相应的特征向量
选择与前k个最大特征值对应的特征向量,其中k维新特征空间的维度(k<=d)
通过前k个特征向量构建映射矩阵W
通过映射矩阵W将d维的输入数据集X转换到新的k维特征子空间
参考:
https://zhuanlan.zhihu.com/p/77151308
2.矩阵运算包Ejml
Ejml全称为Efficient Java Matrix Library,一款高效的矩阵运算java库。 可以实现矩阵的运算,如数组转化为矩阵,矩阵的逆,矩阵的转置,矩阵的乘法,矩阵转为数组等等
下载:
参考:
https://blog.csdn.net/qy20115549/article/details/79957101
3.java实现主成分分析PCA
参考选用基于SVD分解协方差矩阵实现PCA算法来实现由于算法实现过程中需要进行实对称矩阵的特征向量分解,所以先用java实现基于雅克比(Jacobi)方法的特征向量分解。
参考:
https://blog.csdn.net/qy20115549/article/details/79957101
四.python实现主成分分析PCA
1.实现
导入PCA包即可实现
from sklearn.decomposition import PCA
def pca_demo():
"对数据进行pca降维"
data=[[2,8,4,5],[6,3,0,8],[5,4,9,1]] # 4列
# 实例化pca,小数--保留多少信息
transfer=PCA(n_components=0.9)
# 调用fit_transform
data1=transfer.fit_transform(data)
print('保留90%的信息,降维结果为:\n',data1)
# 实例化pca,小数--保留多少信息
transfer=PCA(n_components=3)
# 调用fit_transform
data2=transfer.fit_transform(data)
print('保留3列数据,降维结果为:\n',data2)
pca_demo()
2.结果:
保留90%的信息,降维结果为:
[[ 1.22879107e-15 3.82970843e+00]
[ 5.74456265e+00 -1.91485422e+00]
[-5.74456265e+00 -1.91485422e+00]]
保留3列数据,降维结果为:
[[ 1.22879107e-15 3.82970843e+00 2.65047672e-17]
[ 5.74456265e+00 -1.91485422e+00 2.65047672e-17]
[-5.74456265e+00 -1.91485422e+00 2.65047672e-17]]
五.python解析xml文件
常见的 XML 编程接口有 DOM 和 SAX,这两种接口处理 XML 文件的方式不同,当然使用场合也不同。
Python 有三种方法解析 XML,SAX,DOM,以及 ElementTree。
可以解析XML的Python包:xml.dom、xml.dom.minidom、xml.dom.pulldom、xml.sax、xml.parser.expat、xml.etree.ElementTree
例子-book.xml
<books>
<book id="01">
<bookname>python入门</bookname>
<author>李强</author>
<price>25</price>
</book>
<book id="02">
<bookname>java基础</bookname>
<author>王洋</author>
<price>30</price>
</book>
<book id="03">
<bookname>神雕侠侣</bookname>
<author>金庸</author>
<price>212</price>
</book>
<book id="04">
<bookname>1000题</bookname>
<author>汤家凤</author>
<price>66</price>
</book>
</books>1.SAX (simple API for XML )
Python 标准库包含 SAX 解析器,SAX 用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件。
from xml.sax import parse, ContentHandler #引入继承包ContentHandler
#书的类
class Book:
#定义初始化属性,和xml文件属性相同
def __init__(self,bookname=None,author=None,price=None):
self.bookname=bookname
self.author=author
self.price=price
def __str__(self): #转化为字符串输出
return self.bookname+","+self.author+","+self.price
books=[]#定义一个书的数组,用来存放每次得到的数据
#定义继承ContentHandler的类,可以实现相应的方法
class bkdemo(ContentHandler):
def __init__(self):
#定义全局变量
self.book=None #用来接收book的相应数据
self.tag=None #用来接收characters方法得到的content内容
def startDocument(self): #books对象开始
print("对象开始")
def endDocument(self): #books对象结束
print("对象结束")
def startElement(self, name, attrs): #每一个标签元素的开始,name:标签名称 attrs:标签内部相应属性
if name=='book': #如果标签名是book
self.book=Book() #创建一个Book()对象
def endElement(self, name): #每一个标签元素的结束,name:标签名称 (此时才会得到相应的content)
if name=='bookname':
self.book.bookname=self.tag #对象的标签名=得到相应content的值
if name=='author':
self.book.author=self.tag
if name=='price':
self.book.price=self.tag
if name=='book':
books.append(self.book) #为定义的数组追加得到的相应元素
def characters(self, content):
self.tag=content #写了self的,就可以定义为全局变量
parse("book.xml",bkdemo()) #parse的方法,分别指明xml文件,并调用查找的类方法
for i in books: #对数组books[]循环
print(i)结果:
对象开始
对象结束
python入门,李强,25
java基础,王洋,30
神雕侠侣,金庸,2122.DOM(Document Object Model)
将 XML 数据在内存中解析成一个树,通过对树的操作来操作XML。
#引入parse的包
from xml.dom.minidom import parse
doc=parse("../Test/book.xml") #先把xml文件加载进来
root=doc.documentElement #获取元素的根节点
books=root.getElementsByTagName('book') #找到子节点,得到的是一个数组
for book in books: #把所有的子节点进行遍历
print("===book====")
if book.hasAttribute('id'): #如果有ID属性,则输出
print('书的ID是:%s'% book.getAttribute('id'))
bookname=book.getElementsByTagName("bookname")[0] #根据标签名找到,并且输出第一个元素
print(bookname)
print("书名是:%s"%bookname.childNodes[0].data) #输出标签名的子节点的第一个值,并转为data类型
author=book.getElementsByTagName("author")[0]
print("作者是:%s"%author.childNodes[0].data)
price=book.getElementsByTagName("price")[0]
print("价格是:%s"%price.childNodes[0].data)结果:
===book====
书的ID是:01
书名是:python入门
作者是:李强
价格是:25
===book====
书的ID是:02
书名是:java基础
作者是:王洋
价格是:30
===book====
书的ID是:03
书名是:神雕侠侣
作者是:金庸
价格是:212
===book====
书的ID是:04
书名是:1000题
作者是:汤家凤
价格是:663.ElementTree
就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少。注:因DOM需要将XML数据映射到内存中的树,一是比较慢,二是比较耗内存,而SAX流式读取XML文件,比较快,占用内存少,但需要用户实现回调函数(handler)
from xml.etree import ElementTree #引入ElementTree的包
#书的类
class Book:
#定义初始化属性,和xml文件属性相同
def __init__(self,bookname=None,author=None,price=None):
self.bookname=bookname
self.author=author
self.price=price
def __str__(self): #转化为字符串输出
return self.bookname+","+self.author+","+self.price
roota=ElementTree.parse("book.xml") #parse方法读取xml文件,得到元素树
bk=roota.findall("book") #findall查询所有的book标签
boo=[] #定义一个集合
for aa in bk: #对得到的所有的根元素下的子标签循环输出
book=Book() #定义一个类对象
book.bookname=aa.find("bookname").text #对象的相应标签值=子标签查找到的固定标签名,并以text形式输出
book.author=aa.find("author").text
book.price=aa.find("price").text
boo.append(book) #将得到的属性值追加到定义的集合中
for i in boo: #遍历集合
print(i)python入门,李强,25
java基础,王洋,30
神雕侠侣,金庸,212参考:
https://blog.csdn.net/qq_37174526/article/details/89489212
https://www.cnblogs.com/qianshuixianyu/p/9184213.html
https://www.jb51.net/article/79494.htm
https://www.runoob.com/python/python-xml.html
https://www.jb51.net/article/63780.htm
https://blog.csdn.net/qq_41030861/article/details/82564166?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159480057419724843342572%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=159480057419724843342572&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogtop_click~default-3-82564166.pc_v2_rank_blog_default&utm_term=python%E8%A7%A3%E6%9E%90xml%E6%96%87%E4%BB%B6
六.过程中的知识点总结
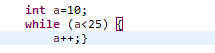
1.循环-while
参考:
https://www.cnblogs.com/langjunnan/p/6856348.html
2.随机数
(1)Random():
创建一个新的随机数生成器。此构造方法将随机数生成器的种子设置为某个值,该值与此构造方法的所有其他调用所用的值完全不同。
Random 的一个特点是:相同种子数的Random对象,对应相同次数生成的随机数字是完全相同的
(2)Math.random():
能够返回带正号的double值,该值大于等于0.0且小于1.0,即取值范围是[0.0,1.0)的左闭右开区间,返回值是一个伪随机选择的数,在该范围内(近似)均匀分布。
在使用Math.Random()的时候,需要注意的地方是该函数是返回double类型的值,所以在要赋值给其他类型的变量的时候注意需要进行塑形转换。
(3)Math.round(float a):返回最接近参数的 int,即四舍五入。
Math.round(double a):返回最接近参数的 long。
Math.ceil(double a):返回最小的(最接近负无穷大) double 值,该值大于等于参数,并等于某个整数,即向上取整。
例如:
System.out.println(ran.nextInt(10));~~5
System.out.print(ran2.nextInt(10));~~5
System.out.println(Math.round(1.5)); ~~2
System.out.println(Math.round(-1.5)); ~~-1
System.out.println(Math.round(0.5)); ~~1
System.out.println(Math.round(-0.5));~~0
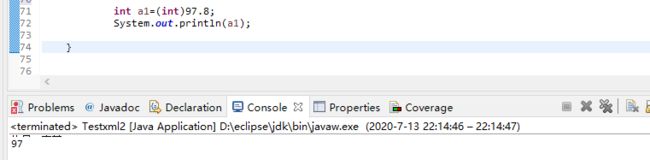
int a =(int)Math.round((Math.random()*(98-1))+1);Math.random生成bai0-1的浮点数du,乘以97即为0-97的浮点zhi数,最外层+1,则变成1-98的浮点数。最后外层的(int)将浮点数转换为整数,因为int是取下限的,即97.8会被转成97
参考:
https://blog.csdn.net/u011433753/article/details/79777075
https://zhidao.baidu.com/question/410496328.html
3.随机字符串
参考:
https://blog.csdn.net/qq_40990854/article/details/82657767
4.几个字符串内随机选取

参考:
https://zhidao.baidu.com/question/1795848614240841947.html
5.整型与字符型相互转换
int i4=(int)(Math.round(Math.random()*0.01));
String co = String.valueOf(i4);参考:
https://blog.csdn.net/eacxzm/article/details/80064752?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
eDateFormat(“yyyyMMddhhmmss”);
///获得当前系统时间 年-月-日 时:分:秒,根据文件命名规则定义相应格式
String time=si.format(new Date());
//将时间拼接在文件名上即可
String file = “conf3/data”+time+".xml";
XMLWriter writer = new XMLWriter(new FileWriter(new File(file)), format);
writer.write(doc);
参考:
https://zhidao.baidu.com/question/2011480315657924548.html
https://blog.csdn.net/woainiqazwsx123/article/details/80343689
6.python解析xml文件中遇到的错误及解决办法
(1)xml.parsers.expat.ExpatError: XML or text declaration not at start of entity: line 2, column 0
问题是:XML或文本声明不在实体的开头即 xml文件要以一下作为开始,不能有空格或者回车等的符号。在文件的最前端 即前面不能有空格。
解决办法:删除xml文件声明前的空格
参考:
https://blog.csdn.net/alan_java88/article/details/54891331