安装Tomcat并捕获浏览器请求信息和Tomcat返回内容
JSP(Java Server Page)是基于Java Servlet(Java的一个类,为Web应用程序提供了基于组件、独立于平台的方法)的Web开发技术。
静态网页和动态网页
它们的区别在于程序是否在服务器端运行,如果回答是,那么就是动态网页。如果网站内容对更新需求不是很大,使用静态的就可以了。
静态网页用HTML编写;动态网页一般用HTML+ASP/PHP/JSP(3P技术):
C/S和B/S架构
C/S是传统的客户端/服务器架构,性能很好,客户端部分需要承受一定的压力。
B/S架构是浏览器/服务器架构,极少数事务逻辑在前端实现,比如最近流行的Web App。
安装Tomcat
就像我们平时的应用程序需要有操作系统支持才能在机器上跑一样,服务器(这里指的是计算机)上的应用程序也要在应用服务器(这里指的就是像Tomcat这样的东西)上跑。安装配置好Tomcat的计算机就可以称为Web服务器了,访问的互联网上的网页都是发布在Web服务器上的。
到Tomcat官网去下载,因为是开源的,更新非常快。
解压之后就可以使用了,不需要安装。在解压好的目录下的bin目录下有一个startup.bat文件,bat文件是微软下的批处理文件(就像Linux下的sh文件)。
需要确保电脑中有JAVA_HOME这样的环境变量,指向正在使用的JDK的目录,才能正确执行这个startup.bat,双击打开:
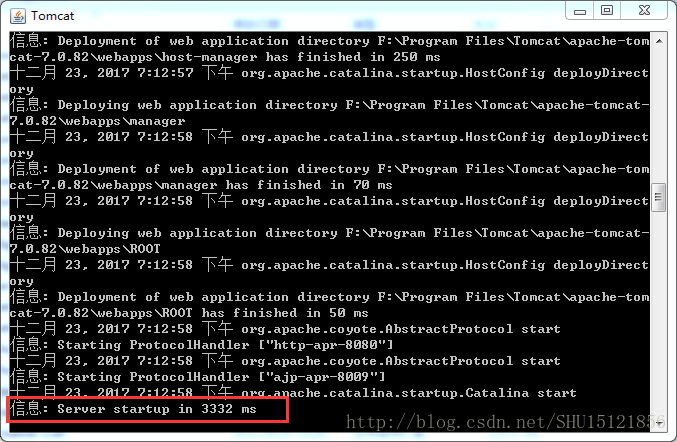
这就说明Tomcat已经正确运行了,不要关闭这个窗体(不然就不再运行了),在浏览器里输入本机环回地址http://127.0.0.1:8080测试一下(Tomcat默认的实验端口是8080,也就是在8080端口监听着):
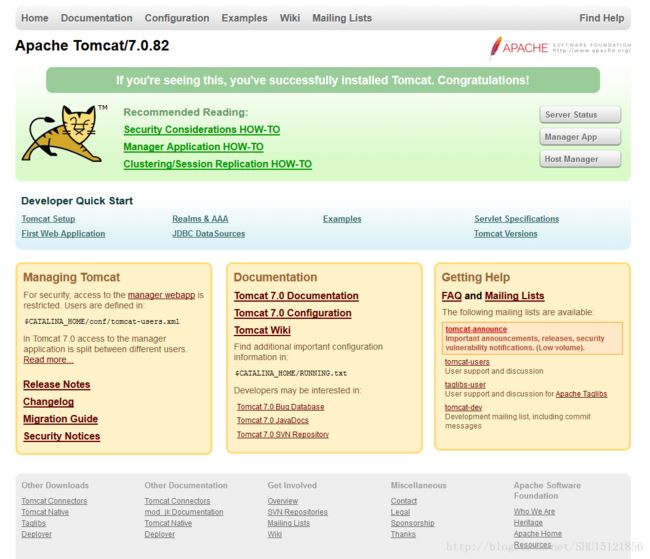
这说明Tomcat是正常工作的,这个网页是Tomcat提供的默认网页。如果要访问自己写好的其它的网页,Tomcat会到自己所管理的目录(即webapps下去寻找):
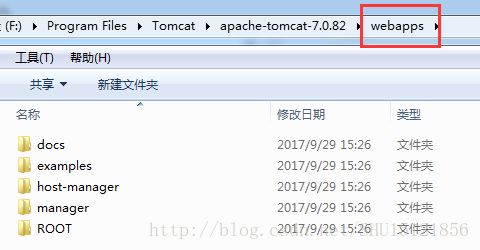
也就是说服务器部署的网页都要按规定放在这个目录之下,其中ROOT里就是刚才那个Tomcat的默认网页:

在这个ROOT目录中新建一个HTML文件测试一下(前面学了用记事本写Java要保存为ANSI编码,写HTML要保存为UTF-8):
在浏览器地址栏输入http://127.0.0.1:8080/lzh.html:

按照书上说的,整个过程是这样:

伪装成Tomcat以观察浏览器发来的请求信息
王洋老师的书上写的这部分十分有趣!关闭真的Tomcat,写一个监听8080端口并打印取得到的内容的程序:
package test;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
public class Main {
public static void main(String[] args) {
try {
//服务器端Socket对象监听8080端口
ServerSocket ss=new ServerSocket(8080);
System.out.println("程序开始了");
Socket s=ss.accept();//等到请求后accept()方法返回socket对象
InputStream is=s.getInputStream();//字节输入流
InputStreamReader isr=new InputStreamReader(is);//包装为字符流
BufferedReader br=new BufferedReader(isr);//为字符流添加缓冲
//一行一行读出来输出
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
} catch (Exception e) {
//生吞异常
}
}
}刚运行,进程会阻塞在这个accept()方法,这时候在浏览器里尝试访问http://127.0.0.1:8080/lzh.html,输出了:
| 输出的每行内容 | 对其的解释 |
|---|---|
| 程序开始了 | |
| GET /lzh.html HTTP/1.1 | 请求lzh.html这个页面,HTTP协议的1.1版本 |
| Host: 127.0.0.1:8080 | 告诉Tomcat当时访问的主机地址和端口号 |
| User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0 | 告诉Tomcat浏览器是什么,操作系统是什么,以及其它框架信息 |
| Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 | 告诉Tomcat这个浏览器能接收的信息类型 |
| Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 | 告诉Tomcat客户机的操作系统语言 |
| Accept-Encoding: gzip, deflate | 告诉Tomcat浏览器能打开的压缩文件格式 |
| Connection: keep-alive | 说明了浏览器和Tomcat之间的连接模式 |
| Upgrade-Insecure-Requests: 1 | |
| If-Modified-Since: Sat, 23 Dec 2017 11:58:12 GMT | 时间戳的时间信息 |
| If-None-Match: W/”254-1514030292223” | 时间戳的唯一编码 |
最后两个信息是在描述Tomcat生成的时间戳,因为浏览器的访问方式是面向不稳定连接的,在浏览器不需要的时候连接可以断开,再次访问(重新建立连接)时就要利用这个时间戳和其它访问区分开。
第一次访问服务器时是没有时间戳信息的,但是之前我已经试过访问这个网页了,所以浏览器保存了时间戳!
伪装成浏览器发送信息以观察真的Tomcat回复的信息
把上个程序得到的信息记录下来,写一个像浏览器刚刚访问环回地址一样,向8080端口发送那些请求信息的程序:
package test;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.net.Socket;
public class Main {
public static void main(String[] args) {
try {
//套接字
Socket s=new Socket("127.0.0.1",8080);
OutputStream os=s.getOutputStream();//字节输出流
OutputStreamWriter osw=new OutputStreamWriter(os);//包装为字节数出打印流
PrintWriter pw=new PrintWriter(osw,true);//包装为打印流
//向刚刚那个套接字发送信息给Tomcat(相当于伪装成浏览器去请求访问那个地址)
pw.println("GET /lzh.html HTTP/1.1");
pw.println("Host: 127.0.0.1:8080");
pw.println("User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) ");
// pw.println("Gecko/20100101 Firefox/57.0");
pw.println("Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
pw.println("Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
pw.println("Accept-Encoding: gzip, deflate");
pw.println("Connection: keep-alive");
// pw.println("Upgrade-Insecure-Requests: 1");
// pw.println("If-Modified-Since: Sat, 23 Dec 2017 11:58:12 GMT");
// pw.println("If-None-Match: W/\"254-1514030292223\"");
pw.println("");//传出的信息需要一个空行结束才能得到Tomcat的确认
//接收Tomcat传回来的信息
InputStream is=s.getInputStream();//字节输入流
InputStreamReader isr=new InputStreamReader(is);//包装为字符流
BufferedReader br=new BufferedReader(isr);//为字符流添加缓冲
//一行一行读出来输出
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
System.out.println(br.readLine());
} catch (Exception e) {
//生吞异常
}
}
}先打开真的Tomcat,然后运行这个程序,相当于伪装浏览器去请求访问lzh.html这个页面,输出了:
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Accept-Ranges: bytes
ETag: W/"254-1514030292223"
Last-Modified: Sat, 23 Dec 2017 11:58:12 GMT
Content-Type: text/html
Content-Length: 254
Date: Sat, 23 Dec 2017 13:25:09 GMT
锘?
<html lang="zh-cn">
<head>
<title>鎴戞槸鍌婚??title>最后面显然是这个网页的HTML文件内容,因为只拿了几行所以不全,而且打印出来的编码有些问题。如果是真的浏览器(而不是这样伪装的),肯定就可以解析这棵DOM树然后显示出网页来了。
对前面的信息头作一些解释:
| 输出的每行内容 | 对其的解释 |
|---|---|
| HTTP/1.1 200 OK | Tomcat告诉浏览器使用HTTP协议的1.1版本,200(而不是404等)表示正常 |
| Server: Apache-Coyote/1.1 | 告诉浏览器服务器软件是什么,Tomcat是Apache的产品 |
| Accept-Ranges: bytes | bytes表示服务器支持断点续传 |
| ETag: W/”254-1514030292223” | Tomcat为其生成的时间戳唯一编码 |
| Last-Modified: Sat, 23 Dec 2017 11:58:12 GMT | 时间戳时间信息 |
| Content-Type: text/html | Tomcat告诉浏览器,本次传送的内容是基于文本文件的html格式 |
| Content-Length: 254 | Tomcat告诉浏览器,内容的长度是254字节 |
| Date: Sat, 23 Dec 2017 13:25:09 GMT | 时间信息 |
| (网页的具体内容) | 网页的具体内容 |