机器学习《文本特征提取》
以下内容均在jupyter lab中运行
本次任务
将文本特征提取转换成模型能用的数据
import pandas as pd
本次数据来自json文件
df = pd.read_json(‘wuxia.car.json’,encoding=‘utf-8’)
这是取出的数据
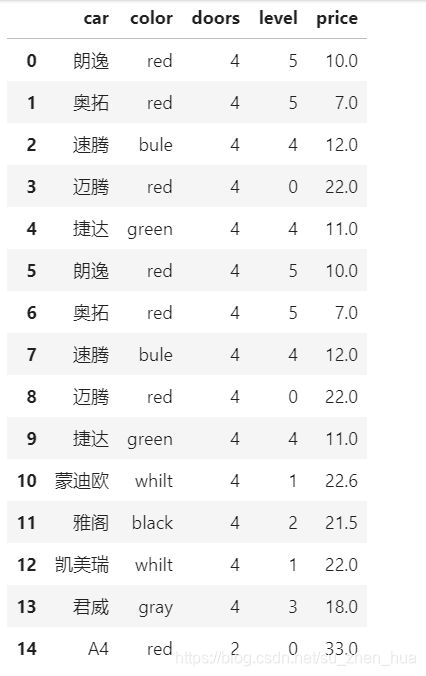
将数据转换成list类型
data = df.iloc[:,:].values.tolist()
listall=[]
for i in data:
dict={}
dict[‘name’]=i[0]
dict[‘color’]=i[1]
dict[‘doors’]=i[2]
dict[‘level’]=i[3]
dict[‘price’]=i[4]
listall.append(dict)

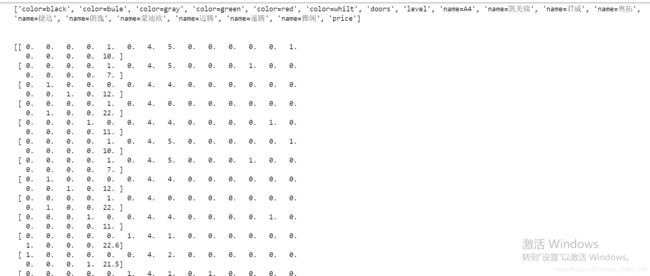
DictVectorizer 处理数据类型是dict
from sklearn.feature_extraction import DictVectorizer
data = dv.fit_transform(listall)
查看处理后的特征对应的列
print(dv.get_feature_names())
打印编码结果 toarray把结果转换为numpy类型
print(data.toarray())
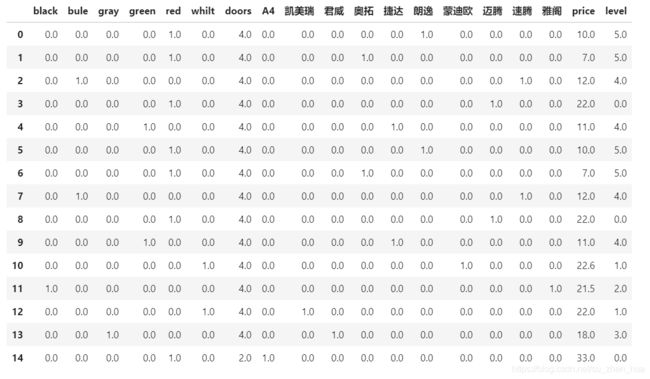
#给编码转成pandas二维数组 columns给列起别名 转成pandas方便存csv
df2 = pd.DataFrame(data.toarray(),
columns=[‘black’,‘bule’,‘gray’,‘green’,‘red’,‘whilt’,‘doors’,‘level’,‘A4’,
‘凯美瑞’,‘君威’,‘奥拓’,‘捷达’,‘朗逸’,‘蒙迪欧’,‘迈腾’,‘速腾’,‘雅阁’,‘price’]
)
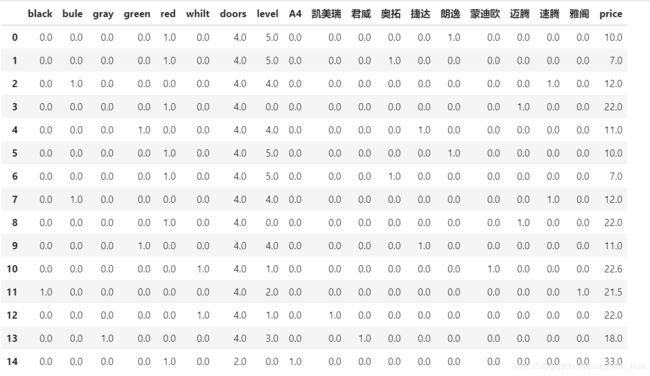
将level作为标签放在最后一列
data=df2.level #取出要换位置的列名
df2=df2.drop(‘level’,axis=1) # 删除要换的列名
df2.insert(18,‘level’,data) # 将取出的重新添加进去 18代表第18列
存csv
df2.to_csv(‘cars.csv’,encoding=‘utf-8’)
读csv
datas = pd.read_csv(‘cars.csv’,encoding=‘utf-8’)
datas.drop(‘Unnamed: 0’,axis=1,inplace=True)
取出数据如下