基于华为FusionInsight的Flume日志采集分析报告
Flume日志采集分析报告
- 1.日志采集系统简介
- 2.系统架构
- 2.1.日志采集系统的整体框架图
- 2.2.日志采集系统的模块分解图
- 3.架构分析
- 3.1.可用性(availablity)
- 3.1.1.Agent层宕机
- 3.1.2.Store层宕机
- 3.2.可靠性(reliability)
- 3.3.可扩展性(scalability)
- 3.3.1.Agent层
- 3.3.2.Store层
- 4.架构测试
- 4.1.测试目的
- 4.2.测试环境
- 4.2.1.基础环境准备
- 4.2.2.flume环境准备
- 4.2.3.Kafka环境准备
- 4.2.3.1.准备topic
- 4.2.3.2.准备kerberos认证
- 4.3.测试项目
- 4.3.1.架构连通性
- 4.3.1.1.基本思路
- 4.3.1.2.实现流程
- 4.3.1.3.测试步骤
- 4.3.1.3.1.配置客户端(client):
- 4.3.1.3.2. 重启Flume客户端,使配置文件生效
- 4.3.1.3.3.构造数据
- 4.3.1.3.4.查看kafka运行结果
- 4.3.2.断点续传
- 4.3.3.数据过滤
- 4.3.4.性能测试
- 4.3.4.1.Kafka参数影响
- 4.3.4.2.Channel的对比
- 5.总结
1.日志采集系统简介
集团各业务平台每天都会产生大量的日志数据。收集业务日志数据,供离线和在线的分析系统使用,正是日志收集系统的要做的事情。高可用性,高可靠性和可扩展性是日志收集系统所具有的基本特征。
本文主要介绍通过Flume实现日志收集系统。Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,可以采集文件,socket数据包、文件、文件夹、kafka等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中。
2.系统架构
2.1.日志采集系统的整体框架图
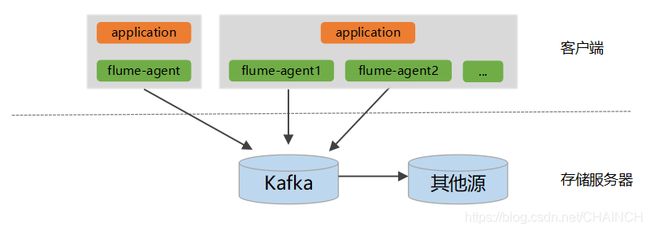
1、整个系统分为两层:Agent层,和Store层。其中Agent层每个机器部署一个进程,负责对单机的日志收集工作;Store层负责提供永久或者临时的日志存储服务,或者将日志流导向其它服务器。
2、Agent层,一台机器可以部署一个或多个agent节点,每个agent节点使用TailFileSource–>KafkaChannel这种方式,将KafkaChannel作为缓冲,效率变高,而且数据不会丢失。这种方法不需要Sink,KafkaChannel相当于Kafka的生产者,这样就充分利用了Kafka集群的优点,当数据量很大的时候,也能承受得住。
3、Store层,使用Kafka存储临时的日志,并给Spark Streaming/Flink系统提供实时日志流,需要永久存储时,可存入hdfs等其他数据源。
2.2.日志采集系统的模块分解图

1、模块命名规则:所有的Source以src开头,所有的Channel以ch开头,所有的Sink以sink开头;
2、Source使用taildir Source,实时保存读取位置至磁盘;Channel使用的KafkaChannel;对于过滤掉的日志使用flume的拦截器(interceptor);
3.架构分析
3.1.可用性(availablity)
对日志收集系统来说,可用性(availablity)指固定周期内系统无故障运行总时间。要想提高系统的可用性,就需要消除系统的单点,提高系统的冗余度。下面来看看日志收集系统在可用性方面的考虑。
3.1.1.Agent层宕机
Agent宕机分为两种情况:机器死机或者Agent进程中断。对于机器死机,由于产生日志的进程也同样会中断,所以不会再产生新的日志,不存在不提供服务的情况。
对于Agent进程中断,我们有下面三种方式来提高系统的可用性。首先,所有的Agent在supervise的方式下启动,如果进程中断会被系统立即重启,以提供服务。其次,对所有的Agent进行存活监控,发现Agent中断立即报警。最后,对于非常重要的日志,读取时,实时保存读取位置,如使用taildirSource。
3.1.2.Store层宕机
假如store层的kafka异常停机或不可访问,此时Agent层无法写kafka。由于flume内部source到channel端提供事务机制,Agent采集到数据,发送至kafka channel失败,会导致事务回滚,重新发送,直到kafka恢复服务,成功保存,这可以提供较好的容错性。
3.2.可靠性(reliability)
对日志收集系统来说,可靠性(reliability)是指Flume在数据流的传输过程中,保证events的可靠传递。
Flume提供了数据流中点到点的可靠性保证的最基本的单跳消息传递语义。
首先,Agent间的事务交换。Flume使用事务的办法来保证event的可靠传递。Source和Sink分别被封装在事务中,这些事务由保存 event的存储提供或者由Channel提供。这就保证了event在数据流的点对点传输中是可靠的。在多级数据流中,如下图,上一级的Sink和下一级的Source都被包含在事务中,保证数据可靠地从一个Channel到另一个Channel转移。
其次,数据流中 Channel的持久性。Flume中MemoryChannel是可能丢失数据的(当Agent宕机时),但KafkaChannel和FileChannel是持久性的,可以保证数据不丢失。

3.3.可扩展性(scalability)
对日志收集系统来说,可扩展性(scalability)是指系统能够线性扩展。当日志量增大时,系统能够以简单的增加机器来达到线性扩容的目的。
对基于Flume的日志收集系统来说,需要在设计的每一层,都可以做到线性扩展地提供服务。下面将对每一层的可扩展性做相应的说明。
3.3.1.Agent层
对于Agent这一层来说,一个方面,Agent收集日志的能力受限于机器的性能,每个机器部署一个或多个Agent,机器性能允许情况下,可以不断扩展;另一方面,如果机器和Agent节点比较多,可能受限于后端kafka提供的服务。
3.3.2.Store层
对于Store这一层来说,Kafka是分布式系统,可以做到线性扩展。
4.架构测试
4.1.测试目的
基于架构分析,使用测试环境对架构的可用性、可靠性、可扩展性等进行全面测试,以验证我们的架构分析是否正确,以及找出在实际环境中可能还存在的问题。
4.2.测试环境
4.2.1.基础环境准备
集群管理界面(Fusioninsight Manager):https://192.168.1.201:28443/web/
测试用户:tpdata/!QAZ2wsx
版本:Flume 1.9,Kafka1.1.0,JDK 1.8
服务器IP:
| 项目 | 地址 |
|---|---|
| 客户端(flume) | 192.168.1.180 |
| 存储服务器(kafka) | 192.168.1.177,192.168.1.178,192.168.1.179 |
| 其他(zookeeper) | 192.168.1.177,192.168.1.178,192.168.1.179 |
4.2.2.flume环境准备
flume客户端的安装
1、从fusionInsight manager管理界面下载客户端,下载位置是“集群>服务>flume> 更多>下载客户端”
2、把下载到的客户端上传到要安装的机器上,如果机器上没有jdk,需要先安装jdk,安装jdk步骤:上传jdk到对应服务器,然后解压jdk
tar -xvf jdk包
配置环境:
vi /etc/profile
添加以下内容
export JAVA_HOME=/tpdata/jdk-8u201(jdk安装目录)
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
完成之后输入Java -version 显示Java版本说明安装成功

3、解压上传的客户端jar包,进入目录
cd /tpdata/client/FusionInsight_Cluster_1_Flume_ClientConfig/Flume/FlumeClient
执行以下命令:
./install.sh -d /tpdata/FlumeClient -f 192.168.1.177,192.168.1.178 -l /var/log/Bigdata -e 192.168.1.180 -n test1
4、安装成功后的进程信息:
1)查看flume的进程id
ps -ef | grep flume
 2)中断flume的client进程,之后flume会自动重启,一般使用这种方式使properties.properties配置文件立刻生效,如:
2)中断flume的client进程,之后flume会自动重启,一般使用这种方式使properties.properties配置文件立刻生效,如:
kill -9 flume的client端口id
5、客户端的卸载
/tpdata/FlumeClient/fusioninsight-flume-1.9.0/inst
./uninstall.sh
4.2.3.Kafka环境准备
4.2.3.1.准备topic
登录192.168.1.177服务器,执行第1步命令创建topic:
1、创建测试topic—flume_test,指定分配5个分区,3个副本;
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-topics.sh --create --topic flume_test --partitions 5 --replication-factor 3 --zookeeper 192.168.1.177:24002,192.168.1.178:24002,192.168.1.179:24002/kafka
2、查看topic列表
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.1.177:24002/kafka
3、查看topic信息,如分区数等
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-topics.sh --topic flume_test --describe --zookeeper 192.168.1.177:24002/kafka
4、命令端向flume_test生产消息
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-console-producer.sh --broker-list 192.168.1.180:21007,192.168.1.181:21007,192.168.1.182:21007 --topic flume_test --producer.config /tpdata/hadoopclient/Kafka/kafka/config/producer.properties
5、消费flume_test消息
1)从上次消费位置消费:
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.180:21007,192.168.1.181:21007,192.168.1.182:21007 --topic flume_test --consumer.config /tpdata/hadoopclient/Kafka/kafka/config/consumer.properties
2)从头开始消费:
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.180:21007,192.168.1.181:21007,192.168.1.182:21007 --topic flume_test --new-consumer --from-beginning --consumer.config /tpdata/hadoopclient/Kafka/kafka/config/consumer.properties
6、查看指定消费者组的topic消费位置(offset偏移量)
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 192.168.1.180:21007 --describe --group example-group1 --command-config /tpdata/hadoopclient/Kafka/kafka/config/consumer.properties
7、删除topic
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-topics.sh --delete --zookeeper 192.168.1.177:24002,192.168.1.178:24002,192.168.1.179:24002/kafka --topic flume_test
4.2.3.2.准备kerberos认证
1、在flume的conf目录新增jaas.conf文件,内容如下:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/tpdata/user.keytab"
principal="[email protected]"
useTicketCache=false
storeKey=true
debug=true;
};
注意:keyTab和principal的值请按照实际情况配置,所配置的principal需要有相应的kafka的权限。
4.3.测试项目
4.3.1.架构连通性
4.3.1.1.基本思路
客户端:监控采集目录下“a”开头,“.log”结尾的文件,agent使用taildirSource,KafkaChannel,无sink的方式,并使用拦截器剔除“字母开头的记录”,将数据发送至kafka指定topic—flume_test;
存储服务器:查看收集情况;
4.3.1.2.实现流程

4.3.1.3.测试步骤
4.3.1.3.1.配置客户端(client):
1)登录192.168.1.180服务器,进入Flume客户端的conf目录:
cd /tpdata/FlumeClient/fusioninsight-flume-1.9.0/conf
2)修改properties.properties文件
client.sources = src_taildir
client.channels = ch_kafka
client.sinks =
client.sources.src_taildir.type = TAILDIR
client.sources.src_taildir.filegroups = f1
client.sources.src_taildir.filegroups.f1 = /tpdata/flume/a.*.log
client.sources.src_taildir.headers.f1. =
client.sources.src_taildir.positionFile = /tpdata/flume/taildir_position.json
client.sources.src_taildir.montime =
client.sources.src_taildir.byteOffsetHeader = false
client.sources.src_taildir.skipToEnd = false
client.sources.src_taildir.idleTimeout = 12000
client.sources.src_taildir.writePosInterval = 3000
client.sources.src_taildir.batchSize = 10000
client.sources.src_taildir.fileHeader = false
client.sources.src_taildir.fileHeaderKey = file
client.sources.src_taildir.channels = ch_kafka
#二、 set interceptor(可配置多个,也可省略)
# 例:设置正则过滤拦截器
client.sources.src_taildir.interceptors = i1
client.sources.src_taildir.interceptors.i1.type = REGEX_FILTER
# 剔除内容中以英文字母开头的记录
client.sources.src_taildir.interceptors.i1.regex = ^[a-z]|[A-Z].*
# 是否剔除符合规则数据
client.sources.src_taildir.interceptors.i1.excludeEvents = true
# 其他拦截器,参见 https://www.jianshu.com/p/1c60e0df744b
client.channels.ch_kafka.type = org.apache.flume.channel.kafka.KafkaChannel
client.channels.ch_kafka.kafka.bootstrap.servers = 192.168.1.180:21007,192.168.1.181:21007,192.168.1.182:21007
client.channels.ch_kafka.kafka.topic = flume_test
client.channels.ch_kafka.kafka.consumer.group.id = flume-group1
client.channels.ch_kafka.parseAsFlumeEvent = true
client.channels.ch_kafka.migrateZookeeperOffsets = true
client.channels.ch_kafka.kafka.consumer.auto.offset.reset = earliest
client.channels.ch_kafka.kafka.producer.security.protocol = SASL_PLAINTEXT
client.channels.ch_kafka.kafka.consumer.security.protocol = SASL_PLAINTEXT
client.channels.ch_kafka.ignoreLongMessage = false
client.channels.ch_kafka.messageMaxLength = 1000012
4.3.1.3.2. 重启Flume客户端,使配置文件生效
1)查看flume的进程id
ps -ef | grep flume
2)中断flume的client进程,之后flume会自动重启
kill -9 flume的client端口id
3)查看flume的客户端进程情况,以确认配置是否正确
ps -ef | grep flume
4.3.1.3.3.构造数据
1)进入配置的文件采集目录
cd /tpdata/
2)运行构造数据的sh脚本
sh createdata_a.sh
其中,以createdata_a.sh为例:
#!/bin/bash
i=100000000
count=1
while [ $count -le 10000000 ]
do
echo $i $i $i $i $i>> /tpdata/flume/a2019.log
let i++
let count++
done
echo "flag" >> /tpdata/flume/a2019.log
构造的数据格式如下,总共1000万条,末尾另加一条“flag”,用于测试拦截器:

3)将数据放入监控目录
cp a2019.log ./flume/
4.3.1.3.4.查看kafka运行结果
1)登录177服务器,新建flume_consumer.properties,配置flume-group1消费者组:
security.protocol = SASL_PLAINTEXT
kerberos.domain.name = hadoop.hadoop.com
group.id = flume-group1
auto.commit.interval.ms = 60000
sasl.kerberos.service.name = kafka
2)使用flume-group1消费者组进行部分消费:
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.180:21007,192.168.1.181:21007,192.168.1.182:21007 --topic flume_test --consumer.config /tpdata/hadoopclient/Kafka/kafka/config/flume_consumer.properties
3)执行以下命令查看消费者组(flume-group1)消费topic(flume_test)的详细信息:
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 192.168.1.180:21007 --describe --group flume-group1 --command-config /tpdata/hadoopclient/Kafka/kafka/config/flume_consumer.properties

注:
PARTITION:topic(flume_test)下面的分区编号;
CURRENT-OFFSET:flume-group1消费者组对每个分区的消费位置;
LOG-END-OFFSET:topic(flume_test)每个分区总的记录数
LAG:flume-group1消费者组对每个分区的剩余多少未消费;
3、计算结果,以LOG-END-OFFSET加总,得1000万条记录,结果正常:
| TOPIC | PARTITION | LOG-END-OFFSET |
|---|---|---|
| flume_test | 1 | 2000000 |
| flume_test | 1 | 2000000 |
| flume_test | 2 | 2000000 |
| flume_test | 3 | 2000000 |
| flume_test | 4 | 2000000 |
| flume_test | 0 | 2000000 |
| flume_test | 合计 | 10000000 |
4.3.2.断点续传
1、初始化
初始化4.4.1架构连通性的测试,删除原始的a2019.log,删除并重新创建kafka topic的flume_test,并重启客户端和中心服务器的flume节点,构造数据,步骤参考4.4.1.3.1-4.4.1.3.3;
2、模拟客户端层宕机
1)关闭180节点的客户端
/tpdata/FlumeClient/fusioninsight-flume-1.9.0/bin/flume-manage.sh stop force

2)查看文件采集位置。
由于source采用的taildir,会实时记录采集位置信息,通过查看taildir_position.json可知,180节点宕机后,a2019.log文件偏移位置(pos)没有继续变化。
cd /tpdata/flume
cat taildir_position.json

a2019.log实际为1000000005字节,实际采集至170000000,表明未完成采集:
![]()
3、重启宕机的180节点客户端
/tpdata/FlumeClient/fusioninsight-flume-1.9.0/bin/flume-manage.sh start force
ps -ef | grep flume
![]()
4、重启后结果
1)taildir的文件采集位置记录正常:
cd /tpdata/flume
ll
cat taildir_position.json

4)kafka——客户端层宕机,数据不会丢失,但会重复
登录177服务器,使用flume-group1消费者组进行部分消费:
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.180:21007,192.168.1.181:21007,192.168.1.182:21007 --topic flume_test --consumer.config /tpdata/hadoopclient/Kafka/kafka/config/flume_consumer.properties
执行以下命令查看消费者组(flume-group1)消费topic(flume_test)的详细信息:
/tpdata/hadoopclient/Kafka/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 192.168.1.180:21007 --describe --group flume-group1 --command-config /tpdata/hadoopclient/Kafka/kafka/config/flume_consumer.properties
采集a2019.log,总共1000万条,最终结果总共10010000条,重复采集10000条,注意,经多次测试,重复采集的量可能为多个批次,也可能未发生重复。

注:数据重复的原因:文件采集时,TailDir的pos位置(taildir_position.json)其实是从内存中读取的,只要操作中间flume进程不挂,就没问题。但进程挂了再重启,只能从磁盘文件taildir_position.json中读取pos,由于内存中的pos位置可能未及时同步到磁盘,导致数据重复。
4.3.3.数据过滤
通过Flume的正则过滤拦截器进行了数据过滤,日志构造了一条字母开头的记录,通过正则过滤拦截器(见客户端配置,regex=1|[A-Z].*),实现了过滤操作。a2019.log总共10000001条数据,剔除最后一条“flag”记录,最终结果为1000万条数据。

4.3.4.性能测试
4.3.4.1.Kafka参数影响
1、kafka的topic分区数:
由下表可知,kafka的topic分区数在30个左右,采集速度为15.9Mb/s,相比分区数为10或者50都更快,表明kafka的topic分区存在一个最优点,并非越多越好。
| channe | Source | Sink | 采集文件大小 | Batchsize | partition | acks | 采集总量(行) | 总耗时(s) | 采集速度(mb/s) | 采集速度(行/s) |
|---|---|---|---|---|---|---|---|---|---|---|
| kafkaChannel | TailDir | Kafka | 953.68 | 10000 | 10 | -1 | 10000000 | 65 | 14.7 | 153846 |
| kafkaChannel | TailDir | Kafka | 953.68 | 10000 | 30 | -1 | 10000000 | 60 | 15.9 | 166667 |
| kafkaChannel | TailDir | Kafka | 953.68 | 10000 | 50 | -1 | 10000000 | 63 | 15.1 | 158730 |
2、flumeBatchSize,批次写入Kafka的Event个数
由下表可知,kafka的flumeBatchSize在10万左右,采集速度为29.8Mb/s,相比flumeBatchSize为1万或者100万都更快,表明kafka的flumeBatchSize存在一个最优点,并非越多越好。此外,flume的客户端宕机重启,可能导致一个批次的数据重复,批次越大,数据重复量越多。
| channe | Source | Sink | 采集文件大小 | Batchsize | partition | acks | 采集总量(行) | 总耗时(s) | 采集速度(mb/s) | 采集速度(行/s) |
|---|---|---|---|---|---|---|---|---|---|---|
| kafkaChannel | TailDir | Kafka | 953.68 | 10000 | 30 | -1 | 10000000 | 60 | 15.9 | 166667 |
| kafkaChannel | TailDir | Kafka | 953.68 | 100000 | 30 | -1 | 10000000 | 32 | 29.8 | 312500 |
| kafkaChannel | TailDir | Kafka | 953.68 | 1000000 | 30 | -1 | 10000000 | 37 | 25.8 | 270270 |
4.3.4.2.Channel的对比
由下表可知,memoryChannel速度最快,为30.8Mb/s,但是根据4.3.4.1结果,将kafka的参数调整到最优,如partition设置为30,Batchsize设为10万,kafkaChannel速度为29.8Mb/s,速度可以与memoryChannel媲美,同时还能更好地保证数据不丢失。
| channe | Source | Sink | 采集文件大小 | Batchsize | partition | acks | 采集总量(行) | 总耗时(s) | 采集速度(mb/s) | 采集速度(行/s) |
|---|---|---|---|---|---|---|---|---|---|---|
| File Channel | TailDir | Kafka | 953.68 | 100000 | 30 | -1 | 10000000 | 406 | 2.3 | 24631 |
| memoryChannel | TailDir | Kafka | 953.68 | 100000 | 30 | -1 | 10000000 | 31 | 30.8 | 322581 |
| kafkaChannel | TailDir | Kafka | 953.68 | 100000 | 30 | -1 | 10000000 | 32 | 29.8 | 312500 |
注:以上测试其他条件如下
1、测试采用一个agent节点采集本地文件发送至kafka集群;
2、Topic的副本数为2;
3、所用机器为192.168.1.180服务器。
5.总结
经过上述架构分析及架构测试结果,可以得出以下结论:
1、使用Kafka Channel采集日志到kafka性能相对较高,kafka参数对采集速度影响较大,需要选择合适的partition和batchsize等。
2、flume通过tailDir Source和Kafka Channel可以实现日志采集的断点续传,保证采集数据不丢失。
但也存在以下缺点:
①flume可以保证数据不丢失,但可能会导致数据重复,如4.4.2断点续传的测试。
数据重复的原因:客户端突然宕机,tailDir采集的pos位置信息可能未能及时同步至磁盘,客户端重启后,会重新从磁盘中读取pos位置,导致数据重复。
数据重复的解决需要根据实际业务场景,制定相应的举措,如监控预警、按主键去重等。
②客户端宕机,如果无法修复重启,也会导致数据丢失。
a-z ↩︎