机器学习数据预处理3:结点向量 (node2vec)
论文题目:node2vec: Scalable Feature Learning for Networks
论文arXiv地址
作者提供的博客地址
源代码GitHub地址
--------------------------------------------------
1. 背景
(1) 如何对图建模?
深度学习在 图像(CV,CG,DIP) 和 自然语言处理 (NLP) 等领域有很好的应用。然而在涉及到图(有向图,无向图)结构的应用 比如社交网络,如何去对图建模,仍旧是一个问题。
(2) 现有方法?
第一阶段:one-hot 编码
具体介绍参见博客: 机器学习数据预处理1:独热编码(One-Hot)
第二阶段:word2vec
概念:
word2vec 算法是实现 单词的向量表示 的算法。word2vec 主要 有 Skip-Gram 和 CBOW 两种模型 :
a) CBOW是给定上下文,来预测 input word。
b) Skip-Gram 是给定 input word 来预测上下文。
其中,Skip-Gram 算法的思想是建立一个神经网络:
训练:
输入:由单词组成的句子 (训练集)。
输出: 得到神经网络中的一些参数,根据参数 可以得到 输入单词的向量表示。
测试:
输入:单词
输出:各个单词 出现在 输入单词的 上下文中 的概率。
总结: 想要 类比 word2vec 实现 node的向量 表示,必须要在图网络中找到,单词是什么,句子是什么。
第三阶段:DeepWalk
概念:DeepWalk 是最早提出的基于 Word2vec 的 节点向量化 模型。
目标:如何去把 一张图 来当作 一篇文本,图中节点表示成文本中的 token。然后调用现成的 word2vec模型 来生成向量。
瓶颈:而图不同于文本的特点是,文本是一个线性序列,图是一个复杂结构。
思路:使用 Skip-Gram 算法,其中
单词:将 node 作为单词;
句子:通过随机游走,得到 node 的序列,将这个序列作为句子。

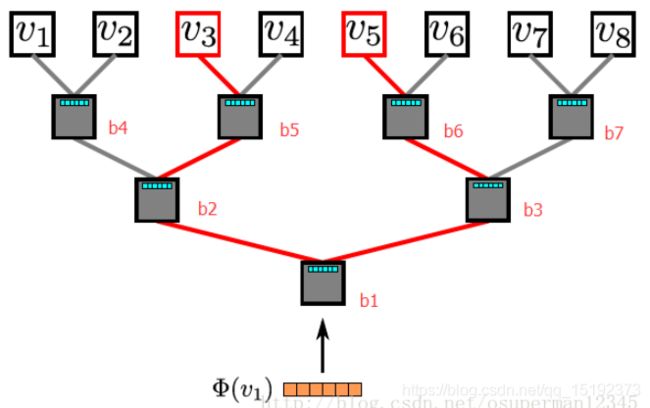
改进:为了提高Skip-Gram的训练过程的效率,DeepWalk采用 分层 softmax 的方法 来训练。
1. 即将 node 分配到 二叉树的叶节点上。
2. 在构造二叉树时,使用霍夫曼编码,将使用频率高的节点放到较短的分支上。
这样算法复杂度就从O(|V|)降到了O(log|V|)。
2. 本文方法?
概念:node2vec 通过改变 随机游走序列的生成方式 进一步 扩展了DeepWalk 算法。
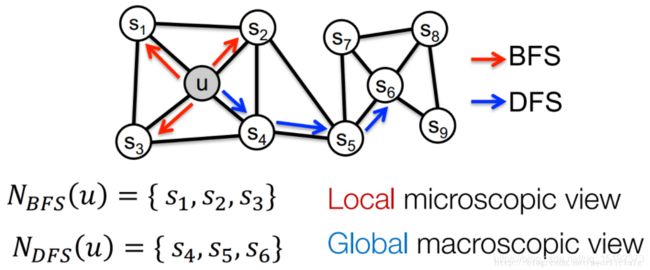
思路:DeepWalk 选取随机游走序列中下一个节点的方式 是均匀随机分布的,而node2vec通过引入两个参数p和q,将 宽度优 先搜索 和 深度优先搜索 引入随机游走序列的生成过程,来对图中的节点进行采样。如图所示。BFS 采样得到的是 Local microscopic view, 而DFS得到的是Global macrooscopoc view。
缺点(自己的思考):Link Prediction 是一个 Graph 问题,它的目标是根据已知的节点和边,得到新的边(的权值/特征)。本文的做法就好比,在一个社交网络上,只和其中很少一部分人建立了社交关系,剩下很多用户都没有关注。是否还有其他改进途径?