语音增强简介
大四上研究过一段时间NLMS,之后直到研一上做的都是关于麦克风阵列的语音增强,感觉时间久了又会记不太清楚,所以稍微整理下。
1 单麦克风语音增强
麦克风,又称话筒或传声器,是一种将模拟声音信号转换成数字电子信号的换能器。按声场作用力麦克风可分为压强式麦克风、压差式麦克风和压强压差组合式麦克风。我们常用的麦克风就是压强式麦克风。用单麦克风对语音进行增强,可通过物理结构和设计滤波器两种方法实现。
(1) 物理结构实现
指向性描述了麦克风对来自不同方向声音的灵敏度,可分为全指向性麦克风、双指向性麦克风和单一指向性麦克风。
全指向性麦克风是压强式麦克风,是最普遍的麦克风。它只有一个入声口,传声器膜片压强的变化产生相应的输出电压。由于压强是一个标量,因而它对不同方向上的声音的灵敏度是相同的。所以这种麦克风采集四周环境的所有声音,不能增强期望语音。
双指向性麦克风是压差式麦克风,它有两个入声口,通过其传声器膜片两侧压强差的变化产生相应的输出电压。这种麦克风可接受来自麦克风前方和后方的声音,因而如果期望信号在这两个方向上时,即可实现语音增强。
单一指向性麦克风是压强与压差复合式麦克风,其结构上是在麦克风管的一端和管侧开口,形成一个声干涉管,如图1-1所示。来自管开口端的声音信号同时到达传声器膜片,没有相位干涉,可获得最大输出;而来自管侧的声音信号到达传声器膜片的路径不同,产生相位干涉,输出被抑制,从而可增强麦克风前端的语音信号。常见的单一指向性麦克风有心型指向性麦克风、超心型指向性麦克风和枪型指向性麦克风。
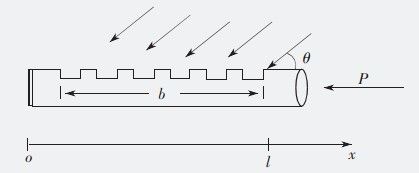
图1-1 声干涉管原理示意图
规格上常用极性图来表示麦克风的指向性,如图1-2所示,每个图中虚线圆形的上方表示麦克风的前方,下方则表示麦克风的后方。

图 1-2 各种麦克风的极性图
这种利用物理结构特点增强后的语音在人的主观感受上有所改善,但对于语音人机交互系统来说仍达不到要求,即使是超指向性麦克风,来自管侧的干扰语音还是会严重影响语音识别的识别率。
(2) 设计滤波器实现
将单个麦克风采集到的信号通过特别设计的滤波器,过滤掉非期望的噪声,实现语音增强。按处理域的不同可分为时域、频域和Karhunen-Loeve展开域(KLE)方法。时域方法就是设计一个最优时域滤波器来尽可能衰减噪音。频域方法是将信号变换到频域,在每个频率点上设计一个最优滤波器来衰减噪声。KLE域方法是先将麦克风采集到的数据的相关矩阵进行QR分解,利用得到的特征向量和特征值来衰减噪声。
这种方法能提高语音的信噪比,但是也引起语音信号的失真,从而影响语音信号的可懂度。
2 麦克风阵列语音增强
麦克风阵列通过其拓扑结构排列来捕获空时信息,并运用这些信息来估计一些参数或提取感兴趣的信号。虽然窄带天线阵列问题已得到很好的解决,但实际上麦克风阵列遇到的问题则要复杂得多,因为语音是宽带信号,室内声场混响很高,环境和信号是非统计的,噪声可能和期望信号具有相同的空间谱特征。
许多麦克风阵列处理算法都是基于窄带的或是由窄带阵列简单扩展而来。这些算法的优点是已经广泛应用于天线阵列,因而仅需简单扩展就可以运用于麦克风阵列。但这些算法没有一个能适用于真实声学环境,因而简单的将这些算法应用于宽带语音处理效果并不理想。麦克风阵列语音增强主要需解决的问题有:噪声衰减,回声消除,去混响,声源定位,声源数估计,声源分离和“鸡尾酒会效应”。与单麦克风语音增强算法不同,运用麦克风阵列要在保证期望信号不失真的情况下尽可能衰减噪声。
3 盲源分离
盲源分离问题起源于20世纪80年代,最早应用于数字通信系统。它是要在不知道输入信号任何信息和信道传播特性的情况下对混合输出信号进行分离,估计出输入信号。在生物医学及图像处理方面,盲源分离已有了很好的应用。
在盲源分离问题中,独立成分分析是应用最为广泛的工具,因为它充分利用了输入信号的独立性。当各输入信号是瞬时线性混合时,独立成分分析能很好的将信号分离开来,然而在室内混响环境中,独立成分分析效果则不理想。尽管最近很多基于独立成分分析的理论方法被提出,但现在仍然不知道它怎样运用于语音声学环境中。因此基于卷积模型的盲源分离方法应运而生,它优化了输入信号的混合模型,更符合现实语音混合模型,但是基于此模型的相关算法有待进一步完善,以更好的应用。
4 麦克风阵列语音增强的研究进展
语音增强和阵列技术的研究开展较早,虽然随着数字信号处理领域相关理论的完善和成熟,这两项技术也取得了一定的成果,但最早的语音增强重点研究单个麦克风语音增强,最早的阵列技术也是利用窄带天线阵列进行探测,而将阵列技术运用到语音增强中来,则始于20世纪80年代,并在90年代成为研究热点。国内的相关研究则更晚。每年国际国内重要期刊和会议上都会有大量相关的文献文章。
(1) 固定波束形成法
固定波束形成法又称延迟-相加波束形成法,最早是由Flanagan于1985年提出的。它先对麦克风阵列各阵元接收到的声音信号进行时延补偿,使各阵元的信号同步,然后设计一个有限长度滤波器进行加权求和,输出的信号就是增强后的信号。因为设计的滤波器系数在处理过程中是固定不变的,所以称这种方法为固定波束形成法。
这种方法的实现比较简单,但它需要较多的麦克风阵元才能达到较好的语音增强效果。
(2) 自适应波束形成法
最早的自适应波束形成法是Frost于1972年提出的线性约束最小方差(Linearly Constrained Minimum Variance,LCMV)算法。该方法也称为Frost波束形成法,它在保证注视方向(Look direction)上期望信号频率响应不变的同时,通过约束条件使得阵列输出功率最小,即等价于使阵列输出噪声功率最小,从而实现噪声抑制。在此算法的基础上,Griffths和Jim于1982年提出广义旁瓣抵消(Generalized Sidelobe Canceler,GSC)算法,通过引入阻塞矩阵,将有约束的Frost滤波器扩展为无约束的GSC滤波器。GSC算法将阵列输出通过上下两个通道,上通道产生语音参考信号,下通道产生噪声参考信号,然后用语音参考信号减去噪声参考信号,从而得到增强信号。这种方法最大的问题在于噪声参考信号中并不仅仅都是噪声信号,也可能包含一些语音信号,这样在相减时可能抵消部分语音信号,造成语音信号失真。为了解决这一问题,许多学者对算法进行了改进,比如Hoshuyma于1996年提出的韧性自适应波束形成法,改进了阻塞矩阵,使得噪声参考信号中的语音成分最小,从而减小了信号失真。因为设计的滤波器系数在处理过程中是随着输入信号的变化而变化的,所以称这种方法为自适应波束形成法。
自适应波束形成法能有效衰减相干噪声,在麦克风阵元数大于声源数时有较好的处理效果。
(3) 后置滤波法
在麦克风阵列中运用后置滤波器进行波束形成的方法是由Zelinski于1988年提出的。该方法以维纳滤波器为基础,在延时-相加波束形成器的输出端加一个滤波器,通过求解Wiener-Hopf方程来求得滤波器系数。在此基础上,许多学者通过不同的方法提出许多不同的后置滤波器,比如McCowan于2002年提出的广义后置滤波器法,就是将噪声场中相关理论模型扩展到后置滤波器的转移函数中,从而改善滤波器性能。
后置滤波器法一般不单独使用,而是与固定波束形成器或自适应波束形成器结合使用,这样通过自适应波束形成器衰减相干噪声,通过后置滤波器衰减非相干噪声,从而更好的抑制了噪声。
(4) 子空间法
子空间法是先对每个麦克风阵元的信号使用单通道子空间或利用输入信号的相关矩阵子空间构建信号子空间,然后采用固定波束形成或自适应波束形成实现语音增强。这种算法分别由Hansen和Asano于1997年提出,并在之后的几年里被其他学者不断完善,比如Doclo等提出的基于广义奇异值分解的波束形成法。
子空间法最大的缺点是计算复杂度太大,难于实时应用于数字信号处理。
(5) 子带波束形成法
针对语音信号是宽带信号这一特点,许多学者于21世纪初提出了子带波束形成法。这种方法先将麦克风采集到的声音信号从时域经过傅里叶变换到频域,然后将频带分段,在每一段运用窄带波束形成法产生输出,然后逆傅里叶变换到时域,从而得到增强后的语音信号。比如McCowan于2001年,Grbic于2003年提出的基于均匀DFT子带波束形成法。
子带波束形成法具有噪声抑制能力强,收敛速度快等优点。
(6) 频率不变波束形成法
一般波束形成法在不同频段的波束形成效果不同,实际应用中男声的频率一般低于女声的频率,导致一般的波束形成法对男声和女声的增强效果不同。针对这一问题,许多学者提出了频率不变波束形成法,即波束形成效果不随频率的改变而改变。这一方法的关键在于频率不变波束形成器的设计,如1970年Hixson和Au等提出利用谐波嵌套法,1988年Doles和Benedict提出的利用非均匀阵列的渐近理论设计法,2002年Weiss等提出的倍频分解法。
在线性阵列的基础上,Chan和Chen于2002年提出了圆阵频率不变波束形成器,于2005年到2007年扩展到同轴圆阵和同轴球型阵,从而将波束形成由一维扩展到二维和三维。