Netty学习笔记五:Netty源码分析
1. Netty学习笔记五:Netty源码分析
文章目录
- 1. Netty学习笔记五:Netty源码分析
- 2. EventLoop和EventLoopGroup线程模型
- 3. Netty启动引导类BootStrap模块
- 3.1. 服务器启动引导类ServerBootStrap
- 4. Netty核心组件Channel模块讲解
- 4.1. Channel简单介绍和作用
- 4.2. Channel的状态
- 5. ChannelHandler和ChannelPipeline模块讲解
- 5.1. Channelhandler和ChannelPipeline核心作用和生命周期
- 5.2. ChannelPipeline
- 6. 适配器模式
- 7. ChannelHandlerContext模块
- 7.1. ChannelHandlerContext简介
- 7.2. AbstractChannelHandlerContext类
- 7.3. DefaultChannelHandlerContext
- 8. Netty中入站出战Handler的执行顺序
- 9. Netty异步模块操作ChannelFulture
- 9.1. ChannelFulture是做什么的?
- 9.2. ChannelFulture的状态
- 9.3. ChannelPromise类
2. EventLoop和EventLoopGroup线程模型
- 高性能RPC框架3个要素
一、IO模型(五种IO模型)
二、数据协议(http/protobuf/Thrift)
三、线程模型(主从线程组模型)
- EventLoop
EventLoop好比一个线程,1个EventLoop可以服务多个Channel,一个Channel只有一个EventLoop,也就是说一个线程负责多个连接通道,可以创建多个EventLoop来优化资源的利用,也就是EventLoopGroup。源码分析默认线程池数量=cpu核心数*2
- EventLoopGroup
EventLoopGroup负责生成EventLoop到创建新的Channel,里面包含多个EventLoop。
EventLoop维护一个Reactor模型(I/O模型),这个I/O模型可以负责多个连接,即:Channel通道,因此I/O模型的好坏也影响系统的效率。
- Selector学习资料
Selector学习
3. Netty启动引导类BootStrap模块
3.1. 服务器启动引导类ServerBootStrap
- group:设置线程组模型,Reactor线程模型对比EventLoopGroup,包含单线程模型,多线程模型,主从线程模型。
单线程模型:
一、如果此时是主从线程组,那就去掉从线程组,然后在group中去掉从线程组的对象。让serverBootstrap.group(boosgroup)只包含一个线程组。
EventLoopGroup bossGroup = new NioEventLoopGroup();
//EventLoopGroup workGroup = new NioEventLoopGroup();
try{
ServerBootstrap serverBootstrap = new ServerBootstrap();
//serverBootstrap.group(bossGroup, workGroup)
serverBootstrap.group(bossGroup)
多线程模型:
一、多线程模型就是主线程组只有一个线程,从线程组有多个线程。主线程就好比主线程中的一个接待员,然后从线程组就好比服务人员。
//配置服务端线程组
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workGroup = new NioEventLoopGroup();
try{
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(bossGroup, workGroup)
主从线程模型
- channel通道
设置channel通道类型NioServerSocketChannel,OioServerSocketChannel
- childHandler
用于对每个通道里面的数据进行处理。
- option
作用于每个新建立的Channel,设置TCP连接中的一些参数,主要设置两个参数:
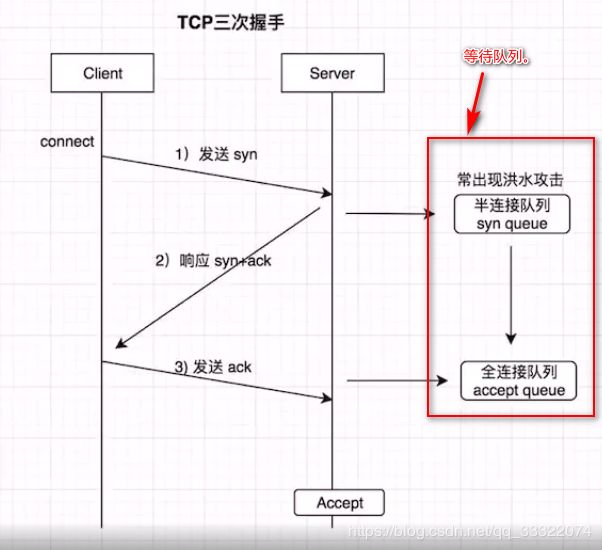
一、设置ChannelOption.SO_BACKLOG:用于存放已完成三次握手的请求的等待队列的最大长度;
syn queue:半连接队列,tcp_max_syn_backlog
accept queue:全连接队列,net.core.somexconn
系统默认somexconn参数足够大,如果backlog比somexconn大,系统就会使用somexconn,否则会施一公backlog
- 洪水攻击:是根据tcp协议进行的一种攻击,TCP有三次握手连接,当第一连接时会生成一个半连接队列,此时攻击者会疯狂的往该队列中注入连接,以至于本来想连接的人员无法进行连接,就会超时报错。
- 避免洪水攻击:
二、设置ChannelOption.TCP_NODELAY:为了解决Nagle的算法问题,默认是false,要求高实时性,有数据立马发送,就将该选项设置为true,关闭Nagle算法。要求减少发送次数,就要使用Nagle算法,就要设置为false,这样数据就会积累一定的数据量才会发送。
三、Nagle算法:就是为了让数据积累一定的量再发送,减少发送数据次数。
4. Netty核心组件Channel模块讲解
4.1. Channel简单介绍和作用
- 什么是Channel:客户端和服务端建立的一个连接通道。通过这个通道我们可以传输数据,并且可以监听通道的变化。
- 什么Channelhandler:负责Channel中获取数据后的逻辑处理。
- 什么是ChannelPipeLine:负责管理ChannelHandler的有序容器。
总结:
一个Channel包含一个ChannelPipeline,所有ChannelHandler都会顺序加入到ChannelPipeline中,创建Channel时会自动创建一个ChannelPipeline,每个Channel都有一个管理它的pipeLine,这种关联是永久性的。
4.2. Channel的状态
- ChannelRegisted:Channel注册到一个EventLoop
- ChannelUnregisted:Channel已经创建,但是未注册到一个EventLoop里面,也就是未和Selector绑定。
- ChannelActive:变为活跃状态(连接到了远程主机)(客户端也会创建一个Channel,并连接远程主机)可以接收发送数据了。
- ChannelInactive:Channel处于非活跃状态,没有连接到远程主机。
- Channel状态变化

5. ChannelHandler和ChannelPipeline模块讲解
5.1. Channelhandler和ChannelPipeline核心作用和生命周期
- ChannelHandler包含几个主要方法。
handlerAdded():当ChannelHandler添加到ChannelPipeline时,就会回调handlerAdded
handlerRemoved():当ChannelHandler从ChannelPipeline移除时,就会回调handlerRemoved()
exceptionCaught():当抛出异常时,会调用此方法。
- ChannelHandler下主要是两个子接口
入站:
ChannelInboundHandler():用于处理数据和Channel状态类型改变。
适配器:ChannelInboundHandlerAdapter(适配器模式)
常用的类:SimpleChannelInboundHandler,这个会写的时候主动帮我们释放了内存。做了一些简单的包装。
出站:
ChannelOutboundHandler():处理输出数据
适配器:ChannelOutboundHandlerAdapter
5.2. ChannelPipeline
好比工厂流水线,可以添加ChannelHandler,可以删除。可以指定跳过某个ChannelHandler。就是一种高级的拦截器。

6. 适配器模式
- 适配器模式解决的问题:
假如有一个接口有很多未曾实现的方法,如果我们用一个类去继承它,我们会发现这个类不得不去实现它的所有方法。然而有些方法我们可能永远也不会用到,这样就会让代码变得更加冗余复杂。
为了减少这种代码的冗余,我们创建了一个类对该方法进行了实现,但是并没有做什么处理。当我们开发时我们只需要继承这个实现的方法就可以了,那么我们此时就可以再实现我们想要的方法了。而不会报错。
7. ChannelHandlerContext模块
7.1. ChannelHandlerContext简介
- ChannelHandlerContext是ChannelHandler上下文的意思。是连接ChannelHandler和ChannelPipeline的桥梁。
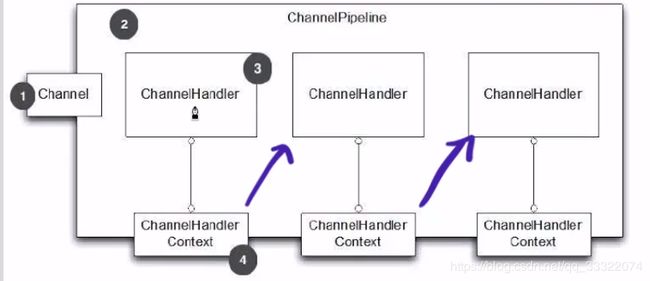
- 从上图看,如果我们要写一些数据给客户端,我们有三种方法
一、通过Channel写回去
Channel channel = ctx.channel();
channel.write(Unpooled.copiedBuffer("abc",CharsetUtil.UTF_8));
二、通过pipeline写回
ChannelPipeline pipeline = ctx.pipeline();
pipeline.writeAndFlush(Unpooled.copiedBuffer("abc",CharsetUtil.UTF_8));
三、通过ChannelHandlerContext写回
ctx.writeAndFlush(data);
- 三种写回方法的区别
一、用Channel写回的时候,会经过所有的ChannelHandler的过滤。
二、用ChannelHandlerContext写回的时候,会经过之后的ChannelHandler。跳过一些ChannelHandler.
三、用ChannelPipeline和Channel一样会经过管道里的所有ChannelHandler.
7.2. AbstractChannelHandlerContext类
- 双向链表类,next/prev分别是后继节点,和前驱节点。
7.3. DefaultChannelHandlerContext
- 是一个不可继承的实现类,但是大部分逻辑是父类完成,只是简单的实现一些方法,主要就是判断Handler的类型。
- ChannelInboundHandler之间的传递,主要是通过调用ctx里面的Firexxx()方法来实现下一个handler的调用。
8. Netty中入站出战Handler的执行顺序
- 一般项目中inboundHandler和outboundHandler有多个,在Pipeline中有哪些执行顺序呢?
一、InboundHandler顺序执行,OutboundHandler逆序执行。(在pipeline中)
二、InboundHandler之间数据传递,通过ctx.fireChannelRead(msg)
三、InboundHandler通过ctx.write(msg),传递到outboundHandler
四、ctx.write(msg)传递消息,Inbound需要放在结尾,在outbound之后,不然outboundHandler不会执行,但是,使用Channel.write(msg),或者pipline.write(msg),情况会不一样,都会执行。
五、outbound和Inbound谁先执行,针对客户端和服务端而言,客户端先发请求后接收数据,先out,后in,服务端相反。

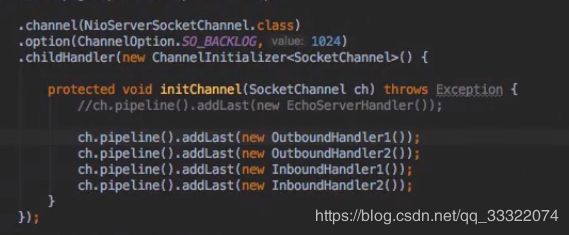
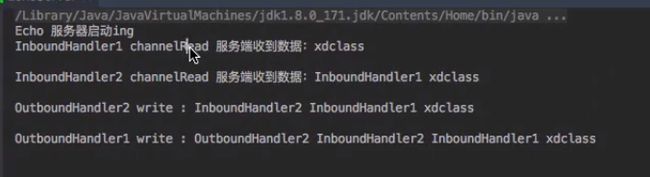
客户端是先输出,再输入服务器,服务端是先输入数据,然后再写回硬件,在服务器中,输出out必须写在int输入的前面,并且输出是逆序执行的。
9. Netty异步模块操作ChannelFulture
9.1. ChannelFulture是做什么的?
- ChannelFulture继承netty架包中的Fulture接口,然后Fulture接口又继承jdk架包中的Fulture接口,因此ChannelFulture的作用和jdk中的fulture是一样的。
jdk1.5之前是没有fulture的,首先要先从线程说起,开启一个线程需要实现Runnable或者继承Thread类,但是这两者有个问题,就是没有任何返回值,是void方法类型。因为线程是异步的,主进程交给线程处理任务时,很难获取线程返回的结果,但是有些实际要求确实需要一个返回值。因此Fulture就出现了。fulture的作用就是检测线程是否执行的状态,包含未执行完,和执行完。并且可以将线程计算的结果返回给主进程。fulture可以来接收多线程的执行结果。
- 形象的描述fulture的作用。
Future模式可以这样来描述:我有一个任务,提交给了Future,Future替我完成这个任务。期间我自己可以去做任何想做的事情。一段时 间之后,我就便可以从Future那儿取出结果。就相当于下了一张订货单,一段时间后可以拿着提订单来提货,这期间可以干别的任何事情。其中Future 接口就是订货单,真正处理订单的是Executor类,它根据Future接口的要求来生产产品。
9.2. ChannelFulture的状态
- 未完成状态:当I/O开始时,将创建一个新的对象,新的最初是未完成的,它既没有成功,也没有被取消,因为I/O操作尚未完成。
- 已完成:当I/O完成,不管是否成功,失败还是取消,Fulture都是标记为已完成的,失败的时候也有具体的信息,但是即使是失败也是属于完成状态。
- 注意: 不要I/O线程中调用fulture对象的sync或者await方法,因为线程时异步的,多线程中这样做可能会进入死锁状态。 因此不能在channelHandler中调用sync或者await,防止死锁。
- 源码分析
//绑定端口,同步等待成功,通过channelFulture监听端口里面传过来的值。serverBootstrap,里面含有线程组,监听端口后,进行同步的等待。一旦有值,就会被channelfulture监听到
ChannelFuture channelFuture = serverBootstrap.bind(port).sync();
//等待服务端监听端口关闭,调用channel通道,然后同步监听closeFulture,一旦出现关闭就同步的进行关闭。
channelFuture.channel().closeFuture().sync();
9.3. ChannelPromise类
- 主要是继承ChannelFulture,进一步拓展用于设置I/O操作的结果。