scrapy框架开发爬虫实战——生产者消费者模式(用了requests模块)
生产者消费者模式分析
在爬虫的工作过程中,需要请求数据,然后再解析数据。
生产者用来解析接口,消费者用来解析数据。
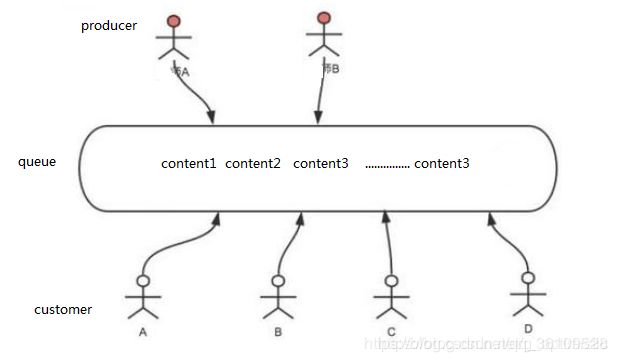
生产者消费者模式的详细介绍:
https://blog.csdn.net/u011109589/article/details/80519863
# -*- coding: utf-8 -*-
# 时间模块
import time
# requests 模块
import requests
# 线程
import threading
# 队列
from queue import Queue
# json
import json
# 子类Thread_producer继承父类Thread
class Thread_producer(threading.Thread):
# name线程名,page_queue任务队列
def __init__(self, name, page_queue):
# 初始化父类线程
threading.Thread.__init__(self)
# 取得任务队列
self.page_queue = page_queue
# 取得线程名
self.name = name
# 复写run()方法
def run(self):
time_start = time.time()
print(self.name, '开始时间:', time_start)
while True:
if self.page_queue.empty():
break
else:
print('当前线程', self.name, '将要从队列中抽取任务')
page = self.page_queue.get()
print(self.name, '将要从队列中抽取的任务是:', page)
url = 'https://careers.tencent.com/tencentcareer/api/post/Query?keyword=python&pageIndex={}&pageSize=10'.format(page)
self.get_content(url)
print(self.name, '完成任务')
time_end = time.time()
print(self.name, '完成时间是:', time_end)
print('耗时', time_end - time_start)
def get_content(self, url):
# 头信息
headers = {
'user - agent': 'Mozilla / 5.0(Windows NT 6.1;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 74.0.3729.108Safari / 537.36'
}
response = requests.get(url=url, headers=headers).content.decode('utf-8')
content_queuq.put(response)
class Thread_customer(threading.Thread):
def __init__(self, name):
threading.Thread.__init__(self)
self.name = name
def run(self):
time_start = time.time()
print(self.name, '开始时间:', time_start)
while True:
if content_queuq.empty() and flag:
break
else:
try:
print('当前线程', self.name, '将要从队列中取任务')
response = content_queuq.get(block=False)
print(self.name, '从队列中抽取的任务是', response)
self.get_data(response)
print(self.name, '完成的任务是:', response)
except:
pass
time_end = time.time()
print(self.name, '完成时间:', time_end)
print('耗时', time_end - time_start)
def get_data(self, response):
content_list = json.loads(response)['Data']['Posts']
for content in content_list:
name = content['RecruitPostName']
country = content['CountryName']
address = content['LocationName']
duty = content['Responsibility']
detail_link = content['PostURL']
info = {
'岗位名称': name,
'国家': country,
'地区': address,
'职责': duty,
'链接': detail_link,
}
with open('TJ_Jobs_requests.txt', 'a', encoding = 'utf-8') as fp:
fp.write(str(info))
content_queuq = Queue()
flag = False
if __name__ == '__main__':
t_start = time.time()
print('主线程开始时间:', t_start)
page_queue = Queue()
for page in range(1, 2):
page_queue.put(page)
producer_name = ['p1', 'p2', 'p3']
producer_thread = []
for name in producer_name:
crawl = Thread_producer(name, page_queue)
crawl.start()
producer_thread.append(crawl)
customer_name = ['c1', 'c2', 'c3']
customer_thread = []
for name in customer_name:
crawl = Thread_customer(name)
crawl.start()
customer_thread.append(crawl)
for thread in producer_thread:
thread.join()
flag = True
for thread in customer_thread:
thread.join()
t_end = time.time()
print('主线程结束时间:', t_end)
print('完成时间:', t_end - t_start)