Notes for LSTM-Based End-to-End Framework for Bio Event Extraction
Contents
- Introduction
- Research background
- Methods for Bio Event Extraction
- Others'
- The author's
- Related Work
- Methodology
- Word Embedding
- Long Short-Term Memory
- Bi-LSTM-Based Trigger Detection
- Tree-LSTM-Based Argument Detection
Introduction
Research background
Structured descriptions of biomedical events consists of event catagory, trigger, and argument. Example:
hyposized that the phosphorylation of TARF2 inhibits the CD40.
- Event1: Phosphorylation, Trigger: phosphorylation, Theme1: TRF2
- Event2: Negative Regulation, Trigger: inhibits, Theme1: CD40, Cause1: Event1
Methods for Bio Event Extraction
Others’
Most used biology event extraction methods are based on three steps:
- event trigger detection
- argument detection
- post-processing
But following these steps may lead to cascading errors. For example, if there is no trigger detected in the first step, the mistale could pass on to further steps. Some solutions to this problem:
- using Markov logic network
- three combined models with a prediction-based PA online learning algorithm
- integrating word embedding to detect events jointly
However, these potential solutions still have problems.
- Still following the three steps thus cannot eliminate cascading errors.
- Not good with sequence information thus cannot capture features automatically.
- Not suffcient to just represent words with word embedding.
Thus methods using LSTM had been put out to solve event extraction.
The author’s
The author presented an end-to-end model based on Bi-LSTM and Tree-LSTM networks. Bi-LSTM is excellent on handling sequence teasks while Tree-LSTM can save the need for external parse trees. Steps for the authors’ method:
- Represent words as a linear sequence using word embedding.
- Build Bi-LSTM model to detect triggers.
- Emply a bidirectional Tree-LSTM to assist argument detection.
- Implementan end-to-end framework to train.
Related Work
The goal of biology event extraction is to detect the types of triggers and relationships between triggers and arguments. There are usually two kinds of approaches.
- Rule-based approach
This approach generate a dictionary and patterns from annotated events and then apply the dictionary and patterns to extract events from input text. This approach have high precision but performs bad during prediction. - Machine learning based approach
It considers each task as a classification problem. The pipeline consists of event trigger identification and event argument detection. ML approaches, especially those using SVMs. However, ML based methods have some drawbacks too.
To overcome problems caused when using traditional methods, some put forward deep neural networks. But this does not eliminate cascading errors for these methods separate trigger detection and argument detection into two individual models without any common parameters shared. As a result, the author carried out an end-to-end model that can do both detections simultaneously.
Methodology

The process has these following steps:
- Preprocess dataset for model training and employ word embedding to represent the raw corpus.
- Use Bi-LSTM to predict trigger types and find trigger words.
- Use Tree-LSTM to represent dependency information of sentences.
- Use Tree-LSTM to detect argument.
Word Embedding
Primary purpose of word embedding is to form a lookup table to represent each word in a vocabulary with dense, low dimensional, and real-valued vectors.The author used Word2Vec, a standard tool in NLP.
- Download abstract texts from PubMed to build a corpus.
- Split abstracts into sentences and tokensize each sentence into tokens.
- Use Word2vec to process the sentences and derive vectors via skip-program language model.
Long Short-Term Memory
LSTM is composed of a cell, inout gate, output gate, and forget gate. Each of the three gates can be considered as a multi-layer neural network that can compute an activation based on a weighted sum. Gates block or pass information based on their own sets of weights.

The given inputs are multiplied by the weight matrices and a bias is added. A sigmoid function is responsible for desciding which values to keep and which to discard.
Bi-LSTM-Based Trigger Detection
Trigger detection process, which is the core operation, involves indentification of event triggers and their types. And the paper used LSTM to learn information among sentences automatically during the training process.
Bi-LSTM newwork can access both preceding and subsequent contexts. It aims to map every word in a dictionary to a numerial vector such that the distance and relationship between vectors reflects the semantic information between words.
In this step, inputs are composed of vectors corresponding to the words in a sentence. During training, Bi-LSTM network is able to learn and improve representations for words automatically.

i: iput gate
f: forget gate
o: output gate
c: cell vector
xt is composed of word embedding and part of speech (POS) embeddings and can be represented as [vt(w);vt( p)].
In the paper’s model, it first uses BI-LSTM ti capture syntactic and semantic information in a sentence. Then predict the trigger type by employing average pooling and logistic regression layers following Bi-LSTM network.
THre is a softmax after output layer of Bi-LSTM, to find which vector has achieved the highest score. Then the corresponding input of the selected vector can be considered as the trigger.

W is weight matrics and b is bia vectors.
Tree-LSTM-Based Argument Detection
Tree-LSTM is used to dnote the type of realtionship between each target pair. Target pair cadidates for argument detection are built using all possible combinations of the trigger word and the remaining words in the sentence.
Example:
trigger word: transcription
second word: stimulates, c-fos;
(“transcription”,“stimulates”) and (“transcription”,“c-fos”) could be arguments of the trigger.
First, build pairs accoding to the trigger. Then, build dependency tree layer by employing Tree-LSTM. Next, for each candidate pair, its new vector can be represented by the combination of its corresponding hidden layer in both Bi-LSTM network and Tree-LSTM network. The softmax layer then receives the target candidate vectors and will make a prediction.
As for dependency tree layer, it represents the relationshipps between two words in the dependency tree. Typically, this layer largely focuses on the shortest dependency path (SDP) between two entities.
In addition, in order to capture more information of the target word pair, we were inspired to adopt bidirectional Tree-LSTM to represent the relationships between words.
- Employ bottom-up LSTM to propagate information from the leaves to each of the nodes.
- Use nodes at the top of the tree to propagate information from the root via top-down LSTM.
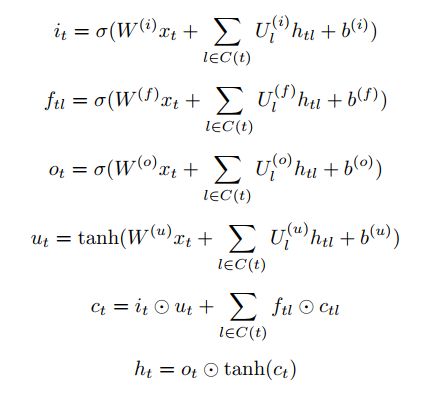
In previous studies, researchers often constructed two models to separate trigger detection and argument detection. In contrast, the author adopted an end-to-end model with a single loss function.
- Apply a dropout operation to the embedding layers and hidden layers in the model.
- Choose a training set to train the model and calculate the total loss from trigger detection and argument detection. Total loss can be defined as loss = l1+l2

- Adopt back propagation through time (BPTT) and the Adem algorithm with gradient clipping, parameter averaging, and L2-regularization to update the parameters of the model.
Additionally, the author trained n models (n corresponds to the number of event types in the study, where all datasets for each model were the same) during experiment to solve problem of one sentence potentially including an arbitrary number of triggers for different event types.