《Thinking in Algorithm》12.详解十一种排序算法
排序算法在算法中占着很重要的地位,很多算法的实现都是基于排序算法的(如搜索算法和合并算法)。所以排序算法也是笔试面试中必考内容。但是不管他怎么考,也就是那几种算法,一般不会超出我接下来要讲的这11种,所以只要认真的掌握着11中就足够了。
那么是哪11种呢,下面是wiki上总结的11种
- 1 Simple sorts
- 1.1 Insertion sort(插入排序)
- 1.2 Selection sort(选择排序)
- 2 Efficient sorts
- 2.1 Merge sort (归并排序)
- 2.2 Heapsort (堆排序)
- 2.3 Quicksort (快速排序)
- 3 Bubble sort and variants
- 3.1 Bubble sort (冒泡排序)
- 3.2 Shell sort (希尔排序)
- 3.3 Comb sort (梳排序)
- 4 Distribution sort
- 4.1 Counting sort(计数排序)
- 4.2 Bucket sort(桶排序)
- 4.3 Radix sort(基数排序)
讲之前先了解几组概念。
排序算法的稳定性?
排序算法可以根据稳定性分为两种:稳定和非稳定算法。那么怎么区分它们?如果链表中存在两个相同元素,稳定排序算法可以在排序之后保持他两原来的次序,而非稳定性的则不能保证。如下图

各种算法的比较
下图中是所有的比较排序算法,从图中我们可以看出比较算法的特性:比较排序有很多性能上的根本限制,如在最差情况下,任何一种比较排序至少需要O(nlogn)比较操作
| Name | Best | Average | Worst | Memory | Stable | Method | Other notes |
|---|---|---|---|---|---|---|---|
| Quicksort | 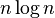 |
|
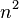 |
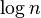 on average, worst case is on average, worst case is 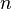 ; Sedgewick variation is worst case ; Sedgewick variation is worst case |
typical in-place sort is not stable; stable versions exist | Partitioning | Quicksort is usually done in place with O(log n) stack space.[citation needed] Most implementations are unstable, as stable in-place partitioning is more complex. Naïve variants use an O(n) space array to store the partition.[citation needed] Quicksort variant using three-way (fat) partitioning takes O(n) comparisons when sorting an array of equal keys. |
| Merge sort | |
|
|
worst case |
Yes | Merging | Highly parallelizable (up to O(log n) using the Three Hungarian's Algorithm[clarification needed] or, more practically, Cole's parallel merge sort) for processing large amounts of data. |
| In-place merge sort | — | — | |
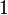 |
Yes | Merging | Can be implemented as a stable sort based on stable in-place merging.[2] |
| Heapsort | |
|
|
|
No | Selection | |
| Insertion sort | |
|
|
|
Yes | Insertion | O(n + d),[clarification needed] where d is the number ofinversions. |
| Introsort | |
|
|
|
No | Partitioning & Selection | Used in several STL implementations. |
| Selection sort | |
|
|
|
No | Selection | Stable with O(n) extra space, for example using lists.[3] |
| Timsort | |
|
|
|
Yes | Insertion & Merging | Makes n comparisons when the data is already sorted or reverse sorted. |
| Shell sort | |
or |
Depends on gap sequence; best known is |
|
No | Insertion | Small code size, no use of call stack, reasonably fast, useful where memory is at a premium such as embedded and older mainframe applications. |
| Bubble sort | |
|
|
|
Yes | Exchanging | Tiny code size. |
| Binary tree sort | |
|
|
|
Yes | Insertion | When using a self-balancing binary search tree. |
| Cycle sort | — | |
|
|
No | Insertion | In-place with theoretically optimal number of writes. |
| Library sort | — | |
|
|
Yes | Insertion | |
| Patience sorting | — | — | |
|
No | Insertion & Selection | Finds all the longest increasing subsequences inO(n log n). |
| Smoothsort | |
|
|
|
No | Selection | An adaptive sort: comparisons when the data is already sorted, and 0 swaps. |
| Strand sort | |
|
|
|
Yes | Selection | |
| Tournament sort | — | |
|
[4] |
? | Selection | |
| Cocktail sort | |
|
|
|
Yes | Exchanging | |
| Comb sort | |
|
|
|
No | Exchanging | Small code size. |
| Gnome sort | |
|
|
|
Yes | Exchanging | Tiny code size. |
| UnShuffle Sort[5] | |
|
|
In place for linked lists. N*sizeof(link) for array. | Can be made stable by appending the input order to the key. | Distribution and Merge | No exchanges are performed. Performance is independent of data size. The constant 'k' is proportional to the entropy in the input. K = 1 for ordered or ordered by reversed input so runtime is equivalent to checking the order O(N). |
| Franceschini's method[6] | — | |
|
|
Yes | ? | |
| Block sort[7] | |
|
|
|
Yes | Insertion & Merging | Combine a block-based O(n) in-place merge algorithm[8] with a bottom-up merge sort. Turns into a full-speed merge sort if additional memory is optionally provided to it. |
下面是整数排序算法和其他非比较排序算法
他们并没有 ![]() 的限制。
的限制。
| Name | Best | Average | Worst | Memory | Stable | n << 2k | Notes |
|---|---|---|---|---|---|---|---|
| Pigeonhole sort | — |  |
|
 |
Yes | Yes | |
| Bucket sort (uniform keys) | — | |
|
 |
Yes | No | Assumes uniform distribution of elements from the domain in the array.[9] |
| Bucket sort (integer keys) | — | |
|
Yes | Yes | If r is O(n), then Average is O(n).[10] | |
| Counting sort | — | |
|
Yes | Yes | If r is O(n), then Average is O(n).[9] | |
| LSD Radix Sort | — |  |
|
|
Yes | No | [9][10] |
| MSD Radix Sort | — | |
|
Yes | No | Stable version uses an external array of size n to hold all of the bins. | |
| MSD Radix Sort (in-place) | — | |
|
No | No | ||
| Spreadsort | — | |
 |
No | No | Asymptotics are based on the assumption that n << 2k, but the algorithm does not require this. |
对这些算法进行比较之后,我们会发现排序算法可真多,但在实际应用中也就几种。在少量数据的情况下我们一般会用到插入排序算法,但在大量数据的集合下,我们就会用到堆排序,归并排序,或者快速排序等。对于更多受限制的数据,例如固定间隔的数,则分布排序(计数排序,基数排序)被广泛用到。冒泡排序在实际中很少用到,不过在教学中倒很常见。
维基百科中将那11种算法分为了4种,1.简单排序 2.有效排序 3.冒泡和变体 4.分配排序
1. 简单排序类别
----------------------------------------------
有两种简单排序算法分别是插入排序和选择排序,两个都是数据量小时效率高。实际中插入排序一般快于选择排序,由于更少的比较和在有差不多有序的集合表现更好的性能。但是选择排序用到更少的写操作,所以当写操作是一个限制因素时它被使用到。
1.1 插入排序算法

Graphical illustration of insertion sort
|
|
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | О(n2) comparisons, swaps |
| Best case performance | O(n) comparisons, O(1) swaps |
| Average case performance | О(n2) comparisons, swaps |
| Worst case space complexity | О(n) total, O(1) auxiliary |
常常被用作为复杂算法的一部分,希尔排序是插入排序的一种变体对数据大时更有效。
优点:
- 实现简单
- 对于少量数据效率高
- 对于差不多已经排好顺序的集合效率高,时间复杂度为O(n+d),d是错位数字的个数
- 比起其他简单二次(O(n^2))算法(选择排序,冒泡排序),他的最好的情况是O(n)(集合接近顺序排好)
- 稳定,不会改变相等数原有的顺序
- in-place,只需要常熟O(1)的额外内存空间

3 7 4 9 5 2 6 1
3 7 4 9 5 2 6 1
3 7 4 9 5 2 6 1
3 4 7 9 5 2 6 1
3 4 7 9 5 2 6 1
3 4 5 7 9 2 6 1
2 3 4 5 7 9 6 1
2 3 4 5 6 7 9 1
1 2 3 4 5 6 7 9
- for i ← 1 to length(A)
- j ← i
- while j > 0 and A[j-1] > A[j]
- swap A[j] and A[j-1]
- j ← j - 1
最好,最坏,平均情况
1.2 选择排序算法

|
|
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | О(n2) |
| Best case performance | О(n2) |
| Average case performance | О(n2) |
| Worst case space complexity | О(n) total, O(1) auxiliary |
插入排序最坏,最好,平均情况都是O(n^2).
算法:将数组分为两部分,一部分是已经排好顺序的,另一部分是未排序的。每次找数组后半部分中最小的一个元素排到前面的序列。如下列数组
64 25 12 22 11 11 25 12 22 64 11 12 25 22 64 11 12 22 25 64 11 12 22 25 64
代码如下
- int i,j;
- int iMin;
- for (j = 0; j < n-1; j++) {
- iMin = j;
- for ( i = j+1; i < n; i++){
- if (a[i] < a[iMin]){
- iMin = i;
- }
- }
- if ( iMin != j ){
- swap(a[j], a[iMin]);
- }
- }
由此可知时间复杂度为(n − 1) + (n − 2) + ... + 2 + 1 = n(n − 1) / 2 ∈ Θ(n2) ,不管任何情况
2. 有效算法
----------------------------------------------
2.1 归并排序算法
算法逻辑:1. 将列表分为n个子列表,每一个列表只包含一个元素 2. 反复地归并子列表成一个新的有序列表,知道只剩下一个子列表

An example of merge sort. First divide the list into the smallest unit (1 element), then compare each element with the adjacent list to sort and merge the two adjacent lists. Finally all the elements are sorted and merged.
|
|
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | O(n log n) |
| Best case performance | O(n log n) typical, O(n) natural variant |
| Average case performance | O(n log n) |
| Worst case space complexity | O(n) auxiliary |

自上而下实现:

- TopDownMergeSort(A[], B[], n)
- {
- TopDownSplitMerge(A, 0, n, B);
- }
- CopyArray(B[], iBegin, iEnd, A[])
- {
- for(k = iBegin; k < iEnd; k++)
- A[k] = B[k];
- }
- // iBegin is inclusive; iEnd is exclusive (A[iEnd] is not in the set)
- TopDownSplitMerge(A[], iBegin, iEnd, B[])
- {
- if(iEnd - iBegin < 2) // if run size == 1
- return; // consider it sorted
- // recursively split runs into two halves until run size == 1,
- // then merge them and return back up the call chain
- iMiddle = (iEnd + iBegin) / 2; // iMiddle = mid point
- TopDownSplitMerge(A, iBegin, iMiddle, B); // split / merge left half
- TopDownSplitMerge(A, iMiddle, iEnd, B); // split / merge right half
- TopDownMerge(A, iBegin, iMiddle, iEnd, B); // merge the two half runs
- CopyArray(B, iBegin, iEnd, A); // copy the merged runs back to A
- }
- // left half is A[iBegin :iMiddle-1]
- // right half is A[iMiddle:iEnd-1 ]
- TopDownMerge(A[], iBegin, iMiddle, iEnd, B[])
- {
- i0 = iBegin, i1 = iMiddle;
- // While there are elements in the left or right runs
- for (j = iBegin; j < iEnd; j++) {
- // If left run head exists and is <= existing right run head.
- if (i0 < iMiddle && (i1 >= iEnd || A[i0] <= A[i1]))
- B[j] = A[i0];
- i0 = i0 + 1;
- else
- B[j] = A[i1];
- i1 = i1 + 1; }
- }
自下而上实现:
- /* array A[] has the items to sort; array B[] is a work array */
- BottomUpSort(int n, int A[], int B[])
- {
- int width;
- /* Each 1-element run in A is already "sorted". */
- /* Make successively longer sorted runs of length 2, 4, 8, 16... until whole array is sorted. */
- for (width = 1; width < n; width = 2 * width)
- {
- int i;
- /* Array A is full of runs of length width. */
- for (i = 0; i < n; i = i + 2 * width)
- {
- /* Merge two runs: A[i:i+width-1] and A[i+width:i+2*width-1] to B[] */
- /* or copy A[i:n-1] to B[] ( if(i+width >= n) ) */
- BottomUpMerge(A, i, min(i+width, n), min(i+2*width, n), B);
- }
- CopyArray(A, B, n);
- }
- }
- BottomUpMerge(int A[], int iLeft, int iRight, int iEnd, int B[])
- {
- int i0 = iLeft;
- int i1 = iRight;
- int j;
- for (j = iLeft; j < iEnd; j++)
- {
- if (i0 < iRight && (i1 >= iEnd || A[i0] <= A[i1]))
- {
- B[j] = A[i0];
- i0 = i0 + 1;
- }
- else
- {
- B[j] = A[i1];
- i1 = i1 + 1;
- }
- }
- }
2.2 堆排序算法
----------------------------------------
堆排序利用的是数据结构-堆,首先你要对堆结构熟悉,详见:数据结构--堆
堆排序是选择排序种类的一部分,相对于基本的选择算法,它的提升是用到了对数时间优先队列(即堆)而不是线性时间搜索。尽管实际中它比完美实现的快速排序慢,但它有个优点就是最坏情况下时间复杂度是O(nlogn).堆排序是一种 in-place algorithm,但不是稳定的排序。
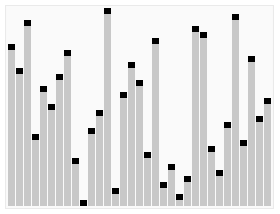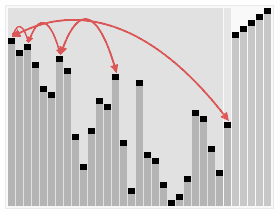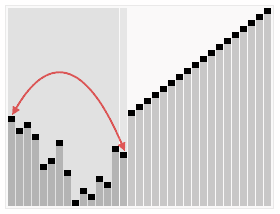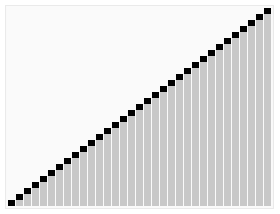
|
|
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance |  |
| Best case performance |  [1] [1] |
| Average case performance | |
| Worst case space complexity |  auxiliary auxiliary |
算法流程:
1. 建立一个最大或最小堆
2. 用根元素与最后一个元素交换位置,将根元素从堆中移除,堆大小减小1。
3. 修复堆,回到上一步,直到堆中不剩元素。
- HEAPSORT(A)
- 1 BUILD-MAX-HEAP(A) //讲数组A转化为堆
- 2 for i ← length[A] downto 2
- 3 do exchange A[1] ↔ A[i] //根元素与最后一个元素交换位置
- 4 heap-size[A] ← heap-size[A] - 1 //数组大小减小1
- 5 MAX-HEAPIFY(A, 1) //修复替换掉根元素A[1]的堆
上面代码中用到的,BUILD-MAX-HEAP(A)和MAX-HEAPIFY(A, 1),我前面的博客数据结构--堆有详细介绍这两算法。
我们假设数组A开始元素顺序为{ 6, 5, 3, 1, 8, 7, 2, 4 },对它进行排序得到从小到大的顺序。
首先执行BUILD-MAX-HEAP(A),将数组A转化为最大堆。如下图:
1. Build the heap
| Heap | newly added element | swap elements |
|---|---|---|
| nil | 6 | |
| 6 | 5 | |
| 6, 5 | 3 | |
| 6, 5, 3 | 1 | |
| 6, 5, 3, 1 | 8 | |
| 6, 5, 3, 1, 8 | 5, 8 | |
| 6, 8, 3, 1, 5 | 6, 8 | |
| 8, 6, 3, 1, 5 | 7 | |
| 8, 6, 3, 1, 5, 7 | 3, 7 | |
| 8, 6, 7, 1, 5, 3 | 2 | |
| 8, 6, 7, 1, 5, 3, 2 | 4 | |
| 8, 6, 7, 1, 5, 3, 2, 4 | 1, 4 | |
| 8, 6, 7, 4, 5, 3, 2, 1 |
2. Sorting.
| Heap | swap elements | delete element | sorted array | details |
|---|---|---|---|---|
| 8, 6, 7, 4, 5, 3, 2, 1 | 8, 1 | swap 8 and 1 in order to delete 8 from heap | ||
| 1, 6, 7, 4, 5, 3, 2, 8 | 8 | delete 8 from heap and add to sorted array | ||
| 1, 6, 7, 4, 5, 3, 2 | 1, 7 | 8 | swap 1 and 7 as they are not in order in the heap | |
| 7, 6, 1, 4, 5, 3, 2 | 1, 3 | 8 | swap 1 and 3 as they are not in order in the heap | |
| 7, 6, 3, 4, 5, 1, 2 | 7, 2 | 8 | swap 7 and 2 in order to delete 7 from heap | |
| 2, 6, 3, 4, 5, 1, 7 | 7 | 8 | delete 7 from heap and add to sorted array | |
| 2, 6, 3, 4, 5, 1 | 2, 6 | 7, 8 | swap 2 and 6 as they are not in order in the heap | |
| 6, 2, 3, 4, 5, 1 | 2, 5 | 7, 8 | swap 2 and 5 as they are not in order in the heap | |
| 6, 5, 3, 4, 2, 1 | 6, 1 | 7, 8 | swap 6 and 1 in order to delete 6 from heap | |
| 1, 5, 3, 4, 2, 6 | 6 | 7, 8 | delete 6 from heap and add to sorted array | |
| 1, 5, 3, 4, 2 | 1, 5 | 6, 7, 8 | swap 1 and 5 as they are not in order in the heap | |
| 5, 1, 3, 4, 2 | 1, 4 | 6, 7, 8 | swap 1 and 4 as they are not in order in the heap | |
| 5, 4, 3, 1, 2 | 5, 2 | 6, 7, 8 | swap 5 and 2 in order to delete 5 from heap | |
| 2, 4, 3, 1, 5 | 5 | 6, 7, 8 | delete 5 from heap and add to sorted array | |
| 2, 4, 3, 1 | 2, 4 | 5, 6, 7, 8 | swap 2 and 4 as they are not in order in the heap | |
| 4, 2, 3, 1 | 4, 1 | 5, 6, 7, 8 | swap 4 and 1 in order to delete 4 from heap | |
| 1, 2, 3, 4 | 4 | 5, 6, 7, 8 | delete 4 from heap and add to sorted array | |
| 1, 2, 3 | 1, 3 | 4, 5, 6, 7, 8 | swap 1 and 3 as they are not in order in the heap | |
| 3, 2, 1 | 3, 1 | 4, 5, 6, 7, 8 | swap 3 and 1 in order to delete 3 from heap | |
| 1, 2, 3 | 3 | 4, 5, 6, 7, 8 | delete 3 from heap and add to sorted array | |
| 1, 2 | 1, 2 | 3, 4, 5, 6, 7, 8 | swap 1 and 2 as they are not in order in the heap | |
| 2, 1 | 2, 1 | 3, 4, 5, 6, 7, 8 | swap 2 and 1 in order to delete 2 from heap | |
| 1, 2 | 2 | 3, 4, 5, 6, 7, 8 | delete 2 from heap and add to sorted array | |
| 1 | 1 | 2, 3, 4, 5, 6, 7, 8 | delete 1 from heap and add to sorted array | |
| 1, 2, 3, 4, 5, 6, 7, 8 | completed |

下图中是堆最大堆进行排序的行为。

2.3 快速排序算法
--------------------------------------------------
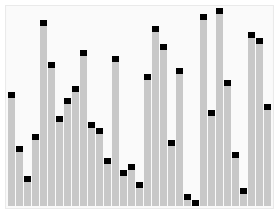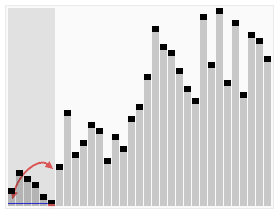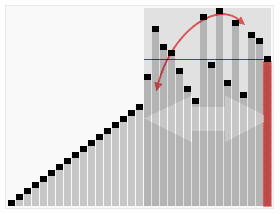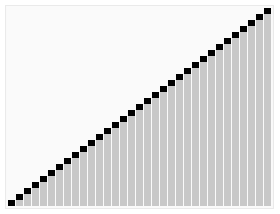
Visualization of the quicksort algorithm. The horizontal lines are pivot values.
|
|
| Class | Sorting algorithm |
|---|---|
| Worst case performance | O(n2) |
| Best case performance | O(n log n) (simple partition) or O(n) (three-way partition and equal keys) |
| Average case performance | O(n log n) |
| Worst case space complexity | O(n) auxiliary (naive) O(log n) auxiliary |
快速排序(类似于归并算法)是一种分而治之算法。首先它将列表分为两个更小的子列表:一个大一个小。然后递归排序这些子列表。下面就用分而治之的方法来排序子数组A[p...r];
步骤:
Divide:从列表中取一个元素作为支点,将数组分为A[p‥q - 1] andA[q + 1‥r] ,A[p ‥ q - 1]中每一个元素都小于A[q] , 而A[q + 1 ‥ r]中每个元素都大于A[q].计算出支点实际存在数组中的位置,即q的值就是PARTITION操作。
Conquer:通过递归的方法对两个数组进行排序
Combine:因为子数组是原地处理的(即in-place),所以不需要合并他们,A[p....r]已经是排好序的。
下面是快速排序的过程伪代码:
- <strong><span style="color:#cc33cc;">QUICKSORT(A, p, r)span>strong>
- 1 if p < r
- 2 then q ← PARTITION(A, p, r)
- 3 QUICKSORT(A, p, q - 1)
- 4 QUICKSORT(A, q + 1, r)
上面的代码中用到了PARTITION(A,p,r)操作,这个操作是快速排序的核心算法。 下面我们就针对它来详解。
首先看伪代码:
- <strong><span style="color:#cc33cc;">PARTITION(A, p, r)span>strong>
- 1 x ← A[r]
- 2 i ← p - 1
- 3 for j ← p to r - 1
- 4 do if A[j] ≤ x
- 5 then i ← i + 1
- 6 exchange A[i] ↔ A[j]
- 7 exchange A[i + 1] ↔ A[r]
- 8 return i + 1

简单介绍下,i是两数组分隔的位置,而j是遍历时的索引。当找到小于A[r]的数时,则执行i++.
而PARTITION算法的返回值是i+1,即支点A[r]所处位置。
这里我们了解了什么是PARTITION操作,实质上他就是找到支点所处数组中的位置。
快速排序性能:
快速排序的性能取决于PARTITION操作,它是否是平衡操作,即能否将数组分为两个大小差不多的数组。如果他分配不均的话,就变成了插入排序。
最坏情况:
最坏的情况就是每次都是不平衡分配,使得一个拥有n-1个元素,一个则含有0个元素。我们知道PARTITION操作的时间复杂度为O(n),而不平均分配的递归会是
T(n) = T(n - 1) + T(0) + Θ(n)
= T(n - 1) + Θ(n)
这样会使得时间复杂度变为O(n^2).跟插入排序一样,而且插入排序在排好序的数组运行时间复杂度为O(n).
最好情况:
每次分配都是一个大小为n/2,另一个为n/2-1。这样递归式变为了
T (n)≤ 2T (n/2) +Θ(n)
这样的话,时间复杂度就是O(nlgn)
平均情况:
时间复杂度也是O(nlgn).算法导论中有详细证明,这里我就举个例子说明下
假设每次分配都是9/10和1/10,那么递归式就是
T(n)≤T (9n/10) +T (n/10) +O(n) 由下图我们可以知道时间复杂度依然是O(nlgn)

3. 冒泡排序和变体类别
--------------------------------------------------------
这种类别的算法在实际中很少使用到,因为效率低下,但在理论教学中常常提到。
3.1 冒泡排序
----------------------------------------------------------
 |
|
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | 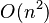 |
| Best case performance | 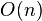 |
| Average case performance | |
| Worst case space complexity | auxiliary |
算法流程:简单概括就是每次找到序列中最大或最小的元素排到最后面去,循环知道每个元素都处于正确位置。如下图:

- for(int x=0; x<n; x++)
- {
- for(int y=0; y<n-1; y++)
- {
- if(array[y]>array[y+1])
- {
- int temp = array[y+1];
- array[y+1] = array[y];
- array[y] = temp;
- }
- }
- }

3.2 希尔排序
-------------------------------------------------------------------
希尔排序是in-place算法,但不是稳定的。
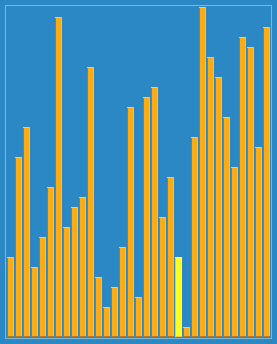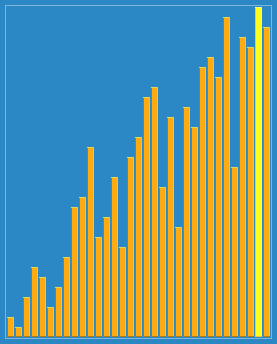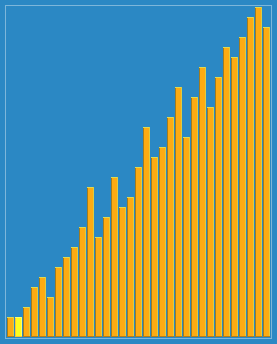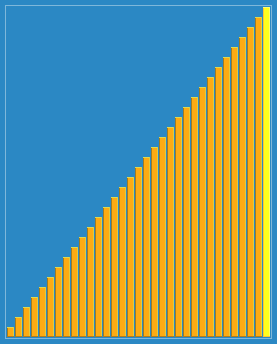 Shellsort with gaps 23, 10, 4, 1 in action. |
|
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | O(n2) |
| Best case performance | O(n log n) |
| Average case performance | depends on gap sequence |
| Worst case space complexity | О(n) total, O(1) auxiliary |
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2

如上图我们去d1=5,d2=3,d3=1
d=5时,分组为 (a1, a6, a11), (a2, a7, a12), (a3, a8), (a4, a9), (a5, a10),对组内的元素进行分别插入排序,得到第二排数组
d=3时,分组为(a1, a4, a7, a10), (a2, a5, a8, a11), (a3, a6, a9, a12),对其分组插入排序,得到第三排数组。
d=1时,分组为 (a1,..., a12),进行插入排序,得到结果。
d的取值
这里你可能会有疑惑,那我们写程序的时候,对于d的值应该怎样取呢?
一般情况下,第一次去n/2,第二次取b/2/2....这样做的最坏时间复杂度为O(n^2).但wikipedia上有一些更优秀的取值,可以改善最坏情况下的时间复杂度,如下表:
| General term (k ≥ 1) | Concrete gaps | Worst-case time complexity |
Author and year of publication |
|---|---|---|---|
| Shell, 1959[2] | |||
 |
Frank & Lazarus, 1960[6] | ||
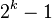 |
|
Hibbard, 1963[7] | |
|
Papernov & Stasevich, 1965[8] | ||
successive numbers of the form  |
 |
Pratt, 1971[9] | |
|
Knuth, 1973[1] |
希尔排序的时间性能优于直接插入排序的原因:
- 当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
- 当n值较小时,n和n2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(n2)差别不大。
- 在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
- void shellsort2(int a[], int n)
- {
- int j, gap;
- for (gap = n / 2; gap > 0; gap /= 2)
- for (j = gap; j < n; j++)//从数组第gap个元素开始
- if (a[j] < a[j - gap])//每个元素与自己组内的数据进行直接插入排序
- {
- int temp = a[j];
- int k = j - gap;
- while (k >= 0 && a[k] > temp)
- {
- a[k + gap] = a[k];
- k -= gap;
- }
- a[k + gap] = temp;
- }
- }
3.3 梳排序
 |
|
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | |
| Best case performance | |
| Average case performance | |
| Worst case space complexity | |
待排数组长度为8,而8÷1.3=6,则比较8和2,4和1,并做交换
[8 4 3 7 6 5 2 1]
[8 4 3 7 6 5 2 1]
交换后的结果为
[2 1 3 7 6 5 8 4]
第二次循环,更新间距为6÷1.3=4,比较2和6,1和5,3和8,7和4
[2 1 3 7 6 5 8 4]
[2 1 3 7 6 5 8 4]
[2 1 3 7 6 5 8 4]
[2 1 3 7 6 5 8 4]
只有7和4需要交换,交换后的结果为
[2 1 3 4 6 5 8 7]
第三次循环,更新距离为3,没有交换
第四次循环,更新距离为2,没有交换
第五次循环,更新距离为1,三处交换
[2 1 3 4 6 5 8 7]
[2 1 3 4 6 5 8 7]
[2 1 3 4 6 5 8 7]
三处交换后的结果为[1 2 3 4 5 6 7 8]
交换后排序结束,顺序输出即可得到[1 2 3 4 5 6 7 8]
- void comb_sort(int *input, size_t size) {
- const float shrink = 1.3f;
- int swap;
- size_t i, gap = size;
- bool swapped = false;
- while ((gap > 1) || swapped) {
- if (gap > 1) {
- gap = (size_t)((float)gap / shrink);
- }
- swapped = false;
- for (i = 0; gap + i < size; ++i) {
- if (input[i] - input[i + gap] > 0) {
- swap = input[i];
- input[i] = input[i + gap];
- input[i + gap] = swap;
- swapped = true;
- }
- }
- }
- }
4. 线性时间的排序
--------------------------------------------------
4.1 计数排序
---------------------------------------------
计数排序不是基于比较的排序算法,它的优势在于对一定范围内(小范围)的整数排序时,它的复杂度为O(n+k),快于任何比较算法。
算法步骤:
我们假设输入的数组A[1....n],数组长度length[A]=n。此时我们要实现它的排序还需要两个而外的数组。
数组B[1...n],用于存储排序后的结果
数组C[0...k],k代表着数组A的的元素都属于0--k
配合下图理解:

(a): 数组C分别记录数组A中0,2,3,5出现的次数。
(b): 对 a图中的数组C进行c[i] = c[i] + c[i-1];得出b图中的结果。
(c): 从数组A中取元素A[8]=3,因为3在数组C中记录显示,小于等于3的元素个数为7(包含他自己),所以将3存入有序数组B中的索引为7.
(d): 同理取出A[7]=0.
(e): 取出A[6]=3
...........
(f): 最后取出A[1]=2,存入对应的B中。得出最终结果。
实现的伪代码
- COUNTING-SORT(A, B, k)
- 1 for i ← 0 to k
- 2 do C[i] ← 0
- 3 for j ← 1 to length[A]
- 4 do C[A[j]] ← C[A[j]] + 1
- 5 ▹ C[i] now contains the number of elements equal to i.
- 6 for i ← 1 to k
- 7 do C[i] ← C[i] + C[i - 1]
- 8 ▹ C[i] now contains the number of elements less than or equal to i.
- 9 for j ← length[A] downto 1
- 10 do B[C[A[j]]] ← A[j]
- public class CountSort{
- public static void main(String []args){
- //排序的数组
- int a[] = {100, 93, 97, 92, 96, 99, 92, 89, 93, 97, 90, 94, 92, 95};
- int b[] = countSort(a);
- for(int i : b){
- System.out.print(i + " ");
- }
- System.out.println();
- }
- public static int[] countSort(int []a){
- int b[] = new int[a.length];
- int max = a[0], min = a[0];
- for(int i : a){
- if(i > max){
- max = i;
- }
- if(i < min){
- min = i;
- }
- }
- //这里k的大小是要排序的数组中,元素大小的极值差+1
- int k = max - min + 1;
- int c[] = new int[k];
- for(int i = 0; i < a.length; ++i){
- c[a[i]-min] += 1;//优化过的地方,减小了数组c的大小
- }
- for(int i = 1; i < c.length; ++i){
- c[i] = c[i] + c[i-1];
- }
- for(int i = a.length-1; i >= 0; --i){
- b[--c[a[i]-min]] = a[i];//按存取的方式取出c的元素
- }
- return b;
- }
- }
4.2 桶排序
-----------------------------------------------------
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | |
| Average case performance | |
| Worst case space complexity |  |
- 桶排序假设待排序的一组数统一的分布在一个范围中,并将这一范围划分成几个 子范围,也就是桶。
- 将待排序的一组数,分档规入这些子桶。并将桶中的数据进行排序。
- 将各个桶中的数据有序的合并起来。

- BUCKET-SORT(A)
- 1 n ← length[A]
- 2 for i ← 1 to n
- 3 do insert A[i] into list B[⌊n A[i]⌋]
- 4 for i ← 0 to n - 1
- 5 do sort list B[i] with insertion sort
- 6 concatenate the lists B[0], B[1], . . ., B[n - 1] together in order
4.3 基数排序
---------------------------------------------------------
| Class | Sorting algorithm |
|---|---|
| Data structure | Array |
| Worst case performance | |
| Worst case space complexity |  |
1 最低位优先(Least Significant Digit first)法,简称LSD法
算法流程:
- Take the least significant digit (or group of bits, both being examples of radices) of each key.
- Group the keys based on that digit, but otherwise keep the original order of keys. (This is what makes the LSD radix sort a stable sort).
- Repeat the grouping process with each more significant digit.
The sort in step 2 is usually done using bucket sort or counting sort, which are efficient in this case since there are usually only a small number of digits.这里我就不翻译了(英语比较捉急),直接用wikipedia上面的,怕翻译的捉急。因为我发现很多人民间版的定义都有错,不得不承认wiki是个好东西。我就简单说下大致意思:
1. 得到最低位的数值,即个位数的数值
2. 对提取出来的数值进行排序。(可以用计数排序或桶排序)
3. 重复上面的操作,知道遍历每一个数位。
实例:例如个位,个位都是[0-10)范围内的。先对他进行归类,把小的放上面,大的放下面,然后个位排好了,在来看10位,我们也这样把小的放上面,大的放下面,依次内推,直到最高位排好。那么不就排好了吗?我们只需要做d(基数个数)的循环就可以了。时间复杂度相当于O(d * n) 因为d为常量,例如5位数,d就是5.所以近似为O(n)的时间复杂度。这次自己写个案例:
| 最初的数据 |
排好个位的数据 |
排好十位的数据 |
排好百位的数据 |
| 981 |
981 |
725 |
129 |
| 387 |
753 |
129 |
387 |
| 753 |
955 |
753 |
456 |
| 129 |
725 |
955 |
725 |
| 955 |
456 |
456 |
753 |
| 725 |
387 |
981 |
955 |
| 456 |
129 |
387 |
981 |
又如下图:

c代码:
- #include
- #define MAX 20
- #define SHOWPASS
- #define BASE 10
- void print(int *a, int n)
- {
- int i;
- for (i = 0; i < n; i++)
- printf("%d\t", a[i]);
- }
- void radixsort(int *a, int n)
- {
- int i, b[MAX], m = a[0], exp = 1;
- //Get the greatest value in the array a and assign it to m
- for (i = 1; i < n; i++)
- {
- if (a[i] > m)
- m = a[i];
- }
- //Loop until exp is bigger than the largest number
- while (m / exp > 0)
- {
- int bucket[BASE] = { 0 };
- //Count the number of keys that will go into each bucket
- for (i = 0; i < n; i++)
- bucket[(a[i] / exp) % BASE]++;
- //Add the count of the previous buckets to acquire the indexes after the end of each bucket location in the array
- for (i = 1; i < BASE; i++)
- bucket[i] += bucket[i - 1];
- //Starting at the end of the list, get the index corresponding to the a[i]'s key, decrement it, and use it to place a[i] into array b.
- for (i = n - 1; i >= 0; i--)
- b[--bucket[(a[i] / exp) % BASE]] = a[i];
- //Copy array b to array a
- for (i = 0; i < n; i++)
- a[i] = b[i];
- //Multiply exp by the BASE to get the next group of keys
- exp *= BASE;
- #ifdef SHOWPASS
- printf("\nPASS : ");
- print(a, n);
- #endif
- }
- }
- int main()
- {
- int arr[MAX];
- int i, n;
- printf("Enter total elements (n <= %d) : ", MAX);
- scanf("%d", &n);
- n = n < MAX ? n : MAX;
- printf("Enter %d Elements : ", n);
- for (i = 0; i < n; i++)
- scanf("%d", &arr[i]);
- printf("\nARRAY : ");
- print(&arr[0], n);
- radixsort(&arr[0], n);
- printf("\nSORTED : ");
- print(&arr[0], n);
- printf("\n");
- return 0;
- }
算法步骤:
A recursively subdividing MSD radix sort algorithm works as follows:
- Take the most significant digit of each key.
- Sort the list of elements based on that digit, grouping elements with the same digit into one bucket.
- Recursively sort each bucket, starting with the next digit to the right.
- Concatenate the buckets together in order.
这时候,就是递归的思想起作用了!既然桶外有序,我们就不管桶外了,关注处理桶内的数据。从次高位开始,再建立10个桶,然后把数据放到桶里,按第一次的方式来处理,直到处理到最低位!
MSL的代码稍微有点复杂,要用到递归!
- #include
- #include
- #include
- using namespace std;
- struct Node{
- int key;
- struct Node *next;
- Node(int _key){
- key=_key;next=NULL;
- }
- };
- void sort(int *a,int s,int n,int high){//把数组a中的数据[s,e)进行排序
- Node *ibuck[10],*itail[10],*p;
- int i,kth,low,num;
- if(high==1)return;
- low=high/10;
- memset(ibuck,0,sizeof(ibuck));
- for(i=s;i
- kth=(a[i]%high)/low;//取出序列中的数,根据位数放置到对应的桶中
- p=new Node(a[i]);//创建新结点
- //把数放到对应的桶中 这里一定要接到末尾,而不能从头结点插入
- ibuck[kth]!=NULL ? itail[kth]->next=p,itail[kth]=p:ibuck[kth]=p,itail[kth]=p;
- }
- for(i=0;s
- num=0;
- while(ibuck[i]!=NULL){
- a[s++]=ibuck[i]->key;
- num++;
- p=ibuck[i],ibuck[i]=ibuck[i]->next,delete p;//收回动态开辟的空间
- }
- if(num>1)
- sort(a,s-num,num,high/10); //这个地方我处理了好久
- }
- }
- void base_sort_MSD(int *a,int n){
- int Max,high,i;
- for(Max=a[0],i=1;i
- for(high=1;Max/high>0;high*=10);
- sort(a,0,n,high);
- }
- int main(){
- int n=10;
- int data[]={1000,50,80000,81000,3,26,467,6987,10953,2354};
- base_sort_MSD(data,n);
- for(int i=0;i
- printf("%d ",data[i]);
- }
我觉得这个人总结的不错,我后面也借鉴了一点他的 。 http://sbp810050504.blog.51cto.com/2799422/1039725 。
留下一个问题:一个文件中存着大量的值在0-1精确到小数点后10位的书然后怎么排好?
好吧,这11种排序算法终于弄完了,不过还有很多没知识点没总结,如他们之间的区别等。这个我之后肯定会补上。现在感觉还理解的不透彻。毕竟刚刚深入的去研究,如果文中又发现错误的地方,希望提出来。
这篇博客中我尽量找的伪代码实现,除非那些比较难理解的伪代码,因为我觉得这是个理论系列,看完之后必须自己去实现一遍,不然等于白看,如果你觉得有些根据伪代码实现不了的,可以到网上找各种语言的代码。
最后推荐一个人的算法专栏:白话经典算法 。里面虽然讲的东西不多,但很多作者独到的见解,而且写的比较容易理解,不像我的。。嗨,以后努力改进。