西瓜书《机器学习》第二章部分课后题
目录
- 题目2.1
- 题目2.2
- 题目2.3
- 题目2.4
- 题目2.5
- 题目2.6
- Acknowledge
题目2.1
数据集包含1000个样本,其中500个正例、500个反例,将其划分为包含70%样本的训练集和30%样本的测试集用于留出法评估,试估算公有多少种划分方式。
训练集和测试集的划分要尽可能保持数据分布的一致性,按题目要求,需要抽700个训练样本,300个测试样本,正例与反例的比例为 1 : 1 1:1 1:1,即抽350个正例和350个反例组成700个训练样本,共有 C 500 350 × C 500 350 C^{350}_{500} \times C^{350}_{500} C500350×C500350种划分方法。
题目若改成600个正例、400个反例,其比例为 3 : 2 3:2 3:2,则抽 700 × 3 / 5 = 420 700 \times 3/5 = 420 700×3/5=420个正例和 700 × 2 / 5 = 280 700 \times 2 / 5 = 280 700×2/5=280个反例组成700个训练样本,剩下180个正例和120个反例组成300个测试赝本,比例同样是 3 : 2 3:2 3:2。
题目2.2
数据集包含100个样本,其中正、反例各一半,假定学习算法所产生的模型是将新样本预测为训练样本较多的类别(训练样本数相同时进行随机猜测),试给出用10折交叉验证法和留一法分别对错误率进行评估所得的结果。
- 10折交叉验证法:每次验证,训练样本中的正例和反例都各占一半,此时模型对新样本的预测为随机猜测,期望错误率为0.5
- 留一法:若取1个正例作为测试样本,则训练样本中正例与反例的比例为 49 : 50 49:50 49:50,此时模型对测试样本的预测结果为反例,错误率为1;若取1个反例作为测试样本,则训练样本中正例与反例的比例为 50 : 49 50:49 50:49,此时模型对测试样本的预测结果为正例,错误率为1。综上所述,期望错误率为1。
题目2.3
若学习器A的 F 1 F_1 F1值比学习器B高,试析A的BEP值是否也比B高。
直接上代码跑数据,假定有5个样本,类别标签分别为:反例、正例、正例、反例、正例,
def perm(array):
if(len(array)<=1):
return [array]
r=[]
for i in range(len(array)):
s=array[:i] + array[i+1:]
p=perm(s)
for x in p:
r.append(array[i:i+1] + x)
return r
array = [0, 1, 2, 3, 4]
label = [0, 1, 1, 0, 1]
# machines = perm(array)
machines = [[4, 3, 2, 0, 1],
[4, 3, 2, 1, 0]]
# mlist是一个学习器
for mlist in machines:
# 依次将学习器mlist中的前i个结果预测为正例
for i in range(len(mlist)):
tempLabel = [0] * len(label)
for j in range(0, i + 1):
tempLabel[mlist[j]] = 1
TP = 0
FN = 0
FP = 0
for m in mlist:
if label[m] == tempLabel[m] and label[m] == 1:
TP = TP + 1
if label[m] == 1 and tempLabel[m] == 0:
FN = FN + 1
if label[m] == 0 and tempLabel[m] == 1:
FP = FP + 1
P = 1.0 * TP / (TP + FP)
R = 1.0 * TP / (TP + FN)
F1 = 0
if P + R != 0:
F1 = 2 * P * R / (P + R)
print(P, '\t', R, '\t', F1)
print('\n')
观测数据,取最后2个学习器记为B、A,可以看到,A的P-R曲线“包住”B的P-R曲线,两个学习器的BEP值相同,但A的某个 F 1 F_1 F1值高于B的某个 F 1 F_1 F1值,
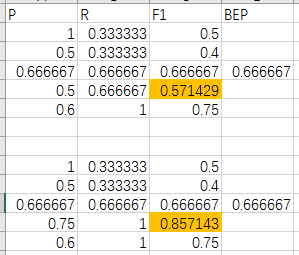
从而得知,若学习器A的 F 1 F_1 F1值比学习器B高,A的BEP值不一定比B高。
题目2.4
试述真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)之间的联系。
若认真实践了题目2.3,接下来做题目2.4会比较有感觉。现根据学习器的预测结果对样例进行排序,排在前面的是学习器认为“最可能”是正例的样本,排在最后面的则是学习器认为“最不可能”是正例的样本。
观察P-R图,查全率和查准率是一对“矛盾”的度量。为了提升查准率,就必须把筛选条件设置得更加严格以尽量排除反例(即把阈值调小),那么排序排在反例后面的正例就会被pass,此时查全率下降;相反,为了提升查全率,就必须放松筛选条件(即把阈值调大),那么排序排在阈值前面的反例就会被预测为正例,此时查准率下降。
观察查全率与真正例率,可知两者相等。
观察ROC曲线图,真正例率与假正例率呈现“单调递增”关系。当调大阈值时,有可能使得FP增大且TN减小,假正例率变大,而此时,亦有可能TP增大且FN减小,真正例率变大。
题目2.5
试证明式(2.22)。
先不考虑 f ( x + ) = f ( x − ) f(\bm{x}^+) = f(\bm{x}^-) f(x+)=f(x−)的情况,观察式(2.20),可简写为
AUC = ∑ i = 1 m − 1 ( x i + 1 − x i ) ⋅ y i , \text{AUC} = \sum^{m-1}_{i=1} (x_{i+1} - x_i) \cdot y_i, AUC=i=1∑m−1(xi+1−xi)⋅yi,
接着将ROC曲线图横轴、纵轴各乘以 m − m^- m−、 m + m^+ m+,发现 x i + 1 − x i = { 0 , 1 } x_{i+1} - x_i = \{ 0, 1 \} xi+1−xi={0,1},仔细观察ROC曲线图,当 x i + 1 − x i = 1 x_{i+1} - x_i = 1 xi+1−xi=1时,点 ( x i + 1 , y i + 1 ) (x_{i+1}, y_{i+1}) (xi+1,yi+1)恰巧是一个反例样本,排序排在它前面的共有 y i y_i yi个正例样本。举一个例子,
共有10个样本,根据学习器的预测结果对样本进行排序,得到 [ 1 , 1 , 1 , 0 , 1 , 0 , 1 , 0 , 0 , 0 ] [1, 1, 1, 0, 1, 0, 1, 0, 0, 0] [1,1,1,0,1,0,1,0,0,0],其ROC曲线图如下,

红色点前面有3个正例样本,蓝色点前面有4个正例样本,绿色点前面有5个正例样本(后面的点依次类推)。
那么,式(2.20)可改写成
AUC = 1 m + m − ∑ x − ∈ D − ∑ x + ∈ D + I ( f ( x + ) > f ( x − ) ) , \text{AUC} = \frac{1}{m^+ m^-} \sum_{\bm{x}^- \in D^{-}} \sum_{\bm{x}^+ \in D^{+}} \mathbb{I} \big( f(\bm{x}^+) > f(\bm{x}^-) \big), AUC=m+m−1x−∈D−∑x+∈D+∑I(f(x+)>f(x−)),
注意两个求和符号的顺序,求和符号部分就是统计有颜色的点前面的正例样本个数,个数乘以1就是那一列的面积,而
1 m + ⋅ 1 m − \frac{1}{m^+} \cdot \frac{1}{m^-} m+1⋅m−1
则是做归一化处理。
同样,计算 ℓ r a n k \ell_{rank} ℓrank时不考虑 f ( x + ) = f ( x − ) f(\bm{x}^+) = f(\bm{x}^-) f(x+)=f(x−)的情况,有颜色的点的“损失”为排序排在该点后面正例样本个数,有
ℓ r a n k = 1 m + m − ∑ x − ∈ D − ∑ x + ∈ D + I ( f ( x + ) < f ( x − ) ) = 1 m + m − ∑ x + ∈ D + ∑ x − ∈ D − I ( f ( x + ) < f ( x − ) ) = ∑ i = 1 m − 1 ( x i + 1 − x i ) ⋅ ( 1 − y i ) , \begin{aligned} \ell_{rank} &= \frac{1}{m^+ m^-} \sum_{\bm{x}^- \in D^{-}} \sum_{\bm{x}^+ \in D^{+}} \mathbb{I} \big( f(\bm{x}^+) < f(\bm{x}^-) \big) \\ &= \frac{1}{m^+ m^-} \sum_{\bm{x}^+ \in D^{+}} \sum_{\bm{x}^- \in D^{-}} \mathbb{I} \big( f(\bm{x}^+) < f(\bm{x}^-) \big) \\ &= \sum^{m-1}_{i=1} (x_{i+1} - x_i) \cdot (1-y_i), \end{aligned} ℓrank=m+m−1x−∈D−∑x+∈D+∑I(f(x+)<f(x−))=m+m−1x+∈D+∑x−∈D−∑I(f(x+)<f(x−))=i=1∑m−1(xi+1−xi)⋅(1−yi),
易推 AUC = 1 − ℓ r a n k \text{AUC} = 1 - \ell_{rank} AUC=1−ℓrank。
接下来考虑 f ( x + ) = f ( x − ) f(\bm{x}^+) = f(\bm{x}^-) f(x+)=f(x−)的情况,
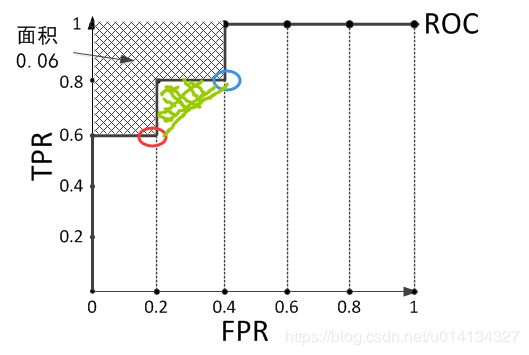
假设红色点与蓝色点的预测值相等,我们记0.5个“罚分”,
1 m + m − ⋅ 1 2 ⋅ I ( f ( x + ) = f ( x − ) ) \frac{1}{m^+ m^-} \cdot \frac{1}{2} \cdot \mathbb{I} \big( f(\bm{x}^+) = f(\bm{x}^-) \big) m+m−1⋅21⋅I(f(x+)=f(x−))
刚好就是上图绿色区域的面积,在式(2.20)的原本形式中,就是求梯形面积。
也可以换一个角度思考,由于 f f f值相等,学习器进行随机预测,蓝色点以0.5概率落在红色点上方(此时 x + \bm{x}^+ x+排在 x − \bm{x}^- x−前面),以0.5概率落在红色点右方(此时 x − \bm{x}^- x−排在 x + \bm{x}^+ x+前面),期望之下则是直接画一条斜线,在计算式(2.21)时就直接添加0.5个“罚分”,注意斜线(折线)都代表了+、-两个样例,所以不妨碍蓝色点之后排在反例之前的正例点个数的统计。
证毕。
题目2.6
试述错误率与ROC曲线的联系。

Acknowledge
题目2.1、题目2.2和题目2.6参考自:https://blog.csdn.net/icefire_tyh/article/details/52065867
感谢@四去六进一
题目2.3的ROC曲线形状理解参考自:
https://www.cnblogs.com/gczr/p/10137063.html
感谢@光彩照人
(曲线不一定经过 ( 0 , 1 ) (0, 1) (0,1)和 ( 1 , 0 ) (1, 0) (1,0))
题目2.4参考自:
https://www.jianshu.com/p/66ab21e08dd0
感谢@AI和金融模型
题目2.5的理解参考自:
https://blog.csdn.net/cherrylvlei/article/details/52958720
感谢@对半独白