论文阅读及代码运行--Free-Form Image Inpainting with Gated Convolution
1、前言
从传统的图像修复方法,如经典算法PatchMach,到基于CNN的图像修复方法,修复的结果越来越更加真实和合理,如GL。但是图像修复本身就是一个高度病态的问题,有太多的主观性。之前修复的方法,更多的是解决规则的中心缺失图像修复,而针对不规则图像的缺失解决办法较少,即使是CA模型也是规则缺失图像的修复。
于是NVIDIA首次提出了使用部分卷积PartialConv来修复不规则孔缺失的图像,其修复的结果不错。但是还是存在问题。
文献:
- CA 2018 CVPR Generative Image Inpainting with Contextual Attention.
- PartialConv 2018 ECCV Image Inpainting for Irregular Holes Using Partial Convolutions.
- GL 2017 TOG Globally and locally consistent image completion.
- GatedConv 2019 ICCV Free-Form Image Inpainting with Gated Convolution
github:
- GatedConv:code
2、GatedConv 论文阅读
2.1、摘要
我们提出了一个生成图像修复系统,用以完成具有自由形态掩码遮挡以及用户指导的图像。所提出的门控卷积解决了普通卷积将所有的像素视为有效像素的问题,通过为所有层中的每个空间位置的每个通道提供一个可学习的动态特征选择机制来泛化部分卷积。 此外,提出了SN-PatchGAN,谱规范化(spectral-normalized)用于稳定训练,加速训练速度,并且解决了全局和局部判别器不适用于自由形状的掩码问题。
2.2、引言
图像修复(图像补全或图像空洞填充)是在缺失区域综合替代图像内容,使修改在视觉和语义上的都是一项正确的任务。可以用于移除分散注意力的物体或修改照片中不需要的区域。还可以扩展到图像/视频不剪切(un-cropping)、旋转、拼接、重新定位(re-targeting)、重新组合(re-compression)、超分辨率、协调(harmonization )和许多其它任务。
在计算机视觉中,存在两种广泛的图像修复方法:1)使用低阶图像特征的块(patch)匹配,2)使用卷积神经网络的前馈生成模型。
第一种方法可以合成看似合理的平稳纹理(stationary textures),但在非平稳的情况下,如复杂的场景、人脸和物体,往往会出现严重的问题。第二种方法可以从大规模数据集中学习到的语义,以端到端的方式合成非平稳图像中的内容。
然后,基于普通卷积的深度生成模型在图像填充上是自然的高度病态的,因为空间卷积过滤器视所有的输入像素和特征一样有效。对于图像填充来说,每一层的输入是由空洞外的有效像素/特征和掩码区域的无效像素组成的。普通卷积使用了相同的过滤器,适用于所有有效、无效和混合(列如,那些空洞边界)的像素/特征,在自由形状上的掩码做测试时,导致视觉的伪影(如颜色差异,模糊和孔周围明显的边缘响应)。
为了解决这一局限性,部分卷积(PartialConv),其中卷积被掩蔽归一化,仅以有效像素为条件。基于规则的掩码更新策略,用于更新下一层的有效位置。部分卷积将所有位置视为无效或有效,并用0或1掩码乘以所有层的输入,该掩码可以看做是一个单一的不可学习的特征门通道。
然而,这种假设是有个几个局限性:
- 考虑跨网络不同层的输入空间位置,他们可能包括:
1)输入图像的有效像素,
2)输入图像的掩蔽像素,
3)感受野的神经元没有覆盖到输入图像的有效像素,
4)感受野的神经元覆盖了不同数量的输入图像的有效像素(这些有效的图像像素也可能有不同的相对位置),
5)深层合成的像素。
启发式的将所有的位置归类为无效或有效,会忽略这些重要信息。 - 如果我们拓展到用户指导的图像修复,用户在掩码内提供的稀疏的草图(sparse sketch),这些像素位置应该被视为有效的还是无效的?如何正确地更新下一层的掩码?
- 对于部分卷积,无效的像素将逐层逐渐消失,基于规则的掩码将在深层全部消失。然而,为了合成孔内的像素,这些深层可能还需要知道当前位置是在孔内还是孔外?全一掩码的部分卷积不能提供这样的信息。
作者提出了一种适用于自由形状图像修复的门控卷积算法,它学习每个通道和每个空间位置的动态特征门控机制(例如,内部和外部掩码,rgb通道或用户指导通道)。
2.3、相关工作
相关工作主要介绍了三个方面的知识,分别为:
-
自动图像修复:
1)传统的方法:搜索最相似的块(patch)来填充缺失区域,但是没有考虑全局语义,只能适用于平稳的纹理。此外,还有使用统计的方法来提高修复的结果,但是搜索过程的代价很高。
2)基于CNN的图像修复方法的一个显著优点是能够学习不同语义的自适应图像特征,能够合成更合理的语义内容。CA模型为了捕获远程空间依赖,提出了上下文注意模块,能够从远程空间位置借用信息。但是该方法主要针对大的矩形掩码,在自由形状的掩码很难推广。于是,NVIDIA提出了部分卷积来修复不规则缺失的图像。 -
有指导的图像修复和合成
-
特征级门控
2.4、方法
2.4.1、门控卷积
普通卷积:
在普通卷积层,应用相同的过滤器来生成输出。对于图像分类和目标检测是有意义的,在这些任务中,输入图像的所有像素都是有效的,以滑动窗口的方式提取局部特征。但是对于图像修复来说,训练过程中会导致模糊,并导致视觉上的伪影。
O y , x = ∑ i = − k h ′ k h ′ ∑ j = − k w ′ k w ′ W k h ′ + i , k w ′ + j ⋅ I y + i , x + j O_{y, x}=\sum_{i=-k_{h}^{\prime}}^{k_{h}^{\prime}} \sum_{j=-k_{w}^{\prime}}^{k_{w}^{\prime}} W_{k_{h}^{\prime}+i, k_{w}^{\prime}+j} \cdot I_{y+i, x+j} Oy,x=∑i=−kh′kh′∑j=−kw′kw′Wkh′+i,kw′+j⋅Iy+i,x+j
部分卷积:
采用了掩蔽和重新归一化的步骤,使卷积仅依赖于有效的像素。本质上,部分卷积可以看作是不可学习的单通道特征的硬门控。
O y , x = { ∑ ∑ W ⋅ ( I ⊙ M sum ( M ) ) , if sum ( M ) > 0 0 , otherwise O_{y, x}=\left\{\begin{array}{ll}{\sum\sum W \cdot\left(I \odot \frac{M}{\operatorname{sum}(M)}\right),} & {\text { if } \operatorname{sum}(\mathrm{M})>0} \\ {0,} & {\text { otherwise }}\end{array}\right. Oy,x={∑∑W⋅(I⊙sum(M)M),0, if sum(M)>0 otherwise
门控卷积:
不同于部分卷积的硬门控掩码更新策略,门控卷积是从数据中自动学习软掩码。
Gating y , x = ∑ ∑ W g ⋅ I Feature y , x = ∑ ∑ W f ⋅ I O y , x = ϕ ( Feature y , x ) ⊙ σ ( Gating y , x ) \begin{aligned} \text {Gating}_{y, x} &=\sum \sum W_{g} \cdot I \\ \text {Feature}_{y, x} &=\sum \sum W_{f} \cdot I \\ O_{y, x} &=\phi\left(\text {Feature}_{y, x}\right) \odot \sigma\left(\text {Gating}_{y, x}\right) \end{aligned} Gatingy,xFeaturey,xOy,x=∑∑Wg⋅I=∑∑Wf⋅I=ϕ(Featurey,x)⊙σ(Gatingy,x)

提出的门控卷积学习每个通道和每个空间位置的动态特征选择机制。有趣的是,通过对中间门控值的可视化可以看出,它不仅可以根据背景、掩模、草图来选择特征,还可以在某些通道中考虑语义分割。即使在较深的层中,门控卷积也可以学习在不同的通道中突出掩蔽区域和草图信息,从而更好地生成修复结果。
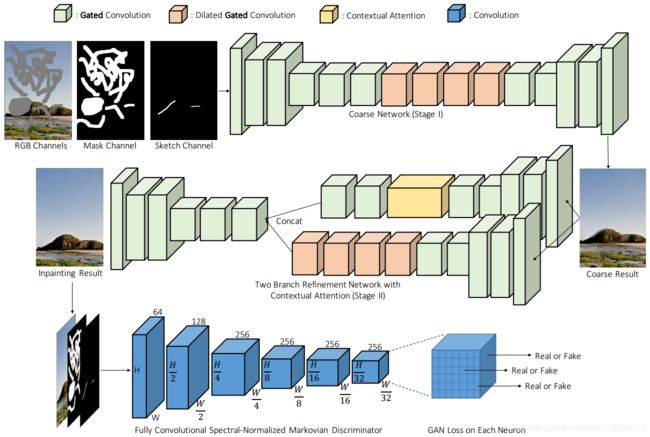
2.4.2、SN-PatchGAN
如上图所示,SN-PatchGAN使用了6个步长卷积(k=5, s=2)以捕获Markovian块的特征统计信息。值得注意的是,在我们的训练设置中,输出图中每个神经元的感受野可以覆盖整个输入图像,因此不需要全局鉴别器。
损失函数
1)铰链损失
L G = − E z ∼ P z ( z ) [ D s n ( G ( z ) ) ] \mathcal{L}_{G}=-\mathbb{E}_{z \sim \mathbb{P}_{z}}(z)\left[D^{s n}(G(z))\right] LG=−Ez∼Pz(z)[Dsn(G(z))]
L D s n = E x ∼ P data ( x ) [ Re L U ( 1 − D s n ( x ) ) ] + E z ∼ P z ( z ) [ Re L U ( 1 + D s n ( G ( z ) ) ) ] \mathcal{L}_{D^{s n}}=\mathbb{E}_{x \sim \mathbb{P}_{\text {data}}(x)}\left[\operatorname{Re} L U\left(\mathbb{1}-D^{s n}(x)\right)\right]+\mathbb{E}_{z \sim \mathbb{P}_{z}(z)}\left[\operatorname{Re} L U\left(\mathbb{1}+D^{s n}(G(z))\right)\right] LDsn=Ex∼Pdata(x)[ReLU(1−Dsn(x))]+Ez∼Pz(z)[ReLU(1+Dsn(G(z)))]
由于类似的块级信息已经在PatchGAN中进行了编码,因此不使用感知损失。不同于PartialConv的6个损失函数,GatedConv使用了 ℓ 1 \ell_{1} ℓ1重构损失以及SN-PatchGAN损失,舍弃了复杂的多超参数,该超参数的比列为1:1。
2.4.3、整体架构
笔者注:GatedConv采用了和CA模型类似的粗细两级网络,粗网络先修复一个粗略的结果,细网络再更加精准的修复,将一个修复任务分成两个任务,而不是一次性修复。GatedConv未中ICCV之前,细网络是单分支的,后来作者修改成了两路分支。虽然这样改善了修复结果,但是两阶段修复存在一个问题,需要消耗大量的计算资源,于是PEPSI(2019 CVPR)提出了并行的编解码结构来解决这个问题。
GatedConv采用的编解码结构,而不是使用PartialConv的U-Net,作者发现U-Net中使用跳跃连接对于非窄掩码(non-narrow mask)没有显著影响。这主要是因为对于掩码区域的中心,这些跳跃连接的输入几乎为零,因此无法将详细的颜色或纹理信息传播到该区域的解码器。对于空洞边界,我们采用门控卷积的编码器和解码器结构足以产生无缝结果。
将所有的普通卷积替换成门控卷积,一个潜在的问题是引入了额外的参数。为了保持和baseline模型相同的效率,作者将模型缩减了25%,在定量和定性上没有明显的性能下降。
2.4.4、自由形状的掩码生成
自动生成自由形状掩码的算法非常重要。采样的掩模本质上应该是
(1)与真实用例中绘制的掩模相似,(2)多样性以避免过拟合,(3)计算和存储效率,(4)可控性和灵活性。
ParialConv是从两个连续视频帧之间的遮挡估计方法中收集一组固定的不规则mask,虽然增加了随机扩张、旋转、裁剪来增加多样性,但是该方法仍然不满足上述其他要求。
笔者这里贴上作者之前的mask生成算法,如下所示:

3、实验
环境:
作者开源了GatedConv的源代码,目前可以运行的环境是tensorflow 1.3.0,1.4.0,1.5.0,1.6.0,1.7.0,笔者在1.2.0上运行的,在1.12以及1.14上没有运行成功。
作者提供了一个工具包,封装了一些常用的函数,运行之前得安装该包。
pip install git+https://github.com/JiahuiYu/neuralgym
train:
1)准备数据集,制作成文件列表,这里有人给了一个方法issues,修改一下文件夹,就可以了。笔者这里自己写了一个制作文件列表的方法。
2)修改inpaint.yml文件,根据自己的需要修改Data_flist,log_dir,image_shape。
3)然后就是python train.py
笔者在服务器上跑了一下该实验,2块2080ti,迭代了218k次,运行了59个小时,只在celeba-hq数据集上train了。感觉时间应该浪费在生成mask上了。
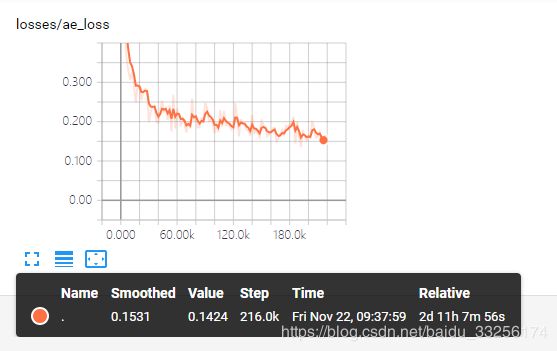
训练结果:

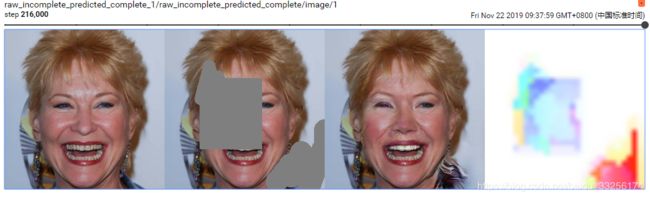


笔者这里没有做test,没有定量分析,后面我会完善这个实验。。。
4、总结
从修复的结果可观,主观评价整体还是不错的,但是仍然存在某些修复结果存在伪影,如下图所示,修复的内容看似合理,但是已经和groundtruth不一样了。加入内容推理和风格转换等,应该可以改善结果。


由于作者水平有限,文中若有不正确的地方,欢迎大家指出,若有任何问题,请在下方讨论。