Sleuth官网地址 http://cloud.spring.io/spring-cloud-static/Camden.SR7/#_spring_cloud_sleuth
微服务之间是通过轻量级的通讯协议进行通信,而网络常常也相对脆弱、网络资源也相当有限。 如果我们能够跟踪每一个请求,了解请 求经过哪些微服务、请求的耗时、网络延迟、业务逻辑耗时这些指标,这样我们就能够更好的分析系统的瓶颈、针对的解决系统问题。因此、我们微服务体系中加上跟踪还是很有必要的。
RabbitMQ用于的微服务和Zipkin服务端的通信(取代微服务和Zipkin服务端通过http通信,实现了微服务和Zipkin服务端的解耦,微服务不需要知道Zipkin服务端的网络地址,一些情况下微服务可能和Zipkin服务端网络不通(Zipkin服务端宕机),使用http通信收集方式将无法工作)
Zipkin提供了一个很友好的界面、利于分析追踪数据(没有尝试过使用elk分析追踪数据(不再需要zipkin服务端,直接分析日志数据))。
Mysql或Elasticsearch实现了追踪数据的持久化(Zipkin默认是将追踪数据存在内存中,如服务端重启或宕机,会导致历史数据丢失,所以追踪数据持久化很有必要).
Spring Cloud Sleuth 提供了一套分布式跟踪解决方案,先了解一下它的术语:
Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)
span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能需要创建一个trace。
Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间
将Span和Trace在一个系统中使用Zipkin注解的过程图形化:
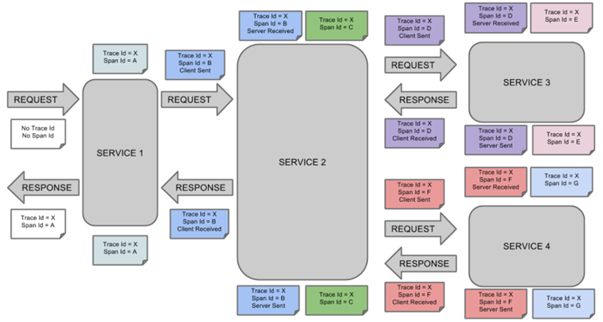
原有微服务整合Spring Cloud Sleuth Zipkin 和 RabbitMQ
对原有微服务只要加依赖和配置就可以了
1. 在需要跟踪的微服务pom中添加如下依赖:

2. 在其配置文件中加入rabbitmq和sleuth的配置:
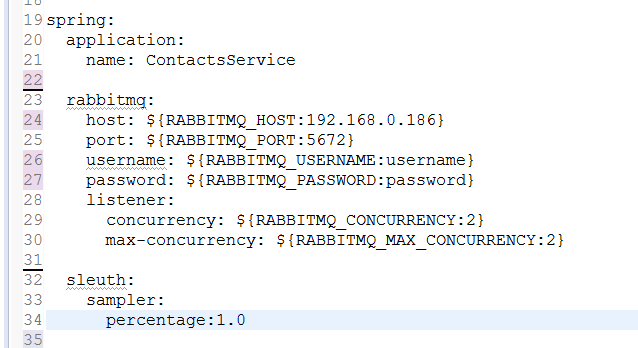
spring.sleuth.sampler.percentage:指定需要取样的请求百分比,默认值是0.1,分布式系统中,数据量也许会应该大。所以,可以根据各自的项目情况,设置合适的采样非常重要。这里因为是开发阶段,我把采样设置成了1.0,即100%。
如果不使用中间件(rabbitmq),还需要配置一个参数指定Zipkin服务器地址(默认访问http://localhost:9411)
spring.zipkin.base-url:http://192.168.1.178:9411
这里配置的地址需改成自己设置的Zipkin地址。
Zipkin服务端:
1. 创建一个artifactId为zipkin-service 的Maven工程,并为项目添加如下pom依赖:

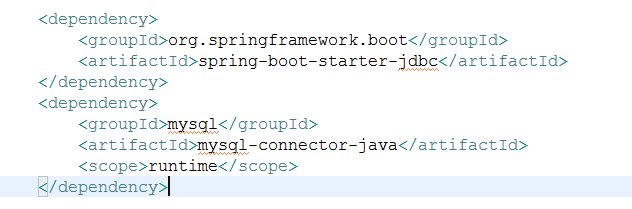
如果使用mysql做数据的持久化的话,这两个依赖不能少。
2. 编写配置文件,在application.yml中添加如下内容:

zipkin.storage.type配置持久化类型,这里配置了elasticsearch,如果要使用mysql的话,需改为mysql
3. 编写启动类,使用@EnableZipkinStreamServer注解,生命一个Zipkin Server。
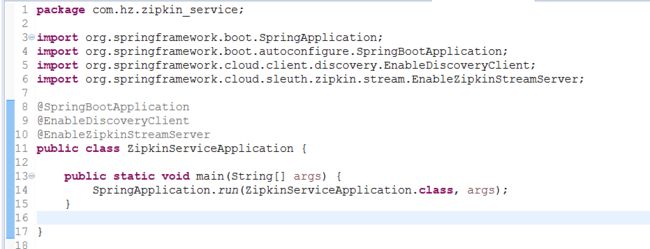
我这里加了@EnableDiscoveryClient注解,把 zipkin-service也当成微服务注册
4. Zipkin界面介绍

可以根据时间、微服务、请求类型等刷选trace列表

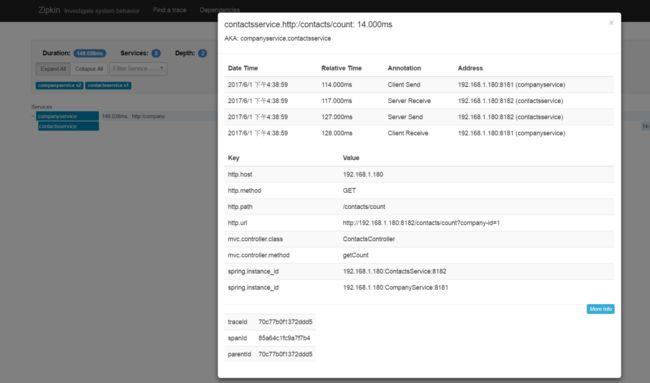
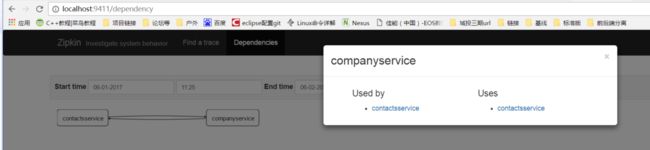
可视化界面有利于我们分析为服务之间的依赖关系,可以选择时间来刷选
5. elasticsearch
elasticsearch的安装部署这里就不说了
6. mysql

Zipkin的jar包中有个mysql.sql文件,用于初始化数据库表结构 。
初次写文章,如有错误、疏漏请大家多多包涵指教。(由于不知道代码如何在上展示,所以全部是截图的)
QQ:656765117 邮件:[email protected]
附上Zipkin服务端代码: http://git.oschina.net/huangzhuo92/zipkin-service