朴素贝叶斯进行新闻主题分类,有代码和数据,可以跑通
folder_path = '/Users/apple/Documents/七月在线/NLP/第2课/Lecture_2/Naive-Bayes-Text-Classifier/Database/SogouC/Sample'
stopwords_file = '/Users/apple/Documents/七月在线/NLP/第2课/Lecture_2/Naive-Bayes-Text-Classifier/stopwords_cn.txt'
下载地址:链接:https://pan.baidu.com/s/1O5mW04PlulaCW5TUd93OUg 密码:ubkq
然后切换Python2.7,跑下面代码就可以进行自然语言入门了
#coding: utf-8
#python 2.7 运行正确
'''
经典的新闻主题分类,用朴素贝叶斯做。
#2018-06-10 June Sunday the 23 week, the 161 day SZ
数据来源:链接:https://pan.baidu.com/s/1_w7wOzNkUEaq3KAGco19EQ 密码:87o0
朴素贝叶斯与应用
文本分类问题
经典的新闻主题分类,用朴素贝叶斯做。
朴素贝叶斯进行文本分类的基本思路是先区分好训练集与测试集,对文本集合进行分词、去除标点符号等特征预处理的操作,然后使用条件独立假设, 将原概率转换成词概率乘积,再进行后续的处理。 贝叶斯公式 + 条件独立假设 = 朴素贝叶斯方法 基于对重复词语在训练阶段与判断(测试)阶段的三种不同处理方式,我们相应的有伯努利模型、多项式模型和混合模型。 在训练阶段,如果样本集合太小导致某些词语并未出现,我们可以采用平滑技术对其概率给一个估计值。 而且并不是所有的词语都需要统计,我们可以按相应的“停用词”和“关键词”对模型进行进一步简化,提高训练和判断速度。
'''
import os
import time
import random
import jieba #处理中文
#import nltk #处理英文
import sklearn
from sklearn.naive_bayes import MultinomialNB
import numpy as np
import pylab as pl
import matplotlib.pyplot as plt
#粗暴的词去重
def make_word_set(words_file):
words_set = set()
with open(words_file, 'r') as fp:
for line in fp.readlines():
word = line.strip().decode("utf-8")
if len(word)>0 and word not in words_set: # 去重
words_set.add(word)
return words_set
# 文本处理,也就是样本生成过程
def text_processing(folder_path, test_size=0.2):
folder_list = os.listdir(folder_path)
data_list = []
class_list = []
# 遍历文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder)
files = os.listdir(new_folder_path)
# 读取文件
j = 1
for file in files:
if j > 100: # 怕内存爆掉,只取100个样本文件,你可以注释掉取完
break
with open(os.path.join(new_folder_path, file), 'r') as fp:
raw = fp.read()
## 是的,随处可见的jieba中文分词
jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数,不支持windows
word_cut = jieba.cut(raw, cut_all=False) # 精确模式,返回的结构是一个可迭代的genertor
word_list = list(word_cut) # genertor转化为list,每个词unicode格式
jieba.disable_parallel() # 关闭并行分词模式
data_list.append(word_list) #训练集list
class_list.append(folder.decode('utf-8')) #类别
j += 1
## 粗暴地划分训练集和测试集
data_class_list = zip(data_list, class_list)
random.shuffle(data_class_list)
index = int(len(data_class_list)*test_size)+1
train_list = data_class_list[index:]
test_list = data_class_list[:index]
train_data_list, train_class_list = zip(*train_list)
test_data_list, test_class_list = zip(*test_list)
#其实可以用sklearn自带的部分做
#train_data_list, test_data_list, train_class_list, test_class_list = sklearn.cross_validation.train_test_split(data_list, class_list, test_size=test_size)
# 统计词频放入all_words_dict
all_words_dict = {}
for word_list in train_data_list:
for word in word_list:
if all_words_dict.has_key(word):
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
# key函数利用词频进行降序排序
all_words_tuple_list = sorted(all_words_dict.items(), key=lambda f:f[1], reverse=True) # 内建函数sorted参数需为list
all_words_list = list(zip(*all_words_tuple_list)[0])
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
def words_dict(all_words_list, deleteN, stopwords_set=set()):
# 选取特征词
feature_words = []
n = 1
for t in range(deleteN, len(all_words_list), 1):
if n > 1000: # feature_words的维度1000
break
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1
输出图像:
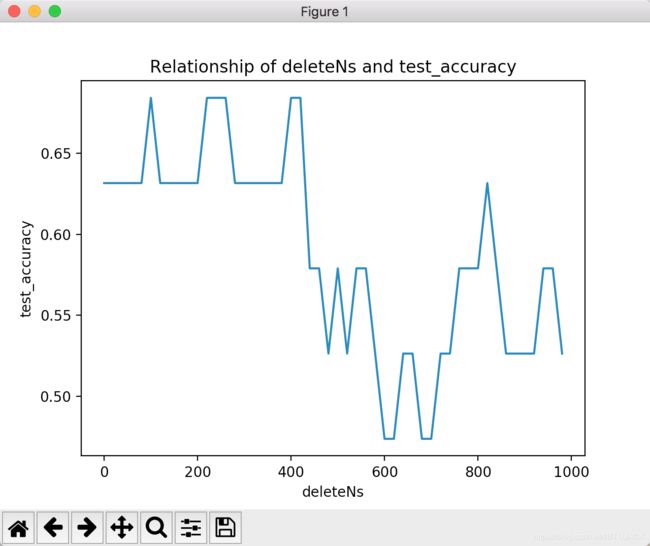
认识你是我们的缘分,同学,等等,学习人工智能,记得关注我。

微信扫一扫
关注该公众号
《湾区人工智能》
回复《人生苦短,我用Python》便可以获取下面的超高清电子书和代码
