ElasticSearch 2 (8) - 概览与简介
ElasticSearch 2 (8) - 概览与简介
摘要
分布式集群架构,具有高扩充性,可随时增加或移除节点,并保证数据正确。
使用Apache Lucene储存JSON文件,提供全文搜索功能
所有操作均可透过RESTful API完成
跨平台,Java写成
版本
elasticsearch版本: elasticsearch-2.2.0
内容
为了搜索,你懂的
有谁在使用?

还有谁在用?

用来做什么?
记录
搜寻
分析
与关系数据库有什么不一样?
索引、类型?
关系数据库 => 数据库 => 表 => 行记录 => 列
ElasticSearch => 索引 => 类型 => 文件 => 字段
如何使用
如何存入?
PUT /megacorp/employee/1
{
“first_name": "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I am hero",
"interests": [ "sports", "music" ]
}- 创建megacorp的索引 Index
- 在里面创建一个employee的类型 Type
- 在里面建立一个_id是1的JSON文件 Document
如何读取?
GET /megacorp/employee/1或
GET /megacorp/employee/_search?q=music或
GET /megacorp/_search?q=hero如何回传?
{
……
"took": 4,
"hits": {
"total": 1,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.095891505,
"_source": {
"first_name": "John",
……
}
}
]
}
} 集群里的日子
Cluster由一个或以上具有相同cluster.name的ElasticSearch节点所组成。当有节点加入或移除时,cluster会自动平均分配数据。
Cluster中会自动选出一个主节点负责cluster的变动,例如新增节点或创建新的Index。
主节点可以不参与文件操作或搜索,因此只有一个主节点不会导致瓶颈。
我们可以发送请求到任一节点,它会清楚在cluster中该如何处理,并回传给我们最终结果。
Cluster的健康状态
GET /_cluster/healthGREEN 所有的主要(master)与复制(replica)的shard都是启动的。
YELLOW 所有的主要shard都是启动的,但复制的没有。
RED 所有的主要与复制的shard都没有启动。
创建索引
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}创建一个名为blogs的Index,并设定它有3个主shard每个主shard总共要有一个副本shard在其他机器。
一个节点的时候

此时cluster健康状态为黄色,因为没有分配副本shard到其他机器。此时ElasticSearch可以正常运作,但是数据若遭到硬件问题时无法复原。
加入第二、第三个节点
此时cluster健康状态为绿色,因所有shard都启动了。此时其中一个节点遇到硬件问题都不会有影响。
增加复制的shard
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
如此一来,坏掉两个节点也不影响。
数据如何分配到shard?
shard = hash(routing) % number_of_primary_shards当有文件要储存进入Index时,ElasticSearch经过上面的计算后决定要把该文件存储到哪一个shard。
routing为任意字符串,预设为文件上的_id,可被改为其他的值。透过改变routing可以决定文件要储存到哪个shard。
当新增或删除文件的时候
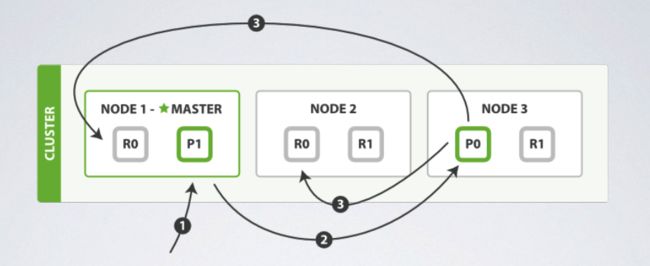
- Node 1 收到新增或删除请求。
- Node 1 算出请求的文件是属于Shard 0,因此将请求转给Node 3。
- Node 3 完成请求时,会再将请求转给复制的shard所在的Node 1与Node 2,并确定他们也都完成,此请求才算是成功。
当取得指定文件的时候
- Node 1 收到获取请求。
- Node 1 算出请求的文件是在Shard 0,而三台机器都有Shard 0,以上图为例,它会将请求转给Node 2。
- Node 2 将文件回传给Node 1,再回传给使用者。
问题:当多个Node上都具有相同shard时,主Node如何转发请求?
当更新文件的时候
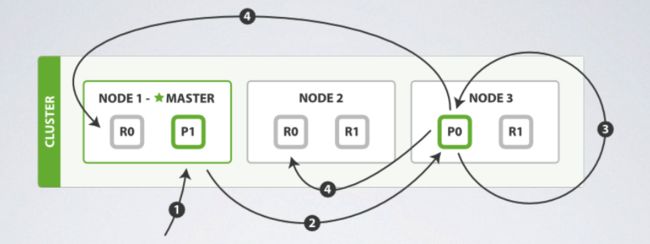
- Node 1 收到更新的请求。
- Node 1 算出请求的文件属于Shard 0,因此将请求转给Node 3。
- Node 3 将文件取出后更新_source并尝试重新索引。此步骤可能重复retry_on_conflict次数。
- Node 3 完成请求时,会再将新的文件传给复制的shard所在的Node 1与Node 2,并确定他们也都完成,此请求才算是成功。
问题:此种情况Node 1是否会优先将请求转给主Shard所在Node?
问题:如果超过重复次数,系统行为如何?
分布式文件存储
如何制作索引?
假如有12条date是2014-xx-xx的文件。但只有一个文件的date是2014-09-15。那我们发送以下请求:
GET /_search?q=2014 # 12 results
GET /_search?q=2014-09-15 # 12 results !
GET /_search?q=date:2014-09-15 # 1 result
GET /_search?q=date:2014 # 0 results !
结果为什么这么奇怪?
映射与分析
跨字段搜索
当存储文件时,ElasticSearch预设会另外存储一个_all字段。该字段预设由所有字段串接而成,并使用inverted index制作索引提供全文搜索。例如:
{
"tweet": "However did I manage before Elasticsearch?",
"date": "2014-09-14",
"name": "Mary Jones",
"user_id": 1
}该文件的_all如下:
"However did I manage before Elasticsearch? 2014-09-14 Mary Jones 1"映射
当有文件存储进来时,ElasticSearch预设会为该type自动生成mapping,用来决定如何制作索引以提供搜索。
{
"gb": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "dateOptionalTime"
},
"name": {
"type": "string"
},
"tweet": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}
}exact value 与full text
ElasticSearch把值分成两类:exact value 与full text。
当针对exact value的字段搜索时,使用布尔判断,例如:Foo != foo。
当针对full text的字段搜索时,则是计算相关程度,例如:UK与United Kingdom相关、jumping与leap也相关。
Inverted Index
ElasticSearch用inverted index建立索引,提供全文搜索。考虑以下两份文件:
The quick brown fox jumped over the lazy dog
与
Quick brown foxes leap over lazy dogs in summer
建立出来的inverted index看起来大概如下表。
--------------------------------------- Term | Doc_1 | Doc_2 --------------------------------------- Quick | | X The | X | brown | X | X dog | X | dogs | | X fox | X | foxes | | X in | | X jumped | X | lazy | X | X leap | | X over | X | X quick | X | summer | | X the | X | ---------------------------------------搜索“quick brown”的结果如下表。
--------------------------------------- Term | Doc_1 | Doc_2 --------------------------------------- brown | X | X --------------------------------------- quick | X | --------------------------------------- Total | 2 | 1 ---------------------------------------此表还可以优化,例如
- Quick可以变成quick
- foxes,dogs可以变成fox与dog
- jumped,leap可以变成jump
这种分词(tokenization)、正规化(normalization)过程叫做analysis
优化结果如下
--------------------------------------- Term | Doc_1 | Doc_2 --------------------------------------- brown | X | X dog | X | X fox | X | X in | | X jump | X | X lazy | X | X over | X | X quick | X | X summer | | X the | X | X ---------------------------------------Analysis与Analyzers
Analysis程序由Analyzer完成,Analyzer由下面三个功能组成:
Character filters
首先,字符串先依次经过character filters处理过,再进行分词。例如可能将html标签移除,或将 & 转换为 and。
Tokenizer
分词器就是将字符串切为许多有意义的单词。
Token filters
每个单词再依序经过token filters做最后处理。例如可能将Quick变成quick、把leap换成jump。
中文分词
ik分词器或mmseg分词器
- https://github.com/medcl/elasticsearch-analysis-ik
- https://github.com/medcl/elasticsearch-analysis-mmseg
Lucene Smart Chinese Analysis
回答之前的问题
假如有12条date是2014-xx-xx的文件。但只有一个文件的date是2014-09-15。那我们发送以下请求:
用2014去全文搜索_all字段
GET /_search?q=2014# 12 results
2014-09-05经过分析后变成使用2014,09,15去全文搜索_all字段,由于每份文件都有2014所以全部相关。
GET /_search?q=2014-09-15# 12 results !
针对date字段搜索exact value
GET /_search?q=date:2014-09-15# 1 result
针对date字段搜索exact value,没有文件的date是2014
GET /_search?q=date:2014# 0 results !
数据是分布式存储的
分布式搜索
- ElasticSearch将搜索分成两个阶段,来完成在分布式系统中的搜索与排序:query与fetch。
排序的其中一个目的是为了分页,考虑一下请求:
GET /_search { "from": 90, "size": 10 }
query阶段
- Node 3 收到搜索请求后制作一个大小为from + size = 100的priority queue来排序。
- Node 3 将搜索请求转给其他每个shard,此例为0号与1号。每个shard将自己搜索,并用priority queue排序出前from + size = 100个结果。
- 每个shard将各自结果的IDs与排序值回传给Node 3,Node 3再将这些结果加入priority queue中。
问题:为什么每个Node都是from + size = 100个结果?
fetch阶段
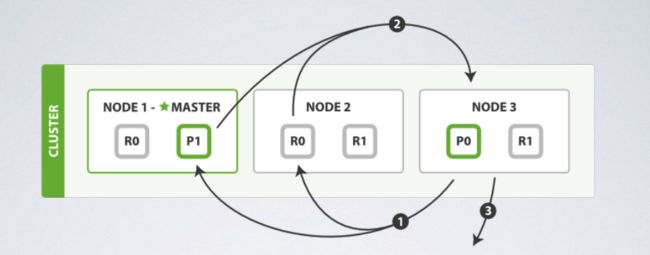
- Node 3 将排序完的IDs取出需要的部分,即最后10笔,再发送Multi-GET请求跟文件所在的shard取得完整的文件。
- shard 各自收到请求后,取出文件,若需要的话再经过处理,例如加上metadata与片段高亮,再回传给Node 3。
- Node 3 取得所有结果后再回传给客户端。
在分布式系统中的排序与分页
- ElasticSearch搜索结果预设只会回传10个经过_score排序的文件。
我们可以透过size与from参数,取得其他分页的结果。例如
GET /_search?size=10&from=10000但是在分布式系统中分页的成本非常高。预设一个Index有5个shard,若要取出第1000页的内容,必须从每个shard取出前10010个文件。再将总共50050个结果重新排序取出10个(10001 ~ 100010)。因此若要取出大量数据,不建议使用排序与分页的功能。
scan与scroll
GET /old_index/_search?search_type=scan&scroll=1m
{
"query": { "match_all": {}},
"size": 1000
}- 设定 search_type = scan,这样一来ElasticSearch不会对结果进行排序。
设定scroll = 1m,将会对这个搜索建立快照,并维持一分钟。根据回传的_scroll_id可以取得下一批的结果。经由size参数可以设定一个shard一批最多取多少文件,因此每一批取得的数量最多为
size * number_of_primary_shards透过scan与scroll,我们可以批次取得大量的文件,而且不会有分页成本。若有需要重新索引整个index时,可以使用此方法完成。
最佳化Index
Index 设定
虽然ElasticSearch在存入文件的时候就会自动创建Index,但使用预设设定可能不是个好主意。例如:
主要的shard数量不能够被修改
自动mapping可能会猜错
使用不符需求的Analyzer
这些设定都需要在存储数据之前设定完成,否则将会需要重新索引整个index。
除了手动设定index之外,也可以使用index template自动套用设定。
mapping的部分则可以设定dynamic_templates自动套用。
别名零宕机Zero downtime
若想要改变已经既有字段的索引方式,例如改变Analyzer。将需要重新索引整个index,否则既有的数据与新索引的不一致。
利用Index别名,可以做到Zero downtime的重新索引。
Application请求的index叫做my_index。实际上my_index是个别名,指到的是my_index_v1。
若要重新索引,则创建新的my_index_v2,并套用新的设定。再透过scan与scroll将文件从my_index_v1放入my_index_v2。
最后将my_index别名导向my_index_v2即可。
Shard内部
- shard是一个低阶的工作单元,事实上是一个Lucene实例,负责文件的存储与搜索。
- inverted index由shard创建,并写入磁盘,而且建立好的inverted index不会被更改。
不会被修改的inverted index
inverted index的不变性带来许多好处,如:
当多个processes来读取时,不需要锁定。
一旦被读入系统的cache,将会一直保留在cache中,如此一来便不用再访问磁盘。
更新inverted index
Lucene 带来了per-segment search的概念,segment就是一个inverted index。既有的segment不被改变,因此当有新文件存入的时候,就建立新的segment;若更新或删除文件时,则另外将旧文件标记.del档案。而搜索时,就依序对各个segment搜索。
合并segments
然而随着时间经过,segment数量越来越多,搜索成本也越来越大。ElasticSearch会定期将segment合并,同时一除掉那些被标记为删除的文件。
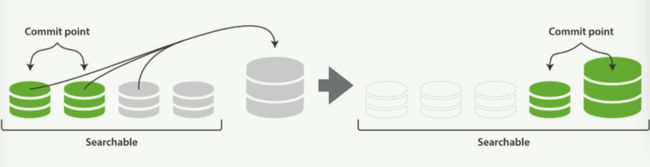
问题:如何定期?
参考
参考来源:
《ElasticSearch: The Definitive Guide》
Slideshare: Elasticsearch 簡介
SlideShare: What is in a Lucene index?