itext实现html转换成pdf (将带分页execl的html转换成pdf)
1.首先下载itext2.08,iTextAsian(亚洲国际化包支持pdf中显示中文),core-Renderer(解析xhtml转换成pdf支持包),jtidy(html转换成xhtml支持包).其中core-Renderer包必须配合itext2.08版本的包,否则会抛出没有是public int[] getCharBBox(char c) 方法异常。
2.使用HttpURLConnection类发送一个post 请求。并利用HttpURLConnection中getInputStream方法获取生成的html的流。
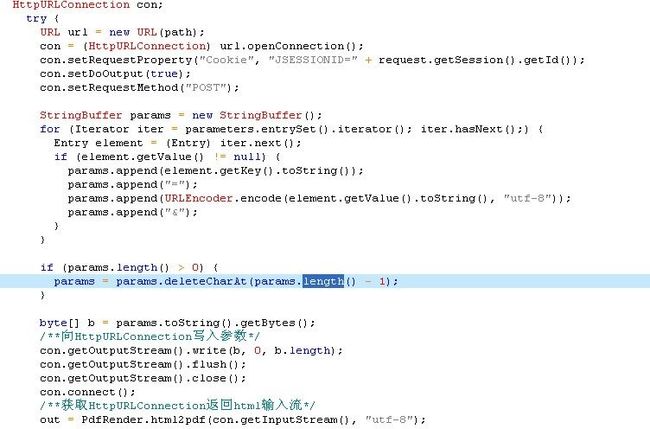
3.利用jtidy将html流转换成xhtml流。并将xhtml流生成xhtml的document文档,最后利用ITextRenderer解析xhtml的document文档生成pdf的OutPutStream流生成pdf.
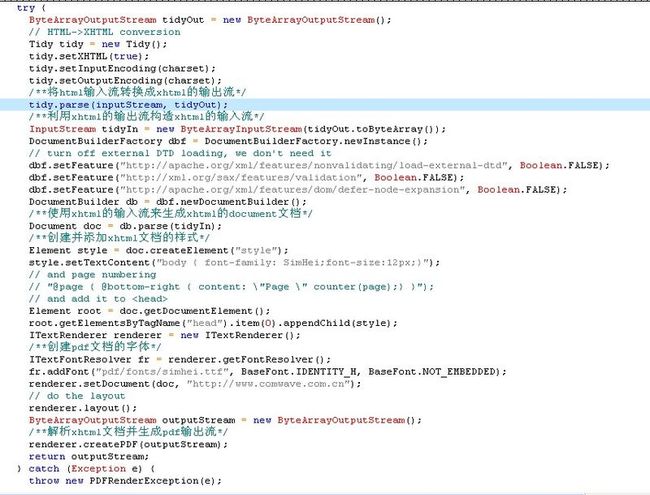
注意:如果网页html的栏位太多,使网页html转换成pdf只会显示一半,这样就必须将字体变小
如将上面字体12px改成11px或更小就可以:
style.setTextContent("body { font-family: SimHei;font-size:11px;}");
4.通过拦截器获html并将html转换成excel和pdf
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException,
ServletException {
String queryString = ((HttpServletRequest) request).getQueryString();
String uri = ((HttpServletRequest) request).getRequestURI();
if (queryString == null) {
chain.doFilter(request, response);
return;
}
response.setCharacterEncoding("UTF-8");
WapperedResponse wrapper = new WapperedResponse((HttpServletResponse) response);
chain.doFilter(request, wrapper);
byte[] excelBytes = wrapper.getResponseData();
ByteArrayInputStream bis = new ByteArrayInputStream(excelBytes);
java.io.BufferedOutputStream bos = null;
HttpServletResponse httpResp = (HttpServletResponse) response;
httpResp.reset();
if (!p.matcher(queryString).find()) {
response.setCharacterEncoding("UTF-8");
httpResp.setHeader("Pragma", "no-cache");
httpResp.setHeader("Cache-Control", "no-cache");
httpResp.setDateHeader("Expires", 0);
httpResp.setContentType("application/vnd.ms-excel");
httpResp.setHeader("Content-disposition", "attachment; filename="
+ encodingFileName(getFileName(uri).replaceAll(".pdf", ".xls")));
String filePath = ApplicationSetting.getProperty("save_report_excelTemp");
if (!new File(filePath).exists())
new File(filePath).mkdirs();
String htmlName = filePath + UUID.randomUUID().toString().replace("-", "") + ".html";
String excelName = filePath + UUID.randomUUID().toString().replace("-", "") + ".xls";
FileOutputStream stream = new FileOutputStream(new File(htmlName));
stream.write(excelBytes);
stream.close();
stream = null;
bis = null;
excelBytes = null;
System.gc();
try {
htmlToExcel(htmlName, excelName);// 一般耗時在打開html檔上
} catch (Exception e) {
e.printStackTrace();
} finally {
if (new File(htmlName).exists())
new File(htmlName).delete();
}
FileInputStream inStream = new FileInputStream(new File(excelName));
byte[] content = new byte[1000];
while (inStream.read(content) != -1) {
response.getOutputStream().write(content);
}
if (inStream != null)
inStream.close();
if (response.getOutputStream() != null)
response.getOutputStream().close();
if (new File(excelName).exists())
new File(excelName).delete();
} else {
httpResp.setHeader("Content-Disposition", " attachment; filename=\"my.pdf\"");
httpResp.setHeader("Expires", "0");
httpResp.setHeader("Cache-Control", "must-revalidate, post-check=0, pre-check=0");
httpResp.setHeader("Pragma", "public");
String fileName = getFileName(uri);
try {
OutputStream ou = response.getOutputStream();
bos = new java.io.BufferedOutputStream(ou);
httpResp.setContentType("application/pdf");
httpResp.setHeader("Content-disposition", "attachment; filename=" + encodingFileName(fileName));
String pdfFontSize = ((HttpServletRequest) request).getParameter("pdfFontSize");
PdfRender.html2pdf(bis, "utf-8", pdfFontSize).writeTo(bos);
} catch (Exception e) {
e.printStackTrace();
}
}
}
4.部分参考资料网址
http://www.iteye.com/topic/509417?page=6
http://today.java.net/pub/a/today/2007/06/26/generating-pdfs-with-flying-saucer-and-itext.html
http://blog.csdn.net/zdtwyjp/archive/2010/07/27/5769353.aspx