SQL Server 2008中增强的汇总技巧
SQL Server 2008中对汇总有明显的增强,有点像Oracle的语法了。请看下面五个例子:
假定场景如下:某几位员工在不同时间参加了不同的项目,获取了相应的收入,现在需要按各种分类进行统计。
基本表如下:
数据如下:
一、使用CUBE汇总数据(http://msdn.microsoft.com/en-us/library/bb522495%28v=sql.105%29.aspx)
小试牛刀,

改进查询:

二、使用ROLLUP汇总数据(http://msdn.microsoft.com/en-us/library/bb522495%28v=sql.105%29.aspx)

注意:使用Rollup与指定的聚合列的顺序有关。
三、使用Grouping Sets创建自定义汇总数据(http://msdn.microsoft.com/en-us/library/bb522495%28v=sql.105%29.aspx)
除了Cube和Rollup,还有更加灵活强大的自定义集合汇总--Grouping Sets

四、使用Grouping标识汇总行(http://technet.microsoft.com/zh-cn/library/ms178544.aspx)
细心的朋友可能会注意到,如果Cube后有两个以上的汇总列时,可能会有一些列是Null,那么这些Null值究竟本身就是Null,还是由于聚合产生的Null呢,此时,Grouping函数大显身手的机会来了。

至此,如果还有美中不足的话,那就是分组还是有点凌乱,下面我们将隆重推出终极武器--Grouping_ID,它与Grouping类似,但提供更为精细的颗粒度,以确认分组级别,当然使用也更为复杂,请看下面的示例:
五、使用Grouping_ID标识分组级别(http://technet.microsoft.com/zh-cn/library/bb510624.aspx)
为了更清楚地说明问题,我们需要修改一下表结构,增加一个字段--项目所在的地点(AreaID),如下:
此时数据变成这样:
我们需要统计小组、地区、月份三个维度的汇总数据。
统计结果:
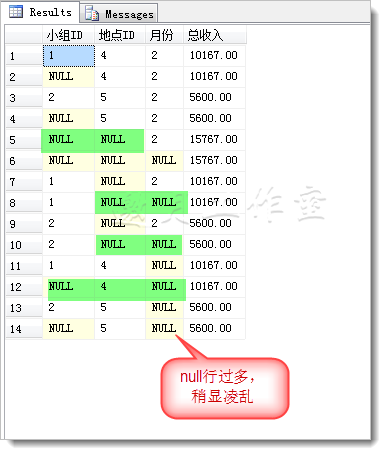
我们注意到,由于维度从两个变成三个,此时数据比较凌乱,即使排序也不能有效解决。幸好,我们有Grouping_ID。看下例:
注意:代码中新增的部分,这里需要稍微解释一下,Grouping_ID接受几个输入列,返回二进制列列表计算的整数值,你可以把这三个维度,看作是(0,1,1)、(0,1,0)这样类似的二进制,而Grouping_ID负责将运算结果以整数形式返回。
效果:
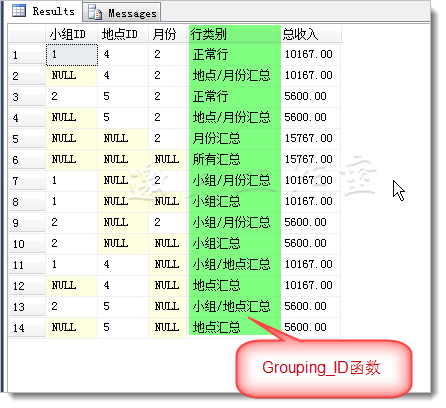
至此,Group By的汇总暂时告一段落,希望您不虚此行,有所斩获!
小结:带有Cube,Rollup,grouping Sets的Group By函数在统计与分析中有着广泛的应用,相信它的高效简捷,在特定的场合会令人你爱不释手!