Lucene源代码之构造自己的分词器
- package org.apache.lucene.analysis.tjuchinese;
- import java.io.IOException;
- import java.io.Reader;
- import java.io.StringReader;
- import java.util.Set;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.analysis.StopFilter;
- import org.apache.lucene.analysis.TokenStream;
- import com.xjt.nlp.word.ICTCLAS;
- public final class TjuChineseAnalyzer extends Analyzer {
- private Set stopWords;
- // 可以在此扩展English stop words和Chinese stop words
- public static final String[] ENGLISH_STOP_WORDS = { "a" , "an" , "and" ,
- "are" , "as" , "at" , "be" , "but" , "by" , "for" , "if" , "in" , "into" ,
- "is" , "it" , "no" , "not" , "of" , "on" , "or" , "s" , "such" , "t" ,
- "that" , "the" , "their" , "then" , "there" , "these" , "they" , "this" ,
- "to" , "was" , "will" , "with" , "我" , "我们" };
- /** Builds an analyzer which removes words in ENGLISH_STOP_WORDS. */
- public TjuChineseAnalyzer() {
- stopWords = StopFilter.makeStopSet(ENGLISH_STOP_WORDS);
- }
- /** Builds an analyzer which removes words in the provided array. */
- public TjuChineseAnalyzer(String[] stopWords) {
- this .stopWords = StopFilter.makeStopSet(stopWords);
- }
- /** Filters LowerCaseTokenizer with StopFilter. */
- public TokenStream tokenStream(String fieldName, Reader reader) {
- try {
- ICTCLAS splitWord = new ICTCLAS();
- String inputString = FileIO.readerToString(reader);
- String resultString = splitWord.paragraphProcess(inputString);
- TokenStream result = new TjuChineseTokenizer( new StringReader(
- resultString));
- result = new StopFilter(result, stopWords);
- return result;
- /*
- * return new StopFilter(new LowerCaseTokenizer(new StringReader(
- * resultString)), stopWords);
- */
- } catch (IOException e) {
- System.out.println( "转换出错" );
- return null ;
- }
- }
- }
TjuChineseTokenizer.java;
- package org.apache.lucene.analysis.tjuchinese;
- import java.io.Reader;
- import org.apache.lucene.analysis.LowerCaseTokenizer;
- public class TjuChineseTokenizer extends LowerCaseTokenizer{
- public TjuChineseTokenizer(Reader Input)
- {
- super (Input);
- }
- }
FileIO.java;
- package org.apache.lucene.analysis.tjuchinese;
- import java.io.BufferedReader;
- import java.io.IOException;
- import java.io.Reader;
- public class FileIO {
- public static String readerToString(Reader reader) throws IOException {
- BufferedReader br = new BufferedReader(reader);
- String ttt = null ;
- // 使用 StringBuffer 类,可以提高字符串操作的效率
- StringBuffer tttt = new StringBuffer( "" );
- while ((ttt = br.readLine()) != null ) {
- tttt.append(ttt);
- }
- return tttt.toString();
- }
- }
eclipse里面的部署为:
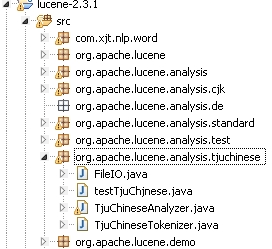
搞定!!
下面测试一下,测试代码如下:
- package org.apache.lucene.analysis.tjuchinese;
- import java.io.IOException;
- import java.io.StringReader;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.analysis.Token;
- import org.apache.lucene.analysis.TokenStream;
- public class testTjuChjnese {
- public static void main(String[] args) {
- String string = "hello!我爱中国人民" ;
- Analyzer analyzer = new TjuChineseAnalyzer();
- TokenStream ts = analyzer
- .tokenStream( "dummy" , new StringReader(string));
- Token token;
- System.out.println( "Tokens:" );
- try {
- int n = 0 ;
- while ((token = ts.next()) != null ) {
- System.out.println((n++) + "->" + token.toString());
- }
- } catch (IOException ioe) {
- ioe.printStackTrace();
- }
- }
- }
运行结果:
Tokens:
0->(hello,0,5)
1->(nx,6,8)
2->(w,12,13)
3->(r,17,18)
4->(爱,20,21)
5->(v,22,23)
6->(中国,25,27)
7->(ns,28,30)
8->(人民,32,34)
9->(n,35,36)
【难点】
- public CharArraySet( int startSize, boolean ignoreCase) {
- this .ignoreCase = ignoreCase;
- int size = INIT_SIZE;
- while (startSize + (startSize>> 2 ) > size)
- size <<= 1 ;
- entries = new char [size][];
- }
startSize + (startSize>>2,不解?
附录:
因为本分词器要用到ICTCLAS java接口。所以要先下载下载地址http://download.csdn.net/source/778456 ;
将文件全部复制到工程文件中(也可以通过导入)后,得到的eclipse视图如下:
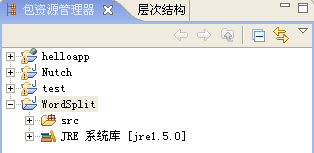
导入视图如下(仅供参考):
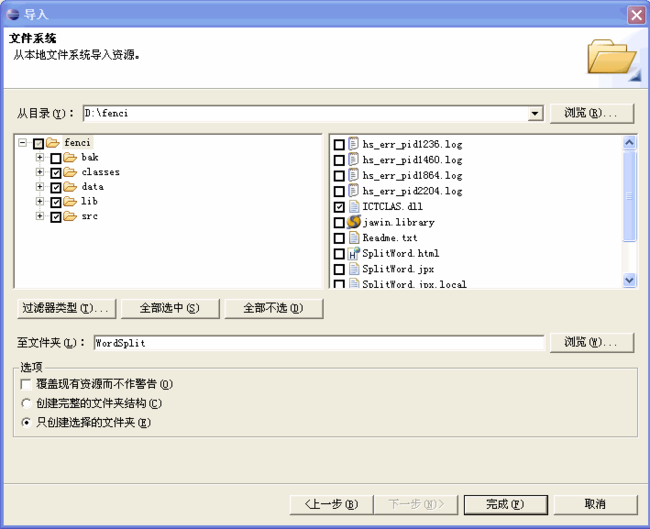
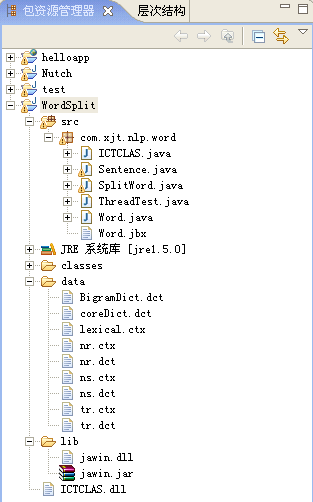
如果出现这样的错误:
java.lang.UnsatisfiedLinkError: no ICTCLAS in java.library.path
at java.lang.ClassLoader.loadLibrary(Unknown Source)
at java.lang.Runtime.loadLibrary0(Unknown Source)
at java.lang.System.loadLibrary(Unknown Source)
at com.xjt.nlp.word.ICTCLAS.<clinit>(ICTCLAS.java:37)
Exception in thread "main"
那么应该就是你缺少了某些文件,尤其是ICTCLAS.dll,另外像“classes”、“data”、“lib”源文件夹也是必需的。
转载:http://blog.csdn.net/caoxu1987728/archive/2008/11/15/3305848.aspx