什么是RDD
Spark是围绕着RDD(Resilient Distributed Dataset,弹性分布式数据集)建立起来的,也就是说,RDD是Spark框架的核心基石。RDD是一个可容错的数据集,这个数据集合中的数据是可以并行处理的。
RDD的特点:
- A list of partitions 一系列的分片,比如说64M一片;类似于Hadoop中的split;
- A function for computing each split 在每个分片上都有一个函数去迭代/执行/计算它
- A list of dependencies on other RDDs 一系列的依赖:RDD a转换为RDD b,RDD b转换为RDD c,那么RDD c就依赖于RDD b,RDDb就依赖于RDDa
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) 对于key-value的RDD可指定一个partitioner,告诉它如何分片;常用的有hash,range
- Optionally, a list of preferred location(s) to compute each split on (e.g. block locations for an HDFS file) 要运行的计算/执行最好在哪(几)个机器上运行。数据本地性。
前三个特点对应于Lineage,后两个对应于Optimized execution
| getPartitions | the set of partitions in this RDD |
| compute | compute a given partition |
| getDependencies | return how this RDD depends on parent RDDs |
| partitioner | specify how they are partitioned |
| getPreferredLocations | specify placement preferences |
| HadoopRDD | Filtered RDD | JoinedRDD | |
| partitions | HDFS上的block | 与父RDD一致 | 一个partition一个任务 |
| dependencies | 无 | 与父RDD 一对一 | 依赖shuffle的每个父RDD |
| compute | 读取每个block的信息 | 计算父RDD的每个分区并过滤 | 读取shuffle数据 |
| partitioner | HDFS block所在位置 | 无 | HashPartitioner |
| preferredLocations | 无 | 无(与父RDD一致) | 无 |
参考:http://www.cnblogs.com/luogankun/p/3801035.html
Spark Shell
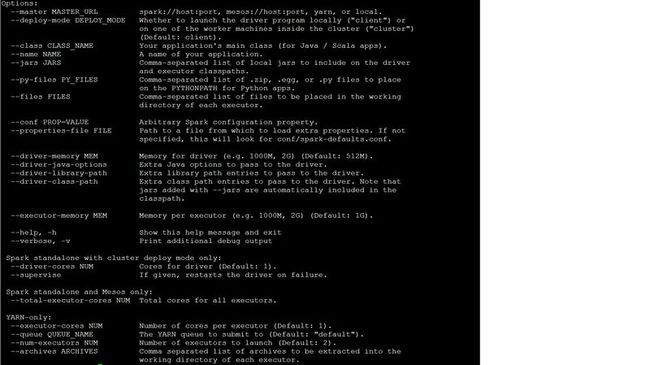
Spark Shell通过初始化一个SparkContext,然后通过Scala语言的脚本特性,可以以脚本的方式来学习Spark提供的API,通过这一点也可以看出Scala确实是有比Java方便简洁的特性。如下是Spark Shell的支持的命令参数
RDD(弹性分布式数据集,Resilent Distributed Dataset)
Spark是围绕着RDD(Resilient Distributed Dataset,弹性分布式数据集)建立起来的,也就是说,RDD是Spark框架的核心基石。RDD是一个可容错的数据集,这个数据集合中的数据是可以并行处理的。有两种方式可以创建RDD:
1. 基于开发者提供的数据集来创建RDD
2. 基于引用外部存储系统中的数据集来创建RDD,比如共享文件系统,HDFS,HBase或者Hadoop InputFormat提供的任意数据源都可以用来创建RDD
并行数据集(程序数据)
Spark可以通过SparkContext的parallelize方法实现对Scala程序提供的数据集创建RDD。 程序中的元素通过数据拷贝的形式创建一个RDD)。比如,下面的例子创建了一个RDD,它包含了1到5的5个数字,例如下面的Scala代码:
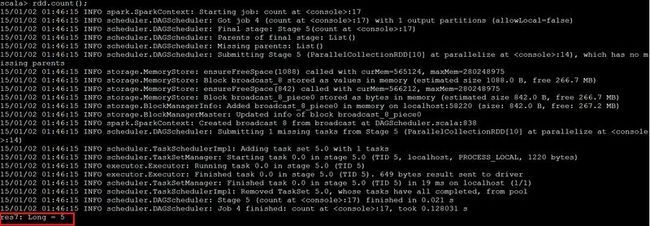
1. 创建ParallelCollectionRDD

2. 执行ParallelCollectionRDD的collect方法

3. 执行RDD的count方法
4. 执行RDD的saveAsTextFile("ParallelCollectionRDD")
rdd.saveAsTextFile("ParallelCollectionRDD");
执行结果是在HDFS的当前用户目录(/user/hadoop)下创建了一个ParallelCollectionRDD目录,并且有个part-00000作为存放文本的文件
[hadoop@hadoop bin]$ hdfs dfs -cat /user/hadoop/ParallelCollectionRDD/part-00000 1 2 3 4 5
外部数据集
1.执行如下操作,则Spark创建了一个RDD(sparkData),而这个RDD的数据来源是HDFS(hdfs://hadoop.master:9000/user/hadoop/sparkdata.txt),也就是说,Spark默认是从当前用户(hadoop)的/user/hadoop下寻找sparkdata.txt文件。
val sparkData = sc.textFile("sparkdata.txt");
注:sparkdata.txt的内容如下:
1 2 3 4 5 6 7 8 9 10
2. sparkData的类型
创建的RDD sparkData的详细信息是如下,可见sparkData是一个MappedRDD类型
sparkData: org.apache.spark.rdd.RDD[String] = sparkdata.txt MappedRDD[4] at textFile at <console>:12
RDD基本操作
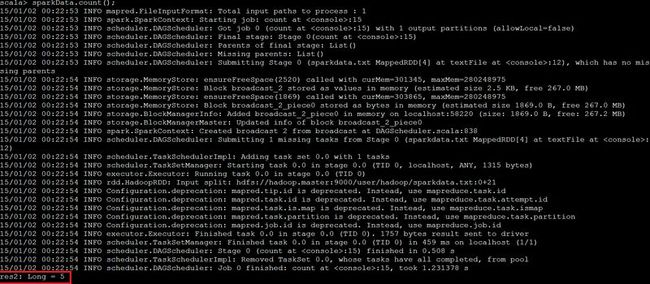
1.统计sparkData RDD中有多少行
sparkData.count()
结果显示如下,得到的结果5,表示sparkData.txt有五行
2. 统计sparkData RDD中所有行的总长度
2.1 Map操作
var lineLengths = sparkData.map(line=>line.length)
执行的结果是: lineLengths是五个MappedDD
lineLengths: org.apache.spark.rdd.RDD[Int] = MappedRDD[5] at map at <console>:14
2.2 Reduce操作
var total = lineLengthMap.reduce((a,b)=>a + b);
执行的结果是:total是一个Int类型的数据。事实上,观察sparkdata.txt的数据,确实是所有行的总长度是16
total: Int = 16
3. Key/Pair RDD
3.1 执行如下操作
lines = sc.textFile("sparkdata.txt")
结果:

3.2 执行如下操作
val pairs = lines.map(s => (s, 1))
结果:

3.3 执行如下操作
val counts = pairs.reduceByKey((a, b) => a + b)
结果:

3.4 执行如下操作:
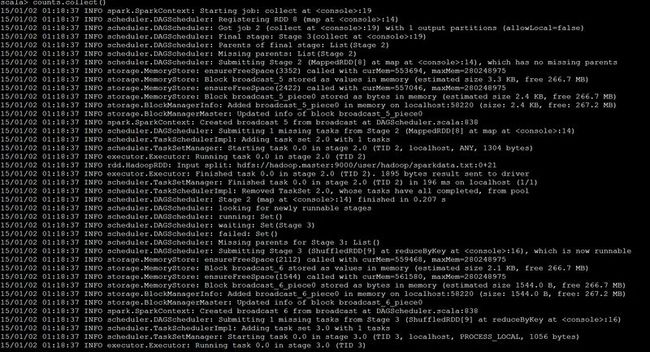
counts.collect()
结果: