元宵爬虫-YuanXiaoSpider
翻译了下..没有元宵的淫文啊....所以用PinYing吧...
这几天写了一个爬虫可以做定向爬虫.也可以做全网爬虫.
该考虑的部分考虑了..不该考虑的没考虑
这里是个程序运行的大概UML不怎么会画凑合看吧
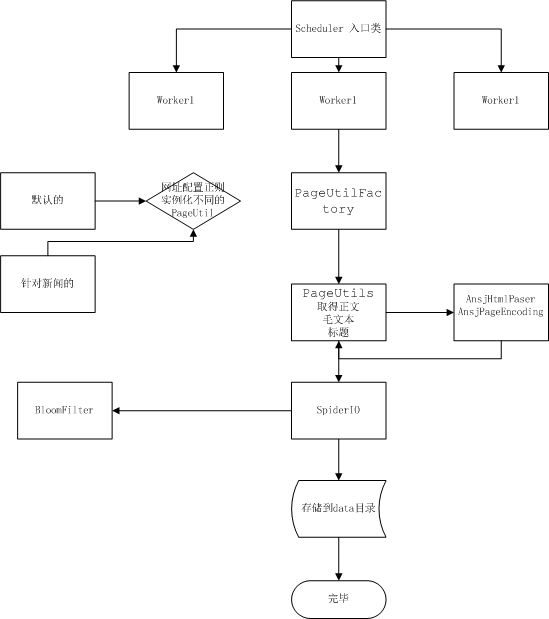
支持正则过滤网址 支持抽取模板
这个项目比起nutch不具有可比性...如果你非要当个demo来看我也不喊冤呵呵...
里面的url抽取..正文抽取...都是自己写的
用到了一些java(据说高级)的东西..可惜仅仅是用到...比如curren nio
周六日费了两天电..目前采集没出大问题(中途断网一次).
如果非要说特点.那就是作者造轮子吧..基于原生java api 写的..不用导包..连log4j 都没要..当然我也没做log...
不是我喜欢造轮子..是不太会用轮子..比如htmlpaser 我怎么看它抽取的正文都不是我想要的东西...js css 都属于正文...而且还得导入个巨大的jar ...这不是我想要的...
数据有了.下一步把cq分词完善下..然后自己写个垃圾索引...一告慰我四年的无为java生涯
使用方法如下
1.首先将项目导入到eclipse
2.在D:/data/url.txt 存放你的种子网页
3.主类在 ansj.sun.spider.thread.Scheduler在这里运行就可以了
配置文件:regexFilter.txt 这个是对需要采集网址的正则过滤
d:/data/wrapper 里面存放用户的自定义抽取模板
抽取模板的例子如下
命名规则必须是news-*.xml
这几天写了一个爬虫可以做定向爬虫.也可以做全网爬虫.
该考虑的部分考虑了..不该考虑的没考虑
这里是个程序运行的大概UML不怎么会画凑合看吧
支持正则过滤网址 支持抽取模板
这个项目比起nutch不具有可比性...如果你非要当个demo来看我也不喊冤呵呵...
里面的url抽取..正文抽取...都是自己写的
用到了一些java(据说高级)的东西..可惜仅仅是用到...比如curren nio
周六日费了两天电..目前采集没出大问题(中途断网一次).
如果非要说特点.那就是作者造轮子吧..基于原生java api 写的..不用导包..连log4j 都没要..当然我也没做log...
不是我喜欢造轮子..是不太会用轮子..比如htmlpaser 我怎么看它抽取的正文都不是我想要的东西...js css 都属于正文...而且还得导入个巨大的jar ...这不是我想要的...
数据有了.下一步把cq分词完善下..然后自己写个垃圾索引...一告慰我四年的无为java生涯
使用方法如下
1.首先将项目导入到eclipse
2.在D:/data/url.txt 存放你的种子网页
3.主类在 ansj.sun.spider.thread.Scheduler在这里运行就可以了
配置文件:regexFilter.txt 这个是对需要采集网址的正则过滤
d:/data/wrapper 里面存放用户的自定义抽取模板
抽取模板的例子如下
命名规则必须是news-*.xml
<?xml version="1.0" encoding="UTF-8"?>
<configure>
<listUrlRegex>
http://roll.mil.news.sina.com.cn/col/zgjq/index_\d+.shtml
</listUrlRegex>
<urlBlock>
<![CDATA[
<div class="fixList">ANSJTEXT</div>
]]>
</urlBlock>
<nextPage>
<![CDATA[
<a title="下一页"ANSJTEXT下一页
]]>
</nextPage>
<urlRegex>http://mil.news.sina.com.cn/(p/)?+\d{4}-\d{2}-\d{2}/\d+(_?+)\d+.html</urlRegex>
<title>
<![CDATA[
<h1 id="artibodyTitle">ANSJTEXT</h1>
]]>
</title>
<content>
<![CDATA[
<!-- publish_helper name='原始正文' p_id='\d+' t_id='\d+' d_id='\d+' f_id='\d+' -->ANSJTEXT<style type="text/css">
]]>
</content>
<publishTime>
<![CDATA[
<span id="pub_date">ANSJTEXT</span>
]]>
</publishTime>
<author>
<![CDATA[
<span id="media_name">ANSJTEXT</span>
]]>
</author>
</configure>