精通 triton 使用 MLIR 的源码逻辑 - 第001节:triton 的应用简介
项目使用到 MLIR,通过了解 triton 对 MLIR 的使用,体会到 MLIR 在较大项目中的使用方式,汇总一下。
1. Triton 概述
OpenAI Triton 是一个开源的编程语言和编译器,旨在简化 GPU 高性能计算(HPC) 的开发,特别是针对深度学习、科学计算等需要高效并行计算的领域。
既允许开发者编写高度优化的代码,又不必过度关注底层硬件细节。这样,通过简化高性能计算,可以加速新算法的实现和实验。传统 GPU 编程(如 CUDA)需要深入理解硬件架构和复杂的优化技术,而 Triton 旨在提供更高层次的抽象,降低开发门槛,但是设计 triton 语言及其编译器本身,门槛却非常高。
Triton 是基于 Python 的 DSL(领域特定语言),Triton 提供类似 Python 的语法,允许用户用简洁的代码表达并行计算逻辑,然后通过编译器优化为高效的 GPU 代码。其中,这些优化是自动化的。自动处理线程调度、内存合并(memory coalescing)、共享内存分配等底层优化,减少手动调优的工作量。Triton 在模块化与可扩展性方面下了不少功夫,它支持用户自定义内核(kernels)和优化策略,同时提供标准化的高性能算子库(如矩阵乘法、卷积等)。同时,Triton 可与 PyTorch 等深度学习框架集成,支持直接调用 Triton 内核。
在理念上,Triton 使用多级并行计算模型,借鉴 CUDA 的线程层次(thread blocks/grids),但通过更高层次的抽象(如 triton.program_id)简化编程。针对数据的局部性做优化,自动利用 GPU 的共享内存(shared memory)和寄存器,优化内存访问模式。Triton 把 LLVM 编译框架融合了进来,Triton 编译器将高级代码转换为优化的 PTX(NVIDIA GPU 的中间表示),同时结合了机器学习驱动的自动调优(auto-tuning)。在其前端,Triton 借助形式化程序语义,通过静态分析和程序变换确保代码的正确性和性能可预测性。
2. 基于预编译的包安装 triton
triton 通常跟 pytorch 一起使用;
2.1 安装 pytorch
安装一个基于 cuda 12.8 的 pytorch:
$ pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128需要下载 几个 GB 的包,网络好的话会比较快,或者下班前、睡觉前安装;
验证安装:
2.2 安装triton
pip install triton验证安装: 跑一个 tutorial 01:
$ wget https://triton-lang.org/main/_downloads/763344228ae6bc253ed1a6cf586aa30d/tutorials_python.zip
$ unzip ........
$ python ./01-vector-add.py运行结果应该如下:
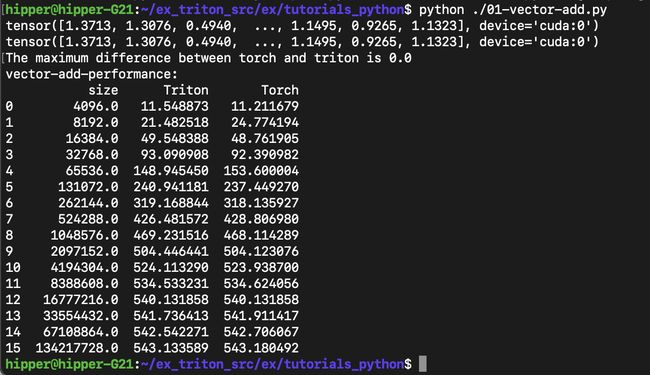
3. 通过 example 了解 triton
3.1 01-vector-add.py 的源码
"""
Vector Addition
===============
In this tutorial, you will write a simple vector addition using Triton.
In doing so, you will learn about:
* The basic programming model of Triton.
* The `triton.jit` decorator, which is used to define Triton kernels.
* The best practices for validating and benchmarking your custom ops against native reference implementations.
"""
# %%
# Compute Kernel
# --------------
import torch
import triton
import triton.language as tl
DEVICE = triton.runtime.driver.active.get_active_torch_device()
@triton.jit
def add_kernel(x_ptr, # *Pointer* to first input vector.
y_ptr, # *Pointer* to second input vector.
output_ptr, # *Pointer* to output vector.
n_elements, # Size of the vector.
BLOCK_SIZE: tl.constexpr, # Number of elements each program should process.
# NOTE: `constexpr` so it can be used as a shape value.
):
# There are multiple 'programs' processing different data. We identify which program
# we are here:
pid = tl.program_id(axis=0) # We use a 1D launch grid so axis is 0.
# This program will process inputs that are offset from the initial data.
# For instance, if you had a vector of length 256 and block_size of 64, the programs
# would each access the elements [0:64, 64:128, 128:192, 192:256].
# Note that offsets is a list of pointers:
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
# Create a mask to guard memory operations against out-of-bounds accesses.
mask = offsets < n_elements
# Load x and y from DRAM, masking out any extra elements in case the input is not a
# multiple of the block size.
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
# Write x + y back to DRAM.
tl.store(output_ptr + offsets, output, mask=mask)
# %%
# Let's also declare a helper function to (1) allocate the `z` tensor
# and (2) enqueue the above kernel with appropriate grid/block sizes:
def add(x: torch.Tensor, y: torch.Tensor):
# We need to preallocate the output.
output = torch.empty_like(x)
assert x.device == DEVICE and y.device == DEVICE and output.device == DEVICE
n_elements = output.numel()
# The SPMD launch grid denotes the number of kernel instances that run in parallel.
# It is analogous to CUDA launch grids. It can be either Tuple[int], or Callable(metaparameters) -> Tuple[int].
# In this case, we use a 1D grid where the size is the number of blocks:
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )
# NOTE:
# - Each torch.tensor object is implicitly converted into a pointer to its first element.
# - `triton.jit`'ed functions can be indexed with a launch grid to obtain a callable GPU kernel.
# - Don't forget to pass meta-parameters as keywords arguments.
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
# We return a handle to z but, since `torch.cuda.synchronize()` hasn't been called, the kernel is still
# running asynchronously at this point.
return output
# %%
# We can now use the above function to compute the element-wise sum of two `torch.tensor` objects and test its correctness:
torch.manual_seed(0)
size = 98432
x = torch.rand(size, device=DEVICE)
y = torch.rand(size, device=DEVICE)
output_torch = x + y
output_triton = add(x, y)
print(output_torch)
print(output_triton)
print(f'The maximum difference between torch and triton is '
f'{torch.max(torch.abs(output_torch - output_triton))}')
# %%
# Seems like we're good to go!
# %%
# Benchmark
# ---------
#
# We can now benchmark our custom op on vectors of increasing sizes to get a sense of how it does relative to PyTorch.
# To make things easier, Triton has a set of built-in utilities that allow us to concisely plot the performance of our custom ops.
# for different problem sizes.
@triton.testing.perf_report(
triton.testing.Benchmark(
x_names=['size'], # Argument names to use as an x-axis for the plot.
x_vals=[2**i for i in range(12, 28, 1)], # Different possible values for `x_name`.
x_log=True, # x axis is logarithmic.
line_arg='provider', # Argument name whose value corresponds to a different line in the plot.
line_vals=['triton', 'torch'], # Possible values for `line_arg`.
line_names=['Triton', 'Torch'], # Label name for the lines.
styles=[('blue', '-'), ('green', '-')], # Line styles.
ylabel='GB/s', # Label name for the y-axis.
plot_name='vector-add-performance', # Name for the plot. Used also as a file name for saving the plot.
args={}, # Values for function arguments not in `x_names` and `y_name`.
))
def benchmark(size, provider):
x = torch.rand(size, device=DEVICE, dtype=torch.float32)
y = torch.rand(size, device=DEVICE, dtype=torch.float32)
quantiles = [0.5, 0.2, 0.8]
if provider == 'torch':
ms, min_ms, max_ms = triton.testing.do_bench(lambda: x + y, quantiles=quantiles)
if provider == 'triton':
ms, min_ms, max_ms = triton.testing.do_bench(lambda: add(x, y), quantiles=quantiles)
gbps = lambda ms: 3 * x.numel() * x.element_size() * 1e-9 / (ms * 1e-3)
return gbps(ms), gbps(max_ms), gbps(min_ms)
# %%
# We can now run the decorated function above. Pass `print_data=True` to see the performance number, `show_plots=True` to plot them, and/or
# `save_path='/path/to/results/' to save them to disk along with raw CSV data:
benchmark.run(print_data=True, show_plots=True)3.2 01-vector-add.py 源码分析
业务逻辑从 Line: 86 开始:torch.manual_seed(0)
首先,设置随机函数的种子;
接着,定义了两个一维的 tensor 变量 x 和 y,并随机了其元素的值;
然后,使用 pytorch 的 + 算符计算了两个 tensor 的逐元素和: output_torch = x + y;
接下来,调用自定义 add 函数,使用 triton kernel 计算了两个 tensor 的逐元素和。
从 add 函数开始逐行注释一下:
@triton.jit
def add_kernel(x_ptr,
y_ptr,
output_ptr,
n_elements,
BLOCK_SIZE: tl.constexpr,
):
pid = tl.program_id(axis=0)# 相当于 cuda 中 blockId.x,axis=0 是指 x方向
block_start = pid * BLOCK_SIZE#当前block 在获取数据时的起始偏移
offsets = block_start + tl.arange(0, BLOCK_SIZE)#本 block 覆盖的偏移范围
mask = offsets < n_elements#offsets 的范围中,其值小于 n_el... 的话,mask 为true,否则为faulse
x = tl.load(x_ptr + offsets, mask=mask)# mask 为true的话,取值
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y#相加
tl.store(output_ptr + offsets, output, mask=mask)#mask 为 true的话,存回 DRAM
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x)# 定义一个shape 跟x一样的tensor 变量。
# 接下来检查 x,y,output 躺在的设备是否相同。
assert x.device == DEVICE and y.device == DEVICE and output.device == DEVICE
# 获取 output 这个 tensor 的元素个数,存在 n_elements 中。
n_elements = output.numel()
# 接下来两行代码将在正文中做一些解释:
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
return output
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )
逐条说明这句的要件:
这是一个动态计算网格大小的 lambda 函数
meta 参数是一个字典,包含内核的编译时常量(这里是 BLOCK_SIZE)
triton.cdiv 是 Triton 提供的向上取整除法函数,确保所有元素都被处理
grid 计算结果是一个元组,表示网格的维度(这里是1D网格)
lambda meta 的设计目标:
允许内核在不同块大小下复用,无需硬编码网格大小
使内核更加灵活,可以自动适应不同输入大小
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
工作方式:
[grid] 部分指定了网格计算函数
Triton 运行时会首先调用 grid({'BLOCK_SIZE': 1024}) 获取实际网格大小,然后启动相应数量的线程块。
然后到了 triton kernel 的函数头:
@triton.jit
def add_kernel(x_ptr,
y_ptr,
output_ptr,
n_elements,
BLOCK_SIZE: tl.constexpr,
):
tl.constexpr 的作用:
标记 BLOCK_SIZE 为编译时常量,在编译时而非运行时确定值
允许 Triton 编译器根据编译时常量进行优化(如循环展开)
函数体就不展开了,结合cuda 的编程方式,可以体会到很强的映射关系。
4. Triton 的 lambda meta 处理过程
Triton 的 lambda meta 语法不是原生 Python 语法,而是一种由 Triton 编译器专门设计的领域特定语言(DSL)扩展。其工作原理大致分为语法解析阶段、编译处理阶段、代码生成阶段:
4.1. 语法解析阶段
当 Triton 遇到 kernel[grid](args) 这种语法时:
step1: 装饰器拦截
@triton.jit 装饰器将 Python 函数标记为 Triton 内核
触发 Triton 的定制化解析流程
step2: AST 转换
Triton 使用 Python 的抽象语法树(AST)解析器获取代码结构
对 AST 进行转换,将特殊语法节点转换为 Triton 内部表示
step3: Lambda Meta 处理
识别 grid = lambda meta: ... 这种特殊模式
提取 lambda 函数体用于后续的网格计算
4.2. 编译时处理机制
网格计算 Lambda 的特殊处理
step1: 元参数字典构建
meta = {
'BLOCK_SIZE': 1024, # 从内核调用传入
# 其他可能的编译时常量...
}
step2: 符号化执行
Triton 编译器对 lambda 体进行符号化分析
将 meta['BLOCK_SIZE'] 替换为实际值(如1024)
计算 triton.cdiv(n_elements, BLOCK_SIZE)
step3: 延迟执行设计
不像普通 Python lambda 立即执行,Triton 在编译时捕获 lambda 表达式,在代码生成阶段才实际计算网格大小
4.3. 代码生成阶段
step1: 网格维度确定
调用 grid(meta) 获取具体网格形状,生成对应的 CUDA 网格启动配置
step2: 内核参数绑定
将 Python 参数(x,y,output)绑定到设备指针,并处理 tl.constexpr 参数的特殊传递
step3: PTX 生成
最终生成类似如下的设备代码结构:
define void @add_kernel(..., i32 %n_elements) {
%pid = call i32 @llvm.nvvm.read.ptx.sreg.ctaid.x()
%block_start = mul i32 %pid, 1024 // BLOCK_SIZE内联
...
}然后可以基于llvm内部后端模块生成PTX
5. triton lambda meta 与 python lambda 的对比
| 特性 | Python Lambda | Triton Lambda Meta |
| 执行时机 | 运行时立即执行 | 编译时延迟执行 |
| 参数类型 | 常规 Python 对象 | 特殊 meta 字典 |
| 可用操作 | 完整 Python 语法 | 受限的 Triton DSL 子集 |
| 优化方式 | 无特别优化 | 常量传播、循环展开等优化 |
| 返回值使用 | 直接使用返回值 | 用于配置内核启动参数 |
6. 设计原理深度解析
这种元编程范式,允许在编译时基于参数动态生成代码,以便实现"一次编写,多配置生成"的效果。
其中用到了编译时常量传播
# 用户代码
grid = lambda meta: (triton.cdiv(n, meta['SIZE']),)实际效果相当于
grid_size = (n + 1023) // 1024 # 当SIZE=1024时如上所述,对其解析涉及到多阶段编译:
阶段1:解析Python AST,识别Triton特殊结构
阶段2:处理lambda meta,确定并行参数
阶段3:生成优化后的设备代码
这种类型系统集成,其中,tl.constexpr 类型提示帮助编译器区分运行时变量(如n_elements)、编译时常量(如BLOCK_SIZE)
7. 使用常数特性实现性能优化
一些常用的 GPU 编程优化技巧,基于 meta 参数的常数性质,得到了实施。
基于 BLOCK_SIZE 的编译时已知性可以至少完成如下三种常用优化:
(1.) 支持完全展开内存加载/存储等循环体
(2.) 支持寄存器分配(若非已知,则需要使用数组的方式,在 global mem 或shared mem上分配空间)
offsets = block_start + tl.arange(0, BLOCK_SIZE)
# 可能被优化为寄存器数组而非内存操作
(3.) 用于边界检查的省略
当 n_elements % BLOCK_SIZE == 0 时
可以省略不必要的 mask 计算和相关分支检查代码的生成,自动进行性能优化
这种设计最终帮助 Triton 在保持 Python 前端简洁性的同时,能够生成与手工优化 CUDA 代码相媲美的高性能GPU代码。