【自然语言处理】文本规范化
目录
一、引言
二、分词
三、词规范化
四、分句
五、文本规范化的Python代码实战
六、总结
一、引言
在自然语言处理的许多任务中,第一步都离不开文本规范化。文本规范化的作用是将使用字符串表示的文本转化为更易于计算机处理的规范形式。文本规范化一般包括3个步骤:分词、词的规范化、分句。本文将分别介绍这3个步骤及Python代码实战。
二、分词
词是语言的基本单元,人类学习语言的过程也是从理解词开始的。显而易见,自然语言处理的第一步就是分词。分词是将一段以字符序列表示的文本转化成词元序列的过程。将文本转化成多个词元后,就完成了对文本的初步结构化,以便计算机以词元为基本的单位对文本进行处理。在自然语言处理中,词元并不一定等同于词。根据不同分词方法的定义,词元可以是字符、子词、词等。
(一)基于空格与标点符号的分词
在以英语为代表的印欧语系中,大部分语言都是使用空格字符来分词。因此一种非常简单的方式就是基于空格进行分词。例如:
输入语句:I am an enthusiast in natural language processing, I like learning Natural Language Processing.
基于空格的分词结果:['I', 'am', 'an', 'enthusiast', 'in', 'natural', 'language', 'processing,', 'I', 'like', 'learning', 'Natural', 'Language', 'Processing.']
我们可以发现,最简单的基于空格分词方法无法将词与词后面的标点符号进行分割。如果标点符号对于后续任务(如文本分类)并不重要,可以去除标点符号后再进一步分词。
输入语句:I am an enthusiast in natural language processing, I like learning Natural Language Processing.
去掉标点符号的句子:I am an enthusiast in natural language processing I like learning Natural Language Processing
基于空格与标点符号的分词结果:['I', 'am', 'an', 'enthusiast', 'in', 'natural', 'language', 'processing', 'I', 'like', 'learning', 'Natural', 'Language', 'Processing']
然而,在有些情况下将标点符号去除往往会造成许多错误,例如一些英文名称缩写、本身词带有标点、价格、日期、链接、标签和电子邮件等。因此,如果仅仅将标点符号去除,那么词就有可能失去了它本身的含义。此外,很多时候我们也希望将多个词看成一个词元,例如Natural Language Processing、Machine Learning。解决这些问题需要用到基于正则表达式的分词方法。
(二)基于正则表达式的分词
正则表达式使用单个字符串(通常称为“模式”,即pattern)来描述、匹配对应文本中完全匹配某个指定规则的字符串。在文本编辑器中,正则表达式常用于检索、替换哪些匹配某个模式的文本。每一个正则表达式的符号都有其明确的含义。
符号'\w'的含义:匹配任意单词字符(26个英文字母的大小写、0~9数字、下划线_),正则表达式等价于[a-zA-Z0-9_]。
符号'\W'的含义:匹配任意非单词字符,\w的补集。
符号'\d'的含义:匹配任意0~9数字字符,正则表达式等价于[0-9]。
符号'\D'的含义:匹配任意非数字字符,\d的补集。
符号‘\s'的含义:匹配空格字符。
符号'\S'的含义:匹配任意非空格字符,\s的补集。
符号'.'的含义:匹配任意字符。
符号'+'的含义:匹配前面的表达式1次或多次。
符号'*'的含义:匹配前面的表达式0次或多次。
符号'?'的含义:匹配前面的表达式0次或1次。
符号'{m}'的含义:匹配前面的表达式恰好m次,m可以为任意整数。
符号'{m,n}'的含义:匹配前面的表达式m~n次,m和n可以为任意正整数,且m 符号'{m,}'的含义:匹配前面的表达式m次及以上,m可以为任意正整数。 符号'|'的含义:或运算符。 符号'(...)'的含义:表示1个组合,匹配时只返回括号内部分。 符号'\1'的含义:表示返回第1个组合。 符号'\2'的含义:表示返回第2个组合。 符号'(?:...)'的含义:表示1个组合,匹配时不保留括号内部分。 符号'[...]'的含义:匹配中括号内的1个字符。 符号'\'的含义:正则表达式中,一些字符(如:^$.?+*()[])有特殊含义,因此在表示原字符时,需要在其前面加上转义字符\。 针对复杂文本(含网址、货币、连接符、省略号等),通过逐步升级正则模式提升分词精度: (三)基于BPE的词元学习器 给定一个词表,其包含所有的字符(如{A,B,C,D,...,a,b,c,d,...}),词元学习器重复以下步骤来构建词表: 1.找出在训练语料库中最长相连的两个符号,这里称其为“ 2.将新组合的符号“ 3.将训练语料库中所有相连的“ 4.重复步骤1~步骤3k次。 (四)基于BPE的词元分词器 得到学习到的词表之后,给定一个新的句子,根据词表中每个字符学到的顺序,使用BPE词元分词器贪心地将字符组合起来。 所谓词规范化就是指将词或词元变成标准形式的过程,也是自然语言处理中必不可少的一部分,将词统一成标准格式可以让计算机更容易理解文本。这种方式的好处是可以减小词表、去除冗余信息、让词义相近的两个词共享相同的特征表示等。 (一)大小写折叠 大小写折叠是将所有的英文大写字母转化成小写字母的过程。在搜索场景中,用户往往喜欢使用小写字母的形式,而在计算机中,大写字母和小写字母并非同一字符,当遇到用户想要搜索一些人名、地名等带有大写字母的专有名词的情况时,若不将小写字母转换成大写,可能难以匹配正确的搜索结果。 (二)词目还原 在诸如英文这样的语言中,很多单词都会根据不同的主语、语境、时态等情形修改为相应的形态,而这些单词本身表达的含义是接近甚至相同的,例如英文中的am、is、are都可以还原成be,英文名词cat根据不同情形有cat、cats、cat's、cats'等多种形态。这些形态对文本的语义影响相对较小,但是大幅提高了词表的大小,因而提高了自然语言模型的构建成本。因此在有些文本处理问题上,需要将所有的词进行词目还原,即找出词的原型。人类在学习这些语言的过程中,可以通过词典查找词的原型;类似的,计算机可以通过构建词典来进行词目还原。 更精确的词目还原基于语素分析。在语言学中,语素是语言中最小的有意义或有语法功能的单位。以中文为例,“自”“然”“语”“言”“处”和“理”这5个语素就组合成了“自然语言处理”这个词。在英文中,情况会有些不一样,英文中的很多单词是由词干和词缀组成的。词干是表达主要含义的语素,而词缀一般和词干连接,表达了附加的含义。例如unbelievable这个词,由“un”(词缀,表示否定)、“believ”(表示believe,词干,表示相信)和“able”(词缀,表示可能的)组成,三者合起来的意思是“不可置信的”。想要准确地抽取出词的词根和词干,就需要使用语素分析。 (三)词干还原 词干还原是将词变成词干的过程。词干还原是一种简单快速的词目还原的方式,通过将所有的词缀直接移除来获取词干。为了保持词干的完整性,波特词干还原器提出了一套基于改写规则的方法来进行词干还原,一共有多个处理阶段: 阶段 1:处理复数和过去分词后缀 阶段 2:处理形容词和副词后缀 阶段 3:处理名词后缀(-ation, -ition 等) 阶段 4:处理更复杂的名词 / 动词后缀(-ment, -ence 等) 阶段 5:处理后缀 “-e” 的简化 阶段 6:处理词尾辅音的双写简化 很多实际场景中,我们往往需要处理很长的文本,例如新闻、财报、日志等。计算机若直接同时处理整个文本会非常困难,因此需要将文本分成许多句子后再分别进行处理。对于分句问题,最常见的方法是根据标点符号来分割文本,例如“!”“?”“。”等标点符号。然而,在某些语言中,个别分句的标点符号会有歧义,例如英文中的句号“.”也同时有省略符(如“Inc.”“Ph.D.”“Mr.”等)、小数点(如“3.5”“.3%”)等含义。这些歧义会导致分句困难。为了解决这种问题,常见的方案是先进行分词,使用基于正则表达式或者基于机器学习的分词方法将文本分解成词元,然后基于标点符号判断句子边界。 先运行下面代码下载可能要用到的模型 (一)文本规范化的基本实现 文本规范化是将原始文本转换为统一、规整形式的过程,代码涵盖的核心方法如下: 分词(Tokenization) 分句(Sentence Segmentation) 子词处理 大小写统一 词形规范化 这些方法共同作用,可将原始文本转换为适合模型输入的规范化形式,提升 NLP 任务(如分类、翻译)的效果。 Python代码如下: 程序运行结果如下: 输入语句:I am an enthusiast in natural language processing, I like learning Natural Language Processing. 迭代后的词频统计表为: ------------------------------------- 迭代后的词频统计表为: ------------------------------------- 迭代后的词频统计表为: ------------------------------------- 迭代后的词频统计表为: ------------------------------------- 迭代后的词频统计表为: ------------------------------------- 迭代后的词频统计表为: ------------------------------------- 迭代后的词频统计表为: ------------------------------------- 迭代后的词频统计表为: ------------------------------------- 迭代后的词频统计表为: ------------------------------------- 原始单词 手动还原结果 NLTK还原结果 结果已保存到 '词干还原结果对比.md' 文件 (二)文本规范化的高级功能实现 1.基础依赖与资源准备 (1)NLTK 资源管理:自动检测并下载 NLP 处理所需的基础资源(如分词模型 (2)第三方库依赖:使用 2.文本预处理核心功能 工具实现了多种文本规范化操作,覆盖从 “分词” 到 “词形归一化” 的全流程: (1) 分词(Tokenization) 提供 4 种分词方法,可通过 GUI 选择: (2) 词干还原(Stemming) 将单词去除后缀,提取核心词干(结果可能不是完整单词),提供两种实现: (3) 词形还原(Lemmatization) 将单词还原为语法正确的基本形式(词目),结合词性提升准确性: 3.GUI 界面功能 工具通过 (1)输入区域:一个带滚动条的文本框,用于输入原始英文文本(默认提供示例文本)。 (2)处理选项区:单选按钮选择分词方法(空格 / 正则 / NLTK/BPE),支持灵活切换预处理策略。 (3)执行按钮:点击 “执行文本规范化” 触发处理流程,自动完成分词、词干还原、词形还原。 (4)结果展示区: 4.整体工作流程 (1)用户在输入框中填写或修改英文文本。 (2)选择所需的分词方法(如 NLTK 分词或 BPE 分词) (3)点击执行按钮后,工具自动完成: (4)结果同步显示在表格和详情框中,用户可直观查看规范化效果。 Python代码如下: 程序运行结果如下: 本文系统介绍了自然语言处理中的文本规范化技术,包括分词、词规范化和分句三大核心步骤。在分词方面,详细阐述了基于空格、正则表达式和BPE算法的不同处理方法,并比较了它们的优缺点。词规范化部分重点讲解了大小写折叠、词目还原和词干还原等技术,通过Python代码展示了实际应用效果。文章还提供了完整的文本规范化工具实现,包含GUI界面和多种分词算法选择功能,并对比了手动与NLTK库的词干还原效果。实验结果表明,结合正则表达式和NLTK工具的混合方法能有效处理复杂文本的规范化需求,为后续NLP任务提供高质量的输入数据。
pattern1(\w+):匹配字母 / 数字组成的单词,但无法处理特殊符号(如 $、.、')。pattern2(\w+|\S\w*):增加对非空白字符开头的单词(如中的)的支持。pattern3(\w+(?:[-']\w+)*):支持含连字符 / 撇号的单词(如 don't、state-of-the-art)。pattern4:结合 pattern2 和 pattern3,同时处理特殊符号开头和连接符单词。pattern5:新增匹配网址的模式(?:\w+\.)+\w+(?:\.)*,优先匹配网址。pattern6:新增匹配货币 / 百分比(如$3.4)的模式\$?\d+(?:.\d+)?%?\,优先处理数值符号。pattern7:新增匹配英文省略号(...)的模式,最终实现对复杂文本的精准分词。 ”和“
”和“ ”。
”。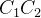 ”加入词表中。”和“”转换成“”。
”加入词表中。”和“”转换成“”。三、词规范化
四、分句
五、文本规范化的Python代码实战
import nltk
nltk.download('punkt') # 下载英文分句模型
nltk.download('punkt_tab')
nltk.download('tagsets')
nltk.download('tagsets_json')
nltk.download('averaged_perceptron_tagger')
nltk.help.upenn_tagset()
nltk.download('averaged_perceptron_tagger_eng')
nltk.tokenize)。
lower()):消除大小写差异,统一文本格式。
import re # 引入正则表达式包
import nltk # 引入自然语言处理NLP工具包
# 引入NLTK分词器、lemmatizer,引入wordnet还原动词
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
from nltk.tokenize import regexp_tokenize
sentence1 = "I am an enthusiast in natural language processing, I like learning Natural Language Processing."
print(f'输入语句:{sentence1}')
# 基于空格的分词
tokens1 = sentence1.split(' ')
print(f'基于空格的分词结果:{tokens1}')
# 去掉句子的“,”和“.”
sentence2 = re.sub(r'\,|\.', '', sentence1)
print(f'去掉标点符号的句子:{sentence2}')
tokens2 = sentence2.split(' ')
print(f'基于空格与标点符号的分词结果:{tokens2}')
sentence3 = "Did you spend $3.4 on arxiv.org for your pre-print?"+" No, it's free! It's..."
pattern1 = r"\w+"
print(f'输入语句:{sentence3}')
print(f'基于正则表达式1的分词结果:{re.findall(pattern1, sentence3)}')
pattern2 = r"\w+|\S\w*"
print(f'基于正则表达式2的分词结果:{re.findall(pattern2, sentence3)}')
pattern3 = r"\w+(?:[-']\w+)*"
print(f'基于正则表达式3的分词结果:{re.findall(pattern3, sentence3)}')
pattern4 = r"\w+(?:[-']\w+)*|\S\w*"
print(f'基于正则表达式4的分词结果:{re.findall(pattern4, sentence3)}')
# 新的匹配模式
new_pattern4 = r"(?:\w+\.)+\w+(?:\.)*"
pattern5 = new_pattern4 + r"|" + pattern4
print(f'基于正则表达式5的分词结果:{re.findall(pattern5, sentence3)}')
# 新的匹配模式,匹配货币或百分比符号
new_pattern5 = r"\$?\d+(?:\.\d+)?%?"
pattern6 = new_pattern5 + r"|" + new_pattern4 + r"|" + pattern5
print(f'基于正则表达式6的分词结果:{re.findall(pattern6, sentence3)}')
# 新的匹配模式,匹配英文省略号
new_pattern6 = r"\.\.\."
pattern7 = new_pattern6 + r"|" + new_pattern5 + r"|" + new_pattern4 + r"|" + pattern6
print(f'基于正则表达式7的分词结果:{re.findall(pattern7, sentence3)}')
tokens = regexp_tokenize(sentence3, pattern7)
print(f'基于自然语言处理的工具包的分词结果:{tokens}')
# 分句
sentence3_spliter = set([".", "?", '!', '...'])
tokens3 = regexp_tokenize(sentence3, pattern7)
sentences = []
boundary = [0]
for token_id, token in enumerate(tokens3):
# 判断句子边界
if token in sentence3_spliter:
# 如果是句子边界,则把分句结果加入进去
sentences.append(tokens3[boundary[-1]:token_id+1])
# 将下一句句子的起始位置加入boundary
boundary.append(token_id+1)
if boundary[-1] != len(tokens3):
sentences.append(tokens3[boundary[-1]:])
print('分句结果:')
for seg_sentence in sentences:
print(seg_sentence)
# 基于子词的分词
print('基于BPE的词元学习器')
corpus = "nan nan nan nan nan nanjing nanjing beijing beijing " + "beijing beijing beijing beijing dongbei dongbei dongbei bei bei"
tokens = corpus.split(' ')
# 构建基于字符的初始此表
vocabulary = set(corpus)
vocabulary.remove(' ')
vocabulary.add('_')
vocabulary = sorted(list(vocabulary))
# 根据语料构建词频统计表
corpus_dict = {}
for token in tokens:
key = token + '_'
if key not in corpus_dict:
corpus_dict[key] = {"split": list(key), "count": 0}
corpus_dict[key]['count'] += 1
print('语料:')
for key in corpus_dict:
print(corpus_dict[key]['count'], corpus_dict[key]['split'])
print(f'词表:{vocabulary}')
for step in range(9):
# 将每一步结果都输出,令max_print_step = 999
max_print_step = 999
if step < max_print_step or step == 8:
print(f'第{step + 1}次迭代')
split_dict = {}
for key in corpus_dict:
splits = corpus_dict[key]['split']
# 遍历所有符号进行统计
for i in range(len(splits) - 1):
# 组合两个符号作为新的符号
current_group = splits[i] + splits[i + 1]
if current_group not in split_dict:
split_dict[current_group] = 0
split_dict[current_group] += corpus_dict[key]['count']
group_hist = [(k, v) for k, v in sorted(split_dict.items(), key=lambda item: item[1], reverse=True)]
if step < max_print_step or step == 8:
print(f'当前最常出现的前5个符号组合:{group_hist[:5]}')
merge_key = group_hist[0][0]
if step < max_print_step or step == 8:
print(f'本次迭代组合的符号为:{merge_key}')
for key in corpus_dict:
if merge_key in key:
new_splits = []
splits = corpus_dict[key]['split']
i = 0
while i < len(splits):
if i + 1 >= len(splits):
new_splits.append(splits[i])
i += 1
continue
if merge_key == splits[i] + splits[i + 1]:
new_splits.append(merge_key)
i += 2
else:
new_splits.append(splits[i])
i += 1
corpus_dict[key]['split'] = new_splits
vocabulary.append(merge_key)
if step < max_print_step or step == 8:
print()
print('迭代后的词频统计表为:')
for key in corpus_dict:
print(corpus_dict[key]['count'], corpus_dict[key]['split'])
print(f'词表:{vocabulary}')
print()
print('-------------------------------------')
# 基于BPE的词元分词器
print('基于BPE的词元分词器')
ordered_vocabulary = {key: x for x, key in enumerate(vocabulary)}
sentence = "nanjing beijing"
print(f'输入语句:{sentence}')
tokens = sentence.split(' ')
tokenized_string = []
for token in tokens:
key = token + '_'
splits = list(key)
# 用于在没有更新的时候跳出
flag = 1
while flag:
flag = 0
split_dict = {}
# 遍历所有符号进行统计
for i in range(len(splits) - 1):
# 组合两个符号作为新的符号
current_group = splits[i] + splits[i + 1]
if current_group not in ordered_vocabulary:
continue
if current_group not in split_dict:
# 判断当前组合是否在词表里,如果是的话加入split_dict
split_dict[current_group] = ordered_vocabulary[current_group]
flag = 1
if not flag:
continue
# 对每个组合进行优先级的排序(此处为从低到高)
group_hist = [(k, v) for k, v in sorted(split_dict.items(), key=lambda item: item[1])]
# 优先级最高的组合
merge_key = group_hist[0][0]
new_splits = []
i = 0
# 根据优先级最高的组合产生新的分词
while i < len(splits):
if i + 1 >= len(splits):
new_splits.append(splits[i])
i += 1
continue
if merge_key == splits[i] + splits[i + 1]:
new_splits.append(merge_key)
i += 2
else:
new_splits.append(splits[i])
i += 1
splits = new_splits
tokenized_string += splits
print(f'分词结果:{tokenized_string}')
# 大小写折叠
print('大小写折叠')
sentence = "Let's study Natural Language Processing."
print(f'原句:{sentence}')
print(f'大小写折叠后的句子:{sentence.lower()}')
print('词目还原')
print('构建词典进行词目还原')
# 构建词典
lemma_dict = {'am': 'be', 'is': 'be', 'are': 'be', 'cats': 'cat', "cats'": 'cat', "cat's": 'cat',
'dogs': 'dog', "dogs'": 'dog', "dog's": 'dog', 'chasing': "chase"}
sentence = "Two dogs are chasing three cats"
words = sentence.split(' ')
print(f'词目还原前:{words}')
lemmatized_words = []
for word in words:
if word in lemma_dict:
lemmatized_words.append(lemma_dict[word])
else:
lemmatized_words.append(word)
print(f'词目还原后:{lemmatized_words}')
print('利用NLTK自带的词典来进行词目还原')
# 下载分词包、wordnet包
nltk.download('punkt', quiet=True)
nltk.download('wordnet', quiet=True)
lemmatizer = WordNetLemmatizer()
sentence = "Two dogs are chasing three cats"
words = word_tokenize(sentence)
print(f'词目还原前:{words}')
lemmatized_words = []
for word in words:
lemmatized_words.append(lemmatizer.lemmatize(word, wordnet.VERB))
print(f'词目还原后:{lemmatized_words}')
print('词干还原')
# 词干还原实现:手动方法与NLTK方法对比
def manual_stemmer(word):
"""
手动实现的简单词干还原函数
基于规则法去除常见后缀,仅支持英语单词
"""
try:
word = word.lower()
length = len(word)
# 规则1: 处理复数形式
if length > 3 and word.endswith('ies'):
return word[:-3] + 'y' # 将ies转换为y (如babies → babi → 简化处理为baby的词干bab)
if word.endswith('sses'):
return word[:-2] # addresses → address
if not word.endswith('ss') and word.endswith('s') and length > 2:
return word[:-1] # 一般复数形式 (cats → cat)
# 规则2: 处理过去式和过去分词 (-ed)
if length > 2 and word.endswith('ed'):
# 特殊情况处理: 双写辅音结尾 (stopped → stop)
if length > 4 and word[-3] == word[-4] and word[-4] not in 'aeiou':
return word[:-3]
return word[:-2] # walked → walk
# 规则3: 处理现在分词 (-ing)
if length > 4 and word.endswith('ing'):
# 特殊情况处理: 双写辅音结尾 (running → run)
if word[-4] == word[-5] and word[-5] not in 'aeiou':
return word[:-4]
return word[:-3] # eating → eat
# 规则4: 处理形容词比较级和最高级 (-er, -est)
if length > 3 and word.endswith('est'):
return word[:-3] # fastest → fast
if length > 2 and word.endswith('er'):
return word[:-2] # faster → fast
# 规则5: 处理副词 (-ly)
if length > 3 and word.endswith('ly'):
return word[:-2] # quickly → quick
# 规则6: 处理名词后缀 (-ment, -ness)
if length > 5 and word.endswith('ment'):
return word[:-4] # development → develop
if length > 4 and word.endswith('ness'):
return word[:-4] # happiness → happy
return word
except Exception as e:
print(f"手动还原错误({word}): {str(e)}")
return word
def nltk_stemmer(word):
"""
使用NLTK库的PorterStemmer实现词干还原
"""
try:
import nltk
from nltk.stem import PorterStemmer
# 下载必要资源
try:
nltk.data.find('tokenizers/punkt')
except LookupError:
print("正在下载NLTK资源...")
nltk.download('punkt', quiet=True)
print("NLTK资源下载完成")
stemmer = PorterStemmer()
return stemmer.stem(word.lower())
except Exception as e:
print(f"NLTK还原错误({word}): {str(e)}")
return word
if __name__ == "__main__":
test_words = [
"cats", "running", "walked", "quickly", "happiness",
"better", "lying", "geese", "development", "jumping",
"stopped", "eaten", "friendship", "happily", "stronger"
]
print("词干还原结果对比 (手动实现 vs NLTK PorterStemmer)\n")
print(f"{'原始单词':<15} {'手动还原结果':<15} {'NLTK还原结果':<15}")
print("-" * 50)
for word in test_words:
try:
manual_result = manual_stemmer(word)
nltk_result = nltk_stemmer(word)
print(f"{word:<15} {manual_result:<15} {nltk_result:<15}")
except Exception as e:
print(f"处理单词 {word} 时出错: {str(e)}")
# 尝试保存结果
try:
with open("词干还原结果对比.md", "w", encoding="utf-8") as f:
f.write("# 词干还原结果对比\n\n")
f.write("## 手动实现 vs NLTK PorterStemmer\n\n")
f.write("| 原始单词 | 手动还原结果 | NLTK还原结果 |\n")
f.write("|----------|--------------|--------------|\n")
for word in test_words:
manual_result = manual_stemmer(word)
nltk_result = nltk_stemmer(word)
f.write(f"| {word} | {manual_result} | {nltk_result} |\n")
print("\n结果已保存到 '词干还原结果对比.md' 文件")
except Exception as e:
print(f"保存文件时出错: {str(e)}")
基于空格的分词结果:['I', 'am', 'an', 'enthusiast', 'in', 'natural', 'language', 'processing,', 'I', 'like', 'learning', 'Natural', 'Language', 'Processing.']
去掉标点符号的句子:I am an enthusiast in natural language processing I like learning Natural Language Processing
基于空格与标点符号的分词结果:['I', 'am', 'an', 'enthusiast', 'in', 'natural', 'language', 'processing', 'I', 'like', 'learning', 'Natural', 'Language', 'Processing']
输入语句:Did you spend $3.4 on arxiv.org for your pre-print? No, it's free! It's...
基于正则表达式1的分词结果:['Did', 'you', 'spend', '3', '4', 'on', 'arxiv', 'org', 'for', 'your', 'pre', 'print', 'No', 'it', 's', 'free', 'It', 's']
基于正则表达式2的分词结果:['Did', 'you', 'spend', '$3', '.4', 'on', 'arxiv', '.org', 'for', 'your', 'pre', '-print', '?', 'No', ',', 'it', "'s", 'free', '!', 'It', "'s", '.', '.', '.']
基于正则表达式3的分词结果:['Did', 'you', 'spend', '3', '4', 'on', 'arxiv', 'org', 'for', 'your', 'pre-print', 'No', "it's", 'free', "It's"]
基于正则表达式4的分词结果:['Did', 'you', 'spend', '$3', '.4', 'on', 'arxiv', '.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '.', '.', '.']
基于正则表达式5的分词结果:['Did', 'you', 'spend', '$3', '.4', 'on', 'arxiv.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '.', '.', '.']
基于正则表达式6的分词结果:['Did', 'you', 'spend', '$3.4', 'on', 'arxiv.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '.', '.', '.']
基于正则表达式7的分词结果:['Did', 'you', 'spend', '$3.4', 'on', 'arxiv.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '...']
基于自然语言处理的工具包的分词结果:['Did', 'you', 'spend', '$3.4', 'on', 'arxiv.org', 'for', 'your', 'pre-print', '?', 'No', ',', "it's", 'free', '!', "It's", '...']
分句结果:
['Did', 'you', 'spend', '$3.4', 'on', 'arxiv.org', 'for', 'your', 'pre-print', '?']
['No', ',', "it's", 'free', '!']
["It's", '...']
基于BPE的词元学习器
语料:
5 ['n', 'a', 'n', '_']
2 ['n', 'a', 'n', 'j', 'i', 'n', 'g', '_']
6 ['b', 'e', 'i', 'j', 'i', 'n', 'g', '_']
3 ['d', 'o', 'n', 'g', 'b', 'e', 'i', '_']
2 ['b', 'e', 'i', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o']
第1次迭代
当前最常出现的前5个符号组合:[('ng', 11), ('be', 11), ('ei', 11), ('ji', 8), ('in', 8)]
本次迭代组合的符号为:ng
5 ['n', 'a', 'n', '_']
2 ['n', 'a', 'n', 'j', 'i', 'ng', '_']
6 ['b', 'e', 'i', 'j', 'i', 'ng', '_']
3 ['d', 'o', 'ng', 'b', 'e', 'i', '_']
2 ['b', 'e', 'i', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng']
第2次迭代
当前最常出现的前5个符号组合:[('be', 11), ('ei', 11), ('ji', 8), ('ing', 8), ('ng_', 8)]
本次迭代组合的符号为:be
5 ['n', 'a', 'n', '_']
2 ['n', 'a', 'n', 'j', 'i', 'ng', '_']
6 ['be', 'i', 'j', 'i', 'ng', '_']
3 ['d', 'o', 'ng', 'be', 'i', '_']
2 ['be', 'i', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng', 'be']
第3次迭代
当前最常出现的前5个符号组合:[('bei', 11), ('ji', 8), ('ing', 8), ('ng_', 8), ('na', 7)]
本次迭代组合的符号为:bei
5 ['n', 'a', 'n', '_']
2 ['n', 'a', 'n', 'j', 'i', 'ng', '_']
6 ['bei', 'j', 'i', 'ng', '_']
3 ['d', 'o', 'ng', 'bei', '_']
2 ['bei', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng', 'be', 'bei']
第4次迭代
当前最常出现的前5个符号组合:[('ji', 8), ('ing', 8), ('ng_', 8), ('na', 7), ('an', 7)]
本次迭代组合的符号为:ji
5 ['n', 'a', 'n', '_']
2 ['n', 'a', 'n', 'ji', 'ng', '_']
6 ['bei', 'ji', 'ng', '_']
3 ['d', 'o', 'ng', 'bei', '_']
2 ['bei', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng', 'be', 'bei', 'ji']
第5次迭代
当前最常出现的前5个符号组合:[('jing', 8), ('ng_', 8), ('na', 7), ('an', 7), ('beiji', 6)]
本次迭代组合的符号为:jing
5 ['n', 'a', 'n', '_']
2 ['n', 'a', 'n', 'jing', '_']
6 ['bei', 'jing', '_']
3 ['d', 'o', 'ng', 'bei', '_']
2 ['bei', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng', 'be', 'bei', 'ji', 'jing']
第6次迭代
当前最常出现的前5个符号组合:[('jing_', 8), ('na', 7), ('an', 7), ('beijing', 6), ('n_', 5)]
本次迭代组合的符号为:jing_
5 ['n', 'a', 'n', '_']
2 ['n', 'a', 'n', 'jing_']
6 ['bei', 'jing_']
3 ['d', 'o', 'ng', 'bei', '_']
2 ['bei', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng', 'be', 'bei', 'ji', 'jing', 'jing_']
第7次迭代
当前最常出现的前5个符号组合:[('na', 7), ('an', 7), ('beijing_', 6), ('n_', 5), ('bei_', 5)]
本次迭代组合的符号为:na
5 ['na', 'n', '_']
2 ['na', 'n', 'jing_']
6 ['bei', 'jing_']
3 ['d', 'o', 'ng', 'bei', '_']
2 ['bei', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng', 'be', 'bei', 'ji', 'jing', 'jing_', 'na']
第8次迭代
当前最常出现的前5个符号组合:[('nan', 7), ('beijing_', 6), ('n_', 5), ('bei_', 5), ('do', 3)]
本次迭代组合的符号为:nan
5 ['nan', '_']
2 ['nan', 'jing_']
6 ['bei', 'jing_']
3 ['d', 'o', 'ng', 'bei', '_']
2 ['bei', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng', 'be', 'bei', 'ji', 'jing', 'jing_', 'na', 'nan']
第9次迭代
当前最常出现的前5个符号组合:[('beijing_', 6), ('nan_', 5), ('bei_', 5), ('do', 3), ('ong', 3)]
本次迭代组合的符号为:beijing_
5 ['nan', '_']
2 ['nan', 'jing_']
6 ['beijing_']
3 ['d', 'o', 'ng', 'bei', '_']
2 ['bei', '_']
词表:['_', 'a', 'b', 'd', 'e', 'g', 'i', 'j', 'n', 'o', 'ng', 'be', 'bei', 'ji', 'jing', 'jing_', 'na', 'nan', 'beijing_']
基于BPE的词元分词器
输入语句:nanjing beijing
分词结果:['nan', 'jing_', 'beijing_']
大小写折叠
原句:Let's study Natural Language Processing.
大小写折叠后的句子:let's study natural language processing.
词目还原
构建词典进行词目还原
词目还原前:['Two', 'dogs', 'are', 'chasing', 'three', 'cats']
词目还原后:['Two', 'dog', 'be', 'chase', 'three', 'cat']
利用NLTK自带的词典来进行词目还原
词目还原前:['Two', 'dogs', 'are', 'chasing', 'three', 'cats']
词目还原后:['Two', 'dog', 'be', 'chase', 'three', 'cat']
词干还原
词干还原结果对比 (手动实现 vs NLTK PorterStemmer)
--------------------------------------------------
cats cat cat
running run run
walked walk walk
quickly quick quickli
happiness happi happi
better bett better
lying ly lie
geese geese gees
development develop develop
jumping jump jump
stopped stop stop
eaten eaten eaten
friendship friendship friendship
happily happi happili
stronger strong stronger
punkt、词形还原词典wordnet、词性标注模型averaged_perceptron_tagger),确保分词、词形还原等功能正常运行。re处理正则表达式分词,tkinter构建 GUI 界面,nltk提供专业 NLP 工具(分词器、词干提取器、词形还原器等)。
r"\w+(?:[-']\w+)*|\$?\d+(?:\.\d+)?%?|\.\.\.|(?:\w+\.)+\w+"),支持处理含连字符(如state-of-the-art)、货币(如$3.4)、网址(如arxiv.org)、省略号(...)等特殊字符的文本。nltk.tokenize.word_tokenize,基于预训练模型进行更精准的分词(如将don't拆分为don和't)。nanjing、beijing等)训练子词表,可处理未登录词(如陌生人名、地名),将其拆分为有意义的子词(如nanjing→nan+jing+_)。
s、过去式ed、分词ing、比较级er等),例如running→run、happiness→happi。PorterStemmer,通过成熟的规则库处理词干(如development→develop、quickly→quickli)。
nltk.pos_tag获取单词词性(名词、动词、形容词等),再使用WordNetLemmatizer根据词性还原(如动词chasing→chase,名词dogs→dog)。tkinter构建直观的交互界面,各组件功能如下:
import re
import nltk
import tkinter as tk
from tkinter import ttk, scrolledtext, messagebox
from nltk.tokenize import word_tokenize, regexp_tokenize
from nltk.stem import WordNetLemmatizer, PorterStemmer
from nltk.corpus import wordnet
# 确保下载必要的NLTK资源
def download_nltk_resources():
required_resources = [
('punkt', 'tokenizers/punkt'),
('wordnet', 'corpora/wordnet'),
('averaged_perceptron_tagger', 'taggers/averaged_perceptron_tagger')
]
for resource_name, resource_path in required_resources:
try:
nltk.data.find(resource_path)
except LookupError:
try:
nltk.download(resource_name, quiet=True)
except Exception as e:
messagebox.showerror("资源下载错误", f"无法下载NLTK资源 {resource_name}: {str(e)}")
# 手动词干还原实现
def manual_stemmer(word):
word = word.lower()
length = len(word)
# 复数处理
if length > 3 and word.endswith('ies'):
return word[:-3] + 'y'
if word.endswith('sses'):
return word[:-2]
if not word.endswith('ss') and word.endswith('s') and length > 2:
return word[:-1]
# 过去式和过去分词 (-ed)
if length > 2 and word.endswith('ed'):
if length > 4 and word[-3] == word[-4] and word[-4] not in 'aeiou':
return word[:-3]
return word[:-2]
# 现在分词 (-ing)
if length > 4 and word.endswith('ing'):
if word[-4] == word[-5] and word[-5] not in 'aeiou':
return word[:-4]
return word[:-3]
# 形容词比较级和最高级 (-er, -est)
if length > 3 and word.endswith('est'):
return word[:-3]
if length > 2 and word.endswith('er'):
return word[:-2]
# 副词 (-ly)
if length > 3 and word.endswith('ly'):
return word[:-2]
# 名词后缀 (-ment, -ness)
if length > 5 and word.endswith('ment'):
return word[:-4]
if length > 4 and word.endswith('ness'):
return word[:-4]
return word
# NLTK词干还原实现
def nltk_stemmer(word):
stemmer = PorterStemmer()
return stemmer.stem(word.lower())
# 获取单词的词性以提高词形还原准确性
def get_wordnet_pos(treebank_tag):
if treebank_tag.startswith('J'):
return wordnet.ADJ
elif treebank_tag.startswith('V'):
return wordnet.VERB
elif treebank_tag.startswith('N'):
return wordnet.NOUN
elif treebank_tag.startswith('R'):
return wordnet.ADV
else:
return wordnet.NOUN
# 词形还原函数
def lemmatize_word(word, pos_tag):
lemmatizer = WordNetLemmatizer()
wordnet_pos = get_wordnet_pos(pos_tag)
return lemmatizer.lemmatize(word, wordnet_pos)
# BPE分词实现
class BPE:
def __init__(self, corpus=None):
self.vocabulary = None
self.ordered_vocabulary = None
if corpus:
self.train(corpus)
def train(self, corpus, iterations=9):
tokens = corpus.split()
vocabulary = set(corpus)
vocabulary.discard(' ')
vocabulary.add('_')
self.vocabulary = sorted(list(vocabulary))
# 构建词频统计
corpus_dict = {}
for token in tokens:
key = token + '_'
if key not in corpus_dict:
corpus_dict[key] = {"split": list(key), "count": 0}
corpus_dict[key]['count'] += 1
# BPE迭代合并
for _ in range(iterations):
split_dict = {}
for key in corpus_dict:
splits = corpus_dict[key]['split']
for i in range(len(splits) - 1):
current_group = splits[i] + splits[i + 1]
if current_group not in split_dict:
split_dict[current_group] = 0
split_dict[current_group] += corpus_dict[key]['count']
if not split_dict:
break
group_hist = sorted(split_dict.items(), key=lambda x: x[1], reverse=True)
merge_key = group_hist[0][0]
self.vocabulary.append(merge_key)
for key in corpus_dict:
splits = corpus_dict[key]['split']
new_splits = []
i = 0
while i < len(splits):
if i + 1 >= len(splits):
new_splits.append(splits[i])
i += 1
continue
if merge_key == splits[i] + splits[i + 1]:
new_splits.append(merge_key)
i += 2
else:
new_splits.append(splits[i])
i += 1
corpus_dict[key]['split'] = new_splits
self.ordered_vocabulary = {key: idx for idx, key in enumerate(self.vocabulary)}
def tokenize(self, text):
if not self.ordered_vocabulary:
raise ValueError("BPE模型尚未训练,请先提供语料进行训练")
tokens = text.split()
tokenized = []
for token in tokens:
key = token + '_'
splits = list(key)
flag = 1
while flag:
flag = 0
split_dict = {}
for i in range(len(splits) - 1):
current_group = splits[i] + splits[i + 1]
if current_group in self.ordered_vocabulary:
split_dict[current_group] = self.ordered_vocabulary[current_group]
flag = 1
if not flag:
break
group_hist = sorted(split_dict.items(), key=lambda x: x[1])
merge_key = group_hist[0][0]
new_splits = []
i = 0
while i < len(splits):
if i + 1 >= len(splits):
new_splits.append(splits[i])
i += 1
continue
if merge_key == splits[i] + splits[i + 1]:
new_splits.append(merge_key)
i += 2
else:
new_splits.append(splits[i])
i += 1
splits = new_splits
tokenized.extend(splits)
return tokenized
# 主GUI应用类
class TextNormalizerApp:
def __init__(self, root):
self.root = root
self.root.title("文本规范化工具")
self.root.geometry("1000x700")
self.root.resizable(True, True)
# 初始化BPE模型
self.bpe = BPE()
self.init_bpe_model()
# 初始化NLTK资源
download_nltk_resources()
# 创建界面组件
self.create_widgets()
def init_bpe_model(self):
# 使用预设语料训练BPE模型
corpus = "nan nan nan nan nan nanjing nanjing beijing beijing " + \
"beijing beijing beijing beijing dongbei dongbei dongbei bei bei"
self.bpe.train(corpus)
def create_widgets(self):
# 创建主框架
main_frame = ttk.Frame(self.root, padding="10")
main_frame.pack(fill=tk.BOTH, expand=True)
# 输入区域
input_frame = ttk.LabelFrame(main_frame, text="输入文本", padding="10")
input_frame.pack(fill=tk.X, pady=(0, 10))
self.input_text = scrolledtext.ScrolledText(input_frame, height=5, wrap=tk.WORD)
self.input_text.pack(fill=tk.X, expand=True)
self.input_text.insert(tk.END,
"I am an enthusiast in natural language processing, I like learning Natural Language Processing.")
# 选项区域
options_frame = ttk.LabelFrame(main_frame, text="处理选项", padding="10")
options_frame.pack(fill=tk.X, pady=(0, 10))
# 分词选项
ttk.Label(options_frame, text="分词方法:").grid(row=0, column=0, sticky=tk.W, padx=(0, 10))
self.tokenization_var = tk.StringVar(value="nltk")
tokenization_frame = ttk.Frame(options_frame)
tokenization_frame.grid(row=0, column=1, sticky=tk.W)
ttk.Radiobutton(tokenization_frame, text="空格分词", variable=self.tokenization_var, value="space").pack(
side=tk.LEFT, padx=5)
ttk.Radiobutton(tokenization_frame, text="正则表达式", variable=self.tokenization_var, value="regex").pack(
side=tk.LEFT, padx=5)
ttk.Radiobutton(tokenization_frame, text="NLTK分词器", variable=self.tokenization_var, value="nltk").pack(
side=tk.LEFT, padx=5)
ttk.Radiobutton(tokenization_frame, text="BPE分词", variable=self.tokenization_var, value="bpe").pack(
side=tk.LEFT, padx=5)
# 处理按钮
button_frame = ttk.Frame(main_frame)
button_frame.pack(fill=tk.X, pady=(0, 10))
ttk.Button(button_frame, text="执行文本规范化", command=self.process_text).pack(side=tk.RIGHT)
# 结果显示区域
result_frame = ttk.LabelFrame(main_frame, text="处理结果", padding="10")
result_frame.pack(fill=tk.BOTH, expand=True)
# 创建结果表格
columns = ("original", "manual_stem", "nltk_stem", "lemma")
self.result_tree = ttk.Treeview(result_frame, columns=columns, show="headings")
# 设置列标题
self.result_tree.heading("original", text="原始单词")
self.result_tree.heading("manual_stem", text="手动词干还原")
self.result_tree.heading("nltk_stem", text="NLTK词干还原")
self.result_tree.heading("lemma", text="词目还原")
# 设置列宽
self.result_tree.column("original", width=150)
self.result_tree.column("manual_stem", width=150)
self.result_tree.column("nltk_stem", width=150)
self.result_tree.column("lemma", width=150)
# 添加滚动条
scrollbar_y = ttk.Scrollbar(result_frame, orient=tk.VERTICAL, command=self.result_tree.yview)
scrollbar_x = ttk.Scrollbar(result_frame, orient=tk.HORIZONTAL, command=self.result_tree.xview)
self.result_tree.configure(yscroll=scrollbar_y.set, xscroll=scrollbar_x.set)
# 布局表格和滚动条
scrollbar_y.pack(side=tk.RIGHT, fill=tk.Y)
scrollbar_x.pack(side=tk.BOTTOM, fill=tk.X)
self.result_tree.pack(fill=tk.BOTH, expand=True)
# 详细结果文本框
self.details_text = scrolledtext.ScrolledText(main_frame, height=8, wrap=tk.WORD)
self.details_text.pack(fill=tk.X, pady=(10, 0))
self.details_text.insert(tk.END, "处理详情将显示在这里...")
self.details_text.config(state=tk.DISABLED)
def get_tokens(self, text):
token_method = self.tokenization_var.get()
if token_method == "space":
return text.split(' ')
elif token_method == "regex":
pattern = r"\w+(?:[-']\w+)*|\$?\d+(?:\.\d+)?%?|\.\.\.|(?:\w+\.)+\w+"
return regexp_tokenize(text, pattern)
elif token_method == "nltk":
return word_tokenize(text)
elif token_method == "bpe":
return self.bpe.tokenize(text)
return []
def process_text(self):
# 清空之前的结果
for item in self.result_tree.get_children():
self.result_tree.delete(item)
self.details_text.config(state=tk.NORMAL)
self.details_text.delete(1.0, tk.END)
# 获取输入文本
input_text = self.input_text.get(1.0, tk.END).strip()
if not input_text:
messagebox.showwarning("输入警告", "请输入要处理的文本")
return
try:
# 分词处理
tokens = self.get_tokens(input_text)
token_method = self.tokenization_var.get()
token_method_name = {
"space": "空格分词",
"regex": "正则表达式分词",
"nltk": "NLTK分词器",
"bpe": "BPE分词"
}[token_method]
self.details_text.insert(tk.END, f"分词方法: {token_method_name}\n")
self.details_text.insert(tk.END, f"分词结果: {tokens}\n\n")
# 获取词性标注以提高词形还原准确性
tagged_words = nltk.pos_tag(tokens)
# 处理每个单词
for word, pos_tag in tagged_words:
# 词干和词形还原
manual_stem = manual_stemmer(word) if word.strip() else ""
nltk_stem = nltk_stemmer(word) if word.strip() else ""
lemma = lemmatize_word(word, pos_tag) if word.strip() else ""
# 添加到结果表格
self.result_tree.insert("", tk.END, values=(word, manual_stem, nltk_stem, lemma))
self.details_text.insert(tk.END, "文本规范化完成!\n")
except Exception as e:
messagebox.showerror("处理错误", f"处理文本时出错: {str(e)}")
self.details_text.insert(tk.END, f"错误: {str(e)}\n")
self.details_text.config(state=tk.DISABLED)
if __name__ == "__main__":
root = tk.Tk()
app = TextNormalizerApp(root)
root.mainloop()




六、总结