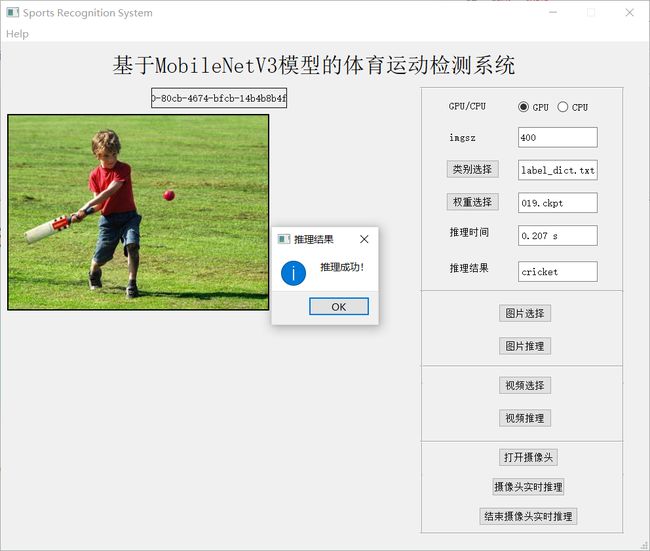
【MobileNet v3 可视化界面】在电脑上实现可视化界面
【MobileNet v3 可视化界面】在电脑上实现可视化界面
一、PyQt5库安装
PyQt5库的安装,可以查看这篇文章:完全弄懂如何用pycharm安装pyqt5及其相关配置
二、界面设置

三、功能链接
GPU or CPU 选择
def GPU_CPU(self):
"""
选择 GPU or CPU
:return:
"""
selected_button = self.widget.sender()
if selected_button is not None and isinstance(selected_button, QRadioButton):
self.device = selected_button.text()
# 保存旧值
old_parameter = self.save_parameter.copy()
# 更新新值
self.save_parameter["device"] = self.device
# 如果参数值有变化
if old_parameter != self.save_parameter:
# 更新旧值
self.pre_parameter = old_parameter模型类别和权重选择
def SelectData(self):
"""
模型类别选择
:return:
"""
self.data_file_name, _ = QFileDialog.getOpenFileName(self, "选择类别文件", "", "所有文件(*.txt)")
if self.data_file_name:
self.label_6.setText(os.path.split(self.data_file_name)[-1])
old_parameter = self.save_parameter.copy()
self.save_parameter["label_txt"] = self.data_file_name
if old_parameter != self.save_parameter:
self.pre_parameter = old_parameter
def SelectWeights(self):
"""
模型权重选择
:return:
"""
self.weights_file_name, _ = QFileDialog.getOpenFileName(self, "选择权重文件", "",
"所有文件(*.pt *.onnx *.ckpt)")
if self.weights_file_name:
self.label_7.setText(os.path.split(self.weights_file_name)[-1])
old_parameter = self.save_parameter.copy()
self.save_parameter["weights"] = self.weights_file_name
if old_parameter != self.save_parameter:
self.pre_parameter = old_parameter图片/视频处理
class LoadImages:
def __init__(self, path, img_size=224):
self.path = path
self.img_size = img_size
IMG_FORMATS = 'bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp', 'pfm' # include image suffixes
VID_FORMATS = 'asf', 'avi', 'gif', 'm4v', 'mkv', 'mov', 'mp4', 'mpeg', 'mpg', 'ts', 'wmv' # include video suffixes
images, videos = [], []
if self.path.split('.')[-1].lower() in IMG_FORMATS:
images = [self.path]
if self.path.split('.')[-1].lower() in VID_FORMATS:
videos = [self.path]
ni, nv = len(images), len(videos)
self.nf = ni + nv # number of files
self.video_flag = [False] * ni + [True] * nv
self.transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((self.img_size + 20, self.img_size + 20), Image.Resampling.NEAREST),
transforms.CenterCrop((self.img_size, self.img_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
if any(videos):
self.cap = cv2.VideoCapture(videos[0])
self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
else:
self.cap = None
def __iter__(self):
self.count = 0
return self
def __next__(self):
if self.count == self.nf:
raise StopIteration
if self.video_flag[self.count]:
# 指向下一帧
self.cap.grab()
# 解码,并返回函数cv2.VideoCapture.grab()捕获的视频帧
ret_val, im0 = self.cap.retrieve()
while not ret_val:
self.count += 1
self.cap.release()
if self.count == self.nf: # last video
raise StopIteration
else:
self.count += 1
im0 = cv2.imread(self.path) # BGR
start_time = time.time()
img = self.transforms(im0)
img = torch.unsqueeze(img, dim=0)
return im0, img, self.cap, start_time
def __len__(self):
return self.nf摄像头处理
class LoadStreams:
def __init__(self, sources='0', img_size=224):
self.img_size = img_size
self.sources = [sources]
self.transforms = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((self.img_size + 20, self.img_size + 20), Image.Resampling.NEAREST),
transforms.CenterCrop((self.img_size, self.img_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
def __iter__(self):
self.count = 0
return self
def __next__(self):
if self.count == len(self.sources):
raise StopIteration
s_time = time.time()
im0 = self.sources[0]
img = self.transforms(im0)
img = torch.unsqueeze(img, dim=0)
self.count += 1
return im0, img, False, s_time
def __len__(self):
return len(self.sources)显示结果
for org_img, img0, video_vap, s_time in dataset:
output = torch.squeeze(infer_model(img0.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).tolist()
if not cap_flag:
label_9.setText(str(round(time.time() - s_time, 4)) + " s")
label_11.setText(str(class_dict[predict_cla]))
_print(f"推理图片源:{infer_path},推理结果:{class_dict[predict_cla]},推理时间:{round(time.time() - s_time, 4)} s")
else:
time_text = f"infer time:{round(time.time() - s_time, 4)}"
result_text = f"infer result:{class_dict[predict_cla]}"
org_img = cv2.putText(org_img, time_text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255, 0, 0), 1)
org_img = cv2.putText(org_img, result_text, (10, 60), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255, 0, 0), 1)
frame = cv2.cvtColor(org_img, cv2.COLOR_BGR2RGB)
image = QImage(frame, org_img.shape[1], org_img.shape[0], QImage.Format_RGB888)
frame_pixmap = QPixmap.fromImage(image)
label_3.setPixmap(frame_pixmap.scaled(label_3.size(), Qt.KeepAspectRatio))
label_9.setText(str(round(time.time() - s_time, 4)) + " s")
label_11.setText(str(class_dict[predict_cla]))
if os.path.isfile(infer_path):
_print(f"推理视频源:{infer_path.split('.')[0]}_{count}.{infer_path.split('.')[-1]},推理结果:{class_dict[predict_cla]},推理时间:{round(time.time() - s_time, 4)} s")
else:
_print(f"推理摄像头源:{infer_path}_{count},推理结果:{class_dict[predict_cla]},推理时间:{round(time.time() - s_time, 4)} s")四、相关界面