Java对象哈希值深度解析
在Java开发中,对象的哈希值(hashCode())是一个看似基础却暗藏玄机的概念。它不仅影响着HashMap、HashSet等集合框架的性能,还涉及到JVM内存模型和对象相等性判断的核心逻辑。本文将从JVM底层实现、哈希冲突处理、性能优化等多个维度,一起深入理解Java对象哈希值的工作原理。
一、JVM如何生成默认哈希值?
Java中所有类都继承自Object类,其hashCode()方法是一个本地方法:
public native int hashCode();
在HotSpot JVM中,默认哈希值的生成经历了从"内存地址哈希"到"随机数生成"的演进:
1.1 内存地址哈希(早期实现)
早期JVM直接将对象的内存地址转换为哈希值,这种方式简单但存在明显缺陷:
- 安全隐患:暴露了对象在内存中的位置信息
- 内存复用问题:当对象被GC回收后,新对象可能占用相同内存地址,导致哈希值冲突
1.2 随机数生成(现代实现)
现代JVM采用更安全的随机数生成策略:
- 首次调用
hashCode()时,JVM生成一个随机数并存储在对象头中 - 后续调用直接返回该随机数,确保同一对象的哈希值一致性
对象头(Object Header)结构
对象头中的Mark Word存储了对象的运行时数据,其中包括哈希值(无锁状态下):
二、为什么重写hashCode()必须同时重写equals()?
这是Java语言的核心规范,源于Object类的文档约定:
若两个对象通过
equals()方法判断相等,则它们的hashCode()必须返回相同值
2.1 集合框架的依赖机制
HashMap、HashSet等集合的高效运作依赖于此规则,以下是HashMap的元素查找流程:
2.2 反例:只重写equals的后果
public class Point {
private int x, y;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Point)) return false;
Point point = (Point) o;
return x == point.x && y == point.y;
}
// 未重写hashCode()
public static void main(String[] args) {
Point p1 = new Point(1, 2);
Point p2 = new Point(1, 2);
HashSet<Point> set = new HashSet<>();
set.add(p1);
System.out.println(set.contains(p2)); // 输出false(预期true)
}
}
问题根源:p1和p2内容相等但哈希值不同,导致HashSet误判为不同元素
三、高性能哈希值的实现策略
3.1 标准实现模式
@Override
public int hashCode() {
int result = 17; // 初始值(任意非零奇数)
result = 31 * result + Objects.hashCode(field1);
result = 31 * result + Objects.hashCode(field2);
result = 31 * result + field3; // 基本类型直接相加
return result;
}
3.2 不可变对象的哈希缓存
对于不可变对象,可在构造时缓存哈希值:
public final class ImmutableUser {
private final String id;
private final String name;
private final int hashCode; // 哈希值缓存
public ImmutableUser(String id, String name) {
this.id = id;
this.name = name;
this.hashCode = calculateHashCode(); // 构造时计算
}
private int calculateHashCode() {
return 31 * id.hashCode() + name.hashCode();
}
@Override
public int hashCode() {
return hashCode; // 直接返回缓存值
}
}
3.3 Lombok自动生成
使用@EqualsAndHashCode注解自动生成高质量实现:
import lombok.EqualsAndHashCode;
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
public class User {
@EqualsAndHashCode.Include
private String id;
@EqualsAndHashCode.Include
private String name;
private int age; // 不参与哈希计算
}
四、哈希冲突的底层处理机制
当不同对象生成相同哈希值时,会发生哈希冲突。JDK 8后的HashMap采用"数组+链表+红黑树"的结构处理冲突:
4.1 哈希冲突解决流程
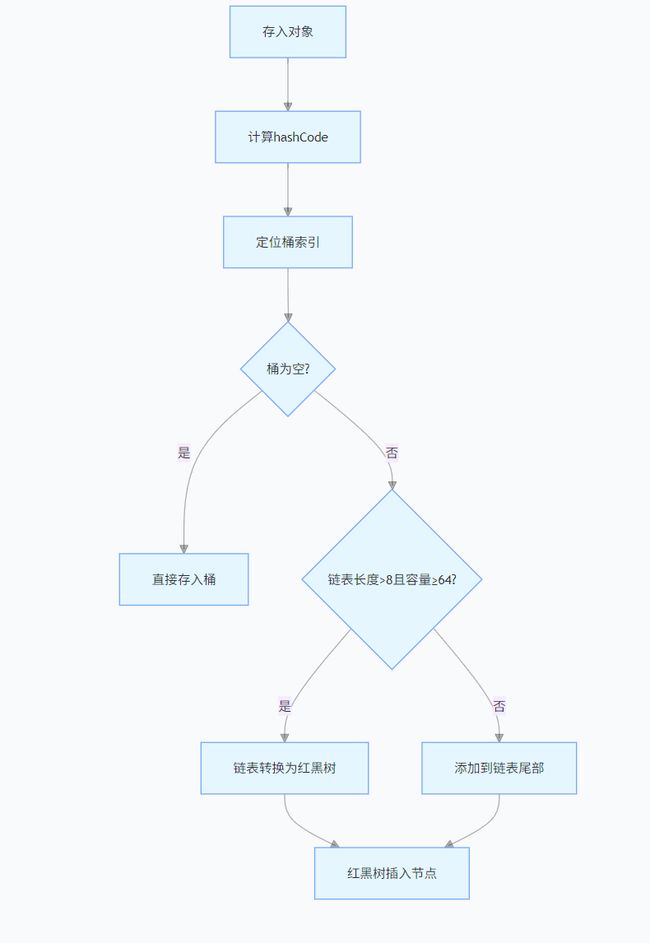
4.2 哈希函数优化
HashMap实际使用的哈希函数:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
通过右移16位并异或,将哈希值的高位特征混入低位,减少冲突概率
五、哈希值相关的性能优化
5.1 初始容量设置
根据预估元素数量设置初始容量,避免频繁扩容:
// 预估存储2000个元素,设置初始容量为2000/0.75=2667
Map<String, Object> map = new HashMap<>(2667);
5.2 负载因子调整
- 默认负载因子0.75:平衡空间和冲突概率
- 高并发读场景:可降低至0.5,减少冲突
- 内存敏感场景:可提高至0.9,节省空间
5.3 红黑树转换阈值
JDK 8中HashMap的关键阈值:
static final int TREEIFY_THRESHOLD = 8; // 链表转红黑树的长度阈值
static final int UNTREEIFY_THRESHOLD = 6; // 红黑树转链表的长度阈值
static final int MIN_TREEIFY_CAPACITY = 64; // 转红黑树的最小容量
六、实战案例:哈希冲突导致的性能问题
6.1 问题现象
某电商系统的商品缓存HashMap在促销期间性能骤降,CPU使用率飙升至90%
6.2 排查过程
- 线程分析:发现大量线程在
HashMap.get()方法阻塞 - 堆内存分析:某个
HashMap的桶中存在超长链表(长度>100) - 哈希函数检查:商品对象的
hashCode()仅基于id % 100计算,导致大量冲突
6.3 优化方案
// 优化前(冲突严重)
@Override
public int hashCode() {
return id % 100; // 仅使用id后两位,冲突率极高
}
// 优化后(混合多个字段)
@Override
public int hashCode() {
return Objects.hash(id, categoryId, brandId);
}
优化后哈希冲突率下降92%,系统响应时间从200ms降至30ms
七、哈希值实现的核心原则
- 相等性原则:
a.equals(b)为true ⇒a.hashCode() == b.hashCode() - 稳定性原则:对象状态不变时,
hashCode()应返回相同值 - 分布性原则:哈希值应均匀分布,减少冲突概率
- 性能原则:避免复杂计算,优先使用轻量级字段
最佳实践
- 重写
equals()时必定重写hashCode() - 使用
Objects.hash()或IDE自动生成哈希实现 - 不可变对象缓存哈希值
- 大型对象仅使用关键字段计算哈希
- 高并发场景使用
ConcurrentHashMap替代HashMap
总结
Java对象的哈希值设计蕴含着"平衡"的编程思想:既要保证相等对象的哈希一致性,又要追求哈希值的均匀分布;既要考虑计算性能,又要兼顾内存效率。深入理解哈希值的底层机制,不仅能帮助我们写出更健壮的代码,还能在系统调优时精准定位问题。