FocalNet:焦点调制网络

摘要
我们提出了焦点调制网络(简称 FocalNets),在该网络中,自注意力(self-attention,SA)被完全替换为焦点调制模块,用于建模视觉中的 token 交互。焦点调制由三个组件组成:(i)焦点上下文化(focal contextualization),通过一组深度可分离卷积层实现,用于从短程到长程编码视觉上下文;(ii)门控聚合(gated aggregation),选择性地将上下文聚合到每个查询 token 的调制器中;(iii)逐元素仿射变换(element-wise affine transformation),将调制器注入查询中。大量实验证明,FocalNets 表现出非凡的可解释性(如图1所示),并在图像分类、目标检测和分割任务中,以相似的计算成本超越了 SoTA 的 SA 架构(如 Swin 和 Focal Transformers)。具体而言,tiny 和 base 规模的 FocalNets 在 ImageNet-1K 上分别达到 82.3% 和 83.9% 的 top-1 准确率。在以 224² 分辨率于 ImageNet-22K 上预训练后,分别在 224² 和 384² 分辨率微调时可达到 86.5% 和 87.3% 的 top-1 准确率。在使用 Mask R-CNN [29] 进行目标检测时,1× 训练的 FocalNet base 相比于 Swin 对应模型高出 2.1 个点,且已超过使用 3× 训练策略的 Swin(49.0 对 48.5)。在使用 UPerNet [90] 进行语义分割时,单尺度下的 FocalNet base 比 Swin 高出 2.4,在多尺度下也优于 Swin(50.5 对 49.7)。使用大型 FocalNet 和 Mask2former [13],我们在 ADE20K 语义分割中达到了 58.5 的 mIoU,在 COCO 全景分割中达到了 57.9 的 PQ。使用巨型 FocalNet 和 DINO [106],我们在 COCO minival 和 test-dev 上分别实现了 64.3 和 64.4 的 mAP,在更大规模的注意力模型(如 Swinv2-G [53] 和 BEIT-3 [84])之上建立了新的 SoTA。这些令人振奋的结果表明,focal modulation 很可能正是视觉任务中所需要的关键模块。

1 引言
Transformers [79] 最初是为自然语言处理(NLP)提出的,自从开创性的 Vision Transformer(ViT)[22] 出现以来,已成为计算机视觉中的主流架构。其在图像分类 [75, 82, 89, 54, 108, 78]、目标检测 [3, 120, 114, 18]、分割 [80, 86, 14] 及其他任务 [45, 112, 4, 9, 81, 41] 中表现出了强大的潜力。在 Transformers 中,self-attention(SA)可以说是其成功的关键,因为它能实现依赖输入的全局交互,而卷积操作则限制在局部区域内,使用共享卷积核进行交互。尽管 SA 拥有上述优势,其效率问题仍受到广泛关注,尤其是在处理高分辨率输入时,其复杂度随视觉 token 数量呈二次增长。
为了解决这个问题,已有许多工作通过 token 粗化 [82]、窗口注意力 [54, 78, 108]、动态 token 选择 [60, 98, 59],或混合方法 [95, 15] 提出了多种 SA 变体。与此同时,还有不少模型通过引入(深度可分离)卷积来增强 SA,以便在更好感知局部结构的同时捕捉长距离依赖关系 [89, 25, 94, 23, 21, 40, 7, 20]。
本工作旨在回答一个基础性的问题:是否存在比 SA 更优的方法,用于建模依赖输入的长距离交互?我们从对当前高级 SA 设计的分析入手。在图2左侧,我们展示了 ViTs [22] 和 Swin Transformer [54] 中常用的(基于窗口的)注意力机制,该机制在红色 query token 与其周围橙色 token 之间执行注意力操作。为了产生输出,SA 需要进行密集的 query-key 交互(红色箭头),随后是同样密集的 query-value 聚合(黄色箭头),这些都涉及 query 与空间上分布广泛的 token(上下文特征)之间的运算。然而,是否有必要执行如此密集的交互与聚合?
在本工作中,我们采用一种替代方法:首先围绕每个 query 焦点式地聚合上下文,然后用聚合的上下文自适应地调制 query。如图2右侧所示,我们可以简单地对输入应用与 query 无关的焦点聚合操作(如深度卷积),以在不同粒度层次上生成汇总的 token。随后,这些汇总 token 被自适应地聚合为一个 modulator,最后注入到 query 中。这种改进仍然可以实现依赖输入的 token 交互,但通过将聚合从各个 query 中解耦,大大简化了交互过程,从而使交互仅基于少量特征而变得轻量化。
我们的方法受到 focal attention [95] 的启发,后者通过多层次聚合来捕捉细粒度和粗粒度的视觉上下文。但我们的方法在每个 query 位置提取 modulator,并在 query 与 modulator 的交互上采用了更简单的方式。我们将这一新机制称为 Focal Modulation,并以此构建了一个无需注意力的架构:Focal Modulation Network,简称 FocalNet。
最后,我们在图像分类、目标检测和分割任务上进行了大量实验,结果显示我们的 FocalNet 在计算成本相当的情况下,持续且显著地超越 SoTA 的 SA 架构。值得注意的是,FocalNet 在使用 tiny 和 base 模型规模时,分别实现了 82.3% 和 83.9% 的 top-1 准确率,其吞吐量分别与 Swin 和 Focal Transformer 相当或翻倍。在 ImageNet-22K 上以 224² 分辨率预训练后,FocalNet 在 224² 和 384² 分辨率微调时分别实现了 86.5% 和 87.3% 的准确率,与 Swin 相比具有相当或更优的性能。
这一优势在迁移到密集预测任务时尤为明显。在 COCO [49] 上的目标检测任务中,我们的 tiny 和 base FocalNet 分别在 Mask R-CNN 1× 设置下实现了 46.1 和 49.0 的 box mAP,超过 Swin 在 3× 设置下的表现(46.0 和 48.5 的 box mAP)。在 ADE20k [118] 上的语义分割任务中,使用 base FocalNet 在单尺度评估中实现了 50.5 的 mIoU,优于 Swin 在多尺度评估中的表现(49.7 的 mIoU)。基于预训练的大型 FocalNet,我们在 ADE20K 上实现了 58.5 的 mIoU,在 COCO 全景分割任务中基于 Mask2former [12] 实现了 57.9 的 PQ。使用巨型 FocalNet 和 DINO [106],我们在 COCO 的 minival 和 test-dev 上分别实现了 64.3 和 64.4 的 mAP,超越了如 Swinv2-G [53] 和 BEIT-3 [84] 等更大型的基于注意力的模型,在 COCO 上建立了新的 SoTA。请见图3中的视觉对比以及实验部分中的详细结果。
最后,我们在与 ViTs 相同的单体布局下应用了 Focal Modulation,并清晰展示了其在不同模型规模下的优越性。

2 相关工作
Self-attention(自注意力)
Transformer [79] 首次在 Vision Transformer(ViT)[22] 中引入到视觉任务中,通过将图像划分为一系列视觉 token。ViT 中的 self-attention(SA)策略在训练过程中使用优化的配方 [22, 75],其性能已经超过了现代卷积神经网络(ConvNets),如 ResNet [30]。之后,提出了多尺度架构 [5, 82, 94]、轻量级卷积层 [89, 25, 46]、局部 self-attention 机制 [54, 108, 15, 95] 和可学习的注意力权重 [101],这些方法都旨在提升性能并支持高分辨率输入。更多的综合性综述可见 [38, 27, 38]。我们的 focal modulation 与 SA 有显著不同,主要体现在:首先从不同粒度的层次聚合上下文,然后调制各个 query token,从而实现一种无需注意力的 token 交互机制。在上下文聚合方面,我们的方法受 focal attention [95] 启发。然而,focal modulation 中的上下文聚合是在每个 query 位置执行的,而不是在目标位置进行,并且是通过调制而非注意力进行处理。这些机制上的差异大大提高了效率和性能。另一个相关的工作是 Poolformer [100],它使用池化操作来总结局部上下文,并通过简单的减法调整个别输入。尽管 Poolformer 在效率上表现不错,但在性能上却落后于像 Swin 这样的流行视觉 Transformer。正如我们所展示的,捕捉不同层次的局部结构是至关重要的。
MLP 架构
视觉 MLP 可以分为两类:(i)全局混合 MLP,如 MLP-Mixer [72] 和 ResMLP [74],通过空间级别的投影进行视觉 token 之间的全局通信,并通过各种技术增强,如门控、路由和傅里叶变换 [51, 58, 70, 71];(ii)局部混合 MLP,通过采样附近的 token 进行交互,使用空间位移、排列和伪核混合 [99, 32, 48, 8, 26]。最近,MixShift-MLP [113] 结合了局部和全局交互,类似于 focal attention [95] 的思想。MLP 架构和我们的 focal modulation 网络都不依赖于注意力。然而,focal modulation 通过多层次的上下文聚合自然地捕捉短距离和长距离的结构,因此在精度和效率的权衡上表现更好。
卷积
卷积神经网络(ConvNets)是深度神经网络在计算机视觉领域复兴的主要驱动力。自从 VGG [63]、InceptionNet [67] 和 ResNet [30] 出现以来,该领域发展迅速。聚焦于卷积网络效率的代表性工作包括 MobileNet [33]、ShuffleNet [111] 和 EfficientNet [69]。另一类工作则致力于将全局上下文融入到卷积网络中,以弥补其不足,如 SE-Net [35]、Non-local Network [85]、GCNet [2]、LR-Net [34] 和 C3Net [97] 等。引入动态操作是增强卷积网络的另一种方式,例如 Involution [43] 和 DyConv [10]。近年来,卷积神经网络也通过两个方面“反击”:(i)卷积层与 SA 结合并带来了显著的性能提升 [89, 25, 46, 23],或反之 [76];(ii)通过使用类似的数据增强和正则化策略,ResNet 缩小了与 ViT 的差距 [88],并且将 SA 替换为(动态)深度卷积 [28, 55] 也能稍微超越 Swin。我们的 focal modulation 网络也利用了深度卷积作为微架构,但通过引入多层次的上下文聚合和依赖输入的调制,超越了传统卷积网络。我们将展示这一新模块在性能上远超原始的卷积网络。
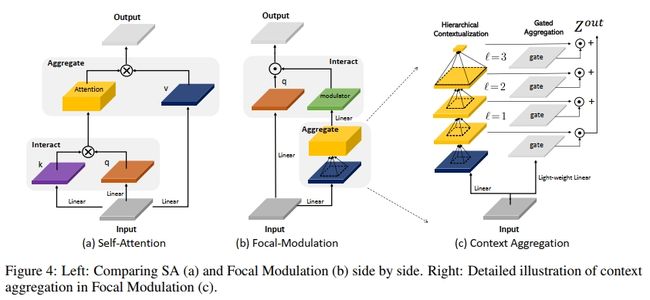
3 焦点调制网络
3.1 从 Self-Attention 到 Focal Modulation
给定一个视觉特征图 X ∈ R H × W × C \mathbf{X} \in \mathbb{R}^{H \times W \times C} X∈RH×W×C 作为输入,一个通用的编码过程为每个视觉 token(查询) x i ∈ R C \pmb { x } _ { i } \in \mathbb { R } ^ { C } xi∈RC 生成一个特征表示 y i ∈ R C \pmb{y}_i \in \mathbb{R}^{C} yi∈RC,通过与其周围环境(例如,邻近的 tokens)交互的过程 T \mathcal{T} T 和在上下文上的聚合过程 M \mathcal{M} M。
Self-Attention(自注意力)
Self-Attention 模块使用后聚合过程,公式为:
y i = M 1 ( T 1 ( x i , X ) , X ) ( 1 ) \pmb { y } _ { i } = \mathcal { M } _ { 1 } ( \mathcal { T } _ { 1 } ( \pmb { x } _ { i } , \pmb { X } ) , \pmb { X } )\quad(1) yi=M1(T1(xi,X),X)(1)
其中,聚合 M 1 \mathcal{M}_1 M1 是在计算查询和目标之间的注意力得分(通过交互 T 1 \mathcal{T}_1 T1)后,基于上下文 X \mathbf{X} X 进行的。
Focal Modulation(焦点调制)
相比之下,Focal Modulation 通过一个早期的聚合过程生成精细的表示 y i { \bf y }_i yi,公式为:
y i = T 2 ( M 2 ( i , X ) , x i ) ( 2 ) \pmb { y } _ { i } = T _ { 2 } ( \mathcal { M } _ { 2 } ( i , \mathbf { X } ) , \pmb { x } _ { i } ) \quad(2) yi=T2(M2(i,X),xi)(2)
在这里,上下文特征首先使用 M 2 \mathcal{M}_2 M2 在每个位置 i i i 聚合,然后查询通过 T 2 \mathcal{T}_2 T2 与聚合后的特征进行交互,形成最终的表示 y i { \bf y }_i yi。
通过比较式(1)和式(2),我们可以看到以下几点:
(i) Focal Modulation 的上下文聚合操作 M 2 \mathcal{M}_2 M2 通过共享操作符(例如,深度卷积)进行上下文计算,从而减少计算量;而 Self-Attention 中的聚合操作 M 1 \mathcal{M}_1 M1 则更加计算密集,因为它需要对不可共享的注意力得分进行求和,或者在不同查询之间进行求和;
(ii) 交互过程 T 2 \mathcal{T}_2 T2 是一个轻量级的操作,仅涉及 token 和其上下文之间的交互,而 Self-Attention 中的交互过程 T 1 \mathcal{T}_1 T1 涉及计算 token 之间的注意力得分,其复杂度是二次的。
基于式(2),我们将我们的 Focal Modulation 实现为:
y i = q ( x i ) ⊙ m ( i , X ) ( 3 ) \pmb { y } _ { i } = q ( \pmb { x } _ { i } ) \odot m ( i , \pmb { X } )\quad(3) yi=q(xi)⊙m(i,X)(3)
其中, q ( ⋅ ) q(\cdot) q(⋅) 是查询投影函数, ⊙ \odot ⊙ 是逐元素相乘操作。 m ( ⋅ ) m(\cdot) m(⋅) 是上下文聚合函数,其输出被称为调制器(modulator)。图 4(a) 和 (b) 比较了 Self-Attention 和 Focal Modulation。所提出的 Focal Modulation 具有以下有利特性:
- 平移不变性:由于 q ( ⋅ ) q(\cdot) q(⋅) 和 m ( ⋅ ) m(\cdot) m(⋅) 始终围绕查询 token i i i 进行计算,且不使用位置嵌入,因此调制操作对输入特征图 X \mathbf{X} X 的平移具有不变性。
- 显式输入依赖性:调制器是通过 m ( ⋅ ) m(\cdot) m(⋅) 计算的,该过程通过聚合目标位置 i i i 周围的局部特征来进行,因此我们的 Focal Modulation 显式地依赖于输入。
- 空间和通道特异性:目标位置 i i i 作为 m ( ⋅ ) m(\cdot) m(⋅) 的指针使得调制具有空间特异性。逐元素相乘操作使得调制具有通道特异性。
- 解耦的特征粒度: q ( ⋅ ) q(\cdot) q(⋅) 保留了个别 tokens 的最精细信息,而 m ( ⋅ ) m(\cdot) m(⋅) 提取了更粗的上下文信息。它们在调制过程中解耦,但通过调制结合在一起。
接下来,我们将详细描述式(3)中 m ( ⋅ ) m(\cdot) m(⋅) 的实现。

3.2 通过 m(·) 的上下文聚合
已经证明,短距离和长距离的上下文对视觉建模都很重要[95, 21, 55]。然而,单一的大接收域聚合不仅在时间和内存上计算开销较大,而且还会破坏局部的精细结构,而这些局部结构对于密集预测任务尤其重要。受到[95]的启发,我们提出了一种多尺度分层上下文聚合方法。如图4©所示,聚合过程包括两个步骤:分层上下文化以从局部到全局范围提取不同粒度的上下文,以及门控聚合以将不同粒度级别的所有上下文特征压缩到调节器中。
步骤1:分层上下文化。
给定输入特征图 X,我们首先通过一个线性层将其投影到一个新的特征空间中,得到 Z 0 = f z ( X ) ∈ R H × W × C . \mathbf { Z } ^ { 0 } =f _ { z } ( \mathbf { X } ) \in \mathbb { R } ^ { H \times W \times C } . Z0=fz(X)∈RH×W×C.。然后,使用一系列 L 个深度卷积堆叠,获得上下文的分层表示。在焦点层 ℓ ∈ { 1 , . . . , L } \ell \in \{ 1 , . . . , L \} ℓ∈{1,...,L},输出 Z ℓ { \bf Z } ^ { \ell } Zℓ由以下公式得出:
Z ℓ = f a ℓ ( Z ℓ − 1 ) ≜ G e L U ( D W C o n v ( Z ℓ − 1 ) ) ∈ R H × W × C ( 4 ) \mathbf { Z } ^ { \ell } = f _ { a } ^ { \ell } ( \mathbf { Z } ^ { \ell - 1 } ) \triangleq \mathsf { G e L U } ( \mathsf { D W C o n v } ( \mathbf { Z } ^ { \ell - 1 } ) ) \in \mathbb { R } ^ { H \times W \times C }\quad(4) Zℓ=faℓ(Zℓ−1)≜GeLU(DWConv(Zℓ−1))∈RH×W×C(4)
温馨提示:
阅读全文请访问"AI深语解构" FocalNet:焦点调制网络