零基础起步:基于GpuGeek的文本生成模型实战
在自然语言处理(NLP)领域,文本生成任务广泛应用于问答系统、智能摘要、内容创作等方向。本文将带领读者使用GpuGeek平台,从注册、上传数据到实例部署与训练,完整构建一个基于GPT2模型的文本生成系统,实战掌握AI模型的云端开发流程。
目录
一、GpuGeek平台使用流程详解
1. 注册与登录
2. 数据上传
3. 创建训练实例
4. 启动与使用实例
5. 关闭实例(手动 & 自动)
二、文本生成实战任务:微调GPT-2
1. 项目背景
2. 数据准备与上传
3. 实例创建并训练模型
安装依赖
数据预处理
模型训练
4. 保存模型并生成文本
一、GpuGeek平台使用流程详解
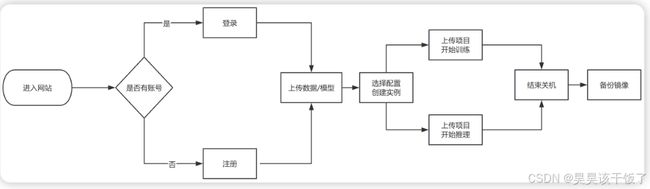
1. 注册与登录
访问 GpuGeek-弹性|便捷|划算,您的专属AI云 注册页面,使用手机号完成注册并登录平台,现在注册有赠送金额哦。
2. 数据上传
平台提供网盘存储功能。在【网盘存储】页面,可以查看存储使用情况和费用信息。点击上传按钮,将本地训练数据(如语料库、配置文件等)上传至指定区域的网盘。
⚠️ 注意:仅对应区域的数据中心可以访问该区域的网盘数据。
3. 创建训练实例
平台提供高算力、企业级安全与稳定性的训练环境。在【个人空间】或其他任意页面点击【创建实例】,根据需求选择:
-
绑定的网盘存储位置(与上传数据一致)
-
数据中心区域
-
实例配置(GPU型号、数据盘大小、内存等)
-
镜像(如 PyTorch + Transformers、JupyterLab 等)
-
计费方式(包月、包天、按量)
确认无误后点击【创建实例】,将自动跳转至【实例管理】页面等待创建完成。
4. 启动与使用实例
创建完成后,在【实例管理】中点击实例名称右侧的【JupyterLab】,自动跳转并打开 Web 控制台。
用户可通过 Web 方式执行代码、上传 notebook、训练模型等。
5. 关闭实例(手动 & 自动)
使用结束后,可手动关闭实例以节省费用。
亦可通过代码控制自动关闭(示例代码如下):
import os
os.system("poweroff")二、文本生成实战任务:微调GPT-2
1. 项目背景
目标:基于中文小说语料微调GPT2模型,实现中文文本生成。 数据集来源:网络爬取小说章节 模型:Huggingface Transformers - GPT2
2. 数据准备与上传
将准备好的纯文本语料(如 novel.txt)上传至GpuGeek网盘:
小说数据预览:
[段落1] 她望着窗外雨雾中的世界,心中百感交集……
[段落2] “你为什么还不回来?”他低声说……上传后记下存储路径,后续创建实例时绑定此网盘。
3. 实例创建并训练模型
创建 PyTorch + Transformers 镜像实例,挂载上述数据目录,打开 JupyterLab。
安装依赖
pip install transformers datasets accelerate数据预处理
from datasets import load_dataset
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
dataset = load_dataset('text', data_files={'train': '/mnt/novel.txt'})
def tokenize_fn(example):
return tokenizer(example['text'], truncation=True, padding='max_length', max_length=128)
tokenized = dataset.map(tokenize_fn, batched=True, remove_columns=["text"])模型训练
from transformers import GPT2LMHeadModel, Trainer, TrainingArguments
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
args = TrainingArguments(
output_dir="/mnt/gpt2-output",
per_device_train_batch_size=2,
num_train_epochs=3,
save_steps=1000,
logging_steps=100,
fp16=True,
report_to="none"
)
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized["train"]
)
trainer.train()4. 保存模型并生成文本
model.save_pretrained("/mnt/final-gpt2")
tokenizer.save_pretrained("/mnt/final-gpt2")
# 测试生成
inputs = tokenizer("她轻轻推开门", return_tensors="pt").input_ids.cuda()
outputs = model.generate(inputs, max_new_tokens=50, do_sample=True)
print(tokenizer.decode(outputs[0]))通过本次实战,读者掌握了如何在GpuGeek平台完成从注册到部署的全流程。平台的高性价比GPU、丰富镜像和网盘共享机制,使得NLP任务能快速启动、低成本完成。未来还可将生成模型部署为API或结合Gradio构建Web端交互系统。