分库分表之数据库分片分类
| 大家好,我是工藤学编程 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列 | 【SpringBoot实战系列】Sharding-Jdbc实现分库分表到分布式ID生成器Snowflake自定义wrokId实战 |
| 环境搭建大集合 | 环境搭建大集合(持续更新) |
| 分库分表 | 分库分表之优缺点分析 |
前情摘要:
本文章目录
- (一)垂直分库分表优化方案
-
- 一、垂直分表:基于字段访问频次的IO优化
-
- 1. 核心原理与应用场景
- 2. 拆分原则与实践案例
- 二、垂直分库:突破单机资源瓶颈的业务解耦
-
- 1. 核心价值与适用场景
- 2. 拆分策略与架构演进
- 三、垂直拆分的局限性
-
- 1. 未解决的核心问题
- (二)水平分库分表
-
- 一、水平分表:单库内的数据切片技术
-
- 1. 核心原理与应用场景
- 2. 拆分规则与实践案例
- 二、水平分库:跨服务器的数据分布技术
-
- 1. 核心价值与适用场景
- 2. 分库策略与架构演进
- 三、水平分库分表的技术挑战与解决方案
-
- 1. 核心技术难点
(一)垂直分库分表优化方案
一、垂直分表:基于字段访问频次的IO优化
1. 核心原理与应用场景
垂直分表是将单张大表按字段功能拆分为「主表」与「扩展表」,通过减少单次查询的IO数据量提升性能,尤其适用于以下场景:
- 表中存在大字段(如text/blob类型的商品描述、详情);
- 字段访问频次差异显著(如商品价格每日访问10万次,而商品详情每日访问1万次)。
2. 拆分原则与实践案例
三大拆分原则:
- 低频字段分离:将30天内访问频次<100次的字段放入扩展表;
- 大字段独立:text/blob类型字段(如商品详情)必须拆分,避免IO阻塞;
- 查询组合优先:经常一起查询的字段(如商品标题、价格、库存)保留在主表。
商品表拆分实例:
-- 拆分前(单表12字段,含4个大字段)
CREATE TABLE `product` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(524) DEFAULT NULL COMMENT '商品标题',
`cover_img` varchar(524) DEFAULT NULL COMMENT '封面图',
`price` int(11) DEFAULT NULL COMMENT '价格(分)',
`total` int(10) DEFAULT '0' COMMENT '总库存',
`left_num` int(10) DEFAULT '0' COMMENT '剩余库存',
`learn_base` text COMMENT '课前须知',
`learn_result` text COMMENT '学习目标',
`summary` varchar(1026) DEFAULT NULL COMMENT '商品概述',
`detail` text COMMENT '商品详情',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
-- 拆分后(主表6字段+扩展表6字段)
CREATE TABLE `product_main` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(524) DEFAULT NULL COMMENT '商品标题',
`cover_img` varchar(524) DEFAULT NULL COMMENT '封面图',
`price` int(11) DEFAULT NULL COMMENT '价格(分)',
`total` int(10) DEFAULT '0' COMMENT '总库存',
`left_num` int(10) DEFAULT '0' COMMENT '剩余库存',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_price` (`price`),
KEY `idx_stock` (`left_num`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `product_extend` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`product_id` int(11) NOT NULL COMMENT '主表ID',
`learn_base` text COMMENT '课前须知',
`learn_result` text COMMENT '学习目标',
`summary` varchar(1026) DEFAULT NULL COMMENT '商品概述',
`detail` text COMMENT '商品详情',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_product_id` (`product_id`),
KEY `idx_update` (`update_time`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
二、垂直分库:突破单机资源瓶颈的业务解耦
1. 核心价值与适用场景
垂直分库是按业务模块将数据拆分到不同数据库(如用户库、订单库、商品库),核心解决:
- 单机CPU/内存利用率长期>90%的性能瓶颈;
- 数据库连接数不足(如MySQL默认100连接数无法支撑高并发);
- 业务模块间资源竞争(如订单写入阻塞商品查询)。
2. 拆分策略与架构演进
典型演进路径:
单体架构(单库) → 垂直分库(按业务拆库) → 微服务架构(库+服务解耦)
电商系统分库实例:
拆分前:
- 数据库:ecommerce_db(含用户、订单、商品表)
- 问题:订单高峰期写入导致商品查询超时,CPU利用率95%
拆分后:
- 用户库:user_db(用户表、会员表)
- 订单库:order_db(订单表、订单详情表)
- 商品库:product_db(商品主表、商品扩展表)
- 效果:各库CPU利用率降至40-60%,连接数利用率降低30%
单体架构示意图:
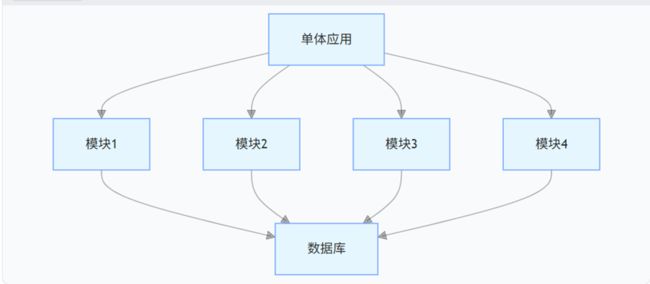
微服务架构示意图:

三、垂直拆分的局限性
1. 未解决的核心问题
垂直分库分表虽能提升并发与IO效率,但无法解决单表数据量过大的问题:
- 单表数据量瓶颈:如订单表日增10万条,1年后单表数据量达3650万,查询性能仍会下降;
- 跨库查询复杂性:如需要查询“用户近30天购买的商品”,需跨用户库、订单库、商品库关联,性能损耗显著。
(二)水平分库分表
一、水平分表:单库内的数据切片技术
1. 核心原理与应用场景
当单表数据量突破500万行时,索引效率大幅下降,全表扫描耗时从毫秒级飙升至秒级。水平分表通过将单表数据按规则拆分到N个结构相同的小表中,核心解决:
- 查询性能瓶颈:如订单表数据量达3000万时,单次查询耗时从500ms增至3s;
- 锁表时间过长:大表DDL操作(如添加字段)可能锁表数分钟,影响业务可用性。
2. 拆分规则与实践案例
三大主流拆分策略:
| 策略类型 | 拆分逻辑 | 典型场景 | 实现复杂度 |
|---|---|---|---|
| RANGE范围拆分 | 按时间/ID范围分片(如order_2024表存2024年订单) |
日志表、交易表等有时间特征的数据 | ★☆☆☆☆ |
| HASH取模拆分 | 按字段哈希值取模(如user_id % 100) |
用户中心、订单表等需均匀分布的数据 | ★★☆☆☆ |
| 复合拆分 | 组合RANGE+HASH(如先按年分表,再按用户ID取模) | 大规模历史数据归档场景 | ★★★☆☆ |
二、水平分库:跨服务器的数据分布技术
1. 核心价值与适用场景
当水平分表后单库仍面临资源瓶颈(如CPU利用率>90%、带宽跑满),需进一步水平分库,将数据分布到多个物理服务器,解决:
- 单机资源上限:单台数据库服务器CPU 32核、内存128GB的硬件限制;
- 并发连接瓶颈:单库MySQL最大连接数16384,高并发场景下仍可能不足;
- IO带宽限制:单台服务器磁盘IO吞吐量(如SSD约2000MB/s)无法支撑海量读写。
2. 分库策略与架构演进
典型分库方案对比:
| 方案类型 | 拆分维度 | 部署实例 | 适用场景 |
|---|---|---|---|
| 按业务分库 | 按模块拆分(如用户库、订单库) | 电商系统拆分为用户库+订单库+商品库 | 业务解耦优先,初期架构 |
| 按数据分库 | 按数据特征拆分(如用户ID取模分库) | 100个库,每个库存1%用户数据 | 高并发、海量数据场景 |
| 混合分库 | 先按业务分库,再按数据分表 | 订单库拆分为100个分库,每个库含10张分表 | 超大规模系统(如日活千万级应用) |
三、水平分库分表的技术挑战与解决方案
1. 核心技术难点
| 问题类型 | 具体表现 | 解决方案 |
|---|---|---|
| 跨库Join查询 | 订单库与商品库分库后,无法直接JOIN | 1. 冗余字段(订单表冗余商品名称) 2. 应用层聚合(先查订单ID,再批量查商品) |
| 分布式事务 | 跨库更新时事务一致性问题 | 1. 最终一致性(消息队列补偿) 2. 强一致性(2PC/3PC协议) |
| 全局主键生成 | 分库后自增ID冲突 | 1. 雪花算法(64位唯一ID) 2. 分布式ID生成器(如百度UidGenerator) |
| 分页排序 | 跨库查询时LIMIT 1000,10性能差 |
1. 前端限制分页深度 2. 二次查询优化(先查ID列表,再查详情) |