Dify文档喂不饱模型?别慌!Embedding 微调就是你的救星!
在 AI 时代,Embedding 是 NLP 任务的基石,直接决定了你的模型是「聪明绝顶」还是「笨拙不堪」。你是否遇到过这些让人头疼的问题:
- 做智能问答时,模型总是答非所问,用户一脸懵圈?
- 做推荐系统时,用户翻遍推荐内容,还是觉得「没一个对味」?
- 做语义搜索时,搜索结果五花八门,相关性差到让人抓狂?
这些问题的罪魁祸首,往往就是你的 Embedding 不够精准!通用 Embedding 在特定领域常常「水土不服」:
- 在电商搜索中,「苹果」是水果还是 iPhone,模型傻傻分不清?
- 在金融行业,「基金」和「理财」的微妙差别,模型完全抓瞎?
别慌!Embedding 微调就是你的救星!这篇文章将手把手带你解锁 Embedding 微调的秘密武器,让你的 NLP 任务更智能、更精准。无论你是初学者还是老司机,跟着这篇干货走,绝对有收获!要扔板砖就扔吧

一、什么是 Embedding 微调?为什么要微调?
1.1Embedding 到底是啥?
在 NLP 任务中,Embedding 是把文本转成计算机能理解的向量(数值表示)。这个向量会保留语义信息,比如:
- 「苹果 」 和 「水果 」 的向量应该很接近(语义相似)。
- 「苹果 」 和 「手机 」 的向量应该远一点(不同类别)。
1.2 通用 Embedding 的局限性
预训练的 Embedding 是在海量的通用数据上训练出来的,虽然它能处理大部分任务,但在一些特定领域可能会表现不佳。例如:
-
在电商搜索,「苹果」到底是指水果还是 iPhone?
-
在金融行业,“「基金」和「理财」的细微差别,普通 Embedding 无法捕捉。
-
在医疗行业,“CT” 既可以指计算机断层扫描(Computed Tomography),也可能是某种化学术语。
-
在法律行业,“合同” 可能要比 “协议” 重要,但通用 Embedding 可能无法体现这种差异。
如果你的搜索系统、推荐算法或问答机器人使用的是通用 Embedding,很可能会遇到匹配不精准、理解不准确等问题。
1.3 Embedding 微调的作用
通过微调 Embedding,我们可以让它更适应特定领域的数据,提升文本匹配的准确性。例如:
-
搜索优化:让搜索结果更符合用户预期。
-
推荐系统:提供更精准的个性化推荐。
-
问答系统(Chatbot):更准确地理解用户问题并返回合适答案。
-
文本分类:更精确地识别文本类别,提高分类模型的效果。
二、Embedding 微调的核心方法
Embedding 微调通常有两种方式:
2.1 无监督微调(Unsupervised Fine-tuning)
如果你手头有大量的未标注文本数据,可以采用无监督训练来更新 Embedding,例如:
- 继续训练 Word2Vec / FastText / GloVe,让它在你的领域语料上进一步学习。
- 使用 BERT / GPT 等模型的 MLM 任务(Masked Language Model),在你的数据上继续预训练。
这种方法适合行业语料较丰富,但缺乏明确的匹配标注数据的场景。
2.2 监督微调(Supervised Fine-tuning)
如果你有正负样本对(Positive & Negative Pairs),可以采用对比学习(Contrastive Learning)进行微调。典型做法包括:
- 使用相似度匹配数据集,让模型学习哪些句子是相似的,哪些是不相似的。
- 采用Triplet Loss 或 Cosine Similarity Loss,让 Embedding 在语义空间中更具区分度。
- 引入动态难负样本(Hard Negative Mining),让模型进一步提升难样本的区分能力。
这种方法适合需要精准文本匹配的任务,例如搜索、问答、推荐系统。
三、如何微调 Embedding(完整代码实战)

3.1选择一个预训练模型
我们可以直接用 Hugging Face 的 Sentence-BERT (SBERT) 作为基础模型,节省训练时间。
from sentence_transformers import SentenceTransformer
# 选择一个预训练的 embedding 模型model = SentenceTransformer("all-MiniLM-L6-v2")
# 试试效果sentences = ["如何申请发票?", "开发票的流程是什么?"]embeddings = model.encode(sentences)print(embeddings.shape) # (2, 384)
解释:
all-MiniLM-L6-v2是一个轻量级的 Sentence-BERT 模型,适用于 NLP 任务。model.encode()将文本转为384 维的向量,便于计算语义相似度。
3.2准备数据(正负样本对)
微调过程中,我们需要让模型学习哪些句子语义相似,哪些不相似。
from sentence_transformers import InputExample
train_data = [ InputExample(texts=["如何申请发票?", "开发票的流程是什么?"], label=1.0), # 语义相似(正样本) InputExample(texts=["如何申请发票?", "如何报销机票?"], label=0.0), # 语义不相似(负样本)]
数据解释:
label=1.0表示两个句子语义相似。label=0.0表示两个句子完全无关。
但这样选负样本 太简单了! 真实世界里,模型真正难区分的是 「难负样本」,比如:
- 「如何申请发票?」 vs 「如何开增值税发票?」(看上去很像,但实际可能不同!)
- 「如何优化 SEO?」 vs 「SEO 优化的技巧是什么?」(微妙的不同)
我们需要 动态难负样本 来让模型学习更复杂的语义关系!
3.3动态难负样本(Hard Negative Mining)
动态难负样本的思路:
- 用模型计算文本相似度(Cosine Similarity)。
- 选取相似度高但标签为负的样本,作为「难负样本」。通过这一步可以极大提升模型效果!
from torch.nn.functional import cosine_similarityimport torch
def find_hard_negatives(embeddings, threshold=0.7): """动态挖掘难负样本""" hard_negatives = [] num_samples = len(embeddings)
for i in range(num_samples): for j in range(num_samples): if i != j: sim_score = cosine_similarity(embeddings[i].unsqueeze(0), embeddings[j].unsqueeze(0)) if sim_score > threshold: hard_negatives.append((sentences[i], sentences[j], sim_score.item()))
return hard_negatives
# 计算 embeddingsembeddings = model.encode(sentences, convert_to_tensor=True)
# 挖掘难负样本hard_negatives = find_hard_negatives(embeddings)# 打印示例for sample in hard_negatives: print(f"Anchor: {sample[0]}, Hard Negative: {sample[1]}, Similarity: {sample[2]:.4f}")
3.4构造训练数据
train_data = []
# 正样本train_data.append(InputExample(texts=["如何申请发票?", "开发票的流程是什么?"], label=1.0))
# 负样本train_data.append(InputExample(texts=["如何申请发票?", "如何报销机票?"], label=0.0))
# 动态难负样本for hn in hard_negatives: train_data.append(InputExample(texts=[hn[0], hn[1]], label=0.2)) # 赋予较低的相似度标签
# 加载训练数据train_dataloader = DataLoader(train_data, shuffle=True, batch_size=16)train_loss = losses.CosineSimilarityLoss(model)
# 训练模型model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=3, warmup_steps=100)
# 保存微调后的模型model.save("fine_tuned_embedding")
四、真实业务场景
你可以这么用:
- 智能客服:让 AI 机器人更准确匹配用户问题,提升回复精准度。
- 文档检索:让搜索更懂语义,而不仅仅是关键词匹配。
- 推荐系统:用户搜索「Python 入门」,推荐更相关的文章,而不是只看关键词。
微调后的 Embedding,让 AI 变得更聪明!
五、总结
通过 Embedding 微调,你的 AI 系统将迎来质的飞跃:搜索更精准、推荐更贴心、问答更聪明。无论是优化智能客服、提升文档检索效率,还是打造个性化推荐,微调后的 Embedding 都能让你的项目大放异彩!
你在 NLP 任务中遇到过 Embedding 不准的坑吗?或者你已经尝试过微调,有什么独家经验?快来评论区分享你的故事吧!让我们一起碰撞思路,让 AI 变得更聪明,让更多人解锁 Embedding 微调的魅力!
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
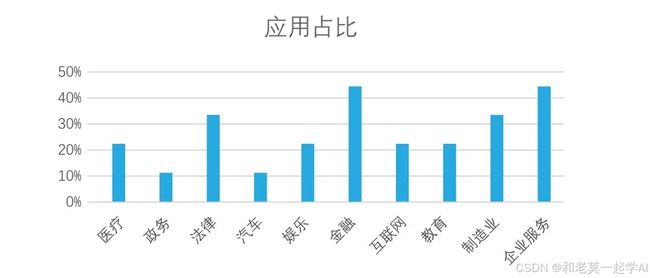
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
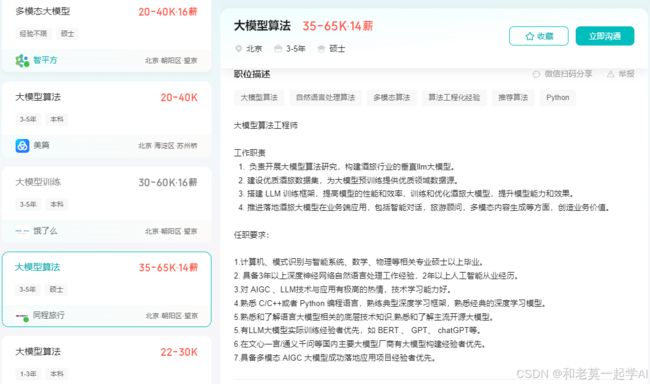
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。

四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全
朋友们如果有需要的话,可以V扫描下方二维码联系领取~
